
1 |
|
1 |
|
 masalah biasa
Dikenali sebagai sistem pengawasan generasi akan datang, mari lihat betapa hebatnya sistem tersebut!
masalah biasa
Dikenali sebagai sistem pengawasan generasi akan datang, mari lihat betapa hebatnya sistem tersebut!
Dikenali sebagai sistem pengawasan generasi akan datang, mari lihat betapa hebatnya sistem tersebut!

Prometheus ialah sistem pemantauan dan penggera sumber terbuka berdasarkan pangkalan data siri masa, kita perlu menyebut SoundCloud, yang merupakan platform perkongsian muzik dalam talian, serupa dengan YouTube untuk perkongsian video. . Semasa mereka bergerak lebih jauh ke jalan seni bina perkhidmatan mikro, dengan ratusan atau ribuan perkhidmatan muncul, terdapat banyak batasan dalam menggunakan sistem pemantauan tradisional StatsD dan Graphite.
Jadi mereka mula membangunkan sistem pemantauan baharu pada tahun 2012. Pengarang asal Prometheus ialah Matt T. Proud, yang juga menyertai SoundCloud pada tahun 2012. Malah, sebelum menyertai SoundCloud, Matt telah bekerja di Google, dia mendapat inspirasi daripada pengurus kluster Google dan sistem pemantauannya Borgmon sistem pemantauan sumber Prometheus Seperti kebanyakan projek Google, bahasa pengaturcaraan yang digunakan ialah Go.
Jelas sekali, sebagai penyelesaian untuk sistem pemantauan seni bina perkhidmatan mikro, Prometheus juga tidak dapat dipisahkan daripada bekas. Seawal 9 Ogos 2006, Eric Schmidt mula mencadangkan konsep pengkomputeran awan (Cloud Computing) pada Persidangan Enjin Carian Dalam tempoh sepuluh tahun berikutnya, perkembangan pengkomputeran awan telah berkembang pesat.
Pada 2013, Matt Stine dari Pivotal mencadangkan konsep Cloud Native Cloud Native terdiri daripada seni bina perkhidmatan mikro, DevOps dan infrastruktur tangkas yang diwakili oleh kontena untuk membantu perusahaan dengan cepat, berterusan, boleh dipercayai dan berskala.
Untuk menyatukan antara muka pengkomputeran awan dan piawaian yang berkaitan, pada Julai 2015, Cloud Native Computing Foundation (CNCF), yang bergabung dengan Linux Foundation, telah wujud. Projek pertama yang menyertai CNCF ialah Kubernetes Google, dan Prometheus adalah yang kedua menyertainya (pada 2016).
1. Gambaran keseluruhan Prometheus
Kami boleh mencari artikel di blog rasmi SoundCloud tentang sebab mereka perlu membangunkan sistem pemantauan baharu, Prometheus: Pemantauan di SoundCloud Dalam artikel ini, mereka memperkenalkan, Sistem pemantauan yang mereka keperluan mesti memenuhi empat ciri berikut:
Model data berbilang dimensi, supaya data boleh dihiris dan dipotong dadu sesuka hati, sepanjang dimensi seperti contoh, perkhidmatan, titik akhir dan kaedah. Kesederhanaan operasi, supaya anda boleh memutarkan pelayan pemantauan di mana dan bila-bila masa anda mahu, walaupun di stesen kerja tempatan anda, tanpa menyediakan bahagian belakang storan teragih atau mengkonfigurasi semula dunia. Pengumpulan data boleh skala dan seni bina terdesentralisasi, supaya anda boleh memantau dengan pasti banyak contoh perkhidmatan anda, dan pasukan bebas boleh menyediakan pelayan pemantauan bebas Akhir sekali, bahasa pertanyaan yang berkuasa yang memanfaatkan model data untuk makluman yang bermakna (termasuk pembungkaman mudah) dan grafik. (untuk papan pemuka dan untuk penerokaan ad-hoc).
Ringkasnya, ia adalah empat ciri berikut:
multi-dimensi model data pengumpulan dan penyelenggaraan data pengumpulan data fakta yang berkuasa, fakta query fakta, model data berbilang dimensi dua bahagian dan bahasa pertanyaan yang kuat Ciri ini adalah persis apa yang diperlukan oleh pangkalan data siri masa, jadi Prometheus bukan sahaja sistem pemantauan, tetapi juga pangkalan data siri masa. Jadi mengapa Prometheus tidak secara langsung menggunakan pangkalan data siri masa sedia ada sebagai storan belakang? Ini kerana SoundCloud bukan sahaja mahu sistem pemantauan mereka mempunyai ciri-ciri pangkalan data siri masa, tetapi juga perlu sangat mudah untuk digunakan dan diselenggara. Melihat pangkalan data siri masa yang lebih popular (lihat lampiran di bawah), ia sama ada mempunyai terlalu banyak komponen atau mempunyai kebergantungan luaran yang berat Contohnya: Druid mempunyai sekumpulan komponen seperti Historical, MiddleManager, Broker, Coordinator, Overlord, dan Penghala, dan ia juga bergantung pada Untuk ZooKeeper, Storan dalam (HDFS atau S3, dsb.), stor Metadata (PostgreSQL atau MySQL), kos penggunaan dan penyelenggaraan adalah sangat tinggi. Prometheus menggunakan seni bina terpencar yang boleh digunakan secara bebas dan tidak bergantung pada storan teragih luaran Anda boleh membina sistem pemantauan dalam beberapa minit. Selain itu, kaedah pengumpulan data Prometheus juga sangat fleksibel. Untuk mengumpul data pemantauan sasaran, anda perlu memasang komponen pengumpulan data pada sasaran Ini dipanggil Pengeksport Ia akan mengumpul data pemantauan pada sasaran dan mendedahkan antara muka HTTP untuk Prometheus mengumpulnya melalui Pull . Data, ini berbeza daripada mod Tekan tradisional. Walau bagaimanapun, Prometheus juga menyediakan cara untuk menyokong mod Push Anda boleh menolak data anda ke Push Gateway, dan Prometheus memperoleh data daripada Push Gateway melalui Pull. Pengeksport semasa sudah boleh mengumpul kebanyakan data pihak ketiga, seperti Docker, HAProxy, StatsD, JMX, dll. Tapak web rasmi mempunyai senarai Pengeksport. -
Sebagai tambahan kepada empat ciri utama ini, semasa Prometheus terus berkembang, ia mula menyokong ciri yang lebih dan lebih maju, seperti: penemuan perkhidmatan, paparan carta yang lebih kaya, penggunaan storan luaran, peraturan penggera yang berkuasa dan pelbagai kaedah pemberitahuan.
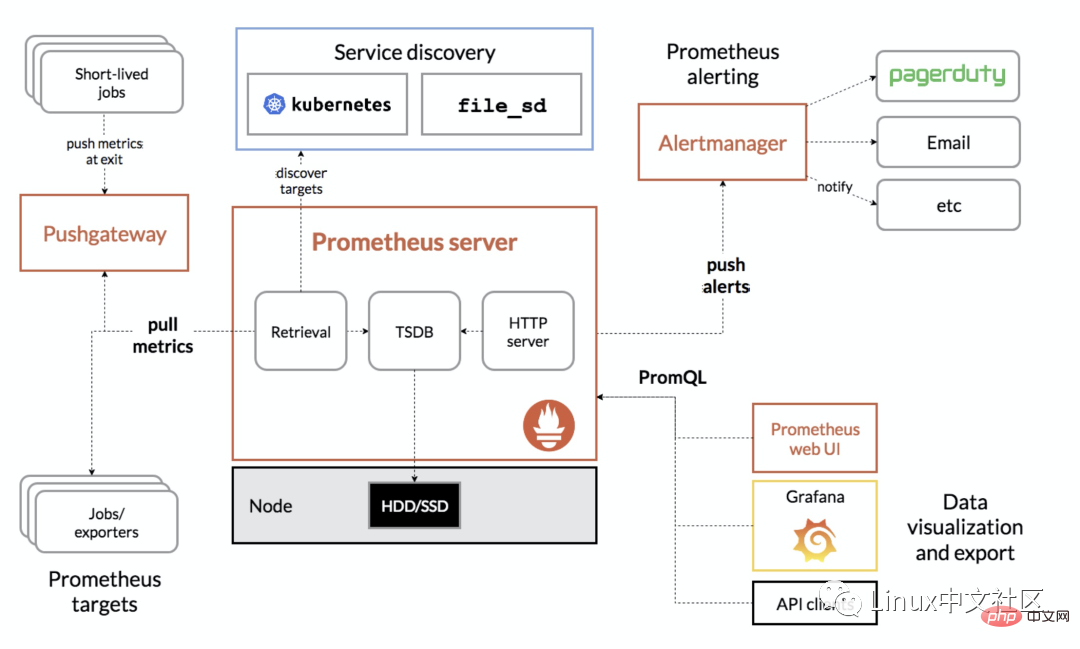
Gambar berikut ialah gambar rajah seni bina keseluruhan Prometheus:

Seperti yang dapat dilihat daripada gambar di atas, ekosistem Prometheus merangkumi beberapa komponen utama: pelayan Prometheus, Pushgateway, Alertmanager, dsb. , tetapi yang besar Kebanyakan komponen tidak diperlukan, dan komponen teras sudah tentu pelayan Prometheus, yang bertanggungjawab untuk mengumpul dan menyimpan data penunjuk, menyokong pertanyaan ekspresi dan menjana penggera. Seterusnya kami akan memasang pelayan Prometheus. 2. Pasang pelayan Prometheus
Prometheus boleh menyokong pelbagai kaedah pemasangan, termasuk Docker, Ansible, Chef, Puppet, Saltstack, dll. Dua kaedah paling mudah diperkenalkan di bawah Salah satunya ialah menggunakan fail boleh laku yang tersusun, yang boleh digunakan di luar kotak, dan satu lagi adalah menggunakan imej Docker.
Kemudian tukar Pergi ke direktori unzip dan semak versi Prometheus:1
$ wget https://github.com/prometheus/prometheus/releases/download/v2.4.3/prometheus-2.4.3.linux-amd64.tar.gz $ tar xvfz prometheus-2.4.3.linux-amd64.tar.gzSalin selepas log masukJalankan pelayan Prometheus:1
$ cd prometheus-2.4.3.linux-amd64 $ ./prometheus --version prometheus, version 2.4.3 (branch: HEAD, revision: 167a4b4e73a8eca8df648d2d2043e21bdb9a7449) build user: root@1e42b46043e9 builddate: 20181004-08:42:02 go version: go1.11.1Salin selepas log masuk2.2 Gunakan imej Docker Lebih mudah untuk memasang Prometheus menggunakan Docker, hanya jalankan arahan berikut:1
$ ./prometheus --config.file=prometheus.ymlSalin selepas log masukSecara amnya:
, kami juga akan menentukan konfigurasi Lokasi fail:Kami meletakkan fail konfigurasi di lokasi1
$ sudo docker run -d -p 9090:9090 prom/prometheusSalin selepas log masuksetempat, iaitu lokasi fail konfigurasi lalai yang dimuatkan oleh prometheus dalam bekas.
如果我们不确定默认的配置文件在哪,可以先执行上面的不带
-v参数的命令,然后通过docker inspect命名看看容器在运行时默认的参数有哪些(下面的 Args 参数):1
$ sudo docker inspect 0c [...]"Id":"0c4c2d0eed938395bcecf1e8bb4b6b87091fc4e6385ce5b404b6bb7419010f46","Created":"2018-10-15T22:27:34.56050369Z","Path":"/bin/prometheus","Args": ["--config.file=/etc/prometheus/prometheus.yml","--storage.tsdb.path=/prometheus","--web.console.libraries=/usr/share/prometheus/console_libraries","--web.console.templates=/usr/share/prometheus/consoles"], [...]Salin selepas log masuk2.3 配置 Prometheus
正如上面两节看到的,Prometheus 有一个配置文件,通过参数
<span style="outline: 0px;color: rgb(0, 0, 0);">--config.file</span>来指定,配置文件格式为 YAML。我们可以打开默认的配置文件<span style="outline: 0px;color: rgb(0, 0, 0);">prometheus.yml</span>看下里面的内容:1
/etc/prometheus $ cat prometheus.yml # myglobalconfigglobal: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. Thedefaultis every 1 minute. # scrape_timeout is set to theglobaldefault(10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules onceandperiodically evaluate them according to theglobal'evaluation_interval'. rule_files: # -"first_rules.yml"# -"second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is addedasa label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']Salin selepas log masukPrometheus 默认的配置文件分为四大块:
blok global: Konfigurasi global Prometheus, seperti scrape_intervalmewakili bagaimana lama Prometheus mengambil data Ambil sekali,evaluation_intervalmenunjukkan kekerapan peraturan penggera dikesan ;alerting 块:关于 Alertmanager 的配置,这个我们后面再看; rule_files 块:告警规则,这个我们后面再看; scrape_config 块:这里定义了 Prometheus 要抓取的目标,我们可以看到默认已经配置了一个名称为
prometheus的 job,这是因为 Prometheus 在启动的时候也会通过 HTTP 接口暴露自身的指标数据,这就相当于 Prometheus 自己监控自己,虽然这在真正使用 Prometheus 时没啥用处,但是我们可以通过这个例子来学习如何使用 Prometheus;可以访问http://localhost:9090/metrics查看 Prometheus 暴露了哪些指标;
scrape_interval表示 Prometheus 多久抓取一次数据,evaluation_interval表示多久检测一次告警规则;三、学习 PromQL
通过上面的步骤安装好 Prometheus 之后,我们现在可以开始体验 Prometheus 了。Prometheus 提供了可视化的 Web UI 方便我们操作,直接访问
blok amaran: Mengenai konfigurasi Alertmanager, kita akan lihat ini kemudian;http://localhost:9090/🎜
scrape_config blok: Prometheus ditakrifkan di sini Untuk sasaran yang ditangkap, kita dapat melihat bahawa ia telah dikonfigurasikan dengan nama bernama prometheus</code > kerja, ini kerana Prometheus juga akan mendedahkan data penunjuknya sendiri melalui antara muka HTTP apabila ia dimulakan, yang bersamaan dengan pemantauan Prometheus itu sendiri. Walaupun ini tidak berguna apabila sebenarnya menggunakan Prometheus, kita boleh gunakan contoh ini untuk Ketahui cara menggunakan Prometheus; lawati <code style="margin: 3px;padding: 3px;outline: 0px;font-size: 14px;border-radius: 4px;font-family: "Operator Mono", Consolas , Monaco, Menlo , monospace;word-break: break-all;color: rgb(155, 110, 35);background-color: rgb(255, 245, 227);">http://localhost:9090/metrics Lihat penunjuk yang Prometheus dedahkan 🎜
3. Belajar PromQL
Selepas memasang Prometheus melalui langkah di atas, kini kita boleh mula mengalami Prometheus. Prometheus menyediakan UI Web visual untuk memudahkan operasi kami http://localhost:9090 / , ia akan melompat ke halaman Graf secara lalai: 🎜
Anda mungkin berasa terharu apabila melawat halaman ini untuk pertama kalinya. , Bendera Baris Perintah, Konfigurasi, Peraturan, Sasaran, Penemuan Perkhidmatan, dsb.
Sebenarnya, halaman Graf ialah fungsi Prometheus yang paling berkuasa Di sini kita boleh menggunakan ungkapan khas yang disediakan oleh Prometheus untuk menanyakan data pemantauan ini dipanggil PromQL (Prometheus Query Language). Anda bukan sahaja boleh menanyakan data pada halaman Graf melalui PromQL, tetapi anda juga boleh menanyakannya melalui API HTTP yang disediakan oleh Prometheus. Data pemantauan yang ditanya boleh dipaparkan dalam dua bentuk: senarai dan graf (sepadan dengan dua label Konsol dan Graf dalam rajah di atas).
Seperti yang kami katakan di atas, Prometheus sendiri juga mendedahkan banyak penunjuk pemantauan, yang juga boleh ditanya pada halaman Graf Kembangkan kotak lungsur di sebelah butang Laksanakan, dan anda boleh melihat banyak nama penunjuk sesuka hati, contohnya: promhttp_metric_handler_requests_total, penunjuk ini mewakili /metrics Bilangan lawatan ke halaman. Prometheus menggunakan halaman ini untuk menangkap data pemantauannya sendiri . Hasil pertanyaan dalam teg Konsol adalah seperti berikut: promhttp_metric_handler_requests_total,这个指标表示 /metrics 页面的访问次数,Prometheus 就是通过这个页面来抓取自身的监控数据的。在 Console 标签中查询结果如下:

上面在介绍 Prometheus 的配置文件时,可以看到 scrape_interval 参数是 15s,也就是说 Prometheus 每 15s 访问一次 /metrics
scrape_interval parameter ialah 15s , iaitu, Prometheus mengakses sekali setiap 15 saat /metrics halaman, jadi kami lulus Muat semula halaman dalam 15 saat dan anda akan melihat bahawa nilai penunjuk akan meningkat secara automatik. Ini boleh dilihat dengan lebih jelas dalam tag Graf: 🎜🎜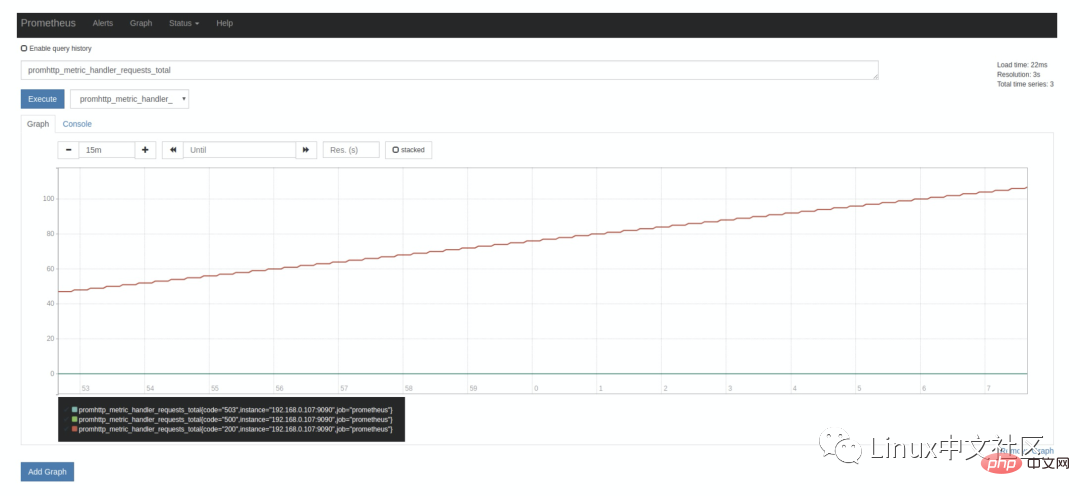
要学习 PromQL,首先我们需要了解下 Prometheus 的数据模型,一条 Prometheus 数据由一个指标名称(metric)和 N 个标签(label,N >= 0)组成的,比如下面这个例子:
1 |
|
这条数据的指标名称为 promhttp_metric_handler_requests_total,并且包含三个标签 code、instance 和 job,这条记录的值为 106。上面说过,Prometheus 是一个时序数据库,相同指标相同标签的数据构成一条时间序列。如果以传统数据库的概念来理解时序数据库,可以把指标名当作表名,标签是字段,timestamp 是主键,还有一个 float64 类型的字段表示值(Prometheus 里面所有值都是按 float64 存储)。
Model data ini serupa dengan model data OpenTSDB Untuk maklumat terperinci, sila rujuk kepada dokumen laman web rasmi Model data. Di samping itu, mengenai penamaan penunjuk dan label, tapak web rasmi mempunyai beberapa cadangan panduan, anda boleh merujuk kepada Metrik dan penamaan label .
Walaupun data yang disimpan dalam Prometheus ialah nilai float64, jika kita membahagikannya mengikut jenis, data Prometheus boleh dibahagikan kepada empat kategori utama:
Counter Tolok -
Ringkasan
Pembilang digunakan untuk mengira, seperti: bilangan permintaan, bilangan penyiapan tugas dan bilangan ralat Nilai ini akan sentiasa meningkat dan tidak akan berkurangan. Tolok ialah nilai umum, yang boleh besar atau kecil, seperti perubahan suhu dan perubahan penggunaan memori. Histogram ialah histogram, atau carta bar, yang sering digunakan untuk menjejaki skala peristiwa, seperti masa permintaan dan saiz tindak balas.
Apa yang istimewa tentangnya ialah ia boleh mengumpulkan kandungan yang dirakam dan menyediakan fungsi kiraan dan jumlah. Ringkasan sangat serupa dengan Histogram dan juga digunakan untuk menjejak skala kejadian peristiwa Perbezaannya ialah ia menyediakan fungsi kuantil yang boleh membahagikan hasil penjejakan dengan peratusan. Contohnya: nilai kuantil 0.95 bermakna mengambil 95% daripada data dalam nilai sampel. Untuk maklumat lanjut, sila rujuk dokumen laman web rasmi Jenis metrik Konsep Ringkasan dan Histogram agak mudah dikelirukan dan merupakan jenis penunjuk tertib tinggi Anda boleh merujuk kepada penerangan Histogram dan ringkasan di sini.
这四种类型的数据只在指标的提供方作区分,也就是上面说的 Exporter,如果你需要编写自己的 Exporter 或者在现有系统中暴露供 Prometheus 抓取的指标,你可以使用 Prometheus client libraries,这个时候你就需要考虑不同指标的数据类型了。如果你不用自己实现,而是直接使用一些现成的 Exporter,然后在 Prometheus 里查查相关的指标数据,那么可以不用太关注这块,不过理解 Prometheus 的数据类型,对写出正确合理的 PromQL 也是有帮助的。
3.2 PromQL 入门
我们从一些例子开始学习 PromQL,最简单的 PromQL 就是直接输入指标名称,比如:
1 |
|
这条语句会查出 Prometheus 抓取的所有 target 当前运行情况,譬如下面这样:
1 |
|
也可以指定某个 label 来查询:
1 |
|
这种写法被称为 Instant vector selectors,这里不仅可以使用 = 号,还可以使用 !=、=~、!~,比如下面这样:
1 |
|
=~ 是根据正则表达式来匹配,必须符合 RE2 的语法。
和 Instant vector selectors 相应的,还有一种选择器,叫做 Range vector selectors,它可以查出一段时间内的所有数据:
1 |
|
这条语句查出 5 分钟内所有抓取的 HTTP 请求数,注意它返回的数据类型是 Range vector,没办法在 Graph 上显示成曲线图,一般情况下,会用在 Counter 类型的指标上,并和 rate() 或 irate() 函数一起使用(注意 rate 和 irate 的区别)。
搜索公众号Java后端栈回复“面试”,送你一份惊喜礼包。
1 |
|
此外,PromQL 还支持 count、sum、min、max、topk 等 聚合操作,还支持 rate、abs、ceil、floor 等一堆的 内置函数,更多的例子,还是上官网学习吧。如果感兴趣,我们还可以把 PromQL 和 SQL 做一个对比,会发现 PromQL 语法更简洁,查询性能也更高。
3.3 HTTP API
我们不仅仅可以在 Prometheus 的 Graph 页面查询 PromQL,Prometheus 还提供了一种 HTTP API 的方式,可以更灵活的将 PromQL 整合到其他系统中使用,譬如下面要介绍的 Grafana,就是通过 Prometheus 的 HTTP API 来查询指标数据的。实际上,我们在 Prometheus 的 Graph 页面查询也是使用了 HTTP API。
我们看下 Prometheus 的 HTTP API 官方文档,它提供了下面这些接口:
DAPATKAN /api/v1/query DAPATKAN /api/v1/query_range DAPATKAN /api/v1/series &label/nilai/ltv1/label/api . - DAPATKAN /api/v1/alertmanagers
- DAPATKAN /api/v1/status/config
- DAPATKAN /api/v1/status/flags
- Bermula dari Prometheus v2 telah ditambah. Antara muka untuk mengurus TSDB:
POST /api/v1/admin/tsdb/snapshot POST /api/v1/admin/tsdb/delete_series POST /api/v1/admin/tsdb
4. Pasang Grafana
Walaupun UI Web yang disediakan oleh Prometheus juga boleh memberikan pandangan yang baik tentang penunjuk yang berbeza, fungsi ini sangat mudah dan hanya sesuai untuk debugging. Untuk melaksanakan sistem pemantauan yang berkuasa, anda juga memerlukan panel yang boleh menyesuaikan paparan penunjuk yang berbeza dan menyokong pelbagai jenis kaedah pembentangan (carta lengkung, carta pai, peta haba, TopN, dll. Ini ialah fungsi papan pemuka.
Jadi Prometheus membangunkan sistem papan pemuka PromDash, tetapi sistem ini telah ditinggalkan tidak lama lagi. Pegawai mula mengesyorkan menggunakan Grafana untuk menggambarkan data penunjuk Prometheus Ini bukan sahaja kerana Grafana sangat berkuasa, tetapi juga kerana ia boleh menjadi sempurna dan lancar disepadukan dengan Prometheus.
Grafana ialah sistem sumber terbuka untuk menggambarkan data pengukuran berskala besar. Ia mempunyai fungsi yang sangat berkuasa dan antara muka yang sangat cantik Anda boleh menggunakannya untuk membuat panel kawalan tersuai Anda boleh mengkonfigurasi data untuk dipaparkan dan kaedah paparan dalam panel. Ia menyokong banyak sumber data yang berbeza, seperti: Graphite, InfluxDB, OpenTSDB, Elasticsearch, Prometheus, dsb., dan ia juga menyokong banyak pemalam.
Mari cuba menggunakan Grafana untuk memaparkan data penunjuk Prometheus. Mula-mula kami memasang Grafana, kami menggunakan kaedah pemasangan Docker yang paling mudah:
1
$ docker run -d -p 3000:3000 grafana/grafanaSalin selepas log masuk运行上面的 docker 命令,Grafana 就安装好了!你也可以采用其他的安装方式,参考 官方的安装文档。安装完成之后,我们访问
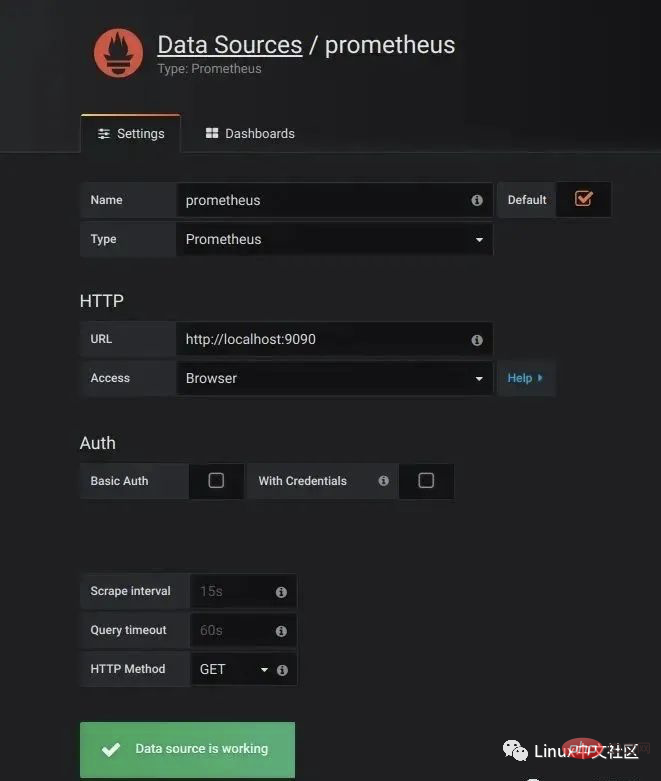
http://localhost:3000/进入 Grafana 的登陆页面,输入默认的用户名和密码(admin/admin)即可。要使用 Grafana,第一步当然是要配置数据源,告诉 Grafana 从哪里取数据,我们点击 Add data source 进入数据源的配置页面:
图片我们在这里依次填上:
Name: prometheus Type: Prometheus URL: http://localhost:9090 Access: Browser
要注意的是,这里的 Access 指的是 Grafana 访问数据源的方式,有 Browser 和 Proxy 两种方式。Browser 方式表示当用户访问 Grafana 面板时,浏览器直接通过 URL 访问数据源的;而 Proxy 方式表示浏览器先访问 Grafana 的某个代理接口(接口地址是
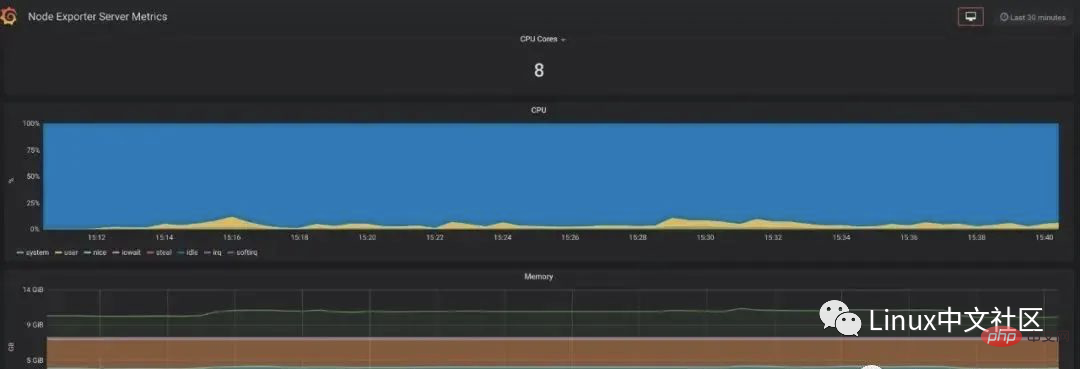
/api/datasources/proxy/),由 Grafana 的服务端来访问数据源的 URL,如果数据源是部署在内网,用户通过浏览器无法直接访问时,这种方式非常有用。Selepas mengkonfigurasi sumber data, Grafana akan menyediakan beberapa panel yang dikonfigurasikan untuk anda gunakan secara lalai Seperti yang ditunjukkan dalam rajah di bawah, tiga panel disediakan secara lalai: Prometheus Stats, Prometheus 2.0 Stats dan metrik Grafana. Klik Import untuk mengimport dan menggunakan panel ini.
Kami mengimport panel Prometheus 2.0 Stats dan anda boleh melihat panel pemantauan berikut. Jika syarikat anda mempunyai syarat, anda boleh memohon monitor besar untuk digantung di dinding, menayangkan panel ini pada skrin besar, dan memerhati status sistem dalam talian dalam masa nyata Ia boleh dikatakan sangat keren. 5. Gunakan Pengeksport untuk mengumpul penunjuk
Setakat ini, apa yang kita lihat hanyalah beberapa penunjuk yang tidak mempunyai kegunaan praktikal Jika kita ingin benar-benar menggunakan Prometheus dalam persekitaran pengeluaran kita, kita sering memerlukan untuk memberi perhatian kepada pelbagai penunjuk Pelbagai penunjuk, seperti beban CPU pelayan, penggunaan memori, overhed IO, trafik rangkaian masuk dan keluar, dsb.
Seperti yang dinyatakan di atas, Prometheus menggunakan kaedah Tarik untuk mendapatkan data penunjuk Untuk Prometheus mendapatkan data daripada sasaran, anda mesti terlebih dahulu memasang program pengumpulan penunjuk pada sasaran dan mendedahkan antara muka HTTP untuk Prometheus membuat pertanyaan Program pengumpulan dipanggil Pengeksport Penunjuk yang berbeza memerlukan Pengeksport yang berbeza untuk dikumpulkan Pada masa ini, terdapat sejumlah besar Pengeksport yang tersedia, meliputi hampir semua sistem dan perisian yang biasa kami gunakan.
Tapak web rasmi menyenaraikan senarai Pengeksport yang biasa digunakan Setiap Pengeksport mengikut konvensyen pelabuhan untuk mengelakkan konflik pelabuhan, iaitu, bermula dari 9100 dan meningkat dalam urutan Berikut ialah senarai port Pengeksport yang lengkap. Perlu juga diperhatikan bahawa sesetengah perisian dan sistem tidak perlu memasang Pengeksport kerana mereka sendiri menyediakan fungsi mendedahkan data penunjuk dalam format Prometheus, seperti Kubernetes, Grafana, Etcd, Ceph, dll.
这一节就让我们来收集一些有用的数据。
5.1 收集服务器指标
首先我们来收集服务器的指标,这需要安装 node_exporter,这个 exporter 用于收集 *NIX 内核的系统,如果你的服务器是 Windows,可以使用 WMI exporter。
和 Prometheus server 一样,node_exporter 也是开箱即用的:
1
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz $ tar xvfz node_exporter-0.16.0.linux-amd64.tar.gz $ cd node_exporter-0.16.0.linux-amd64 $ ./node_exporterSalin selepas log masuknode_exporter 启动之后,我们访问下
/metrics接口看看是否能正常获取服务器指标:1
$ curl http://localhost:9100/metricsSalin selepas log masuk如果一切 OK,我们可以修改 Prometheus 的配置文件,将服务器加到
scrape_configs中:1
scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['192.168.0.107:9090'] - job_name: 'server' static_configs: - targets: ['192.168.0.107:9100']Salin selepas log masuk修改配置后,需要重启 Prometheus 服务,或者发送
HUP信号也可以让 Prometheus 重新加载配置:1
$ killall -HUP prometheusSalin selepas log masuk在 Prometheus Web UI 的 Status -> Targets 中,可以看到新加的服务器:
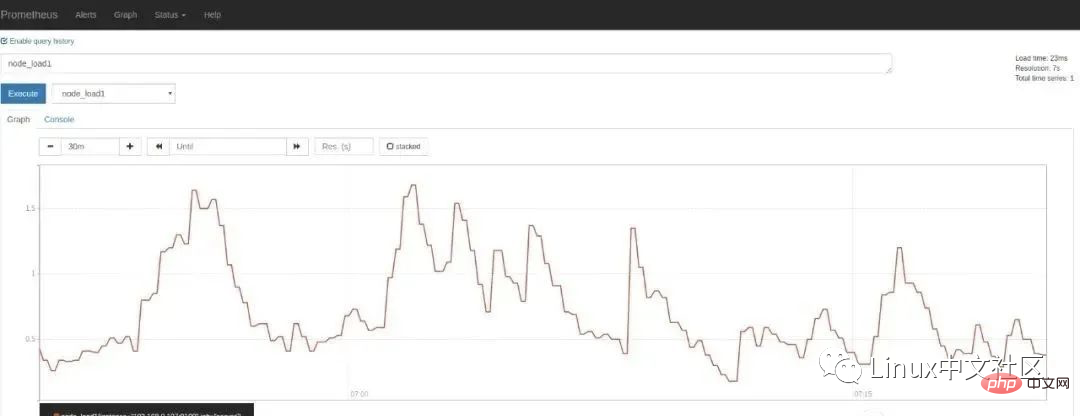
在 Graph 页面的指标下拉框可以看到很多名称以 node 开头的指标,譬如我们输入
node_load1观察服务器负载:如果想在 Grafana 中查看服务器的指标,可以在 Grafana 的 Dashboards 页面 搜索
node exporter,有很多的面板模板可以直接使用,譬如:Node Exporter Server Metrics 或者 Node Exporter Full 等。我们打开 Grafana 的 Import dashboard 页面,输入面板的 URL(https://grafana.com/dashboards/405)或者 ID(405)即可。注意事项
一般情况下,node_exporter 都是直接运行在要收集指标的服务器上的,官方不推荐用 Docker 来运行 node_exporter。如果逼不得已一定要运行在 Docker 里,要特别注意,这是因为 Docker 的文件系统和网络都有自己的 namespace,收集的数据并不是宿主机真实的指标。可以使用一些变通的方法,比如运行 Docker 时加上下面这样的参数:
1
docker run -d \ --net="host"\ --pid="host"\ -v"/:/host:ro,rslave"\ quay.io/prometheus/node-exporter \ --path.rootfs /hostSalin selepas log masuk关于 node_exporter 的更多信息,可以参考 node_exporter 的文档 和 Prometheus 的官方指南 Monitoring Linux host metrics with the Node Exporter,另外,Julius Volz 的这篇文章 How To Install Prometheus using Docker on Ubuntu 14.04 也是很好的入门材料。
5.2 收集 MySQL 指标
mysqld_exporter 是 Prometheus 官方提供的一个 exporter,我们首先 下载最新版本 并解压(开箱即用):
1
$ wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.11.0/mysqld_exporter-0.11.0.linux-amd64.tar.gz $ tar xvfz mysqld_exporter-0.11.0.linux-amd64.tar.gz $ cd mysqld_exporter-0.11.0.linux-amd64/Salin selepas log masukmysqld_exporter 需要连接到 mysqld 才能收集它的指标,可以通过两种方式来设置 mysqld 数据源。第一种是通过环境变量
DATA_SOURCE_NAME,这被称为 DSN(数据源名称),它必须符合 DSN 的格式,一个典型的 DSN 格式像这样:user:password@(host:port)/。1
$ export DATA_SOURCE_NAME='root:123456@(192.168.0.107:3306)/' $ ./mysqld_exporterSalin selepas log masuk另一种方式是通过配置文件,默认的配置文件是
~/.my.cnf,或者通过--config.my-cnf参数指定:1
$ ./mysqld_exporter --config.my-cnf=".my.cnf"Salin selepas log masuk配置文件的格式如下:
1
$ cat .my.cnf [client] host=localhost port=3306 user=root password=123456Salin selepas log masuk如果要把 MySQL 的指标导入 Grafana,可以参考 这些 Dashboard JSON。另外,MySQL 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
注意事项
这里为简单起见,在 mysqld_exporter 中直接使用了 root 连接数据库,在真实环境中,可以为 mysqld_exporter 创建一个单独的用户,并赋予它受限的权限(PROCESS、REPLICATION CLIENT、SELECT),最好还限制它的最大连接数(MAX_USER_CONNECTIONS)。
1
CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'password' WITH MAX_USER_CONNECTIONS 3; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';Salin selepas log masuk5.3 收集 Nginx 指标
官方提供了两种收集 Nginx 指标的方式。另外,Nginx 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
第一种是 Nginx metric library,这是一段 Lua 脚本(prometheus.lua),Nginx 需要开启 Lua 支持(libnginx-mod-http-lua 模块)。为方便起见,也可以使用 OpenResty 的 OPM(OpenResty Package Manager) 或者 luarocks(The Lua package manager) 来安装。
第二种是 Nginx VTS exporter,这种方式比第一种要强大的多,安装要更简单,支持的指标也更丰富,它依赖于 nginx-module-vts 模块,vts 模块可以提供大量的 Nginx 指标数据,可以通过 JSON、HTML 等形式查看这些指标。Nginx VTS exporter 就是通过抓取
/status/format/json接口来将 vts 的数据格式转换为 Prometheus 的格式。Walau bagaimanapun, antara muka baharu telah ditambahkan pada versi terkini nginx-module-vts:
/ status/format/prometheus, antara muka ini secara langsung boleh mengembalikan format Prometheus Dari sudut ini, kita juga boleh melihat pengaruh Prometheus Dianggarkan bahawa pengeksport Nginx VTS akan dibersarakan tidak lama lagi (TODO: to disahkan)./status/format/prometheus,这个接口可以直接返回 Prometheus 的格式,从这点这也能看出 Prometheus 的影响力,估计 Nginx VTS exporter 很快就要退役了(TODO:待验证)。除此之外,还有很多其他的方式来收集 Nginx 的指标,比如:
Selain itu, terdapat banyak cara lain untuk mengumpul penunjuk Nginx, seperti:nginx_exporter通过抓取 Nginx 自带的统计页面/nginx_status可以获取一些比较简单的指标(需要开启ngx_http_stub_status_module模块);nginx_request_exporter通过 syslog 协议 收集并分析 Nginx 的 access log 来统计 HTTP 请求相关的一些指标;nginx-prometheus-shiny-exporter和nginx_request_exporter类似,也是使用 syslog 协议来收集 access log,不过它是使用 Crystal 语言 写的。还有vovolie/lua-nginx-prometheusnginx_exporter< /code> Dengan meraih halaman statistik yang disertakan dengan Nginx <code style="margin: 3px;padding: 3px;outline: 0px;font-size: 14px;border-radius: 4px;font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(155, 110, 35);background-color: rgb(255, 245, 227);">/nginx_status</code > Anda boleh dapatkan beberapa penunjuk yang agak mudah (perlu menghidupkan <code style="margin: 3px;padding: 3px;outline: 0px;font-size: 14px;border-radius: 4px;font-family: "Operator Mono", Consolas , Monaco, Menlo, monospace;word-break: break-all;color: rgb(155, 110, 35);background-color: rgb(255, 245, 227);">ngx_http_stub_status_modulemodul);< kod style="margin: 3px;padding: 3px;outline: 0px;font-size: 14px;border-radius: 4px;font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break - all;color: rgb(155, 110, 35);background-color: rgb(255, 245, 227);">nginx_request_exporter Mengumpul dan menganalisis log akses Nginx melalui protokol syslog untuk mengumpul statistik yang berkaitan dengan permintaan HTTP Beberapa penunjuk;nginx-prometheus-shiny-exporterdannginx_request_exporterSerupa, ia juga menggunakan protokol syslog untuk mengumpul log akses, tetapi ia ditulis dalam bahasa Crystal . Jugavovolie/lua-nginx-prometheusBerdasarkan Openresty, Prometheus, Consul, Grafana melaksanakan statistik trafik pada nama domain dan peringkat Endpoint. Pelajar yang memerlukan atau berminat boleh memasang dan merasai sendiri dengan merujuk kepada dokumentasi, tetapi saya tidak akan mencubanya satu persatu di sini. 🎜5.4 收集 JMX 指标
最后让我们来看下如何收集 Java 应用的指标,Java 应用的指标一般是通过 JMX(Java Management Extensions) 来获取的,顾名思义,JMX 是管理 Java 的一种扩展,它可以方便的管理和监控正在运行的 Java 程序。
JMX Exporter 用于收集 JMX 指标,很多使用 Java 的系统,都可以使用它来收集指标,比如:Kafaka、Cassandra 等。首先我们下载 JMX Exporter:
1
$ wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jarSalin selepas log masukJMX Exporter 是一个 Java Agent 程序,在运行 Java 程序时通过
-javaagent参数来加载:1
$ java -javaagent:jmx_prometheus_javaagent-0.3.1.jar=9404:config.yml -jar spring-boot-sample-1.0-SNAPSHOT.jarSalin selepas log masuk其中,9404 是 JMX Exporter 暴露指标的端口,
config.yml是 JMX Exporter 的配置文件,它的内容可以 参考 JMX Exporter 的配置说明 。然后检查下指标数据是否正确获取:
1
$ curl http://localhost:9404/metricsSalin selepas log masuk六、告警和通知
至此,我们能收集大量的指标数据,也能通过强大而美观的面板展示出来。不过作为一个监控系统,最重要的功能,还是应该能及时发现系统问题,并及时通知给系统负责人,这就是 Alerting(告警)。
Prometheus 的告警功能被分成两部分:一个是告警规则的配置和检测,并将告警发送给 Alertmanager,另一个是 Alertmanager,它负责管理这些告警,去除重复数据,分组,并路由到对应的接收方式,发出报警。常见的接收方式有:Email、PagerDuty、HipChat、Slack、OpsGenie、WebHook 等。
6.1 配置告警规则
我们在上面介绍 Prometheus 的配置文件时了解到,它的默认配置文件 prometheus.yml 有四大块:
global、alerting、rule_files、scrape_config,其中rule_files块就是告警规则的配置项,alerting 块用于配置 Alertmanager,这个我们下一节再看。现在,先让我们在rule_files块中添加一个告警规则文件:1
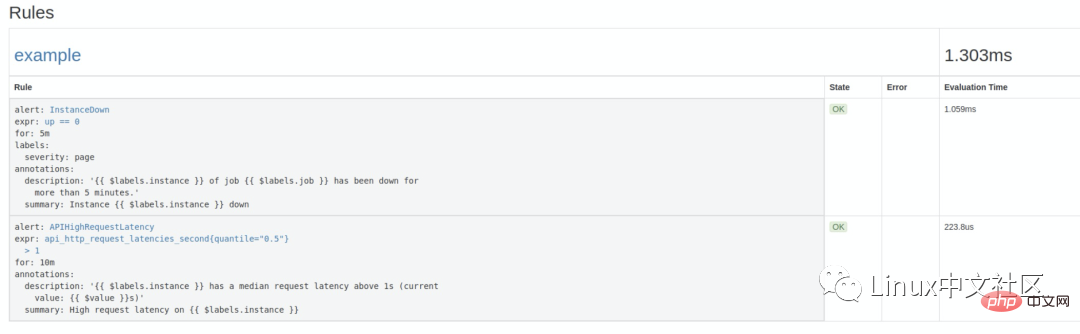
rule_files: -"alert.rules"Salin selepas log masuk然后参考 官方文档,创建一个告警规则文件
alert.rules:1
groups: - name: example rules: # Alertforany instance that is unreachablefor>5 minutes. - alert: InstanceDown expr: up == 0for: 5m labels: severity: page annotations: summary:"Instance {{ $labels.instance }} down"description:"{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."# Alertforany instance that has a median request latency >1s. - alert: APIHighRequestLatency expr: api_http_request_latencies_second{quantile="0.5"} > 1for: 10m annotations: summary:"High request latency on {{ $labels.instance }}"description:"{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"Salin selepas log masuk这个规则文件里,包含了两条告警规则:
InstanceDown和APIHighRequestLatency。顾名思义,InstanceDown 表示当实例宕机时(up === 0)触发告警,APIHighRequestLatency 表示有一半的 API 请求延迟大于 1s 时(api_http_request_latencies_second{quantile="0.5"} > 1)触发告警。搜索公众号GitHub猿回复“理财”,送你一份惊喜礼包。
配置好后,需要重启下 Prometheus server,然后访问
http://localhost:9090/rules可以看到刚刚配置的规则:访问
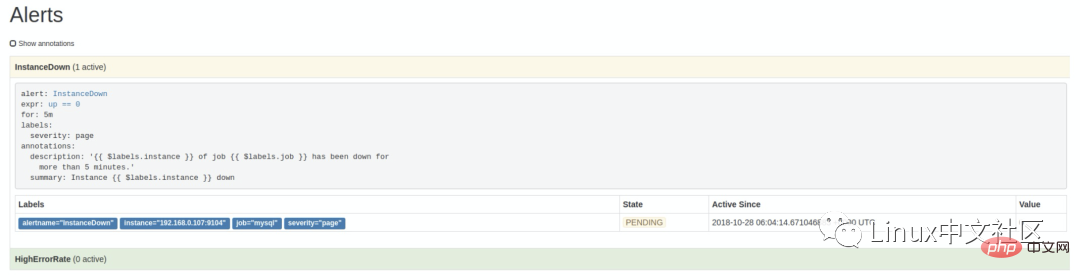
http://localhost:9090/alerts可以看到根据配置的规则生成的告警:这里我们将一个实例停掉,可以看到有一条 alert 的状态是
PENDING,这表示已经触发了告警规则,但还没有达到告警条件。这是因为这里配置的for参数是 5m,也就是 5 分钟后才会触发告警,我们等 5 分钟,可以看到这条 alert 的状态变成了FIRING。6.2 使用 Alertmanager 发送告警通知
虽然 Prometheus 的
<span style="outline: 0px;color: rgb(0, 0, 0);">/alerts</span>页面可以看到所有的告警,但是还差最后一步:触发告警时自动发送通知。这是由 Alertmanager 来完成的,我们首先 下载并安装 Alertmanager,和其他 Prometheus 的组件一样,Alertmanager 也是开箱即用的:1
$ wget https://github.com/prometheus/alertmanager/releases/download/v0.15.2/alertmanager-0.15.2.linux-amd64.tar.gz $ tar xvfz alertmanager-0.15.2.linux-amd64.tar.gz $ cd alertmanager-0.15.2.linux-amd64 $ ./alertmanagerSalin selepas log masukAlertmanager 启动后默认可以通过
http://localhost:9093/来访问,但是现在还看不到告警,因为我们还没有把 Alertmanager 配置到 Prometheus 中,我们回到 Prometheus 的配置文件prometheus.yml,添加下面几行:1
alerting: alertmanagers: - scheme: http static_configs: - targets: -"192.168.0.107:9093"Salin selepas log masuk这个配置告诉 Prometheus,当发生告警时,将告警信息发送到 Alertmanager,Alertmanager 的地址为
http://192.168.0.107:9093。也可以使用命名行的方式指定 Alertmanager:1
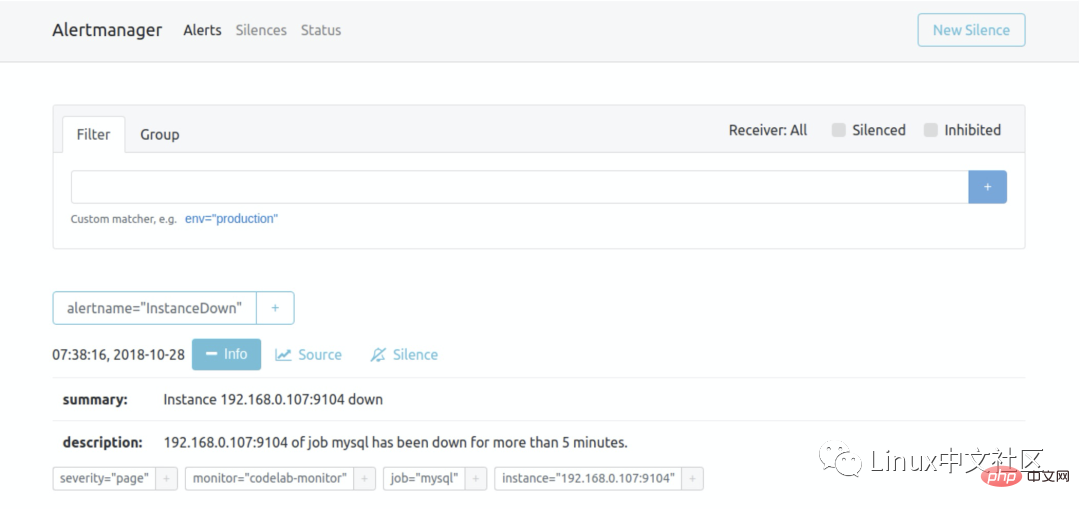
$ ./prometheus -alertmanager.url=http://192.168.0.107:9093Salin selepas log masuk这个时候再访问 Alertmanager,可以看到 Alertmanager 已经接收到告警了:
下面的问题就是如何让 Alertmanager 将告警信息发送给我们了,我们打开默认的配置文件
alertmanager.ym:1
global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://127.0.0.1:5001/' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']Salin selepas log masuk参考 官方的配置手册 了解各个配置项的功能,其中 global 块表示一些全局配置;route 块表示通知路由,可以根据不同的标签将告警通知发送给不同的 receiver,这里没有配置 routes 项,表示所有的告警都发送给下面定义的 web.hook 这个 receiver;如果要配置多个路由,可以参考 这个例子:
1
routes: - receiver: 'database-pager' group_wait: 10s match_re: service: mysql|cassandra - receiver: 'frontend-pager' group_by: [product, environment] match: team: frontendSalin selepas log masuk紧接着,receivers 块表示告警通知的接收方式,每个 receiver 包含一个 name 和一个 xxx_configs,不同的配置代表了不同的接收方式,Alertmanager 内置了下面这些接收方式:
email_config hipchat_config pagerduty_config pushover_opsconfig config victorops_config wechat_configs webhook_config -
sambil menerima Terdapat banyak cara untuk menerimanya, tetapi kebanyakannya jarang digunakan di China. Yang paling biasa digunakan ialah boleh menyokong penggunaan WeChat untuk memberi amaran, yang juga agak selaras dengan keadaan negara.
7. Ketahui lebih lanjut
Sehingga ke tahap ini, kami telah mempelajari kebanyakan fungsi Prometheus Menggabungkan Prometheus + Grafana + Alertmanager boleh membina sistem pemantauan yang sangat lengkap. Namun, apabila benar-benar menggunakannya, kita akan mendapati lebih banyak masalah.
7.1 Penemuan Perkhidmatan
Memandangkan Prometheus secara aktif memperoleh data pemantauan melalui Pull, adalah perlu untuk menentukan senarai nod pemantauan secara manual Apabila bilangan nod yang dipantau meningkat, fail konfigurasi perlu diubah setiap kali nod ditambahkan. yang sangat menyusahkan ini perlu diselesaikan melalui mekanisme penemuan perkhidmatan (SD).
Prometheus menyokong pelbagai mekanisme penemuan perkhidmatan dan secara automatik boleh mendapatkan sasaran untuk dikumpulkan Anda boleh merujuk di sini Mekanisme penemuan perkhidmatan yang disertakan termasuk: azure, consul, dns, ec2, openstack, file, gce, kubernetes, marathon, triton. , zookeeper (saraf, set pelayan), untuk kaedah konfigurasi, sila rujuk halaman Konfigurasi manual. Ia boleh dikatakan bahawa mekanisme SD sangat kaya, tetapi pada masa ini disebabkan oleh sumber pembangunan yang terhad, mekanisme SD baharu tidak lagi dibangunkan, dan hanya mekanisme SD berasaskan fail dikekalkan.
Terdapat banyak tutorial tentang penemuan perkhidmatan di Internet Sebagai contoh, artikel ini dalam blog rasmi Prometheus, Penemuan Perkhidmatan Lanjutan dalam Prometheus 0.14.0, mempunyai pengenalan yang agak sistematik untuk ini, dan menerangkan secara komprehensif konfigurasi pelabelan semula, dan bagaimana. untuk menggunakan DNS-SRV dan Konsul dan fail untuk melakukan penemuan perkhidmatan.
Selain itu, laman web rasmi juga menyediakan contoh pengenalan penemuan perkhidmatan berasaskan fail The Prometheus tutorial pengenalan bengkel yang ditulis oleh Julius Volz juga menggunakan DNS-SRV untuk penemuan perkhidmatan. Selain itu, soalan dan jawapan temu bual siri perkhidmatan mikro telah diselesaikan Cari arkitek Internet di WeChat dan hantar: 2T di latar belakang, yang boleh dibaca dalam talian.
7.2 Pengurusan konfigurasi amaran
Tidak kira konfigurasi Prometheus atau konfigurasi Alertmanager, tiada API untuk kami mengubah suai secara dinamik. Senario yang sangat biasa ialah kita perlu membina sistem penggera dengan peraturan yang boleh disesuaikan berdasarkan Prometheus Pengguna boleh membuat, mengubah suai atau memadam peraturan penggera pada halaman mengikut keperluan mereka sendiri, atau mengubah suai kaedah pemberitahuan penggera dan orang yang boleh dihubungi, seperti dalam. Soalan daripada pengguna ini dalam Kumpulan Google Prometheus: Bagaimana untuk menambahkan peraturan makluman secara dinamik dalam fail rules.conf dan prometheus yml melalui API atau sesuatu?
Malangnya, Simon Pasquier berkata di bawah bahawa pada masa ini tiada API sedemikian, dan tiada rancangan sedemikian untuk membangunkan API sedemikian pada masa hadapan, kerana fungsi tersebut harus diserahkan kepada alatan seperti Boneka, Chef, Ansible, dan Salt Sistem pengurusan konfigurasi sedemikian.
7.3 Menggunakan Pushgateway
Pushgateway digunakan terutamanya untuk mengumpul beberapa pekerjaan jangka pendek Memandangkan pekerjaan sedemikian wujud untuk masa yang singkat, ia mungkin hilang sebelum Prometheus datang ke Pull. Pegawai mempunyai penjelasan yang baik tentang masa untuk menggunakan Pushgateway. . Tahniah kepada pengarang asal ini. Halaman Media dokumentasi rasmi Prometheus juga menyediakan banyak sumber pembelajaran. Mengenai Prometheus, masih terdapat bahagian yang sangat penting yang belum dibincangkan oleh blog ini, seperti yang dinyatakan di awal blog, Prometheus adalah projek kedua untuk menyertai CNCF selepas Kubernetes terintegrasi dengan Docker dan Kubernetes semakin menjadi arus perdana sebagai sistem pemantauan untuk Docker dan Kubernetes.
Untuk pemantauan Docker, anda boleh merujuk kepada panduan di tapak web rasmi: Memantau metrik kontena Docker menggunakan cAdvisor, yang memperkenalkan cara menggunakan cAdvisor untuk memantau kontena walau bagaimanapun, Docker kini juga mula menyokong pemantauan Prometheus secara asli, rujuk kepada Docker's metrik rasmi Document Collect Docker dengan Prometheus; Mengenai pemantauan Kubernetes, terdapat banyak sumber tentang Promehtheus dalam komuniti Cina Kubernetes Selain itu, e-buku "Cara Memantau Kubernetes dengan Postur Elegan" juga mempunyai pengenalan yang agak komprehensif kepada pemantauan Kubernetes. .
Dalam dua tahun kebelakangan ini, Prometheus telah berkembang dengan sangat pesat, komuniti juga sangat aktif, dan semakin ramai orang di China sedang belajar Prometheus. Dengan mempopularkan konsep seperti perkhidmatan mikro, DevOps, pengkomputeran awan dan asli awan, semakin banyak syarikat mula menggunakan Docker dan Kubernetes untuk membina sistem dan aplikasi mereka sendiri seperti Nagios dan Cacti akan menjadi semakin popular . Semakin kurang sesuai, saya percaya Prometheus akhirnya akan berkembang menjadi sistem pemantauan yang paling sesuai untuk persekitaran awan.
Lampiran: Apakah pangkalan data siri masa?
Seperti yang dinyatakan di atas, Prometheus ialah sistem pemantauan berdasarkan pangkalan data siri masa Pangkalan data siri masa sering disingkatkan sebagai TSDB (Pangkalan Data Siri Masa). Banyak sistem pemantauan popular menggunakan pangkalan data siri masa untuk menyimpan data, kerana ciri-ciri pangkalan data siri masa bertepatan dengan sistem pemantauan.
Ditambah: Operasi penulisan yang kerap diperlukan, dan ia ditulis dalam susunan kronologi Dipadam: Tiada pemadaman rawak diperlukan Dalam keadaan biasa, semua data dalam blok masa akan dipadamkan terus - : Tidak perlu mengemas kini data bertulis
- Semak: Ia adalah perlu untuk menyokong operasi baca serentak tinggi Operasi baca adalah dalam susunan menaik atau menurun mengikut masa work
- InfluxDB: https://influxdata.com/
b+: http //kx. com/ Graphite: http://graphiteapp.org/ RRDtool: http://oss.oetiker.ch/rrdtool/ OpenTSDB: http://opentsdb. net/ Prometheus: https://prometheus.io/ Druid: http://druid.io/
Selain itu, liubin menulis satu siri artikel tentang pangkalan data siri masa di blognya : Persidangan seni mempertahankan diri Pangkalan Data Siri Masa, disyorkan.
 图片
图片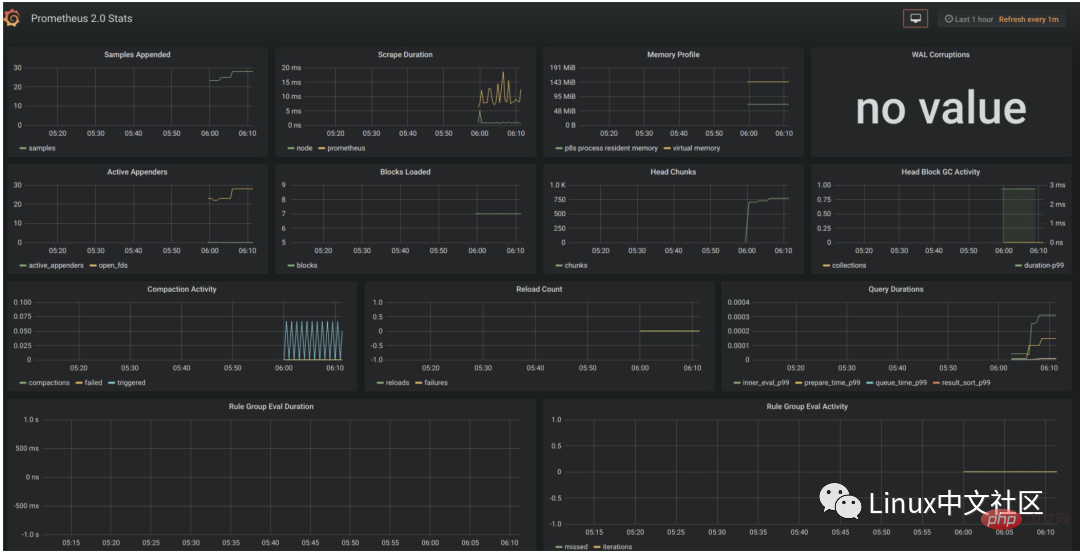
Atas ialah kandungan terperinci Dikenali sebagai sistem pengawasan generasi akan datang, mari lihat betapa hebatnya sistem tersebut!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!
Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Dikenali sebagai sistem pemantauan generasi akan datang! Mari lihat betapa hebatnya ia
Aug 03, 2023 pm 02:53 PM
Dikenali sebagai sistem pemantauan generasi akan datang! Mari lihat betapa hebatnya ia
Aug 03, 2023 pm 02:53 PM
Dalam dua tahun yang lalu, Prometheus telah berkembang dengan sangat pesat, komuniti juga sangat aktif, dan semakin ramai orang di China sedang belajar Prometheus. Dengan populariti konsep seperti perkhidmatan mikro, DevOps, pengkomputeran awan dan asli awan, semakin banyak syarikat mula menggunakan Docker dan Kubernetes untuk membina sistem dan aplikasi mereka sendiri.
 Bagaimana untuk melaksanakan sistem pemantauan keselamatan pintar melalui pembangunan C++?
Aug 25, 2023 pm 02:48 PM
Bagaimana untuk melaksanakan sistem pemantauan keselamatan pintar melalui pembangunan C++?
Aug 25, 2023 pm 02:48 PM
Bagaimana untuk melaksanakan sistem pemantauan keselamatan pintar melalui pembangunan C++? Sistem pemantauan keselamatan pintar memainkan peranan yang sangat penting dalam memastikan keselamatan nyawa dan harta benda orang ramai dalam masyarakat moden. Menggunakan bahasa C++ untuk pembangunan boleh memberikan permainan penuh kepada ciri kecekapan, kestabilan dan fleksibilitinya. Artikel ini akan memperkenalkan cara menggunakan C++ untuk membangun dan melaksanakan sistem pemantauan keselamatan pintar yang mudah, dan menyediakan contoh kod yang sepadan. Pertama sekali, kita perlu menjelaskan keperluan fungsian sistem pemantauan keselamatan pintar. Sistem pemantauan keselamatan pintar asas harus termasuk pengawasan video, pengesanan sasaran bergerak
 Ringkasan pengalaman dalam membina analisis log dan sistem pemantauan berdasarkan MongoDB
Nov 04, 2023 pm 01:17 PM
Ringkasan pengalaman dalam membina analisis log dan sistem pemantauan berdasarkan MongoDB
Nov 04, 2023 pm 01:17 PM
1. Analisis keperluan dan reka bentuk sistem Dengan popularisasi Internet dan peranti mudah alih, bilangan log pelbagai aplikasi rangkaian dan sistem telah meningkat secara mendadak. Analisis dan pemantauan log besar ini boleh membantu perusahaan memahami operasi sistem dalam masa nyata, menemui masalah yang berpotensi dan membaikinya tepat pada masanya, serta meningkatkan kestabilan dan kebolehpercayaan sistem. Untuk memenuhi permintaan ini, pasukan kami membina analisis log dan sistem pemantauan berdasarkan MongoDB. Artikel ini akan meringkaskan pengalaman kami semasa proses binaan. 1.1 Analisis keperluan dalam pembinaan analisis log dan sistem pemantauan
 Artikel ini cukup untuk memantau sistem! Tutorial pemantauan biasa seperti Zabbix dan Prometheus
Aug 01, 2023 pm 04:31 PM
Artikel ini cukup untuk memantau sistem! Tutorial pemantauan biasa seperti Zabbix dan Prometheus
Aug 01, 2023 pm 04:31 PM
Pemantauan biasanya dikenali sebagai "mata ketiga". Ia adalah sistem yang kita hadapi hampir setiap hari automasi operasi dan penyelenggaraan, operasi dan penyelenggaraan tradisional, DevOps, Atau SRE, pemantauan adalah kemahiran yang diperlukan.
 Cara menggunakan bahasa go untuk membangun dan melaksanakan sistem pemantauan dan penggera
Aug 04, 2023 pm 01:10 PM
Cara menggunakan bahasa go untuk membangun dan melaksanakan sistem pemantauan dan penggera
Aug 04, 2023 pm 01:10 PM
Cara menggunakan bahasa Go untuk membangun dan melaksanakan sistem pemantauan dan penggera Pengenalan: Dengan perkembangan pesat teknologi Internet, sistem teragih berskala besar telah menjadi arus perdana pembangunan perisian moden, dan salah satu cabaran yang datang bersamanya ialah pemantauan sistem dan Makluman. Untuk memastikan kestabilan dan prestasi sistem, adalah sangat penting untuk membangunkan dan melaksanakan sistem pemantauan dan penggera yang cekap dan boleh dipercayai. Artikel ini akan memperkenalkan cara menggunakan bahasa Go untuk membangun dan melaksanakan sistem pemantauan dan penggera serta memberikan contoh kod yang berkaitan. 1. Reka bentuk dan seni bina sistem pemantauan Komponen utama sistem pemantauan termasuk:
 Bagaimana untuk melaksanakan sistem pemantauan mesin layan diri masa nyata menggunakan PHP dan Redis
Jun 28, 2023 am 08:31 AM
Bagaimana untuk melaksanakan sistem pemantauan mesin layan diri masa nyata menggunakan PHP dan Redis
Jun 28, 2023 am 08:31 AM
Dengan kemajuan teknologi dan populariti Internet of Things, mesin layan diri telah menjadi salah satu peranti biasa dalam kehidupan orang ramai. Walau bagaimanapun, pemantauan dan pengurusan mesin layan diri adalah tugas yang sangat kompleks yang akan menjadi sangat rumit dan memakan masa jika kaedah tradisional digunakan. Oleh itu, artikel ini akan memperkenalkan cara menggunakan PHP dan Redis untuk melaksanakan sistem pemantauan mesin layan diri masa nyata, dengan itu meningkatkan kecekapan pengurusan dan ketepatan mesin layan diri. Redis ialah sistem penyimpanan data dalam memori yang boleh digunakan untuk menyimpan dan mengakses data Ia juga menyokong pelbagai struktur data, seperti rentetan, jadual cincang, senarai dan set.
 Membina sistem analisis dan pemantauan log yang cekap: Panduan pembangunan bahasa Go
Nov 20, 2023 pm 02:48 PM
Membina sistem analisis dan pemantauan log yang cekap: Panduan pembangunan bahasa Go
Nov 20, 2023 pm 02:48 PM
Membina Sistem Analisis dan Pemantauan Log yang Cekap: Panduan Pembangunan Bahasa Go Dengan perkembangan pesat Internet, sejumlah besar aplikasi dan perkhidmatan perlu memproses dan merekod data log besar-besaran. Sistem analisis dan pemantauan log telah menjadi salah satu alat utama untuk memastikan ketersediaan tinggi dan prestasi aplikasi yang dioptimumkan. Sebagai bahasa pengaturcaraan yang cekap, mudah digunakan dan menyokong serentak, bahasa Go secara beransur-ansur menjadi bahasa pilihan untuk analisis log dan pembangunan sistem pemantauan. Artikel ini akan memperkenalkan cara menggunakan bahasa Go untuk membina analisis log dan sistem pemantauan yang cekap, serta memberikan beberapa cadangan dan garis panduan pembangunan.
 Pembinaan praktikal dan aplikasi sistem analisis pintar acara dipacu AI
Jan 16, 2024 am 08:06 AM
Pembinaan praktikal dan aplikasi sistem analisis pintar acara dipacu AI
Jan 16, 2024 am 08:06 AM
1. Latar Belakang Dengan aplikasi meluas teknologi baharu seperti virtualisasi dan pengkomputeran awan, skala infrastruktur IT dalam pusat data perusahaan telah berkembang dengan pesat. Ini mengakibatkan peningkatan dalam saiz perkakasan dan perisian komputer, serta kegagalan komputer yang kerap. Oleh itu, kakitangan operasi dan penyelenggaraan barisan hadapan amat memerlukan alat operasi dan penyelenggaraan yang lebih profesional dan berkuasa untuk menghadapi cabaran. Dalam operasi harian dan penyelenggaraan pusat data, sistem pemantauan asas dan sistem pemantauan aplikasi biasanya digunakan untuk membina mekanisme penemuan kerosakan. Dengan menetapkan ambang pratetap, apabila pelbagai keabnormalan perisian dan perkakasan berlaku, item penunjuk akan melebihi ambang ini, mencetuskan penggera. Pakar operasi dimaklumkan dengan segera dan melakukan penyelesaian masalah untuk memastikan operasi stabil pusat data. Mekanisme pemantauan sedemikian boleh segera menemui dan menyelesaikan masalah yang berpotensi dan meningkatkan kecekapan pusat data.