

Pengikisan metadata menggunakan New York Times API

简介
上周,我写了一篇关于抓取网页以收集元数据的介绍,并提到不可能抓取《纽约时报》网站。 《纽约时报》付费墙会阻止您收集基本元数据的尝试。但有一种方法可以使用纽约时报 API 来解决这个问题。
最近我开始在 Yii 平台上构建一个社区网站,我将在以后的教程中发布该网站。我希望能够轻松添加与网站内容相关的链接。虽然人们可以轻松地将 URL 粘贴到表单中,但提供标题和来源信息却非常耗时。
因此,在今天的教程中,我将扩展我最近编写的抓取代码,以在添加《纽约时报》链接时利用《纽约时报》API 来收集头条新闻。
请记住,我参与了下面的评论主题,所以请告诉我您的想法!您还可以通过 Twitter @lookahead_io 与我联系。
开始使用
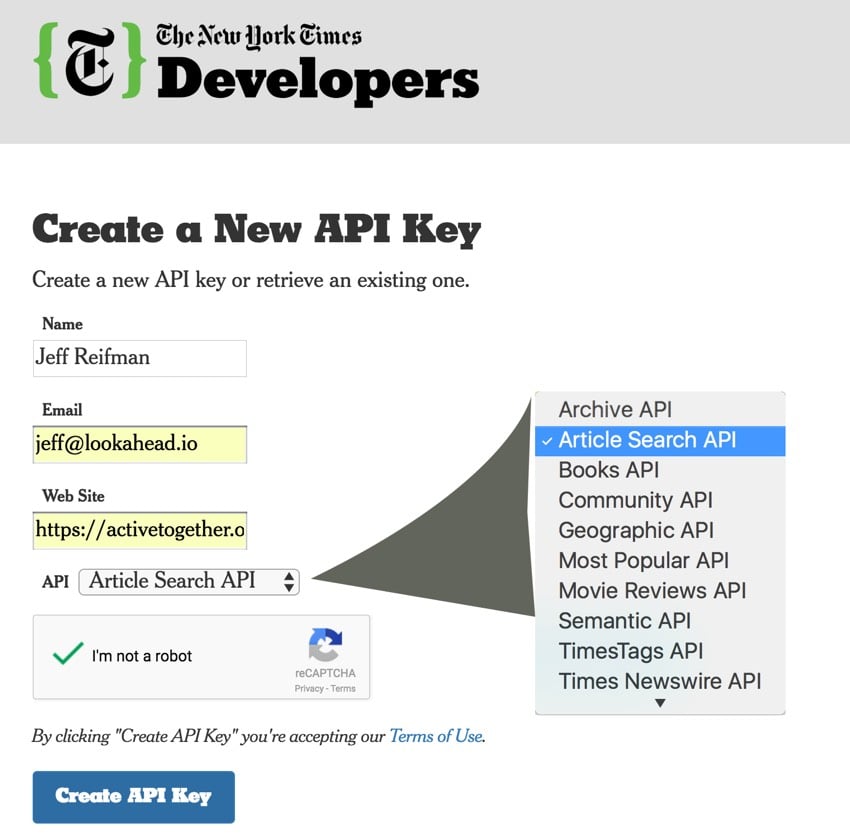
注册 API 密钥

首先,让我们注册并请求 API 密钥:
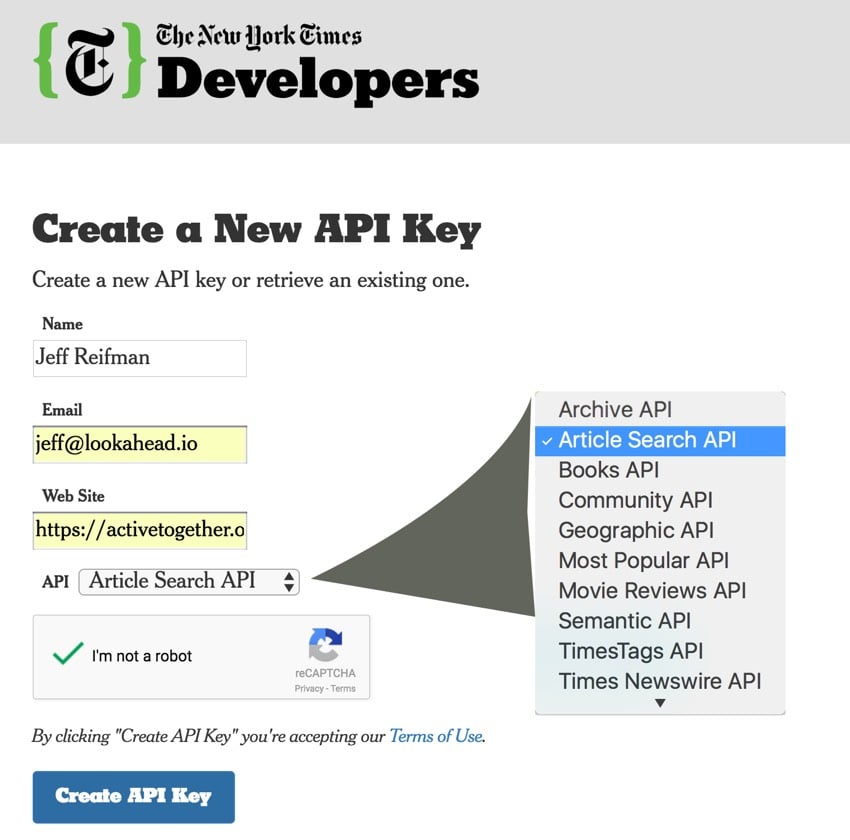
提交表单后,您将通过电子邮件收到密钥:
探索纽约时报 API

The Times 提供以下类别的 API:
- 存档
- 文章搜索
- 书籍
- 社区
- 地理
- 最受欢迎
- 电影评论
- 语义
- 泰晤士报
- 时代标签
- 头条新闻
很多。并且,在“图库”页面中,您可以单击任何主题来查看各个 API 类别文档:
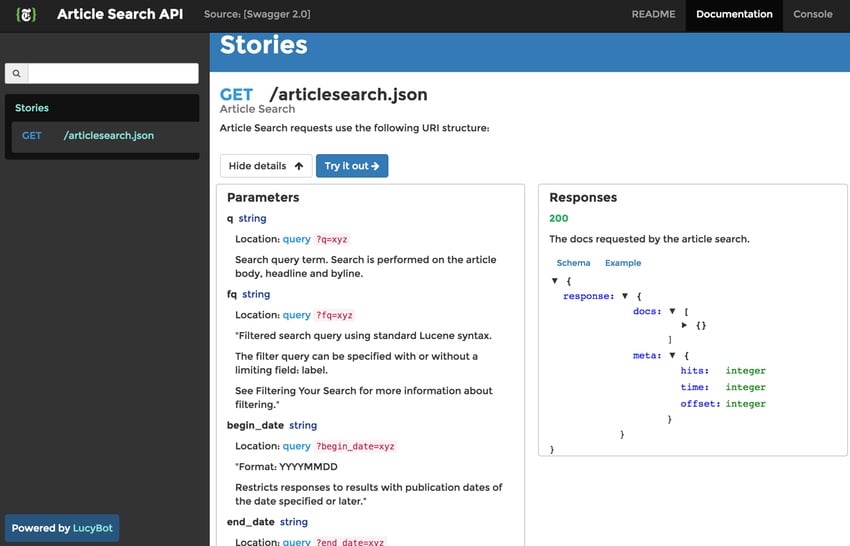
《纽约时报》使用 LucyBot 为其 API 文档提供支持,并且有一个有用的常见问题解答:

他们甚至向您展示如何快速获取 API 使用限制(您需要插入密钥):
curl --head
https://api.nytimes.com/svc/books/v3/lists/overview.json?api-key=<your-api-key>
2>/dev/null | grep -i "X-RateLimit"
X-RateLimit-Limit-day: 1000
X-RateLimit-Limit-second: 5
X-RateLimit-Remaining-day: 180
X-RateLimit-Remaining-second: 5
我最初很难理解该文档 - 它是基于参数的规范,而不是编程指南。不过,我在纽约时报 API GitHub 页面上发布了一些问题,这些问题很快就得到了有用的解答。
使用文章搜索
在今天的节目中,我将重点介绍如何使用《纽约时报》文章搜索。基本上,我们将扩展上一个教程中的创建链接表单:
当用户点击查找时,我们将向 链接::grab($url)。这是 jQuery:
$(document).on("click", '[id=lookup]', function(event) {
$.ajax({
url: $('#url_prefix').val()+'/link/grab',
data: {url: $('#url').val()},
success: function(data) {
$('#title').val(data);
return true;
}
});
});
这是控制器和模型方法:
// Controller call via AJAX Lookup request
public static function actionGrab($url) {
Yii::$app->response->format = Response::FORMAT_JSON;
return Link::grab($url);
}
...
// Link::grab() method
public static function grab($url) {
//clean up url for hostname
$source_url = parse_url($url);
$source_url = $source_url['host'];
$source_url=str_ireplace('www.','',$source_url);
$source_url = trim($source_url,' \\');
// use the NYT API when hostname == nytimes.com
if ($source_url=='nytimes.com') {
...
接下来,让我们使用 API 密钥发出文章搜索请求:
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com
/svc/search/v2/articlesearch.json?fl=headline&fq=web_url:%22'.
$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
$title = $result->response->docs[0]->headline->main;
} else {
// not NYT, use the standard metatag scraper from last episode
...
}
}
return $title;
}
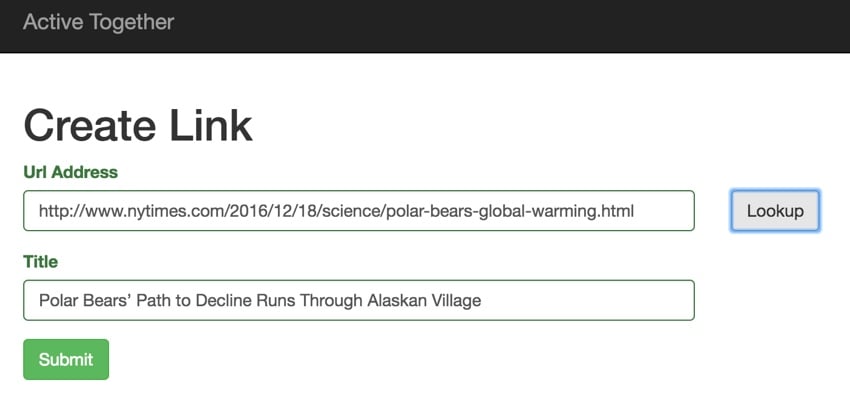
它的工作原理非常简单 - 这是生成的标题(顺便说一句,气候变化正在杀死北极熊,我们应该关心):
如果您想了解 API 请求的更多详细信息,只需向 ?fl 添加其他参数即可=headline 请求例如 关键字 和 lead_paragraph:
Yii::$app->response->format = Response::FORMAT_JSON; $nytKey=Yii::$app->params['nytapi']; $curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'. 'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey; $curl = curl_init(); curl_setopt($curl, CURLOPT_RETURNTRANSFER, true); curl_setopt($curl, CURLOPT_URL,$curl_dest); $result = json_decode(curl_exec($curl)); var_dump($result);
结果如下:

也许我会在接下来的剧集中编写一个 PHP 库来更好地解析 NYT API,但此代码打破了关键字和引导段落:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
echo $result->response->docs[0]->headline->main.'<br />'.'<br />';
echo $result->response->docs[0]->lead_paragraph.'<br />'.'<br />';
foreach ($result->response->docs[0]->keywords as $k) {
echo $k->value.'<br/>';
}
以下是本文显示的内容:
Polar Bears’ Path to Decline Runs Through Alaskan Village The bears that come here are climate refugees, on land because the sea ice they rely on for hunting seals is receding. Polar Bears Greenhouse Gas Emissions Alaska Global Warming Endangered and Extinct Species International Union for Conservation of Nature National Snow and Ice Data Center Polar Bears International United States Geological Survey
希望这能开始扩展您对如何使用这些 API 的想象力。现在可能实现的事情非常令人兴奋。
结束中
纽约时报 API 非常有用,我很高兴看到他们向开发者社区提供它。通过 GitHub 获得如此快速的 API 支持也令人耳目一新——我只是没想到会这样。请记住,它适用于非商业项目。如果您有一些赚钱的想法,请给他们留言,看看他们是否愿意与您合作。出版商渴望新的收入来源。
Saya harap anda mendapati coretan pengikisan web ini membantu dan melaksanakannya ke dalam projek anda. Jika anda ingin menonton rancangan hari ini, anda boleh mencuba beberapa web mengikis di tapak web saya Active Together .
Sila kongsi sebarang pendapat dan maklum balas dalam komen. Anda juga boleh menghubungi saya terus di Twitter @lookahead_io pada bila-bila masa. Pastikan anda menyemak halaman pengajar saya dan siri lain: Membina Permulaan Anda dengan PHP dan Pengaturcaraan dengan Yii2.
Pautan berkaitan
- Perpustakaan API New York Times
- Spesifikasi API Awam New York Times di GitHub
- Cara mengambil metadata dari halaman web (Envato Tuts+)
- Cara merangkak halaman web menggunakan Node.js dan jQuery (Envato Tuts+)
- Bina Pengikis Web pertama anda dengan Ruby (Envato Tuts+)
Atas ialah kandungan terperinci Pengikisan metadata menggunakan New York Times API. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1359
1359
 52
52

 Pengikisan metadata menggunakan New York Times API
Sep 02, 2023 pm 10:13 PM
Pengikisan metadata menggunakan New York Times API
Sep 02, 2023 pm 10:13 PM
Pengenalan Minggu lepas, saya menulis pengenalan tentang mengikis halaman web untuk mengumpul metadata, dan menyebut bahawa adalah mustahil untuk mengikis laman web New York Times. The New York Times paywall menyekat percubaan anda untuk mengumpul metadata asas. Tetapi ada cara untuk menyelesaikan masalah ini menggunakan API New York Times. Baru-baru ini saya mula membina tapak web komuniti pada platform Yii, yang akan saya terbitkan dalam tutorial akan datang. Saya mahu dapat menambahkan pautan yang berkaitan dengan kandungan tapak dengan mudah. Walaupun orang ramai boleh menampal URL ke dalam borang dengan mudah, memberikan tajuk dan maklumat sumber memakan masa. Jadi dalam tutorial hari ini saya akan melanjutkan kod mengikis yang saya tulis baru-baru ini untuk memanfaatkan New York Times API untuk mengumpulkan tajuk berita apabila menambah pautan ke New York Times. Ingat, saya terlibat
 Akses metadata pelbagai fail audio dan video menggunakan Python
Sep 05, 2023 am 11:41 AM
Akses metadata pelbagai fail audio dan video menggunakan Python
Sep 05, 2023 am 11:41 AM
Kami boleh mengakses metadata fail audio menggunakan Mutagen dan modul eyeD3 dalam Python. Untuk metadata video kita boleh menggunakan filem dan perpustakaan OpenCV dalam Python. Metadata ialah data yang menyediakan maklumat tentang data lain, seperti data audio dan video. Metadata untuk fail audio dan video termasuk format fail, resolusi fail, saiz fail, tempoh, kadar bit, dsb. Dengan mengakses metadata ini, kami boleh mengurus media dengan lebih cekap dan menganalisis metadata untuk mendapatkan beberapa maklumat berguna. Dalam artikel ini, kita akan melihat beberapa perpustakaan atau modul yang disediakan oleh Python untuk mengakses metadata fail audio dan video. Akses metadata audio Sesetengah perpustakaan untuk mengakses metadata fail audio adalah - menggunakan mutagenesis
 Bagaimana untuk merangkak dan memproses data dengan memanggil antara muka API dalam projek PHP?
Sep 05, 2023 am 08:41 AM
Bagaimana untuk merangkak dan memproses data dengan memanggil antara muka API dalam projek PHP?
Sep 05, 2023 am 08:41 AM
Bagaimana untuk merangkak dan memproses data dengan memanggil antara muka API dalam projek PHP? 1. Pengenalan Dalam projek PHP, kita selalunya perlu merangkak data dari tapak web lain dan memproses data ini. Banyak tapak web menyediakan antara muka API, dan kami boleh mendapatkan data dengan memanggil antara muka ini. Artikel ini akan memperkenalkan cara menggunakan PHP untuk memanggil antara muka API untuk merangkak dan memproses data. 2. Dapatkan URL dan parameter antara muka API Sebelum memulakan, kita perlu mendapatkan URL antara muka API sasaran dan parameter yang diperlukan.
 Microsoft melancarkan bahasa definisi model jadual baharu untuk Power BI
Apr 13, 2023 pm 04:13 PM
Microsoft melancarkan bahasa definisi model jadual baharu untuk Power BI
Apr 13, 2023 pm 04:13 PM
Microsoft telah mengumumkan tarikh tamat sokongan untuk Power BI Desktop pada Windows 8.1. Baru-baru ini, platform analitik data utama gergasi teknologi itu turut memperkenalkan sokongan TypeScript dan ciri baharu yang lain. Hari ini, Bahasa Definisi Model Tabular (TMDL) baharu untuk Power BI telah dilancarkan dan kini tersedia dalam pratonton awam. TMDL diperlukan kerana fail BIM yang sangat kompleks yang diekstrak daripada model data semantik besar yang dibuat menggunakan Power BI. Secara tradisinya mengandungi metadata model dalam Bahasa Skrip Model Tabular (TMSL), fail ini dianggap sukar untuk diproses lebih lanjut. Selain itu, dengan berbilang pembangun yang sedang bekerja
 Ringkasan pengalaman pembangunan Vue: petua untuk mengoptimumkan SEO dan merangkak enjin carian
Nov 22, 2023 am 10:56 AM
Ringkasan pengalaman pembangunan Vue: petua untuk mengoptimumkan SEO dan merangkak enjin carian
Nov 22, 2023 am 10:56 AM
Ringkasan pengalaman pembangunan Vue: Petua untuk mengoptimumkan SEO dan merangkak enjin carian Dengan perkembangan pesat Internet, laman web SEO (SearchEngineOptimization, pengoptimuman enjin carian) telah menjadi semakin penting. Untuk tapak web yang dibangunkan menggunakan Vue, pengoptimuman untuk SEO dan merangkak enjin carian adalah penting. Artikel ini akan meringkaskan beberapa pengalaman pembangunan Vue dan berkongsi beberapa petua untuk mengoptimumkan SEO dan rangkak enjin carian. Menggunakan teknologi prapaparan Vue
 Bagaimana untuk menambah metadata ke DataFrame atau Siri menggunakan Pandas dalam Python?
Aug 19, 2023 pm 08:33 PM
Bagaimana untuk menambah metadata ke DataFrame atau Siri menggunakan Pandas dalam Python?
Aug 19, 2023 pm 08:33 PM
Ciri utama Pandas ialah keupayaan untuk mengendalikan metadata yang boleh memberikan maklumat tambahan tentang data yang terdapat dalam DataFrame atau Siri. Pandas ialah perpustakaan yang berkuasa dan digunakan secara meluas dalam Python untuk manipulasi dan analisis data. Dalam artikel ini, kami akan meneroka cara menambah metadata pada DataFrame atau Siri dalam Python menggunakan Pandas. Apakah metadata dalam Pandas? Metadata ialah maklumat tentang data dalam DataFrame atau Siri. Ia boleh termasuk jenis data tentang lajur, unit ukuran atau sebarang maklumat penting dan berkaitan lain untuk menyediakan konteks tentang data yang disediakan. Anda boleh menggunakan Panda untuk
 Bagaimana untuk menggunakan perpustakaan kelas PHP Goutte untuk merangkak web dan pengekstrakan data?
Aug 09, 2023 pm 02:16 PM
Bagaimana untuk menggunakan perpustakaan kelas PHP Goutte untuk merangkak web dan pengekstrakan data?
Aug 09, 2023 pm 02:16 PM
Bagaimana untuk menggunakan perpustakaan kelas PHPGoutte untuk merangkak web dan pengekstrakan data? Gambaran Keseluruhan: Dalam proses pembangunan harian, kita selalunya perlu mendapatkan pelbagai data daripada Internet, seperti kedudukan filem, ramalan cuaca, dsb. Merangkak web adalah salah satu kaedah biasa untuk mendapatkan data ini. Dalam pembangunan PHP, kita boleh menggunakan perpustakaan kelas Goutte untuk melaksanakan rangkak web dan fungsi pengekstrakan data. Artikel ini akan memperkenalkan cara menggunakan perpustakaan kelas PHPGoutte untuk merangkak halaman web dan mengekstrak data serta melampirkan contoh kod. Apa itu Gout
 Bagaimana cara menggunakan Scrapy untuk merangkak buku Douban dan penilaian serta ulasannya?
Jun 22, 2023 am 10:21 AM
Bagaimana cara menggunakan Scrapy untuk merangkak buku Douban dan penilaian serta ulasannya?
Jun 22, 2023 am 10:21 AM
Dengan perkembangan Internet, orang ramai semakin bergantung kepada Internet untuk mendapatkan maklumat. Bagi pencinta buku, Douban Books telah menjadi platform yang sangat diperlukan. Di samping itu, Douban Books juga menyediakan banyak penilaian dan ulasan buku, membolehkan pembaca memahami buku dengan lebih komprehensif. Walau bagaimanapun, mendapatkan maklumat ini secara manual adalah sama dengan mencari jarum dalam timbunan jerami Pada masa ini, kita boleh menggunakan alat Scrapy untuk merangkak data. Scrapy ialah rangka kerja perangkak web sumber terbuka berdasarkan Python, yang boleh membantu kami dengan cekap
