
 pangkalan data
SQL
Pangkalan data dibahagikan kepada pangkalan data dan jadual Bilakah? Bagaimana untuk membahagikan?
pangkalan data
SQL
Pangkalan data dibahagikan kepada pangkalan data dan jadual Bilakah? Bagaimana untuk membahagikan?
Pangkalan data dibahagikan kepada pangkalan data dan jadual Bilakah? Bagaimana untuk membahagikan?
1. Segmentasi Data
Pangkalan data perhubungan itu sendiri lebih berkemungkinan menjadi kesesakan sistem, dan kapasiti penyimpanan, bilangan sambungan dan keupayaan mesin tunggal adalah terhad. Apabila volum data satu jadual mencapai 1000W atau 100G, disebabkan bilangan dimensi pertanyaan yang banyak, walaupun pangkalan data hamba ditambah dan indeks dioptimumkan, prestasi masih akan menurun dengan teruk apabila melakukan banyak operasi. Pada masa ini, adalah perlu untuk mempertimbangkan membahagikannya. Tujuan pembahagian adalah untuk mengurangkan beban pada pangkalan data dan memendekkan masa pertanyaan.
1000W atau 100G boleh dikatakan sebagai nilai rujukan industri Perincian bergantung kepada kemudahan perkakasan sistem semasa, reka bentuk struktur meja dan faktor lain.
Kandungan teras pengedaran pangkalan data tidak lebih daripada pembahagian data (Sharding), serta kedudukan dan penyepaduan data selepas pembahagian. Segmentasi data adalah untuk menyimpan data secara berselerak dalam berbilang pangkalan data, menjadikan jumlah data dalam pangkalan data tunggal lebih kecil Dengan memperluaskan bilangan hos, masalah prestasi pangkalan data tunggal dapat dikurangkan, dengan itu mencapai tujuan untuk meningkatkan prestasi operasi pangkalan data.
Segmentasi data boleh dibahagikan kepada dua cara mengikut jenis segmentasinya: segmentasi menegak (menegak) dan segmentasi mendatar (mendatar)
1. Segmen menegak (menegak)
Segmentasi menegak Terdapat dua jenis biasa: sub-perpustakaan menegak dan sub-jadual menegak.
Sharding menegak adalah untuk menyimpan jadual berbeza dengan korelasi rendah dalam pangkalan data berbeza berdasarkan gandingan perniagaan. Pendekatan ini serupa dengan membahagikan sistem besar kepada berbilang sistem kecil, yang dibahagikan secara bebas mengikut klasifikasi perniagaan. Sama seperti pendekatan "tadbir urus perkhidmatan mikro", setiap perkhidmatan mikro menggunakan pangkalan data yang berasingan. Seperti yang ditunjukkan dalam gambar:
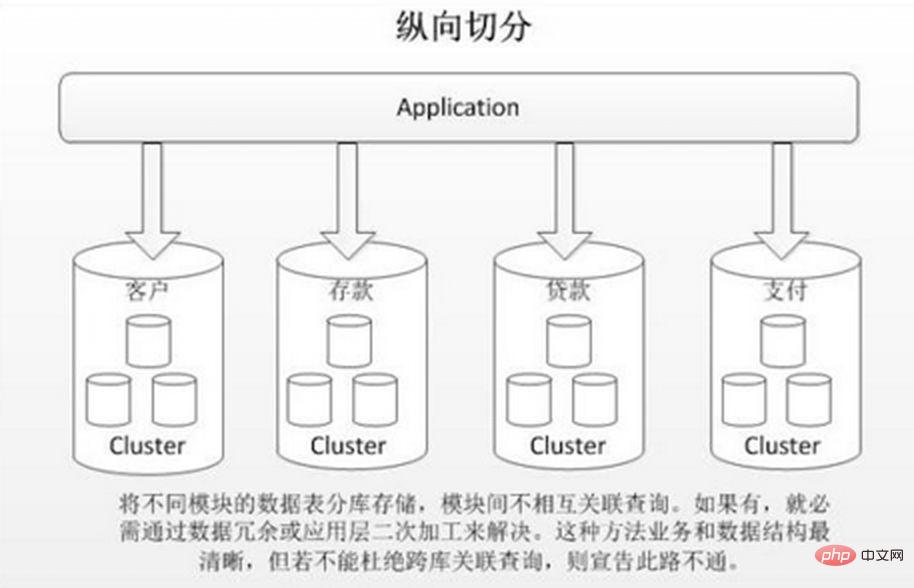
Pemisahan jadual menegak adalah berdasarkan "lajur" dalam pangkalan data Jika jadual mempunyai banyak medan, anda boleh membuat jadual sambungan baharu dan membahagikan medan yang tidak kerap digunakan atau mempunyai panjang medan yang besar kepada lanjutan. meja. Apabila terdapat banyak medan (contohnya, jadual besar mempunyai lebih daripada 100 medan), "memecahkan jadual besar kepada jadual kecil" adalah lebih mudah untuk dibangunkan dan diselenggara, dan juga boleh mengelakkan masalah silang halaman Lapisan bawah MySQL adalah disimpan melalui halaman data Rakaman yang mengambil terlalu banyak ruang akan membawa kepada persilangan halaman, menyebabkan overhed prestasi tambahan. Di samping itu, pangkalan data memuatkan data ke dalam memori dalam unit baris, supaya panjang medan dalam jadual lebih pendek dan kekerapan akses lebih tinggi Memori boleh memuatkan lebih banyak data, kadar pukulan lebih tinggi, dan cakera IO adalah dikurangkan, dengan itu meningkatkan prestasi pangkalan data. . data perniagaan yang berbeza, pengembangan, dsb. 3. Dalam senario konkurensi tinggi, segmentasi menegak akan meningkatkan kesesakan IO, sambungan pangkalan data dan sumber perkakasan mesin tunggal ke tahap tertentu
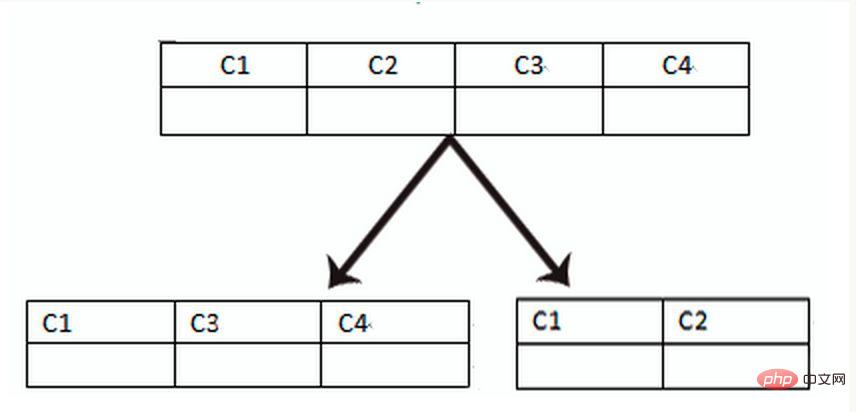
Apabila aplikasi sukar Tidak kira betapa halus segmentasi menegak, atau bilangan baris data selepas pembahagian adalah besar, akan terdapat satu kesesakan prestasi membaca, menulis dan storan pangkalan data Pada masa ini, pembahagian mendatar diperlukan.
Sharding mendatar dibahagikan kepada sharding intra-database dan sub-database sharding Berdasarkan hubungan logik inheren data dalam jadual, jadual yang sama tersebar ke dalam beberapa pangkalan data atau berbilang jadual mengikut keadaan yang berbeza Sahaja sebahagian daripada data disertakan, sekali gus mengurangkan jumlah data dalam satu jadual dan mencapai kesan teragih. Seperti yang ditunjukkan dalam rajah:
Pecahan dalam pangkalan data hanya menyelesaikan masalah volum data yang berlebihan dalam satu jadual, tetapi tidak mengedarkan jadual ke perpustakaan pada mesin yang berbeza, jadi ia berguna untuk mengurangkan tekanan pada pangkalan data MySQL , ia tidak begitu membantu Semua orang masih bersaing untuk CPU, memori, dan rangkaian IO mesin fizikal yang sama. Kebaikan sharding mendatar:
1. Tiada kesesakan prestasi yang disebabkan oleh volum data yang berlebihan dan konkurensi yang tinggi dalam satu pangkalan data, yang meningkatkan kestabilan sistem dan kapasiti beban 2. Transformasi sisi aplikasi adalah kecil dan tiada perlu bahagikan modul bisnes
Kelemahan:
1. Sukar untuk memastikan konsistensi urus niaga merentas serpihan 2. Prestasi pertanyaan gabungan silang pangkalan data adalah sukar dan jumlah penyelenggaraan adalah besar muncul dalam pelbagai pangkalan data / jadual, kandungan setiap perpustakaan/jadual adalah berbeza. Beberapa peraturan pemecahan data biasa ialah:
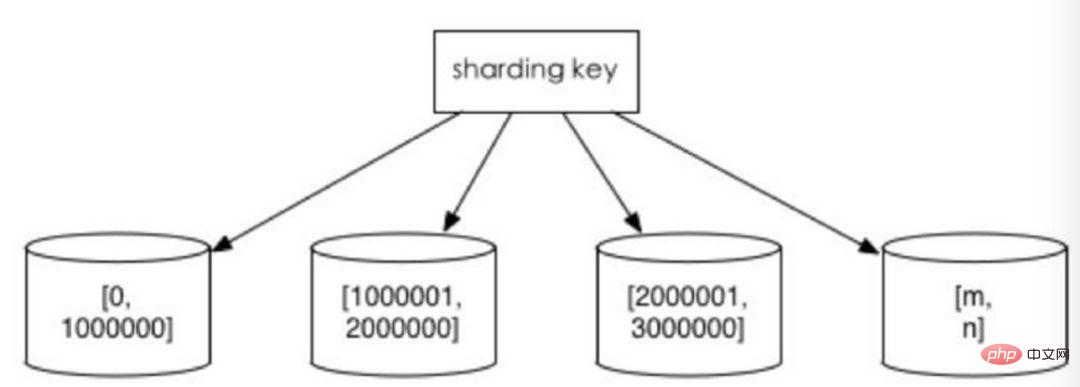
1. Pisahkan mengikut julat nilai mengikut selang masa atau selang ID. Sebagai contoh: mengedarkan data bulan atau hari yang berbeza ke dalam perpustakaan yang berbeza mengikut tarikh; tetapkan rekod dengan userId dari 1 hingga 9999 ke pustaka pertama, rekod dengan userId dari 10000 hingga 20000 ke pustaka kedua, dan seterusnya. Dari satu segi, "pemisahan data panas dan sejuk" yang digunakan dalam sesetengah sistem, memindahkan beberapa data sejarah yang kurang digunakan ke perpustakaan lain dan hanya menyediakan pertanyaan data panas dalam fungsi perniagaan, adalah amalan yang serupa.
Kelebihan ini adalah:
1 Saiz satu meja boleh dikawal 2. Ia secara semula jadi mudah untuk mengembangkan secara mendatar, anda hanya perlu menambah nod tidak perlu memindahkan data serpihan lain 3. Apabila menggunakan medan serpihan untuk carian julat, serpihan berterusan boleh mencari serpihan dengan cepat untuk pertanyaan pantas, dengan berkesan mengelakkan masalah pertanyaan serpihan.
Kelemahan: Data hotspot menjadi hambatan prestasi. Perkongsian berterusan mungkin mempunyai titik liputan data, seperti serpihan mengikut medan masa Beberapa serpihan menyimpan data dalam tempoh masa terkini dan mungkin kerap dibaca dan ditulis, manakala beberapa serpihan menyimpan data sejarah yang jarang ditanya
2. Ambil modulo berdasarkan nilai berangka Secara amnya gunakan kaedah pemisahan mod modulo cincang, contohnya: bahagikan jadual Pelanggan kepada 4 perpustakaan berdasarkan medan cusno, dan letakkan yang mempunyai baki 0. Pergi ke perpustakaan pertama, letakkan baki dengan 1 di perpustakaan kedua, dan seterusnya. Dengan cara ini, data pengguna yang sama akan bertaburan ke dalam pangkalan data yang sama Jika keadaan pertanyaan mengandungi medan cusno, pangkalan data yang sepadan boleh diletakkan dengan jelas untuk pertanyaan.
Kelebihan: Pemecahan data secara relatifnya, dan ia tidak terdedah kepada titik panas dan kesesakan akses serentak
Keburukan:
1 algoritma cincang yang konsisten Boleh mengelakkan masalah ini dengan lebih baik) 2. Mudah untuk menghadapi masalah kompleks pertanyaan silang serpihan. Sebagai contoh, dalam contoh di atas, jika cusno tidak termasuk dalam keadaan pertanyaan yang kerap digunakan, pangkalan data tidak akan ditempatkan Oleh itu, adalah perlu untuk memulakan pertanyaan kepada empat perpustakaan pada masa yang sama, kemudian menggabungkan data dalam memori. , ambil set minimum dan kembalikan kepada aplikasi Sebaliknya, perpustakaan menjadi seret.
. dan menembusi rangkaian IO dan perkakasan Kesesakan sumber dan bilangan sambungan juga membawa beberapa masalah. Cabaran teknikal dan penyelesaian yang sepadan ini diterangkan di bawah. 1. Masalah ketekalan transaksi Transaksi silang serpihan juga merupakan urus niaga yang diedarkan, dan tiada penyelesaian mudah Secara amnya, "protokol XA" dan "komit dua fasa" boleh digunakan untuk mengendalikannya.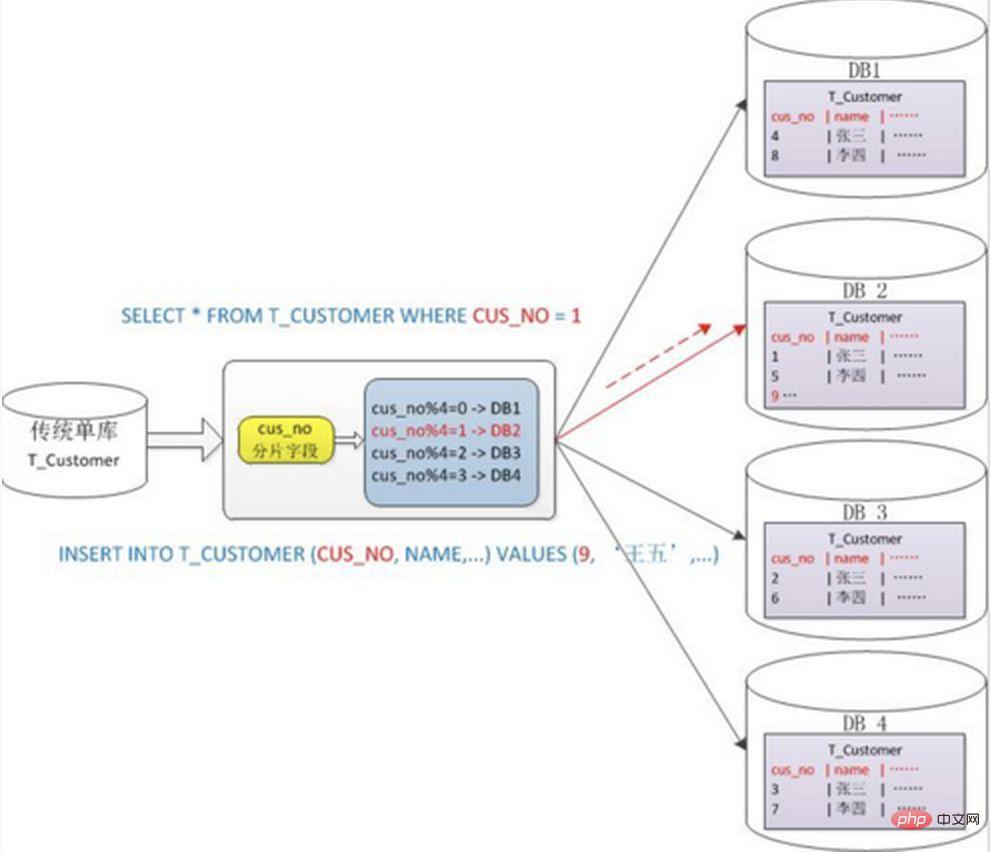 Urus niaga yang diedarkan boleh memastikan keatoman operasi pangkalan data ke tahap yang terbaik. Walau bagaimanapun, apabila menyerahkan transaksi, berbilang nod perlu diselaraskan, yang melambatkan titik masa menyerahkan transaksi dan memanjangkan masa pelaksanaan transaksi. Ini membawa kepada peningkatan kebarangkalian konflik atau kebuntuan apabila transaksi mengakses sumber yang dikongsi. Apabila bilangan nod pangkalan data meningkat, trend ini akan menjadi lebih dan lebih serius, sekali gus menjadi belenggu untuk pengembangan mendatar sistem pada peringkat pangkalan data.
Urus niaga yang diedarkan boleh memastikan keatoman operasi pangkalan data ke tahap yang terbaik. Walau bagaimanapun, apabila menyerahkan transaksi, berbilang nod perlu diselaraskan, yang melambatkan titik masa menyerahkan transaksi dan memanjangkan masa pelaksanaan transaksi. Ini membawa kepada peningkatan kebarangkalian konflik atau kebuntuan apabila transaksi mengakses sumber yang dikongsi. Apabila bilangan nod pangkalan data meningkat, trend ini akan menjadi lebih dan lebih serius, sekali gus menjadi belenggu untuk pengembangan mendatar sistem pada peringkat pangkalan data. Bagi sistem yang mempunyai keperluan prestasi tinggi tetapi keperluan konsistensi rendah, konsistensi masa nyata sistem selalunya tidak diperlukan, selagi konsistensi akhir dicapai dalam tempoh masa yang dibenarkan , transaksi pampasan boleh digunakan. Berbeza daripada kaedah melancarkan urus niaga serta-merta selepas ralat berlaku semasa pelaksanaan, pampasan urus niaga ialah semakan bedah siasat dan langkah pemulihan Beberapa kaedah pelaksanaan biasa termasuk: penyemakan penyelarasan data, perbandingan berdasarkan log dan perbandingan biasa dengan standard sumber data. Pampasan transaksi juga harus dipertimbangkan bersama-sama dengan sistem perniagaan.
2. Masalah sambung pertanyaan berkaitan nod silangJadual global juga boleh dianggap sebagai "jadual kamus data", iaitu beberapa jadual yang mungkin bergantung pada semua modul dalam sistem untuk mengelakkan pertanyaan sambung silang pangkalan data boleh menyimpan salinan jadual jenis ini dalam setiap pangkalan data. Data ini biasanya jarang diubah suai, jadi tidak perlu risau tentang isu konsistensi.
2) Lebihan medan
Reka bentuk anti-paradigma tipikal yang menggunakan ruang untuk masa dan mengelakkan pertanyaan penyertaan untuk prestasi. Contohnya: apabila jadual pesanan menyimpan userId, ia juga menyimpan salinan berlebihan nama pengguna, supaya apabila menanya butiran pesanan, tidak perlu menanyakan "jadual pengguna pembeli".
Walau bagaimanapun, kaedah ini mempunyai senario terpakai yang terhad, dan lebih sesuai untuk situasi di mana terdapat sedikit medan bergantung. Konsistensi data medan berlebihan juga sukar dipastikan Sama seperti contoh jadual pesanan di atas, selepas pembeli mengubah suai Nama pengguna, adakah ia perlu dikemas kini secara serentak dalam pesanan sejarah? Ini juga harus dipertimbangkan bersama-sama dengan senario perniagaan sebenar.
3) Pemasangan data
Di peringkat sistem, terdapat dua pertanyaan Hasil pertanyaan pertama memfokuskan pada mencari ID data yang berkaitan, dan kemudian memulakan permintaan kedua berdasarkan ID untuk mendapatkan yang berkaitan. data. Akhir sekali, data yang diperoleh dikumpulkan ke dalam medan.
4) ER sharding
Dalam pangkalan data relasional, jika anda boleh terlebih dahulu menentukan hubungan antara jadual dan menyimpan rekod jadual yang berkaitan pada serpihan yang sama, maka lebih baik Untuk mengelakkan masalah cantuman rentas serpihan. Dalam kes 1:1 atau 1:n, ia biasanya dibahagikan mengikut kunci utama ID jadual utama. Seperti yang ditunjukkan dalam rajah di bawah:
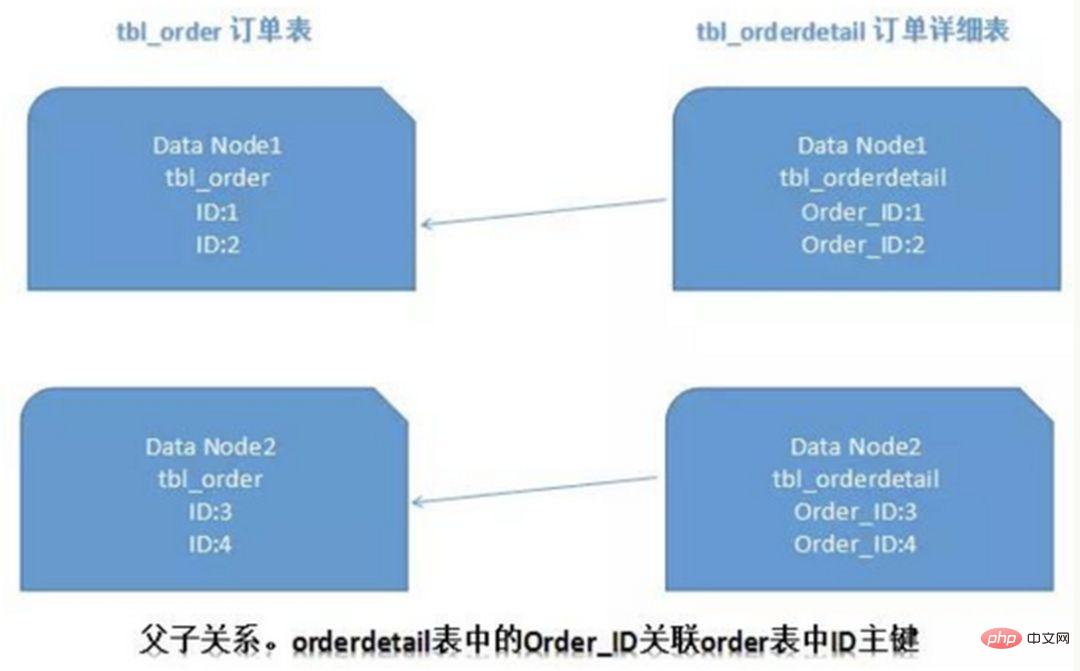
Dengan cara ini, jadual pesanan pesanan dan jadual butiran pesanan butiran pada Data Node1 boleh sebahagiannya berkaitan dengan pertanyaan melalui orderId, dan perkara yang sama berlaku pada Data Node2.
3. Isu kelui silang nod, pengisihan dan fungsi
Apabila menanyakan berbilang pangkalan data merentas nod, masalah seperti hadkan halaman dan susunan mengikut isihan akan berlaku. Paging perlu diisih mengikut medan yang ditentukan Apabila medan pengisihan adalah medan pengisihan, ia menjadi lebih rumit untuk mencari serpihan yang ditentukan; Data perlu diisih dan dikembalikan dalam nod serpihan yang berbeza dahulu, dan kemudian set hasil yang dikembalikan oleh serpihan berbeza diringkaskan dan diisih semula, dan akhirnya dikembalikan kepada pengguna. Seperti yang ditunjukkan dalam gambar:
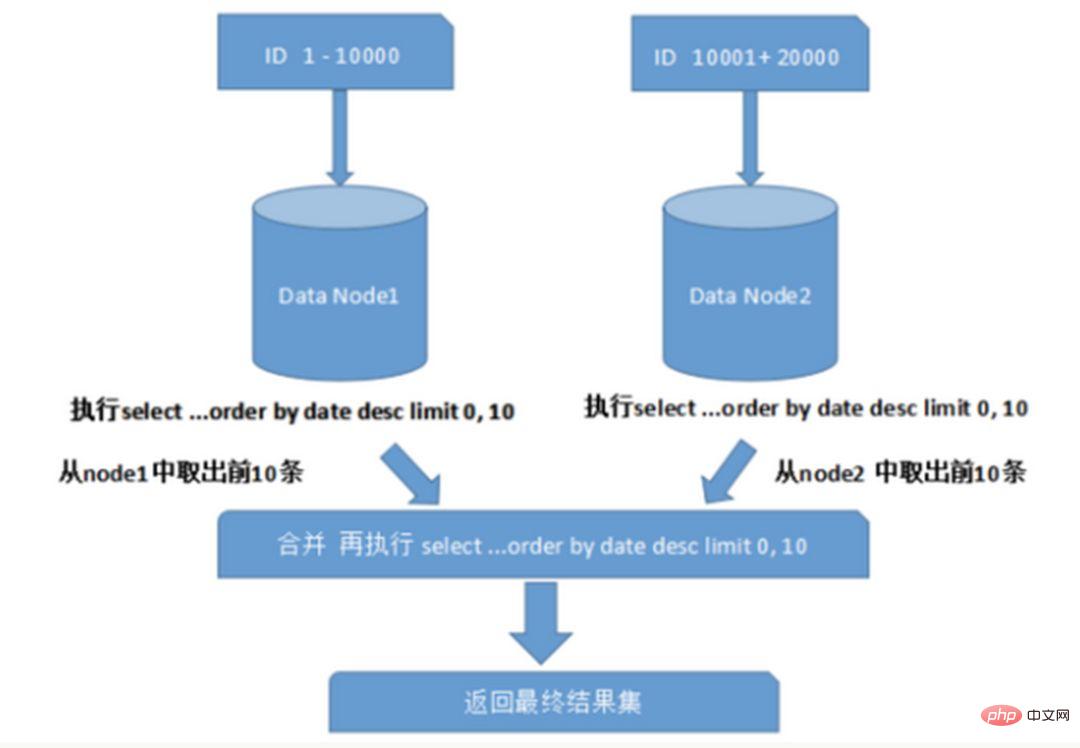
Gambar di atas hanya mengambil data dari halaman pertama, yang tidak memberi impak yang besar terhadap prestasi. Walau bagaimanapun, jika bilangan halaman yang diperoleh adalah sangat besar, keadaan menjadi lebih rumit, kerana data dalam setiap nod serpihan mungkin rawak Untuk ketepatan pengisihan, N halaman pertama data semua nod perlu diisih dan Digabungkan Akhirnya, Kemudian lakukan pengisihan keseluruhan Operasi sedemikian menggunakan sumber CPU dan memori, jadi semakin besar bilangan halaman, semakin teruk prestasi sistem.
Apabila menggunakan fungsi seperti Max, Min, Sum dan Count untuk pengiraan, anda juga perlu melaksanakan fungsi yang sepadan pada setiap shard terlebih dahulu, kemudian meringkaskan set hasil setiap shard dan mengira sekali lagi, dan akhirnya keputusan kembali. Seperti yang ditunjukkan dalam gambar:
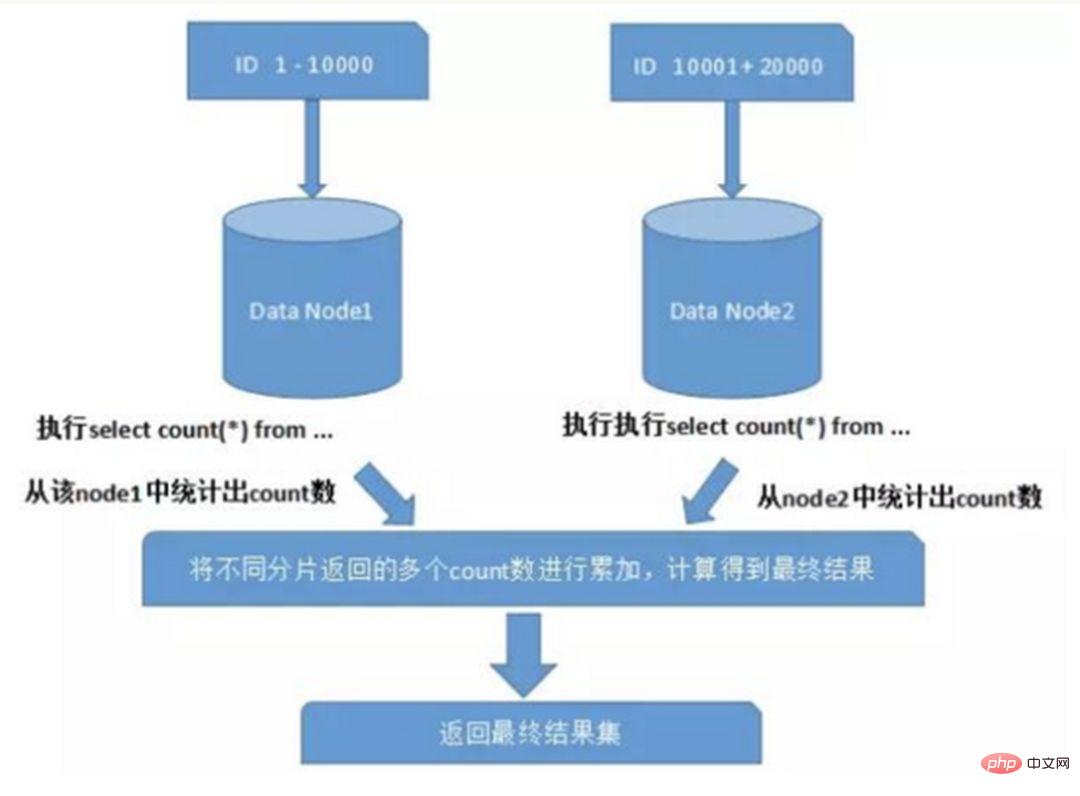
4. Masalah pengelakan kunci utama global
Dalam persekitaran sub-pangkalan data dan sub-jadual, memandangkan data dalam jadual wujud dalam pangkalan data yang berbeza pada masa yang sama, auto- biasa kenaikan nilai kunci primer tidak akan berguna, ID yang dijana oleh pangkalan data partition tertentu tidak boleh dijamin unik di peringkat global. Oleh itu, adalah perlu untuk mereka bentuk kunci utama global secara berasingan untuk mengelakkan pertindihan kunci utama merentas pangkalan data. Terdapat beberapa strategi penjanaan kunci primer biasa:
1) UUID
Borang piawai UUID mengandungi 32 nombor perenambelasan, dibahagikan kepada 5 segmen, 36 aksara dalam bentuk 8-4-4-4-12 , contohnya : 550e8400-e29b-41d4-a716-446655440000
UUID ialah kunci utama, yang merupakan penyelesaian paling mudah Ia dijana secara tempatan, mempunyai prestasi tinggi dan tidak mempunyai penggunaan masa rangkaian. Tetapi kelemahannya juga jelas kerana UUID adalah sangat panjang, ia akan mengambil banyak ruang penyimpanan Selain itu, akan terdapat masalah prestasi apabila membuat indeks sebagai kunci utama dan pertanyaan berdasarkan indeks gangguan UUID akan menyebabkan perubahan kerap dalam lokasi data , mengakibatkan paging.
2) Digabungkan dengan pangkalan data untuk mengekalkan jadual ID kunci utama
Cipta jadual jujukan dalam pangkalan data:
CREATE TABLE `sequence` ( `id` bigint(20) unsigned NOT NULL auto_increment, `stub` char(1) NOT NULL default '', PRIMARY KEY (`id`), UNIQUE KEY `stub` (`stub`) ) ENGINE=MyISAM;
Medan rintisan ditetapkan sebagai indeks unik Nilai rintisan yang sama hanya mempunyai satu rekod dalam jadual jujukan dan boleh digunakan untuk berbilang jadual pada masa yang sama. Kandungan jadual jujukan adalah seperti berikut:
+-------------------+------+ | id | stub | +-------------------+------+ | 72157623227190423 | a | +-------------------+------+
Gunakan enjin storan MyISAM dan bukannya InnoDB untuk prestasi yang lebih tinggi. MyISAM menggunakan kunci peringkat jadual, dan membaca serta menulis ke jadual adalah bersiri, jadi tidak perlu risau tentang membaca nilai ID yang sama dua kali semasa bersamaan.
Apabila ID 64-bit yang unik secara global diperlukan, laksanakan:
REPLACE INTO sequence (stub) VALUES ('a'); SELECT LAST_INSERT_ID();
Kedua-dua pernyataan ini berada pada tahap Sambungan pilih lastinsertid() mesti berada di bawah sambungan pangkalan data yang sama seperti ganti ke untuk mendapatkan ID baharu yang baru dimasukkan.
Kelebihan menggunakan replace into dan bukannya insert into ialah ia mengelakkan bilangan baris meja yang terlalu banyak dan tidak memerlukan pembersihan biasa.
Penyelesaian ini agak mudah, tetapi kelemahannya juga jelas: terdapat satu titik masalah dan ia sangat bergantung pada DB Apabila DB tidak normal, keseluruhan sistem tidak akan tersedia. Mengkonfigurasi master-slave boleh meningkatkan ketersediaan, tetapi apabila pangkalan data induk gagal dan menukar master-slave, ketekalan data sukar untuk dijamin dalam keadaan khusus. Di samping itu, kesesakan prestasi terhad kepada prestasi baca dan tulis MySQL tunggal.
Strategi penjanaan kunci utama yang digunakan oleh pasukan flickr adalah serupa dengan penyelesaian jadual jujukan di atas, tetapi lebih baik menyelesaikan masalah titik tunggal dan kesesakan prestasi.
Idea keseluruhan penyelesaian ini adalah untuk mewujudkan lebih daripada 2 pelayan penjana ID global, menggunakan hanya satu pangkalan data pada setiap pelayan dan setiap pangkalan data mempunyai jadual jujukan untuk merekodkan ID global semasa. Saiz langkah pertumbuhan ID dalam jadual ialah bilangan perpustakaan, dan nilai permulaan disusun mengikut urutan, supaya penjanaan ID boleh dicincang ke setiap pangkalan data. Seperti yang ditunjukkan dalam gambar di bawah:
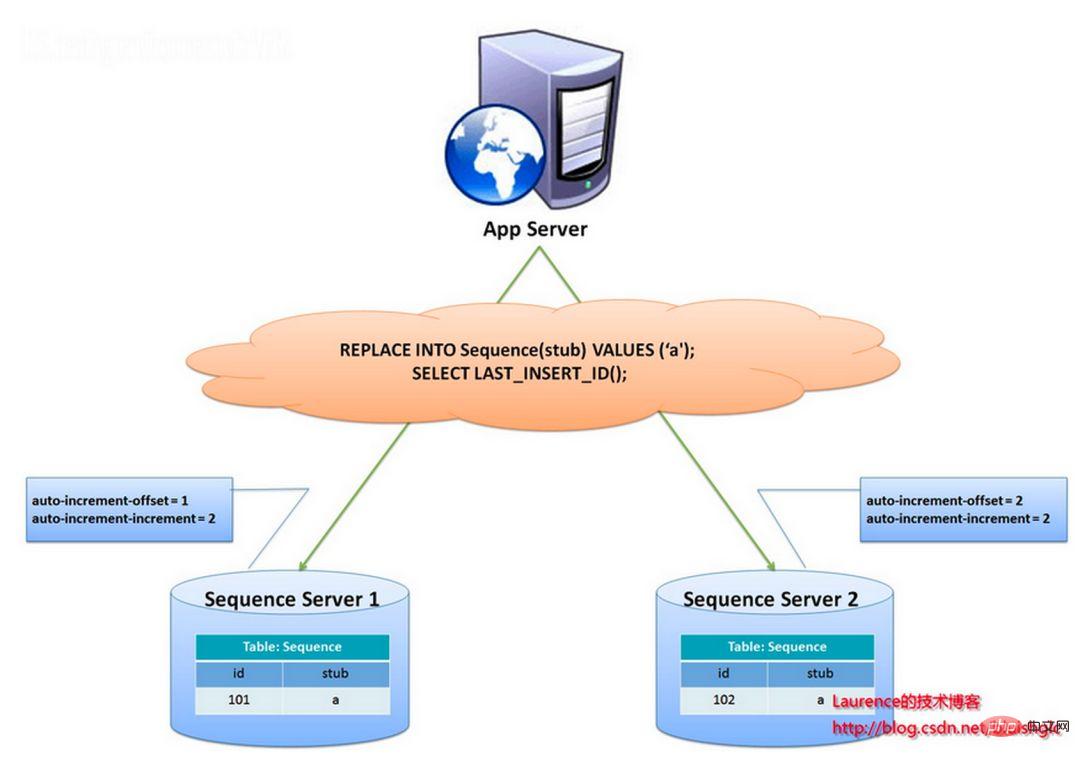
ID dijana oleh dua pelayan pangkalan data dan nilai auto_increment berbeza ditetapkan. Nilai permulaan jujukan pertama ialah 1, dan setiap langkah meningkat sebanyak 2. Nilai permulaan jujukan yang lain ialah 2, dan setiap langkah meningkat sebanyak 2. Akibatnya, ID yang dijana oleh stesen pertama adalah semua nombor ganjil (1, 3, 5, 7...), dan ID yang dijana oleh stesen kedua ialah semua nombor genap (2, 4, 6, 8.. .).
Penyelesaian ini mengagihkan tekanan menjana ID pada kedua-dua mesin secara sama rata. Ia juga menyediakan toleransi kerosakan sistem Jika ralat berlaku pada mesin pertama, ia boleh bertukar secara automatik ke mesin kedua untuk mendapatkan ID. Walau bagaimanapun, ia mempunyai kelemahan berikut: apabila menambah mesin ke sistem, pengembangan mendatar adalah lebih rumit setiap kali ID diperoleh, DB perlu dibaca dan ditulis Tekanan pada DB masih sangat tinggi, dan prestasinya hanya boleh diperbaiki dengan bergantung pada mesin timbunan.
Anda boleh terus mengoptimumkan berdasarkan penyelesaian flickr, menggunakan kaedah kelompok untuk mengurangkan tekanan penulisan pangkalan data, mendapatkan julat segmen nombor ID setiap kali, dan kemudian pergi ke pangkalan data untuk mendapatkannya selepas digunakan, yang boleh mengurangkan dengan ketara tekanan pada pangkalan data. Seperti yang ditunjukkan dalam rajah di bawah:
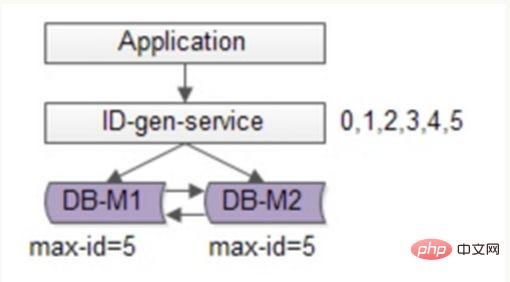
Masih menggunakan dua DB untuk memastikan ketersediaan, hanya ID maksimum semasa disimpan dalam pangkalan data. Perkhidmatan penjanaan ID menarik 6 ID dalam kelompok setiap kali, dan mula-mula menukar maxid kepada 5. Apabila aplikasi mengakses perkhidmatan penjanaan ID, ia tidak perlu mengakses pangkalan data dan ID 0~5 dihantar secara berurutan daripada segmen nombor cache. Selepas ID ini dikeluarkan, tukar maxid kepada 11 dan ID 6~11 boleh diedarkan pada masa akan datang. Akibatnya, tekanan pada pangkalan data dikurangkan kepada 1/6 daripada yang asal.
3) Algoritma ID meningkat sendiri yang diedarkan oleh kepingan salji
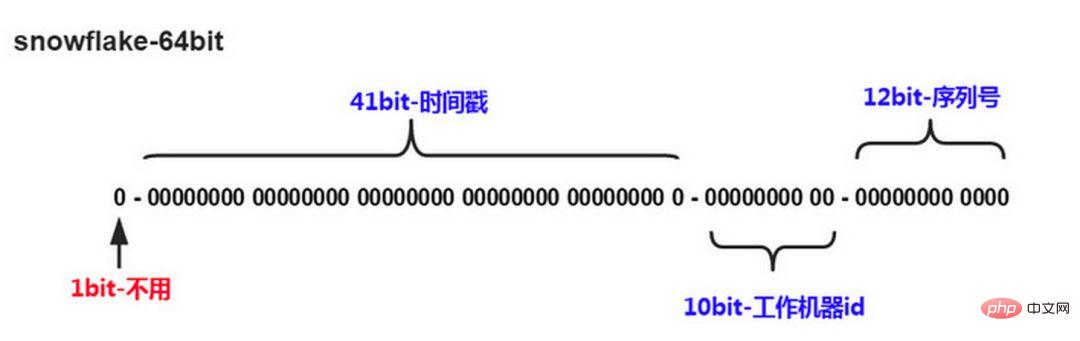
Algoritma kepingan salji Twitter menyelesaikan keperluan sistem teragih untuk menjana ID global dan menjana nombor Panjang 64-bit:
tidak digunakanDigit pertama 41 bit seterusnya ialah masa peringkat milisaat, dan panjang 41 bit boleh mewakili 69 tahun masa
5 digit datacenterId, 5 digit workerId. Panjang 10-bit menyokong penggunaan sehingga 1024 nod
12 bit terakhir dikira dalam milisaat, dan nombor urutan pengiraan 12-bit menyokong setiap nod yang menjana 4096 urutan ID setiap milisaat
Ringkasnya
Menggabungkan pangkalan data dan penyelesaian ID unik kepingan salji, anda boleh merujuk kepada penyelesaian industri yang lebih matang: Leaf - Sistem penjanaan ID teragih Meituan-Dianping, dan mengambil kira ketersediaan tinggi, pemulihan bencana dan penyebaran Jam dan isu-isu lain.
5. Isu migrasi dan pengembangan data
Apabila perniagaan berkembang pesat dan menghadapi kesesakan prestasi dan penyimpanan, reka bentuk sharding akan dipertimbangkan pada masa ini, adalah tidak dapat dielakkan untuk mempertimbangkan isu pemindahan data sejarah. Pendekatan umum ialah membaca data sejarah dahulu, dan kemudian menulis data pada setiap nod serpihan mengikut peraturan sharding yang ditentukan. Di samping itu, perancangan kapasiti perlu dijalankan berdasarkan volum data semasa dan QPS, serta kelajuan pembangunan perniagaan, untuk mengira anggaran bilangan serpihan yang diperlukan (secara amnya disyorkan bahawa volum data satu jadual pada serpihan tunggal tidak melebihi 1000W)
Jika analisis julat berangka digunakan Untuk serpihan, anda hanya perlu menambah nod untuk mengembangkan, dan tidak perlu memindahkan data serpihan. Jika pembahagian modulo berangka digunakan, agak menyusahkan untuk mempertimbangkan isu pengembangan kemudian.
3. Bila hendak mempertimbangkan segmentasi
Mari kita bincangkan tentang masa untuk mempertimbangkan segmentasi data.
1 Cuba jangan berpecah jika boleh
Tidak semua jadual perlu dipecah, ia bergantung terutamanya pada kadar pertumbuhan data. Segmentasi akan meningkatkan kerumitan perniagaan pada tahap tertentu Selain membawa penyimpanan data dan pertanyaan, pangkalan data juga merupakan salah satu tugas pentingnya untuk membantu perniagaan dalam merealisasikan keperluannya dengan lebih baik.
Jangan gunakan helah sub-pangkalan data dan sub-jadual melainkan benar-benar perlu untuk mengelakkan "reka bentuk berlebihan" dan "pengoptimuman pramatang". Sebelum membelah pangkalan data dan jadual, jangan pecahkan hanya untuk pemisahan Cuba yang terbaik untuk melakukan apa yang anda boleh dahulu, seperti menaik taraf perkakasan, menaik taraf rangkaian, memisahkan baca dan tulis, pengoptimuman indeks, dsb. Apabila jumlah data mencapai kesesakan satu jadual, pertimbangkan untuk memecah pangkalan data dan jadual.
2 Jumlah data terlalu besar dan operasi dan penyelenggaraan biasa menjejaskan akses perniagaan
Pengendalian dan penyelenggaraan yang disebut di sini merujuk kepada:
1) Untuk sandaran pangkalan data, jika satu jadual terlalu besar, sejumlah besar cakera IO diperlukan semasa sandaran dan rangkaian IO. Sebagai contoh, jika 1T data dihantar melalui rangkaian dan menduduki 50MB, ia akan mengambil masa 20,000 saat untuk menyelesaikan penghantaran Risiko keseluruhan proses adalah agak tinggi
2) Apabila membuat pengubahsuaian DDL pada jadual besar, MySQL akan. kunci seluruh jadual. Ini akan mengambil masa yang lama Dalam tempoh ini, perniagaan tidak akan dapat mengakses jadual ini, yang akan memberi kesan yang besar. Jika anda menggunakan pt-online-schema-change, pencetus dan jadual bayangan akan dibuat semasa penggunaan, yang juga mengambil masa yang lama. Semasa operasi ini, ia dikira sebagai masa berisiko. Membahagikan jadual data dan mengurangkan jumlah keseluruhan boleh membantu mengurangkan risiko ini.
3)大表会经常访问与更新,就更有可能出现锁等待。将数据切分,用空间换时间,变相降低访问压力
3、随着业务发展,需要对某些字段垂直拆分
举个例子,假如项目一开始设计的用户表如下:
id bigint #用户的IDname varchar #用户的名字last_login_time datetime #最近登录时间personal_info text #私人信息..... #其他信息字段
在项目初始阶段,这种设计是满足简单的业务需求的,也方便快速迭代开发。而当业务快速发展时,用户量从10w激增到10亿,用户非常的活跃,每次登录会更新 lastloginname 字段,使得 user 表被不断update,压力很大。而其他字段:id, name, personalinfo 是不变的或很少更新的,此时在业务角度,就要将 lastlogintime 拆分出去,新建一个 usertime 表。
personalinfo 属性是更新和查询频率较低的,并且text字段占据了太多的空间。这时候,就要对此垂直拆分出 userext 表了。
4、数据量快速增长
随着业务的快速发展,单表中的数据量会持续增长,当性能接近瓶颈时,就需要考虑水平切分,做分库分表了。此时一定要选择合适的切分规则,提前预估好数据容量
5、安全性和可用性
鸡蛋不要放在一个篮子里。在业务层面上垂直切分,将不相关的业务的数据库分隔,因为每个业务的数据量、访问量都不同,不能因为一个业务把数据库搞挂而牵连到其他业务。利用水平切分,当一个数据库出现问题时,不会影响到100%的用户,每个库只承担业务的一部分数据,这样整体的可用性就能提高。
四. 案例分析
1、用户中心业务场景
用户中心是一个非常常见的业务,主要提供用户注册、登录、查询/修改等功能,其核心表为:
User(uid, login_name, passwd, sex, age, nickname) uid为用户ID, 主键login_name, passwd, sex, age, nickname, 用户属性
任何脱离业务的架构设计都是耍流氓,在进行分库分表前,需要对业务场景需求进行梳理:
用户侧:前台访问,访问量较大,需要保证高可用和高一致性。主要有两类需求:
1. Log masuk pengguna: Tanya maklumat pengguna melalui login_name/telefon/e-mel, 1% permintaan tergolong dalam jenis ini 2. Pertanyaan maklumat pengguna: Selepas log masuk, tanya maklumat pengguna melalui uid, 99% permintaan tergolong dalam jenis iniOperasi side : Akses hujung belakang, menyokong keperluan operasi dan melaksanakan pertanyaan halaman berdasarkan umur, jantina, masa log masuk, masa pendaftaran, dsb. Ia adalah sistem dalaman dengan volum capaian rendah dan keperluan rendah pada ketersediaan dan konsistensi.
2. Kaedah segmentasi mendatar
Apabila jumlah data menjadi lebih besar dan lebih besar, pangkalan data perlu dibahagikan secara mendatar Kaedah segmentasi yang diterangkan di atas termasuk "berdasarkan julat berangka" dan "berdasarkan modulo berangka". ".
"Mengikut julat berangka": Berdasarkan uid kunci primer, data dibahagikan secara mendatar kepada berbilang pangkalan data mengikut julat uid. Contohnya: user-db1 menyimpan data dengan julat uid dari 0 hingga 1000w, dan user-db2 menyimpan data dengan julat uid dari 1000w hingga 2000wuid.
Kelebihannya: pengembangan mudah, jika kapasiti tidak mencukupi, tambah db baru.
Kelemahannya ialah : Jumlah permintaan tidak sekata Secara amnya, pengguna yang baru didaftarkan akan menjadi lebih aktif, jadi pengguna-db2 baharu akan mempunyai beban yang lebih tinggi daripada pengguna-db1, mengakibatkan penggunaan pelayan tidak seimbang
"Mengikut kepada Modul nilai berangka ": Uid kunci primer juga digunakan sebagai asas untuk pembahagian, dan data dibahagikan secara mendatar kepada berbilang pangkalan data berdasarkan nilai modulo uid. Contohnya: user-db1 menyimpan uid data modulo 1, user-db2 menyimpan uid data modulo 0.
Kelebihannya ialah : volum data dan volum permintaan diagihkan sama rata
Keburukan ialah : pengembangan menyusahkan Apabila kapasiti tidak mencukupi, menambah db baharu memerlukan pengubahsuaian. Penghijrahan data yang lancar perlu dipertimbangkan.
3. Kaedah pertanyaan bukan uid
Selepas segmentasi mendatar, permintaan untuk pertanyaan oleh uid boleh dipenuhi dengan baik dan boleh dihalakan terus ke pangkalan data tertentu. Untuk pertanyaan berdasarkan bukan-uid, seperti login_name, tidak diketahui perpustakaan mana yang harus diakses Dalam kes ini, semua perpustakaan perlu dilalui, dan prestasi akan dikurangkan dengan banyak.
Untuk bahagian pengguna, penyelesaian "mewujudkan hubungan pemetaan daripada atribut bukan uid kepada uid" boleh diguna pakai untuk bahagian operasi, penyelesaian "memisahkan bahagian depan dan belakang" boleh diguna pakai. . atau cache. Apabila mengakses nama log masuk, tanya dahulu uid yang sepadan dengan login_name melalui jadual pemetaan, dan kemudian cari pustaka tertentu melalui uid.
Jadual pemetaan hanya mempunyai dua lajur dan boleh membawa banyak data Apabila jumlah data terlalu besar, jadual pemetaan juga boleh dibahagikan secara mendatar. Jenis struktur indeks format kv ini boleh menggunakan cache untuk mengoptimumkan prestasi pertanyaan, dan hubungan pemetaan tidak akan kerap berubah, dan kadar hit cache akan menjadi sangat tinggi.
2) Kaedah gen
Gen pemecah: Jika perpustakaan dibahagikan kepada 8 perpustakaan melalui uid, dan penghalaan dilakukan menggunakan uid%8, pada masa ini, 3 bit uid terakhir menentukan di mana baris data Pengguna ini jatuh. Perpustakaan mana yang ada di atasnya, maka 3 bit ini boleh dianggap sebagai gen sub-perpustakaan.
Kaedah perhubungan pemetaan di atas memerlukan storan tambahan bagi jadual pemetaan Apabila membuat pertanyaan dengan medan bukan uid, pangkalan data tambahan atau akses cache diperlukan. Jika anda ingin menghapuskan storan dan pertanyaan yang berlebihan, anda boleh menggunakan fungsi f untuk mengambil gen nama log masuk sebagai gen sub-perpustakaan uid. Apabila menjana uid, rujuk kepada skema penjanaan ID unik yang diedarkan yang diterangkan di atas, ditambah dengan tiga nilai bit terakhir = f (nama log masuk). Apabila menanyakan nama log masuk, anda hanya perlu mengira nilai f(loginname)%8 untuk mencari perpustakaan tertentu. Walau bagaimanapun, ini memerlukan perancangan kapasiti terlebih dahulu, menganggarkan bilangan pangkalan data volum data perlu dibahagikan dalam beberapa tahun akan datang, dan menempah bilangan bit gen pangkalan data tertentu. 3.2. Pengasingan soalan meja depan dan meja belakang.
Berdiri di atas bahu gergasi boleh menjimatkan banyak usaha pada masa ini, terdapat beberapa penyelesaian sumber terbuka yang agak matang untuk sub-pangkalan data dan sub -meja:
sharding-jdbc (Dangdang) TSharding (Mogujie) Atlas (Qihoo 360) -
(berdasarkan Cobar) Oceanus ( 58.com) Vitess (Google)
Atas ialah kandungan terperinci Pangkalan data dibahagikan kepada pangkalan data dan jadual Bilakah? Bagaimana untuk membahagikan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
1205
24
52
1205
24

 Bagaimanakah bahasa Go melaksanakan operasi penambahan, pemadaman, pengubahsuaian dan pertanyaan pangkalan data?
Mar 27, 2024 pm 09:39 PM
Bagaimanakah bahasa Go melaksanakan operasi penambahan, pemadaman, pengubahsuaian dan pertanyaan pangkalan data?
Mar 27, 2024 pm 09:39 PM
Bahasa Go ialah bahasa pengaturcaraan yang cekap, ringkas dan mudah dipelajari Ia digemari oleh pembangun kerana kelebihannya dalam pengaturcaraan serentak dan pengaturcaraan rangkaian. Dalam pembangunan sebenar, operasi pangkalan data adalah bahagian yang sangat diperlukan Artikel ini akan memperkenalkan cara menggunakan bahasa Go untuk melaksanakan operasi penambahan, pemadaman, pengubahsuaian dan pertanyaan pangkalan data. Dalam bahasa Go, kami biasanya menggunakan perpustakaan pihak ketiga untuk mengendalikan pangkalan data, seperti pakej sql yang biasa digunakan, gorm, dsb. Di sini kami mengambil pakej sql sebagai contoh untuk memperkenalkan cara melaksanakan operasi penambahan, pemadaman, pengubahsuaian dan pertanyaan pangkalan data. Andaikan kami menggunakan pangkalan data MySQL.
 iOS 18 menambah fungsi album 'Dipulihkan' baharu untuk mendapatkan semula foto yang hilang atau rosak
Jul 18, 2024 am 05:48 AM
iOS 18 menambah fungsi album 'Dipulihkan' baharu untuk mendapatkan semula foto yang hilang atau rosak
Jul 18, 2024 am 05:48 AM
Keluaran terbaharu Apple bagi sistem iOS18, iPadOS18 dan macOS Sequoia telah menambah ciri penting pada aplikasi Photos, yang direka untuk membantu pengguna memulihkan foto dan video yang hilang atau rosak dengan mudah disebabkan pelbagai sebab. Ciri baharu ini memperkenalkan album yang dipanggil "Dipulihkan" dalam bahagian Alat pada apl Foto yang akan muncul secara automatik apabila pengguna mempunyai gambar atau video pada peranti mereka yang bukan sebahagian daripada pustaka foto mereka. Kemunculan album "Dipulihkan" menyediakan penyelesaian untuk foto dan video yang hilang akibat kerosakan pangkalan data, aplikasi kamera tidak disimpan ke pustaka foto dengan betul, atau aplikasi pihak ketiga yang menguruskan pustaka foto. Pengguna hanya memerlukan beberapa langkah mudah
 Bagaimanakah Hibernate melaksanakan pemetaan polimorfik?
Apr 17, 2024 pm 12:09 PM
Bagaimanakah Hibernate melaksanakan pemetaan polimorfik?
Apr 17, 2024 pm 12:09 PM
Pemetaan polimorfik hibernate boleh memetakan kelas yang diwarisi ke pangkalan data dan menyediakan jenis pemetaan berikut: subkelas bercantum: Cipta jadual berasingan untuk subkelas, termasuk semua lajur kelas induk. table-per-class: Cipta jadual berasingan untuk subkelas, yang mengandungi hanya lajur khusus subkelas. union-subclass: serupa dengan joined-subclass, tetapi jadual kelas induk menggabungkan semua lajur subclass.
 Tutorial terperinci tentang mewujudkan sambungan pangkalan data menggunakan MySQLi dalam PHP
Jun 04, 2024 pm 01:42 PM
Tutorial terperinci tentang mewujudkan sambungan pangkalan data menggunakan MySQLi dalam PHP
Jun 04, 2024 pm 01:42 PM
Cara menggunakan MySQLi untuk mewujudkan sambungan pangkalan data dalam PHP: Sertakan sambungan MySQLi (require_once) Cipta fungsi sambungan (functionconnect_to_db) Fungsi sambungan panggilan ($conn=connect_to_db()) Laksanakan pertanyaan ($result=$conn->query()) Tutup sambungan ( $conn->close())
 Apr 09, 2024 pm 12:36 PM
Apr 09, 2024 pm 12:36 PM
HTML tidak boleh membaca pangkalan data secara langsung, tetapi ia boleh dicapai melalui JavaScript dan AJAX. Langkah-langkah termasuk mewujudkan sambungan pangkalan data, menghantar pertanyaan, memproses respons dan mengemas kini halaman. Artikel ini menyediakan contoh praktikal menggunakan JavaScript, AJAX dan PHP untuk membaca data daripada pangkalan data MySQL, menunjukkan cara untuk memaparkan hasil pertanyaan secara dinamik dalam halaman HTML. Contoh ini menggunakan XMLHttpRequest untuk mewujudkan sambungan pangkalan data, menghantar pertanyaan dan memproses respons, dengan itu mengisi data ke dalam elemen halaman dan merealisasikan fungsi HTML membaca pangkalan data.
 Bagaimana untuk mengendalikan ralat sambungan pangkalan data dalam PHP
Jun 05, 2024 pm 02:16 PM
Bagaimana untuk mengendalikan ralat sambungan pangkalan data dalam PHP
Jun 05, 2024 pm 02:16 PM
Untuk mengendalikan ralat sambungan pangkalan data dalam PHP, anda boleh menggunakan langkah berikut: Gunakan mysqli_connect_errno() untuk mendapatkan kod ralat. Gunakan mysqli_connect_error() untuk mendapatkan mesej ralat. Dengan menangkap dan mengelog mesej ralat ini, isu sambungan pangkalan data boleh dikenal pasti dan diselesaikan dengan mudah, memastikan kelancaran aplikasi anda.
 Petua dan amalan untuk mengendalikan aksara Cina bercelaru dalam pangkalan data dengan PHP
Mar 27, 2024 pm 05:21 PM
Petua dan amalan untuk mengendalikan aksara Cina bercelaru dalam pangkalan data dengan PHP
Mar 27, 2024 pm 05:21 PM
PHP ialah bahasa pengaturcaraan bahagian belakang yang digunakan secara meluas dalam pembangunan laman web Ia mempunyai fungsi operasi pangkalan data yang kuat dan sering digunakan untuk berinteraksi dengan pangkalan data seperti MySQL. Walau bagaimanapun, disebabkan kerumitan pengekodan aksara Cina, masalah sering timbul apabila berurusan dengan aksara Cina bercelaru dalam pangkalan data. Artikel ini akan memperkenalkan kemahiran dan amalan PHP dalam mengendalikan aksara bercelaru bahasa Cina dalam pangkalan data, termasuk punca biasa aksara bercelaru, penyelesaian dan contoh kod khusus. Sebab biasa aksara bercelaru ialah tetapan set aksara pangkalan data yang salah: set aksara yang betul perlu dipilih semasa mencipta pangkalan data, seperti utf8 atau u
 Bagaimana untuk menggunakan fungsi panggil balik pangkalan data di Golang?
Jun 03, 2024 pm 02:20 PM
Bagaimana untuk menggunakan fungsi panggil balik pangkalan data di Golang?
Jun 03, 2024 pm 02:20 PM
Menggunakan fungsi panggil balik pangkalan data di Golang boleh mencapai: melaksanakan kod tersuai selepas operasi pangkalan data yang ditentukan selesai. Tambah tingkah laku tersuai melalui fungsi berasingan tanpa menulis kod tambahan. Fungsi panggil balik tersedia untuk operasi memasukkan, mengemas kini, memadam dan pertanyaan. Anda mesti menggunakan fungsi sql.Exec, sql.QueryRow atau sql.Query untuk menggunakan fungsi panggil balik.
