
 Peranti teknologi
AI
Gunakan BigDL-LLM untuk mempercepatkan berpuluh bilion parameter LLM inferens dengan serta-merta
Peranti teknologi
AI
Gunakan BigDL-LLM untuk mempercepatkan berpuluh bilion parameter LLM inferens dengan serta-merta
Gunakan BigDL-LLM untuk mempercepatkan berpuluh bilion parameter LLM inferens dengan serta-merta

Kami memasuki era baharu AI yang didorong oleh Model Bahasa Besar (LLM) memainkan peranan yang semakin penting dalam pelbagai aplikasi seperti perkhidmatan pelanggan, pembantu maya, penciptaan kandungan, bantuan pengaturcaraan, dll.
Walau bagaimanapun, apabila skala LLM terus berkembang, penggunaan sumber yang diperlukan untuk menjalankan model besar juga semakin meningkat, menyebabkan operasinya menjadi lebih perlahan dan lebih perlahan, yang membawa cabaran besar kepada pembangun aplikasi AI.
Untuk tujuan ini, Intel baru-baru ini melancarkan perpustakaan sumber terbuka model besar yang dipanggil BigDL-LLM[1], yang boleh membantu pembangun dan penyelidik AI mempercepatkan pengoptimuman model bahasa besar pada platform Intel ® dan menambah baik Pengalaman menggunakan model bahasa besar pada platform Intel ® .

Berikut menunjukkan 33 bilion parameter model bahasa besar Vicuna-33b-v1.3[2] yang dipercepatkan menggunakan BigDL-LLM pada mesin yang dilengkapi dengan Intel® Xeon8® Xeon
8®46P pemproses menjalankan kesan masa nyata pada pelayan. 
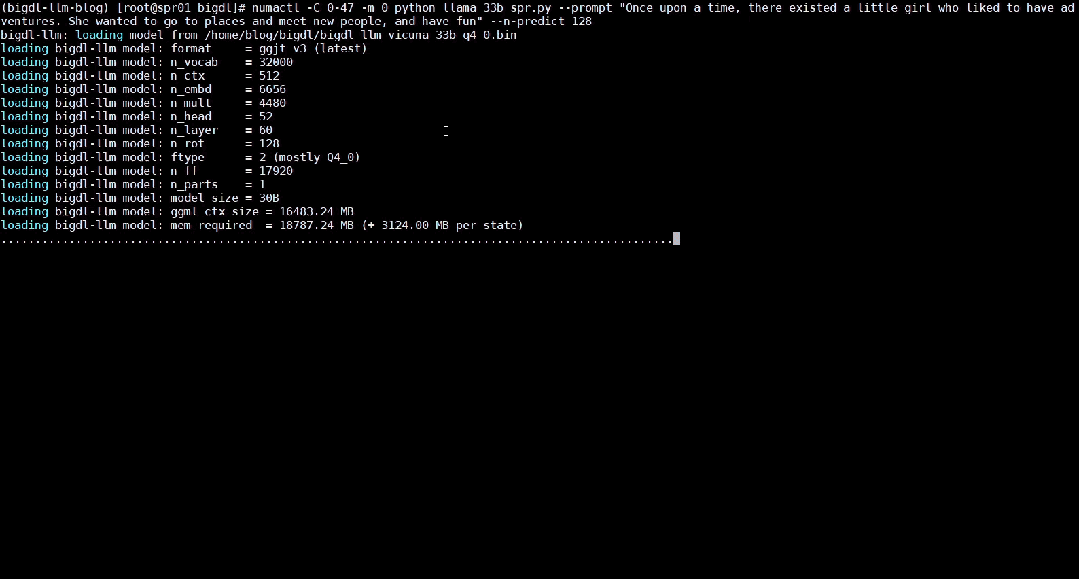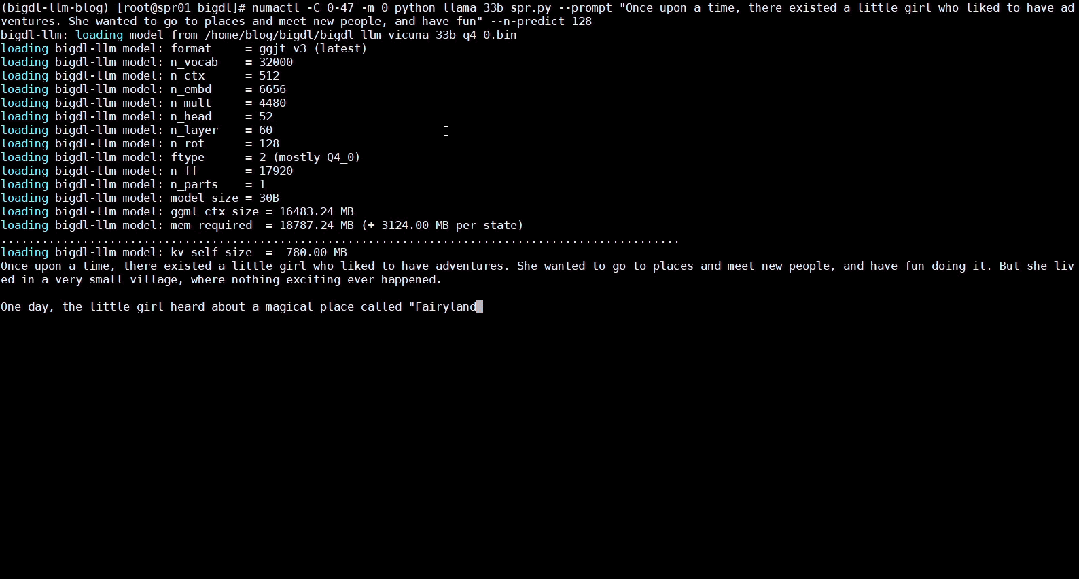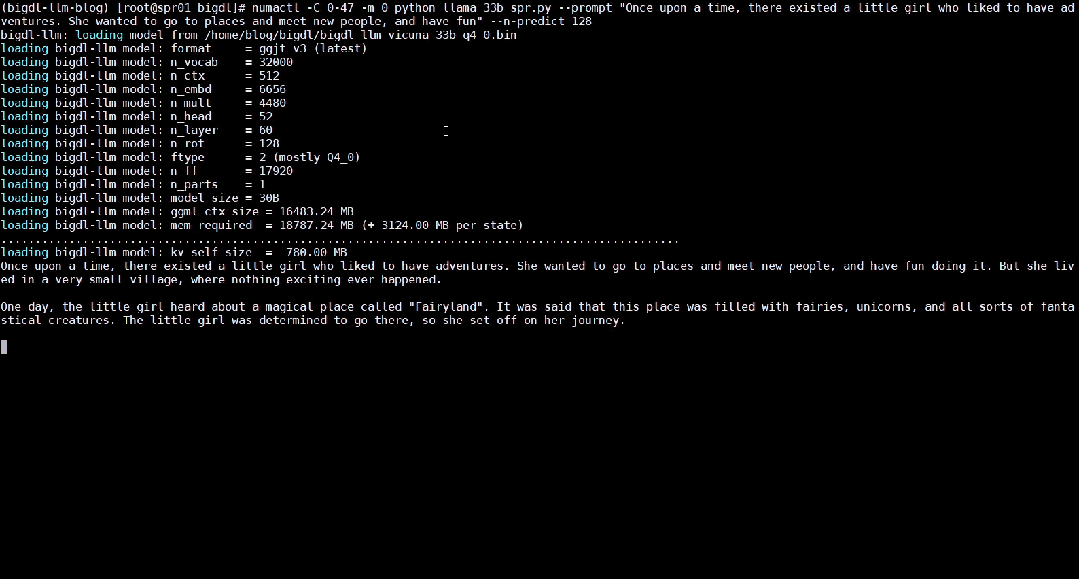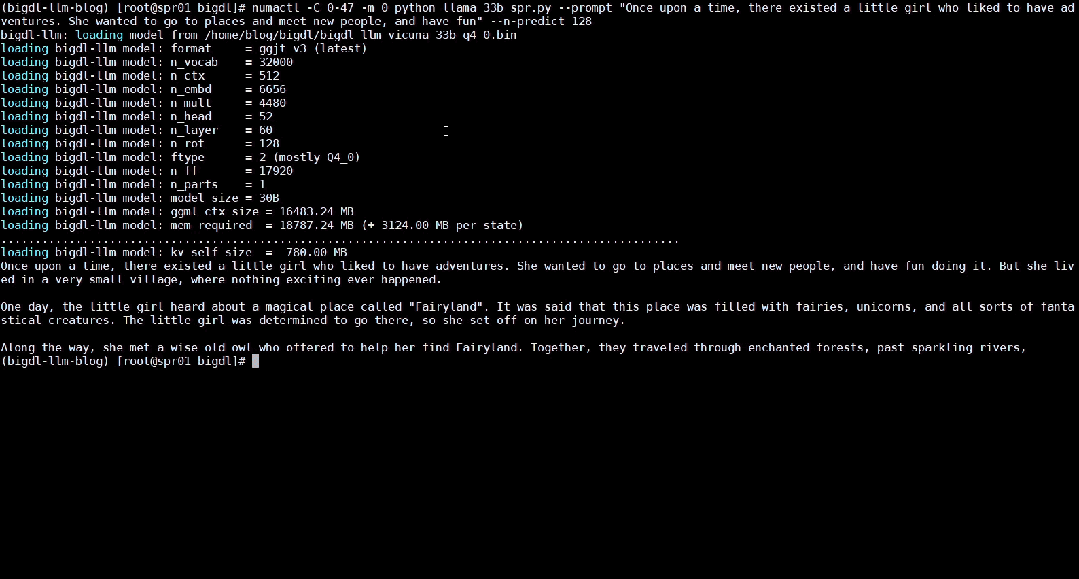
△Kelajuan sebenar menjalankan model bahasa besar parameter 33 bilion pada pelayan yang dilengkapi dengan pemproses Intel® Xeon
®Platinum 8468 (rakaman skrin masa nyata) : Intel
: Intel
Pustaka pecutan model bahasa besar sumber terbuka pada platformBigDL-LLM ialah perpustakaan sumber terbuka yang memfokuskan pada pengoptimuman dan mempercepatkan model bahasa besar Ia adalah sebahagian daripada BigDL dan dikeluarkan di bawah lesen Apache 2.0Ia menyediakan pelbagai jenis bahasa rendah. tahap pengoptimuman Ketepatan (seperti INT4/INT5/INT8), dan boleh menggunakan pelbagai teknologi pecutan perkakasan bersepadu Intel
®CPU (AVX/VNNI/AMX, dsb.) dan pengoptimuman perisian terkini untuk memperkasakan model bahasa besar pada Intel® Mencapai pengoptimuman yang lebih cekap dan operasi yang lebih pantas pada platform. Ciri penting BigDL-LLM ialah untuk model berdasarkan Hugging Face Transformers API, anda hanya perlu menukar satu baris kod untuk mempercepatkan model Secara teori, ia boleh menyokong berjalan
sebarang model Transformers, yang berguna untuk mereka yang biasa dengan Transformers Pembangun API sangat mesra.
Selain API Transformers, ramai orang juga menggunakan LangChain untuk membangunkan aplikasi model bahasa yang besar. Untuk tujuan ini, BigDL-LLM juga menyediakan integrasi LangChain yang mudah digunakan
[3], membolehkan pembangun menggunakan BigDL-LLM dengan mudah untuk membangunkan aplikasi baharu atau memindahkan aplikasi sedia ada berdasarkan Transformers API atau LangChain API . Selain itu, untuk model bahasa besar PyTorch umum (model yang tidak menggunakan Transformer atau LangChain API), anda juga boleh menggunakan BigDL-LLM optimize_model API pecutan satu klik untuk meningkatkan prestasi. Untuk butiran, sila rujuk GitHub README[4] dan dokumentasi rasmi
[5]. BigDL-LLM juga menyediakan sejumlah besar sampel pecutan LLM sumber terbuka yang biasa digunakan (cth. sampel menggunakan Transformers API[6] dan sampel menggunakan LangChain API[7], serta tutorial (termasuk menyokong buku nota jupyter)
[8], mudah untuk pembangun memulakan dan mencubanya dengan cepat
Pemasangan dan penggunaan: Proses pemasangan yang ringkas dan antara muka API yang mudah digunakan
Sangat mudah untuk memasang BigDL-LLM, cuma jalankan perkara berikut arahan: pip install --pre --upgrade bigdl-llm[all]
Ia juga sangat mudah untuk menggunakan BigDL-LLM untuk mempercepatkan model besar (di sini kami hanya menggunakan API gaya Transformers sebagai contoh)
Gunakan API gaya Transformer BigDL-LLM Untuk mempercepatkan model, anda hanya perlu menukar bahagian pemuatan model Proses penggunaan seterusnya adalah sama seperti Transformers asli menggunakan API BigDL-LLM hampir sama dengan API Transformers - pengguna hanya perlu menukar import dan menetapkannya dalam parameter from_pretrained load_in_4bit=True
BigDL-LLM akan melakukan 4-bit low-. kuantisasi ketepatan semasa proses pemuatan model, dan gunakan pelbagai teknologi pecutan perisian dan perkakasan untuk pengoptimuman semasa proses inferens berikutnya
#Load Hugging Face Transformers model with INT4 optimizationsfrom bigdl.llm. transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)△ Jika kod tidak dipaparkan sepenuhnya, sila luncurkan ke kiri atau kanan
示例:快速实现一个基于大语言模型的语音助手应用
下文将以 LLM 常见应用场景“语音助手”为例,展示采用 BigDL-LLM 快速实现 LLM 应用的案例。通常情况下,语音助手应用的工作流程分为以下两个部分:
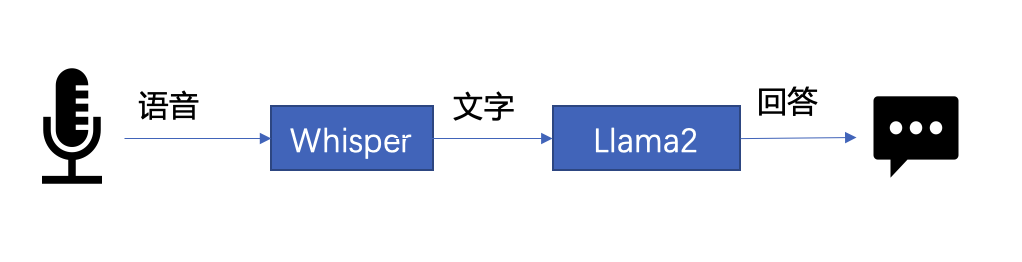
△图 1. 语音助手工作流程示意
- 语音识别——使用语音识别模型(本示例采用了 Whisper 模型[9] )将用户的语音转换为文本;
- 文本生成——将 1 中输出的文本作为提示语 (prompt),使用一个大语言模型(本示例采用了 Llama2[10] )生成回复。
以下是本文使用 BigDL-LLM 和 LangChain[11] 来搭建语音助手应用的过程:
在语音识别阶段:第一步,加载预处理器 processor 和语音识别模型 recog_model。本示例中使用的识别模型 Whisper 是一个 Transformers 模型。
只需使用 BigDL-LLM 中的 AutoModelForSpeechSeq2Seq 并设置参数 load_in_4bit=True,就能够以 INT4 精度加载并加速这一模型,从而显著缩短模型推理用时。
#processor = WhisperProcessor .from_pretrained(recog_model_path)recog_model = AutoModelForSpeechSeq2Seq .from_pretrained(recog_model_path, load_in_4bit=True)
△若代码显示不全,请左右滑动
第二步,进行语音识别。首先使用处理器从输入语音中提取输入特征,然后使用识别模型预测 token,并再次使用处理器将 token 解码为自然语言文本。
input_features = processor(frame_data,sampling_rate=audio.sample_rate,return_tensor=“pt”).input_featurespredicted_ids = recogn_model.generate(input_features, forced_decoder_ids=forced_decoder_ids)text = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
△若代码显示不全,请左右滑动
在文本生成阶段,首先使用 BigDL-LLM 的 TransformersLLM API 创建一个 LangChain 语言模型(TransformersLLM 是在 BigDL-LLM 中定义的语言链 LLM 集成)。
可以使用这个 API 来加载 Hugging Face Transformers 的任何模型
llm = TransformersLLM . from_model_id(model_id=llm_model_path,model_kwargs={"temperature": 0, "max_length": args.max_length, "trust_remote_code": True},)△若代码显示不全,请左右滑动
然后,创建一个正常的对话链 LLMChain,并将已经创建的 llm 设置为输入参数。
# The following code is complete the same as the use-casevoiceassistant_chain = LLMChain(llm=llm, prompt=prompt,verbose=True,memory=ConversationBufferWindowMemory(k=2),)
△若代码显示不全,请左右滑动
以下代码将使用一个链条来记录所有对话历史,并将其适当地格式化为大型语言模型的输入。这样,我们可以生成合适的回复。只需将识别模型生成的文本作为 "human_input" 输入即可。代码如下:
response_text = voiceassistant_chain .predict(human_input=text, stop=”\n\n”)
△若代码显示不全,请左右滑动
最后,将语音识别和文本生成步骤放入循环中,即可在多轮对话中与该“语音助手”交谈。您可访问底部 [12] 链接,查看完整的示例代码,并使用自己的电脑进行尝试。快用 BigDL-LLM 来快速搭建自己的语音助手吧!
作者简介
黄晟盛是英特尔公司的资深架构师,黄凯是英特尔公司的AI框架工程师,戴金权是英特尔院士、大数据技术全球CTO和BigDL项目的创始人,他们都从事着与大数据和AI相关的工作
Atas ialah kandungan terperinci Gunakan BigDL-LLM untuk mempercepatkan berpuluh bilion parameter LLM inferens dengan serta-merta. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1381
1381
 52
52

 Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Laman web ini melaporkan pada 27 Jun bahawa Jianying ialah perisian penyuntingan video yang dibangunkan oleh FaceMeng Technology, anak syarikat ByteDance Ia bergantung pada platform Douyin dan pada asasnya menghasilkan kandungan video pendek untuk pengguna platform tersebut Windows , MacOS dan sistem pengendalian lain. Jianying secara rasmi mengumumkan peningkatan sistem keahliannya dan melancarkan SVIP baharu, yang merangkumi pelbagai teknologi hitam AI, seperti terjemahan pintar, penonjolan pintar, pembungkusan pintar, sintesis manusia digital, dsb. Dari segi harga, yuran bulanan untuk keratan SVIP ialah 79 yuan, yuran tahunan ialah 599 yuan (nota di laman web ini: bersamaan dengan 49.9 yuan sebulan), langganan bulanan berterusan ialah 59 yuan sebulan, dan langganan tahunan berterusan ialah 499 yuan setahun (bersamaan dengan 41.6 yuan sebulan) . Di samping itu, pegawai yang dipotong juga menyatakan bahawa untuk meningkatkan pengalaman pengguna, mereka yang telah melanggan VIP asal
 Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Tingkatkan produktiviti, kecekapan dan ketepatan pembangun dengan menggabungkan penjanaan dipertingkatkan semula dan memori semantik ke dalam pembantu pengekodan AI. Diterjemah daripada EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, pengarang JanakiramMSV. Walaupun pembantu pengaturcaraan AI asas secara semulajadi membantu, mereka sering gagal memberikan cadangan kod yang paling relevan dan betul kerana mereka bergantung pada pemahaman umum bahasa perisian dan corak penulisan perisian yang paling biasa. Kod yang dijana oleh pembantu pengekodan ini sesuai untuk menyelesaikan masalah yang mereka bertanggungjawab untuk menyelesaikannya, tetapi selalunya tidak mematuhi piawaian pengekodan, konvensyen dan gaya pasukan individu. Ini selalunya menghasilkan cadangan yang perlu diubah suai atau diperhalusi agar kod itu diterima ke dalam aplikasi
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Pemula AI secara kolektif menukar pekerjaan kepada OpenAI, dan pasukan keselamatan berkumpul semula selepas Ilya pergi!
Jun 08, 2024 pm 01:00 PM
Pemula AI secara kolektif menukar pekerjaan kepada OpenAI, dan pasukan keselamatan berkumpul semula selepas Ilya pergi!
Jun 08, 2024 pm 01:00 PM
Minggu lalu, di tengah gelombang peletakan jawatan dalaman dan kritikan luar, OpenAI dibelenggu oleh masalah dalaman dan luaran: - Pelanggaran kakak balu itu mencetuskan perbincangan hangat global - Pekerja menandatangani "fasal tuan" didedahkan satu demi satu - Netizen menyenaraikan " Ultraman " tujuh dosa maut" ” Pembasmi khabar angin: Menurut maklumat dan dokumen bocor yang diperolehi oleh Vox, kepimpinan kanan OpenAI, termasuk Altman, sangat mengetahui peruntukan pemulihan ekuiti ini dan menandatanganinya. Di samping itu, terdapat isu serius dan mendesak yang dihadapi oleh OpenAI - keselamatan AI. Pemergian lima pekerja berkaitan keselamatan baru-baru ini, termasuk dua pekerjanya yang paling terkemuka, dan pembubaran pasukan "Penjajaran Super" sekali lagi meletakkan isu keselamatan OpenAI dalam perhatian. Majalah Fortune melaporkan bahawa OpenA
 Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Editor |. KX Dalam bidang penyelidikan dan pembangunan ubat, meramalkan pertalian pengikatan protein dan ligan dengan tepat dan berkesan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan. Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat mengenai permukaan protein, struktur dan jujukan 3D, dan menggunakan mekanisme perhatian silang untuk membandingkan ciri modaliti yang berbeza penjajaran. Keputusan eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini. Penyelidikan berkaitan bermula dengan "S
