
 Peranti teknologi
AI
Interspeech 2023 |. Penstriman Enjin Gunung Berapi Peningkatan Pertuturan dan Pengekodan Audio AI
Peranti teknologi
AI
Interspeech 2023 |. Penstriman Enjin Gunung Berapi Peningkatan Pertuturan dan Pengekodan Audio AI
Interspeech 2023 |. Penstriman Enjin Gunung Berapi Peningkatan Pertuturan dan Pengekodan Audio AI


Pengenalan latar belakang
Untuk menangani pelbagai senario komunikasi audio dan video yang kompleks, seperti berbilang peranti, berbilang orang dan berbilang bunyi senario, media penstriman Teknologi komunikasi secara beransur-ansur menjadi teknologi yang amat diperlukan dalam kehidupan manusia. Untuk mencapai pengalaman subjektif yang lebih baik dan membolehkan pengguna mendengar dengan jelas dan benar, penyelesaian teknologi audio penstriman menggabungkan pembelajaran mesin tradisional dan penyelesaian peningkatan suara berasaskan AI, menggunakan penyelesaian teknologi rangkaian saraf dalam untuk mencapai pengurangan hingar suara dan pembatalan gema , mengganggu penghapusan suara dan pengekodan dan penyahkodan audio, dsb., untuk melindungi kualiti audio dalam komunikasi masa nyata.
Sebagai persidangan antarabangsa utama dalam bidang penyelidikan pemprosesan isyarat pertuturan, Interspeech sentiasa mewakili hala tuju penyelidikan yang paling canggih dalam bidang akustik 2023 telah memasukkan beberapa artikel yang berkaitan dengan audio algoritma peningkatan pertuturan isyarat, antaranya, Sebanyak 4 kertas penyelidikan daripada Pasukan Audio Penstriman Enjin Volcano telah diterima oleh persidangan itu, termasuk peningkatan pertuturan, pengekodan dan penyahkodan berasaskan AI # 🎜🎜#, pembatalan gema dan peningkatan pertuturan adaptif terkawal tanpa wayar .
Perlu dinyatakan bahawa dalam bidang peningkatan pertuturan adaptif tanpa pengawasan, pasukan bersama ByteDance dan NPU melakukan penyesuaian domain tanpa pengawasan pada subtugas cabaran CHiME (Computational Hearing in Multisource Environments) tahun ini penyesuaian domain untuk peningkatan pertuturan perbualan (UDASE) memenangi kejuaraan (https://www.chimechallenge.org/current/task2/results). Cabaran CHiME ialah pertandingan antarabangsa penting yang dilancarkan pada 2011 oleh institusi penyelidikan terkenal seperti Institut Sains Komputer dan Automasi Perancis, Universiti Sheffield di UK, dan Makmal Penyelidikan Elektronik Mitsubishi di Amerika Syarikat masalah jauh yang mencabar dalam bidang penyelidikan pertuturan pada tahun ini, ia telah diadakan untuk kali ketujuh. Pasukan yang mengambil bahagian dalam pertandingan CHiME sebelum ini termasuk Universiti Cambridge di United Kingdom, Universiti Carnegie Mellon di Amerika Syarikat, Universiti Johns Hopkins, NTT di Jepun, Hitachi Academia Sinica dan universiti dan institusi penyelidikan terkenal antarabangsa yang lain, serta Universiti Tsinghua, Akademi Sains Universiti China, Institut Akustik Akademi Sains China, NPU, iFlytek dan universiti dan institut penyelidikan tempatan terkemuka yang lain. Artikel ini akan memperkenalkan masalah senario teras dan penyelesaian teknikal yang diselesaikan oleh empat kertas iniKongsi kemajuan pasukan audio penstriman Volcano Engine dalam peningkatan pertuturan, pembatalan gema berasaskan pengekod AI dan auto tanpa pengawasan. -automasi Menyesuaikan diri dengan pemikiran dan amalan dalam bidang peningkatan pertuturan.
Kaedah peningkatan harmonik pertuturan ringan berdasarkan penapis sikat yang boleh dipelajariAlamat kertas: https://www.isca-speech.org /archive/interspeech_2023/le23ch_interspeech .htmlLatar BelakangTerhad oleh kelewatan dan sumber pengkomputeran, peningkatan pertuturan dalam senario komunikasi audio dan video masa nyata biasanya menggunakan ciri input penapis. Melalui bank penapis seperti Mel dan ERB, spektrum asal dimampatkan ke dalam sub-jalur dimensi lebih rendah. Dalam domain subband, output model peningkatan pertuturan berasaskan pembelajaran mendalam ialah perolehan pertuturan subband, yang mewakili perkadaran tenaga pertuturan sasaran. Walau bagaimanapun, audio yang dipertingkatkan pada domain sub-jalur termampat adalah kabur kerana kehilangan butiran spektrum, selalunya memerlukan pemprosesan pasca untuk meningkatkan harmonik. RNNoise dan PercepNet menggunakan penapis sikat untuk meningkatkan harmonik, tetapi disebabkan anggaran frekuensi asas dan pengiraan keuntungan penapis sikat dan penyahgandingan model, ia tidak boleh dioptimumkan dari hujung ke hujung DeepFilterNet menggunakan penapis domain frekuensi masa untuk menyekat hingar antara harmoni , tetapi tidak menggunakan maklumat frekuensi asas pertuturan secara eksplisit. Sebagai tindak balas kepada masalah di atas, pasukan mencadangkan kaedah peningkatan harmonik pertuturan berdasarkan penapis sikat yang boleh dipelajari Kaedah ini menggabungkan anggaran kekerapan asas dan penapisan sikat, dan keuntungan penapis sikat boleh dioptimumkan dari hujung ke hujung. Eksperimen menunjukkan bahawa kaedah ini boleh mencapai peningkatan harmonik yang lebih baik dengan jumlah pengiraan yang sama seperti kaedah sedia ada. Struktur rangka kerja modelPenganggar frekuensi asas (Penganggar F0)Untuk mengurangkan kesukaran anggaran frekuensi asas dan menjadikan keseluruhan pautan tamat -to-end Run, diskritkan julat frekuensi asas sasaran untuk dianggarkan kepada N frekuensi asas diskret, dan gunakan pengelas untuk menganggar. 1 dimensi ditambah untuk mewakili bingkai bukan bersuara, dan output model akhir ialah kebarangkalian dimensi N+1. Selaras dengan CREPE, pasukan menggunakan ciri lancar Gaussian sebagai sasaran latihan dan Binary Cross Entropy sebagai fungsi kehilangan: #Penapis Sikat Boleh Dipelajari
Untuk setiap frekuensi asas diskret di atas, pasukan menggunakan penapis FIR yang serupa dengan PercepNet untuk penapisan sikat, yang boleh dinyatakan sebagai kereta nadi termodulat: 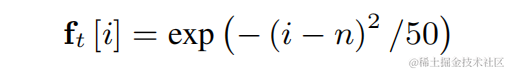
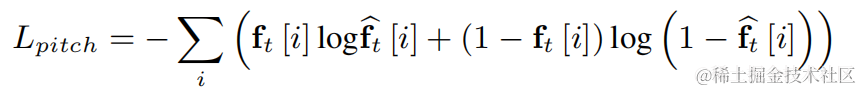
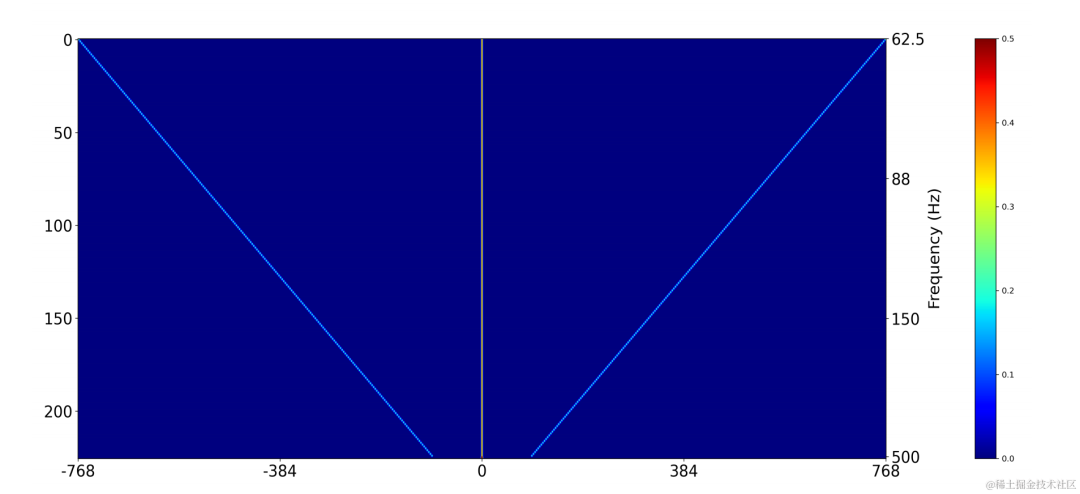
Gunakan lapisan lilitan dua dimensi (Conv2D) untuk mengira secara serentak hasil penapisan semua frekuensi asas diskret semasa latihan Berat lilitan dua dimensi boleh dinyatakan sebagai matriks dalam rajah di bawah dimensi, dan setiap dimensi digunakan Permulaan penapis di atas:
Darab label panas satu frekuensi asas sasaran dan output lilitan dua dimensi untuk mendapatkan hasil penapisan yang sepadan dengan frekuensi asas setiap bingkai :

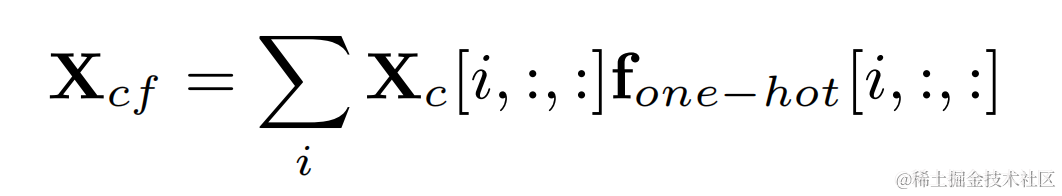
Audio selepas peningkatan harmonik Tambahkan berat audio asal dan darabkannya dengan keuntungan sub-jalur untuk mendapatkan output akhir:
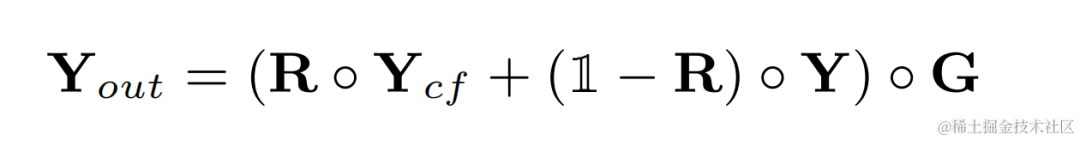
Semasa inferens, setiap bingkai hanya perlu mengira hasil penapisan satu kekerapan asas, jadi kos pengiraan kaedah ini adalah rendah.
Struktur model
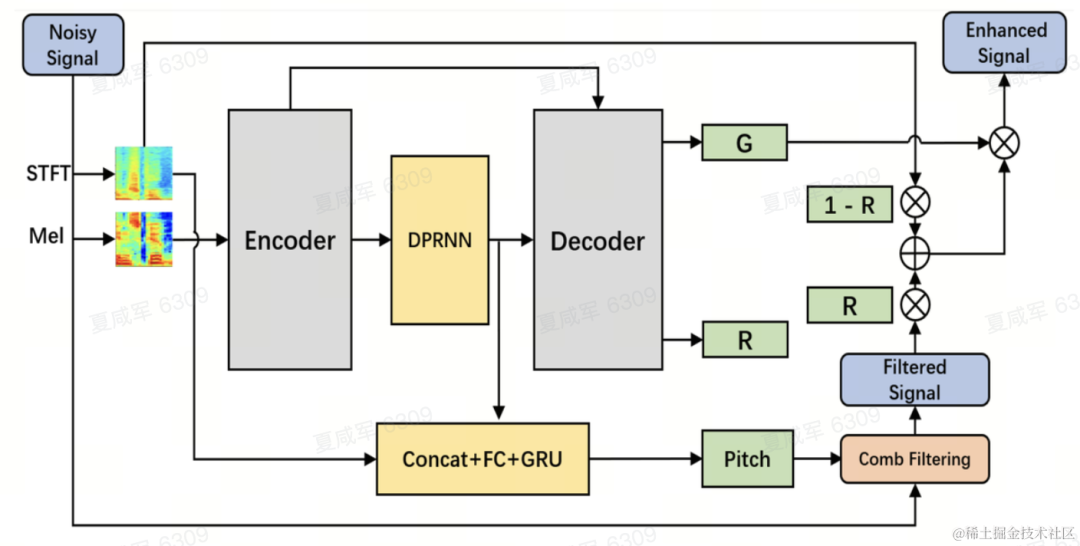
Pasukan menggunakan Dual-Path Convolutional Recurrent Network (DPCRN) sebagai tulang belakang model peningkatan pertuturan dan menambah penganggar frekuensi asas. Pengekod dan Penyahkod menggunakan lilitan boleh dipisahkan dalam untuk membentuk struktur simetri Penyahkod mempunyai dua cabang selari yang masing-masing mengeluarkan gain sub-jalur G dan pekali pemberat R. Input kepada penganggar frekuensi asas ialah keluaran modul DPRNN dan spektrum linear. Jumlah pengiraan model ini ialah kira-kira 300 M MAC, yang mana jumlah pengiraan penapisan sikat adalah kira-kira 0.53M MAC.
Latihan model
Dalam percubaan, set data cabaran VCTK-DEMAND dan DNS4 digunakan untuk latihan, dan kehilangan fungsi peningkatan pertuturan dan anggaran kekerapan asas digunakan untuk pembelajaran berbilang tugas.
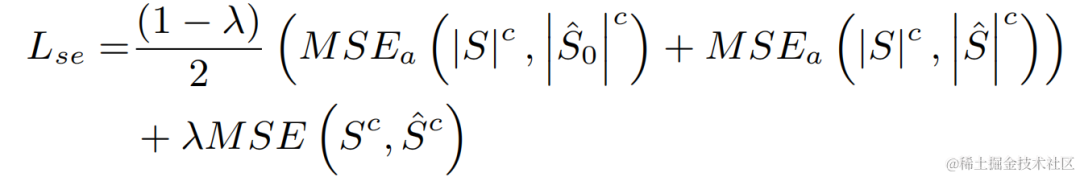
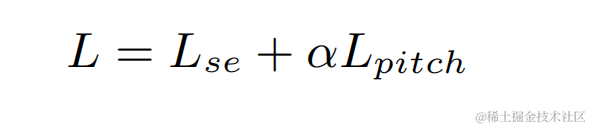
Hasil eksperimen
Pasukan audio penstriman membandingkan model penapis sikat yang boleh dipelajari dengan model yang menggunakan penapis sikat PercepNet dan algoritma penapis DeepFilterNet, masing-masing dipanggil DPCRN-CF dan DPCRN. Pada set ujian VCTK, kaedah yang dicadangkan dalam artikel ini menunjukkan kelebihan berbanding kaedah sedia ada.
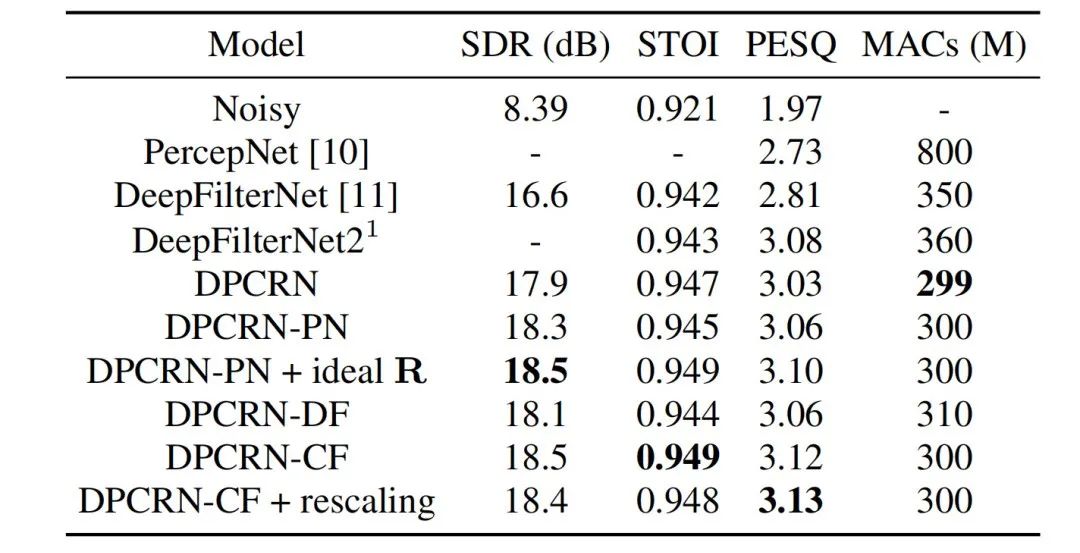
Pada masa yang sama, pasukan menjalankan eksperimen ablasi mengenai anggaran kekerapan asas dan penapis yang boleh dipelajari. Keputusan eksperimen menunjukkan bahawa pembelajaran hujung ke hujung menghasilkan keputusan yang lebih baik daripada menggunakan algoritma penganggaran frekuensi asas berasaskan pemprosesan isyarat dan pemberat penapis.
Pengekod audio rangkaian neural hujung ke hujung berdasarkan Intra-BRNN dan GB-RVQ
Alamat kertas: https://www.isca-speech.org/archive/pdfs/interspeech_2023/xu23_inters
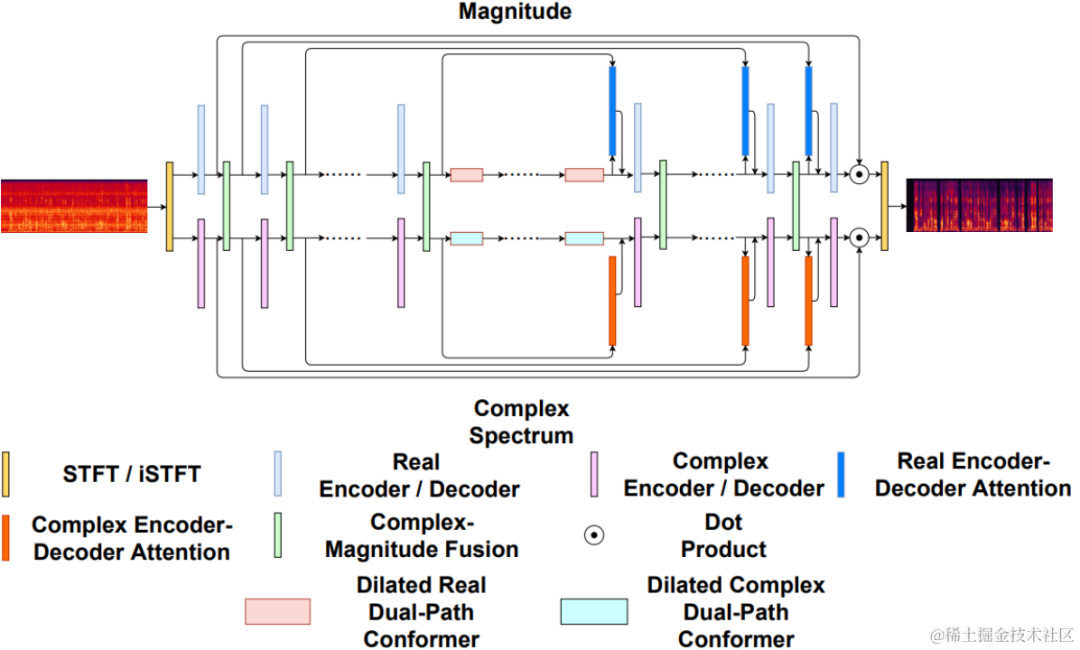
Latar BelakangDalam beberapa tahun kebelakangan ini, banyak model rangkaian saraf telah digunakan untuk tugas pengekodan pertuturan kadar bit rendah Walau bagaimanapun, sesetengah model hujung ke hujung gagal menggunakan sepenuhnya maklumat berkaitan dalam bingkai, dan pengkuantiti yang diperkenalkan mempunyai besar. ralat pengkuantitian, mengakibatkan kualiti audio pasca pengekodan. Untuk meningkatkan kualiti pengekod audio rangkaian saraf hujung ke hujung, pasukan audio penstriman mencadangkan codec pertuturan saraf hujung ke hujung, iaitu CBRC (Convolutional and Bidirectional Recurrent neural Codec). CBRC menggunakan struktur berjalin 1D-CNN (konvolusi satu dimensi) dan Intra-BRNN (rangkaian saraf berulang dwiarah dalam bingkai) untuk menggunakan korelasi intra bingkai dengan lebih berkesan. Di samping itu, pasukan menggunakan Kuantiti Vektor Baki Kumpulan dan Carian Pancaran (GB-RVQ) dalam CBRC untuk mengurangkan hingar pengkuantitian. CBRC mengekod audio 16kHz dengan panjang bingkai 20ms, tanpa kelewatan sistem tambahan, dan sesuai untuk senario komunikasi masa nyata. Keputusan eksperimen menunjukkan bahawa kualiti suara pengekodan CBRC dengan kadar bit 3kbps adalah lebih baik daripada Opus dengan 12kbps. Struktur bingkai model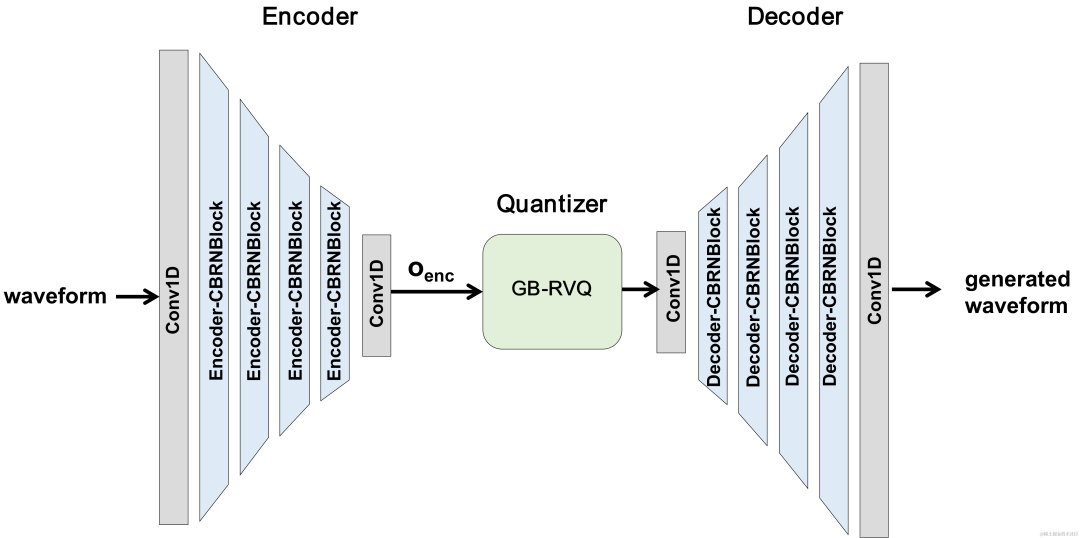
Struktur keseluruhan CBRC
Encoder dan Dekoder struktur rangkaian
Encoder menggunakan 4 CBRNBlocks berlatarkan untuk mengekstrak ciri audio Setiap CBRNBlock terdiri daripada tiga Residual Unit yang mengekstrak ciri dan konvolusi satu dimensi yang mengawal kadar pensampelan. Setiap kali ciri dalam Pengekod diturunkan sampel, bilangan saluran ciri digandakan. ResidualUnit terdiri daripada modul konvolusi sisa dan rangkaian berulang dwiarah baki, di mana lapisan konvolusi menggunakan konvolusi sebab, manakala struktur GRU dwiarah dalam Intra-BRNN hanya memproses ciri audio dalam bingkai 20ms. Rangkaian Penyahkod ialah struktur cermin Pengekod, menggunakan lilitan transpos satu dimensi untuk pensampelan naik. Struktur berjalin 1D-CNN dan Intra-BRNN membolehkan Pengekod dan Penyahkod menggunakan sepenuhnya korelasi intra-bingkai audio 20ms tanpa memperkenalkan kelewatan tambahan.
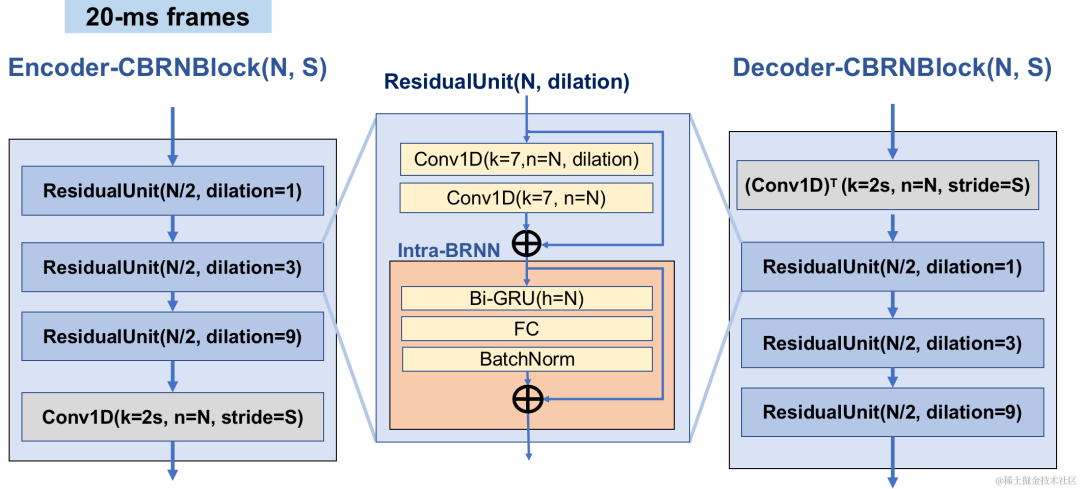
CBRNBlock structure
Kumpulan dan #Quntizer carian sisa GB-R Vektor 🎜#
CBRC menggunakan Residual Vector Quantizer (RVQ) untuk mengukur dan memampatkan ciri keluaran rangkaian pengekodan kepada kadar bit yang ditentukan. RVQ menggunakan lata pengkuantiti vektor berbilang lapisan (VQ) untuk memampatkan ciri Setiap lapisan VQ mengkuantiskan baki pengkuantitian lapisan sebelumnya VQ, yang boleh mengurangkan dengan ketara jumlah parameter buku kod bagi satu lapisan VQ pada masa yang sama. kadar bit. Pasukan itu mencadangkan dua struktur pengkuantiti yang lebih baik dalam CBRC, iaitu RVQ mengikut kumpulan dan pengkuantiti vektor sisa carian pancaran (RVQ carian pancaran). Kuantiti Vektor Baki Kumpulan RVQ mengikut kumpulan| #🎜## 🎜🎜# |
RVQ mengikut kumpulan mengelompokkan output Pengekod, dan menggunakan RVQ terkumpul untuk mengkuantumkan ciri terkumpul secara bebas, dan kemudian keluaran terkuantisasi terkumpul disambungkan ke dalam Dekoder input. RVQ mengikut kumpulan menggunakan pengkuantitian kumpulan untuk mengurangkan parameter buku kod dan kerumitan pengiraan pengkuantiti, di samping mengurangkan kesukaran latihan CBRC hujung ke hujung dan dengan itu meningkatkan kualiti audio yang dikodkan CBRC. Pasukan ini memperkenalkan RVQ carian Beam ke dalam latihan hujung ke hujung pengekod audio saraf, dan menggunakan algoritma carian Beam untuk memilih gabungan buku kod dengan ralat laluan kuantisasi terkecil dalam RVQ untuk mengurangkan ralat pengkuantitian pengkuantiti . Algoritma RVQ asal memilih buku kod dengan ralat terkecil dalam setiap lapisan pengkuantitian VQ sebagai output, tetapi gabungan buku kod optimum untuk setiap lapisan pengkuantitian VQ mungkin tidak semestinya gabungan buku kod yang optimum secara global. Pasukan ini menggunakan RVQ carian Beam untuk mengekalkan k laluan pengkuantitian optimum dalam setiap lapisan VQ berdasarkan kriteria ralat laluan pengkuantitian minimum, membolehkan pemilihan gabungan buku kod yang lebih baik dalam ruang carian pengkuantitian yang lebih besar dan mengurangkan ralat pengkuantitian.
|

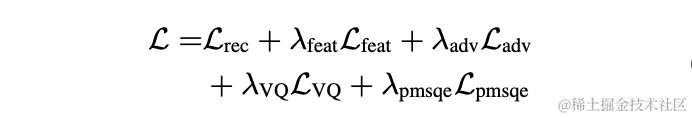
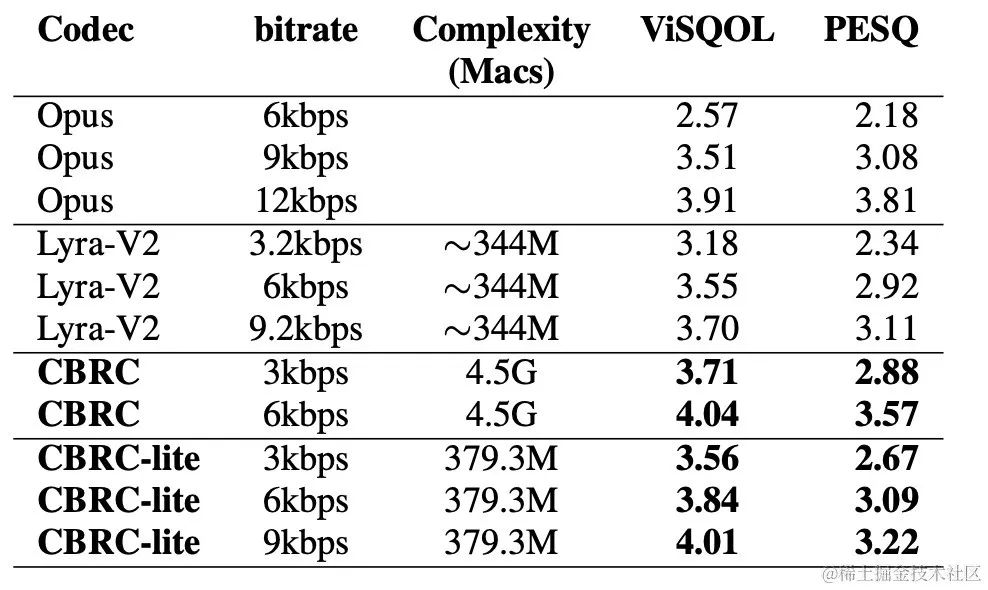


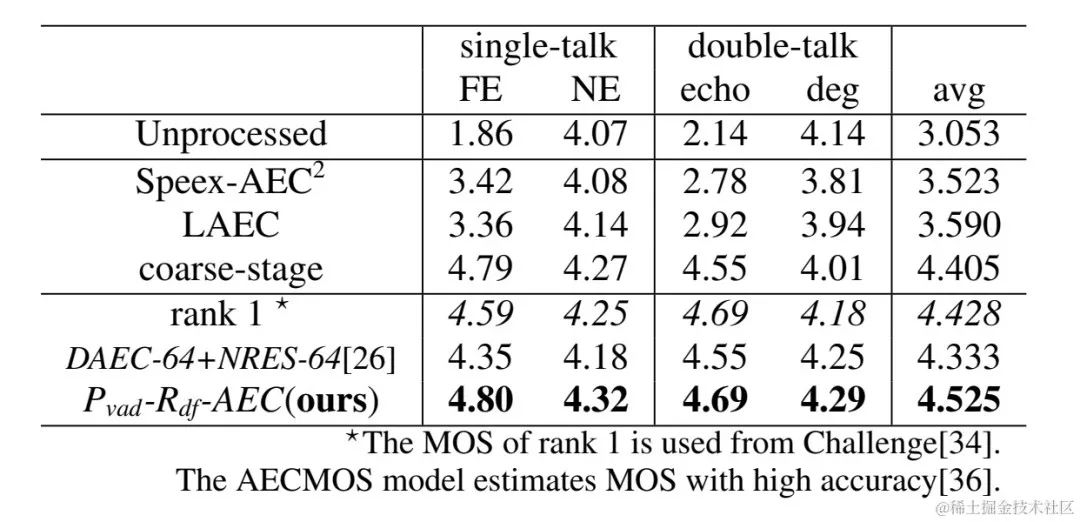 Hasil eksperimental GitHub Pautan: https://github.com/enhancer12/tspnnnndual Speaking Scene Prestasi:
Hasil eksperimental GitHub Pautan: https://github.com/enhancer12/tspnnnndual Speaking Scene Prestasi: 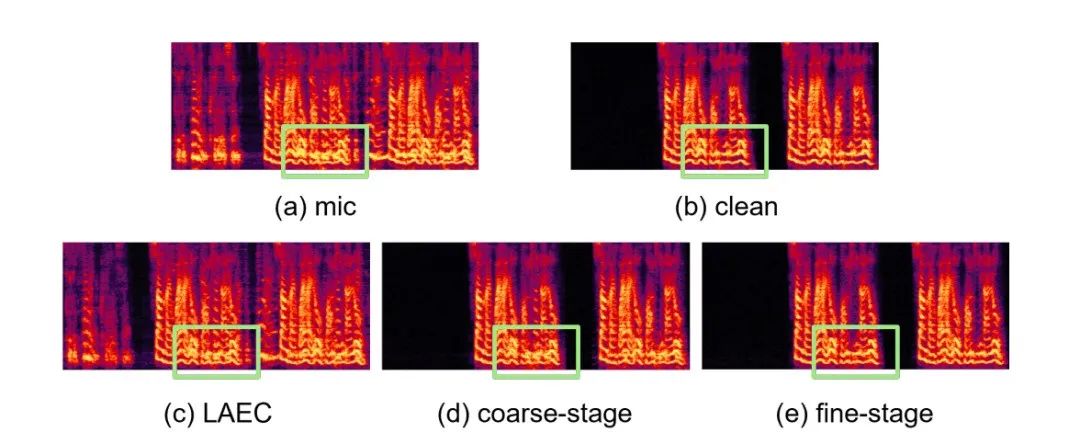
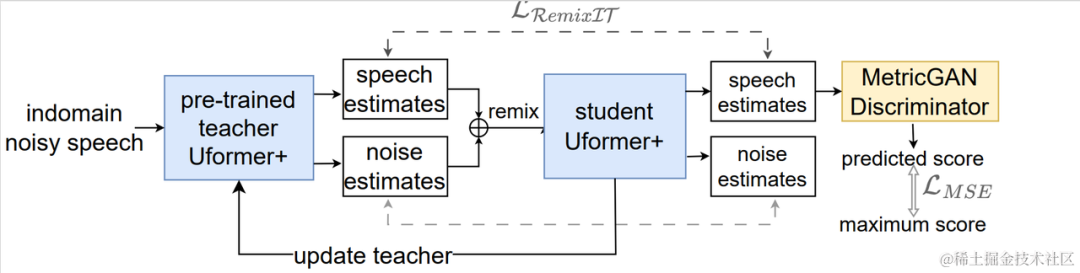
 Selepas semua data latihan melengkapkan satu lelaran, parameter rangkaian guru dikemas kini mengikut formula berikut:, di manakah parameter pusingan K- latihan rangkaian guru,
Selepas semua data latihan melengkapkan satu lelaran, parameter rangkaian guru dikemas kini mengikut formula berikut:, di manakah parameter pusingan K- latihan rangkaian guru, 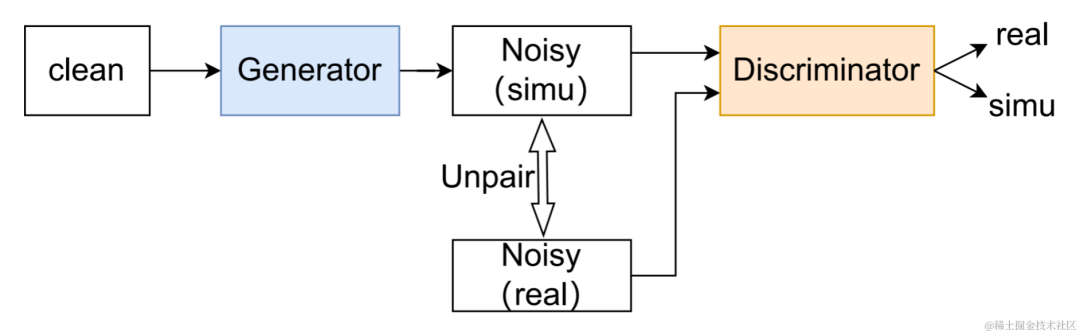 Hasil eksperimen
Hasil eksperimenAtas ialah kandungan terperinci Interspeech 2023 |. Penstriman Enjin Gunung Berapi Peningkatan Pertuturan dan Pengekodan Audio AI. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Pengekodan Vibe membentuk semula dunia pembangunan perisian dengan membiarkan kami membuat aplikasi menggunakan bahasa semulajadi dan bukannya kod yang tidak berkesudahan. Diilhamkan oleh penglihatan seperti Andrej Karpathy, pendekatan inovatif ini membolehkan Dev
 Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Februari 2025 telah menjadi satu lagi bulan yang berubah-ubah untuk AI generatif, membawa kita beberapa peningkatan model yang paling dinanti-nantikan dan ciri-ciri baru yang hebat. Dari Xai's Grok 3 dan Anthropic's Claude 3.7 Sonnet, ke Openai's G
 Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Yolo (anda hanya melihat sekali) telah menjadi kerangka pengesanan objek masa nyata yang terkemuka, dengan setiap lelaran bertambah baik pada versi sebelumnya. Versi terbaru Yolo V12 memperkenalkan kemajuan yang meningkatkan ketepatan
 Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4 kini tersedia dan digunakan secara meluas, menunjukkan penambahbaikan yang ketara dalam memahami konteks dan menjana tindak balas yang koheren berbanding dengan pendahulunya seperti ChATGPT 3.5. Perkembangan masa depan mungkin merangkumi lebih banyak Inter yang diperibadikan
 Google ' s Gencast: Peramalan Cuaca dengan Demo Mini Gencast
Mar 16, 2025 pm 01:46 PM
Google ' s Gencast: Peramalan Cuaca dengan Demo Mini Gencast
Mar 16, 2025 pm 01:46 PM
Google Deepmind's Gencast: AI Revolusioner untuk Peramalan Cuaca Peramalan cuaca telah menjalani transformasi dramatik, bergerak dari pemerhatian asas kepada ramalan berkuasa AI yang canggih. Google Deepmind's Gencast, tanah air
 AI mana yang lebih baik daripada chatgpt?
Mar 18, 2025 pm 06:05 PM
AI mana yang lebih baik daripada chatgpt?
Mar 18, 2025 pm 06:05 PM
Artikel ini membincangkan model AI yang melampaui chatgpt, seperti Lamda, Llama, dan Grok, menonjolkan kelebihan mereka dalam ketepatan, pemahaman, dan kesan industri. (159 aksara)
 O1 vs GPT-4O: Adakah model baru OpenAI ' lebih baik daripada GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 vs GPT-4O: Adakah model baru OpenAI ' lebih baik daripada GPT-4O?
Mar 16, 2025 am 11:47 AM
Openai's O1: Hadiah 12 Hari Bermula dengan model mereka yang paling berkuasa Ketibaan Disember membawa kelembapan global, kepingan salji di beberapa bahagian dunia, tetapi Openai baru sahaja bermula. Sam Altman dan pasukannya melancarkan mantan hadiah 12 hari
 Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Artikel ini mengkaji semula penjana seni AI atas, membincangkan ciri -ciri mereka, kesesuaian untuk projek kreatif, dan nilai. Ia menyerlahkan Midjourney sebagai nilai terbaik untuk profesional dan mengesyorkan Dall-E 2 untuk seni berkualiti tinggi dan disesuaikan.
