
 Peranti teknologi
AI
Bina aplikasi LLM: Memanfaatkan keupayaan carian vektor Perkhidmatan Kognitif Azure
Peranti teknologi
AI
Bina aplikasi LLM: Memanfaatkan keupayaan carian vektor Perkhidmatan Kognitif Azure
Bina aplikasi LLM: Memanfaatkan keupayaan carian vektor Perkhidmatan Kognitif Azure

Pengarang |. Simon Bisson
Dipilih |. Ethan
API Carian Kognitif Microsoft kini menawarkan carian vektor sebagai perkhidmatan untuk digunakan dengan model bahasa besar dalam Azure OpenAI dan banyak lagi.
Alat seperti Semantic Core, TypeChat dan LangChain memungkinkan untuk membina aplikasi di sekitar teknologi AI generatif seperti Azure OpenAI. Ini kerana ia membenarkan kekangan dikenakan ke atas model bahasa besar (LLM) asas, yang boleh digunakan sebagai alat untuk membina dan menjalankan antara muka bahasa semula jadi
Pada asasnya, LLM ialah alat untuk menavigasi ruang semantik di mana saraf dalam rangkaian boleh meramalkan suku kata seterusnya dalam rangkaian token bermula dari isyarat awal. Jika gesaan bersifat terbuka, LLM mungkin melebihi skop inputnya dan menghasilkan sesuatu yang kelihatan munasabah tetapi sebenarnya tidak masuk akal.
Sama seperti kita semua cenderung mempercayai output enjin carian, kita juga cenderung mempercayai output LLM kerana kita melihatnya sebagai satu lagi aspek teknologi biasa. Tetapi melatih model bahasa yang besar menggunakan data yang dipercayai daripada tapak seperti Wikipedia, Stack Overflow dan Reddit tidak menyampaikan pemahaman tentang kandungan itu hanya memberikan keupayaan untuk menjana teks yang mengikut corak yang sama seperti teks dalam sumber tersebut. Kadangkala output mungkin betul, tetapi pada masa lain ia mungkin salah.
Bagaimanakah kita boleh mengelakkan ralat dan output yang tidak bermakna daripada model bahasa yang besar dan memastikan pengguna kami mendapat jawapan yang tepat dan munasabah untuk pertanyaan mereka?
1. Hadkan model besar dengan kekangan memori semantik
Apa yang perlu kita lakukan ialah menghadkan LLM untuk memastikan ia hanya menjana teks daripada set data yang lebih kecil. Di sinilah timbunan pembangunan berasaskan LLM baharu Microsoft masuk. Ia menyediakan alatan yang diperlukan untuk mengawal model anda dan menghalangnya daripada menjana ralat
Anda boleh memaksa format output tertentu dengan menggunakan alatan seperti TypeChat, atau menggunakan saluran paip orkestra seperti Semantic Kernel untuk memproses sumber maklumat lain yang dipercayai, Ini "berakar" dengan berkesan model dalam ruang semantik yang diketahui, dengan itu mengekang LLM. Di sini, LLM boleh melakukan apa yang dilakukannya dengan baik, meringkaskan gesaan yang dibina dan menjana teks berdasarkan gesaan itu, tanpa melebihkan (atau sekurang-kurangnya dengan ketara mengurangkan kebarangkalian melebihkan).
Apa yang Microsoft panggil "memori semantik" adalah asas kepada kaedah terakhir. Memori semantik menggunakan carian vektor untuk memberikan petunjuk yang boleh digunakan untuk menyediakan output fakta LLM. Pangkalan data vektor mengurus konteks gesaan awal, carian vektor mencari data tersimpan yang sepadan dengan pertanyaan pengguna awal dan LLM menjana teks berdasarkan data tersebut. Lihat pendekatan ini dalam tindakan dalam Bing Chat, yang menggunakan alat carian vektor asli Bing untuk membina jawapan yang diperoleh daripada pangkalan data cariannya
Memori semantik membolehkan pangkalan data vektor dan carian vektor menyediakan cara aplikasi berasaskan LLM. Anda boleh memilih untuk menggunakan salah satu daripada pangkalan data vektor sumber terbuka yang semakin meningkat, atau menambah indeks vektor pada pangkalan data SQL dan NoSQL anda yang biasa. Produk baharu yang kelihatan amat berguna memanjangkan Carian Kognitif Azure, menambahkan indeks vektor pada data anda dan menyediakan API baharu untuk menanyakan indeks tersebut
2. Tambahkan indeks vektor pada Carian Kognitif Azure
Carian Kognitif Azure dibina atas carian Microsoft sendiri alatan. Ia menyediakan gabungan pertanyaan Lucene yang biasa dan alat pertanyaan bahasa semula jadinya sendiri. Azure Cognitive Search ialah platform perisian-sebagai-perkhidmatan yang boleh mengehoskan data peribadi dan mengakses kandungan menggunakan API Perkhidmatan Kognitif. Baru-baru ini, Microsoft turut menambah sokongan untuk membina dan menggunakan indeks vektor, yang membolehkan anda menggunakan carian persamaan untuk menentukan kedudukan hasil yang berkaitan dalam data anda dan menggunakannya dalam aplikasi berasaskan AI. Ini menjadikan Azure Cognitive Search sebagai alat yang ideal untuk aplikasi LLM yang dihoskan Azure yang dibina dengan Semantic Kernel dan Azure OpenAI, dan pemalam Semantic Kernel untuk Carian Kognitif untuk C# dan Python juga tersedia
Seperti perkhidmatan Azure yang lain, Azure Cognitive Search adalah terurus. perkhidmatan yang berfungsi dengan perkhidmatan Azure yang lain. Ia membolehkan anda mengindeks dan mencari merentasi pelbagai perkhidmatan storan Azure, teks pengehosan, imej, audio dan video. Data disimpan di berbilang wilayah, menyediakan ketersediaan tinggi dan mengurangkan kependaman dan masa tindak balas. Selain itu, untuk aplikasi perusahaan, anda boleh menggunakan Microsoft Entra ID (nama baharu untuk Azure Active Directory) untuk mengawal akses kepada data peribadi
3 Jana dan simpan vektor benam untuk kandungan
Perlu diingat bahawa Azure Cognitive Search It ialah. perkhidmatan "bawa vektor benam anda sendiri". Carian Kognitif tidak akan menjana pembenaman vektor yang anda perlukan, jadi anda perlu menggunakan Azure OpenAI atau API pembenaman OpenAI untuk membuat pembenaman untuk kandungan anda. Ini mungkin memerlukan pembahagian fail besar untuk memastikan anda kekal dalam had token perkhidmatan. Bersedia untuk mencipta jadual baharu untuk mengindeks data vektor apabila diperlukan
Dalam Carian Kognitif Azure, carian vektor menggunakan model jiran terdekat untuk mengembalikan bilangan dokumen pilihan pengguna yang serupa dengan pertanyaan asal. Proses ini memanggil pengindeksan vektor dengan menggunakan pembenaman vektor pertanyaan asal dan mengembalikan vektor dan kandungan indeks yang serupa daripada pangkalan data sedia untuk digunakan oleh gesaan LLM
Microsoft menggunakan kedai vektor ini sebagai sebahagian daripada corak reka bentuk Retrieval Augmented Generation (RAG) untuk Pembelajaran Mesin Azure dan bersama-sama dengan alat aliran segeranya. RAG memanfaatkan pengindeksan vektor dalam carian kognitif untuk membina konteks yang membentuk asas gesaan LLM. Ini memberi anda cara kod rendah untuk membina dan menggunakan indeks vektor, seperti menetapkan bilangan dokumen serupa yang dikembalikan oleh pertanyaan. Mulakan dengan mencipta sumber untuk Azure OpenAI dan Carian Kognitif di rantau yang sama. Ini akan membolehkan anda memuatkan indeks carian dengan benaman dengan kependaman minimum. Anda perlu memanggil API Azure OpenAI dan API Carian Kognitif untuk memuatkan indeks, jadi adalah idea yang baik untuk memastikan kod anda boleh bertindak balas kepada sebarang had kadar yang mungkin dalam perkhidmatan untuk anda dengan menambahkan kod yang mengurus percubaan semula. Apabila anda menggunakan API perkhidmatan, anda harus menggunakan panggilan tak segerak untuk menjana benaman dan memuatkan indeks.
Vektor disimpan dalam indeks carian sebagai medan vektor, di mana vektor ialah nombor titik terapung dengan dimensi. Vektor ini dipetakan melalui graf kejiranan dunia kecil yang boleh dilayari hierarki yang menyusun vektor ke dalam kejiranan vektor yang serupa, mempercepatkan proses sebenar mencari indeks vektor.
Selepas mentakrifkan skema indeks untuk carian vektor, anda boleh memuatkan data ke dalam indeks untuk carian kognitif. Ambil perhatian bahawa data mungkin dikaitkan dengan berbilang vektor. Contohnya, jika anda menggunakan carian kognitif untuk mengehoskan dokumen syarikat, anda mungkin mempunyai vektor berasingan untuk istilah metadata dokumen utama dan kandungan dokumen. Set data mesti disimpan sebagai dokumen JSON, yang memudahkan proses menggunakan keputusan untuk memasang konteks segera. Indeks tidak perlu mengandungi dokumen sumber kerana ia menyokong penggunaan pilihan storan Azure yang paling biasa
Sebelum menjalankan pertanyaan, anda perlu terlebih dahulu memanggil model pembenaman pilihan anda dengan badan pertanyaan. Ini mengembalikan vektor berbilang dimensi yang boleh anda gunakan untuk mencari indeks pilihan anda. Apabila memanggil API carian vektor, nyatakan indeks vektor sasaran, bilangan padanan yang dikehendaki dan medan teks yang berkaitan dalam indeks. Memilih ukuran persamaan yang sesuai boleh sangat membantu untuk pertanyaan, yang paling biasa digunakan ialah metrik kosinus
5 Melangkaui vektor teks ringkas
Keupayaan vektor Azure Cognitive Search melangkaui teks yang sepadan. Carian Kognitif boleh digunakan dengan benam berbilang bahasa untuk menyokong carian dokumen merentas berbilang bahasa. Anda juga boleh menggunakan API yang lebih kompleks. Sebagai contoh, anda boleh mencampurkan alat carian semantik Bing dalam Carian Hibrid untuk memberikan hasil yang lebih tepat, dengan itu meningkatkan kualiti output daripada aplikasi berkuasa LLM.
Microsoft dengan pantas menghasilkan alatan dan teknologi yang digunakannya untuk membina enjin carian Bing berasaskan GPT-4nya sendiri, serta pelbagai Copilot. Enjin orkestrasi seperti Semantic Kernel dan aliran segera Azure AI Studio adalah teras kepada pendekatan Microsoft untuk bekerja dengan model bahasa yang besar. Sekarang setelah asas-asas tersebut telah diletakkan, kami melihat syarikat itu melancarkan lebih banyak teknologi pemboleh yang diperlukan. Carian vektor dan pengindeksan vektor adalah kunci untuk memberikan respons yang tepat. Dengan membina alatan biasa untuk menyampaikan perkhidmatan ini, Microsoft akan membantu kami meminimumkan kos dan keluk pembelajaran
Atas ialah kandungan terperinci Bina aplikasi LLM: Memanfaatkan keupayaan carian vektor Perkhidmatan Kognitif Azure. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1385
1385
 52
52

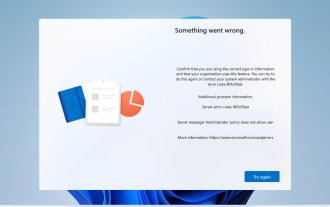 Kod ralat 801c03ed: Bagaimana untuk membetulkannya pada Windows 11
Oct 04, 2023 pm 06:05 PM
Kod ralat 801c03ed: Bagaimana untuk membetulkannya pada Windows 11
Oct 04, 2023 pm 06:05 PM
Ralat 801c03ed biasanya disertakan dengan mesej berikut: Dasar pentadbir tidak membenarkan pengguna ini menyertai peranti. Mesej ralat ini akan menghalang anda daripada memasang Windows dan menyertai rangkaian, dengan itu menghalang anda daripada menggunakan komputer anda, jadi adalah penting untuk menyelesaikan isu ini secepat mungkin. Apakah kod ralat 801c03ed? Ini ialah ralat pemasangan Windows yang berlaku atas sebab berikut: Persediaan Azure tidak membenarkan pengguna baharu untuk menyertai. Objek peranti tidak didayakan pada Azure. Kegagalan cincang perkakasan dalam panel Azure. Bagaimana untuk membetulkan kod ralat 03c11ed pada Windows 801? 1. Semak tetapan Intune Log masuk ke portal Azure. Navigasi ke Peranti dan pilih Tetapan Peranti. Tukar "Pengguna boleh
 Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Penterjemah |. Tinjauan Bugatti |. Chonglou Artikel ini menerangkan cara menggunakan enjin inferens GroqLPU untuk menjana respons sangat pantas dalam JanAI dan VSCode. Semua orang sedang berusaha membina model bahasa besar (LLM) yang lebih baik, seperti Groq yang memfokuskan pada bahagian infrastruktur AI. Sambutan pantas daripada model besar ini adalah kunci untuk memastikan model besar ini bertindak balas dengan lebih cepat. Tutorial ini akan memperkenalkan enjin parsing GroqLPU dan cara mengaksesnya secara setempat pada komputer riba anda menggunakan API dan JanAI. Artikel ini juga akan menyepadukannya ke dalam VSCode untuk membantu kami menjana kod, kod refactor, memasukkan dokumentasi dan menjana unit ujian. Artikel ini akan mencipta pembantu pengaturcaraan kecerdasan buatan kami sendiri secara percuma. Pengenalan kepada enjin inferens GroqLPU Groq
 Caltech Cina menggunakan AI untuk menumbangkan bukti matematik! Mempercepatkan 5 kali terkejut Tao Zhexuan, 80% langkah matematik adalah automatik sepenuhnya
Apr 23, 2024 pm 03:01 PM
Caltech Cina menggunakan AI untuk menumbangkan bukti matematik! Mempercepatkan 5 kali terkejut Tao Zhexuan, 80% langkah matematik adalah automatik sepenuhnya
Apr 23, 2024 pm 03:01 PM
LeanCopilot, alat matematik formal yang telah dipuji oleh ramai ahli matematik seperti Terence Tao, telah berkembang semula? Sebentar tadi, profesor Caltech Anima Anandkumar mengumumkan bahawa pasukan itu mengeluarkan versi diperluaskan kertas LeanCopilot dan mengemas kini pangkalan kod. Alamat kertas imej: https://arxiv.org/pdf/2404.12534.pdf Percubaan terkini menunjukkan bahawa alat Copilot ini boleh mengautomasikan lebih daripada 80% langkah pembuktian matematik! Rekod ini adalah 2.3 kali lebih baik daripada aesop garis dasar sebelumnya. Dan, seperti sebelum ini, ia adalah sumber terbuka di bawah lesen MIT. Dalam gambar, dia ialah Song Peiyang, seorang budak Cina
 Daripada 'manusia + RPA' kepada 'manusia + generatif AI + RPA', bagaimanakah LLM mempengaruhi interaksi manusia-komputer RPA?
Jun 05, 2023 pm 12:30 PM
Daripada 'manusia + RPA' kepada 'manusia + generatif AI + RPA', bagaimanakah LLM mempengaruhi interaksi manusia-komputer RPA?
Jun 05, 2023 pm 12:30 PM
Sumber imej@visualchinesewen|Wang Jiwei Daripada "manusia + RPA" kepada "manusia + generatif AI + RPA", bagaimanakah LLM mempengaruhi interaksi manusia-komputer RPA? Dari perspektif lain, bagaimanakah LLM mempengaruhi RPA dari perspektif interaksi manusia-komputer? RPA, yang menjejaskan interaksi manusia-komputer dalam pembangunan program dan automasi proses, kini akan turut diubah oleh LLM? Bagaimanakah LLM mempengaruhi interaksi manusia-komputer? Bagaimanakah AI generatif mengubah interaksi manusia-komputer RPA? Ketahui lebih lanjut mengenainya dalam satu artikel: Era model besar akan datang, dan AI generatif berdasarkan LLM sedang mengubah interaksi manusia-komputer RPA dengan pantas mentakrifkan semula interaksi manusia-komputer, dan LLM mempengaruhi perubahan dalam seni bina perisian RPA. Jika anda bertanya apakah sumbangan RPA kepada pembangunan program dan automasi, salah satu jawapannya ialah ia telah mengubah interaksi manusia-komputer (HCI, h
 Plaud melancarkan perakam boleh pakai NotePin AI untuk $169
Aug 29, 2024 pm 02:37 PM
Plaud melancarkan perakam boleh pakai NotePin AI untuk $169
Aug 29, 2024 pm 02:37 PM
Plaud, syarikat di belakang Perakam Suara AI Plaud Note (tersedia di Amazon dengan harga $159), telah mengumumkan produk baharu. Digelar NotePin, peranti ini digambarkan sebagai kapsul memori AI, dan seperti Pin AI Humane, ini boleh dipakai. NotePin ialah
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Mar 01, 2024 pm 09:16 PM
Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Mar 01, 2024 pm 09:16 PM
Memandangkan prestasi model bahasa berskala besar sumber terbuka terus bertambah baik, prestasi dalam penulisan dan analisis kod, pengesyoran, ringkasan teks dan pasangan menjawab soalan (QA) semuanya bertambah baik. Tetapi apabila ia berkaitan dengan QA, LLM sering gagal dalam isu yang berkaitan dengan data yang tidak terlatih, dan banyak dokumen dalaman disimpan dalam syarikat untuk memastikan pematuhan, rahsia perdagangan atau privasi. Apabila dokumen ini disoal, LLM boleh berhalusinasi dan menghasilkan kandungan yang tidak relevan, rekaan atau tidak konsisten. Satu teknik yang mungkin untuk menangani cabaran ini ialah Retrieval Augmented Generation (RAG). Ia melibatkan proses meningkatkan respons dengan merujuk pangkalan pengetahuan berwibawa di luar sumber data latihan untuk meningkatkan kualiti dan ketepatan penjanaan. Sistem RAG termasuk sistem mendapatkan semula untuk mendapatkan serpihan dokumen yang berkaitan daripada korpus
 GraphRAG dipertingkatkan untuk mendapatkan semula graf pengetahuan (dilaksanakan berdasarkan kod Neo4j)
Jun 12, 2024 am 10:32 AM
GraphRAG dipertingkatkan untuk mendapatkan semula graf pengetahuan (dilaksanakan berdasarkan kod Neo4j)
Jun 12, 2024 am 10:32 AM
Penjanaan Dipertingkatkan Pengambilan Graf (GraphRAG) secara beransur-ansur menjadi popular dan telah menjadi pelengkap hebat kepada kaedah carian vektor tradisional. Kaedah ini mengambil kesempatan daripada ciri-ciri struktur pangkalan data graf untuk menyusun data dalam bentuk nod dan perhubungan, dengan itu mempertingkatkan kedalaman dan perkaitan kontekstual bagi maklumat yang diambil. Graf mempunyai kelebihan semula jadi dalam mewakili dan menyimpan maklumat yang pelbagai dan saling berkaitan, dan dengan mudah boleh menangkap hubungan dan sifat yang kompleks antara jenis data yang berbeza. Pangkalan data vektor tidak dapat mengendalikan jenis maklumat berstruktur ini dan ia lebih menumpukan pada pemprosesan data tidak berstruktur yang diwakili oleh vektor berdimensi tinggi. Dalam aplikasi RAG, menggabungkan data graf berstruktur dan carian vektor teks tidak berstruktur membolehkan kami menikmati kelebihan kedua-duanya pada masa yang sama, iaitu perkara yang akan dibincangkan oleh artikel ini. struktur
