
 Peranti teknologi
AI
Pelbagai gaya panduan VCT, semuanya dengan satu gambar, membolehkan anda melaksanakannya dengan mudah
Peranti teknologi
AI
Pelbagai gaya panduan VCT, semuanya dengan satu gambar, membolehkan anda melaksanakannya dengan mudah
Pelbagai gaya panduan VCT, semuanya dengan satu gambar, membolehkan anda melaksanakannya dengan mudah

Dalam beberapa tahun kebelakangan ini, teknologi penjanaan imej telah membuat banyak penemuan penting. Terutama sejak keluaran model besar seperti DALLE2 dan Stable Diffusion, teknologi imej penjanaan teks telah matang secara beransur-ansur, dan penjanaan imej berkualiti tinggi mempunyai senario praktikal yang luas. Walau bagaimanapun, penyuntingan terperinci imej sedia ada masih menjadi masalah yang sukar
Di satu pihak, disebabkan oleh keterbatasan penerangan teks, model imej tekstual berkualiti tinggi sedia ada hanya boleh menggunakan teks untuk mengedit imej secara deskriptif, dan untuk beberapa tertentu. kesan, teks sukar untuk diterangkan; sebaliknya, dalam senario aplikasi sebenar, tugas penyuntingan pemurnian imej selalunya hanya mempunyai sebilangan kecil imej rujukan, Ini menjadikan banyak penyelesaian yang memerlukan sejumlah besar data untuk latihan, dalam Small jumlah data, terutamanya apabila terdapat hanya satu imej rujukan, sukar untuk digunakan.
Baru-baru ini, penyelidik dari NetEase Interactive Entertainment AI Lab mencadangkan penyelesaian pengeditan imej ke imej berdasarkan panduan imej tunggal Memandangkan imej rujukan tunggal, objek atau gaya dalam imej rujukan boleh dipindahkan ke imej sumber tanpa mengubah. struktur keseluruhan imej sumber.Kertas penyelidikan telah diterima oleh ICCV 2023, dan kod yang berkaitan adalah sumber terbuka.
- Alamat kertas: https://arxiv.org/abs/2307.14352
- Alamat kod: https://github.com/CrystalNeuro
- -concept-visual-concept Mari kita lihat dahulu set gambar untuk merasai kesannya.
Penyampaian tesis: Sudut kiri atas setiap set gambar ialah imej sumber, sudut kiri bawah ialah imej rujukan, dan sebelah kanan ialah imej hasil terjana

Bingkai utama
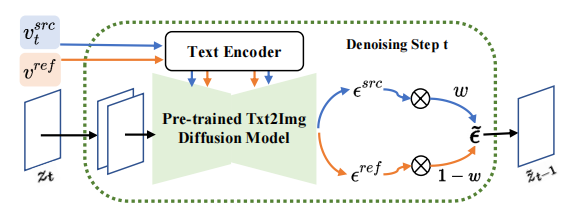
Pengarang kertas kerja mencadangkan rangka kerja penyuntingan imej berdasarkan Inversion-Fusion - VCT (penterjemah konsep visual, penukar konsep visual). Seperti yang ditunjukkan dalam rajah di bawah, rangka kerja keseluruhan VCT merangkumi dua proses: proses penyongsangan kandungan-konsep (Content-concept Inversion) dan proses gabungan konsep kandungan (Content-concept Fusion). Proses penyongsangan konsep kandungan menggunakan dua algoritma penyongsangan berbeza untuk mempelajari dan mewakili vektor terpendam maklumat struktur imej asal dan maklumat semantik imej rujukan proses gabungan konsep kandungan menggunakan vektor terpendam maklumat struktur dan maklumat semantik untuk menjana hasil akhir.
Kandungan yang perlu ditulis semula ialah: rangka kerja utama kertas tersebut
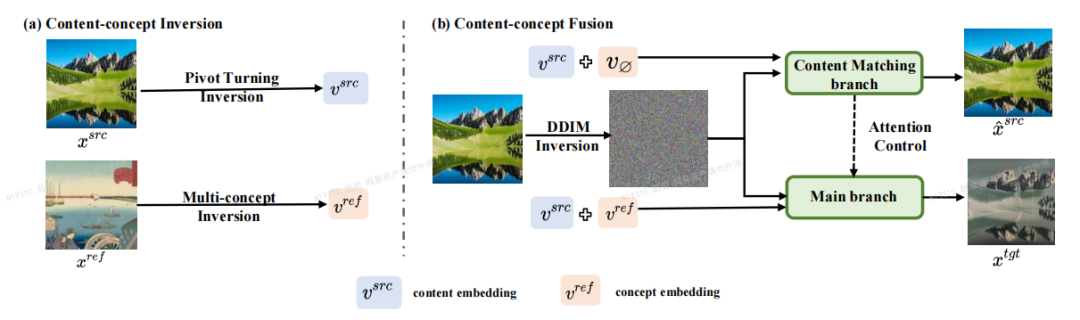
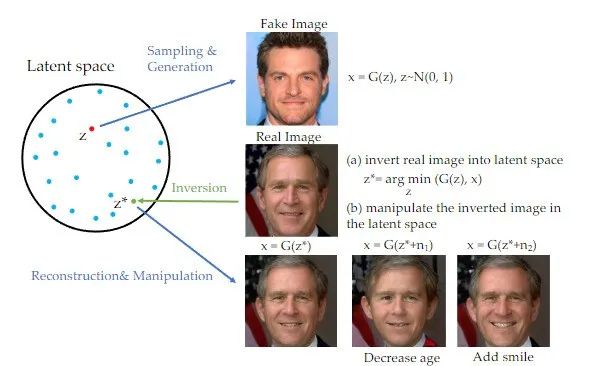
Perlu dinyatakan bahawa dalam bidang Generative Adversarial Networks (GAN) dalam beberapa tahun kebelakangan ini, kaedah penyongsangan telah digunakan secara meluas dan digunakan dalam banyak hasil yang luar biasa telah dicapai pada tugas penjanaan imej [1]. Apabila GAN menulis semula kandungan, teks asal perlu ditulis semula ke dalam bahasa Cina. ruang tersembunyi. Skim penyongsangan ini boleh mengeksploitasi sepenuhnya kuasa penjanaan model generatif pra-terlatih. Kajian ini sebenarnya menulis semula kandungan dengan GAN Teks asal perlu ditulis semula ke dalam bahasa Cina, dan ayat asal tidak perlu digunakan untuk tugas penyuntingan imej berdasarkan panduan imej dengan model penyebaran sebagai priori.
Pengenalan kaedah
VCT mereka bentuk proses resapan dua cawangan, yang merangkumi pembinaan semula kandungan Cawangan B* dan cawangan induk B untuk penyuntingan. Ia bermula daripada bunyi xT yang sama yang diperoleh daripada DDIM Inversion【2】
, algoritma yang menggunakan model resapan untuk mengira hingar daripada imej, untuk pembinaan semula kandungan dan penyuntingan kandungan masing-masing. Model pra-latihan yang digunakan dalam kertas ini ialah Model Resapan Terpendam (pendekatan LDM Proses resapan berlaku dalam ruang z ruang vektor terpendam Proses dua cabang boleh dinyatakan sebagai:
. 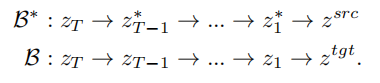
Proses resapan dua cawangan
Cawangan pembinaan semula kandungan B* mempelajari vektor ciri kandungan T 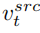 , yang digunakan untuk memulihkan maklumat struktur imej asal, dan melalui skema kawalan perhatian lembut, struktur Maklumat diserahkan kepada editor cabang induk B. Skim kawalan perhatian lembut menggunakan kerja prompt2prompt [3] Google Formulanya ialah:
, yang digunakan untuk memulihkan maklumat struktur imej asal, dan melalui skema kawalan perhatian lembut, struktur Maklumat diserahkan kepada editor cabang induk B. Skim kawalan perhatian lembut menggunakan kerja prompt2prompt [3] Google Formulanya ialah:
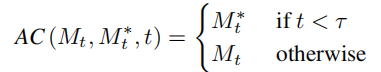
Iaitu, apabila bilangan langkah larian model resapan berada dalam julat tertentu, peta ciri perhatian bagi menyunting cawangan utama akan digantikan dengan cawangan pembinaan semula kandungan Peta ciri untuk mencapai kawalan struktur imej yang dihasilkan. Cawangan utama penyuntingan B menggabungkan vektor ciri kandungan 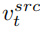 dipelajari daripada imej asal dan vektor ciri konsep
dipelajari daripada imej asal dan vektor ciri konsep 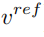 dipelajari daripada imej rujukan untuk menghasilkan gambar yang diedit.
dipelajari daripada imej rujukan untuk menghasilkan gambar yang diedit.
Ruang hingar (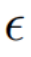 ruang) gabungan
ruang) gabungan
Pada setiap langkah model resapan, gabungan vektor ciri berlaku dalam ruang hingar bagi ruang bunyi, yang merupakan pemberat vektor ciri adalah input kepada model resapan. Percampuran ciri cawangan pembinaan semula kandungan berlaku pada vektor ciri kandungan 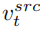 dan vektor teks kosong, selaras dengan bentuk panduan penyebaran bebas pengelas [4]:
dan vektor teks kosong, selaras dengan bentuk panduan penyebaran bebas pengelas [4]:
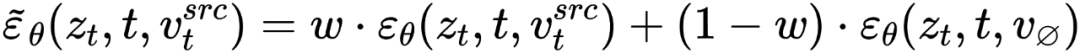
pencampuran penyuntingan cabang utama Ia merupakan campuran vektor ciri kandungan 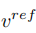 dan vektor ciri konsep
dan vektor ciri konsep 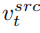 , iaitu
, iaitu
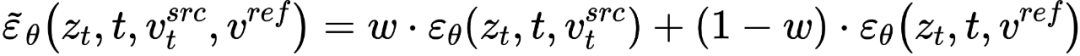
Pada ketika ini, kunci kepada penyelidikan adalah bagaimana untuk mendapatkan vektor ciri maklumat struktur daripada imej sumber tunggal 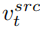 , dan daripada imej sumber tunggal Gambar rujukan untuk mendapatkan vektor ciri maklumat konsep
, dan daripada imej sumber tunggal Gambar rujukan untuk mendapatkan vektor ciri maklumat konsep 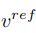 . Artikel mencapai tujuan ini melalui dua skema penyongsangan yang berbeza.
. Artikel mencapai tujuan ini melalui dua skema penyongsangan yang berbeza.
Untuk memulihkan imej sumber, artikel itu merujuk kepada skema pengoptimuman NULL-text [5] dan mempelajari vektor ciri peringkat T untuk dipadankan dan sesuai dengan imej sumber. Tetapi tidak seperti NULL-text, yang mengoptimumkan vektor teks kosong agar sesuai dengan laluan DDIM, artikel ini secara langsung menepati anggaran vektor ciri bersih dengan mengoptimumkan vektor ciri imej sumber Formula pemasangan ialah:
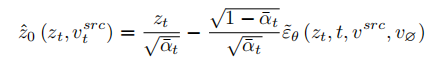
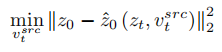
Berbeza daripada maklumat struktur pembelajaran, maklumat konsep dalam imej rujukan perlu diwakili oleh satu vektor ciri yang sangat umum Peringkat T model resapan berkongsi vektor ciri konsep 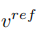 . Artikel tersebut mengoptimumkan skema penyongsangan sedia ada Penyongsangan Tekstual [6] dan DreamArtist [7]. Ia menggunakan vektor ciri berbilang konsep untuk mewakili kandungan imej rujukan Fungsi kehilangan termasuk istilah anggaran hingar model resapan dan anggaran jangka kerugian pembinaan semula dalam ruang vektor pendam:
. Artikel tersebut mengoptimumkan skema penyongsangan sedia ada Penyongsangan Tekstual [6] dan DreamArtist [7]. Ia menggunakan vektor ciri berbilang konsep untuk mewakili kandungan imej rujukan Fungsi kehilangan termasuk istilah anggaran hingar model resapan dan anggaran jangka kerugian pembinaan semula dalam ruang vektor pendam:
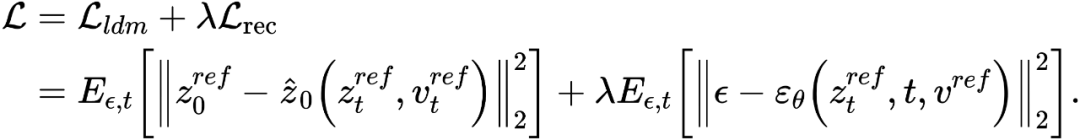
Hasil eksperimen
Artikel menjalankan eksperimen mengenai penggantian subjek dan tugas penggayaan, yang boleh menukar kandungan menjadi subjek atau gaya imej rujukan sambil mengekalkan maklumat struktur imej sumber dengan lebih baik.

Kandungan yang ditulis semula: Kertas mengenai kesan eksperimen
Berbanding dengan penyelesaian sebelumnya, rangka kerja VCT yang dicadangkan dalam artikel ini mempunyai kelebihan berikut:
)Generalisasi aplikasi : Berbanding dengan tugas penyuntingan imej sebelumnya berdasarkan panduan imej, VCT tidak memerlukan sejumlah besar data untuk latihan, dan mempunyai kualiti penjanaan dan generalisasi yang lebih baik. Ia berdasarkan idea penyongsangan dan berdasarkan model graf Vincentian berkualiti tinggi yang dipralatih pada data dunia terbuka Dalam aplikasi sebenar, hanya satu imej input dan satu imej rujukan diperlukan untuk mencapai kesan penyuntingan imej yang lebih baik.
(2) Ketepatan visual: Berbanding dengan penyelesaian imej penyuntingan teks terkini, VCT menggunakan gambar untuk panduan rujukan. Rujukan gambar membolehkan anda mengedit gambar dengan lebih tepat daripada penerangan teks. Rajah berikut menunjukkan hasil perbandingan antara VCT dan penyelesaian lain:


Tiada maklumat tambahan diperlukan : Berbanding dengan beberapa penyelesaian terkini yang memerlukan penambahan maklumat kawalan tambahan (seperti peta topeng atau peta kedalaman) untuk kawalan panduan, VCT secara langsung mempelajari maklumat struktur dan maklumat semantik daripada imej sumber dan imej rujukan generasi, rajah berikut menunjukkan beberapa hasil perbandingan. Antaranya, Paint-by-example menggantikan objek yang sepadan dengan objek dalam imej rujukan dengan menyediakan peta topeng imej sumber Controlnet mengawal hasil yang dijana melalui lukisan garisan, peta kedalaman, dan lain-lain imej dan rujukan imej, maklumat struktur pembelajaran dan maklumat kandungan untuk digabungkan ke dalam imej sasaran tanpa sekatan tambahan.

Kesan Kesan Penyuntingan Imej Berdasarkan Panduan Imej -Metease Interactive Entertainment AI Lab
Netease Interactive Entertainment AI Lab telah ditubuhkan pada tahun 2017 dan bergabung dengan Netease Interactive Entertainment Business Group makmal kecerdasan buatan terkemuka dalam industri permainan. Makmal ini memberi tumpuan kepada penyelidikan dan aplikasi penglihatan komputer, pertuturan dan pemprosesan bahasa semula jadi, dan pembelajaran pengukuhan dalam senario permainan. Ia bertujuan untuk meningkatkan tahap teknikal permainan dan produk popular NetEase Interactive Entertainment melalui teknologi AI. Pada masa ini, teknologi ini telah digunakan dalam banyak permainan popular, seperti "Fantasy Westward Journey", "Harry Potter: Magic Awakening", "Onmyoji", "Westward Journey", dll.
Atas ialah kandungan terperinci Pelbagai gaya panduan VCT, semuanya dengan satu gambar, membolehkan anda melaksanakannya dengan mudah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bagaimana untuk Muat Turun Imej Kertas Dinding Spotlight Windows pada PC
Aug 23, 2023 pm 02:06 PM
Bagaimana untuk Muat Turun Imej Kertas Dinding Spotlight Windows pada PC
Aug 23, 2023 pm 02:06 PM
Windows tidak pernah mengabaikan estetika. Daripada bidang hijau bucolic XP kepada reka bentuk berputar biru Windows 11, kertas dinding desktop lalai telah menjadi sumber kegembiraan pengguna selama bertahun-tahun. Dengan Windows Spotlight, anda kini mempunyai akses terus kepada imej yang cantik dan mengagumkan untuk skrin kunci dan kertas dinding desktop anda setiap hari. Malangnya, imej ini tidak melepak. Jika anda telah jatuh cinta dengan salah satu imej sorotan Windows, maka anda pasti ingin tahu cara memuat turunnya supaya anda boleh mengekalkannya sebagai latar belakang anda buat seketika. Ini semua yang anda perlu tahu. Apakah WindowsSpotlight? Sorotan Tetingkap ialah pengemas kini kertas dinding automatik yang tersedia daripada Pemperibadian > dalam apl Tetapan
 Menyelam mendalam ke dalam model, data dan rangka kerja: tinjauan menyeluruh 54 halaman model bahasa besar yang cekap
Jan 14, 2024 pm 07:48 PM
Menyelam mendalam ke dalam model, data dan rangka kerja: tinjauan menyeluruh 54 halaman model bahasa besar yang cekap
Jan 14, 2024 pm 07:48 PM
Model bahasa berskala besar (LLM) telah menunjukkan keupayaan yang menarik dalam banyak tugas penting, termasuk pemahaman bahasa semula jadi, penjanaan bahasa dan penaakulan yang kompleks, dan telah memberi kesan yang mendalam kepada masyarakat. Walau bagaimanapun, keupayaan cemerlang ini memerlukan sumber latihan yang ketara (ditunjukkan di sebelah kiri) dan masa inferens yang panjang (ditunjukkan di sebelah kanan). Oleh itu, penyelidik perlu membangunkan cara teknikal yang berkesan untuk menyelesaikan masalah kecekapan mereka. Di samping itu, seperti yang dapat dilihat dari sebelah kanan rajah, beberapa LLM (Model Bahasa) yang cekap seperti Mistral-7B telah berjaya digunakan dalam reka bentuk dan penggunaan LLM. LLM yang cekap ini boleh mengurangkan memori inferens dengan ketara sambil mengekalkan ketepatan yang serupa dengan LLaMA1-33B
 Menghancurkan H100, GPU generasi seterusnya Nvidia didedahkan! Reka bentuk modul berbilang cip 3nm pertama, diperkenalkan pada 2024
Sep 30, 2023 pm 12:49 PM
Menghancurkan H100, GPU generasi seterusnya Nvidia didedahkan! Reka bentuk modul berbilang cip 3nm pertama, diperkenalkan pada 2024
Sep 30, 2023 pm 12:49 PM
Proses 3nm, prestasi melepasi H100! Baru-baru ini, media asing DigiTimes mengumumkan bahawa Nvidia sedang membangunkan GPU generasi akan datang, B100, dengan nama kod "Blackwell" Dikatakan bahawa sebagai produk untuk aplikasi kecerdasan buatan (AI) dan pengkomputeran berprestasi tinggi (HPC). , B100 akan menggunakan proses proses 3nm TSMC, serta reka bentuk modul berbilang cip (MCM) yang lebih kompleks, dan akan muncul pada suku keempat 2024. Bagi Nvidia, yang memonopoli lebih daripada 80% pasaran GPU kecerdasan buatan, ia boleh menggunakan B100 untuk menyerang semasa seterika panas dan seterusnya menyerang pencabar seperti AMD dan Intel dalam gelombang penggunaan AI ini. Menurut anggaran NVIDIA, menjelang 2027, nilai output medan ini dijangka mencapai lebih kurang
 Bagaimana untuk menggunakan teknologi segmentasi semantik imej dalam Python?
Jun 06, 2023 am 08:03 AM
Bagaimana untuk menggunakan teknologi segmentasi semantik imej dalam Python?
Jun 06, 2023 am 08:03 AM
Dengan pembangunan berterusan teknologi kecerdasan buatan, teknologi segmentasi semantik imej telah menjadi hala tuju penyelidikan yang popular dalam bidang analisis imej. Dalam segmentasi semantik imej, kami membahagikan kawasan yang berbeza dalam imej dan mengelaskan setiap kawasan untuk mencapai pemahaman yang menyeluruh tentang imej. Python ialah bahasa pengaturcaraan yang terkenal dengan keupayaan analisis data dan visualisasi datanya yang hebat menjadikannya pilihan pertama dalam bidang penyelidikan teknologi kecerdasan buatan. Artikel ini akan memperkenalkan cara menggunakan teknologi segmentasi semantik imej dalam Python. 1. Pengetahuan prasyarat semakin mendalam
 iOS 17: Cara menggunakan pemangkasan satu klik dalam foto
Sep 20, 2023 pm 08:45 PM
iOS 17: Cara menggunakan pemangkasan satu klik dalam foto
Sep 20, 2023 pm 08:45 PM
Dengan apl iOS 17 Photos, Apple memudahkan untuk memangkas foto mengikut spesifikasi anda. Baca terus untuk mengetahui caranya. Sebelum ini dalam iOS 16, memangkas imej dalam apl Foto melibatkan beberapa langkah: Ketik antara muka pengeditan, pilih alat pangkas dan kemudian laraskan pemangkasan menggunakan gerak isyarat picit untuk zum atau seret penjuru alat pangkas. Dalam iOS 17, Apple bersyukur telah memudahkan proses ini supaya apabila anda mengezum masuk pada mana-mana foto yang dipilih dalam pustaka Foto anda, butang Pangkas baharu muncul secara automatik di penjuru kanan sebelah atas skrin. Mengklik padanya akan memaparkan antara muka pemangkasan penuh dengan tahap zum pilihan anda, jadi anda boleh memangkas ke bahagian imej yang anda suka, memutar imej, menyongsangkan imej atau menggunakan nisbah skrin atau menggunakan penanda
 Semakan paling komprehensif tentang model besar multimodal ada di sini! 7 penyelidik Microsoft bekerjasama bersungguh-sungguh, 5 tema utama, 119 halaman dokumen
Sep 25, 2023 pm 04:49 PM
Semakan paling komprehensif tentang model besar multimodal ada di sini! 7 penyelidik Microsoft bekerjasama bersungguh-sungguh, 5 tema utama, 119 halaman dokumen
Sep 25, 2023 pm 04:49 PM
Kajian yang paling komprehensif tentang model besar berbilang mod ada di sini! Ditulis oleh 7 penyelidik Cina di Microsoft, ia mempunyai 119 halaman - ia bermula daripada dua jenis arahan penyelidikan model besar berbilang modal yang telah selesai dan masih berada di barisan hadapan, dan meringkaskan secara komprehensif lima topik penyelidikan khusus: pemahaman visual dan penjanaan visual Ejen berbilang modal model besar berbilang modal yang disokong oleh model visual bersatu LLM memfokuskan pada fenomena: model asas berbilang modal telah beralih daripada khusus kepada universal. Ps. Inilah sebabnya penulis melukis secara langsung imej Doraemon pada permulaan kertas. Siapa yang patut membaca ulasan (laporan) ini? Dalam kata-kata asal Microsoft: Selagi anda berminat untuk mempelajari pengetahuan asas dan kemajuan terkini model asas pelbagai mod, sama ada anda seorang penyelidik profesional atau pelajar, kandungan ini sangat sesuai untuk anda berkumpul.
 Bagaimana untuk mengubah saiz kumpulan imej menggunakan PowerToys pada Windows
Aug 23, 2023 pm 07:49 PM
Bagaimana untuk mengubah saiz kumpulan imej menggunakan PowerToys pada Windows
Aug 23, 2023 pm 07:49 PM
Mereka yang perlu bekerja dengan fail imej setiap hari selalunya perlu mengubah saiznya agar sesuai dengan keperluan projek dan pekerjaan mereka. Walau bagaimanapun, jika anda mempunyai terlalu banyak imej untuk diproses, saiz semula imej secara individu boleh mengambil banyak masa dan usaha. Dalam kes ini, alat seperti PowerToys boleh berguna untuk, antara lain, mengubah saiz fail kumpulan menggunakan utiliti pengubah semula imejnya. Begini cara untuk menyediakan tetapan Image Resizer anda dan mulakan saiz semula kumpulan imej dengan PowerToys. Cara Mengubah Saiz Imej Secara Berkelompok dengan PowerToys PowerToys ialah program semua-dalam-satu dengan pelbagai utiliti dan ciri untuk membantu anda mempercepatkan tugas harian anda. Salah satu utilitinya ialah imej
 Bagaimana untuk mengedit foto pada iPhone menggunakan iOS 17
Nov 30, 2023 pm 11:39 PM
Bagaimana untuk mengedit foto pada iPhone menggunakan iOS 17
Nov 30, 2023 pm 11:39 PM
Fotografi mudah alih secara asasnya telah mengubah cara kami merakam dan berkongsi detik kehidupan. Kemunculan telefon pintar, terutamanya iPhone, memainkan peranan penting dalam peralihan ini. Terkenal dengan teknologi kamera canggih dan ciri penyuntingan yang mesra pengguna, iPhone telah menjadi pilihan pertama untuk jurugambar amatur dan berpengalaman. Pelancaran iOS 17 menandakan peristiwa penting dalam perjalanan ini. Kemas kini terbaharu Apple membawa satu set ciri penyuntingan foto yang dipertingkatkan, memberikan pengguna kit alat yang lebih berkuasa untuk menukar syot kilat setiap hari mereka kepada imej yang menarik secara visual dan kaya secara artistik. Perkembangan teknologi ini bukan sahaja memudahkan proses fotografi tetapi juga membuka ruang baharu untuk ekspresi kreatif, membolehkan pengguna menyuntik sentuhan profesional ke dalam foto mereka dengan mudah.
