

Algoritma pembelajaran penyeliaan sendiri telah mencapai kemajuan yang ketara dalam pemprosesan bahasa semula jadi, penglihatan komputer dan bidang lain. Walaupun algoritma pembelajaran yang diselia sendiri ini secara konsep umum, operasi khusus mereka adalah berdasarkan modaliti data tertentu. Ini bermakna algoritma pembelajaran penyeliaan sendiri yang berbeza perlu dibangunkan untuk modaliti data yang berbeza. Untuk tujuan ini, kertas kerja ini mencadangkan teknik penambahan data umum yang boleh digunakan untuk sebarang modaliti data. Berbanding dengan pembelajaran penyeliaan kendiri tujuan am sedia ada, kaedah ini boleh mencapai peningkatan prestasi yang ketara, dan boleh menggantikan satu siri kaedah peningkatan data kompleks yang direka bentuk untuk modaliti tertentu dan mencapai prestasi yang serupa.

Kandungan yang ditulis semula: Pada masa ini, pembelajaran perwakilan Siam/pembelajaran kontrastif memerlukan penggunaan teknik penambahan data untuk membina sampel berbeza bagi data yang sama dan memasukkannya ke dalam dua struktur rangkaian selari untuk menjana isyarat penyeliaan yang cukup kuat. Walau bagaimanapun, teknik penambahan data ini biasanya sangat bergantung pada pengetahuan sedia ada khusus modaliti, selalunya memerlukan reka bentuk manual atau mencari kombinasi terbaik yang sesuai untuk modaliti semasa. Selain memakan masa dan intensif buruh, kaedah penambahan data terbaik yang ditemui juga sukar untuk dipindahkan ke kawasan lain. Contohnya, getaran warna biasa untuk imej RGB semula jadi tidak boleh digunakan pada modaliti data lain kecuali imej semula jadi
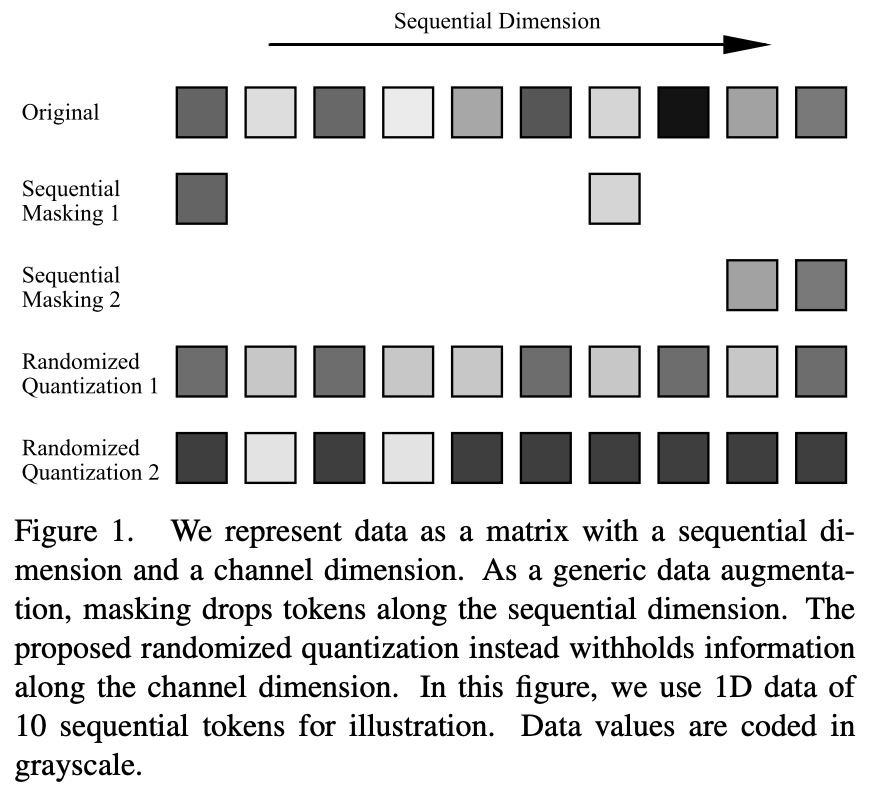
Secara umumnya, data input boleh diwakili sebagai perduaan yang terdiri daripada dimensi jujukan dan dimensi saluran. Dimensi jujukan sering dikaitkan dengan modaliti data, seperti dimensi spatial imej, dimensi temporal pertuturan dan dimensi sintaksis bahasa. Dimensi saluran adalah bebas daripada modaliti. Dalam pembelajaran penyeliaan kendiri, pemodelan oklusi atau menggunakan oklusi sebagai penambahan data telah menjadi kaedah pembelajaran yang berkesan. Walau bagaimanapun, operasi ini dilakukan pada dimensi jujukan. Untuk digunakan secara meluas untuk modaliti data yang berbeza, kertas kerja ini mencadangkan kaedah peningkatan data yang bertindak pada dimensi saluran: pengkuantitian rawak. Dengan mengkuantumkan data secara dinamik dalam setiap saluran menggunakan pengkuantiti tidak seragam, nilai terkuantis diambil secara rawak daripada selang yang dibahagikan secara rawak. Dengan cara ini, perbezaan maklumat input asal dalam selang yang sama dipadamkan, sambil mengekalkan saiz relatif data dalam selang yang berbeza, dengan itu mencapai kesan penyamaran
Kaedah ini boleh digunakan dalam pelbagai data modaliti Ia mengatasi kaedah pembelajaran penyeliaan kendiri sedia ada dalam mana-mana modaliti, termasuk imej semula jadi, awan titik 3D, pertuturan, teks, data sensor, imej perubatan, dsb. Dalam pelbagai tugas pembelajaran pra-latihan, seperti pembelajaran kontras (seperti MoCo-v3) dan pembelajaran penyeliaan kendiri penyulingan kendiri (seperti BYOL), ciri dipelajari yang lebih baik daripada kaedah sedia ada. Kaedah ini juga telah disahkan untuk struktur rangkaian tulang belakang yang berbeza seperti CNN dan Transformer.
Kuantisasi merujuk kepada penggunaan set nilai diskret untuk mewakili data berterusan bagi memudahkan penyimpanan, operasi dan penghantaran data yang cekap. Walau bagaimanapun, matlamat umum operasi pengkuantitian adalah untuk memampatkan data tanpa kehilangan ketepatan, jadi prosesnya adalah deterministik dan direka bentuk sedekat mungkin dengan data asal. Ini mengehadkan kekuatannya sebagai cara peningkatan dan kekayaan data outputnya.
Artikel ini mencadangkan operasi pengkuantitian rawak, yang secara bebas membahagikan setiap data saluran input kepada berbilang selang rawak tidak bertindih (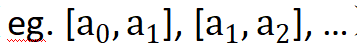 ), dan menggabungkan input asal yang terdapat dalam setiap selang Peta kepada
), dan menggabungkan input asal yang terdapat dalam setiap selang Peta kepada 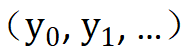 sampel secara rawak daripada selang.
sampel secara rawak daripada selang.

Keupayaan pengkuantitian rawak sebagai menyembunyikan data dimensi saluran dalam tugasan pembelajaran penyeliaan sendiri bergantung kepada reka bentuk tiga aspek berikut: 1) membahagikan selang berangka secara rawak; ) nombor selang berangka dibahagikan.
Secara khusus, proses rawak membawa sampel yang lebih kaya, dan data yang sama boleh menjana sampel data yang berbeza setiap kali operasi pengkuantitian rawak dilakukan. Pada masa yang sama, proses rawak juga membawa peningkatan yang lebih besar kepada data asal Contohnya, selang data yang besar dibahagikan secara rawak, atau apabila titik pemetaan menyimpang dari titik median selang, ia boleh menyebabkan input dan output asal menjadi. jatuh antara selang yang lebih besar antara.
Dengan mengurangkan bilangan selang pembahagian dengan sewajarnya, keamatan peningkatan boleh ditingkatkan dengan mudah. Dengan cara ini, apabila digunakan pada pembelajaran perwakilan Siam, kedua-dua cawangan rangkaian dapat menerima data input dengan perbezaan maklumat yang mencukupi, dengan itu membina isyarat pembelajaran yang kuat yang memudahkan pembelajaran ciri
#🎜🎜 ##🎜 🎜#Rajah berikut menggambarkan kesan modaliti data yang berbeza selepas menggunakan kaedah peningkatan data ini:
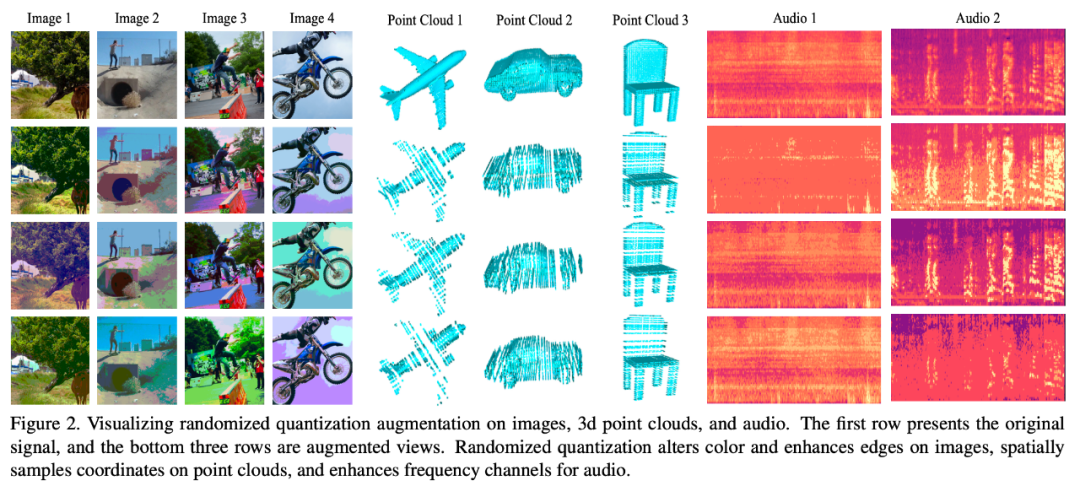 #🎜 🎜#Hasil eksperimen 🎜🎜#
#🎜 🎜#Hasil eksperimen 🎜🎜#
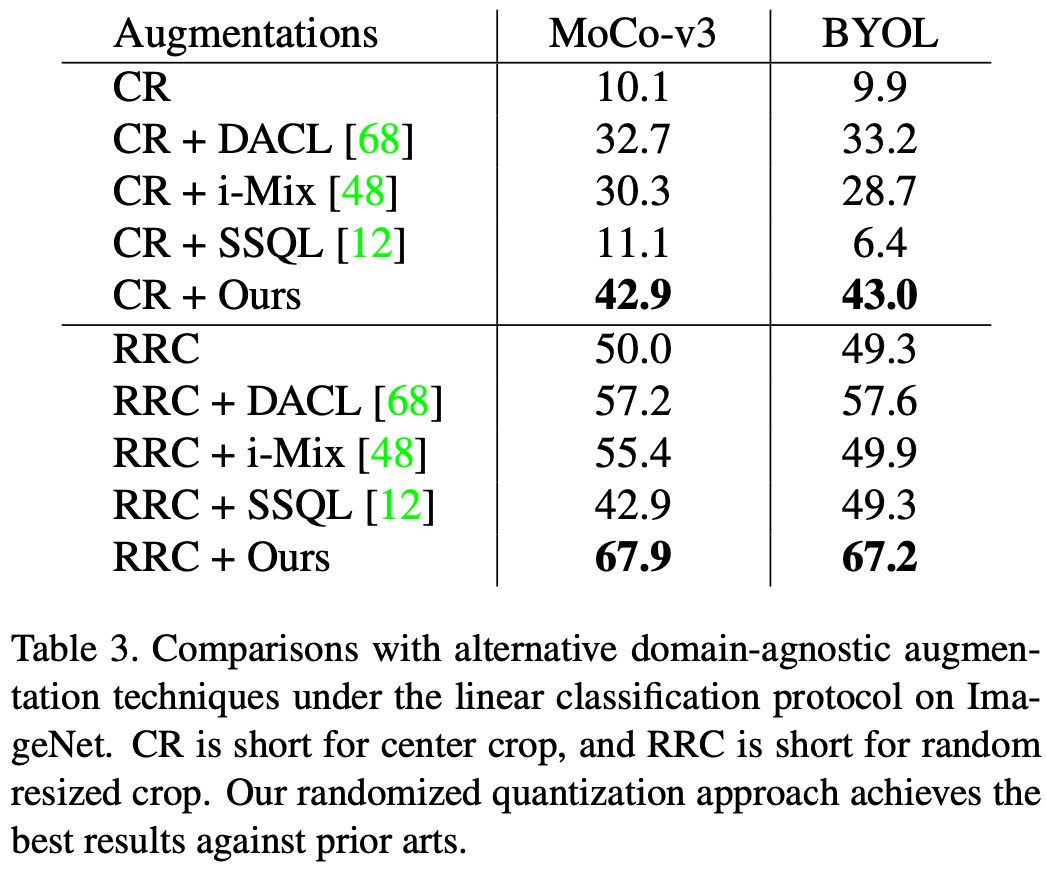
#🎜🎜🎜🎜## menilai kesan pengkuantitian rawak yang digunakan pada MoCo-v3 dan BYOL pada set data ImageNet-1K Indeks penilaian ialah penilaian linear. Apabila digunakan secara bersendirian sebagai satu-satunya kaedah penambahan data, iaitu, penambahan dalam artikel ini digunakan pada pangkas tengah imej asal, dan apabila digunakan bersama-sama dengan pangkas saiz rawak biasa (RRC), kaedah ini telah mencapai hasil yang lebih baik. daripada kaedah Kajian penyeliaan kendiri am yang sedia ada untuk hasil yang lebih baik.
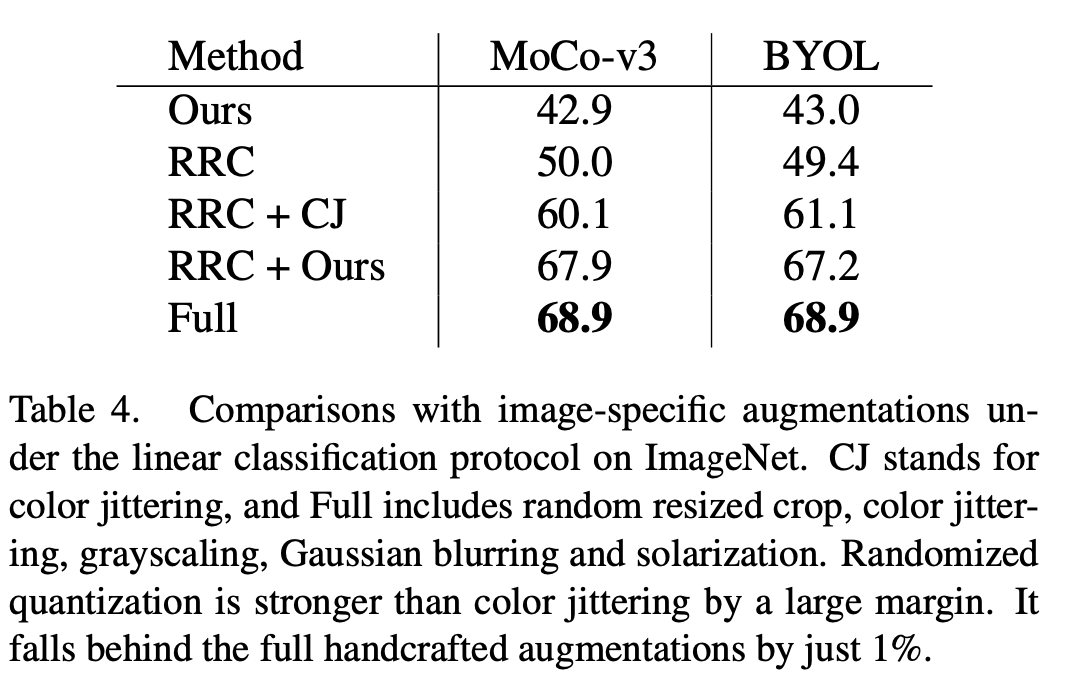
Berbanding dengan kaedah peningkatan data sedia ada yang dibangunkan untuk data imej, seperti warna jittering (CJ), Kaedah dalam artikel ini mempunyai kelebihan prestasi yang jelas. Pada masa yang sama, kaedah ini juga boleh menggantikan satu siri kaedah peningkatan data yang kompleks (Penuh) dalam MoCo-v3/BYOL, termasuk kegelisahan warna, skala kelabu rawak, kabur Gaussian rawak, Pendedahan rawak (pesolaran), dan mencapai kesan yang serupa dengan kaedah peningkatan data yang kompleks.
Kandungan yang perlu ditulis semula ialah: Modal 2: Awan Titik 3D🎜#🎜 #
Dalam tugas pengelasan set data ModelNet40 dan tugas pembahagian set data Bahagian ShapeNet, kajian ini mengesahkan keunggulan pengkuantitian rawak berbanding kaedah penyeliaan kendiri sedia ada. Terutama apabila jumlah data dalam set latihan hiliran adalah kecil, kaedah kajian ini jauh melebihi algoritma penyeliaan sendiri awan titik sedia ada 🎜🎜#Kandungan ditulis semula: Mod ketiga: suara Kaedah ini juga mencapai prestasi yang lebih baik daripada kaedah pembelajaran penyeliaan kendiri sedia ada pada set data pertuturan. Kertas kerja ini mengesahkan keunggulan kaedah ini pada enam set data hiliran Antaranya, pada set data yang paling sukar VoxCeleb1 (yang mengandungi bilangan kategori terbesar dan jauh melebihi bilangan set data lain), kaedah ini telah mencapai peningkatan prestasi yang ketara. (5.6 mata).
Kandungan yang ditulis semula ialah: Mod 4: DABS#🎟#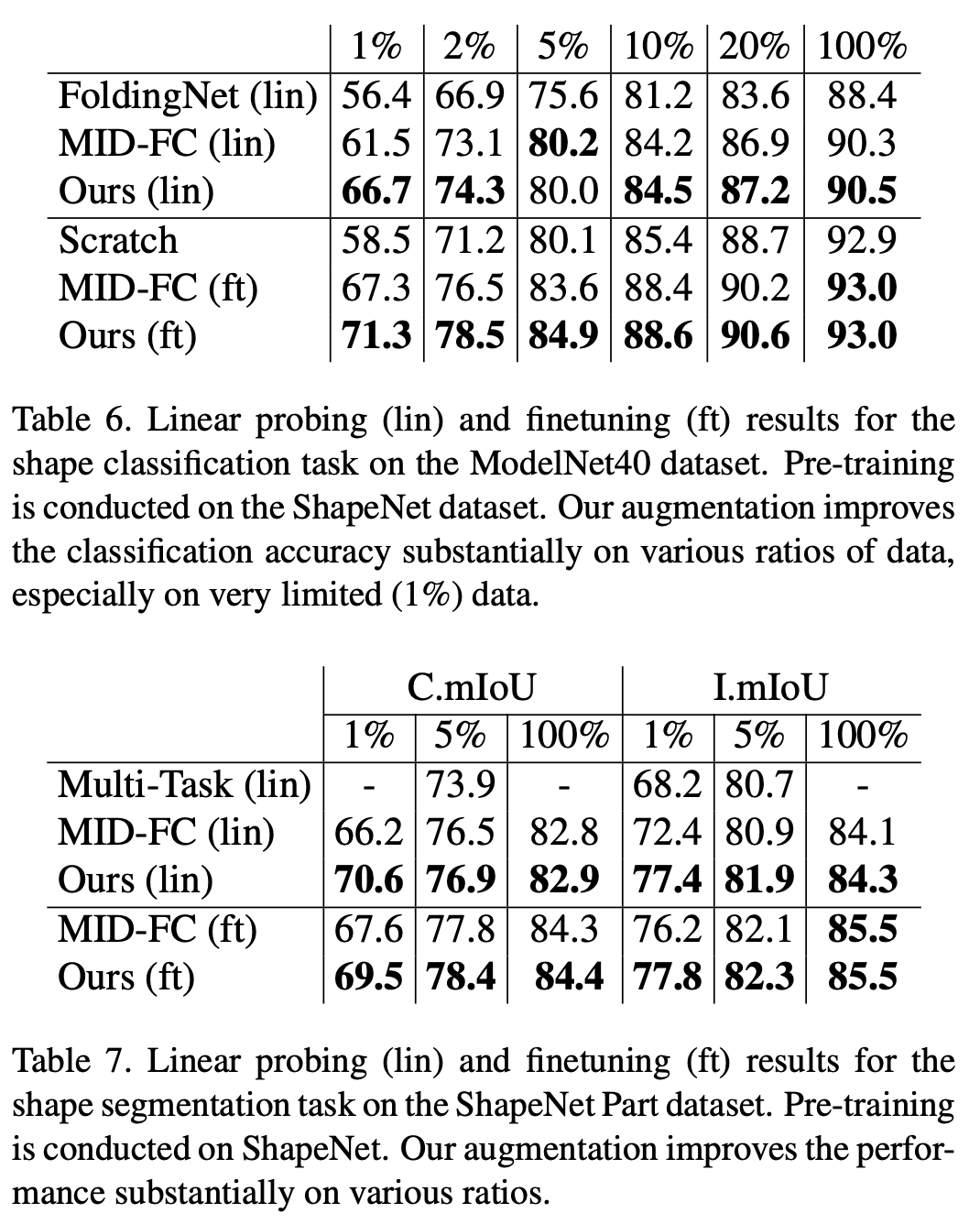 #🎜 🎜🎜#
#🎜 🎜🎜#
DABS ialah penanda aras pembelajaran penyeliaan kendiri am yang meliputi pelbagai data modal, termasuk imej semula jadi, teks, pertuturan, data penderia dan imej perubatan dan gambar, teks, dsb. Mengenai pelbagai data modal yang diliputi oleh DABS, kaedah kami juga lebih baik daripada kaedah pembelajaran penyeliaan kendiri mod sedia ada
# 🎜🎜##🎜🎜 #Pembaca yang berminat boleh membaca kertas asal untuk mengetahui butiran kandungan penyelidikanAtas ialah kandungan terperinci Teknologi peningkatan data sejagat, kuantisasi rawak sesuai untuk sebarang modaliti data. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
 Apakah empat alat analisis data besar?
Apakah empat alat analisis data besar?
 Penggunaan fungsi instr dalam oracle
Penggunaan fungsi instr dalam oracle
 Penggunaan arahan NTSD
Penggunaan arahan NTSD
 Apakah rangka kerja rpc?
Apakah rangka kerja rpc?
 Apakah rangka kerja kecerdasan buatan Python?
Apakah rangka kerja kecerdasan buatan Python?
 Windows tidak dapat menyambung ke penyelesaian wifi
Windows tidak dapat menyambung ke penyelesaian wifi
 Penyelesaian skrin hitam permulaan Ubuntu
Penyelesaian skrin hitam permulaan Ubuntu








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



