
 Peranti teknologi
AI
Latih model profesional kecil dengan pantas: Hanya 1 arahan, $5 dan 20 minit, cuba Prompt2Model!
Peranti teknologi
AI
Latih model profesional kecil dengan pantas: Hanya 1 arahan, $5 dan 20 minit, cuba Prompt2Model!
Latih model profesional kecil dengan pantas: Hanya 1 arahan, $5 dan 20 minit, cuba Prompt2Model!

Model Bahasa Berskala Besar (LLM) membolehkan pengguna membina sistem pemprosesan bahasa semula jadi yang berkuasa melalui pembayang dan pembelajaran kontekstual. Walau bagaimanapun, dari perspektif lain, LLM menunjukkan regresi tertentu dalam beberapa tugas pemprosesan bahasa semula jadi yang khusus: penggunaan model ini memerlukan banyak sumber pengkomputeran dan berinteraksi dengan model melalui API mungkin menimbulkan isu privasi yang berpotensi
menangani masalah ini, penyelidik dari Carnegie Mellon University (CMU) dan Universiti Tsinghua bersama-sama melancarkan rangka kerja Prompt2Model. Matlamat rangka kerja ini adalah untuk menggabungkan penjanaan data berasaskan LLM dan kaedah mendapatkan semula untuk mengatasi cabaran di atas. Menggunakan rangka kerja Prompt2Model, pengguna hanya perlu memberikan gesaan yang sama seperti LLM untuk mengumpul data secara automatik dan cekap melatih model khusus kecil yang sesuai untuk tugasan tertentu
Para penyelidik menjalankan eksperimen ke atas tiga tugasan subsistem pemprosesan bahasa semula jadi telah dikaji. Mereka menggunakan sebilangan kecil gesaan sampel sebagai input dan membelanjakan hanya $5 untuk mengumpul data dan 20 minit latihan. Prestasi model yang dijana melalui rangka kerja Prompt2Model adalah 20% lebih tinggi daripada model LLM berkuasa gpt-3.5-turbo. Pada masa yang sama, saiz model dikurangkan dengan faktor 700. Para penyelidik selanjutnya mengesahkan kesan data ini pada prestasi model dalam senario kehidupan sebenar, membolehkan pembangun model menganggarkan kebolehpercayaan model sebelum penggunaan. Rangka kerja telah disediakan dalam bentuk sumber terbuka:

- Alamat repositori GitHub rangka kerja: https://github.com/neulab/prompt2model pautan video demonstrasi anda
- be/LYYQ_EhGd -Q
- Pautan kertas berkaitan rangka kerja: https://arxiv.org/abs/2308.12261
Latar belakang
untuk pemprosesan sistem yang biasanya agak rumit. Pembina sistem perlu mentakrifkan dengan jelas skop tugas, mendapatkan set data khusus, memilih seni bina model yang sesuai, melatih dan menilai model, dan kemudian menggunakan ia untuk aplikasi praktikal
Model Bahasa Skala Besar ( LLM) seperti GPT-3 menyediakan penyelesaian yang lebih mudah untuk proses ini. Pengguna hanya perlu menyediakan arahan tugasan dan beberapa contoh, dan LLM boleh menjana output teks yang sepadan. Walau bagaimanapun, menjana teks daripada pembayang boleh menjadi intensif dari segi pengiraan, dan menggunakan pembayang adalah kurang stabil daripada model yang dilatih khas. Selain itu, kebolehgunaan LLM juga dihadkan oleh kos, kelajuan dan privasi Untuk menyelesaikan masalah ini, penyelidik membangunkan rangka kerja Prompt2Model. Rangka kerja ini menggabungkan penjanaan data berasaskan LLM dan teknik mendapatkan semula untuk mengatasi batasan di atas. Sistem mula-mula mengekstrak maklumat penting daripada maklumat segera, kemudian menjana dan mendapatkan semula data latihan, dan akhirnya menjana model khusus yang sedia untuk digunakan
Rangka kerja Prompt2Model secara automatik melaksanakan langkah teras berikut: 1. Prapemprosesan data: Bersihkan dan piawaikan data input untuk memastikan ia sesuai untuk latihan model. 2. Pemilihan model: Pilih seni bina model dan parameter yang sesuai mengikut keperluan tugasan. 3. Latihan model: Gunakan data praproses untuk melatih model yang dipilih untuk mengoptimumkan prestasi model. 4. Penilaian model: Penilaian prestasi model terlatih melalui penunjuk penilaian untuk menentukan prestasinya pada tugas tertentu. 5. Penalaan model: Berdasarkan keputusan penilaian, tala model untuk meningkatkan lagi prestasinya. 6. Penetapan model: Gunakan model terlatih ke persekitaran aplikasi sebenar untuk mencapai fungsi ramalan atau inferens. Dengan mengautomasikan langkah teras ini, rangka kerja Prompt2Model boleh membantu pengguna membina dan menggunakan model pemprosesan bahasa semula jadi berprestasi tinggi dengan pantas
Set data dan perolehan model: Kumpul set data yang berkaitan dan model pra-latihan.
- Penjanaan set data: Gunakan LLM untuk mencipta set data berlabel pseudo.
- Penalaan halus model: Perhalusi model dengan mencampurkan data yang diambil dan data yang dijana.
- Pengujian Model: Uji model pada set data ujian dan set data sebenar yang disediakan oleh pengguna.
- Melalui penilaian empirikal ke atas pelbagai tugasan yang berbeza, kami mendapati bahawa kos Prompt2Model berkurangan dengan ketara dan saiz model juga berkurangan dengan ketara, tetapi prestasinya melebihi gpt-3.5-turbo. Rangka kerja Prompt2Model bukan sahaja boleh digunakan sebagai alat untuk membina sistem pemprosesan bahasa semula jadi dengan cekap, tetapi juga sebagai platform untuk meneroka teknologi latihan integrasi model
Framework
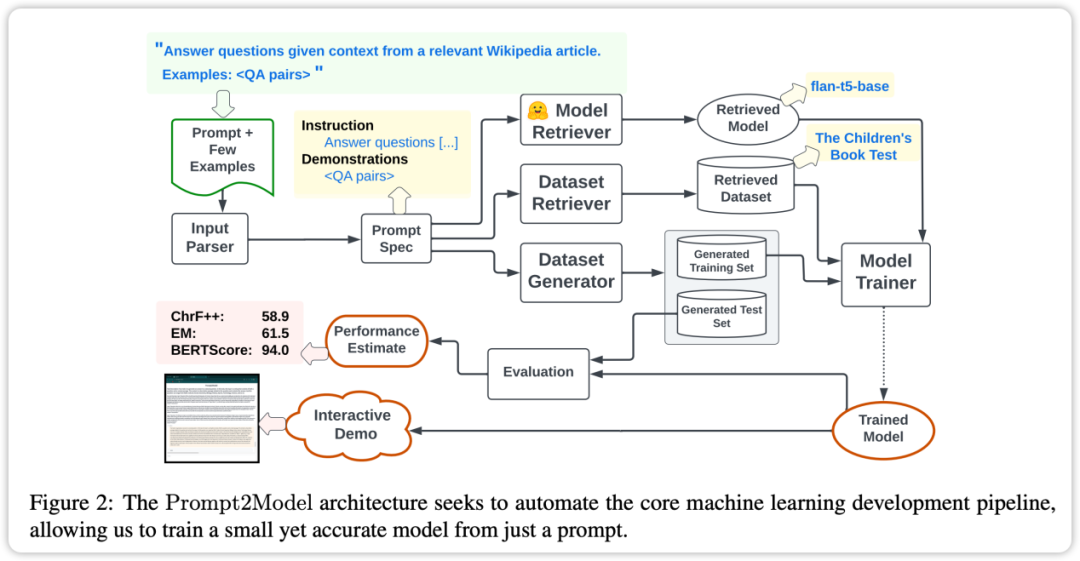
Ciri teras rangka kerja Prompt2Model ialah tahap automasi yang tinggi. Prosesnya termasuk pengumpulan data, latihan model, penilaian dan penggunaan, seperti yang ditunjukkan dalam rajah di atas. Antaranya, sistem pengumpulan data automatik memainkan peranan utama dengan mendapatkan data yang berkait rapat dengan keperluan pengguna melalui pengambilan set data dan penjanaan data berasaskan LLM. Seterusnya, model pra-latihan diambil dan diperhalusi pada set data yang diperoleh. Akhir sekali, model terlatih dinilai pada set ujian dan antara muka pengguna web (UI) dicipta untuk berinteraksi dengan model
Prompt2Model Ciri utama rangka kerja termasuk:
- Pemandu segera: Prompt2Model Idea teras ialah menggunakan gesaan sebagai pemacu, pengguna boleh menerangkan secara langsung tugasan yang diperlukan tanpa pergi ke butiran pelaksanaan khusus pembelajaran mesin.
- Pengumpulan data automatik: Rangka kerja menggunakan pengambilan set data dan teknologi penjanaan untuk mendapatkan data yang sangat sepadan dengan tugas pengguna, dengan itu mewujudkan set data yang diperlukan untuk latihan.
- Model pra-latihan: Rangka kerja menggunakan model pra-latihan dan memperhalusinya, dengan itu menjimatkan banyak kos latihan dan masa.
- Penilaian kesan: Prompt2Model menyokong ujian dan penilaian model pada set data sebenar, membolehkan ramalan awal dan penilaian prestasi dibuat sebelum menggunakan model, sekali gus meningkatkan kebolehpercayaan model.
Rangka kerja Prompt2Model mempunyai ciri-ciri berikut, menjadikannya alat berkuasa yang boleh melengkapkan proses pembinaan sistem pemprosesan bahasa semula jadi dengan cekap, dan menyediakan fungsi lanjutan, seperti pengumpulan data automatik, penilaian model dan antara muka interaksi pengguna Cipta .
NL-to-Code Jepun: Menggunakan MCoNaLa sebagai set data penilaian sebenar.
Penormalan Ungkapan Temporal: Gunakan set data Temporal sebagai set data penilaian sebenar.
- Selain itu, penyelidik juga menggunakan GPT-3.5-turbo sebagai model asas untuk perbandingan. Keputusan eksperimen membawa kepada kesimpulan berikut:
- Dalam semua tugas kecuali tugas penjanaan kod, model yang dijana oleh sistem Prompt2Model adalah jauh lebih baik daripada model penanda aras GPT-3.5-turbo, walaupun skala parameter model yang dihasilkan adalah jauh lebih kecil daripada GPT-3.5-turbo.
- Dengan mencampurkan set data perolehan dengan set data yang dijana untuk latihan, anda boleh mencapai hasil yang setanding dengan yang menggunakan latihan set data sebenar secara langsung. Ini mengesahkan bahawa rangka kerja Prompt2Model boleh mengurangkan kos anotasi manual.
Set data ujian yang dijana oleh penjana data dengan berkesan boleh membezakan prestasi model berbeza pada set data sebenar. Ini menunjukkan bahawa data yang dihasilkan adalah berkualiti tinggi dan mempunyai keberkesanan yang mencukupi dalam latihan model.
- Dalam tugas penukaran Jepun kepada kod, sistem Prompt2Model berprestasi lebih teruk daripada GPT-3.5-turbo.
- Ia mungkin disebabkan oleh kualiti rendah set data yang dijana dan kekurangan model pra-latihan yang sesuai
- Ringkasnya, sistem Prompt2Model berjaya menghasilkan model kecil berkualiti tinggi pada pelbagai tugas, sangat mengurangkan keperluan untuk anotasi manual data. Walau bagaimanapun, penambahbaikan lanjut masih diperlukan pada beberapa tugasan
Ringkasan
Rangka kerja Prompt2Model ialah teknologi inovatif yang dibangunkan oleh pasukan penyelidik melalui model gesaan bahasa semulajadi secara automatik Pengenalan teknologi ini sangat mengurangkan kesukaran membina model pemprosesan bahasa semula jadi yang disesuaikan dan mengembangkan lagi skop aplikasi teknologi NLP
Hasil percubaan pengesahan menunjukkan bahawa saiz model yang dijana oleh rangka kerja Prompt2Model dikurangkan dengan ketara berbanding model bahasa yang lebih besar, dan ia berprestasi lebih baik daripada GPT-3.5-turbo dan model lain pada pelbagai tugas. Pada masa yang sama, set data penilaian yang dihasilkan oleh rangka kerja ini juga telah terbukti berkesan dalam menilai prestasi model yang berbeza pada set data sebenar. Ini memberikan nilai penting dalam membimbing penggunaan terakhir model
Rangka kerja Prompt2Model menyediakan industri dan pelbagai pengguna dengan kos rendah, cara yang mudah digunakan untuk mendapatkan model NLP yang memenuhi keperluan khusus. Ini amat penting dalam mempromosikan aplikasi meluas teknologi NLP. Kerja masa depan akan terus didedikasikan untuk mengoptimumkan lagi prestasi rangka kerja
Mengikut susunan artikel, pengarang artikel ini adalah seperti berikut: Kandungan yang ditulis semula: Mengikut susunan artikel, pengarang artikel ini adalah seperti berikut:
Vijay Viswanathan: http://www.cs.cmu.edu/~vijayv/
Zhao Chenyang: https ://zhaochenyang20.github.io/Eren_Chenyang_Zhao/
Amanda Bertsch: https://www.cs.cmu.edu/~abertsch/ Amanda Belch: https://www.cs.cmu.edu/~abertsch/
Wu Tongshuang: https://www.cs.cmu.edu/~sherryw/
Graham · Newbig: http: //www.phontron.com/
Atas ialah kandungan terperinci Latih model profesional kecil dengan pantas: Hanya 1 arahan, $5 dan 20 minit, cuba Prompt2Model!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 phpmyadmin mencipta jadual data
Apr 10, 2025 pm 11:00 PM
phpmyadmin mencipta jadual data
Apr 10, 2025 pm 11:00 PM
Untuk membuat jadual data menggunakan phpmyadmin, langkah -langkah berikut adalah penting: Sambungkan ke pangkalan data dan klik tab baru. Namakan jadual dan pilih enjin penyimpanan (disyorkan innoDB). Tambah butiran lajur dengan mengklik butang Tambah Lajur, termasuk nama lajur, jenis data, sama ada untuk membenarkan nilai null, dan sifat lain. Pilih satu atau lebih lajur sebagai kunci utama. Klik butang Simpan untuk membuat jadual dan lajur.
 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Mewujudkan pangkalan data Oracle tidak mudah, anda perlu memahami mekanisme asas. 1. Anda perlu memahami konsep pangkalan data dan Oracle DBMS; 2. Menguasai konsep teras seperti SID, CDB (pangkalan data kontena), PDB (pangkalan data pluggable); 3. Gunakan SQL*Plus untuk membuat CDB, dan kemudian buat PDB, anda perlu menentukan parameter seperti saiz, bilangan fail data, dan laluan; 4. Aplikasi lanjutan perlu menyesuaikan set aksara, memori dan parameter lain, dan melakukan penalaan prestasi; 5. Beri perhatian kepada ruang cakera, keizinan dan parameter, dan terus memantau dan mengoptimumkan prestasi pangkalan data. Hanya dengan menguasai ia dengan mahir memerlukan amalan yang berterusan, anda boleh benar -benar memahami penciptaan dan pengurusan pangkalan data Oracle.
 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Untuk membuat pangkalan data Oracle, kaedah biasa adalah menggunakan alat grafik DBCA. Langkah -langkah adalah seperti berikut: 1. Gunakan alat DBCA untuk menetapkan DBName untuk menentukan nama pangkalan data; 2. Tetapkan SYSPASSWORD dan SYSTEMPASSWORD kepada kata laluan yang kuat; 3. Tetapkan aksara dan NationalCharacterset ke Al32utf8; 4. Tetapkan MemorySize dan Tablespacesize untuk menyesuaikan mengikut keperluan sebenar; 5. Tentukan laluan logfile. Kaedah lanjutan dibuat secara manual menggunakan arahan SQL, tetapi lebih kompleks dan terdedah kepada kesilapan. Perhatikan kekuatan kata laluan, pemilihan set aksara, saiz dan memori meja makan
 Cara Menulis Penyataan Pangkalan Data Oracle
Apr 11, 2025 pm 02:42 PM
Cara Menulis Penyataan Pangkalan Data Oracle
Apr 11, 2025 pm 02:42 PM
Inti dari pernyataan Oracle SQL adalah pilih, masukkan, mengemas kini dan memadam, serta aplikasi fleksibel dari pelbagai klausa. Adalah penting untuk memahami mekanisme pelaksanaan di sebalik pernyataan, seperti pengoptimuman indeks. Penggunaan lanjutan termasuk subqueries, pertanyaan sambungan, fungsi analisis, dan PL/SQL. Kesilapan umum termasuk kesilapan sintaks, isu prestasi, dan isu konsistensi data. Amalan terbaik pengoptimuman prestasi melibatkan menggunakan indeks yang sesuai, mengelakkan pilih *, mengoptimumkan di mana klausa, dan menggunakan pembolehubah terikat. Menguasai Oracle SQL memerlukan amalan, termasuk penulisan kod, debugging, berfikir dan memahami mekanisme asas.
 Cara Menambah, Ubah Suai dan Padam Panduan Operasi Lapangan Jadual MySQL Data
Apr 11, 2025 pm 05:42 PM
Cara Menambah, Ubah Suai dan Padam Panduan Operasi Lapangan Jadual MySQL Data
Apr 11, 2025 pm 05:42 PM
Panduan Operasi Lapangan di MySQL: Tambah, mengubah suai, dan memadam medan. Tambahkan medan: alter table table_name tambah column_name data_type [not null] [default default_value] [primary kekunci] [AUTO_INCREMENT] Modify Field: Alter Table Table_Name Ubah suai column_name data_type [not null] [default default_value] [Kunci Utama]
 Penjelasan terperinci mengenai contoh pertanyaan bersarang dalam pangkalan data MySQL
Apr 11, 2025 pm 05:48 PM
Penjelasan terperinci mengenai contoh pertanyaan bersarang dalam pangkalan data MySQL
Apr 11, 2025 pm 05:48 PM
Pertanyaan bersarang adalah cara untuk memasukkan pertanyaan lain dalam satu pertanyaan. Mereka digunakan terutamanya untuk mendapatkan data yang memenuhi syarat kompleks, mengaitkan pelbagai jadual, dan mengira nilai ringkasan atau maklumat statistik. Contohnya termasuk mencari pekerja di atas gaji purata, mencari pesanan untuk kategori tertentu, dan mengira jumlah jumlah pesanan bagi setiap produk. Apabila menulis pertanyaan bersarang, anda perlu mengikuti: Tulis subqueries, tulis hasilnya kepada pertanyaan luar (dirujuk dengan alias atau sebagai klausa), dan mengoptimumkan prestasi pertanyaan (menggunakan indeks).
 Apakah kekangan integriti jadual pangkalan data Oracle?
Apr 11, 2025 pm 03:42 PM
Apakah kekangan integriti jadual pangkalan data Oracle?
Apr 11, 2025 pm 03:42 PM
Kekangan integriti pangkalan data Oracle dapat memastikan ketepatan data, termasuk: tidak null: nilai null dilarang; Unik: Keunikan menjamin, membolehkan nilai null tunggal; Kunci utama: kekangan utama utama, menguatkan unik, dan melarang nilai null; Kunci asing: Mengekalkan hubungan antara jadual, kunci asing merujuk kepada kunci utama jadual utama; Semak: Hadkan nilai lajur mengikut syarat.
 Apa yang dilakukan Oracle
Apr 11, 2025 pm 06:06 PM
Apa yang dilakukan Oracle
Apr 11, 2025 pm 06:06 PM
Oracle adalah syarikat perisian Sistem Pengurusan Pangkalan Data (DBMS) terbesar di dunia. Produk utamanya termasuk fungsi berikut: Sistem Pengurusan Pengurusan Pangkalan Data Relasi (Oracle Database) Alat Pembangunan (Oracle Apex, Oracle Visual Builder) Middleware (Oracle Weblogic Server, Oracle SOA Suite) Analisis Awan (Oracle Cloud Infrastructure)
