

Analisis mendalam: komponen dan fungsi utama dalam rangka kerja AI LLM


Artikel ini meneroka secara mendalam seni bina peringkat tinggi rangka kerja kecerdasan buatan, menganalisis komponen dalamannya dan fungsinya dalam keseluruhan sistem. Rangka kerja AI ini bertujuan untuk memudahkan untuk menggabungkan perisian tradisional dengan model bahasa besar (LLM).
Tujuan teras adalah untuk menyediakan pembangun satu set alat untuk membantu mereka menyepadukan kecerdasan buatan dengan lancar ke dalam perisian yang telah digunakan dalam syarikat. Strategi inovatif ini telah mencipta platform perisian untuk kami yang boleh menjalankan banyak aplikasi AI dan ejen pintar pada masa yang sama, dengan itu merealisasikan penyelesaian yang lebih canggih dan kompleks.
1. Contoh aplikasi rangka kerja AI
Untuk memahami dengan lebih mendalam tentang keupayaan rangka kerja ini, berikut adalah beberapa contoh aplikasi yang boleh dibangunkan menggunakan rangka kerja ini:
- Pembantu Jualan AI: Ini adalah Alat automatik untuk mencari bakal pelanggan, menganalisis keperluan perniagaan mereka dan merangka cadangan untuk pasukan jualan anda. Pembantu AI sedemikian akan mencari cara yang berkesan untuk menjalin hubungan dengan pelanggan sasaran dan membuka langkah pertama jualan.
- AI Pembantu Penyelidik Hartanah: Alat ini boleh terus memantau penyenaraian baharu dalam pasaran hartanah dan menapis penyenaraian yang layak berdasarkan kriteria yang ditetapkan. Selain itu, ia boleh merangka strategi komunikasi, mengumpul lebih banyak maklumat tentang hartanah tertentu, dan memberikan bantuan kepada pengguna dalam semua aspek pembelian rumah.
- Apl Ringkasan Perbincangan AI ZhihuApl pintar ini seharusnya dapat menganalisis perbincangan tentang Zhihu dan mengeluarkan kesimpulan, tugasan dan langkah seterusnya yang perlu diambil.
2. Modul rangka kerja AI
Rangka kerja AI harus menyediakan satu set modul berbeza kepada pembangun, termasuk definisi kontrak, antara muka dan pelaksanaan abstraksi biasa.
Penyelesaian ini harus menjadi asas yang kukuh di mana anda boleh membina penyelesaian anda sendiri, menggunakan corak yang terbukti, menambah pelaksanaan modul individu anda sendiri atau menggunakan modul yang disediakan komuniti.
- Modul Petunjuk dan Rantaian bertanggungjawab untuk membina pembayang, iaitu program yang ditulis untuk model bahasa, dan rangkaian panggilan ke pembayang ini, yang dilaksanakan satu demi satu mengikut urutan. Modul ini harus memungkinkan untuk melaksanakan pelbagai teknik yang digunakan dalam Model Bahasa (LM) dan Model Bahasa Besar (LLM). Ia juga harus dapat menggabungkan gesaan dengan model dan mencipta kumpulan gesaan yang menyediakan satu fungsi merentas berbilang model LLM.
- Modul model bertanggungjawab untuk memproses dan menyambungkan model LLM kepada perisian, menjadikannya tersedia untuk bahagian lain sistem.
- Modul komunikasi bertanggungjawab untuk mengendalikan dan menambah saluran komunikasi baharu dengan pengguna, sama ada dalam bentuk sembang dalam salah satu program pemesejan atau dalam bentuk API dan webhook untuk penyepaduan dengan sistem lain. Modul
- Tools bertanggungjawab menyediakan kefungsian untuk menambah alatan yang digunakan oleh aplikasi AI, seperti keupayaan untuk membaca kandungan tapak web daripada pautan, membaca fail PDF, mencari maklumat dalam talian atau menghantar e-mel.
- Modul memori harus bertanggungjawab untuk pengurusan memori dan membenarkan untuk menambah pelaksanaan fungsi memori tambahan untuk aplikasi AI, menyimpan keadaan semasa, data dan tugas yang sedang dilaksanakan.
- Modul Pangkalan PengetahuanModul ini harus bertanggungjawab mengurus hak akses dan membenarkan penambahan sumber baharu pengetahuan organisasi, seperti maklumat tentang proses, dokumen, panduan dan semua maklumat yang ditangkap secara elektronik dalam organisasi.
- Modul PenghalaanModul ini harus bertanggungjawab untuk mengalihkan maklumat luaran daripada modul komunikasi ke aplikasi AI yang sesuai. Peranannya adalah untuk menentukan niat pengguna dan melancarkan aplikasi yang betul. Jika aplikasi telah dimulakan sebelum ini dan belum menyelesaikan operasi, ia harus menyambung semula dan menghantar data daripada modul komunikasi.
- Modul Aplikasi AIModul ini sepatutnya membenarkan penambahan aplikasi AI khusus yang memfokuskan pada melaksanakan tugas tertentu, seperti mengautomasikan atau sebahagian proses mengautomasikan. Penyelesaian contoh mungkin ialah aplikasi ringkasan sembang Slack atau Teams. Aplikasi sedemikian mungkin termasuk satu atau lebih gesaan yang dipautkan bersama, menggunakan alatan, memori dan memanfaatkan maklumat daripada pangkalan pengetahuan.
- Modul Ejen AIModul ini harus mengandungi versi aplikasi yang lebih maju yang boleh bercakap secara autonomi kepada model LLM dan melaksanakan tugas yang diberikan secara automatik atau separa automatik.
- Modul Akauntabiliti dan KetelusanModul Akauntabiliti dan Ketelusan merekodkan semua interaksi antara pengguna dan sistem AI. Ia menjejaki pertanyaan, respons, cap masa dan kepengarangan untuk membezakan antara kandungan yang dijana manusia dan yang dijana AI. Log ini memberikan keterlihatan ke dalam tindakan autonomi yang diambil oleh AI dan mesej antara model dan perisian.
- Modul PenggunaSelain kefungsian pengurusan pengguna asas, modul ini juga harus mengekalkan pemetaan akaun pengguna merentas sistem bersepadu daripada modul yang berbeza.
- Modul KebenaranModul ini harus menyimpan maklumat kebenaran pengguna dan mengawal akses pengguna kepada sumber, memastikan mereka hanya boleh mengakses sumber dan aplikasi yang sesuai.
3. Seni bina komponen rangka kerja AI
Untuk menunjukkan interaksi antara modul berbeza dalam seni bina rangka kerja AI, berikut ialah gambaran keseluruhan gambar rajah komponen:
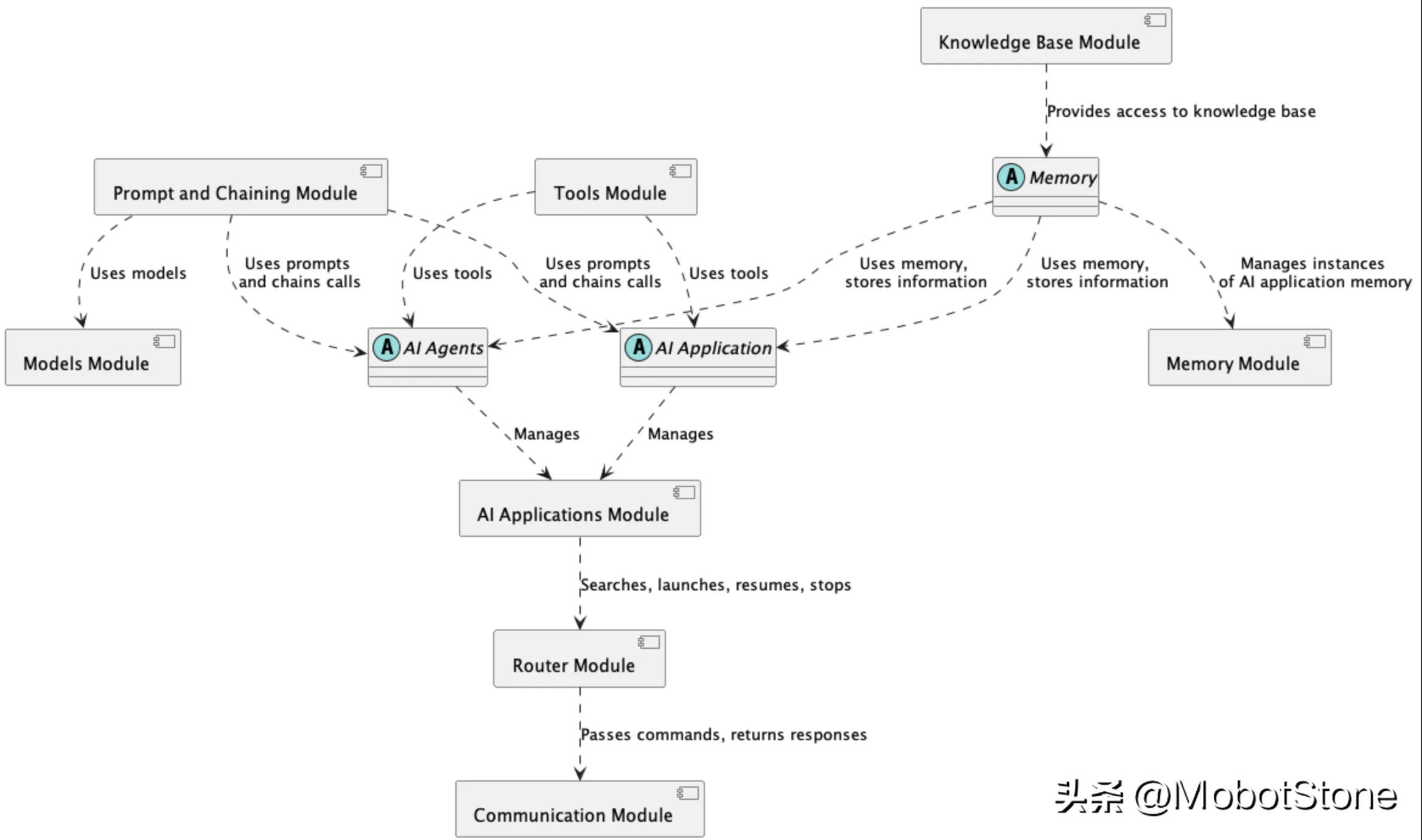
Rajah ini menunjukkan hubungan antara kunci komponen rangka kerja Perhubungan:
- Gesaan dan Modul Berantai: Bina gesaan untuk model AI dan gabungkan berbilang gesaan melalui panggilan berantai untuk mencapai logik yang lebih kompleks.
- Modul memori: Pengurusan memori melalui pengabstrakan memori. Modul asas pengetahuan menyediakan akses kepada sumber pengetahuan.
- Modul alat: Menyediakan alatan yang boleh digunakan oleh aplikasi dan ejen AI.
- Modul Penghalaan: Pertanyaan terus ke aplikasi AI yang sesuai. Aplikasi diuruskan dalam modul aplikasi AI.
- Modul Komunikasi: Mengendalikan saluran komunikasi seperti sembang.
Seni bina komponen ini menunjukkan cara modul berbeza berfungsi bersama-sama untuk memungkinkan untuk membina penyelesaian AI yang kompleks. Reka bentuk modular membolehkan fungsi diperkembangkan dengan mudah dengan menambah komponen baharu.
4. Contoh dinamik modul
Untuk menggambarkan kerjasama antara modul rangka kerja AI, mari analisa laluan pemprosesan maklumat biasa dalam sistem:
- Pengguna menghantar pertanyaan menggunakan fungsi sembang melalui modul komunikasi.
- Modul penghalaan menganalisis kandungan dan menentukan aplikasi AI yang sesuai daripada modul aplikasi.
- Aplikasi mendapatkan semula data yang diperlukan daripada modul storan untuk memulihkan konteks perbualan.
- Seterusnya, ia menggunakan modul Perintah untuk membina arahan yang sesuai dan menghantarnya kepada model AI dari modul Model.
- Jika perlu, ia akan melaksanakan alatan dalam modul Alat, seperti mencari maklumat dalam talian.
- Akhir sekali, ia mengembalikan respons kepada pengguna melalui modul komunikasi.
- Maklumat penting akan disimpan dalam modul storan untuk meneruskan perbualan.
Terima kasih kepada cara kerja ini, modul rangka kerja seharusnya dapat bekerjasama antara satu sama lain untuk membolehkan aplikasi dan ejen AI melaksanakan senario yang kompleks.
5. Ringkasan
Rangka kerja AI harus menyediakan alat yang komprehensif untuk membina sistem berasaskan AI moden. Seni bina modular yang fleksibel seharusnya membolehkan pengembangan fungsi dan penyepaduan dengan mudah dengan perisian sedia ada organisasi. Terima kasih kepada rangka kerja AI, pengaturcara seharusnya dapat mereka bentuk dan melaksanakan pelbagai penyelesaian inovatif dengan cepat menggunakan model bahasa. Dengan modul siap sedia, mereka seharusnya dapat menumpukan pada logik perniagaan dan fungsi aplikasi. Ini membolehkan rangka kerja AI mempercepatkan transformasi digital banyak organisasi dengan ketara.
Atas ialah kandungan terperinci Analisis mendalam: komponen dan fungsi utama dalam rangka kerja AI LLM. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Mengapakah model bahasa besar menggunakan SwiGLU sebagai fungsi pengaktifan?
Apr 08, 2024 pm 09:31 PM
Mengapakah model bahasa besar menggunakan SwiGLU sebagai fungsi pengaktifan?
Apr 08, 2024 pm 09:31 PM
Jika anda telah memberi perhatian kepada seni bina model bahasa yang besar, anda mungkin pernah melihat istilah "SwiGLU" dalam model dan kertas penyelidikan terkini. SwiGLU boleh dikatakan sebagai fungsi pengaktifan yang paling biasa digunakan dalam model bahasa besar Kami akan memperkenalkannya secara terperinci dalam artikel ini. SwiGLU sebenarnya adalah fungsi pengaktifan yang dicadangkan oleh Google pada tahun 2020, yang menggabungkan ciri-ciri SWISH dan GLU. Nama penuh Cina SwiGLU ialah "unit linear berpagar dua arah". Ia mengoptimumkan dan menggabungkan dua fungsi pengaktifan, SWISH dan GLU, untuk meningkatkan keupayaan ekspresi tak linear model. SWISH ialah fungsi pengaktifan yang sangat biasa yang digunakan secara meluas dalam model bahasa besar, manakala GLU telah menunjukkan prestasi yang baik dalam tugas pemprosesan bahasa semula jadi.
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Mar 01, 2024 pm 09:16 PM
Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Mar 01, 2024 pm 09:16 PM
Memandangkan prestasi model bahasa berskala besar sumber terbuka terus bertambah baik, prestasi dalam penulisan dan analisis kod, pengesyoran, ringkasan teks dan pasangan menjawab soalan (QA) semuanya bertambah baik. Tetapi apabila ia berkaitan dengan QA, LLM sering gagal dalam isu yang berkaitan dengan data yang tidak terlatih, dan banyak dokumen dalaman disimpan dalam syarikat untuk memastikan pematuhan, rahsia perdagangan atau privasi. Apabila dokumen ini disoal, LLM boleh berhalusinasi dan menghasilkan kandungan yang tidak relevan, rekaan atau tidak konsisten. Satu teknik yang mungkin untuk menangani cabaran ini ialah Retrieval Augmented Generation (RAG). Ia melibatkan proses meningkatkan respons dengan merujuk pangkalan pengetahuan berwibawa di luar sumber data latihan untuk meningkatkan kualiti dan ketepatan penjanaan. Sistem RAG termasuk sistem mendapatkan semula untuk mendapatkan serpihan dokumen yang berkaitan daripada korpus
 Pengoptimuman LLM menggunakan teknologi SPIN untuk latihan penalaan halus permainan sendiri
Jan 25, 2024 pm 12:21 PM
Pengoptimuman LLM menggunakan teknologi SPIN untuk latihan penalaan halus permainan sendiri
Jan 25, 2024 pm 12:21 PM
2024 ialah tahun pembangunan pesat untuk model bahasa besar (LLM). Dalam latihan LLM, kaedah penjajaran ialah cara teknikal yang penting, termasuk penyeliaan penalaan halus (SFT) dan pembelajaran pengukuhan dengan maklum balas manusia (RLHF) yang bergantung pada pilihan manusia. Kaedah ini telah memainkan peranan penting dalam pembangunan LLM, tetapi kaedah penjajaran memerlukan sejumlah besar data beranotasi secara manual. Menghadapi cabaran ini, penalaan halus telah menjadi bidang penyelidikan yang rancak, dengan para penyelidik giat berusaha untuk membangunkan kaedah yang boleh mengeksploitasi data manusia dengan berkesan. Oleh itu, pembangunan kaedah penjajaran akan menggalakkan lagi kejayaan dalam teknologi LLM. Universiti California baru-baru ini menjalankan kajian yang memperkenalkan teknologi baharu yang dipanggil SPIN (SelfPlayfInetuNing). S
 Menggunakan graf pengetahuan untuk meningkatkan keupayaan model RAG dan mengurangkan tanggapan palsu model besar
Jan 14, 2024 pm 06:30 PM
Menggunakan graf pengetahuan untuk meningkatkan keupayaan model RAG dan mengurangkan tanggapan palsu model besar
Jan 14, 2024 pm 06:30 PM
Halusinasi adalah masalah biasa apabila bekerja dengan model bahasa besar (LLM). Walaupun LLM boleh menjana teks yang lancar dan koheren, maklumat yang dijananya selalunya tidak tepat atau tidak konsisten. Untuk mengelakkan LLM daripada halusinasi, sumber pengetahuan luaran, seperti pangkalan data atau graf pengetahuan, boleh digunakan untuk memberikan maklumat fakta. Dengan cara ini, LLM boleh bergantung pada sumber data yang boleh dipercayai ini, menghasilkan kandungan teks yang lebih tepat dan boleh dipercayai. Pangkalan Data Vektor dan Graf Pengetahuan Pangkalan Data Vektor Pangkalan data vektor ialah satu set vektor berdimensi tinggi yang mewakili entiti atau konsep. Ia boleh digunakan untuk mengukur persamaan atau korelasi antara entiti atau konsep yang berbeza, dikira melalui perwakilan vektornya. Pangkalan data vektor boleh memberitahu anda, berdasarkan jarak vektor, bahawa "Paris" dan "Perancis" lebih dekat daripada "Paris" dan
 Penjelasan terperinci tentang GQA, mekanisme perhatian yang biasa digunakan dalam model besar, dan pelaksanaan kod Pytorch
Apr 03, 2024 pm 05:40 PM
Penjelasan terperinci tentang GQA, mekanisme perhatian yang biasa digunakan dalam model besar, dan pelaksanaan kod Pytorch
Apr 03, 2024 pm 05:40 PM
Perhatian Pertanyaan Berkumpulan (GroupedQueryAttention) ialah kaedah perhatian berbilang pertanyaan dalam model bahasa besar Matlamatnya adalah untuk mencapai kualiti MHA sambil mengekalkan kelajuan MQA. GroupedQueryAttention kumpulan pertanyaan, dan pertanyaan dalam setiap kumpulan berkongsi berat perhatian yang sama, yang membantu mengurangkan kerumitan pengiraan dan meningkatkan kelajuan inferens. Dalam artikel ini, kami akan menerangkan idea GQA dan cara menterjemahkannya ke dalam kod. GQA ada dalam kertas GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint
 RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap
Jan 18, 2024 pm 05:27 PM
RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap
Jan 18, 2024 pm 05:27 PM
Apabila model bahasa berskala ke skala yang belum pernah berlaku sebelum ini, penalaan halus menyeluruh untuk tugas hiliran menjadi sangat mahal. Bagi menyelesaikan masalah ini, penyelidik mula memberi perhatian dan mengamalkan kaedah PEFT. Idea utama kaedah PEFT adalah untuk mengehadkan skop penalaan halus kepada set kecil parameter untuk mengurangkan kos pengiraan sambil masih mencapai prestasi terkini dalam tugas pemahaman bahasa semula jadi. Dengan cara ini, penyelidik boleh menjimatkan sumber pengkomputeran sambil mengekalkan prestasi tinggi, membawa tempat tumpuan penyelidikan baharu ke bidang pemprosesan bahasa semula jadi. RoSA ialah teknik PEFT baharu yang, melalui eksperimen pada satu set penanda aras, didapati mengatasi prestasi penyesuaian peringkat rendah (LoRA) sebelumnya dan kaedah penalaan halus tulen yang jarang menggunakan belanjawan parameter yang sama. Artikel ini akan pergi secara mendalam
 LLMLingua: Sepadukan LlamaIndex, mampatkan petunjuk dan menyediakan perkhidmatan inferens model bahasa besar yang cekap
Nov 27, 2023 pm 05:13 PM
LLMLingua: Sepadukan LlamaIndex, mampatkan petunjuk dan menyediakan perkhidmatan inferens model bahasa besar yang cekap
Nov 27, 2023 pm 05:13 PM
Kemunculan model bahasa besar (LLM) telah merangsang inovasi dalam pelbagai bidang. Walau bagaimanapun, peningkatan kerumitan gesaan, didorong oleh strategi seperti gesaan rantaian pemikiran (CoT) dan pembelajaran kontekstual (ICL), menimbulkan cabaran pengiraan. Gesaan yang panjang ini memerlukan sumber yang besar untuk membuat penaakulan dan oleh itu memerlukan penyelesaian yang cekap. Artikel ini akan memperkenalkan penyepaduan LLMLingua dan LlamaIndex proprietari untuk melaksanakan penaakulan yang cekap ialah kertas kerja yang diterbitkan oleh penyelidik Microsoft di EMNLP2023 LongLLMLingua ialah kaedah yang meningkatkan keupayaan llm untuk melihat maklumat penting dalam senario konteks yang panjang melalui pemampatan pantas. LLMLingua dan llamindex
