

Dalam beberapa tahun kebelakangan ini, banyak penemuan mengejutkan telah dibuat dalam bidang imej yang dijana teks, dan banyak model mampu menghasilkan imej yang berkualiti tinggi dan pelbagai berdasarkan arahan teks. Walaupun imej yang dijana sudah sangat realistik, model semasa biasanya pandai menjana imej fizikal seperti landskap dan objek, tetapi menghadapi kesukaran menjana imej dengan butiran yang sangat koheren, seperti imej dengan teks glif kompleks seperti aksara Cina
Untuk menyelesaikan masalah ini Masalahnya, daripada Penyelidik dari OPPO dan institusi lain telah mencadangkan rangka kerja pembelajaran universal yang dipanggil GlyphDraw. Matlamat rangka kerja ini adalah untuk membolehkan model menjana imej yang dibenamkan dengan teks yang koheren. Karya ini adalah yang pertama untuk menyelesaikan masalah penjanaan watak Cina dalam bidang sintesis imej

Sila klik pautan berikut untuk melihat kertas: https://arxiv.org/abs/2303.17870
Pautan laman utama projek: https ://1073521013.github.io/glyph-draw.github.io/
Mari kita lihat kesan penjanaan dahulu, seperti menjana slogan amaran untuk dewan pameran:



 , penyelidikan telah menjana keputusan yang cemerlang. Sumbangan utama penyelidikan ini termasuk:
, penyelidikan telah menjana keputusan yang cemerlang. Sumbangan utama penyelidikan ini termasuk:

Pertama, set data penyelidikan membina imej strategi yang kompleks . Kemudian, menggunakan algoritma sintesis imej sumber terbuka Resapan Stabil, rangka kerja pembelajaran umum GlyphDraw dicadangkan, seperti ditunjukkan dalam Rajah 2. Matlamat keseluruhan latihan resapan stabil boleh dinyatakan sebagai formula berikut:
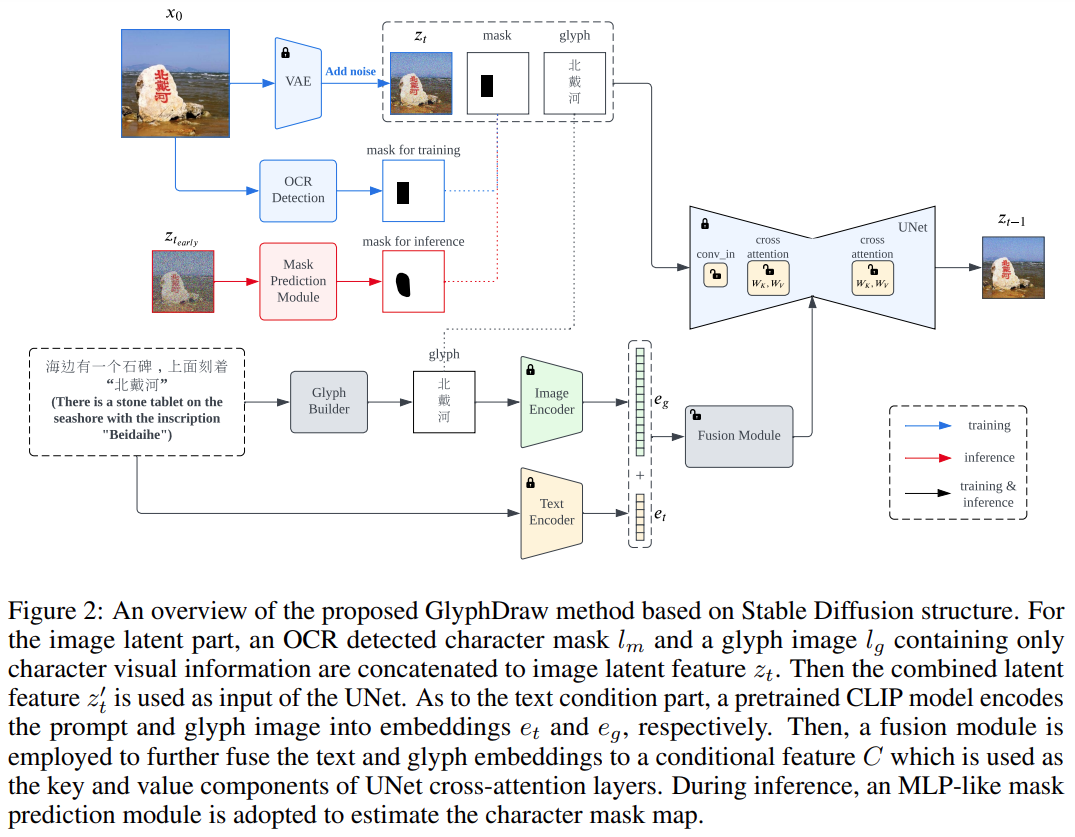 GlyphDraw adalah berdasarkan Stabil Mekanisme perhatian silang dalam Resapan. Ia melakukan penggantian lata bagi vektor pendam z_t input asal dengan vektor pendam z_t imej, topeng teks l_m dan imej glyph l_g
GlyphDraw adalah berdasarkan Stabil Mekanisme perhatian silang dalam Resapan. Ia melakukan penggantian lata bagi vektor pendam z_t input asal dengan vektor pendam z_t imej, topeng teks l_m dan imej glyph l_g
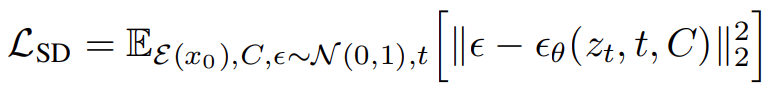 Tambahan pula, dengan menggunakan modul gabungan khusus domain, keadaan C ialah dilengkapi dengan glif bercampur dan ciri teks. Pengenalan topeng teks dan maklumat glif membolehkan keseluruhan proses latihan mencapai kawalan resapan halus, yang merupakan komponen utama untuk meningkatkan prestasi model dan akhirnya dapat menjana imej dengan teks aksara Cina
Tambahan pula, dengan menggunakan modul gabungan khusus domain, keadaan C ialah dilengkapi dengan glif bercampur dan ciri teks. Pengenalan topeng teks dan maklumat glif membolehkan keseluruhan proses latihan mencapai kawalan resapan halus, yang merupakan komponen utama untuk meningkatkan prestasi model dan akhirnya dapat menjana imej dengan teks aksara Cina
Khususnya, perwakilan piksel maklumat teks , terutamanya dalam bentuk teks yang kompleks, seperti aksara Cina piktografi, terdapat perbezaan yang jelas daripada objek semula jadi. Sebagai contoh, perkataan Cina "langit" terdiri daripada berbilang strok dalam struktur dua dimensi, dan imej semula jadi yang sepadan ialah "langit biru bertitik awan putih." Sebaliknya, aksara Cina mempunyai butiran yang sangat halus dan pergerakan atau ubah bentuk kecil pun boleh menyebabkan teks menjadi tidak betul, menjadikan penjanaan imej mustahil
Membenamkan aksara ke dalam latar belakang imej semula jadi juga memerlukan pertimbangan isu utama, iaitu mengawal penjanaan piksel teks dengan tepat tanpa menjejaskan piksel imej semula jadi bersebelahan. Untuk memaparkan aksara Cina yang sempurna pada imej semula jadi, pengarang mereka bentuk dua komponen utama, iaitu kawalan kedudukan dan kawalan glif, yang disepadukan ke dalam model sintesis resapan
Tidak seperti input bersyarat global model lain, penjanaan aksara memerlukan lebih Fokus pada kawasan setempat tertentu bagi imej kerana taburan ciri terpendam bagi piksel aksara adalah sangat berbeza daripada piksel imej semula jadi. Untuk mengelakkan pembelajaran model daripada runtuh, kajian ini secara inovatif mencadangkan kawalan kawasan kedudukan berbutir halus untuk memisahkan taburan antara kawasan berbeza
Kandungan bertulis semula: Selain kawalan kedudukan, satu lagi isu penting ialah sintesis strok aksara Cina Dapatkan kawalan halus . Memandangkan kerumitan dan kepelbagaian aksara Cina, adalah sangat sukar untuk hanya belajar daripada set data teks imej yang besar tanpa sebarang pengetahuan terdahulu yang jelas. Untuk menjana aksara Cina dengan tepat, kajian ini memperkenalkan imej glif eksplisit sebagai maklumat bersyarat tambahan ke dalam proses penyebaran model
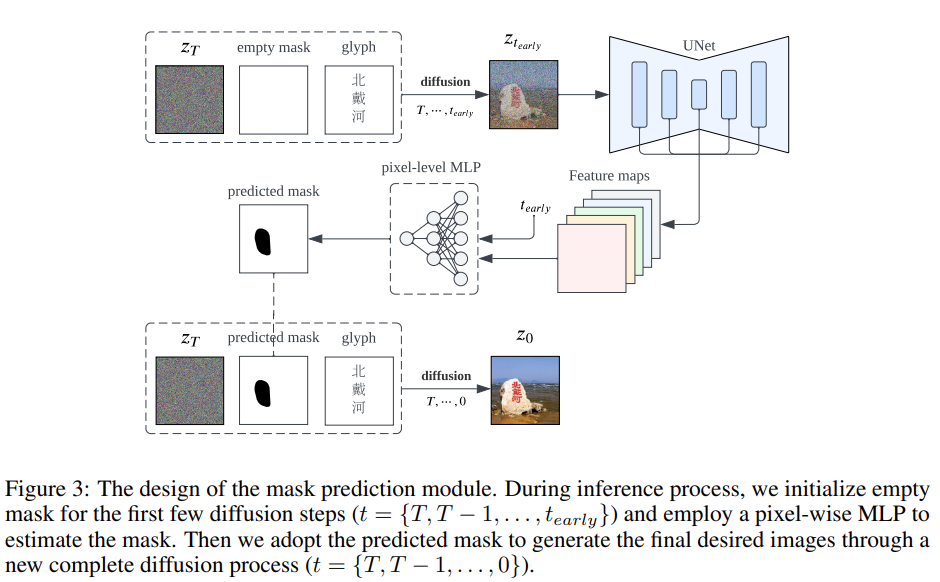
Untuk mengekalkan maksud asal tidak berubah, kandungan perlu ditulis semula ke dalam bahasa Cina berikut ialah kandungan yang ditulis semula: Reka Bentuk Penyelidikan dan Hasil Eksperimen
Memandangkan tiada set data sebelumnya khusus untuk penjanaan imej aksara Cina, kajian ini mula-mula mencipta set data penanda aras ChineseDrawText untuk penilaian kualitatif dan kuantitatif. Selepas itu, penyelidik menguji ketepatan penjanaan beberapa kaedah pada ChineseDrawText dan menilainya melalui model pengecaman OCR
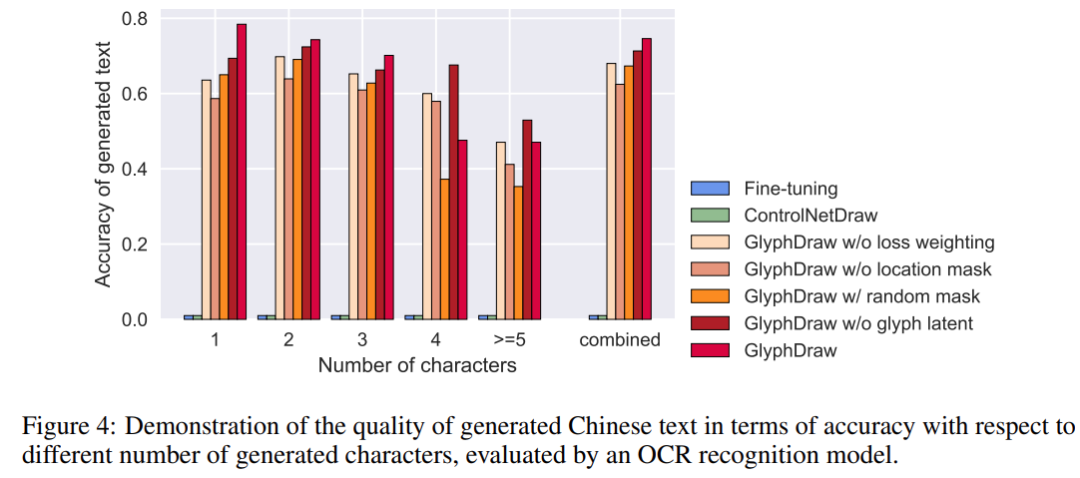
Model GlyphDraw yang dicadangkan dalam kajian ini mencapai ketepatan purata dengan menggunakan sepenuhnya maklumat glif dan kedudukan tambahan. sebanyak 75% membuktikan keupayaan cemerlang model dalam penjanaan imej watak. Rajah di bawah menunjukkan hasil perbandingan visual beberapa kaedah

Selain itu, GlyphDraw juga boleh mengekalkan prestasi sintesis imej domain terbuka dengan mengehadkan parameter latihan Pada MS-COCO FID-10k, FID sintesis imej umum hanya dihentikan 2.3


Pembaca yang berminat boleh membaca teks asal kertas kerja untuk mengetahui lebih banyak butiran penyelidikan.
Atas ialah kandungan terperinci OPPO mencadangkan GlyphDraw: generasi satu klik imej dengan aksara Cina, model resapan kepada mengeluarkan emotikon. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penggunaan uniqueResult
Penggunaan uniqueResult
 pangkalan data phpstudy tidak boleh memulakan penyelesaian
pangkalan data phpstudy tidak boleh memulakan penyelesaian
 Bagaimana untuk mencari nilai maksimum dan minimum elemen tatasusunan dalam Java
Bagaimana untuk mencari nilai maksimum dan minimum elemen tatasusunan dalam Java
 Pengenalan kepada maksud javascript
Pengenalan kepada maksud javascript
 Bagaimana untuk menangani muat turun fail yang disekat dalam Windows 10
Bagaimana untuk menangani muat turun fail yang disekat dalam Windows 10
 Apakah fungsi tetingkap?
Apakah fungsi tetingkap?
 Bagaimana untuk mengosongkan ruang dokumen awan WPS apabila ia penuh?
Bagaimana untuk mengosongkan ruang dokumen awan WPS apabila ia penuh?
 Perbezaan antara rom dan ram
Perbezaan antara rom dan ram








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



