
 pembangunan bahagian belakang
Tutorial Python
4000 perkataan penerangan terperinci, mengesyorkan 20 kaedah fungsi Panda yang berguna
pembangunan bahagian belakang
Tutorial Python
4000 perkataan penerangan terperinci, mengesyorkan 20 kaedah fungsi Panda yang berguna
4000 perkataan penerangan terperinci, mengesyorkan 20 kaedah fungsi Panda yang berguna

. Tingkatkan kecekapan kerja, dan saya harap semua orang boleh memperoleh sesuatu selepas membacanya
item()方法items()方法iterrows()方法insert()方法assign()方法eval()方法pop()方法truncate()方法count()方法add_prefix()方法/add_suffix()方法clip()方法-
filter()🎜 first()方法first()方法isin()方法df.plot.area()方法df.plot.bar()方法df.plot.box()方法df.plot.pie()方法
iterrows()方法🎜🎜🎜 🎜insert()方法🎜🎜🎜🎜 assign()方法🎜🎜🎜🎜eval()方法🎜🎜🎜🎜count()方法🎜🎜🎜🎜add_prefix()方法/add_suffix()方法🎜🎜🎜🎜clip()方法🎜🎜🎜🎜filter()方法🎜🎜
items()方法
items()方法可以用来遍历数据集当中的每一列,同时返回列名以及每一列当中的内容,通过以元组的形式,示例如下df = pd.DataFrame({'species': ['bear', 'bear', 'marsupial'],
'population': [1864, 22000, 80000]},
index=['panda', 'polar', 'koala'])
dfoutput
species population panda bear 1864 polar bear 22000 koala marsupial 80000
然后我们使用items()方法
for label, content in df.items():
print(f'label: {label}')
print(f'content: {content}', sep='\n')
print("=" * 50)output
label: species content: panda bear polar bear koala marsupial Name: species, dtype: object ================================================== label: population content: panda 1864 polar 22000 koala 80000 Name: population, dtype: int64 ==================================================
相继的打印出了‘species’和‘population’这两列的列名和相应的内容
iterrows()方法
iterrows()isin()方法
df.plot.area() 方法🎜🎜🎜df .plot.bar()方法🎜🎜🎜df.plot.box()方法🎜🎜🎜df.plot.pie()方法🎜item()方法
item()方法可以用来遍历数据集当中的毆当中的毗,同时返回列名以及每一列当中的内容,通过以元组的形式,示例如下🎜rreee🎜们作output🎜作output🎜作住用item()方法🎜for label, content in df.iterrows():
print(f'label: {label}')
print(f'content: {content}', sep='\n')
print("=" * 50)label: panda content: species bear population 1864 Name: panda, dtype: object ================================================== label: polar content: species bear population 22000 Name: polar, dtype: object ================================================== label: koala content: species marsupial population 80000 Name: koala, dtype: object ==================================================
iterrows()方法
iterrows()方法而言,其功能则是遍历数据集当中的每一行,返回每一行的索引地不一切的内容,示例如下🎜df.insert(1, "size", [2000, 3000, 4000])
label: panda content: species bear population 1864 Name: panda, dtype: object ================================================== label: polar content: species bear population 22000 Name: polar, dtype: object ================================================== label: koala content: species marsupial population 80000 Name: koala, dtype: object ==================================================
insert()方法
insert()方法主要是用于在数据集当中的特定位置处插入数据,示例如下
df.insert(1, "size", [2000, 3000, 4000])
output
species size population panda bear 2000 1864 polar bear 3000 22000 koala marsupial 4000 80000
可见在DataFrame数据集当中,列的索引也是从0开始的
assign()方法
assign()方法可以用来在数据集当中添加新的列,示例如下
df.assign(size_1=lambda x: x.population * 9 / 5 + 32)
output
species population size_1 panda bear 1864 3387.2 polar bear 22000 39632.0 koala marsupial 80000 144032.0
lambda匿名函数,在数据集当中添加一个新的列,命名为‘size_1’,当然我们也可以通过assign()方法来创建不止一个列df.assign(size_1 = lambda x: x.population * 9 / 5 + 32,
size_2 = lambda x: x.population * 8 / 5 + 10)output
species population size_1 size_2 panda bear 1864 3387.2 2992.4 polar bear 22000 39632.0 35210.0 koala marsupial 80000 144032.0 128010.0
eval()方法
eval()方法主要是用来执行用字符串来表示的运算过程的,例如
df.eval("size_3 = size_1 + size_2")output
species population size_1 size_2 size_3 panda bear 1864 3387.2 2992.4 6379.6 polar bear 22000 39632.0 35210.0 74842.0 koala marsupial 80000 144032.0 128010.0 272042.0
当然我们也可以同时对执行多个运算过程
df = df.eval(''' size_3 = size_1 + size_2 size_4 = size_1 - size_2 ''')
output
species population size_1 size_2 size_3 size_4 panda bear 1864 3387.2 2992.4 6379.6 394.8 polar bear 22000 39632.0 35210.0 74842.0 4422.0 koala marsupial 80000 144032.0 128010.0 272042.0 16022.0
pop()方法
pop()方法主要是用来删除掉数据集中特定的某一列数据
df.pop("size_3")output
panda 6379.6 polar 74842.0 koala 272042.0 Name: size_3, dtype: float64
而原先的数据集当中就没有这个‘size_3’这一例的数据了
truncate()方法
truncate()方法主要是根据行索引来筛选指定行的数据的,示例如下
df = pd.DataFrame({'A': ['a', 'b', 'c', 'd', 'e'],
'B': ['f', 'g', 'h', 'i', 'j'],
'C': ['k', 'l', 'm', 'n', 'o']},
index=[1, 2, 3, 4, 5])output
A B C 1 a f k 2 b g l 3 c h m 4 d i n 5 e j o
我们使用truncate()方法来做一下尝试
df.truncate(before=2, after=4)
output
A B C 2 b g l 3 c h m 4 d i n
before和after存在于truncate()方法中,目的就是把行索引2之前和行索引4之后的数据排除在外,筛选出剩余的数据count()方法
count()方法主要是用来计算某一列当中非空值的个数,示例如下
df = pd.DataFrame({"Name": ["John", "Myla", "Lewis", "John", "John"],
"Age": [24., np.nan, 25, 33, 26],
"Single": [True, True, np.nan, True, False]})output
Name Age Single 0 John 24.0 True 1 Myla NaN True 2 Lewis 25.0 NaN 3 John 33.0 True 4 John 26.0 False
我们使用count()方法来计算一下数据集当中非空值的个数
df.count()
output
Name 5 Age 4 Single 4 dtype: int64
add_prefix()方法/add_suffix()方法
add_prefix()方法和add_suffix()方法分别会给列名以及行索引添加后缀和前缀,对于Series()数据集而言,前缀与后缀是添加在行索引处,而对于DataFrame()数据集而言,前缀与后缀是添加在列索引处,示例如下s = pd.Series([1, 2, 3, 4])
output
0 1 1 2 2 3 3 4 dtype: int64
我们使用add_prefix()方法与add_suffix()方法在Series()数据集上
s.add_prefix('row_')
output
row_0 1 row_1 2 row_2 3 row_3 4 dtype: int64
又例如
s.add_suffix('_row')
output
0_row 1 1_row 2 2_row 3 3_row 4 dtype: int64
DataFrame()形式数据集而言,add_prefix()方法以及add_suffix()方法是将前缀与后缀添加在列索引处的df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [3, 4, 5, 6]})output
A B 0 1 3 1 2 4 2 3 5 3 4 6
示例如下
df.add_prefix("column_")output
column_A column_B 0 1 3 1 2 4 2 3 5 3 4 6
又例如
df.add_suffix("_column")output
A_column B_column 0 1 3 1 2 4 2 3 5 3 4 6
clip()方法
clip()方法主要是通过设置阈值来改变数据集当中的数值,当数值超过阈值的时候,就做出相应的调整data = {'col_0': [9, -3, 0, -1, 5], 'col_1': [-2, -7, 6, 8, -5]}
df = pd.DataFrame(data)output
df.clip(lower = -4, upper = 4)
output
col_0 col_1 0 4 -2 1 -3 -4 2 0 4 3 -1 4 4 4 -4
lower和upper分别代表阈值的上限与下限,数据集当中超过上限与下限的值会被替代。filter()方法
pandas当中的filter()方法是用来筛选出特定范围的数据的,示例如下
df = pd.DataFrame(np.array(([1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12])),
index=['A', 'B', 'C', 'D'],
columns=['one', 'two', 'three'])output
one two three A 1 2 3 B 4 5 6 C 7 8 9 D 10 11 12
我们使用filter()方法来筛选数据
df.filter(items=['one', 'three'])
output
one three A 1 3 B 4 6 C 7 9 D 10 12
我们还可以使用正则表达式来筛选数据
df.filter(regex='e$', axis=1)
output
one three A 1 3 B 4 6 C 7 9 D 10 12
当然通过参数axis来调整筛选行方向或者是列方向的数据
df.filter(like='B', axis=0)
output
one two three B 4 5 6
first()方法
当数据集当中的行索引是日期的时候,可以通过该方法来筛选前面几行的数据
index_1 = pd.date_range('2021-11-11', periods=5, freq='2D')
ts = pd.DataFrame({'A': [1, 2, 3, 4, 5]}, index=index_1)
tsoutput
A 2021-11-11 1 2021-11-13 2 2021-11-15 3 2021-11-17 4 2021-11-19 5
我们使用first()方法来进行一些操作,例如筛选出前面3天的数据
ts.first('3D')
output
A 2021-11-11 1 2021-11-13 2
isin()方法
isin()方法主要是用来确认数据集当中的数值是否被包含在给定的列表当中
df = pd.DataFrame(np.array(([1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12])),
index=['A', 'B', 'C', 'D'],
columns=['one', 'two', 'three'])
df.isin([3, 5, 12])output
one two three A False False True B False True False C False False False D False False True
True,否则就返回Falsedf.plot.area()方法
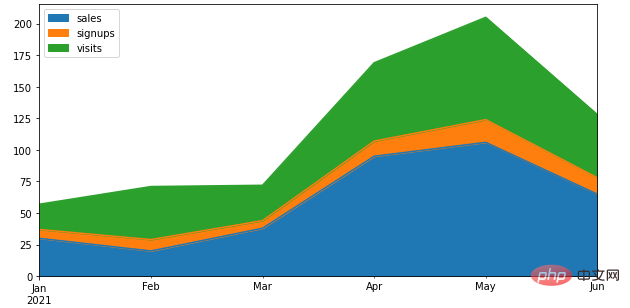
Pandas当中通过一行代码来绘制图表,将所有的列都通过面积图的方式来绘制df = pd.DataFrame({
'sales': [30, 20, 38, 95, 106, 65],
'signups': [7, 9, 6, 12, 18, 13],
'visits': [20, 42, 28, 62, 81, 50],
}, index=pd.date_range(start='2021/01/01', end='2021/07/01', freq='M'))
ax = df.plot.area(figsize = (10, 5))output
df.plot.bar()方法
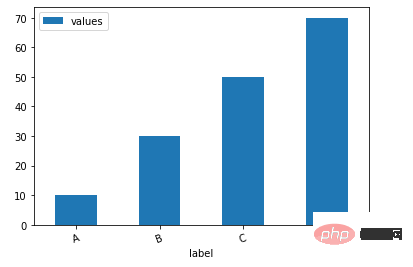
下面我们看一下如何通过一行代码来绘制柱状图
df = pd.DataFrame({'label':['A', 'B', 'C', 'D'], 'values':[10, 30, 50, 70]})
ax = df.plot.bar(x='label', y='values', rot=20)output
当然我们也可以根据不同的类别来绘制柱状图
age = [0.1, 17.5, 40, 48, 52, 69, 88]
weight = [2, 8, 70, 1.5, 25, 12, 28]
index = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
df = pd.DataFrame({'age': age, 'weight': weight}, index=index)
ax = df.plot.bar(rot=0)output
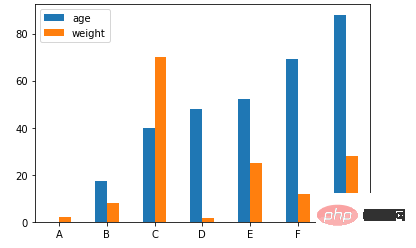
当然我们也可以横向来绘制图表
ax = df.plot.barh(rot=0)
output
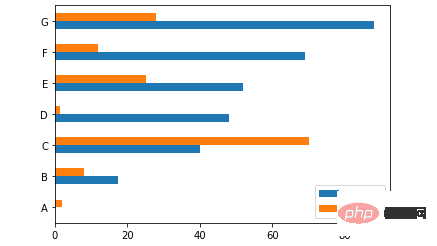
df.plot.box()方法
我们来看一下箱型图的具体的绘制,通过pandas一行代码来实现
data = np.random.randn(25, 3) df = pd.DataFrame(data, columns=list('ABC')) ax = df.plot.box()
output
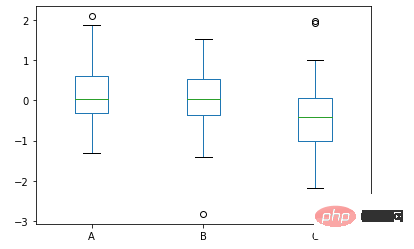
df.plot.pie()方法
接下来是饼图的绘制
df = pd.DataFrame({'mass': [1.33, 4.87 , 5.97],
'radius': [2439.7, 6051.8, 6378.1]},
index=['Mercury', 'Venus', 'Earth'])
plot = df.plot.pie(y='mass', figsize=(8, 8))output
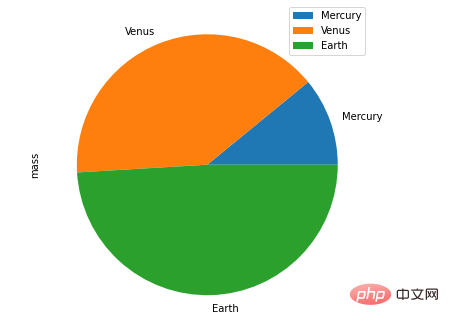
除此之外,还有折线图、直方图、散点图等等,步骤与方式都与上述的技巧有异曲同工之妙,大家感兴趣的可以自己另外去尝试。
Atas ialah kandungan terperinci 4000 perkataan penerangan terperinci, mengesyorkan 20 kaedah fungsi Panda yang berguna. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Apabila memilih versi pytorch di bawah CentOS, faktor utama berikut perlu dipertimbangkan: 1. Keserasian versi CUDA Sokongan GPU: Jika anda mempunyai NVIDIA GPU dan ingin menggunakan pecutan GPU, anda perlu memilih pytorch yang menyokong versi CUDA yang sepadan. Anda boleh melihat versi CUDA yang disokong dengan menjalankan arahan NVIDIA-SMI. Versi CPU: Jika anda tidak mempunyai GPU atau tidak mahu menggunakan GPU, anda boleh memilih versi CPU PyTorch. 2. Pytorch versi python
 Cara melakukan pra -proses data dengan pytorch di centOs
Apr 14, 2025 pm 02:15 PM
Cara melakukan pra -proses data dengan pytorch di centOs
Apr 14, 2025 pm 02:15 PM
Dengan cekap memproses data pitorch pada sistem CentOS, langkah-langkah berikut diperlukan: Pemasangan Ketergantungan: Kemas kini pertama sistem dan pasang Python3 dan PIP: Sudoyumupdate-iSudoyumStallpython3-Isudoyumstallpython3-y Konfigurasi Persekitaran Maya (disyorkan): Gunakan Conda untuk membuat dan mengaktifkan persekitaran maya baru, contohnya: condacreate-n
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
