
 pembangunan bahagian belakang
Tutorial Python
Pandas+Pyecharts |. Visualisasi analisis data jualan produk elektronik + potret RFM pengguna
pembangunan bahagian belakang
Tutorial Python
Pandas+Pyecharts |. Visualisasi analisis data jualan produk elektronik + potret RFM pengguna
Pandas+Pyecharts |. Visualisasi analisis data jualan produk elektronik + potret RFM pengguna

Isu ini menggunakan Python untuk menganalisis data jualan produk elektronik, sila lihat:
pesanan setiap bulan
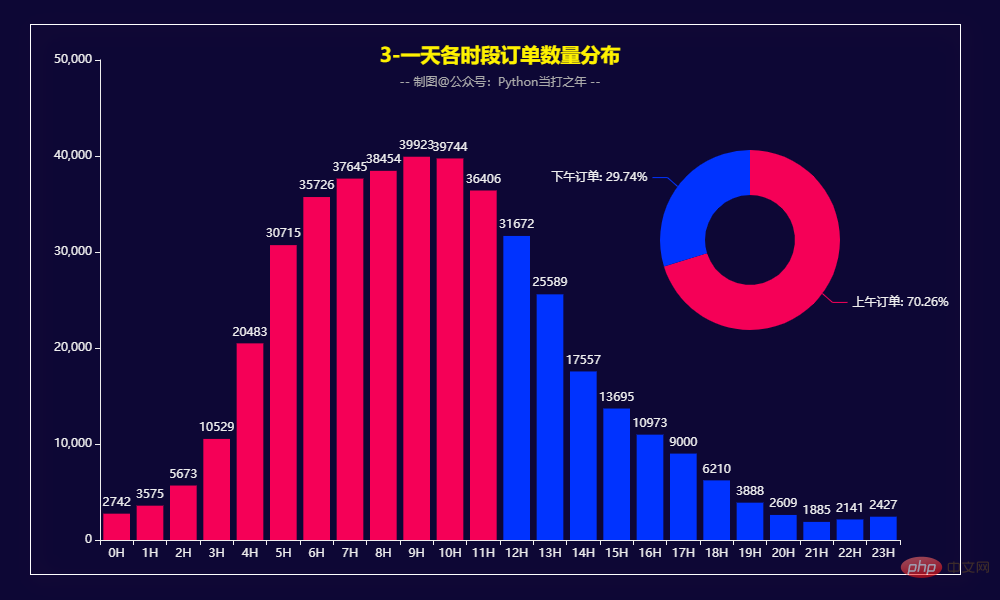
Pengagihan kuantiti pesanan harian
-
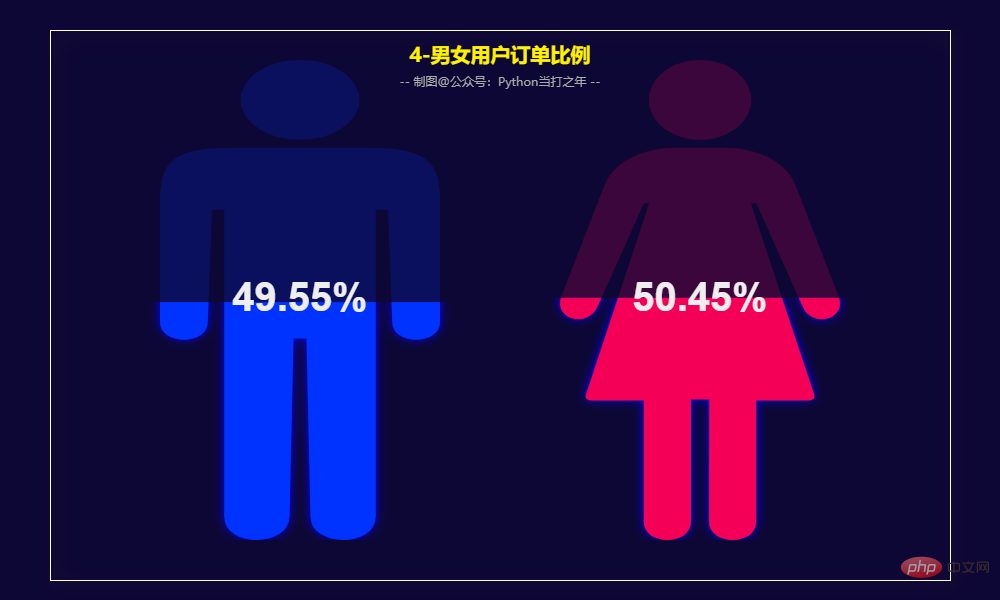
Kadaran pesanan pengguna lelaki dan wanita
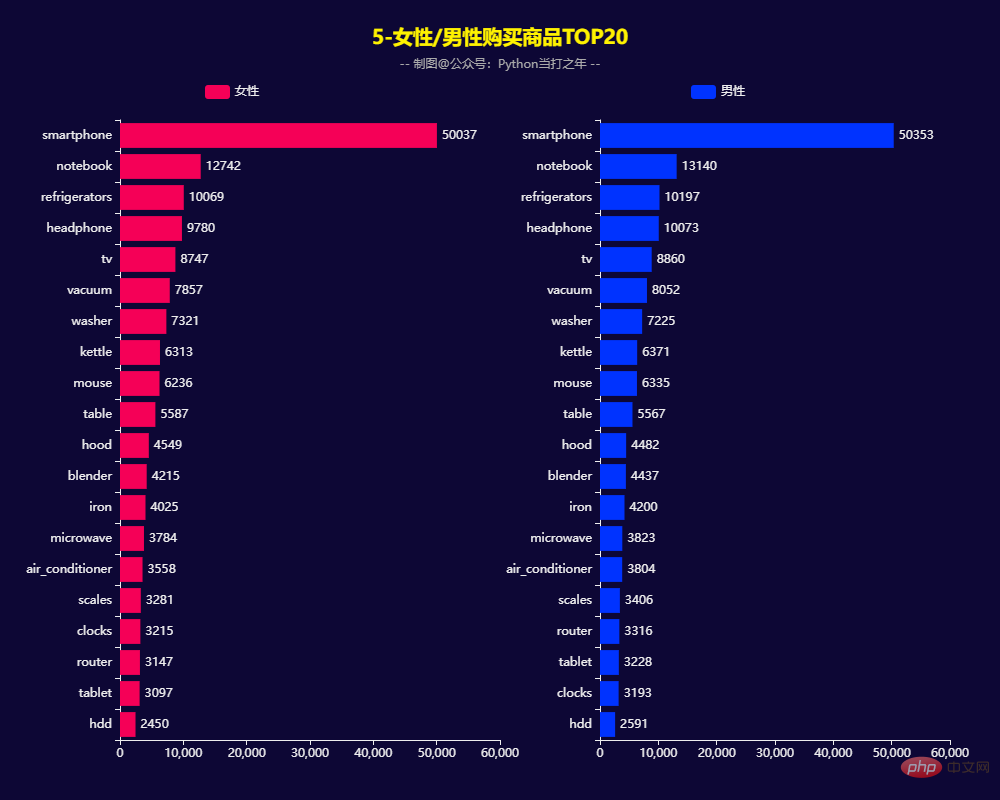
oleh wanita/lelaki -
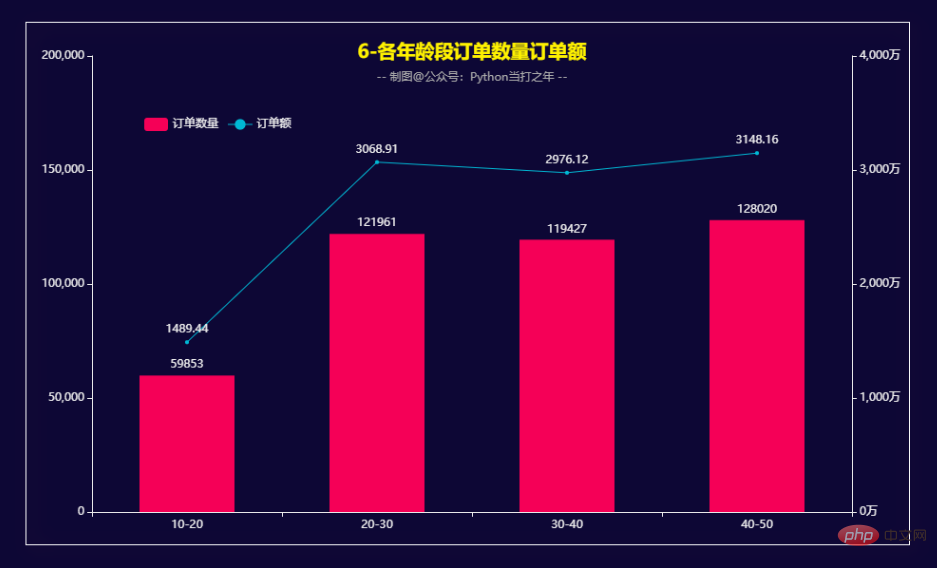
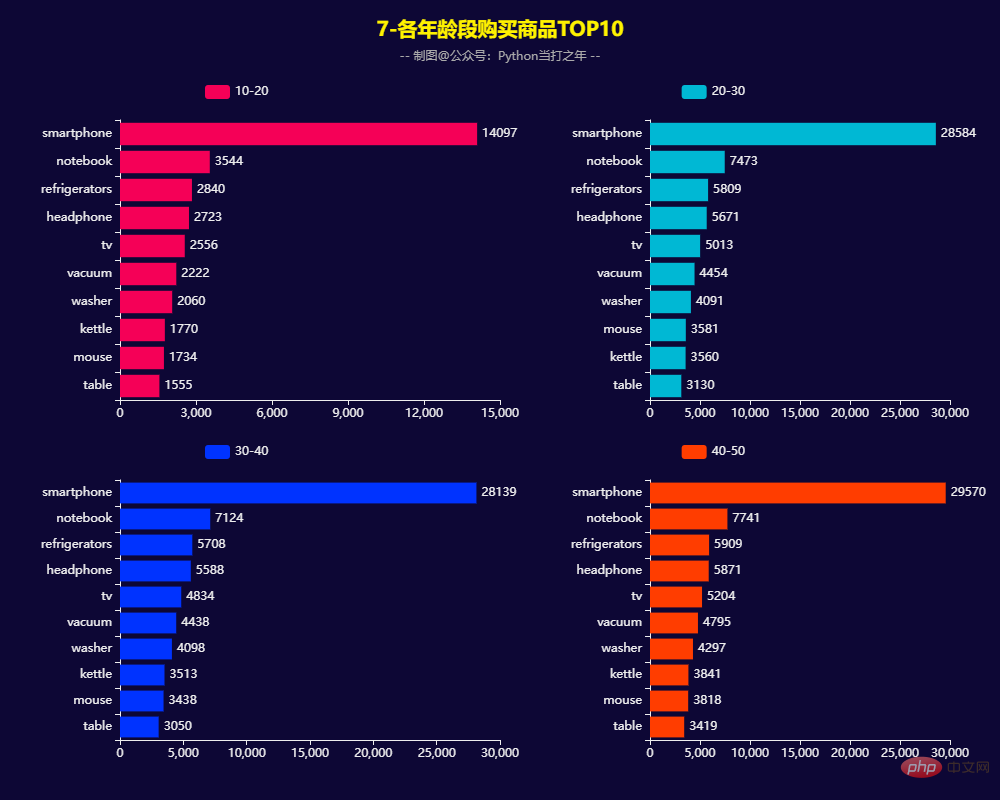
Pesanan untuk semua peringkat umur Kuantiti Jumlah Pesanan -
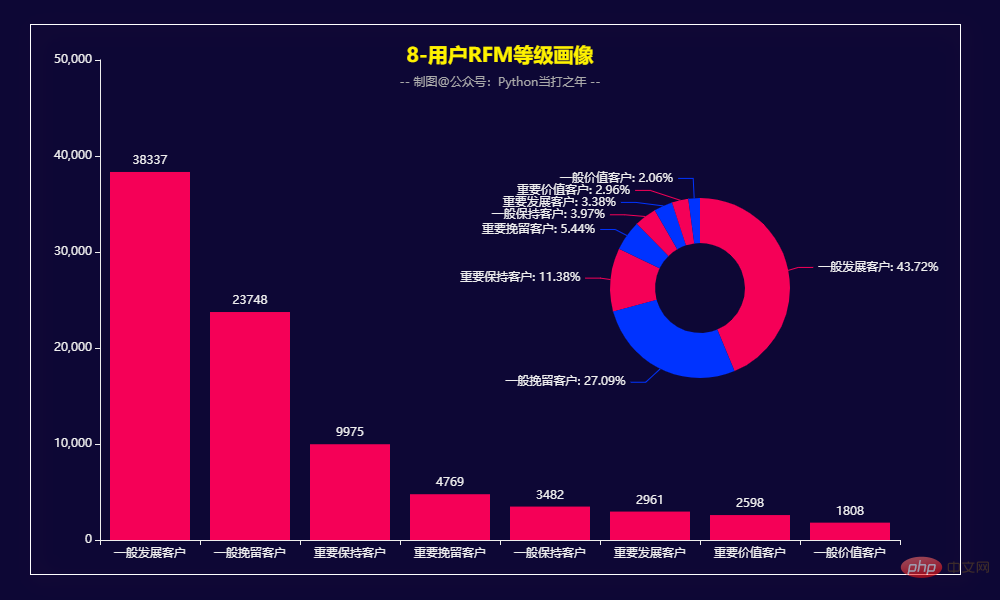
Imej RFM Pengguna
-
Semoga ia membantu semua orang, jika anda mempunyai sebarang soalan Jika anda memerlukan penambahbaikan, sila hubungi editor.
Perpustakaan yang terlibat:
Panda 一共有564169条数据,其中category_code、brand两列有部分数据缺失。 2.3 去掉部分用不到的列 (564169, 9) 2.4 去除重复数据 2.5 增加部分时间列 2.6 过滤数据,也可以选择均值填充 8月份的订单量和订单额达到峰值。 男性订单数量占比49.55%,女性订单数量占比50.45%,基本持平。 3.5 女性/男性购买商品TOP20 3.7 各年龄段购买商品TOP10 3.8 用户RFM等级画像 RFM模型是衡量客户价值和客户创利能力的重要工具和手段。该模型通过一个客户的近期购买行为(R)、购买的总体频率(F)以及花了多少钱(M)三项指标来描述该客户的价值状况,从而能够更加准确地将成本和精力更精确的花在用户层次身上,实现针对性的营销。 用户分类: 计算等级: 用户画像: 根据RFM模型可将用户分为以下8类: 重要保持客户:最近消费时间较远,消费金额和频次都很高。 Pelanggan pembangunan penting: Pengguna yang mempunyai masa penggunaan baru-baru ini dan jumlah penggunaan yang tinggi, tetapi frekuensi rendah dan kesetiaan rendah, yang berpotensi tinggi, mesti memberi tumpuan kepada pembangunan. Pengekalan pelanggan yang penting: Pengguna yang masa penggunaan baru-baru ini jauh dan kekerapan penggunaan tidak tinggi, tetapi jumlah penggunaan yang tinggi mungkin pengguna yang akan hilang atau sudah hilang, dan langkah pengekalan perlu diambil. Pelanggan nilai am: masa penggunaan baru-baru ini, frekuensi tinggi tetapi jumlah penggunaan rendah Perlu menaikkan harga unit mereka. Pelanggan pembangunan am: Masa penggunaan baru-baru ini agak baru-baru ini, dan jumlah penggunaan serta kekerapan tidak tinggi. Secara amnya mengekalkan pelanggan : Masa penggunaan baru-baru ini jauh, kekerapan penggunaan tinggi, dan jumlah penggunaan tidak tinggi.
—Pemprosesan dataPyecarts
—Penggambaran datapemprosesan data P andasimport pandas as pd
from pyecharts.charts import Line
from pyecharts.charts import Bar
from pyecharts.charts import Pie
from pyecharts.charts import Grid
from pyecharts.charts import PictorialBar
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
import warnings
warnings.filterwarnings('ignore')
df1 = df[['event_time', 'order_id', 'category_code', 'brand', 'price', 'user_id', 'age', 'sex', 'local']]
df1.shape
df1 = df1.drop_duplicates()
df1.shape
(556456, 9)
df1['event_time'] = pd.to_datetime(df1['event_time'].str[:19],format="%Y-%m-%d %H:%M:%S")
df1['Year'] = df1['event_time'].dt.year
df1['Month'] = df1['event_time'].dt.month
df1['Day'] = df1['event_time'].dt.day
df1['hour'] = df1['event_time'].dt.hour
df1.head(10)
df1 = df1.dropna(subset=['category_code'])
df1 = df1[(df1["Year"] == 2020)&(df1["price"] > 0)]
df1.shape
(429261, 13)
2.7 对年龄分组
df1['age_group'] = pd.cut(df1['age'],[10,20,30,40,50],labels=['10-20','20-30','30-40','40-50'])
2.8 增加商品一、二级分类
df1["category_code_1"] = df1["category_code"].apply(lambda x: x.split(".")[0] if "." in x else x)
df1["category_code_2"] = df1["category_code"].apply(lambda x: x.split(".")[-1] if "." in x else x)
df1.head(10)
def get_bar1():
bar1 = (
Bar()
.add_xaxis(x_data)
.add_yaxis("订单数量", y_data1)
.extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter="{value}万")))
.set_global_opts(
legend_opts=opts.LegendOpts(pos_top='25%', pos_left='center'),
title_opts=opts.TitleOpts(
title='1-每月订单数量订单额',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='7%',
pos_left="center"
)
)
)
line = (
Line()
.add_xaxis(x_data)
.add_yaxis("订单额", y_data2, yaxis_index=1)
)
bar1.overlap(line)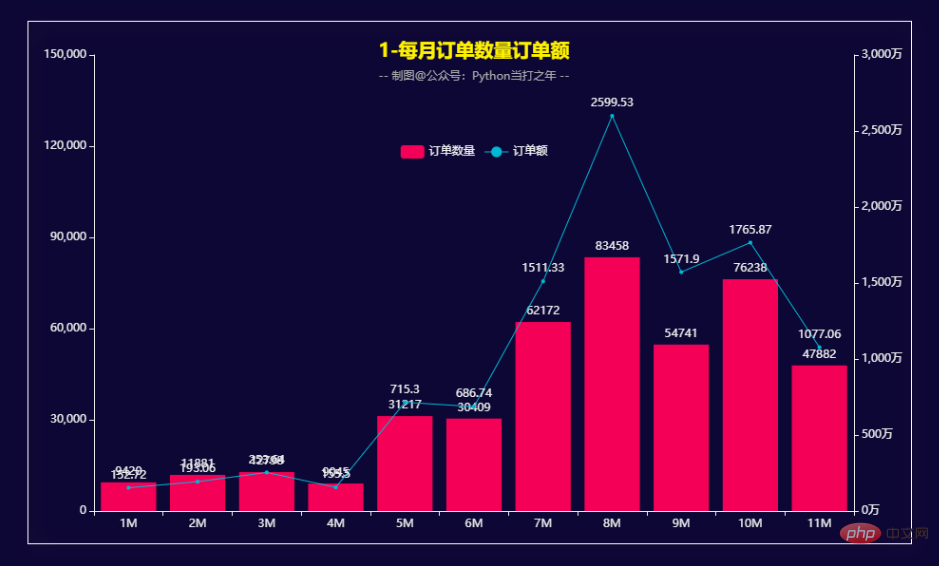
def get_bar2():
pie1 = (
Pie()
.add(
"",
datas,
radius=["13%", "25%"],
label_opts=opts.LabelOpts(formatter="{b}: {d}%"),
)
)
bar1 = (
Bar(init_opts=opts.InitOpts(theme='dark', width='1000px', height='600px', bg_color='#0d0735'))
.add_xaxis(x_data)
.add_yaxis("", y_data, itemstyle_opts=opts.ItemStyleOpts(color=JsCode(color_function)))
.set_global_opts(
legend_opts=opts.LegendOpts(is_show=False),
title_opts=opts.TitleOpts(
title='2-一月各天订单数量分布',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='7%',
pos_left="center"
)
)
)
bar1.overlap(pie1)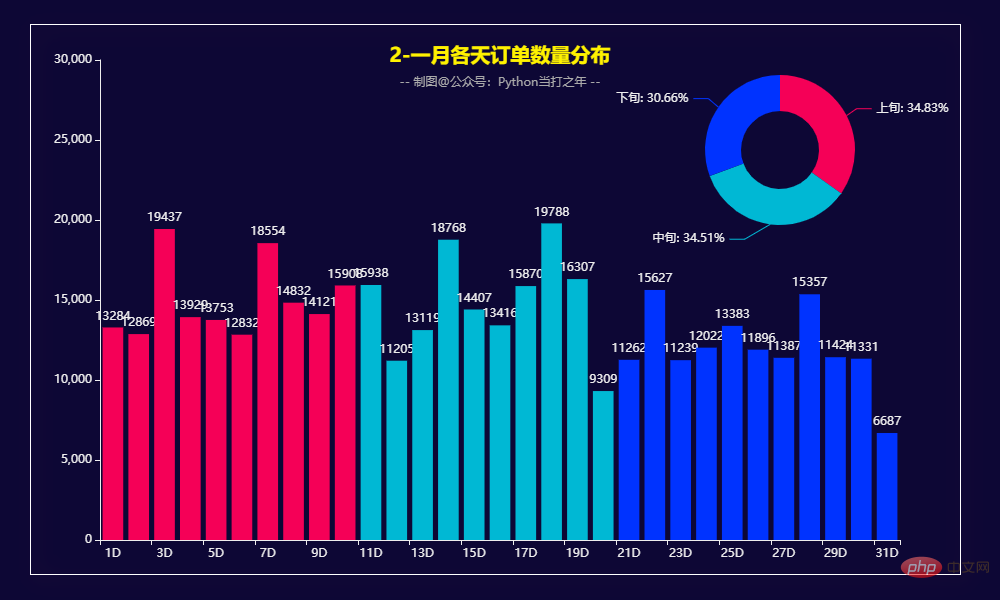
def get_bar3():
bar1 = (
Bar()
.add_xaxis(x_data1)
.add_yaxis('女性', y_data1,
label_opts=opts.LabelOpts(position='right')
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='5-女性/男性购买商品TOP20',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='3%',
pos_left="center"),
legend_opts=opts.LegendOpts(pos_left='20%', pos_top='10%')
)
.reversal_axis()
)
bar2 = (
Bar()
.add_xaxis(x_data2)
.add_yaxis('男性', y_data2,
label_opts=opts.LabelOpts(position='right')
)
.set_global_opts(
legend_opts=opts.LegendOpts(pos_right='25%', pos_top='10%')
)
.reversal_axis()
)
grid1 = (
Grid()
.add(bar1, grid_opts=opts.GridOpts(pos_left='12%', pos_right='50%', pos_top='15%'))
.add(bar2, grid_opts=opts.GridOpts(pos_left='60%', pos_right='5%', pos_top='15%'))
)
def rfm_func(x):
level = x.apply(lambda x:"1" if x > 0 else '0')
RMF = level.R + level.F + level.M
dic_rfm ={
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要发展客户',
'001':'重要挽留客户',
'110':'一般价值客户',
'100':'一般发展客户',
'010':'一般保持客户',
'000':'一般挽留客户'
}
result = dic_rfm[RMF]
return resultdf_rfm = df1.copy()
df_rfm = df_rfm[['user_id','event_time','price']]
# 时间以当年年底为准
df_rfm['days'] = (pd.to_datetime("2020-12-31")-df_rfm["event_time"]).dt.days
# 计算等级
df_rfm = pd.pivot_table(df_rfm,index="user_id",
values=["user_id","days","price"],
aggfunc={"user_id":"count","days":"min","price":"sum"})
df_rfm = df_rfm[["days","user_id","price"]]
df_rfm.columns = ["R","F","M"]
df_rfm['RMF'] = df_rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
df_rfm.head()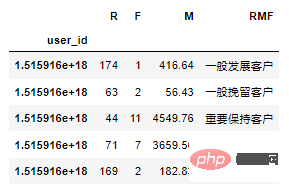
Atas ialah kandungan terperinci Pandas+Pyecharts |. Visualisasi analisis data jualan produk elektronik + potret RFM pengguna. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Menyelesaikan masalah pemasangan panda biasa: tafsiran dan penyelesaian kepada ralat pemasangan
Feb 19, 2024 am 09:19 AM
Menyelesaikan masalah pemasangan panda biasa: tafsiran dan penyelesaian kepada ralat pemasangan
Feb 19, 2024 am 09:19 AM
Tutorial pemasangan Pandas: Analisis ralat pemasangan biasa dan penyelesaiannya, contoh kod khusus diperlukan Pengenalan: Pandas ialah alat analisis data yang berkuasa yang digunakan secara meluas dalam pembersihan data, pemprosesan data dan visualisasi data, jadi ia sangat dihormati dalam bidang sains data. Walau bagaimanapun, disebabkan oleh konfigurasi persekitaran dan isu pergantungan, anda mungkin menghadapi beberapa kesukaran dan ralat semasa memasang panda. Artikel ini akan memberi anda tutorial pemasangan panda dan menganalisis beberapa ralat pemasangan biasa serta penyelesaiannya. 1. Pasang panda
 Cara membaca fail txt dengan betul menggunakan panda
Jan 19, 2024 am 08:39 AM
Cara membaca fail txt dengan betul menggunakan panda
Jan 19, 2024 am 08:39 AM
Cara menggunakan panda untuk membaca fail txt dengan betul memerlukan contoh kod khusus Pandas ialah perpustakaan analisis data Python yang digunakan secara meluas. Ia boleh digunakan untuk memproses pelbagai jenis data, termasuk fail CSV, fail Excel, pangkalan data SQL, dll. Pada masa yang sama, ia juga boleh digunakan untuk membaca fail teks, seperti fail txt. Walau bagaimanapun, apabila membaca fail txt, kadangkala kami menghadapi beberapa masalah, seperti masalah pengekodan, masalah pembatas, dsb. Artikel ini akan memperkenalkan cara membaca txt dengan betul menggunakan panda
 Baca fail CSV dan lakukan analisis data menggunakan panda
Jan 09, 2024 am 09:26 AM
Baca fail CSV dan lakukan analisis data menggunakan panda
Jan 09, 2024 am 09:26 AM
Pandas ialah alat analisis data yang berkuasa yang boleh membaca dan memproses pelbagai jenis fail data dengan mudah. Antaranya, fail CSV ialah salah satu daripada format fail data yang paling biasa dan biasa digunakan. Artikel ini akan memperkenalkan cara menggunakan Panda untuk membaca fail CSV dan melakukan analisis data serta memberikan contoh kod khusus. 1. Import perpustakaan yang diperlukan Mula-mula, kita perlu mengimport perpustakaan Pandas dan perpustakaan lain yang berkaitan yang mungkin diperlukan, seperti yang ditunjukkan di bawah: importpandasaspd 2. Baca fail CSV menggunakan Pan
 kaedah pemasangan panda python
Nov 22, 2023 pm 02:33 PM
kaedah pemasangan panda python
Nov 22, 2023 pm 02:33 PM
Python boleh memasang panda dengan menggunakan pip, menggunakan conda, daripada kod sumber, dan menggunakan alat pengurusan pakej bersepadu IDE. Pengenalan terperinci: 1. Gunakan pip dan jalankan arahan pemasangan panda pip dalam terminal atau command prompt untuk memasang panda 2. Gunakan conda dan jalankan arahan pemasangan panda di terminal atau command prompt untuk memasang panda; pemasangan dan banyak lagi.
 Panda dengan mudah membaca data daripada pangkalan data SQL
Jan 09, 2024 pm 10:45 PM
Panda dengan mudah membaca data daripada pangkalan data SQL
Jan 09, 2024 pm 10:45 PM
Alat pemprosesan data: Pandas membaca data daripada pangkalan data SQL dan memerlukan contoh kod khusus Memandangkan jumlah data terus berkembang dan kerumitannya meningkat, pemprosesan data telah menjadi bahagian penting dalam masyarakat moden. Dalam proses pemprosesan data, Pandas telah menjadi salah satu alat pilihan untuk ramai penganalisis dan saintis data. Artikel ini akan memperkenalkan cara menggunakan pustaka Pandas untuk membaca data daripada pangkalan data SQL dan menyediakan beberapa contoh kod khusus. Pandas ialah alat pemprosesan dan analisis data yang berkuasa berdasarkan Python
 Bagaimana untuk memasang panda dalam python
Dec 04, 2023 pm 02:48 PM
Bagaimana untuk memasang panda dalam python
Dec 04, 2023 pm 02:48 PM
Langkah-langkah untuk memasang panda dalam python: 1. Buka terminal atau command prompt 2. Masukkan arahan "pip install panda" untuk memasang perpustakaan panda; 3. Tunggu pemasangan selesai, dan anda boleh mengimport dan menggunakan perpustakaan panda dalam skrip Python; 4. Gunakan Ia adalah persekitaran maya tertentu Pastikan untuk mengaktifkan persekitaran maya yang sepadan sebelum memasang panda 5. Jika anda menggunakan persekitaran pembangunan bersepadu, anda boleh menambah kod "import panda sebagai pd". import perpustakaan panda.
 Petua praktikal untuk membaca fail txt menggunakan panda
Jan 19, 2024 am 09:49 AM
Petua praktikal untuk membaca fail txt menggunakan panda
Jan 19, 2024 am 09:49 AM
Petua praktikal untuk membaca fail txt menggunakan panda, contoh kod khusus diperlukan Dalam analisis data dan pemprosesan data, fail txt ialah format data biasa. Menggunakan panda untuk membaca fail txt membolehkan pemprosesan data yang cepat dan mudah. Artikel ini akan memperkenalkan beberapa teknik praktikal untuk membantu anda menggunakan panda dengan lebih baik untuk membaca fail txt, bersama-sama dengan contoh kod tertentu. Baca fail txt dengan pembatas Apabila menggunakan panda untuk membaca fail txt dengan pembatas, anda boleh menggunakan read_c
 Mendedahkan kaedah penduaan data yang cekap dalam Pandas: Petua untuk mengalih keluar data pendua dengan cepat
Jan 24, 2024 am 08:12 AM
Mendedahkan kaedah penduaan data yang cekap dalam Pandas: Petua untuk mengalih keluar data pendua dengan cepat
Jan 24, 2024 am 08:12 AM
Rahsia kaedah deduplikasi Pandas: cara yang cepat dan cekap untuk menyahduplikasi data, yang memerlukan contoh kod khusus Dalam proses analisis dan pemprosesan data, duplikasi dalam data sering ditemui. Data pendua mungkin mengelirukan keputusan analisis, jadi penduaan adalah langkah yang sangat penting. Pandas, pustaka pemprosesan data yang berkuasa, menyediakan pelbagai kaedah untuk mencapai penyahduplikasian data Artikel ini akan memperkenalkan beberapa kaedah penyahduplikasian yang biasa digunakan, dan melampirkan contoh kod tertentu. Kes penduaan yang paling biasa berdasarkan satu lajur adalah berdasarkan sama ada nilai lajur tertentu diduakan.
