
 pembangunan bahagian belakang
C++
Program C++: susun semula kedudukan perkataan dalam susunan abjad
pembangunan bahagian belakang
C++
Program C++: susun semula kedudukan perkataan dalam susunan abjad
Program C++: susun semula kedudukan perkataan dalam susunan abjad


Dalam masalah ini, rentetan diberikan sebagai input dan kita perlu mengisih perkataan yang terdapat dalam rentetan dalam susunan leksikografi. Untuk melakukan ini, kami menetapkan indeks bermula dari 1 kepada setiap perkataan dalam rentetan (dipisahkan oleh ruang) dan mendapatkan output sebagai indeks yang diisih.
String = {“Hello”, “World”}
“Hello” = 1
“World” = 2
Memandangkan perkataan dalam rentetan input telah disusun dalam susunan leksikografi, output akan dicetak sebagai "1 2".
Mari lihat beberapa senario input/hasil -
Dengan mengandaikan semua perkataan dalam rentetan input adalah sama, mari lihat hasilnya -
Input: {“hello”, “hello”, “hello”}
Result: 3
Hasil yang diperolehi akan menjadi kedudukan terakhir perkataan.
Sekarang mari kita pertimbangkan rentetan input yang mengandungi perkataan yang bermula dengan huruf yang sama, output yang terhasil akan berdasarkan huruf seterusnya bagi huruf permulaan.
Input: {“Title”, “Tutorial”, “Truth”}
Result: 1 3 2
Satu lagi senario input biasa untuk kaedah ini dan keputusan yang diperoleh adalah seperti berikut -
Input: {“Welcome”, “To”, “Tutorialspoint”}
Result: 2 3 1
Nota - Kedudukan yang dikembalikan ialah kedudukan asal perkataan ini dalam rentetan input. Nombor ini tidak berubah setelah perkataan diisih dalam kaedah.
Algoritma
Kaedah ini dilakukan menggunakan vektor dan jenis data abstrak peta.
Gunakan lelaran automatik untuk melintasi rentetan input dalam julat rentetan.
Pertukaran abjad perkataan dilakukan dengan menolak elemen ini ke belakang jenis data vektor.
Setelah perkataan disusun semula secara leksikografi, kedudukan asal perkataan tersebut dalam rentetan dikembalikan sebagai output.
Contoh
Mari kita mempunyai rentetan iaitu ["artikel", "titik", "dunia"], dan susunan rentetan itu ialah -
“articles”: 1 “point”: 2 “world”: 3
Kita boleh memetakan setiap rentetan dengan indeks. Kami kemudiannya boleh mengisih rentetan dan mencetak indeks peta. Kita boleh menggunakan peta, struktur data yang diisih dalam C++, untuk menyimpan pasangan nilai kunci. Mari kita cepat melaksanakan pendekatan kita.
#include <iostream>
#include <vector>
#include <map>
using namespace std;
vector<int> solve(vector<string>& arr) {
map<string, int> mp;
int index = 1;
for(string s : arr)
mp[s] = index++;
vector<int> res;
for(auto it : mp)
res.push_back(it.second);
return res;
}
int main() {
vector<string> arr = {"articles", "point", "world"};
vector<int> res = solve(arr);
for(int i : res) cout << i << " ";
return 0;
}
Output
1 2 3
Kini susunan semula rentetan akan menjadi -
“point,” “articles,” “world”
Kerumitan masa - O(n * log n)
Kerumitan ruang - O(n)
KESIMPULAN
Kami menggunakan peta untuk mengisih dan memetakan sesuatu untuk kami. Kita juga boleh menggunakan peta cincang, mengisih vektor atau tatasusunan, dan kemudian mencetak indeks dalam peta cincang. Kerumitan masa ialah O(n*log(n)) dan kerumitan ruang ialah O(n).
Atas ialah kandungan terperinci Program C++: susun semula kedudukan perkataan dalam susunan abjad. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

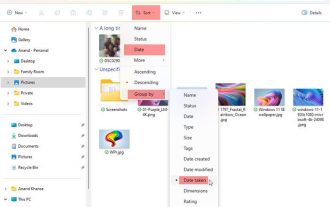 Bagaimana untuk mengisih foto mengikut tarikh yang diambil dalam Windows 11/10
Feb 19, 2024 pm 08:45 PM
Bagaimana untuk mengisih foto mengikut tarikh yang diambil dalam Windows 11/10
Feb 19, 2024 pm 08:45 PM
Artikel ini akan memperkenalkan cara mengisih gambar mengikut tarikh penangkapan dalam Windows 11/10, dan juga membincangkan perkara yang perlu dilakukan jika Windows tidak menyusun gambar mengikut tarikh. Dalam sistem Windows, menyusun foto dengan betul adalah penting untuk memudahkan anda mencari fail imej. Pengguna boleh mengurus folder yang mengandungi foto berdasarkan kaedah pengisihan yang berbeza seperti tarikh, saiz dan nama. Selain itu, anda boleh menetapkan tertib menaik atau menurun mengikut keperluan untuk menyusun fail dengan lebih fleksibel. Cara Isih Foto mengikut Tarikh Diambil dalam Windows 11/10 Untuk mengisih foto mengikut tarikh yang diambil dalam Windows, ikut langkah berikut: Buka Gambar, Desktop atau mana-mana folder tempat anda meletakkan foto Dalam menu Reben, klik
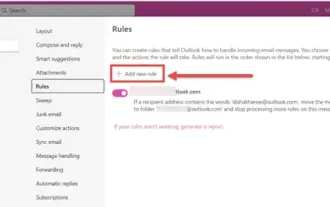 Cara mengisih e-mel mengikut penghantar, subjek, tarikh, kategori, saiz dalam Outlook
Feb 19, 2024 am 10:48 AM
Cara mengisih e-mel mengikut penghantar, subjek, tarikh, kategori, saiz dalam Outlook
Feb 19, 2024 am 10:48 AM
Outlook menawarkan banyak tetapan dan ciri untuk membantu anda mengurus kerja anda dengan lebih cekap. Salah satunya ialah pilihan pengisihan yang membolehkan anda mengkategorikan e-mel anda mengikut keperluan anda. Dalam tutorial ini, kami akan mempelajari cara menggunakan ciri pengisihan Outlook untuk menyusun e-mel berdasarkan kriteria seperti pengirim, subjek, tarikh, kategori atau saiz. Ini akan memudahkan anda memproses dan mencari maklumat penting, menjadikan anda lebih produktif. Microsoft Outlook ialah aplikasi berkuasa yang memudahkan untuk mengurus jadual e-mel dan kalendar anda secara berpusat. Anda boleh menghantar, menerima dan mengatur e-mel dengan mudah, manakala fungsi kalendar terbina dalam memudahkan untuk menjejaki acara dan janji temu anda yang akan datang. Bagaimana untuk berada di Outloo
 Menapis dan menyusun data XML menggunakan Python
Aug 07, 2023 pm 04:17 PM
Menapis dan menyusun data XML menggunakan Python
Aug 07, 2023 pm 04:17 PM
Melaksanakan penapisan dan pengisihan data XML menggunakan Python Pengenalan: XML ialah format pertukaran data yang biasa digunakan yang menyimpan data dalam bentuk teg dan atribut. Apabila memproses data XML, kami selalunya perlu menapis dan mengisih data. Python menyediakan banyak alat dan perpustakaan yang berguna untuk memproses data XML. Artikel ini akan memperkenalkan cara menggunakan Python untuk menapis dan mengisih data XML. Membaca fail XML Sebelum kita mula, kita perlu membaca fail XML. Python mempunyai banyak perpustakaan pemprosesan XML,
 Pembangunan PHP: Bagaimana untuk melaksanakan pengisihan data jadual dan fungsi halaman
Sep 20, 2023 am 11:28 AM
Pembangunan PHP: Bagaimana untuk melaksanakan pengisihan data jadual dan fungsi halaman
Sep 20, 2023 am 11:28 AM
Pembangunan PHP: Bagaimana untuk melaksanakan fungsi pengisihan data jadual dan halaman Dalam pembangunan web, memproses sejumlah besar data adalah tugas biasa. Untuk jadual yang perlu memaparkan sejumlah besar data, biasanya perlu melaksanakan fungsi pengisihan dan halaman untuk memberikan pengalaman pengguna yang baik dan mengoptimumkan prestasi sistem. Artikel ini akan memperkenalkan cara menggunakan PHP untuk melaksanakan fungsi pengisihan dan halaman data jadual, dan memberikan contoh kod khusus. Fungsi pengisihan melaksanakan fungsi pengisihan dalam jadual, membolehkan pengguna mengisih dalam tertib menaik atau menurun mengikut medan yang berbeza. Berikut ialah borang pelaksanaan
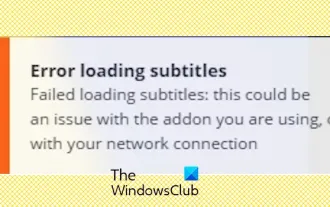 Sari kata Stremio tidak berfungsi; ralat memuatkan sari kata
Feb 24, 2024 am 09:50 AM
Sari kata Stremio tidak berfungsi; ralat memuatkan sari kata
Feb 24, 2024 am 09:50 AM
Sarikata tidak berfungsi pada Stremio pada PC Windows anda? Sesetengah pengguna Stremio melaporkan bahawa sari kata tidak dipaparkan dalam video. Ramai pengguna melaporkan mengalami mesej ralat yang mengatakan "Ralat memuatkan sari kata." Berikut ialah mesej ralat penuh yang muncul dengan ralat ini: Ralat berlaku semasa memuatkan sari kata Gagal memuatkan sari kata: Ini mungkin masalah dengan pemalam yang anda gunakan atau rangkaian anda. Seperti yang dikatakan oleh mesej ralat, mungkin sambungan internet anda yang menyebabkan ralat. Jadi sila semak sambungan rangkaian anda dan pastikan internet anda berfungsi dengan baik. Selain itu, mungkin terdapat sebab lain di sebalik ralat ini, termasuk sarikata yang bercanggah, sari kata yang tidak disokong untuk kandungan video tertentu dan apl Stremio yang sudah lapuk. suka
 Bagaimanakah kaedah Arrays.sort() dalam Java menyusun tatasusunan mengikut pembanding tersuai?
Nov 18, 2023 am 11:36 AM
Bagaimanakah kaedah Arrays.sort() dalam Java menyusun tatasusunan mengikut pembanding tersuai?
Nov 18, 2023 am 11:36 AM
Bagaimanakah kaedah Arrays.sort() dalam Java menyusun tatasusunan mengikut pembanding tersuai? Di Java, kaedah Arrays.sort() ialah kaedah yang sangat berguna untuk menyusun tatasusunan. Secara lalai, kaedah ini disusun mengikut tertib menaik. Tetapi kadangkala, kita perlu mengisih tatasusunan mengikut peraturan yang ditentukan sendiri. Pada masa ini, anda perlu menggunakan pembanding tersuai (Comparator). Pembanding tersuai ialah kelas yang melaksanakan antara muka Pembanding.
 Program C++: susun semula kedudukan perkataan dalam susunan abjad
Sep 01, 2023 pm 11:37 PM
Program C++: susun semula kedudukan perkataan dalam susunan abjad
Sep 01, 2023 pm 11:37 PM
Dalam masalah ini, rentetan diberikan sebagai input dan kita perlu mengisih perkataan yang terdapat dalam rentetan dalam susunan leksikografi. Untuk melakukan ini, kami menetapkan indeks bermula dari 1 kepada setiap perkataan dalam rentetan (dipisahkan oleh ruang) dan mendapatkan output dalam bentuk indeks yang diisih. String={"Hello","World"}"Hello"=1 "World"=2 Memandangkan perkataan dalam rentetan input adalah dalam susunan leksikografi, output akan mencetak "12". Mari lihat beberapa senario input/hasil - dengan mengandaikan semua perkataan dalam rentetan input adalah sama, mari lihat keputusan - Input:{"hello","hello","hello"}Result:3 Keputusan diperoleh
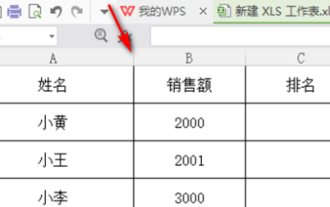 Bagaimana untuk mengisih markah WPS
Mar 20, 2024 am 11:28 AM
Bagaimana untuk mengisih markah WPS
Mar 20, 2024 am 11:28 AM
Dalam kerja kami, kami sering menggunakan perisian wps Terdapat banyak cara untuk memproses data dalam perisian wps, dan fungsinya juga sangat berkuasa Kami sering menggunakan fungsi untuk mencari purata, ringkasan, dan sebagainya kaedah yang boleh digunakan untuk data statistik telah disediakan untuk semua orang dalam perpustakaan perisian WPS Di bawah kami akan memperkenalkan langkah-langkah bagaimana untuk mengisih markah dalam WPS Selepas membaca ini, anda boleh belajar daripada pengalaman. 1. Mula-mula buka jadual yang perlu diberi ranking. Seperti yang ditunjukkan di bawah. 2. Kemudian masukkan formula =pangkat(B2, B2: B5, 0), dan pastikan anda memasukkan 0. Seperti yang ditunjukkan di bawah. 3. Selepas memasukkan formula, tekan kekunci F4 pada papan kekunci komputer Langkah ini adalah untuk menukar rujukan relatif kepada rujukan mutlak.
