
 Peranti teknologi
AI
ACM MM 2023 |. DiffBFR: Kaedah pemulihan muka penindasan bunyi yang dicadangkan oleh Meitu & Universiti Sains dan Teknologi China
Peranti teknologi
AI
ACM MM 2023 |. DiffBFR: Kaedah pemulihan muka penindasan bunyi yang dicadangkan oleh Meitu & Universiti Sains dan Teknologi China
ACM MM 2023 |. DiffBFR: Kaedah pemulihan muka penindasan bunyi yang dicadangkan oleh Meitu & Universiti Sains dan Teknologi China

Matlamat Pemulihan Wajah Buta (BFR) adalah untuk memulihkan imej muka berkualiti tinggi daripada imej muka berkualiti rendah. Ini adalah tugas penting dalam bidang penglihatan komputer dan grafik, dan digunakan secara meluas dalam pelbagai senario seperti pemulihan imej pengawasan, pemulihan foto lama dan resolusi super imej muka
Namun, tugas ini sangat Ia mencabar kerana kemerosotan ketidakpastian akan merosakkan kualiti imej malah membawa kepada kehilangan maklumat imej, seperti kabur, hingar, persampelan rendah dan artifak mampatan. Kaedah BFR sebelumnya biasanya bergantung pada rangkaian adversarial generatif (GAN) untuk menyelesaikan masalah ini dengan mereka bentuk pelbagai priors khusus muka, termasuk priors generatif, prior reference dan priors geometri. Walaupun kaedah ini telah mencapai tahap terkini, kaedah ini masih tidak dapat mencapai sepenuhnya matlamat untuk mendapatkan tekstur yang realistik semasa memulihkan butiran Semasa proses pemulihan imej, set data imej wajah biasanya bertaburan dalam ruang dimensi tinggi, dan dimensi ciri taburan berbentuk taburan ekor panjang. Berbeza daripada pengedaran ekor panjang bagi tugas pengelasan imej, ciri serantau ekor panjang dalam pemulihan imej merujuk kepada atribut yang mempunyai kesan kecil pada identiti tetapi memberi kesan besar pada kesan visual, seperti tahi lalat, kedutan dan ton, dsb.
# 🎜🎜# Mengikut kesederhanaan yang ditunjukkan dalam Rajah 1, untuk tidak mengubah maksud asal, hasil eksperimen perlu ditulis semula ke dalam bahasa Cina Kita boleh mendapati bahawa kaedah berasaskan GAN yang lalu mempunyai masalah yang jelas apabila memproses sampel kepala dan ekor pengedaran ekor panjang pada masa yang sama Kelicinan berlebihan dan kehilangan perincian berlaku semasa membaiki imej. Kaedah berdasarkan Model Probistik Penyebaran (DPM) boleh lebih sesuai dengan pengedaran ekor panjang dan mengekalkan ciri ekor sambil menyesuaikan pengedaran data sebenar# 🎜🎜#
# 🎜🎜#Kandungan yang perlu ditulis semula ialah: ujian berasaskan GAN dan berasaskan DPM terhadap isu ekor panjang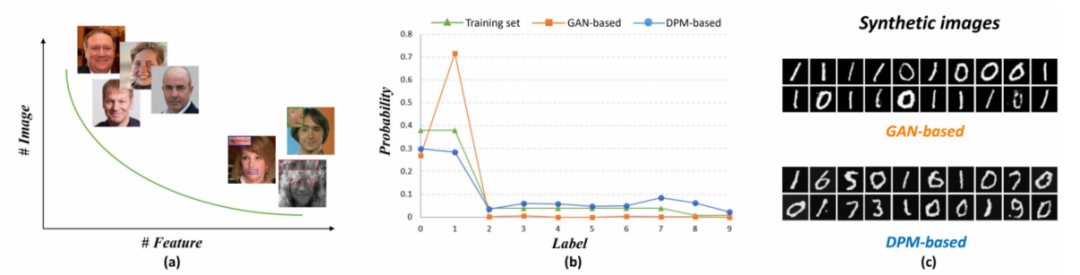
Kandungan yang perlu ditulis semula ialah: Pautan kertas: https://arxiv.org/ abs/2305.04517
Penyelidikan ini meneroka kebolehsuaian dua model generatif, Generative Adversarial Networks (GAN) dan Deep Partial Models (DPM), dalam menangani masalah long-tail. Dengan mereka bentuk modul pemulihan muka yang sesuai, maklumat terperinci yang lebih tepat boleh diperolehi, dengan itu mengurangkan kelicinan muka yang berlebihan yang mungkin berlaku dalam kaedah generatif dan meningkatkan ketepatan dan ketepatan pemulihan. Kertas penyelidikan ini telah diterima oleh ACM MM 2023
kaedah pembaikan imej muka buta berasaskan DPM - DiffBFR
Kajian mendapati bahawa penyebaran model adalah dalam mengelakkan Mengungguli kaedah GAN dari segi keruntuhan mod latihan dan pemasangan untuk menjana pengedaran berekor panjang. Oleh itu, DiffBFR memilih untuk menggunakan model kebarangkalian resapan untuk meningkatkan pembenaman maklumat terdahulu muka, dan menggunakan ini sebagai rangka kerja asas untuk memilih DPM sebagai penyelesaian. Ini kerana model resapan mempunyai keupayaan berkuasa untuk menghasilkan imej berkualiti tinggi dalam mana-mana julat pengedaranUntuk menyelesaikan pengedaran ciri ekor panjang pada set data muka yang terdapat dalam kertas dan seterusnya -melancarkan masalah kaedah berasaskan GAN yang lalu, kajian ini meneroka reka bentuk yang munasabah untuk lebih sesuai dengan anggaran taburan ekor panjang dan mengatasi masalah terlalu licin dalam proses pembaikan. Melalui eksperimen mudah GAN dan DPM dengan saiz parameter yang sama pada set data MNIST (Rajah 1), kajian mendapati bahawa kaedah DPM boleh sesuai dengan taburan ekor panjang, manakala GAN memberi terlalu banyak perhatian kepada ciri kepala dan mengabaikan ciri ekor Akibatnya, ciri ekor tidak dapat dihasilkan. Oleh itu, DPM dipilih sebagai penyelesaian kepada BFR
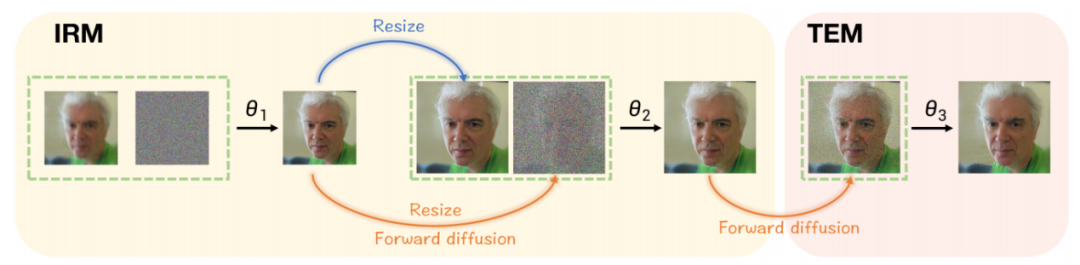
Dengan memperkenalkan dua pembolehubah perantaraan, DiffBFR mencadangkan dua modul pembaikan khusus. Reka bentuk ini menggunakan pendekatan dua peringkat, pertama memulihkan maklumat identiti daripada imej LQ, dan kemudian meningkatkan butiran tekstur berdasarkan pengedaran wajah sebenar. Reka bentuk ini terdiri daripada dua bahagian utama:(1) Modul Pemulihan Identiti (IRM):
modul ini Matlamatnya adalah untuk memelihara butiran wajah dalam keputusan. Pada masa yang sama, kaedah pensampelan terpenggal dicadangkan, yang menggantikan kaedah denoising menggunakan taburan rawak Gaussian tulen dalam proses terbalik dengan menambahkan sebahagian daripada hingar pada imej berkualiti rendah. Makalah ini secara teorinya membuktikan bahawa perubahan ini mengecilkan bukti teoritis batas bawah (ELBO) DPM, dengan itu memulihkan lebih banyak butiran asal. Berdasarkan bukti teori, dua model resapan bersyarat bertingkat dengan saiz input berbeza diperkenalkan untuk meningkatkan kesan pensampelan dan mengurangkan kesukaran latihan menjana imej resolusi tinggi secara langsung. Pada masa yang sama, dibuktikan lagi bahawa lebih tinggi kualiti input bersyarat, lebih dekat dengan pengedaran data sebenar, dan lebih tepat imej yang dipulihkan. Ini juga sebab mengapa DiffBFR mula-mula memulihkan imej resolusi rendah(2) Modul Peningkatan Tekstur (TEM):
Kaedah yang digunakan untuk mentekstur imej adalah dengan memperkenalkan model resapan tanpa syarat. Model ini bebas sepenuhnya daripada imej berkualiti rendah, seterusnya menjadikan hasil yang dipulihkan lebih dekat dengan data imej sebenar. Makalah ini secara teorinya membuktikan bahawa model resapan tanpa syarat yang dilatih pada imej berkualiti tinggi semata-mata menyumbang kepada pengedaran imej output yang betul dalam ruang aras piksel. Iaitu, selepas menggunakan model ini, pengedaran imej yang dilukis mempunyai FID yang lebih rendah berbanding sebelum menggunakannya, dan secara keseluruhannya lebih serupa dengan pengedaran imej berkualiti tinggi. Khususnya, maklumat identiti dikekalkan oleh pemangkasan langkah masa pensampelan, dan tekstur aras piksel digilap Langkah inferens pensampelan DiffBFR ditunjukkan dalam Rajah 2, dan rajah skematik proses inferens pensampelan ditunjukkan dalam Rajah 3.
Kandungan yang perlu ditulis semula ialah: Rajah 2 menunjukkan langkah inferens persampelan kaedah DiffBFR
Kandungan yang perlu ditulis semula ialah: Rajah 3 menunjukkan rajah skematik proses inferens persampelan Kaedah DiffBFR
 Untuk tidak mengubah maksud Asal, keputusan eksperimen perlu ditulis semula ke dalam bahasa Cina
Untuk tidak mengubah maksud Asal, keputusan eksperimen perlu ditulis semula ke dalam bahasa Cina
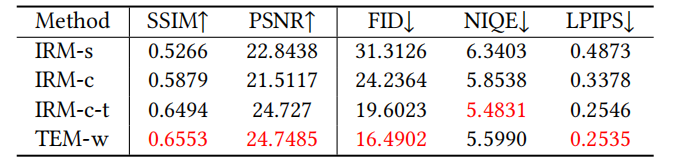
Kesan visualisasi kaedah BFR berasaskan GAN dan kaedah berasaskan DPM dibandingkan, sebagai Ditunjukkan dalam Rajah 4 untuk Rajah 5, prestasi kaedah SOTA untuk BFR dibandingkan dengan perbandingan visualisasi kaedah BFR ditunjukkan dalam Rajah 6

Dalam model, kita boleh membandingkan prestasi IRM dan TEM melalui visualisasi

Dalam model, prestasi IRM dan TEM dibandingkan, seperti yang ditunjukkan dalam Rajah 8


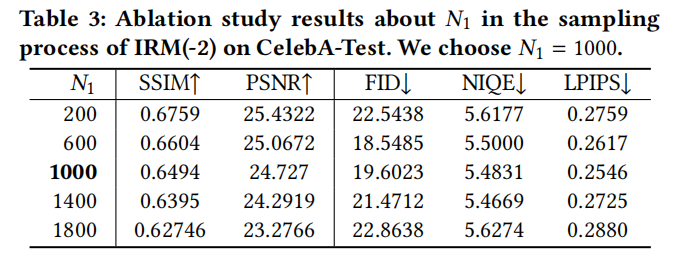
yang perlu ditulis semula ialah: Bandingkan prestasi IRM Rajah 9 di bawah parameter berbeza
Untuk Rajah 10, kita perlu membandingkan prestasi parameter yang berbeza
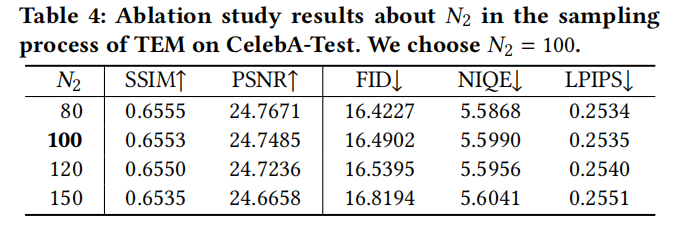
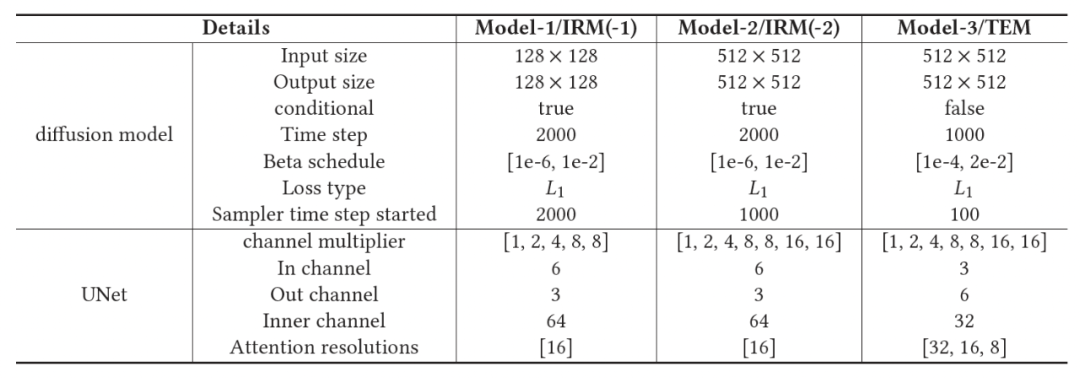
ditulis semula ialah: Rajah 11 menunjukkan tetapan parameter setiap modul DiffBFR
Kertas kerja ini mencadangkan model pemulihan imej muka degradasi buta DiffBFR berdasarkan model penyebaran untuk menyelesaikan masalah kaedah berasaskan GAN sebelumnya ranap mod dan masalah hilang ekor panjang. Dengan membenamkan pengetahuan sedia ada ke dalam model resapan, imej yang dipulihkan berkualiti tinggi dan jelas boleh dijana daripada imej muka yang rosak teruk secara rawak. Secara khusus, kajian ini mencadangkan dua modul, IRM dan TEM, yang digunakan untuk memulihkan realiti dan memulihkan butiran masing-masing. Melalui terbitan teori dan demonstrasi imej eksperimen, keunggulan model ditunjukkan, dan perbandingan kualitatif dan kuantitatif dibuat dengan kaedah terkini yang sedia ada
Apa yang perlu ditulis semula ialah: Pasukan Penyelidik
Kertas kerja ini dicadangkan bersama oleh penyelidik dari Institut Penyelidikan Pengimejan Meitu (MT Lab) dan Akademi Sains Universiti China. Institut Penyelidikan Pengimejan Meitu (MT Lab) telah ditubuhkan pada tahun 2010. Ia adalah pasukan Meitu yang memfokuskan pada penyelidikan algoritma, pembangunan kejuruteraan dan pelaksanaan produk dalam bidang penglihatan komputer, pembelajaran mendalam, realiti tambahan dan bidang lain. Sejak penubuhannya, pasukan itu komited untuk meneroka penyelidikan dalam bidang penglihatan komputer, dan mula menggunakan pembelajaran mendalam pada 2013 untuk menyediakan sokongan teknikal untuk produk perisian dan perkakasan Meitu. Pada masa yang sama, mereka juga menyediakan perkhidmatan SaaS yang disasarkan untuk pelbagai medan menegak dalam industri pengimejan, dan mempromosikan pembangunan ekologi produk kecerdasan buatan Meitu melalui teknologi pengimejan termaju. Mereka telah mengambil bahagian dalam pertandingan antarabangsa terkemuka seperti CVPR, ICCV, dan ECCV, memenangi lebih daripada sepuluh kejuaraan dan naib juara, dan menerbitkan lebih daripada 48 kertas persidangan akademik antarabangsa terkemuka. Institut Penyelidikan Pengimejan Meitu (MT Lab) telah lama komited dalam penyelidikan dan pembangunan dalam bidang pengimejan, telah mengumpul rizab teknikal yang kaya, dan mempunyai pengalaman pelaksanaan teknologi yang kaya dalam bidang gambar, video, reka bentuk dan orang digital
Atas ialah kandungan terperinci ACM MM 2023 |. DiffBFR: Kaedah pemulihan muka penindasan bunyi yang dicadangkan oleh Meitu & Universiti Sains dan Teknologi China. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 Sistem pemanduan pintar Qiankun ADS3.0 Huawei akan dilancarkan pada bulan Ogos dan akan dilancarkan pada Xiangjie S9 buat kali pertama
Jul 30, 2024 pm 02:17 PM
Sistem pemanduan pintar Qiankun ADS3.0 Huawei akan dilancarkan pada bulan Ogos dan akan dilancarkan pada Xiangjie S9 buat kali pertama
Jul 30, 2024 pm 02:17 PM
Pada 29 Julai, pada majlis pelepasan kereta baharu AITO Wenjie yang ke-400,000, Yu Chengdong, Pengarah Urusan Huawei, Pengerusi Terminal BG, dan Pengerusi Smart Car Solutions BU, menghadiri dan menyampaikan ucapan dan mengumumkan bahawa model siri Wenjie akan akan dilancarkan tahun ini Pada bulan Ogos, Huawei Qiankun ADS 3.0 versi telah dilancarkan, dan ia dirancang untuk terus naik taraf dari Ogos hingga September. Xiangjie S9, yang akan dikeluarkan pada 6 Ogos, akan memperkenalkan sistem pemanduan pintar ADS3.0 Huawei. Dengan bantuan lidar, versi Huawei Qiankun ADS3.0 akan meningkatkan keupayaan pemanduan pintarnya, mempunyai keupayaan bersepadu hujung-ke-hujung, dan mengguna pakai seni bina hujung ke hujung baharu GOD (pengenalpastian halangan am)/PDP (ramalan). membuat keputusan dan kawalan), menyediakan fungsi NCA pemanduan pintar dari ruang letak kereta ke ruang letak kereta, dan menaik taraf CAS3.0
 Satu lagi tablet Snapdragon 8Gen3 ~ OPPOPad3 terdedah
Jul 29, 2024 pm 04:26 PM
Satu lagi tablet Snapdragon 8Gen3 ~ OPPOPad3 terdedah
Jul 29, 2024 pm 04:26 PM
Bulan lalu, OnePlus mengeluarkan tablet pertama yang dilengkapi dengan Snapdragon 8 Gen3: OnePlus Tablet Pro Menurut berita terkini, versi "penggantian bayi" tablet ini, OPPOPad3, juga akan dikeluarkan tidak lama lagi. Gambar di atas menunjukkan OPPOPad2 Menurut Stesen Sembang Digital, rupa dan konfigurasi OPPOPad3 adalah sama persis dengan OnePlus Tablet Pro Warna: emas, biru (berbeza daripada OnePlus' hijau dan kelabu gelap: 8 /12/16GB+512GB Tarikh keluaran: Produk baharu untuk tempoh yang sama pada suku keempat tahun ini (Oktober-Disember): Cari.
 Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Dalam pembuatan moden, pengesanan kecacatan yang tepat bukan sahaja kunci untuk memastikan kualiti produk, tetapi juga teras untuk meningkatkan kecekapan pengeluaran. Walau bagaimanapun, set data pengesanan kecacatan sedia ada selalunya tidak mempunyai ketepatan dan kekayaan semantik yang diperlukan untuk aplikasi praktikal, menyebabkan model tidak dapat mengenal pasti kategori atau lokasi kecacatan tertentu. Untuk menyelesaikan masalah ini, pasukan penyelidik terkemuka yang terdiri daripada Universiti Sains dan Teknologi Hong Kong Guangzhou dan Teknologi Simou telah membangunkan set data "DefectSpectrum" secara inovatif, yang menyediakan anotasi berskala besar yang kaya dengan semantik bagi kecacatan industri. Seperti yang ditunjukkan dalam Jadual 1, berbanding set data industri lain, set data "DefectSpectrum" menyediakan anotasi kecacatan yang paling banyak (5438 sampel kecacatan) dan klasifikasi kecacatan yang paling terperinci (125 kategori kecacatan
 Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Komuniti LLM terbuka ialah era apabila seratus bunga mekar dan bersaing Anda boleh melihat Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 dan banyak lagi. model yang cemerlang. Walau bagaimanapun, berbanding dengan model besar proprietari yang diwakili oleh GPT-4-Turbo, model terbuka masih mempunyai jurang yang ketara dalam banyak bidang. Selain model umum, beberapa model terbuka yang mengkhusus dalam bidang utama telah dibangunkan, seperti DeepSeek-Coder-V2 untuk pengaturcaraan dan matematik, dan InternVL untuk tugasan bahasa visual.
 Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Bagi AI, Olimpik Matematik tidak lagi menjadi masalah. Pada hari Khamis, kecerdasan buatan Google DeepMind menyelesaikan satu kejayaan: menggunakan AI untuk menyelesaikan soalan sebenar IMO Olimpik Matematik Antarabangsa tahun ini, dan ia hanya selangkah lagi untuk memenangi pingat emas. Pertandingan IMO yang baru berakhir minggu lalu mempunyai enam soalan melibatkan algebra, kombinatorik, geometri dan teori nombor. Sistem AI hibrid yang dicadangkan oleh Google mendapat empat soalan dengan betul dan memperoleh 28 mata, mencapai tahap pingat perak. Awal bulan ini, profesor UCLA, Terence Tao baru sahaja mempromosikan Olimpik Matematik AI (Anugerah Kemajuan AIMO) dengan hadiah berjuta-juta dolar Tanpa diduga, tahap penyelesaian masalah AI telah meningkat ke tahap ini sebelum Julai. Lakukan soalan secara serentak pada IMO Perkara yang paling sukar untuk dilakukan dengan betul ialah IMO, yang mempunyai sejarah terpanjang, skala terbesar dan paling negatif
 Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Editor |KX Sehingga hari ini, perincian dan ketepatan struktur yang ditentukan oleh kristalografi, daripada logam ringkas kepada protein membran yang besar, tidak dapat ditandingi oleh mana-mana kaedah lain. Walau bagaimanapun, cabaran terbesar, yang dipanggil masalah fasa, kekal mendapatkan maklumat fasa daripada amplitud yang ditentukan secara eksperimen. Penyelidik di Universiti Copenhagen di Denmark telah membangunkan kaedah pembelajaran mendalam yang dipanggil PhAI untuk menyelesaikan masalah fasa kristal Rangkaian saraf pembelajaran mendalam yang dilatih menggunakan berjuta-juta struktur kristal tiruan dan data pembelauan sintetik yang sepadan boleh menghasilkan peta ketumpatan elektron yang tepat. Kajian menunjukkan bahawa kaedah penyelesaian struktur ab initio berasaskan pembelajaran mendalam ini boleh menyelesaikan masalah fasa pada resolusi hanya 2 Angstrom, yang bersamaan dengan hanya 10% hingga 20% daripada data yang tersedia pada resolusi atom, manakala Pengiraan ab initio tradisional
 Pandangan alam semula jadi: Ujian kecerdasan buatan dalam perubatan berada dalam keadaan huru-hara Apa yang perlu dilakukan?
Aug 22, 2024 pm 04:37 PM
Pandangan alam semula jadi: Ujian kecerdasan buatan dalam perubatan berada dalam keadaan huru-hara Apa yang perlu dilakukan?
Aug 22, 2024 pm 04:37 PM
Editor |. ScienceAI Berdasarkan data klinikal yang terhad, beratus-ratus algoritma perubatan telah diluluskan. Para saintis sedang membahaskan siapa yang harus menguji alat dan cara terbaik untuk melakukannya. Devin Singh menyaksikan seorang pesakit kanak-kanak di bilik kecemasan mengalami serangan jantung semasa menunggu rawatan untuk masa yang lama, yang mendorongnya untuk meneroka aplikasi AI untuk memendekkan masa menunggu. Menggunakan data triage daripada bilik kecemasan SickKids, Singh dan rakan sekerja membina satu siri model AI untuk menyediakan potensi diagnosis dan mengesyorkan ujian. Satu kajian menunjukkan bahawa model ini boleh mempercepatkan lawatan doktor sebanyak 22.3%, mempercepatkan pemprosesan keputusan hampir 3 jam bagi setiap pesakit yang memerlukan ujian perubatan. Walau bagaimanapun, kejayaan algoritma kecerdasan buatan dalam penyelidikan hanya mengesahkan perkara ini
 Bai Jian menyampaikan berita tentang Telefon NIO baharu dan menjawab sebab NIO berkeras untuk membuat telefon mudah alih
Jul 25, 2024 pm 01:14 PM
Bai Jian menyampaikan berita tentang Telefon NIO baharu dan menjawab sebab NIO berkeras untuk membuat telefon mudah alih
Jul 25, 2024 pm 01:14 PM
Telefon NIO NIO baharu (NIOPhone 2) akan dikeluarkan pada 27 Julai. Apabila tarikh keluaran semakin hampir, pada 24 Julai, Bai Jian, Naib Presiden NIO Technology (Anhui) Co., Ltd., menjawab dua daripada soalan paling biasa mengenai Telefon NIO dalam kalangan netizen. NIOPhone "Mengapa NIO berkeras untuk membuat telefon mudah alih?" Bai Jian menjawab bahawa Weilai telah mula berfikir dan merancang untuk membuat telefon bimbit sangat awal, dan ia bukanlah sesuatu yang sesuka hati, apatah lagi seperti yang dikatakan oleh sesetengah orang, kerana beberapa jenama telefon bimbit telah mula membuat kereta. Bai Jian menyampaikan berita tentang "kereta pintar dan telefon mudah alih" NIOPhone baharu
