

Spring Boot melaksanakan teknologi pemisahan baca-tulis MySQL
Cara melaksanakan pemisahan baca dan tulis, projek Spring Boot, pangkalan data ialah MySQL, dan lapisan kegigihan menggunakan MyBatis.
Sebenarnya, sangat mudah untuk melaksanakan perkara ini Fikirkan dahulu soalan:
Dalam senario konkurensi tinggi, apakah kaedah pengoptimuman yang ada untuk pangkalan data?
Kaedah pelaksanaan berikut biasanya digunakan: pemisahan baca-tulis, caching, kluster seni bina tuan-hamba, sub-pangkalan data dan sub-jadual, dsb.
Dalam aplikasi Internet, kebanyakannya lebih banyak membaca dan kurang menulis Dua perpustakaan disediakan, perpustakaan utama dan perpustakaan bacaan.
Perpustakaan utama bertanggungjawab untuk menulis, dan perpustakaan hamba bertanggungjawab terutamanya untuk membaca Kluster perpustakaan membaca boleh diwujudkan Melalui pengasingan fungsi membaca dan menulis pada sumber data, tujuan untuk mengurangkan konflik membaca dan menulis , melegakan beban pangkalan data, dan melindungi pangkalan data boleh dicapai. Dalam penggunaan sebenar, mana-mana bahagian yang melibatkan penulisan dialihkan terus ke perpustakaan utama, dan bahagian bacaan dialihkan terus ke perpustakaan bacaan Ini adalah teknologi pemisahan baca-tulis biasa.
Artikel ini akan memfokuskan pada pemisahan membaca dan menulis serta meneroka cara melaksanakannya.
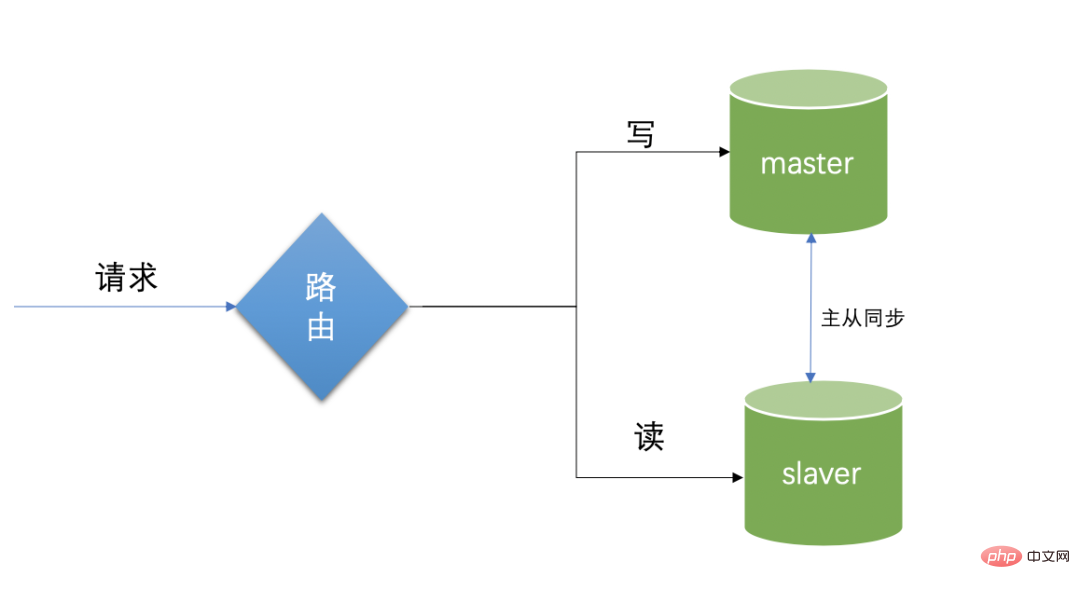
Limitasi penyegerakan master-hamba: ini dibahagikan kepada pangkalan data induk dan pangkalan data hamba. data akan disegerakkan secara automatik ke pangkalan data hamba. Pangkalan data hamba bertanggungjawab untuk membaca Apabila permintaan baca datang, data dibaca terus dari pangkalan data bacaan, dan pangkalan data induk akan menyalin data secara automatik ke pangkalan data hamba. Walau bagaimanapun, blog ini tidak memperkenalkan bahagian pengetahuan konfigurasi ini, kerana ia lebih tertumpu kepada kerja operasi dan penyelenggaraan.
Ada masalah yang terlibat di sini:Masalah kelewatan replikasi tuan-hamba Apabila menulis ke pangkalan data utama, permintaan baca tiba-tiba datang, dan data tidak disegerakkan sepenuhnya pada masa ini, permintaan baca akan muncul. . Data tidak boleh dibaca atau data dibaca kurang daripada nilai asal. Penyelesaian khusus yang paling mudah adalah untuk mengarahkan permintaan baca sementara ke perpustakaan utama, tetapi pada masa yang sama ia juga kehilangan sebahagian daripada makna pemisahan tuan-hamba. Maksudnya, dalam erti kata ketat senario konsistensi data, pemisahan baca-tulis tidak sepenuhnya sesuai Beri perhatian kepada ketepatan masa kemas kini sebagai kekurangan penggunaan pemisahan baca-tulis.Baiklah, bahagian ini hanya untuk pemahaman. Seterusnya, mari kita lihat cara untuk mencapai pemisahan baca dan tulis melalui kod Java:
Nota: Projek ini perlu memperkenalkan kebergantungan berikut: Spring Boot, spring-aop, spring-jdbc, aspectjweaver, dll.
Programmer: Hanya ada 30 hari, bagaimana untuk menyediakan?
1: Konfigurasi sumber data tuan-hamba
Kami perlu mengkonfigurasi pangkalan data tuan-hamba Konfigurasi pangkalan data tuan-hamba biasanya ditulis dalam fail konfigurasi. Melalui anotasi @ConfigurationProperties, fail konfigurasi (biasanya dinamakan: application.Properties) dipetakan kepada atribut kelas tertentu, supaya nilai bertulis dibaca dan disuntik ke dalam konfigurasi kod tertentu Menurut prinsip bahawa tabiat lebih besar daripada konvensyen, kita semua menganotasi perpustakaan utama sebagai tuan, perpustakaan hamba ditandakan sebagai hamba. application.Properties)里的属性映射到具体的类属性上,从而读取到写入的值注入到具体的代码配置中,按照习惯大于约定的原则,主库我们都是注为 master,从库注为 slave。
本项目采用了阿里的 druid 数据库连接池,使用 build 建造者模式创建 DataSource 对象,DataSource 就是代码层面抽象出来的数据源,接着需要配置 sessionFactory、sqlTemplate、事务管理器等。
/**
* 主从配置
*/
@Configuration
@MapperScan(basePackages = "com.wyq.mysqlreadwriteseparate.mapper", sqlSessionTemplateRef = "sqlTemplate")
public class DataSourceConfig {
/**
* 主库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource master() {
return DruidDataSourceBuilder.create().build();
}
/**
* 从库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaver() {
return DruidDataSourceBuilder.create().build();
}
/**
* 实例化数据源路由
*/
@Bean
public DataSourceRouter dynamicDB(@Qualifier("master") DataSource masterDataSource,
@Autowired(required = false) @Qualifier("slaver") DataSource slaveDataSource) {
DataSourceRouter dynamicDataSource = new DataSourceRouter();
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceEnum.MASTER.getDataSourceName(), masterDataSource);
if (slaveDataSource != null) {
targetDataSources.put(DataSourceEnum.SLAVE.getDataSourceName(), slaveDataSource);
}
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(masterDataSource);
return dynamicDataSource;
}
/**
* 配置sessionFactory
* @param dynamicDataSource
* @return
* @throws Exception
*/
@Bean
public SqlSessionFactory sessionFactory(@Qualifier("dynamicDB") DataSource dynamicDataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setMapperLocations(
new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/*Mapper.xml"));
bean.setDataSource(dynamicDataSource);
return bean.getObject();
}
/**
* 创建sqlTemplate
* @param sqlSessionFactory
* @return
*/
@Bean
public SqlSessionTemplate sqlTemplate(@Qualifier("sessionFactory") SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
/**
* 事务配置
*
* @param dynamicDataSource
* @return
*/
@Bean(name = "dataSourceTx")
public DataSourceTransactionManager dataSourceTransactionManager(@Qualifier("dynamicDB") DataSource dynamicDataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(dynamicDataSource);
return dataSourceTransactionManager;
}
}二: 数据源路由的配置
路由在主从分离是非常重要的,基本是读写切换的核心。Spring 提供了 AbstractRoutingDataSource 根据用户定义的规则选择当前的数据源,作用就是在执行查询之前,设置使用的数据源,实现动态路由的数据源,在每次数据库查询操作前执行它的抽象方法 determineCurrentLookupKey()
public class DataSourceRouter extends AbstractRoutingDataSource {
/**
* 最终的determineCurrentLookupKey返回的是从DataSourceContextHolder中拿到的,因此在动态切换数据源的时候注解
* 应该给DataSourceContextHolder设值
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.get();
}
}AbstractRoutingDataSource mengikut peraturan yang ditetapkan pengguna Fungsi memilih sumber data semasa adalah untuk menetapkan sumber data yang digunakan sebelum melaksanakan pertanyaan, melaksanakan sumber data penghalaan dinamik dan melaksanakan kaedah abstraknya sebelum setiap operasi pertanyaan pangkalan datadetermineCurrentLookupKey() Menentukan sumber data yang hendak digunakan. 🎜🎜Untuk mempunyai pengurus sumber data global, kami perlu memperkenalkan DataSourceContextHolder, pengurus konteks pangkalan data, yang boleh difahami sebagai pembolehubah global dan boleh diakses pada bila-bila masa (lihat pengenalan terperinci di bawah). untuk menyimpan data semasa. 🎜public class DataSourceRouter extends AbstractRoutingDataSource {
/**
* 最终的determineCurrentLookupKey返回的是从DataSourceContextHolder中拿到的,因此在动态切换数据源的时候注解
* 应该给DataSourceContextHolder设值
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.get();
}
}三:数据源上下文环境
数据源上下文保存器,便于程序中可以随时取到当前的数据源,它主要利用 ThreadLocal 封装,因为 ThreadLocal 是线程隔离的,天然具有线程安全的优势。这里暴露了 set 和 get、clear 方法,set 方法用于赋值当前的数据源名,get 方法用于获取当前的数据源名称,clear 方法用于清除 ThreadLocal 中的内容,因为 ThreadLocal 的 key 是 weakReference 是有内存泄漏风险的,通过 remove 方法防止内存泄漏。
/**
* 利用ThreadLocal封装的保存数据源上线的上下文context
*/
public class DataSourceContextHolder {
private static final ThreadLocal<String> context = new ThreadLocal<>();
/**
* 赋值
*
* @param datasourceType
*/
public static void set(String datasourceType) {
context.set(datasourceType);
}
/**
* 获取值
* @return
*/
public static String get() {
return context.get();
}
public static void clear() {
context.remove();
}
}四:切换注解和 Aop 配置
首先我们来定义一个@DataSourceSwitcher 注解,拥有两个属性
① 当前的数据源② 是否清除当前的数据源,并且只能放在方法上,(不可以放在类上,也没必要放在类上,因为我们在进行数据源切换的时候肯定是方法操作),该注解的主要作用就是进行数据源的切换,在 dao 层进行操作数据库的时候,可以在方法上注明表示的是当前使用哪个数据源。
@DataSourceSwitcher 注解的定义:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface DataSourceSwitcher {
/**
* 默认数据源
* @return
*/
DataSourceEnum value() default DataSourceEnum.MASTER;
/**
* 清除
* @return
*/
boolean clear() default true;
}DataSourceAop配置:
为了赋予@DataSourceSwitcher 注解能够切换数据源的能力,我们需要使用 AOP,然后使用@Aroud 注解找到方法上有@DataSourceSwitcher.class 的方法,然后取注解上配置的数据源的值,设置到 DataSourceContextHolder 中,就实现了将当前方法上配置的数据源注入到全局作用域当中。
@Slf4j
@Aspect
@Order(value = 1)
@Component
public class DataSourceContextAop {
@Around("@annotation(com.wyq.mysqlreadwriteseparate.annotation.DataSourceSwitcher)")
public Object setDynamicDataSource(ProceedingJoinPoint pjp) throws Throwable {
boolean clear = false;
try {
Method method = this.getMethod(pjp);
DataSourceSwitcher dataSourceSwitcher = method.getAnnotation(DataSourceSwitcher.class);
clear = dataSourceSwitcher.clear();
DataSourceContextHolder.set(dataSourceSwitcher.value().getDataSourceName());
log.info("数据源切换至:{}", dataSourceSwitcher.value().getDataSourceName());
return pjp.proceed();
} finally {
if (clear) {
DataSourceContextHolder.clear();
}
}
}
private Method getMethod(JoinPoint pjp) {
MethodSignature signature = (MethodSignature) pjp.getSignature();
return signature.getMethod();
}
}五:用法以及测试
在配置好了读写分离之后,就可以在代码中使用了,一般而言我们使用在 service 层或者 dao 层,在需要查询的方法上添加@DataSourceSwitcher(DataSourceEnum.SLAVE),它表示该方法下所有的操作都走的是读库。在需要 update 或者 insert 的时候使用@DataSourceSwitcher(DataSourceEnum.MASTER)表示接下来将会走写库。
其实还有一种更为自动的写法,可以根据方法的前缀来配置 AOP 自动切换数据源,比如 update、insert、fresh 等前缀的方法名一律自动设置为写库。select、get、query 等前缀的方法名一律配置为读库,这是一种更为自动的配置写法。缺点就是方法名需要按照 aop 配置的严格来定义,否则就会失效。
@Service
public class OrderService {
@Resource
private OrderMapper orderMapper;
/**
* 读操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.SLAVE)
public List<Order> getOrder(String orderId) {
return orderMapper.listOrders(orderId);
}
/**
* 写操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.MASTER)
public List<Order> insertOrder(Long orderId) {
Order order = new Order();
order.setOrderId(orderId);
return orderMapper.saveOrder(order);
}
}六:总结
还是画张图来简单总结一下:
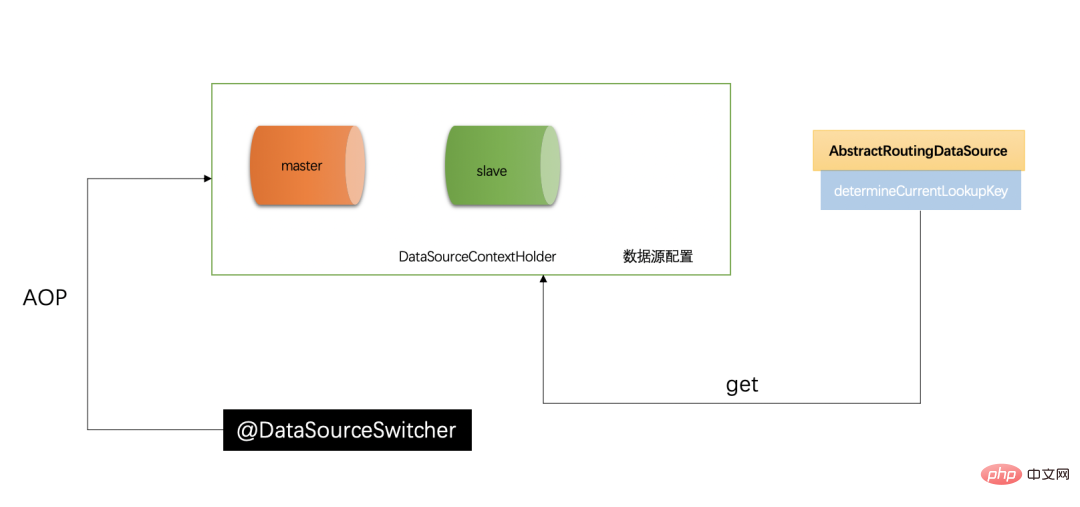
Artikel ini memperkenalkan cara melaksanakan pemisahan baca-tulis pangkalan data Ambil perhatian bahawa titik teras pemisahan baca-tulis ialah penghalaan data, yang perlu diwarisi AbstractRoutingDataSource,复写它的 determineCurrentLookupKey ()方法。同时需要注意全局的上下文管理器 DataSourceContextHolder ialah kelas utama yang menyimpan konteks sumber data dan juga nilai sumber data yang terdapat dalam kaedah penghalaan. Ia bersamaan dengan stesen pemindahan untuk sumber data, dan digabungkan dengan lapisan bawah jdbc-Template untuk mencipta dan mengurus sumber data, urus niaga, dll., pemisahan baca-tulis pangkalan data kami direalisasikan dengan sempurna.
Atas ialah kandungan terperinci Spring Boot melaksanakan teknologi pemisahan baca-tulis MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 MySQL: Kemudahan Pengurusan Data untuk Pemula
Apr 09, 2025 am 12:07 AM
MySQL: Kemudahan Pengurusan Data untuk Pemula
Apr 09, 2025 am 12:07 AM
MySQL sesuai untuk pemula kerana mudah dipasang, kuat dan mudah untuk menguruskan data. 1. Pemasangan dan konfigurasi mudah, sesuai untuk pelbagai sistem operasi. 2. Menyokong operasi asas seperti membuat pangkalan data dan jadual, memasukkan, menanyakan, mengemas kini dan memadam data. 3. Menyediakan fungsi lanjutan seperti menyertai operasi dan subqueries. 4. Prestasi boleh ditingkatkan melalui pengindeksan, pengoptimuman pertanyaan dan pembahagian jadual. 5. Sokongan sokongan, pemulihan dan langkah keselamatan untuk memastikan keselamatan data dan konsistensi.
 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Buat pangkalan data menggunakan Navicat Premium: Sambungkan ke pelayan pangkalan data dan masukkan parameter sambungan. Klik kanan pada pelayan dan pilih Buat Pangkalan Data. Masukkan nama pangkalan data baru dan set aksara yang ditentukan dan pengumpulan. Sambung ke pangkalan data baru dan buat jadual dalam penyemak imbas objek. Klik kanan di atas meja dan pilih masukkan data untuk memasukkan data.
 Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Anda boleh membuat sambungan MySQL baru di Navicat dengan mengikuti langkah -langkah: Buka aplikasi dan pilih Sambungan Baru (Ctrl N). Pilih "MySQL" sebagai jenis sambungan. Masukkan nama host/alamat IP, port, nama pengguna, dan kata laluan. (Pilihan) Konfigurasikan pilihan lanjutan. Simpan sambungan dan masukkan nama sambungan.
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Cara Melaksanakan SQL di Navicat
Apr 08, 2025 pm 11:42 PM
Cara Melaksanakan SQL di Navicat
Apr 08, 2025 pm 11:42 PM
Langkah -langkah untuk melaksanakan SQL di Navicat: Sambungkan ke pangkalan data. Buat tetingkap editor SQL. Tulis pertanyaan SQL atau skrip. Klik butang Run untuk melaksanakan pertanyaan atau skrip. Lihat hasilnya (jika pertanyaan dilaksanakan).
 Navicat menyambung ke kod ralat dan penyelesaian pangkalan data
Apr 08, 2025 pm 11:06 PM
Navicat menyambung ke kod ralat dan penyelesaian pangkalan data
Apr 08, 2025 pm 11:06 PM
Kesilapan dan penyelesaian yang biasa apabila menyambung ke pangkalan data: Nama pengguna atau kata laluan (ralat 1045) Sambungan blok firewall (ralat 2003) Timeout sambungan (ralat 10060)
