Semalam, Meta menggunakan sumber terbuka model asas yang mengkhusus dalam penjanaan kod Kod Llama, yang boleh digunakan untuk tujuan penyelidikan dan komersial secara percuma. Model siri Kod Llama mempunyai tiga versi parameter, dengan jumlah parameter masing-masing 7B, 13B dan 34B. Dan menyokong berbilang bahasa pengaturcaraan, termasuk Python, C++, Java, PHP, Typescript (Javascript), C# dan Bash. Meta menyediakan versi Code Llama termasuk:
Code Llama, model kod asas
Code Sheep-Python, versi Python-In🜎🜎; arahan bahasa semula jadi yang diperhalusi Versi
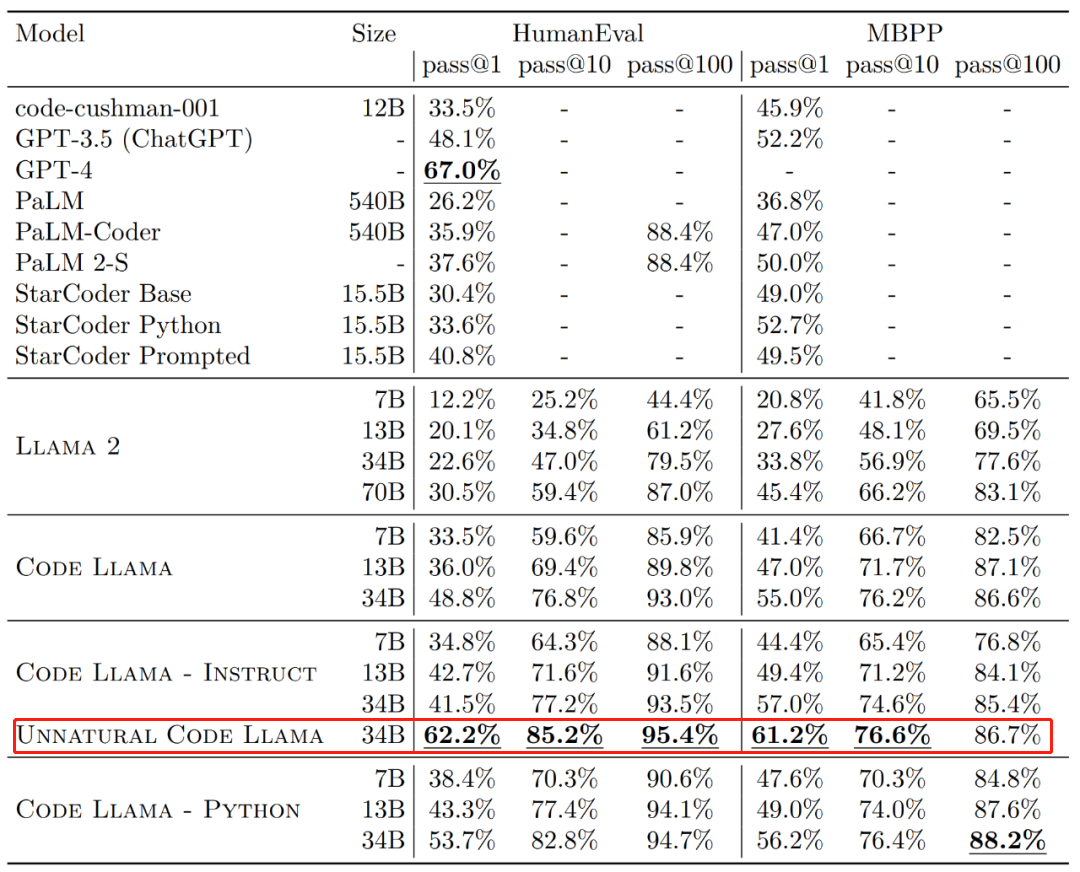
Dari segi keberkesanan, kadar lulus generasi sekali (lulus@1) versi berbeza Kod Llama pada set data HumanEval dan MBPP melebihi GPT-3.5.
Selain itu, pas@1 versi 34B "Unnatural" Code Llama pada dataset HumanEval adalah hampir dengan GPT-4 (62.2% vs 67.0%). Walau bagaimanapun, Meta tidak mengeluarkan versi ini, tetapi peningkatan prestasi yang ketara telah dicapai melalui latihan pada set kecil data yang dikodkan berkualiti tinggi.
Sumber imej: https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/ Sejurus selepas sehari, seorang penyelidik melaporkan kepada GPT-4 Satu cabaran telah dilancarkan. Mereka datang dari Phind, sebuah organisasi yang bertujuan untuk membina enjin carian AI untuk pembangun, dan penyelidikan menggunakan Kod Llama-34B yang ditala dengan baik untuk mengalahkan GPT-4 dalam penilaian HumanEval.
Sejurus selepas sehari, seorang penyelidik melaporkan kepada GPT-4 Satu cabaran telah dilancarkan. Mereka datang dari Phind, sebuah organisasi yang bertujuan untuk membina enjin carian AI untuk pembangun, dan penyelidikan menggunakan Kod Llama-34B yang ditala dengan baik untuk mengalahkan GPT-4 dalam penilaian HumanEval.
Pengasas bersama Phind Michael Royzen berkata: "Ini hanyalah percubaan awal, bertujuan untuk menghasilkan semula (dan mengatasi) keputusan "Unnatural Code Llama" dalam kertas Meta. Pada masa hadapan, kami akan mempunyai portfolio pakar model CodeLlama berbeza yang saya fikir akan berdaya saing dalam aliran kerja dunia sebenar. ”
Kedua-dua model telah menjadi sumber terbuka:
Para penyelidik mengeluarkan kedua-dua model ini di Huggingface, anda boleh pergi dan menyemaknya.
Phind-CodeLlama-34B-v1: https://huggingface.co/Phind/Phind-CodeLlama-34B-v1
- Phind-CodeLlama-34B-Python-face: https://hugging-v1. /Phind/Phind-CodeLlama-34B-Python-v1
- Seterusnya mari kita lihat bagaimana penyelidikan ini dilaksanakan.
Kod Llama-34B yang diperhalusi untuk mengalahkan GPT-4
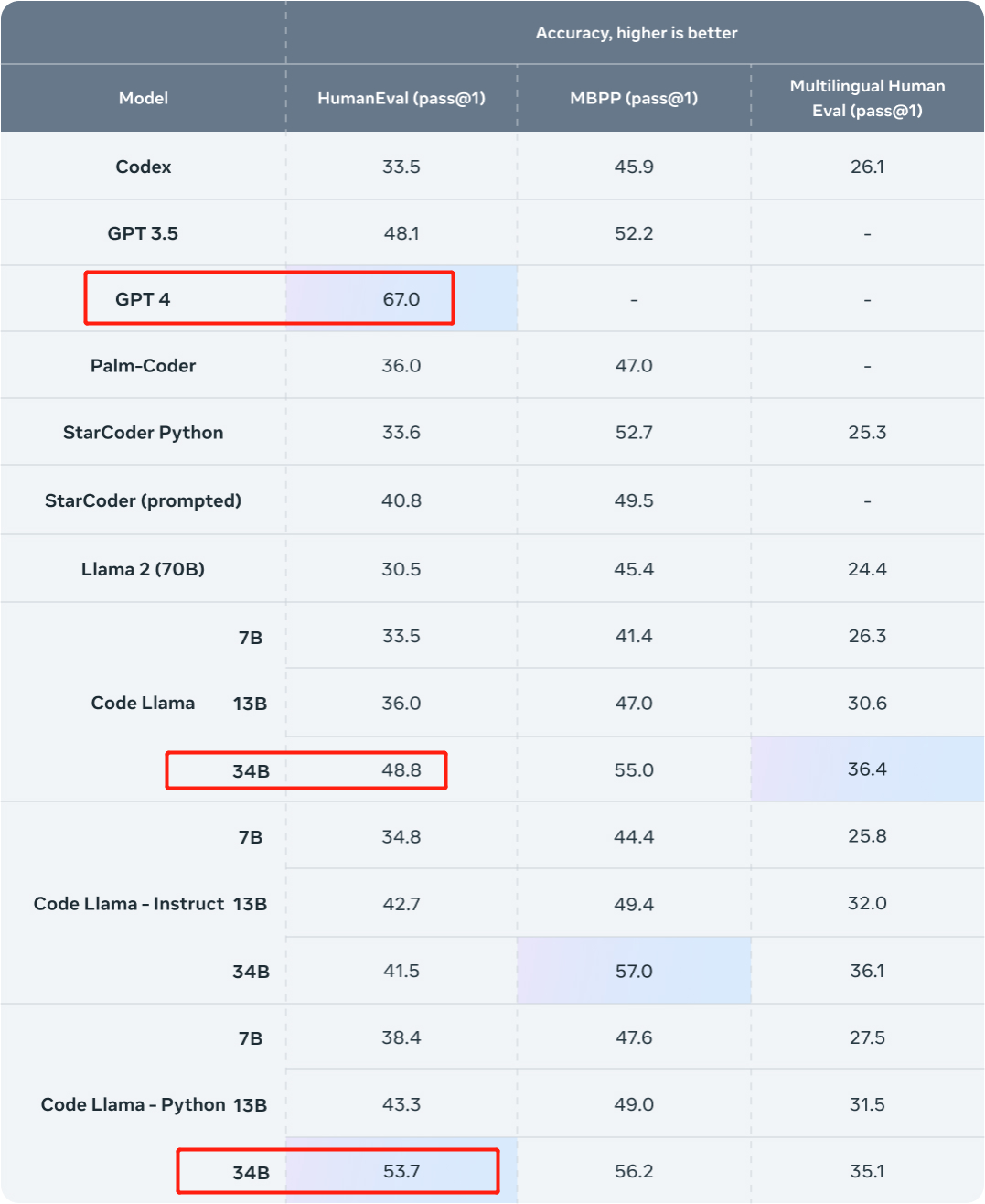
Mari kita lihat hasilnya dahulu. Kajian ini menggunakan set data dalaman Phind untuk memperhalusi Kod Llama-34B dan Kod Llama-34B-Python, menghasilkan dua model Phind-CodeLlama-34B-v1 dan Phind-CodeLlama-34B-Python-v1 masing-masing.
Dua model yang baru diperolehi masing-masing mencapai 67.6% dan 69.5% lulus@1 di HumanEval.
Sebagai perbandingan, CodeLlama-34B pass@1 ialah 48.8%; CodeLlama-34B-Python pass@1 ialah 53.7%.
Dan pas@1 GPT-4 pada HumanEval ialah 67% (data dikeluarkan oleh OpenAI dalam "Laporan Teknikal GPT-4" yang dikeluarkan pada Mac tahun ini).
Sumber imej: https://ai.meta.com/blog/code-llama-large-language-model-coding/
Sumber imej: https://cdn. openai.com/papers/gpt-4.pdfBercakap tentang penalaan halus, sudah tentu, set data amat diperlukan Kajian ini memperhalusi Kod Llama-34B dan Kod Llama-34B-Python pada set data proprietari yang mengandungi kira-kira 80,000 masalah dan penyelesaian pengaturcaraan berkualiti tinggi. Set data ini tidak mengambil contoh pelengkapan kod tetapi pasangan arahan-jawapan, yang berbeza daripada struktur data HumanEval. Kajian itu kemudian melatih model Phind selama dua zaman, dengan jumlah kira-kira 160,000 contoh. Para penyelidik berkata bahawa teknologi LoRA tidak digunakan dalam latihan, tetapi penalaan halus tempatan telah digunakan. Selain itu, kajian ini juga menggunakan teknologi DeepSpeed ZeRO 3 dan Flash Attention 2 Mereka menghabiskan tiga jam pada 32 A100-80GB GPU untuk melatih model ini, dengan panjang jujukan 4096 token. Selain itu, kajian itu juga menggunakan kaedah dekontaminasi OpenAI pada set data untuk menjadikan keputusan model lebih berkesan. Adalah diketahui bahawa walaupun GPT-4 yang sangat berkuasa akan menghadapi dilema pencemaran data Dari segi orang awam, model terlatih mungkin telah dilatih mengenai data penilaian. . data model. Jika ya, model boleh mengingati masalah ini dan jelas akan menunjukkan prestasi yang lebih baik pada masalah khusus ini apabila menilai model. Seolah-olah seseorang itu tahu soalan peperiksaan sebelum mengambil peperiksaan. Untuk menyelesaikan masalah ini, OpenAI mendedahkan cara GPT-4 menilai pencemaran data dalam dokumen teknikal GPT-4 awam "Laporan Teknikal GPT-4". Mereka mendedahkan strategi mereka untuk mengukur dan menilai pencemaran data ini. Secara khusus, OpenAI menggunakan padanan subrentetan untuk mengukur pencemaran silang antara set data penilaian dan data pra-latihan. Kedua-dua data penilaian dan latihan diproses dengan mengalih keluar semua ruang dan simbol, hanya meninggalkan aksara (termasuk nombor). Untuk setiap contoh penilaian, OpenAI secara rawak memilih tiga subrentetan 50 aksara (jika terdapat kurang daripada 50 aksara, keseluruhan contoh digunakan). Padanan ditentukan jika mana-mana daripada tiga subrentetan penilaian sampel ialah subrentetan contoh latihan yang diproses. Ini akan menghasilkan senarai contoh yang tercemar, yang OpenAI membuang dan menyiarkan semula untuk mendapatkan skor yang tidak tercemar. Tetapi kaedah penapisan ini mempunyai beberapa had, pemadanan subrentetan boleh membawa kepada negatif palsu (jika terdapat perbezaan kecil antara data penilaian dan latihan) serta positif palsu. Akibatnya, OpenAI hanya menggunakan sebahagian daripada maklumat dalam contoh penilaian, memanfaatkan soalan, konteks atau data yang setara sahaja, dan mengabaikan jawapan, respons atau data yang setara. Dalam sesetengah kes, pilihan berbilang pilihan juga dikecualikan. Pengecualian ini boleh menyebabkan peningkatan dalam positif palsu. Berkenaan bahagian ini, pembaca yang berminat boleh merujuk kertas untuk mengetahui lebih lanjut. Alamat kertas: https://cdn.openai.com/papers/gpt-4.pdfNamun, terdapat beberapa kontroversi mengenai markah HumanEval yang digunakan oleh Phind semasa menanda aras GPT-4. Sesetengah orang mengatakan bahawa markah ujian terkini GPT-4 telah mencapai 85%. Tetapi Phind menjawab bahawa penyelidikan berkaitan yang memperoleh skor ini tidak menjalankan penyelidikan pencemaran, dan adalah mustahil untuk menentukan sama ada GPT-4 telah melihat data ujian HumanEval apabila ia menerima pusingan ujian baharu. Memandangkan beberapa kajian terbaru tentang "GPT-4 menjadi bodoh", adalah lebih selamat untuk menggunakan data dalam laporan teknikal asal.
Namun, memandangkan kerumitan penilaian model yang besar, sama ada keputusan penilaian ini boleh mencerminkan keupayaan sebenar model masih menjadi isu kontroversi. Anda boleh memuat turun model dan mengalaminya sendiri.
Kandungan yang ditulis semula adalah seperti berikut: Pautan rujukan:
Kandungan yang perlu ditulis semula ialah: https://benjaminmarie.com/the-decontaminated-evaluation-of-gpt-4/
Kandungan yang perlu ditulis semula ialah Kandungannya ialah: https://www.phind.com/blog/code-llama-beats-gpt4
Atas ialah kandungan terperinci Keupayaan pengekodan Code Llama melonjak, dan versi HumanEval yang diperhalusi mendapat markah lebih baik daripada GPT-4 dan dikeluarkan dalam satu hari. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!


 Sejurus selepas sehari, seorang penyelidik melaporkan kepada GPT-4 Satu cabaran telah dilancarkan. Mereka datang dari Phind, sebuah organisasi yang bertujuan untuk membina enjin carian AI untuk pembangun, dan penyelidikan menggunakan Kod Llama-34B yang ditala dengan baik untuk mengalahkan GPT-4 dalam penilaian HumanEval.
Sejurus selepas sehari, seorang penyelidik melaporkan kepada GPT-4 Satu cabaran telah dilancarkan. Mereka datang dari Phind, sebuah organisasi yang bertujuan untuk membina enjin carian AI untuk pembangun, dan penyelidikan menggunakan Kod Llama-34B yang ditala dengan baik untuk mengalahkan GPT-4 dalam penilaian HumanEval. 
 Kandungan yang ditulis semula adalah seperti berikut: Pautan rujukan:
Kandungan yang ditulis semula adalah seperti berikut: Pautan rujukan: 
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



