
 Peranti teknologi
AI
Penalaan halus LLaMA mengurangkan separuh keperluan memori, Tsinghua mencadangkan pengoptimum 4-bit
Peranti teknologi
AI
Penalaan halus LLaMA mengurangkan separuh keperluan memori, Tsinghua mencadangkan pengoptimum 4-bit
Penalaan halus LLaMA mengurangkan separuh keperluan memori, Tsinghua mencadangkan pengoptimum 4-bit

Latihan dan penalaan halus model besar mempunyai keperluan tinggi pada memori video, dan keadaan pengoptimuman ialah salah satu perbelanjaan utama memori video. Baru-baru ini, pasukan Zhu Jun dan Chen Jianfei dari Universiti Tsinghua mencadangkan pengoptimum 4-bit untuk latihan rangkaian saraf, yang menjimatkan overhed memori latihan model dan boleh mencapai ketepatan yang setanding dengan pengoptimum ketepatan penuh.
Pengoptimum 4-bit telah diuji pada pelbagai tugas pra-latihan dan penalaan halus, dan boleh mengurangkan overhed memori penalaan halus LLaMA-7B sambil mengekalkan ketepatan tanpa kehilangan sebanyak 57%.
Kertas: https://arxiv.org/abs/2309.01507
#🎜🎜 /arxiv.org/abs/2309.01507 /github.com/thu-ml/low-bit-optimizers
Kesempitan memori latihan model#🎜 ##🎜🎜 #Dari GPT-3, Gopher kepada LLaMA, ia telah menjadi konsensus industri bahawa model besar mempunyai prestasi yang lebih baik. Walau bagaimanapun, sebaliknya, saiz memori video GPU tunggal telah berkembang dengan perlahan, yang menjadikan memori video sebagai hambatan utama untuk latihan model besar Bagaimana untuk melatih model besar dengan memori GPU terhad telah menjadi masalah penting.
Untuk tujuan ini, kita perlu terlebih dahulu menjelaskan sumber yang menggunakan memori video. Sebenarnya, terdapat tiga jenis sumber iaitu:
1 "Data memory", termasuk data input dan output nilai pengaktifan oleh setiap lapisan saraf rangkaian, saiznya secara langsung dipengaruhi oleh saiz kelompok dan resolusi imej/panjang konteks;
2, termasuk parameter model, kecerunan dan keadaan pengoptimum saiznya adalah berkadar dengan bilangan parameter model;
3 "Memori video sementara" termasuk memori sementara dan cache lain yang digunakan dalam pengiraan kernel GPU. Apabila saiz model bertambah, perkadaran memori model meningkat secara beransur-ansur, menjadi hambatan utama.
Saiz keadaan pengoptimum ditentukan oleh pengoptimum yang digunakan. Pada masa ini, pengoptimum AdamW sering digunakan untuk melatih Transformers, yang perlu menyimpan dan mengemas kini dua keadaan pengoptimum semasa proses latihan, iaitu detik pertama dan kedua. Jika bilangan parameter model ialah N, maka bilangan keadaan pengoptimum dalam AdamW ialah 2N, yang jelas merupakan overhed memori grafik yang besar.
Mengambil LLaMA-7B sebagai contoh, bilangan parameter model ini adalah kira-kira 7B Jika pengoptimum AdamW berketepatan penuh (32-bit). memperhalusinya, kemudian Saiz memori video yang diduduki oleh keadaan pengoptimum adalah lebih kurang 52.2GB. Di samping itu, walaupun pengoptimum SGD yang naif tidak memerlukan keadaan tambahan dan menyimpan memori yang diduduki oleh keadaan pengoptimum, prestasi model sukar untuk dijamin. Oleh itu, artikel ini memfokuskan pada cara mengurangkan keadaan pengoptimum dalam memori model sambil memastikan prestasi pengoptimum tidak terjejas.
Kaedah untuk menjimatkan ingatan pengoptimum
Pada masa ini, dari segi algoritma latihan, kita boleh menyimpan memori overhead pengoptimum. Terdapat tiga kategori kaedah utama:
1. Pemfaktoran); #🎜🎜 #
2 Elakkan menyimpan kebanyakan keadaan pengoptimum dengan hanya melatih set parameter kecil, seperti LoRA #🎜##🎜 ##🎜🎜 #3 Berdasarkan pemampatan, gunakan format berangka ketepatan rendah untuk mewakili status pengoptimum.
Khususnya, Dettmers et al (ICLR 2022) mencadangkan pengoptimum 8-bit yang sepadan untuk SGD dengan momentum dan AdamW, dengan menggunakan kuantisasi blok (block- Wise quantization) dan teknologi format berangka eksponen dinamik (format berangka eksponen dinamik) telah mencapai hasil yang sepadan dengan pengoptimum ketepatan penuh asal dalam tugas seperti pemodelan bahasa, klasifikasi imej, pembelajaran diselia sendiri dan terjemahan mesin.
Berdasarkan ini, kertas kerja ini mengurangkan lagi ketepatan berangka bagi keadaan pengoptimum kepada 4 bit, mencadangkan kaedah pengkuantitian untuk keadaan pengoptimum yang berbeza, dan akhirnya mencadangkan 4- sedikit pengoptimum AdamW. Pada masa yang sama, kertas kerja ini meneroka kemungkinan menggabungkan kaedah pemampatan dan penguraian peringkat rendah, dan mencadangkan pengoptimum Faktor 4-bit ini menikmati prestasi yang baik dan kecekapan memori yang lebih baik. Kertas kerja ini menilai pengoptimuman 4-bit pada beberapa tugas klasik, termasuk pemahaman bahasa semula jadi, klasifikasi imej, terjemahan mesin dan arahan penalaan halus model besar.
Pada semua tugasan, pengoptimum 4-bit mencapai hasil yang setanding dengan pengoptimum ketepatan penuh sambil menggunakan kurang memori.
Tetapan masalah
Rangka kerja berasaskan pemampatan🎜🎜 yang cekap #
Pertama, kita perlu memahami cara memperkenalkan operasi mampatan ke dalam pengoptimum yang biasa digunakan, yang diberikan oleh Algoritma 1. dengan A ialah pengoptimum berasaskan kecerunan (seperti SGD atau AdamW). Pengoptimum mengambil parameter sedia ada w, kecerunan g dan keadaan pengoptimum s dan mengeluarkan parameter baharu dan keadaan pengoptimum. Dalam Algoritma 1, s_t ketepatan penuh adalah sementara, manakala ketepatan rendah (s_t ) ̅ dikekalkan dalam memori GPU. Sebab penting mengapa kaedah ini boleh menjimatkan memori video adalah bahawa parameter rangkaian saraf sering disambungkan bersama dari vektor parameter setiap lapisan. Oleh itu, kemas kini pengoptimum juga dilakukan lapisan demi lapisan/tensor Di bawah Algoritma 1, keadaan pengoptimum paling banyak satu parameter dibiarkan dalam ingatan dalam bentuk ketepatan penuh, dan keadaan pengoptimum yang sepadan dengan lapisan lain berada dalam keadaan termampat. negeri.

Kaedah mampatan utama: kuantisasi #🎜 🎜🎜#
Kuantisasi ialah teknologi yang menggunakan nilai berangka berketepatan rendah untuk mewakili data berketepatan tinggi Artikel ini mengasingkan operasi kuantifikasi kepada dua bahagian: normalisasi dan pemetaan, supaya ia boleh Reka bentuk yang lebih ringan dan eksperimen. dengan kaedah pengkuantitian baharu. Dua operasi, penormalan dan pemetaan, digunakan secara berurutan pada data ketepatan penuh dengan cara mengikut unsur. Penormalan bertanggungjawab untuk mengunjurkan setiap elemen dalam tensor kepada selang unit, di mana penormalan tensor (penormalan setiap tensor) dan penormalan dari segi blok (penormalan mengikut blok) ditakrifkan seperti berikut: #🎜🎜 ##🎜 🎜#
Kaedah normalisasi yang berbeza mempunyai butiran yang berbeza, dan keupayaannya untuk mengendalikan outlier akan berbeza, dan overhed memori tambahan yang mereka bawa juga berbeza. Operasi pemetaan bertanggungjawab untuk memetakan nilai ternormal kepada integer yang boleh diwakili dengan ketepatan yang rendah. Secara formal, diberi sedikit lebar b (iaitu, setiap nilai diwakili oleh b bit selepas pengkuantitian) dan fungsi yang dipratentukan T #Operasi pemetaan ditakrifkan sebagai:
#🎜🎜 #
Oleh itu, cara mereka bentuk T yang sesuai untuk mengurangkan Ralat pengkuantitian memainkan peranan penting. Artikel ini mempertimbangkan pemetaan linear (linear) dan pemetaan eksponen dinamik (eksponen dinamik). Akhir sekali, proses dekuantisasi adalah untuk menggunakan operator songsang pemetaan dan normalisasi dalam urutan.
Kaedah mampatan momen pesanan pertama
Berikut adalah terutamanya untuk status pengoptimum pertama AdamW -order momen dan detik tertib kedua) mencadangkan kaedah kuantifikasi yang berbeza. Untuk detik pertama, kaedah pengkuantitian dalam kertas ini adalah berdasarkan kaedah Dettmers et al (ICLR 2022), menggunakan penormalan blok (saiz blok 2048) dan pemetaan eksponen dinamik.
Dalam eksperimen awal, kami secara langsung mengurangkan lebar bit daripada 8 bit kepada 4 bit dan mendapati bahawa momen tertib pertama adalah sangat teguh untuk pengkuantitian dan telah digunakan dalam banyak tugas Kesan padanan dicapai, tetapi terdapat juga kehilangan prestasi pada beberapa tugas. Untuk meningkatkan lagi prestasi, kami mengkaji corak detik pertama dengan teliti dan mendapati terdapat banyak outlier dalam satu tensor.
Kerja sebelum ini telah melakukan beberapa kajian tentang corak outlier dalam parameter dan nilai pengaktifan Agihan parameter adalah agak lancar, manakala nilai pengaktifan diagihkan mengikut saluran. Artikel ini mendapati bahawa taburan outlier dalam keadaan pengoptimum adalah rumit, dengan sesetengah tensor mempunyai outlier yang diagihkan dalam baris tetap dan tensor lain mempunyai outlier yang diagihkan dalam lajur tetap.
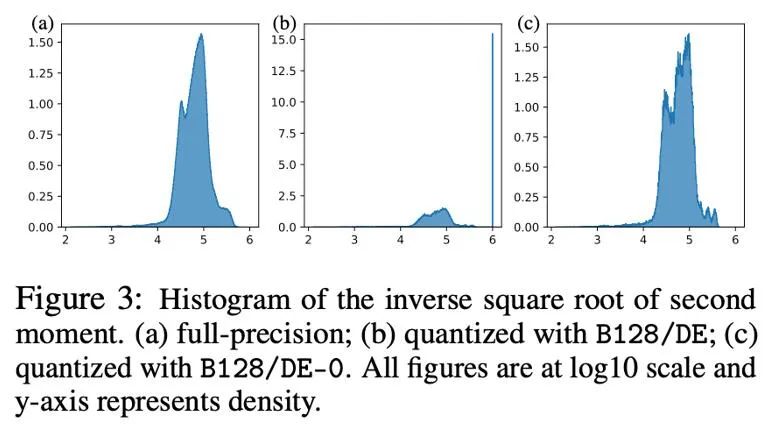
Untuk tensor dengan taburan outlier mengikut lajur, normalisasi blok baris pertama mungkin menghadapi kesukaran. Oleh itu, kertas kerja ini mencadangkan untuk menggunakan blok yang lebih kecil dengan saiz blok 128, yang boleh mengurangkan ralat pengkuantitian sambil mengekalkan overhed memori tambahan dalam julat yang boleh dikawal. Rajah di bawah menunjukkan ralat pengkuantitian untuk saiz blok yang berbeza.
Kaedah mampatan momen tertib kedua
Berbanding dengan momen tertib pertama, pengkuantitian momen tertib kedua adalah lebih sukar dan akan membawa ketidakstabilan masalah latihan. Kertas kerja ini menentukan bahawa masalah titik sifar adalah kesesakan utama dalam mengira detik tertib kedua Selain itu, kaedah penormalan yang lebih baik dicadangkan untuk taburan terpencil yang tidak terkondisi: penormalan peringkat-1. Artikel ini juga mencuba kaedah penguraian (pemfaktoran) momen tertib kedua.
masalah titik sifar
#🎜 syarat-syarat nilai pengaktifan🎜 , dan kecerunan Dalam pengkuantitian, titik sifar selalunya amat diperlukan, dan ia juga merupakan titik dengan kekerapan tertinggi selepas pengkuantitian. Walau bagaimanapun, dalam formula lelaran Adam, saiz kemas kini adalah berkadar dengan kuasa -1/2 momen kedua, jadi perubahan dalam julat sekitar sifar akan mempengaruhi saiz kemas kini, menyebabkan ketidakstabilan.
Rajah berikut menunjukkan kuasa saat-1/2 Adam kedua sebelum dan selepas kuantisasi dalam bentuk Taburan histogram, iaitu, h (v)=1/(√v+10^(-6) ). Jika sifar dimasukkan (rajah b), maka kebanyakan nilai ditolak sehingga 10^6, mengakibatkan ralat anggaran yang besar. Pendekatan mudah adalah untuk mengalih keluar sifar dalam peta eksponen dinamik, selepas berbuat demikian (rajah c) penghampiran kepada saat kedua menjadi lebih tepat. Dalam situasi sebenar, untuk menggunakan keupayaan ekspresif nilai berangka ketepatan rendah dengan berkesan, kami mencadangkan untuk menggunakan pemetaan linear yang mengalihkan titik sifar dan mencapai keputusan yang baik dalam eksperimen.
Rank-1 Dinormalisasi ##🎜🎜🎜##🎜🎜🎜##🎜🎜🎜##🎜 🎜#Berdasarkan pengedaran terpencil yang kompleks bagi momen tertib pertama dan detik tertib kedua, dan diilhamkan oleh pengoptimum SM3, artikel ini mencadangkan kaedah normalisasi baharu, Dinamakan peringkat-1 normalisasi. Untuk tensor matriks bukan negatif x∈R^(n×m), statistik satu dimensinya ditakrifkan sebagai:
#🎜🎜 #
Kemudian penormalan peringkat-1 boleh ditakrifkan sebagai:
peringkat-1 mengeksploitasi penormalan satu -maklumat dimensi tensor dengan cara yang lebih halus, dan boleh mengendalikan outlier dari segi baris atau lajur dengan lebih bijak dan cekap. Di samping itu, normalisasi peringkat-1 boleh digeneralisasikan dengan mudah kepada tensor dimensi tinggi, dan apabila saiz tensor meningkat, overhed memori tambahan yang dijananya adalah lebih kecil daripada normalisasi blok.
Di samping itu, artikel ini mendapati bahawa kaedah penguraian peringkat rendah bagi momen tertib kedua dalam pengoptimum Adafaktor boleh mengelakkan masalah titik sifar dengan berkesan, jadi ia juga mempunyai kelebihan kaedah penguraian peringkat rendah dan pengkuantitian diterokai secara gabungan. Rajah di bawah menunjukkan satu siri eksperimen ablasi untuk momen tertib kedua, yang mengesahkan bahawa masalah titik sifar ialah kesesakan pengiraan detik tertib kedua Ia juga mengesahkan keberkesanan kaedah penormalan peringkat-1 dan penguraian peringkat rendah.
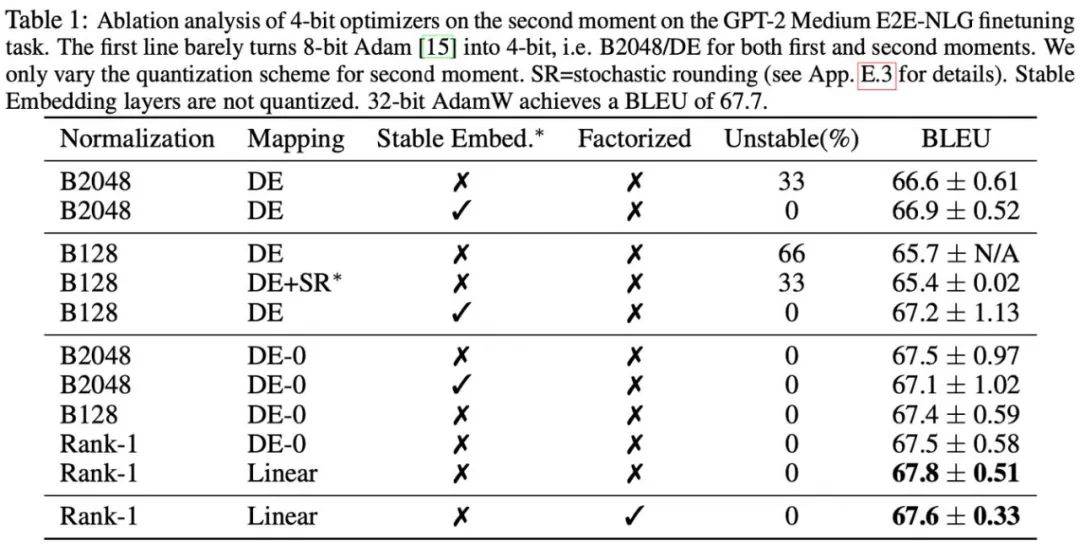
Hasil eksperimen#🎜#🎜 berasaskan##🎜#🎜🎜 pada pemerhatian Berdasarkan fenomena dan kaedah penggunaan, dua pengoptimum ketepatan rendah akhirnya dicadangkan: AdamW 4-bit dan Faktor 4-bit, dan dibandingkan dengan pengoptimum lain, termasuk AdamW 8-bit, Adafactor dan SM3. Kajian telah dipilih untuk penilaian pada pelbagai tugas, termasuk pemahaman bahasa semula jadi, klasifikasi imej, terjemahan mesin, dan penalaan halus arahan model besar. Jadual di bawah menunjukkan prestasi setiap pengoptimum pada tugas yang berbeza.
Anda boleh lihat semua itu tugasan , termasuk NLU, QA, NLG, pengoptimum 4-bit boleh memadankan atau bahkan melebihi AdamW 32-bit Pada masa yang sama, pada semua tugasan pra-latihan, pengoptimum CLS, MT dan 4-bit mencapai tahap. setanding dengan ketepatan penuh. Ia boleh dilihat daripada tugas penalaan halus arahan bahawa 4-bit AdamW tidak memusnahkan keupayaan model pra-latihan, dan pada masa yang sama boleh membolehkan mereka memperoleh keupayaan untuk mematuhi arahan dengan lebih baik.
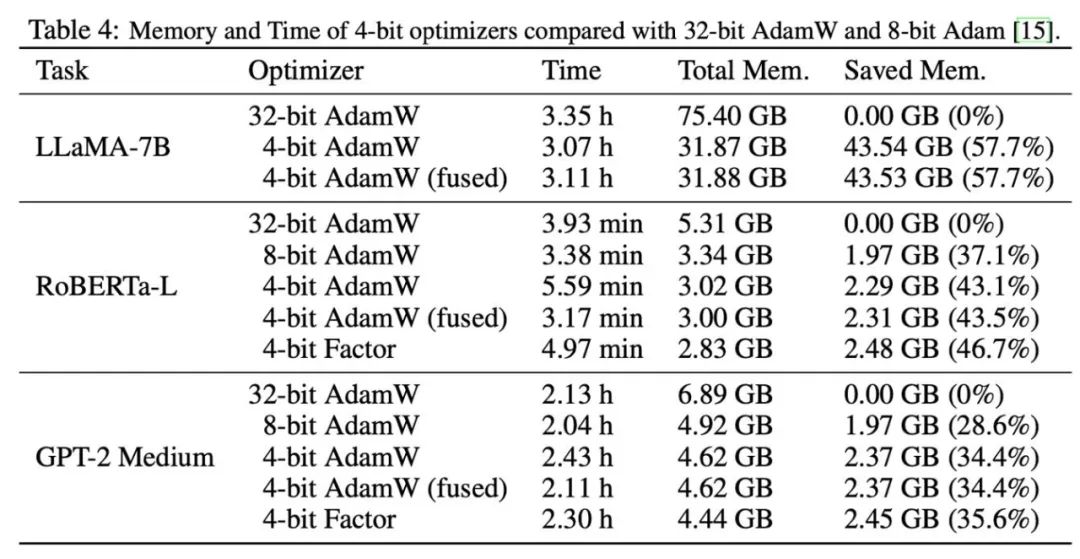
Selepas itu, kami menguji memori dan kecekapan pengiraan pengoptimum 4-bit, dan hasilnya ditunjukkan dalam jadual di bawah. Berbanding dengan pengoptimum 8-bit, pengoptimum 4-bit yang dicadangkan dalam artikel ini boleh menjimatkan lebih banyak memori, dengan penjimatan maksimum 57.7% dalam eksperimen penalaan halus LLaMA-7B. Selain itu, kami menyediakan versi pengendali gabungan AdamW 4-bit, yang boleh menjimatkan memori tanpa menjejaskan kecekapan pengiraan. Untuk tugasan penalaan halus arahan LLaMA-7B, 4-bit AdamW juga membawa kesan pecutan kepada latihan akibat tekanan cache yang berkurangan. Tetapan dan keputusan percubaan terperinci boleh didapati dalam pautan kertas.
Ganti satu baris kod untuk menggunakannya dalam PyTorch
import lpmmoptimizer = lpmm.optim.AdamW (model.parameters (), lr=1e-3, betas=(0.9, 0.999))
Salin selepas log masuk
Kami menyediakan pengoptimum 4-bit di luar kotak, anda hanya perlu menggantikan pengoptimum asal dengan pengoptimum 4-bit pada masa ini menyokong versi ketepatan rendah Adam dan SGD. Pada masa yang sama, kami juga menyediakan antara muka untuk mengubah suai parameter pengkuantitian untuk menyokong senario penggunaan tersuai.

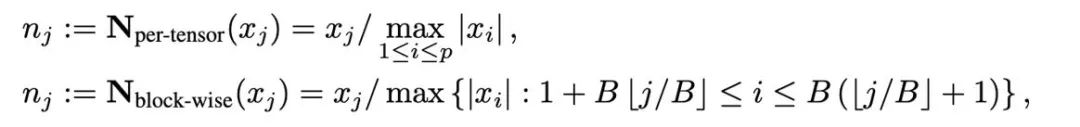 Operasi pemetaan ditakrifkan sebagai:
Operasi pemetaan ditakrifkan sebagai: 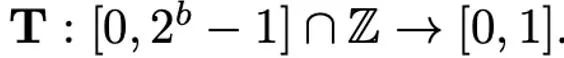
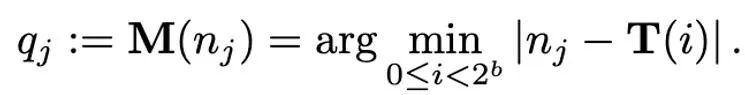 Berikut adalah terutamanya untuk status pengoptimum pertama AdamW -order momen dan detik tertib kedua) mencadangkan kaedah kuantifikasi yang berbeza. Untuk detik pertama, kaedah pengkuantitian dalam kertas ini adalah berdasarkan kaedah Dettmers et al (ICLR 2022), menggunakan penormalan blok (saiz blok 2048) dan pemetaan eksponen dinamik.
Berikut adalah terutamanya untuk status pengoptimum pertama AdamW -order momen dan detik tertib kedua) mencadangkan kaedah kuantifikasi yang berbeza. Untuk detik pertama, kaedah pengkuantitian dalam kertas ini adalah berdasarkan kaedah Dettmers et al (ICLR 2022), menggunakan penormalan blok (saiz blok 2048) dan pemetaan eksponen dinamik. 
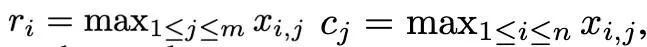
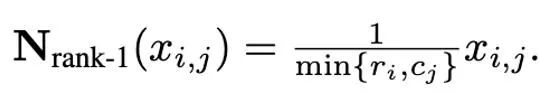
 #🎜#🎜 berasaskan##🎜#🎜🎜 pada pemerhatian Berdasarkan fenomena dan kaedah penggunaan, dua pengoptimum ketepatan rendah akhirnya dicadangkan: AdamW 4-bit dan Faktor 4-bit, dan dibandingkan dengan pengoptimum lain, termasuk AdamW 8-bit, Adafactor dan SM3. Kajian telah dipilih untuk penilaian pada pelbagai tugas, termasuk pemahaman bahasa semula jadi, klasifikasi imej, terjemahan mesin, dan penalaan halus arahan model besar. Jadual di bawah menunjukkan prestasi setiap pengoptimum pada tugas yang berbeza.
#🎜#🎜 berasaskan##🎜#🎜🎜 pada pemerhatian Berdasarkan fenomena dan kaedah penggunaan, dua pengoptimum ketepatan rendah akhirnya dicadangkan: AdamW 4-bit dan Faktor 4-bit, dan dibandingkan dengan pengoptimum lain, termasuk AdamW 8-bit, Adafactor dan SM3. Kajian telah dipilih untuk penilaian pada pelbagai tugas, termasuk pemahaman bahasa semula jadi, klasifikasi imej, terjemahan mesin, dan penalaan halus arahan model besar. Jadual di bawah menunjukkan prestasi setiap pengoptimum pada tugas yang berbeza. 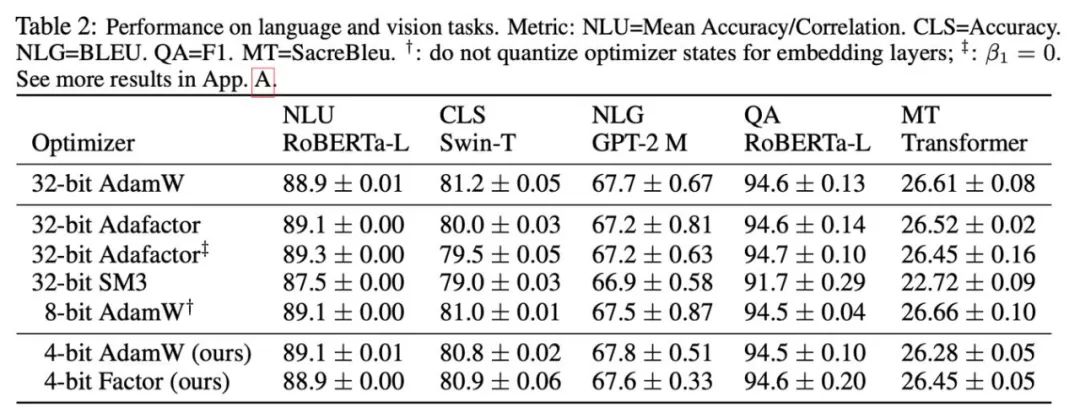
import lpmmoptimizer = lpmm.optim.AdamW (model.parameters (), lr=1e-3, betas=(0.9, 0.999))
Atas ialah kandungan terperinci Penalaan halus LLaMA mengurangkan separuh keperluan memori, Tsinghua mencadangkan pengoptimum 4-bit. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote Company Kekosongan Syarikat: Lokasi Lokasi: Jauh Pejabat Jauh Jenis: Gaji sepenuh masa: $ 130,000- $ 140,000 Penerangan Pekerjaan Mengambil bahagian dalam penyelidikan dan pembangunan aplikasi mudah alih Circle dan ciri-ciri berkaitan API awam yang meliputi keseluruhan kitaran hayat pembangunan perisian. Tanggungjawab utama kerja pembangunan secara bebas berdasarkan rubyonrails dan bekerjasama dengan pasukan react/redux/relay front-end. Membina fungsi teras dan penambahbaikan untuk aplikasi web dan bekerjasama rapat dengan pereka dan kepimpinan sepanjang proses reka bentuk berfungsi. Menggalakkan proses pembangunan positif dan mengutamakan kelajuan lelaran. Memerlukan lebih daripada 6 tahun backend aplikasi web kompleks
 Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
MySQL boleh mengembalikan data JSON. Fungsi JSON_EXTRACT mengekstrak nilai medan. Untuk pertanyaan yang kompleks, pertimbangkan untuk menggunakan klausa WHERE untuk menapis data JSON, tetapi perhatikan kesan prestasinya. Sokongan MySQL untuk JSON sentiasa meningkat, dan disyorkan untuk memberi perhatian kepada versi dan ciri terkini.
 Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Penjelasan terperinci mengenai atribut asid asid pangkalan data adalah satu set peraturan untuk memastikan kebolehpercayaan dan konsistensi urus niaga pangkalan data. Mereka menentukan bagaimana sistem pangkalan data mengendalikan urus niaga, dan memastikan integriti dan ketepatan data walaupun dalam hal kemalangan sistem, gangguan kuasa, atau pelbagai pengguna akses serentak. Gambaran keseluruhan atribut asid Atomicity: Transaksi dianggap sebagai unit yang tidak dapat dipisahkan. Mana -mana bahagian gagal, keseluruhan transaksi dilancarkan kembali, dan pangkalan data tidak mengekalkan sebarang perubahan. Sebagai contoh, jika pemindahan bank ditolak dari satu akaun tetapi tidak meningkat kepada yang lain, keseluruhan operasi dibatalkan. Begintransaction; UpdateAcCountSsetBalance = Balance-100Wh
 Mysql tidak dapat dipasang setelah memuat turun
Apr 08, 2025 am 11:24 AM
Mysql tidak dapat dipasang setelah memuat turun
Apr 08, 2025 am 11:24 AM
Sebab utama kegagalan pemasangan MySQL adalah: 1. Isu kebenaran, anda perlu menjalankan sebagai pentadbir atau menggunakan perintah sudo; 2. Ketergantungan hilang, dan anda perlu memasang pakej pembangunan yang relevan; 3. Konflik pelabuhan, anda perlu menutup program yang menduduki port 3306 atau mengubah suai fail konfigurasi; 4. Pakej pemasangan adalah korup, anda perlu memuat turun dan mengesahkan integriti; 5. Pembolehubah persekitaran dikonfigurasikan dengan salah, dan pembolehubah persekitaran mesti dikonfigurasi dengan betul mengikut sistem operasi. Selesaikan masalah ini dan periksa dengan teliti setiap langkah untuk berjaya memasang MySQL.
 Kunci utama MySQL boleh menjadi batal
Apr 08, 2025 pm 03:03 PM
Kunci utama MySQL boleh menjadi batal
Apr 08, 2025 pm 03:03 PM
Kunci utama MySQL tidak boleh kosong kerana kunci utama adalah atribut utama yang secara unik mengenal pasti setiap baris dalam pangkalan data. Jika kunci utama boleh kosong, rekod tidak dapat dikenal pasti secara unik, yang akan membawa kepada kekeliruan data. Apabila menggunakan lajur integer sendiri atau UUIDs sebagai kunci utama, anda harus mempertimbangkan faktor-faktor seperti kecekapan dan penghunian ruang dan memilih penyelesaian yang sesuai.
