
Mula-mula kita perlu tahu, Apabila CPU mengakses memori, ia tidak mengakses memori secara langsung, tetapi mula-mula mengakses cache (cache). CPU访问内存时,不是直接去访问内存的,而是先访问缓存(cache)。
当缓存中已经有了我们要的数据时,CPU就会直接从缓存中读数据,而不是从内存中读。
CPU和缓存的关系如下:
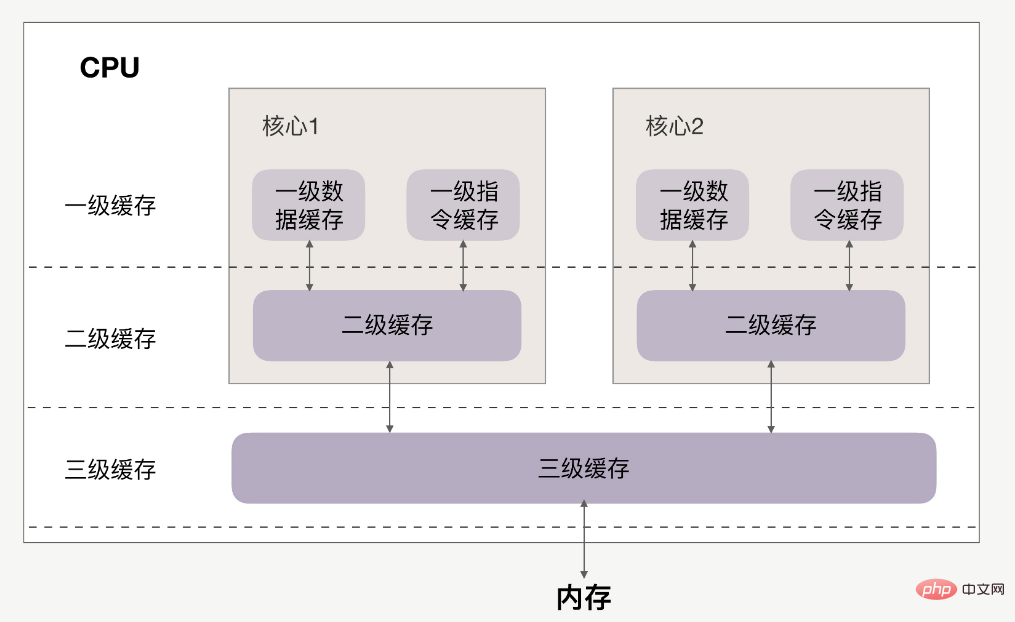
缓存分为一级、二级、三级,最靠近CPU的是一级缓存,最远的是内存,离CPU越近速度越快。
访问速度上,L1>L2>L3>内存,缓存比内存速度要快得非常多。
如果CPU操作的数据在缓存中,则直接从缓存中读取,这个过程就叫缓存命中。
因此提升性能的关键,就是要提高缓存命中率。下面来看如何提高缓存命中率。
来看一个实例,有一个N*N
CPU akan membaca data terus daripada cache dan bukannya membaca daripada memori.
CPU dan cache Hubungannya adalah seperti berikut: 🎜N*N tatasusunan dua dimensi, sebagai contoh: 🎜int array[N][N];
for(i = 0; i < N; i+=1)
{
for(j = 0; j < N; j+=1)
{
array[i][j] = 0;//速度快
//array[j][i] = 0;//速度慢
}
}有两种访问方式:array[i][j]和array[j][i]。
在性能上,array[i][j]会比array[j][i]执行地更快,并且速度相差8倍。
首先数组在内存上是连续的,假设N等于2,则array[2][2]在内存中的排布是:
array[0][0]、array[0][1]、array[1][0]、array[1][1]、
以array[i][j]方式访问,即按内存中的顺序访问,当访问array[0][0]时,CPU就已经把数组的剩余三个数据(array[0][1]、array[1][0]、array[1][1])加载到了缓存当中。
当继续访问后三个元素时,CPU会直接从缓存中读取数据,而不需要从内存中读取(cache命中)。因此速度会很快。
如果以array[j][i]方式访问数组,则访问顺序为:
array[0][0]、array[1][0]、array[0][1]、array[1][1]
此时访问顺序是跳跃的,并不是按数组在内存中的的排布顺序来访问。如果N很大的话,那么执行array[j][i]时,array[j+1][i]的内容是没法读进缓存里的,等到要访问array[j+1][i]时就只能从内存中读取。
所以array[j][i]的速度会慢于array[i][j]。
刚刚提到,如果这个二维数组的N很大,array[j+1][i]的内容是没法读到缓存里的,那CPU一次能够将多少数据加载进缓存里呢?
这个其实跟cache line有关,cache line代表缓存一次载入数据的大小。可以通过以下命令查看cache line为多大:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size

cache line为64,代表CPU缓存一次数据的大小为64字节。
Apabila melawati array[0][0]</code >, bilangan bait yang diduduki oleh elemen adalah kurang daripada <code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;background-color : rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239, 112, 96);"> 64 bait, CPU Seterusnya elemen akan ditambah mengikut susunan dan array[0 ][1], array [1] [0]Baca kandungan ke dalam cache bersama-sama sehingga cukup64 bait. array[0][0]时,该元素所占用的字节数不到64字节,CPU就会按顺序补足后续元素,就会把后面的array[0][1]、array[1][0]等内容一起读到缓存里,直到凑够64字节。
正因如此,按顺序访问的array[i][j]才会比不按顺序访问的array[j][i]
array[i ][j ] akan menjadi lebih baik daripada yang diakses tanpa tertibarray[j][i] adalah pantas. 🎜Mari kita lihat mengapa kelajuannya berbeza 8倍。我们知道,二维数组中,第一维元素放的是地址,第二维元素才是数据。64位系统中,地址占用8个字节,cache line为64的话,地址已经占用了8字节,那每个cache line最多能载入不到8个二维数组元素,N很大的情况下,他们的性能平均下来就会相差将近8 kali.
Kesimpulan: Mengakses dalam susunan susun atur memori boleh meningkatkan kadar hit cache data. .
有一个数组
array,数组元素内容为0-255之间的随机数:int array[N]; for (i = 0; i < TESTN; i++) array[i] = rand() % 256;Salin selepas log masuk现在,要把数组中数字小于128的元素置为0,并且对数组排序。
大家应该都能想到,有两种方法:
先遍历数组,把小于128的元素置为0,然后排序。 先对数组排序,再遍历数组,把小于128的元素置为0。 for(i = 0; i < N; i++) { if (array [i] < 128) array[i] = 0; } sort(array, array +N);Salin selepas log masuk先排序后遍历的速度会比较快,为什么?
因为在
for循环中会执行很多次if分支判断语句,而CPU拥有分支预测器。如果分支预测器可以预测接下来要执行的分支(执行
if还是执行else),那么就可以提前把这些指令放到缓存中,CPU执行的时候就会很快了。如果一个数组的内容完全随机的话,那么分支预测器就很难进行正确的预测。但如果数组内容是有序的,它就会根据历史命中数据的情况对未来进行预测,那命中率就会很高,所以先排序后遍历的速度会比较快。
怎么验证指令缓存命中率的情况呢?
在
Linux下,可以使用Perf性能分析工具进行验证。通过 -e选项,指定 branch-loads和cabang-loads-miss事件,可以分别统计出分支预测成功的测kuat>和分支预测失败的次数,通过L1-cache-load-misses事件也能统计一级缓存中指令未命中的次数。但是,这些性产缓存中指令未命中的次数。但是,这些性产能䎬些性令未命中的次数。 ,perf工具能否统计这些事件取决于CPU是否支持以及芯片原厂是否去实现了现了都 是 不 支持 或者 或者 没 实现 的。Linux下,可以使用Perf性能分析工具进行验证。通过-e选项,指定branch-loads和branch-loads-misses事件,可以分别统计出分支预测成功的次数和分支预测失败的次数,通过L1-icache-load-misses事件也能统计一级缓存中指令未命中的次数。但是,这些性能事件都属于硬件事件,perf工具能否统计这些事件取决于CPU是否支持以及芯片原厂是否去实现了该接口,我看很多都是不支持或者没实现的。另外,在Linux内核中,可以看到大量的
likely和unlikely宏,并且它们都出现if语句中,这两个宏的作用就是为了提高性能。这是显示预测概率的宏,如果你觉得CPU的分支预测不准,但
另外, 在 linux 内核 中, 可以 看到 看到 的 的if中条件为"真"的概率很高,那么你就可以使用likely()kemungkinan和tidak mungkin宏,并且它们都出现jika语句中,这两个宏的作用就是为了提高性能。🎜🎜这是显示预用就是为了提高性能。 CPU的分支预测不准,但if中条件为"真"的概率很高,那么你就可以使用kemungkinan()括起来,以此提升性能。🎜#define likely(x) __builtin_expect(!!(x), 1) #define unlikely(x) __builtin_expect(!!(x), 0) if (likely(a == 1)) …Salin selepas log masuk提高多核CPU下的缓存命中率
首先要清楚,一级缓存、二级缓存是每颗核心独享的,三级缓存则面向所有核心。
但多核CPU下的系统有个特点,存在CPU核心迁移问题。
Sebagai contoh, proses
A在时间片内使用CPU核心1,自然填满了CPU核心1的一、二级缓存,但基于调度策略,时间片结束后,CPU核心1会被让出,防止某些进程饿死。如果此时CPU核心1很忙,那么进程A很可能就会被调度到CPU核心2上运行。这样的话,无论我们怎么优化代码,也只能在一个时间片内高效地使用CPUcache tahap pertama dan kedua akan menghadapi isu kecekapan cache dalam kepingan masa seterusnya.Dalam kes ini, anda boleh mempertimbangkan untuk mengikat proses kepada CPU untuk dijalankan.
perfalatan juga menyediakan prestasi jenis ini Statistik acara dipanggilcpu-migration, IaituBilangan pemindahan CPUperf工具也提供了这类性能事件的统计,叫cpu-migrations,即CPU迁移次数。CPU迁移次数多的话,缓存效率就会低。将进程绑定CPU运行,性能也会得到提升。
总结
这些是
Ikat proses ke CPU untuk dijalankan, dan prestasi juga akan dipertingkatkan.CPU. Jika bilangan migrasi CPU adalah besar, kecekapan cache akan menjadi rendah.Ringkasan
Ini ialahImpak CPUcache pada prestasi, ini sudah menjadi tahap yang sangat rendah pengoptimuman prestasi, tidak kira bahasa pengaturcaraan yang sah.
Sangat memahami caching, saya percaya pemahaman anda tentang lapisan asas akan sangat membantu. . proses ke CPU untuk dijalankan
Atas ialah kandungan terperinci Pengoptimuman prestasi tahap sangat rendah: biarkan CPU melaksanakan kod anda dengan lebih pantas. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



