
 Peranti teknologi
AI
Baichuan Intelligent mengeluarkan model besar Baichuan2: ia mendahului sepenuhnya daripada Llama2, dan bahagian latihan juga adalah sumber terbuka
Peranti teknologi
AI
Baichuan Intelligent mengeluarkan model besar Baichuan2: ia mendahului sepenuhnya daripada Llama2, dan bahagian latihan juga adalah sumber terbuka
Baichuan Intelligent mengeluarkan model besar Baichuan2: ia mendahului sepenuhnya daripada Llama2, dan bahagian latihan juga adalah sumber terbuka

Apabila industri terkejut bahawa Baichuan Intelligent mengeluarkan model besar dalam purata 28 hari, syarikat itu tidak berhenti.
Pada sidang akhbar pada petang 6 September, Baichuan Intelligence mengumumkan sumber terbuka rasmi model besar Baichuan-2 yang telah diperhalusi.
 Zhang Bo, ahli akademik Akademi Sains China dan dekan kehormat Institut Kecerdasan Buatan Universiti Tsinghua, berada di sidang akhbar.
Zhang Bo, ahli akademik Akademi Sains China dan dekan kehormat Institut Kecerdasan Buatan Universiti Tsinghua, berada di sidang akhbar.
Ini adalah satu lagi keluaran baharu oleh Baichuan sejak keluaran model besar Baichuan-53B pada bulan Ogos. Model sumber terbuka termasuk Baichuan2-7B, Baichuan2-13B, Baichuan2-13B-Chat dan versi terkuantiti 4-bit mereka, dan semuanya percuma dan tersedia secara komersial.
Sebagai tambahan kepada pendedahan penuh model, Baichuan Intelligence juga membuka Sumber Check Point untuk latihan model kali ini, dan menerbitkan laporan teknikal Baichuan 2, yang memperincikan butiran latihan model baharu itu. Wang Xiaochuan, pengasas dan Ketua Pegawai Eksekutif Baichuan Intelligence, menyatakan harapan bahawa langkah ini dapat membantu institusi akademik model besar, pemaju dan pengguna perusahaan memperoleh pemahaman yang mendalam tentang proses latihan model besar, dan lebih menggalakkan pembangunan teknologi model besar penyelidikan akademik dan komuniti.
Baichuan 2 model besar pautan asal: https://github.com/baichuan-inc/Baichuan2
Laporan teknikal: https://cdn.baichuan-ai com /paper/Baichuan2-technical-report.pdf
Model sumber terbuka hari ini bersaiz "lebih kecil" berbanding model besar, antaranya Baichuan2-7B-Base dan Baichuan2-13B-Base kedua-duanya berdasarkan 2.6 trilion data berbilang bahasa berkualiti tinggi digunakan untuk latihan Atas dasar mengekalkan keupayaan penjanaan dan penciptaan model sumber terbuka generasi sebelumnya, keupayaan dialog berbilang pusingan yang lancar, dan ambang penggunaan yang rendah, kedua-dua model mempunyai kelebihan yang kukuh dalam. matematik, kod dan sebagainya, keselamatan, penaakulan logik, pemahaman semantik dan kebolehan lain telah dipertingkatkan dengan ketara.
"Ringkasnya, model parameter Baichuan7B 7 bilion sudah setanding dengan model parameter 13 bilion LLaMA2 pada penanda aras Bahasa Inggeris. Oleh itu, kita boleh membuat perbezaan besar dengan model kecil dan kecil model adalah bersamaan dengan keupayaan model yang besar, dan model dengan saiz yang sama boleh mencapai prestasi yang lebih tinggi, secara menyeluruh mengatasi prestasi LLaMA2," kata Wang Xiaochuan.
Berbanding dengan model 13B generasi sebelumnya, Baichuan2-13B-Base mempunyai peningkatan 49% dalam keupayaan matematik, peningkatan 46% dalam keupayaan pengekodan, peningkatan 37% dalam keupayaan keselamatan, peningkatan 25% dalam keupayaan penaakulan logik, dan peningkatan dalam keupayaan pemahaman semantik 15%.
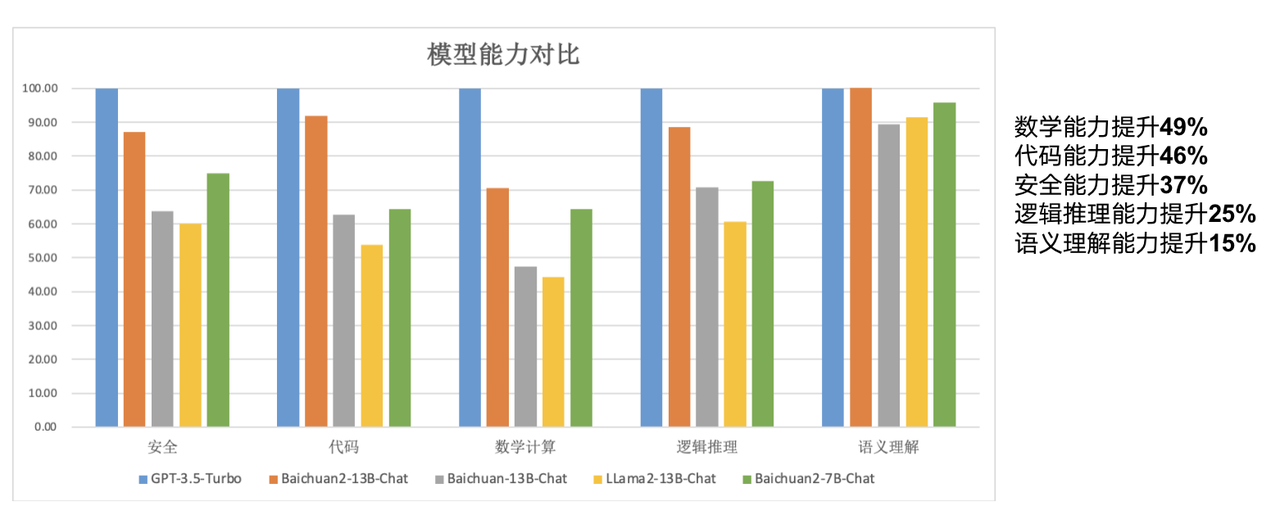
Menurut laporan, pada model baharu itu, penyelidik dari Baichuan Intelligence telah membuat banyak pengoptimuman daripada pemerolehan data kepada penalaan halus.
"Kami memperoleh lebih banyak pengalaman daripada carian sebelumnya, menjalankan pemarkahan kualiti kandungan berbutir-butir pada sejumlah besar data latihan model, dan menggunakan 260 juta T tahap korpus untuk melatih model 7B dan 13B. Dan sokongan berbilang bahasa telah ditambah," kata Wang Xiaochuan. "Kami boleh mencapai prestasi latihan sebanyak 180TFLOPS dalam kelompok Qianka A800, dan kadar penggunaan mesin melebihi 50%. Selain itu, kami juga telah menyelesaikan banyak kerja penjajaran keselamatan." Kedua-dua model telah menunjukkan prestasi yang baik pada senarai penilaian utama Dalam beberapa penanda aras penilaian berwibawa seperti MMLU, CMMLU dan GSM8K, mereka mendahului LLaMA2 dengan margin yang besar Berbanding dengan model lain dengan bilangan parameter yang sama, prestasi mereka juga sangat mengagumkan . Prestasinya jauh lebih baik daripada model pesaing LLaMA2 dengan saiz yang sama.
Apa yang lebih patut disebut ialah menurut pelbagai penanda aras penilaian bahasa Inggeris yang berwibawa seperti MMLU, Baichuan2-7B mempunyai 7 bilion parameter pada tahap yang sama dengan LLaMA2 dengan 13 bilion parameter pada tugas bahasa Inggeris arus perdana.
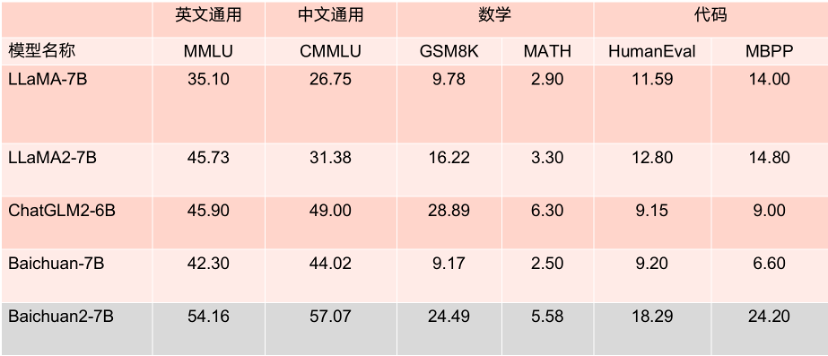 Keputusan penanda aras model parameter 7B.
Keputusan penanda aras model parameter 7B.
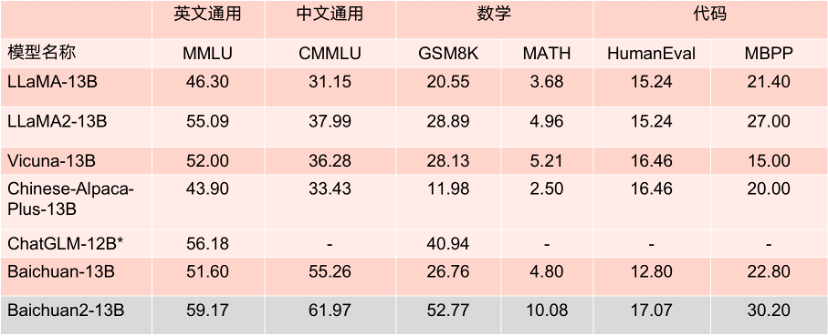 Keputusan penanda aras model parameter 13B.
Keputusan penanda aras model parameter 13B.
Baichuan2-7B dan Baichuan2-13B bukan sahaja terbuka sepenuhnya kepada penyelidikan akademik, tetapi pembangun juga boleh menggunakannya secara percuma secara komersial selepas memohon melalui e-mel untuk mendapatkan lesen komersial rasmi.
"Selain keluaran model, kami juga berharap dapat memberikan lebih banyak sokongan kepada bidang akademik," kata Wang Xiaochuan. "Selain laporan teknikal, kami juga telah membuka model parameter berat dalam proses latihan model besar Baichuan2. Ini boleh membantu semua orang memahami pra-latihan, atau melakukan penalaan halus dan peningkatan. Ini juga kali pertama di China bahawa sebuah syarikat telah membuka model seperti proses Latihan "
Latihan model besar termasuk beberapa langkah seperti pemerolehan data besar-besaran berkualiti tinggi, latihan yang stabil bagi kelompok latihan berskala besar dan algoritma model. penalaan. Setiap pautan memerlukan pelaburan sejumlah besar bakat, kuasa pengkomputeran dan sumber lain Kos yang tinggi untuk melatih model sepenuhnya dari awal telah menghalang komuniti akademik daripada menjalankan penyelidikan mendalam tentang latihan model besar.
Baichuan Intelligence mempunyai Check Ponit sumber terbuka untuk keseluruhan proses latihan model dari 220B hingga 2640B. Ini amat bernilai bagi institusi penyelidikan saintifik untuk mengkaji proses latihan model besar, latihan model berterusan dan penjajaran nilai model, dsb., dan boleh menggalakkan kemajuan penyelidikan saintifik model besar domestik.
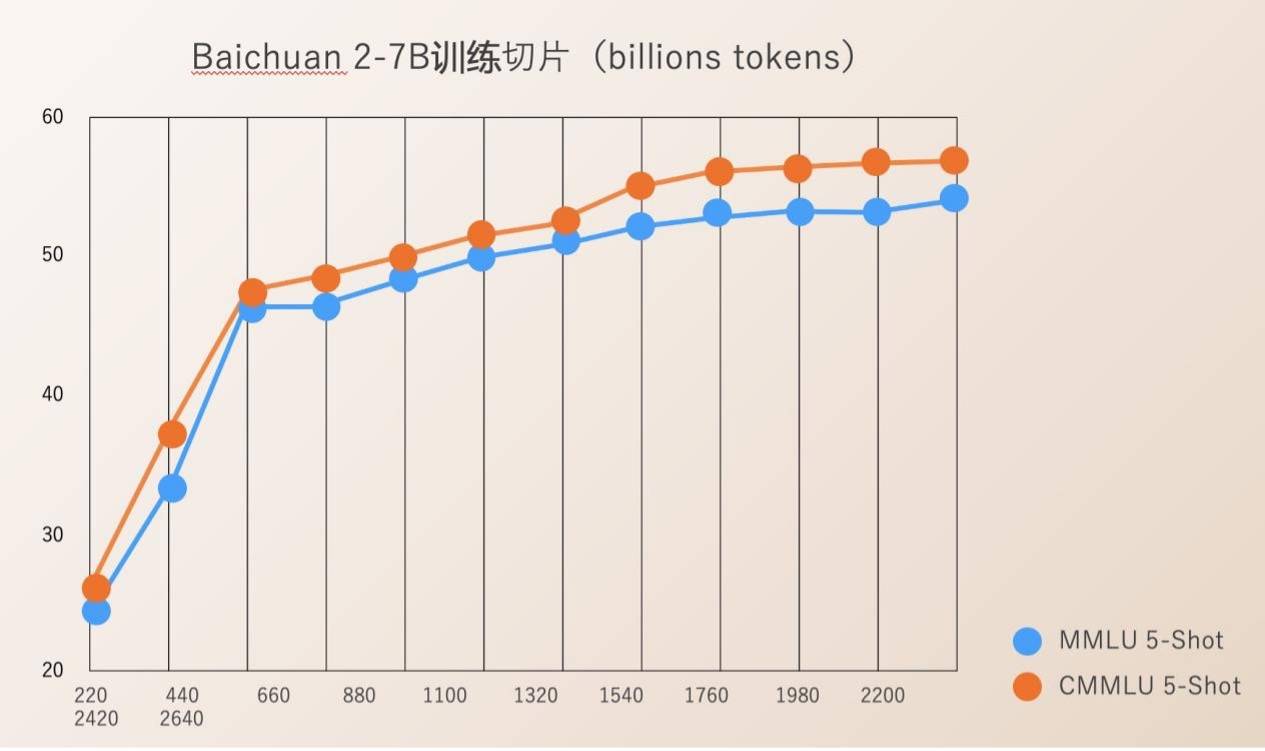
Sebelum ini, kebanyakan model sumber terbuka hanya mendedahkan berat model mereka sendiri dan jarang menyebut butiran latihan Pembangun hanya boleh melakukan penalaan halus yang terhad, menjadikannya sukar untuk menjalankan penyelidikan yang mendalam.
Laporan teknikal Baichuan 2 yang diterbitkan oleh Baichuan Intelligence memperincikan keseluruhan proses latihan Baichuan 2, termasuk pemprosesan data, pengoptimuman struktur model, undang-undang penskalaan, penunjuk proses, dsb.
Sejak penubuhannya, Baichuan Intelligence menganggap mempromosikan kemakmuran model besar ekologi China melalui sumber terbuka sebagai hala tuju pembangunan penting syarikat. Kurang daripada empat bulan selepas penubuhannya, ia telah mengeluarkan dua model besar Cina komersial percuma sumber terbuka, Baichuan-7B dan Baichuan-13B, serta model besar yang dipertingkatkan carian Baichuan-53B Kedua-dua model besar sumber terbuka telah dinilai dalam banyak ulasan berwibawa Ia berada pada kedudukan tinggi dalam senarai dan telah dimuat turun lebih daripada 5 juta kali.
Minggu lepas, pelancaran kumpulan pertama fotografi perkhidmatan awam model berskala besar merupakan berita penting dalam bidang teknologi. Antara syarikat model besar yang diasaskan tahun ini, Baichuan Intelligent adalah satu-satunya yang telah didaftarkan di bawah "Langkah Interim untuk Pengurusan Perkhidmatan Kepintaran Buatan Generatif" dan secara rasmi boleh menyediakan perkhidmatan kepada orang ramai.
Dengan keupayaan R&D model besar asas peneraju industri dan keupayaan inovasi, kedua-dua model besar Baichuan 2 sumber terbuka kali ini telah menerima respons positif daripada perusahaan huluan dan hiliran, termasuk Tencent Cloud, Alibaba Cloud, Volcano Ark, Huawei, MediaTek dan banyak lagi perusahaan terkenal Semua mengambil bahagian dalam persidangan ini dan mencapai kerjasama dengan Baichuan Intelligence. Menurut laporan, jumlah muat turun model besar Baichuan Intelligence pada Hugging Face telah mencecah 3.37 juta pada bulan lalu.
Menurut rancangan Baichuan Intelligence sebelum ini, tahun ini mereka akan mengeluarkan model besar dengan ratusan bilion parameter dan melancarkan "aplikasi super" pada suku pertama tahun depan.
Atas ialah kandungan terperinci Baichuan Intelligent mengeluarkan model besar Baichuan2: ia mendahului sepenuhnya daripada Llama2, dan bahagian latihan juga adalah sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
Ia juga merupakan video Tusheng, tetapi PaintsUndo telah mengambil laluan yang berbeza. Pengarang ControlNet LvminZhang mula hidup semula! Kali ini saya menyasarkan bidang lukisan. Projek baharu PaintsUndo telah menerima 1.4kstar (masih meningkat secara menggila) tidak lama selepas ia dilancarkan. Alamat projek: https://github.com/lllyasviel/Paints-UNDO Melalui projek ini, pengguna memasukkan imej statik, dan PaintsUndo secara automatik boleh membantu anda menjana video keseluruhan proses mengecat, daripada draf baris hingga produk siap . Semasa proses lukisan, perubahan garisan adalah menakjubkan Hasil akhir video sangat serupa dengan imej asal: Mari kita lihat lukisan lengkap.
 Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Jika jawapan yang diberikan oleh model AI tidak dapat difahami sama sekali, adakah anda berani menggunakannya? Memandangkan sistem pembelajaran mesin digunakan dalam bidang yang lebih penting, menjadi semakin penting untuk menunjukkan sebab kita boleh mempercayai output mereka, dan bila tidak mempercayainya. Satu cara yang mungkin untuk mendapatkan kepercayaan dalam output sistem yang kompleks adalah dengan menghendaki sistem menghasilkan tafsiran outputnya yang boleh dibaca oleh manusia atau sistem lain yang dipercayai, iaitu, difahami sepenuhnya sehingga apa-apa ralat yang mungkin boleh dilakukan. dijumpai. Contohnya, untuk membina kepercayaan dalam sistem kehakiman, kami memerlukan mahkamah memberikan pendapat bertulis yang jelas dan boleh dibaca yang menjelaskan dan menyokong keputusan mereka. Untuk model bahasa yang besar, kita juga boleh menggunakan pendekatan yang sama. Walau bagaimanapun, apabila mengambil pendekatan ini, pastikan model bahasa menjana
 Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Semua pengarang kertas kerja ini adalah daripada pasukan guru Zhang Lingming di Universiti Illinois di Urbana-Champaign (UIUC), termasuk: Steven Code repair; pelajar kedoktoran tahun empat, penyelidik
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
Baru-baru ini, Hipotesis Riemann, yang dikenali sebagai salah satu daripada tujuh masalah utama milenium, telah mencapai kejayaan baharu. Hipotesis Riemann ialah masalah yang tidak dapat diselesaikan yang sangat penting dalam matematik, berkaitan dengan sifat tepat taburan nombor perdana (nombor perdana ialah nombor yang hanya boleh dibahagikan dengan 1 dan dirinya sendiri, dan ia memainkan peranan asas dalam teori nombor). Dalam kesusasteraan matematik hari ini, terdapat lebih daripada seribu proposisi matematik berdasarkan penubuhan Hipotesis Riemann (atau bentuk umumnya). Dalam erti kata lain, sebaik sahaja Hipotesis Riemann dan bentuk umumnya dibuktikan, lebih daripada seribu proposisi ini akan ditetapkan sebagai teorem, yang akan memberi kesan yang mendalam terhadap bidang matematik dan jika Hipotesis Riemann terbukti salah, maka antara cadangan ini sebahagian daripadanya juga akan kehilangan keberkesanannya. Kejayaan baharu datang daripada profesor matematik MIT Larry Guth dan Universiti Oxford
 Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
sorakan! Bagaimana rasanya apabila perbincangan kertas adalah perkataan? Baru-baru ini, pelajar di Universiti Stanford mencipta alphaXiv, forum perbincangan terbuka untuk kertas arXiv yang membenarkan soalan dan ulasan disiarkan terus pada mana-mana kertas arXiv. Pautan laman web: https://alphaxiv.org/ Malah, tidak perlu melawati tapak web ini secara khusus. Hanya tukar arXiv dalam mana-mana URL kepada alphaXiv untuk terus membuka kertas yang sepadan di forum alphaXiv: anda boleh mencari perenggan dengan tepat dalam. kertas itu, Ayat: Dalam ruang perbincangan di sebelah kanan, pengguna boleh menyiarkan soalan untuk bertanya kepada pengarang tentang idea dan butiran kertas tersebut Sebagai contoh, mereka juga boleh mengulas kandungan kertas tersebut, seperti: "Diberikan kepada
 Penjanaan video tanpa had, perancangan dan membuat keputusan, penyebaran paksa penyepaduan ramalan token seterusnya dan penyebaran jujukan penuh
Jul 23, 2024 pm 02:05 PM
Penjanaan video tanpa had, perancangan dan membuat keputusan, penyebaran paksa penyepaduan ramalan token seterusnya dan penyebaran jujukan penuh
Jul 23, 2024 pm 02:05 PM
Pada masa ini, model bahasa berskala besar autoregresif menggunakan paradigma ramalan token seterusnya telah menjadi popular di seluruh dunia Pada masa yang sama, sejumlah besar imej dan video sintetik di Internet telah menunjukkan kepada kami kuasa model penyebaran. Baru-baru ini, pasukan penyelidik di MITCSAIL (salah seorang daripadanya ialah Chen Boyuan, pelajar PhD di MIT) berjaya menyepadukan keupayaan berkuasa model resapan jujukan penuh dan model token seterusnya, dan mencadangkan paradigma latihan dan pensampelan: Diffusion Forcing (DF). ). Tajuk kertas: DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Alamat kertas: https:/
 Latihan aksiomatik membolehkan LLM mempelajari penaakulan kausal: model 67 juta parameter adalah setanding dengan trilion tahap parameter GPT-4
Jul 17, 2024 am 10:14 AM
Latihan aksiomatik membolehkan LLM mempelajari penaakulan kausal: model 67 juta parameter adalah setanding dengan trilion tahap parameter GPT-4
Jul 17, 2024 am 10:14 AM
Tunjukkan rantai sebab kepada LLM dan ia mempelajari aksiom. AI sudah pun membantu ahli matematik dan saintis menjalankan penyelidikan Contohnya, ahli matematik terkenal Terence Tao telah berulang kali berkongsi pengalaman penyelidikan dan penerokaannya dengan bantuan alatan AI seperti GPT. Untuk AI bersaing dalam bidang ini, keupayaan penaakulan sebab yang kukuh dan boleh dipercayai adalah penting. Penyelidikan yang akan diperkenalkan dalam artikel ini mendapati bahawa model Transformer yang dilatih mengenai demonstrasi aksiom transitiviti sebab pada graf kecil boleh digeneralisasikan kepada aksiom transitiviti pada graf besar. Dalam erti kata lain, jika Transformer belajar untuk melakukan penaakulan sebab yang mudah, ia boleh digunakan untuk penaakulan sebab yang lebih kompleks. Rangka kerja latihan aksiomatik yang dicadangkan oleh pasukan adalah paradigma baharu untuk pembelajaran penaakulan sebab berdasarkan data pasif, dengan hanya demonstrasi
