


Mula-mula perkenalkan beberapa konsep asas graf pengetahuan.
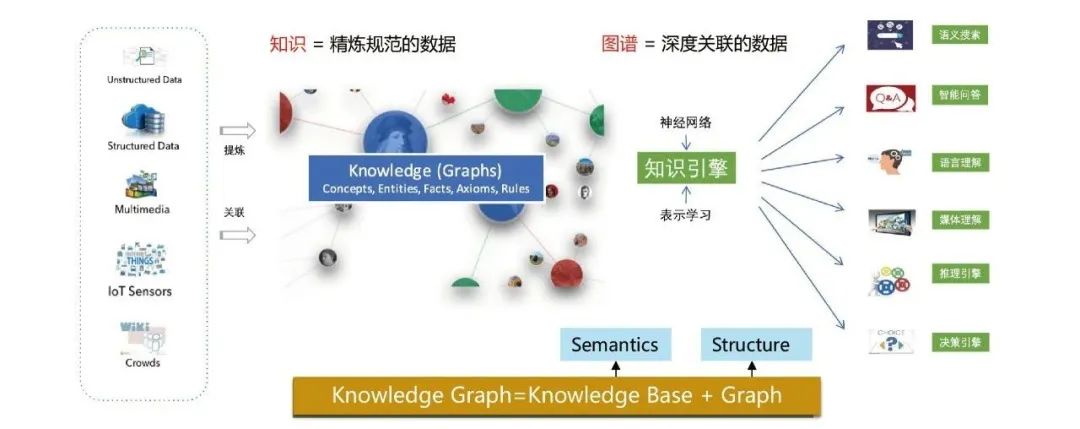
2. Mengapa kita perlu membina graf pengetahuan
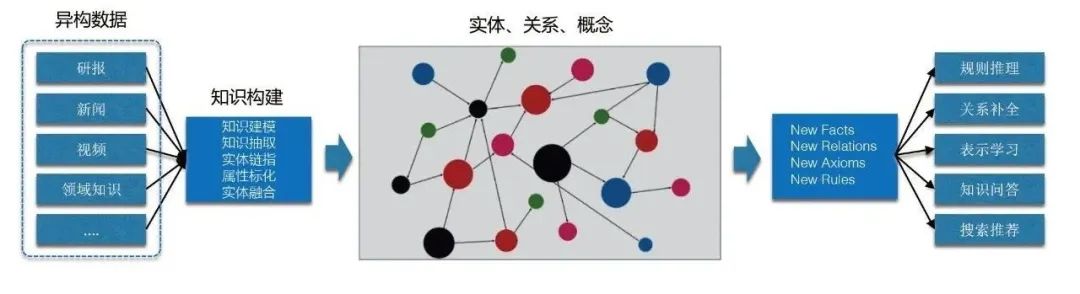
[2] Graf pengetahuan boleh membawa pelbagai faedah, termasuk:
Penyawaian semantik: Gunakan teknologi pembinaan graf untuk meningkatkan tahap penyeragaman dan penormalan entiti, perhubungan, konsep, dsb.
Penyepaduan asas pengetahuan berstruktur dalam domain perniagaan dan graf pengetahuan sedia ada juga dicapai melalui teknologi penjajaran entiti. 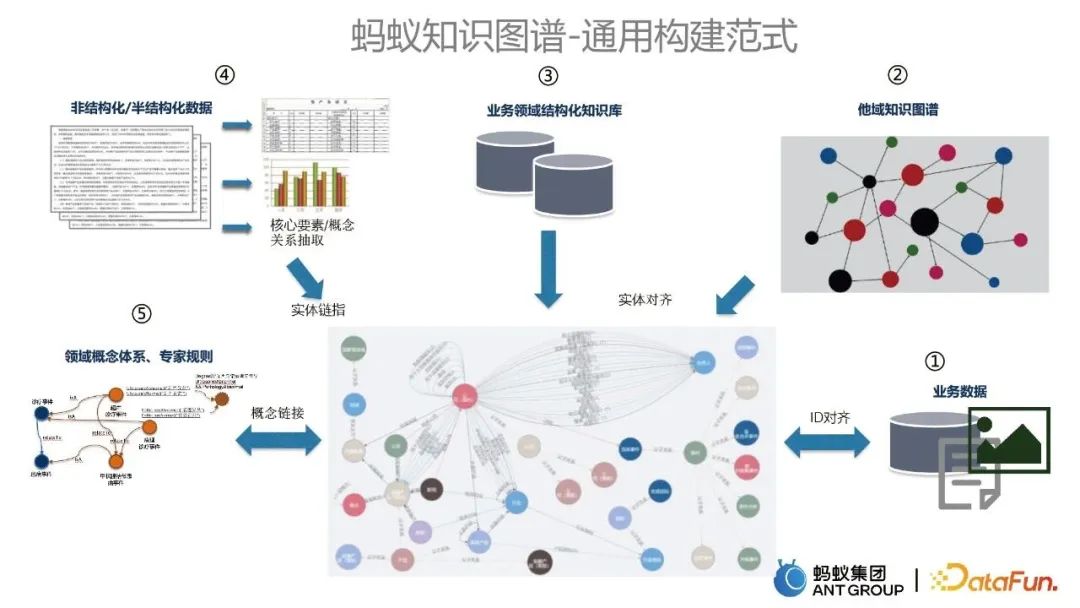
Data tidak berstruktur dan separa berstruktur, seperti teks, akan digunakan untuk mengekstrak maklumat dan mengemas kini peta sedia ada melalui teknologi pemautan entiti.
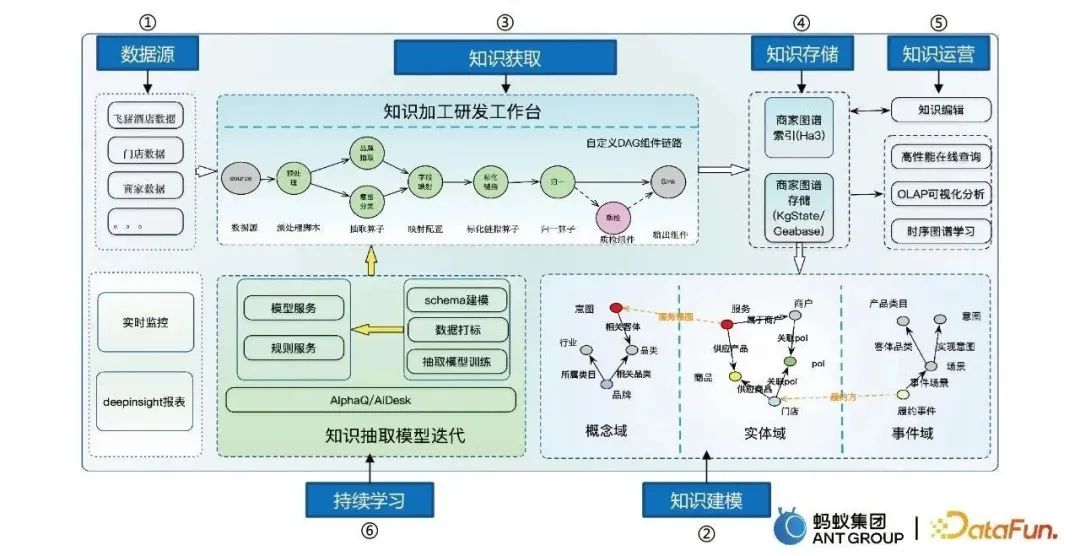
Proses pembinaan peta terutamanya merangkumi enam langkah:
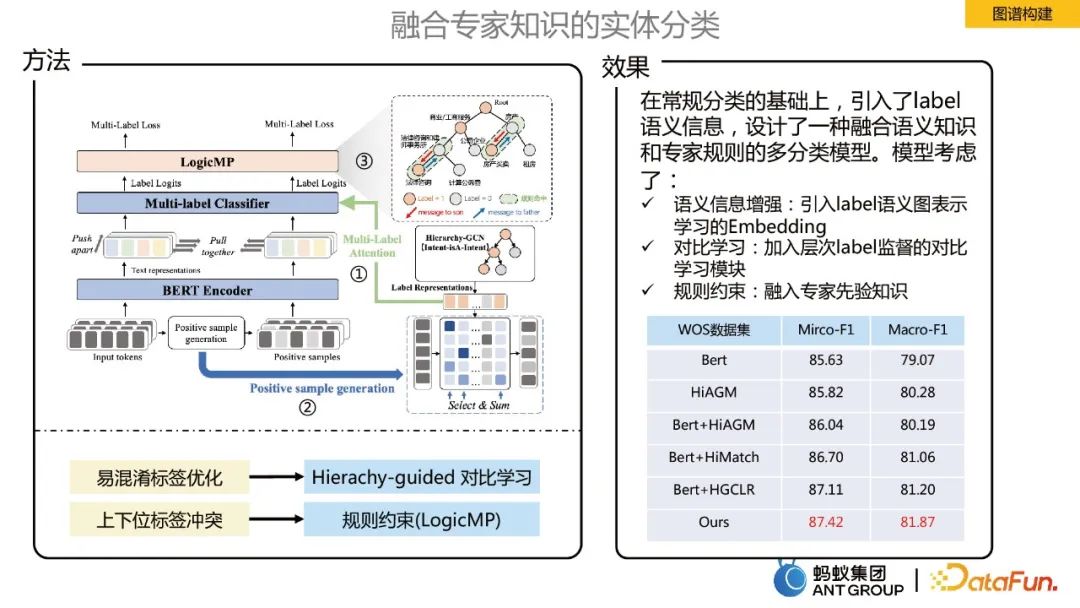
Dalam membina graf pengetahuan, adalah perlu untuk mengklasifikasikan entiti input, yang merupakan masalah skala besar senario Tugas pengelasan label. Untuk menyepadukan pengetahuan pakar untuk klasifikasi entiti, tiga perkara pengoptimuman utama berikut dibuat:
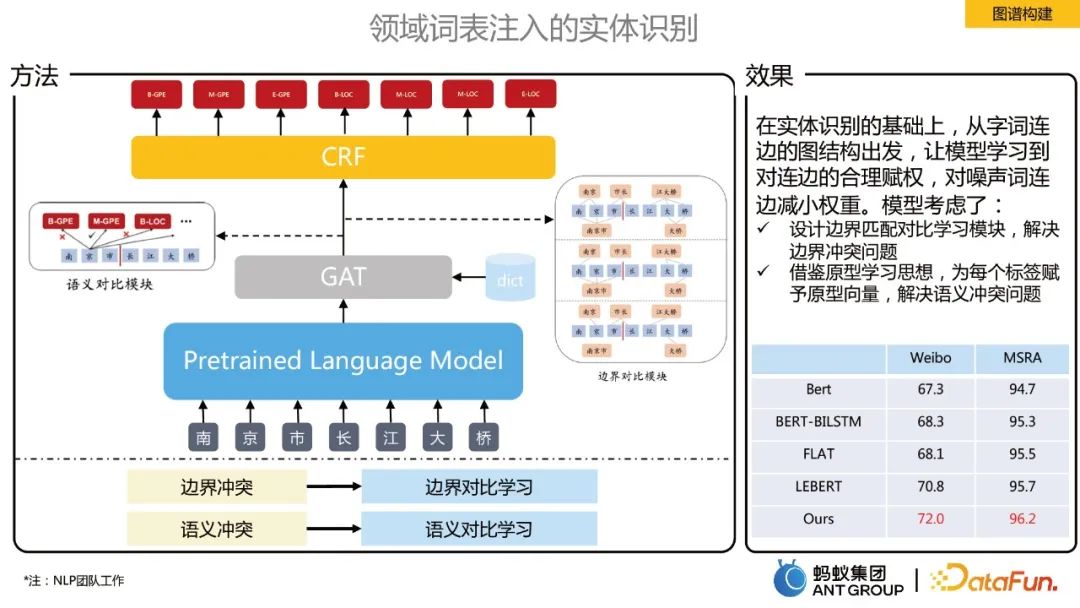
Atas dasar pengecaman entiti, bermula daripada struktur graf tepi perkataan, model mempelajari pemberat yang munasabah bagi bahagian tepi dan mengecilkan perkataan yang bising . Dua modul, pembelajaran kontrastif sempadan dan pembelajaran kontrastif semantik, dicadangkan:
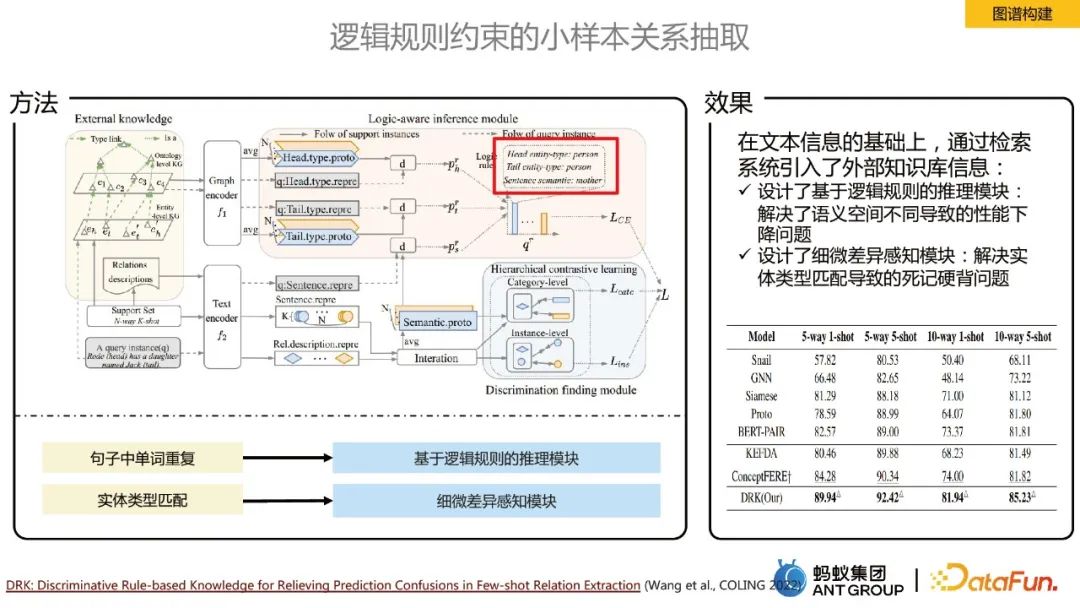
Dalam masalah domain, kami mempunyai sangat sedikit sampel berlabel dan akan menghadapi senario pengekstrakan beberapa pukulan atau sifar dalam kes ini Idea teras adalah untuk memperkenalkan asas pengetahuan luaran Untuk menyelesaikan masalah penurunan prestasi yang disebabkan oleh ruang semantik yang berbeza, modul penaakulan berdasarkan peraturan logik direka untuk menyelesaikan masalah pembelajaran hafalan yang disebabkan oleh pemadanan jenis entiti, a modul persepsi perbezaan halus direka bentuk.
Cantuman graf merujuk kepada cantuman maklumat antara graf dalam bidang perniagaan yang berbeza.
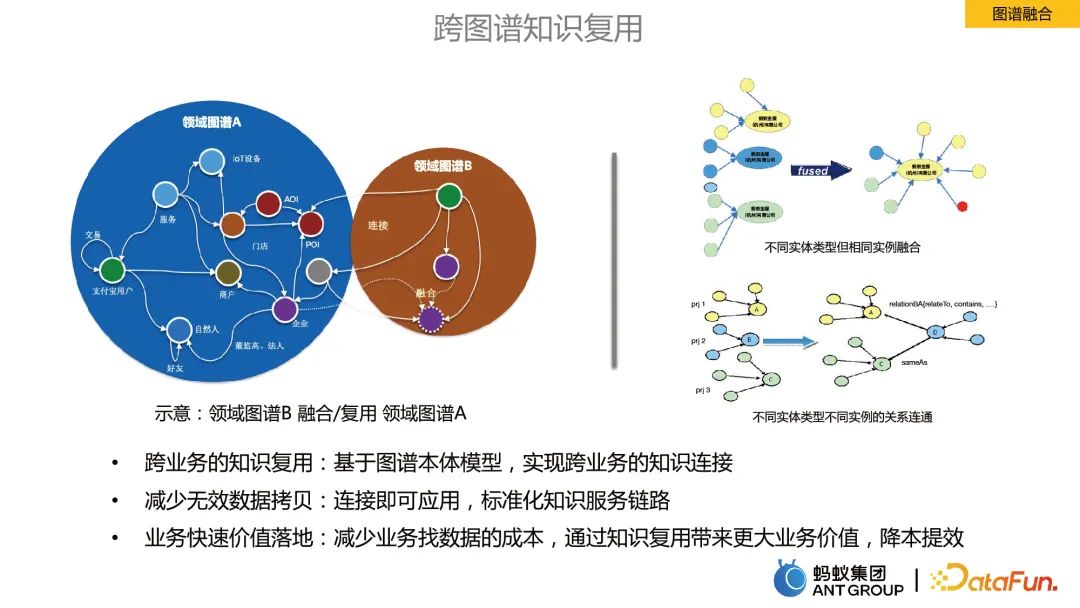
Faedah pelakuran graf:
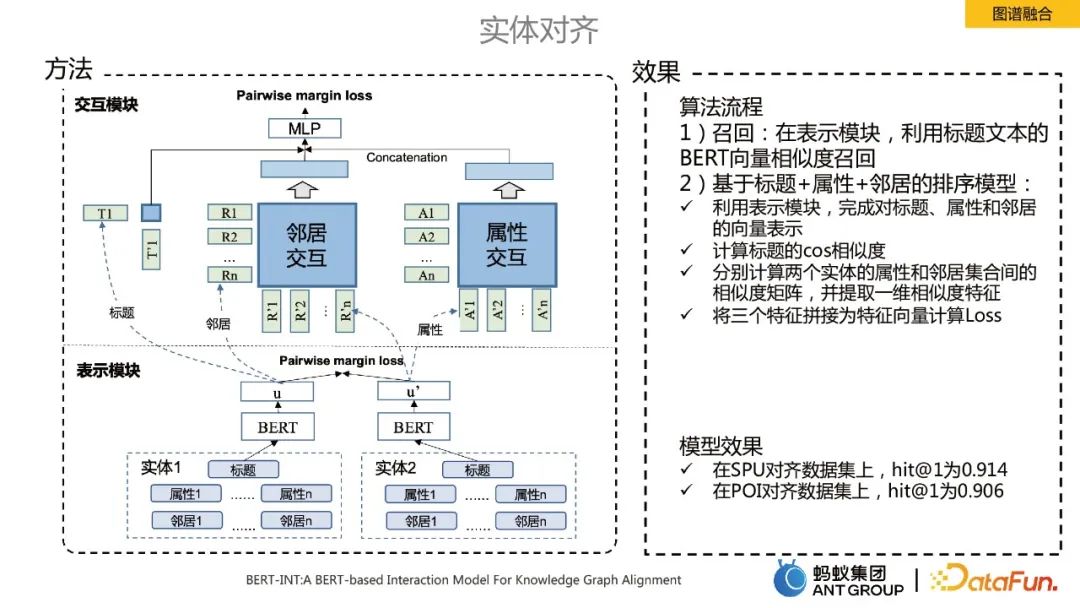
Titik teknikal teras dalam proses gabungan graf pengetahuan ialah penjajaran entiti Di sini kami menggunakan algoritma SOTA BERT-INT, yang terutamanya merangkumi dua modul, satu modul pembentangan dan satu lagi modul interaksi.
Proses pelaksanaan algoritma terutamanya termasuk mengingat dan menyusun:
Imbas kembali: Dalam modul perwakilan, penarikan semula persamaan vektor BERT bagi teks tajuk digunakan.
Model penarafan berdasarkan tajuk + atribut + jiran: ü Gunakan modul perwakilan untuk melengkapkan perwakilan vektor tajuk, atribut dan jiran:
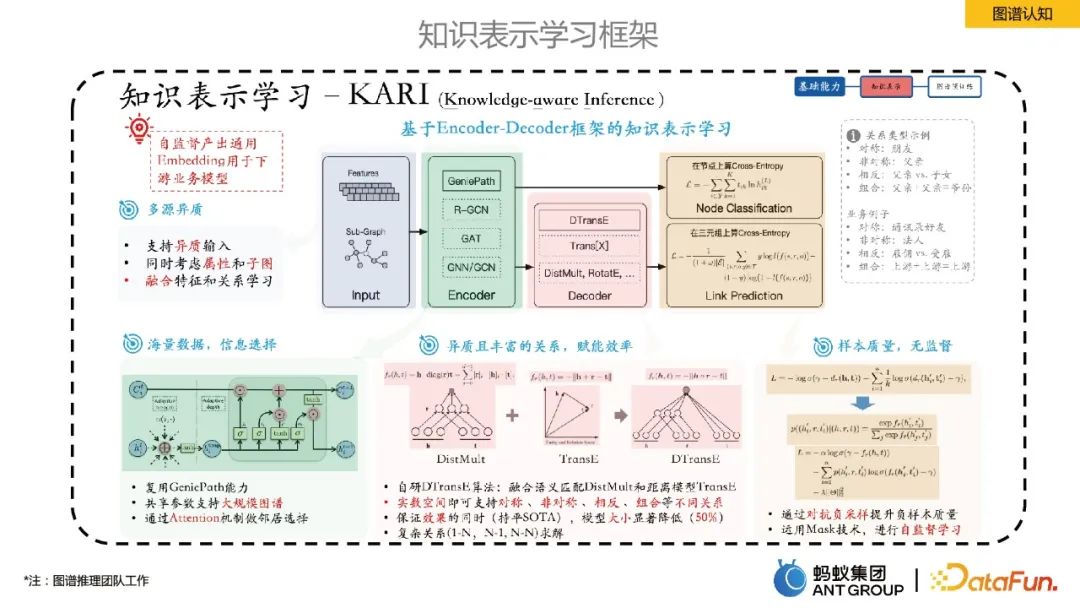
Bahagian ini terutamanya memperkenalkan rangka kerja pembelajaran perwakilan pengetahuan dalaman Ant.
Ant mencadangkan pembelajaran perwakilan pengetahuan berdasarkan rangka kerja Pengekod-Penyahkod. Antaranya, Pengekod ialah beberapa kaedah pembelajaran saraf graf, dan Penyahkod ialah beberapa pembelajaran perwakilan pengetahuan, seperti ramalan pautan. Rangka kerja pembelajaran perwakilan ini boleh menyelia sendiri pengeluaran entiti/perhubungan Embeddings sejagat, yang mempunyai beberapa faedah: 1) Saiz Benam jauh lebih kecil daripada ruang ciri asal, mengurangkan kos penyimpanan 2) Vektor berdimensi rendah lebih padat, mengurangkan dengan berkesan masalah kelangkaan data ; 3) Pembelajaran dalam ruang vektor yang sama menjadikan gabungan data heterogen daripada pelbagai sumber lebih semula jadi 4) Penyematan mempunyai kesejagatan tertentu dan mudah untuk kegunaan perniagaan hiliran.
Seterusnya, saya akan berkongsi beberapa kes aplikasi biasa graf pengetahuan dalam Kumpulan Semut. . Seperti yang ditunjukkan di bawah.
2. Beberapa kes tipikal
Kes 1: Pengingatan padanan berstruktur berdasarkan graf pengetahuan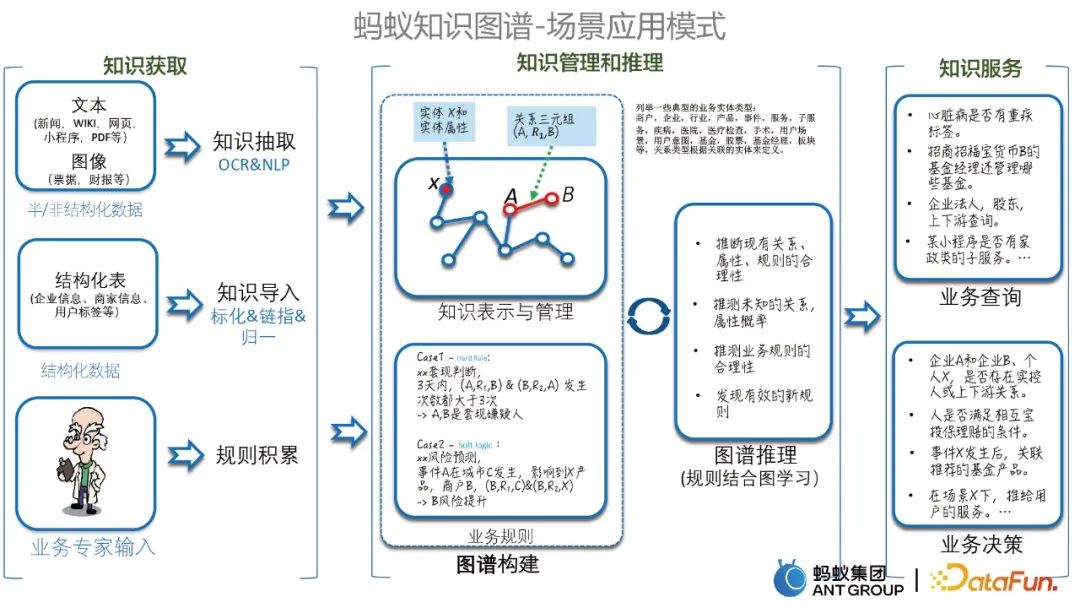
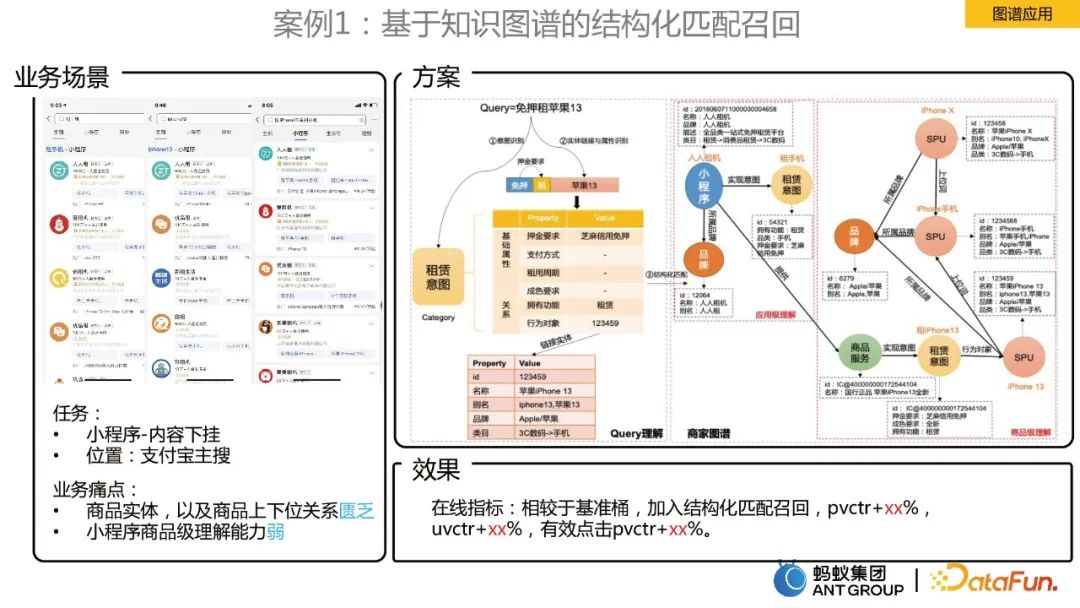
Entiti produk dan kekurangan hubungan antara peringkat atas dan bawah produk.
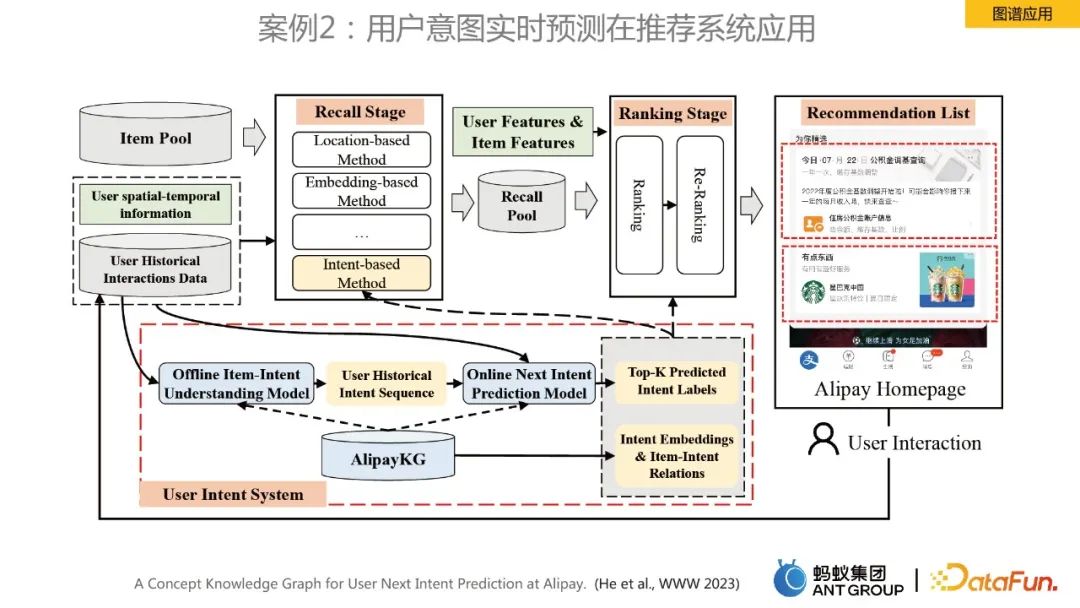 Kes 3: Pengesyoran kupon pemasaran yang menyepadukan perwakilan pengetahuan
Kes 3: Pengesyoran kupon pemasaran yang menyepadukan perwakilan pengetahuan
Untuk menyelesaikan masalah di atas, kami mereka bentuk algoritma penarikan semula vektor dalam yang menggabungkan perwakilan graf dinamik. Oleh kerana kami mendapati bahawa gelagat kupon penggunaan pengguna adalah kitaran, satu kelebihan statik tidak boleh memodelkan gelagat kitaran ini. Untuk tujuan ini, kami mula-mula membina graf dinamik, dan kemudian menggunakan algoritma graf dinamik yang dibangunkan sendiri oleh pasukan untuk mempelajari perwakilan Benam Selepas mendapatkan perwakilan, kami memasukkannya ke dalam model menara berkembar untuk penarikan semula vektor.
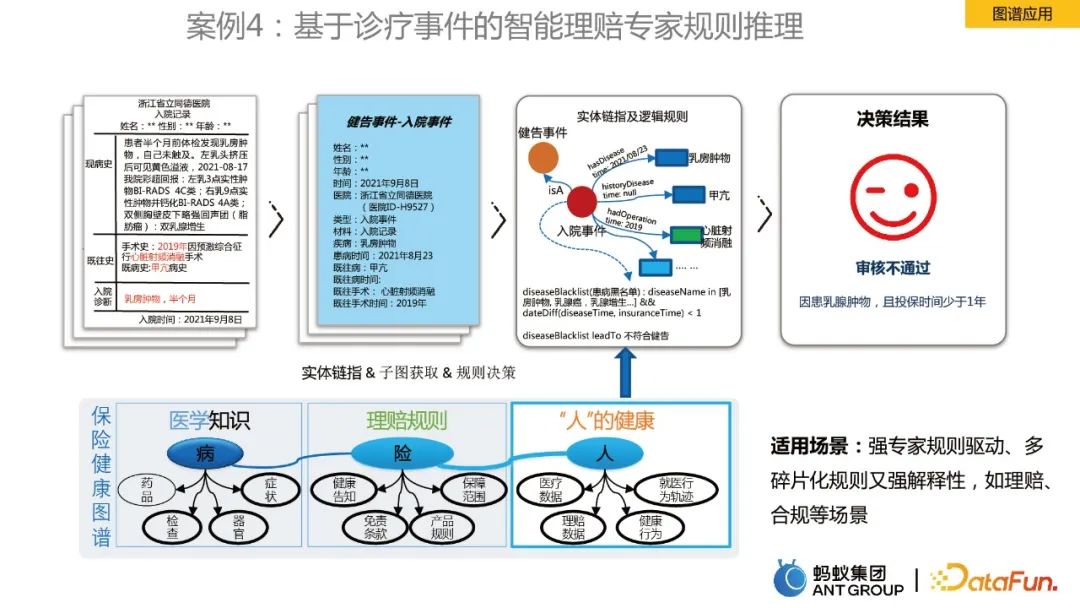
Kes terakhir ialah tentang penaakulan peraturan graf. Mengambil peta kesihatan insurans perubatan sebagai contoh, ia termasuk pengetahuan perubatan, peraturan tuntutan dan maklumat kesihatan "orang", yang dikaitkan dengan entiti dan ditambah dengan peraturan logik sebagai asas untuk membuat keputusan. Melalui peta, kecekapan penyelesaian tuntutan pakar telah dipertingkatkan.
Akhir sekali, mari kita bincangkan secara ringkas peluang graf pengetahuan dalam konteks perkembangan pesat model besar semasa.
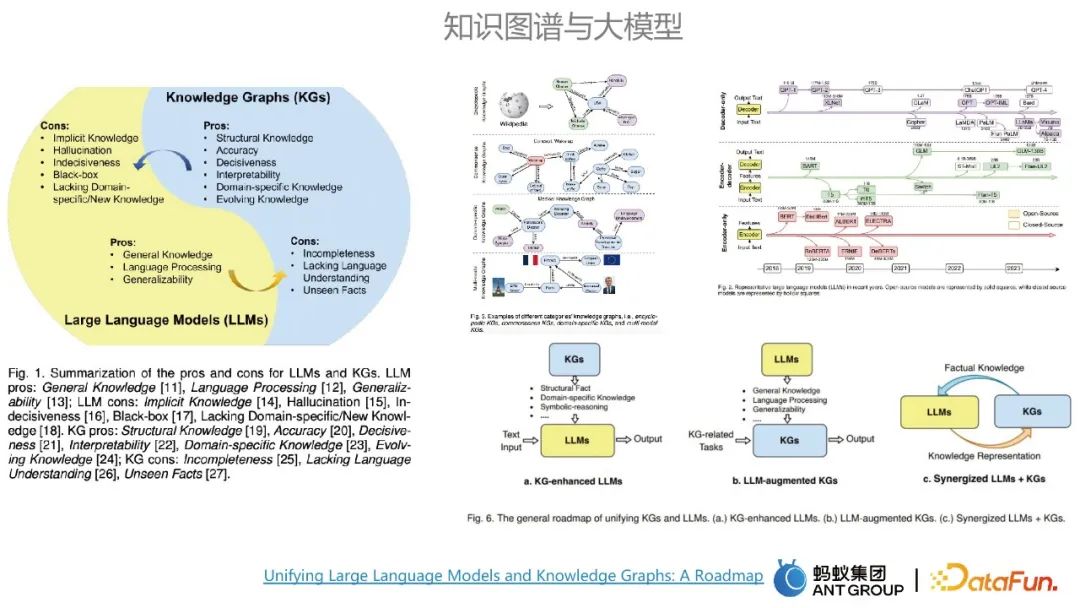
Graf pengetahuan dan model besar masing-masing mempunyai kelebihan dan kekurangannya sendiri Kelebihan utama model besar ialah pemodelan pengetahuan am dan kelemahan model adalah betul Ini boleh diimbangi oleh kelebihan graf pengetahuan. Kelebihan peta termasuk ketepatan yang tinggi dan kebolehtafsiran yang kuat. Model besar dan graf pengetahuan boleh mempengaruhi satu sama lain.
Biasanya terdapat tiga laluan untuk penyepaduan graf dan model besar Satu ialah menggunakan graf pengetahuan untuk meningkatkan model besar; dan graf pengetahuan, kelebihan pelengkap, model besar boleh dianggap sebagai pangkalan pengetahuan berparameter, dan graf pengetahuan boleh dianggap sebagai pangkalan pengetahuan yang dipaparkan.
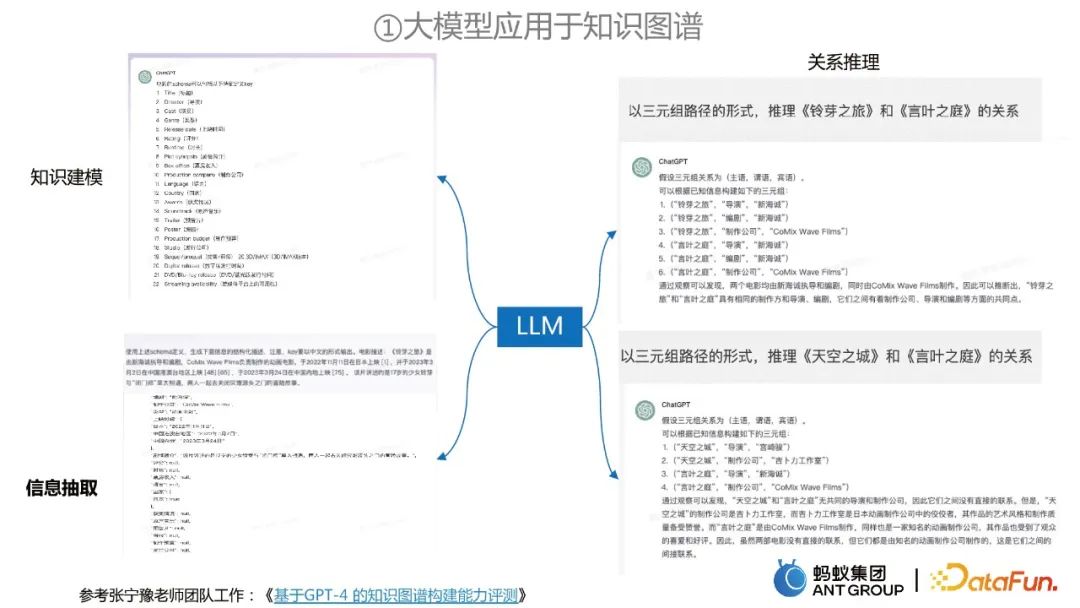
Dalam proses pembinaan graf pengetahuan, model besar boleh digunakan untuk pengekstrakan maklumat, pemodelan pengetahuan dan Penaakulan hubungan.

Kerja Akademi DAMO ini menguraikan masalah pengekstrakan maklumat kepada dua peringkat:
Menggunakan graf pengetahuan pada model besar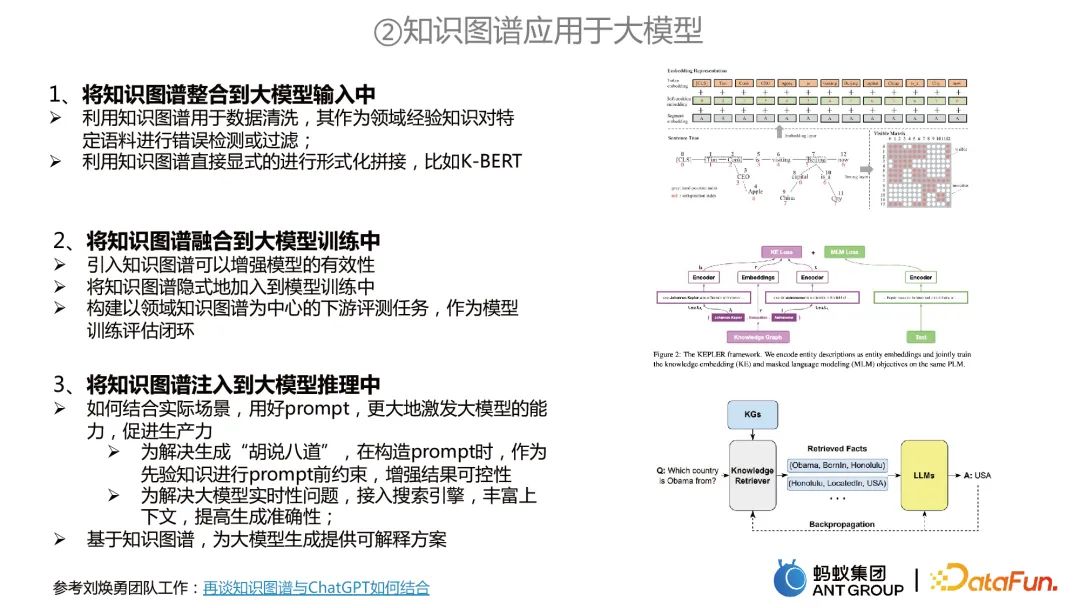
Menggunakan graf pengetahuan kepada model besar terutamanya merangkumi tiga aspek:
Mengintegrasikan graf input model yang besar. Graf pengetahuan boleh digunakan untuk pembersihan data, atau graf pengetahuan boleh digunakan untuk melaksanakan penyambungan formal secara langsung.
Sepadukan graf pengetahuan ke dalam latihan model besar. Sebagai contoh, dua tugasan dilatih pada masa yang sama Graf pengetahuan boleh digunakan untuk tugas perwakilan pengetahuan, dan model besar boleh digunakan untuk pra-latihan MLM, dan kedua-duanya dimodelkan secara bersama.
Suntikan graf pengetahuan ke dalam penaakulan model besar. Pertama, dua masalah dengan model besar boleh diselesaikan Satu ialah menggunakan graf pengetahuan sebagai kekangan priori untuk mengelakkan "karut" model besar; Sebaliknya, berdasarkan graf pengetahuan, penyelesaian yang boleh ditafsir boleh disediakan untuk penjanaan model yang besar. 🎜🎜
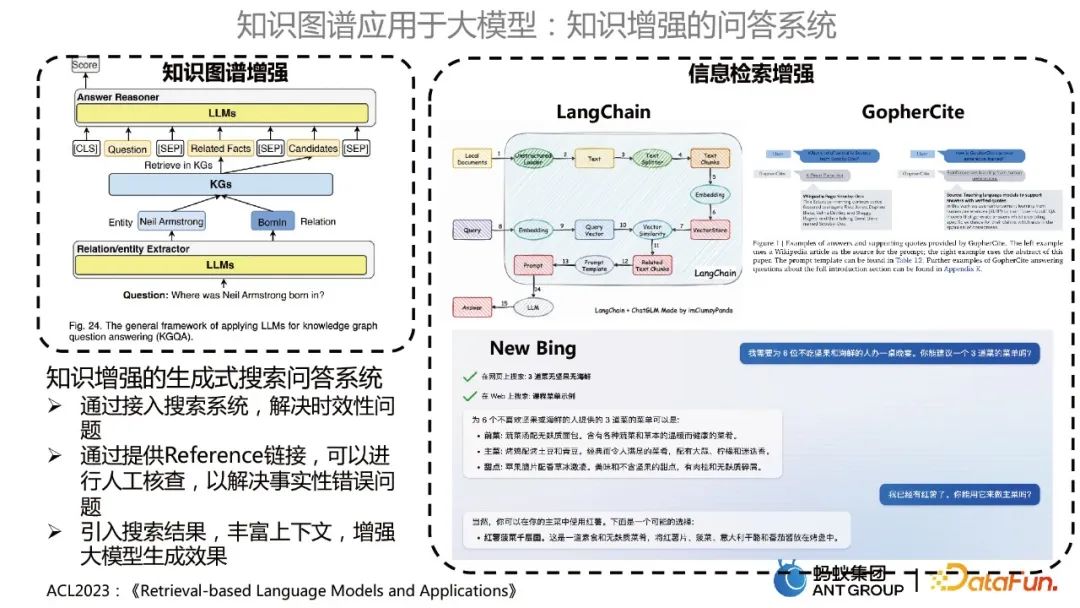
terutamanya merangkumi dua kategori Satu ialah sistem Soal Jawab yang dipertingkatkan graf pengetahuan, yang menggunakan model besar untuk mengoptimumkan model KBQA, yang lain ialah peningkatan perolehan maklumat, serupa dengan LangCiteChain , dan Bing Baharu Gunakan model besar untuk merumus soalan dan jawapan asas pengetahuan.
Sistem soal jawab carian generatif yang dipertingkatkan pengetahuan mempunyai kelebihan berikut:

Cara graf pengetahuan dan model besar boleh berinteraksi dan berfungsi bersama dengan lebih baik, termasuk tiga arah berikut:
Atas ialah kandungan terperinci Jia Qianghuai: Pembinaan dan penggunaan graf pengetahuan berskala besar semut. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah ciri-ciri utama komputer?
Apakah ciri-ciri utama komputer?
 Platform dagangan riak
Platform dagangan riak
 Apakah teknik ujian biasa?
Apakah teknik ujian biasa?
 Cara menggunakan fungsi imfinfo
Cara menggunakan fungsi imfinfo
 Komputer mempunyai internet tetapi pelayar tidak boleh membuka halaman web
Komputer mempunyai internet tetapi pelayar tidak boleh membuka halaman web
 Bagaimana untuk menyediakan pengalihan nama domain
Bagaimana untuk menyediakan pengalihan nama domain
 Platform manakah yang lebih baik untuk perdagangan mata wang maya?
Platform manakah yang lebih baik untuk perdagangan mata wang maya?
 Syiling paling menjanjikan pada tahun 2024
Syiling paling menjanjikan pada tahun 2024








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



