
 Peranti teknologi
AI
180 bilion parameter, model besar sumber terbuka terkemuka dunia Falcon diumumkan secara rasmi! Hancurkan LLaMA 2, prestasi hampir dengan GPT-4
Peranti teknologi
AI
180 bilion parameter, model besar sumber terbuka terkemuka dunia Falcon diumumkan secara rasmi! Hancurkan LLaMA 2, prestasi hampir dengan GPT-4
180 bilion parameter, model besar sumber terbuka terkemuka dunia Falcon diumumkan secara rasmi! Hancurkan LLaMA 2, prestasi hampir dengan GPT-4

Semalaman, model besar sumber terbuka paling berkuasa di dunia Falcon 180B melancarkan seluruh Internet!
Dengan 180 bilion parameter, Falcon menyelesaikan latihan mengenai 3.5 trilion token dan terus mendahului kedudukan Memeluk Wajah.
Dalam ujian penanda aras, Falcon 180B mengalahkan Llama 2 dalam pelbagai tugas seperti penaakulan, pengekodan, kecekapan dan ujian pengetahuan.
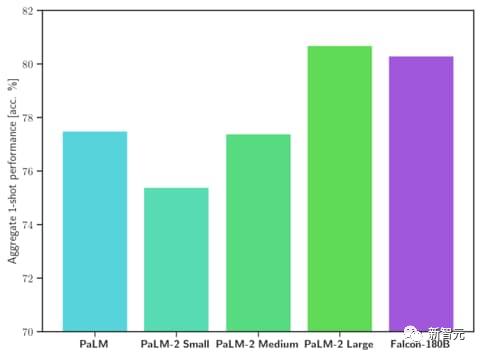
Malah, Falcon 180B adalah setanding dengan Google PaLM 2, dan prestasinya hampir dengan GPT-4.
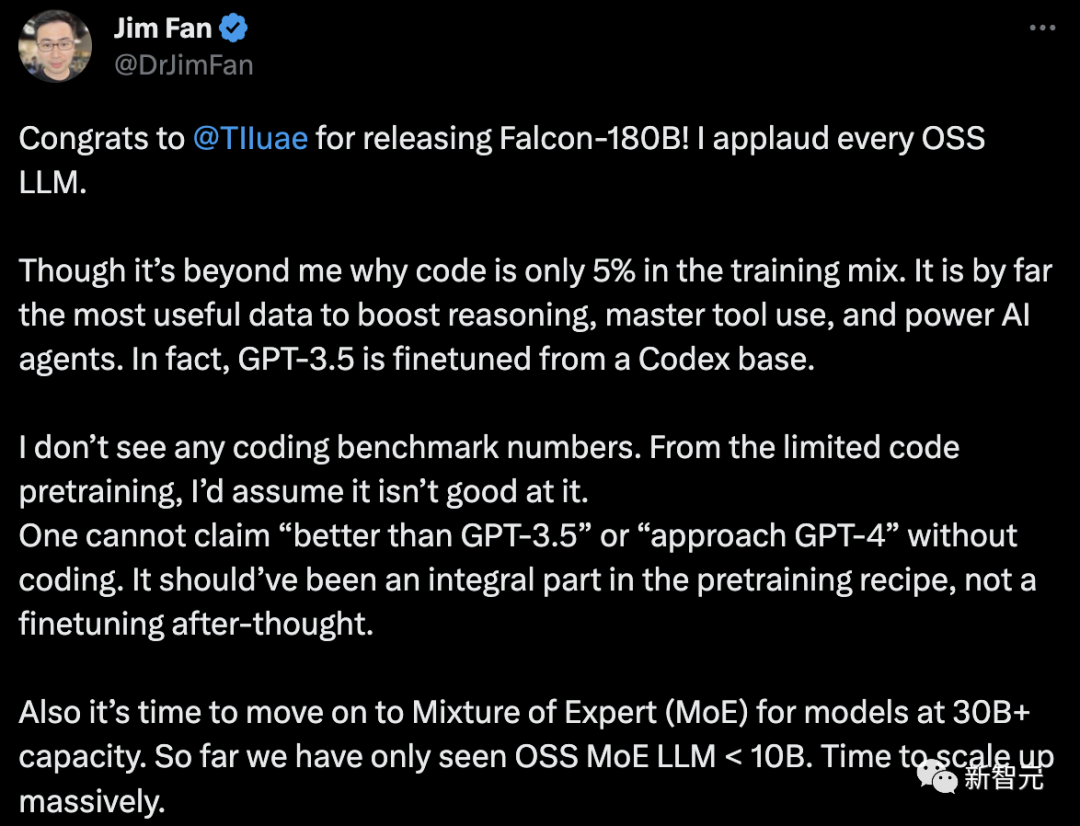
Walau bagaimanapun, saintis kanan NVIDIA Jim Fan mempersoalkan perkara ini,
- Kod hanya menyumbang 5% daripada data latihan Falcon-180B.
Dan kod setakat ini adalah data yang paling berguna untuk meningkatkan keupayaan penaakulan, menguasai penggunaan alat dan meningkatkan ejen AI. Malah, GPT-3.5 diperhalusi berdasarkan Codex.
- Tiada pengekodan data penanda aras.
Tanpa keupayaan pengekodan, anda tidak boleh mendakwa sebagai "lebih baik daripada GPT-3.5" atau "dekat dengan GPT-4". Ia harus menjadi sebahagian daripada resipi pra-latihan, bukan tweak selepas fakta.
- Untuk model bahasa dengan parameter lebih besar daripada 30B, sudah tiba masanya untuk mengguna pakai sistem pakar hibrid (KPM). Setakat ini kami hanya melihat OSS MoE LLM
Mari kita lihat, apakah asal usul Falcon 180B?

Model besar sumber terbuka paling berkuasa di dunia
Sebelum ini, Falcon telah melancarkan tiga saiz model, iaitu 1.3B, 7.5B, dan 40B.
Secara rasmi, Falcon 180B ialah versi 40B yang dinaik taraf Ia dilancarkan oleh TII, pusat penyelidikan teknologi terkemuka dunia di Abu Dhabi, dan tersedia untuk kegunaan komersial percuma.

Kali ini, penyelidik membuat inovasi teknikal pada model asas, seperti menggunakan Perhatian Berbilang Pertanyaan untuk meningkatkan kebolehskalaan model.
Untuk proses latihan, Falcon 180B adalah berdasarkan Amazon SageMaker, platform pembelajaran mesin awan Amazon, dan telah menyelesaikan latihan 3.5 trilion token pada sehingga 4096 GPU.
Jumlah masa pengiraan GPU, kira-kira 7,000,000.
Saiz parameter Falcon 180B ialah 2.5 kali ganda daripada Llama 2 (70B), dan jumlah pengiraan yang diperlukan untuk latihan ialah 4 kali ganda daripada Llama 2.
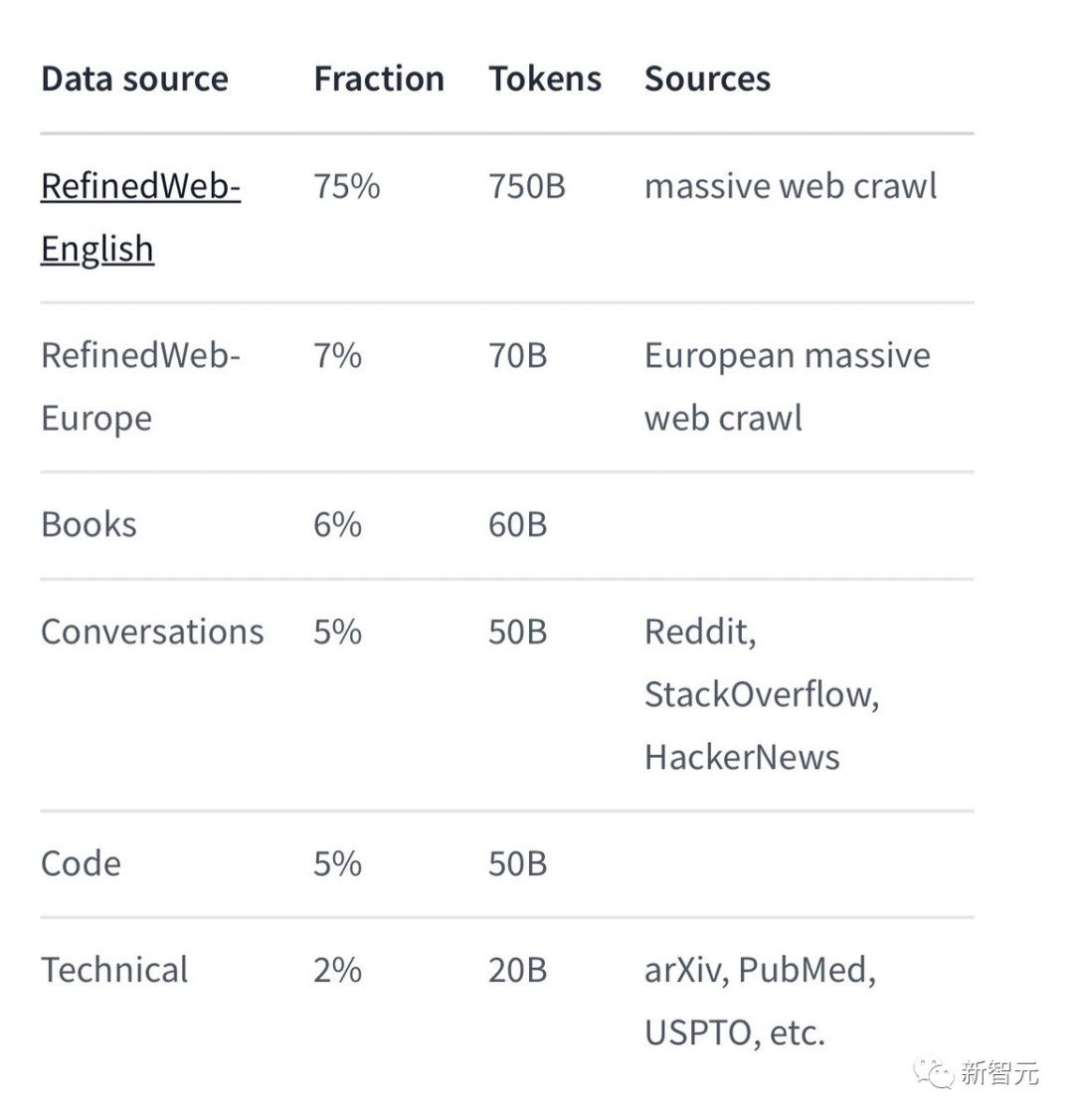
Antara data latihan khusus, Falcon 180B terutamanya set data RefinedWe (kira-kira 85%).
Selain itu, ia dilatih mengenai gabungan data yang teratur seperti perbualan, kertas teknikal dan sebahagian kecil kod.
Set data pra-latihan ini cukup besar, malah 3.5 trilion token hanya menduduki kurang daripada satu zaman. . 3.5.
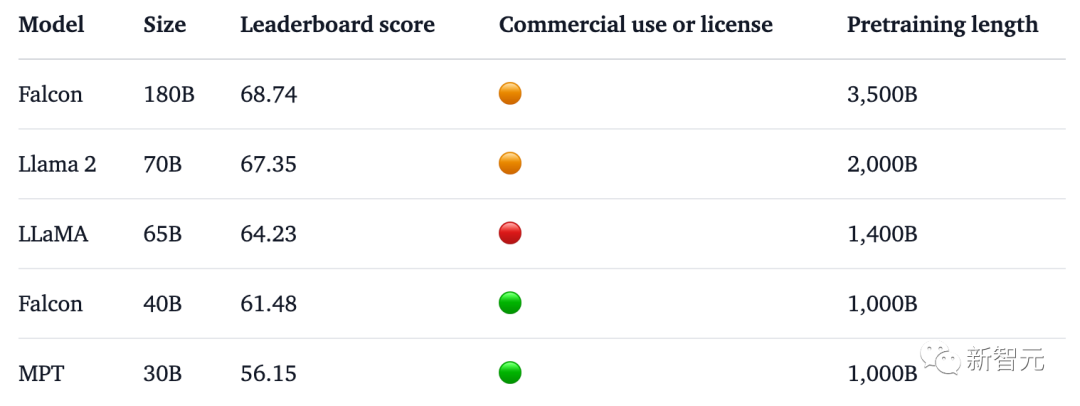
 Setanding dengan PaLM 2-Large Google di HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC dan ReCoRD.
Setanding dengan PaLM 2-Large Google di HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC dan ReCoRD.
Selain itu, ia kini merupakan model besar terbuka dengan skor tertinggi (68.74 mata) pada senarai model besar sumber terbuka Hugging Face, mengatasi LlaMA 2 (67.35).
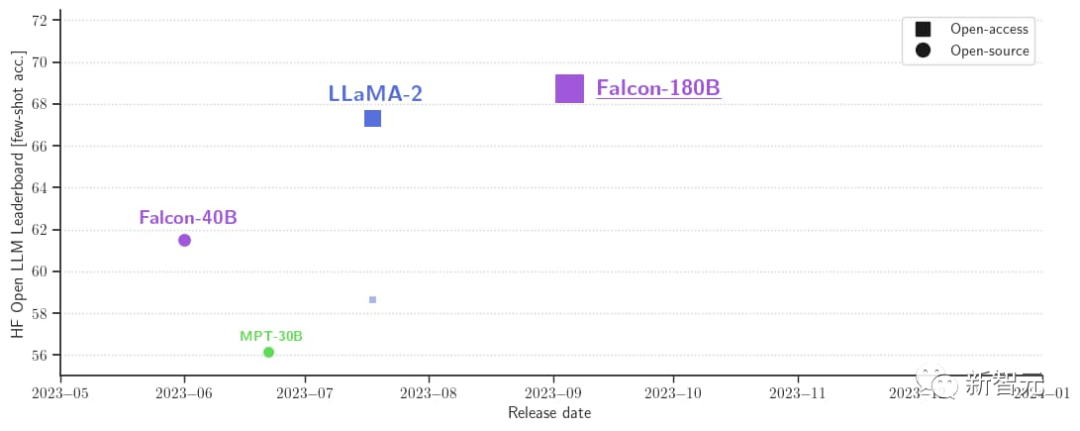
Falcon 180B kini tersedia
Pada masa yang sama, para penyelidik juga mengeluarkan model perbualan sembang Falcon-180B-Chat. Model ini diperhalusi pada set data perbualan dan arahan yang meliputi Open-Platypus, UltraChat dan Airoboros.

Kini, semua orang boleh merasai pengalaman demo.
Alamat: https://huggingface.co/tiiuae/falcon-180B-chat
Format segera
Model asas tidak mempunyai perbualan besar kerana ia adalah Prompt model. Ia juga tidak dilatih melalui arahan, jadi ia tidak bertindak balas dalam cara perbualan.
Model pra-latihan ialah platform yang bagus untuk penalaan halus, tetapi mungkin anda tidak sepatutnya menggunakannya secara langsung. Model dialognya mempunyai mod dialog mudah.
System: Add an optional system prompt hereUser: This is the user inputFalcon: This is what the model generatesUser: This might be a second turn inputFalcon: and so on
Transformers
Bermula dari Transformers 4.33, Falcon 180B boleh digunakan dan dimuat turun dalam ekosistem Hugging Face.
Pastikan anda log masuk ke akaun Hugging Face anda dan memasang versi terkini transformer:
pip install --upgrade transformershuggingface-cli login
bfloat16
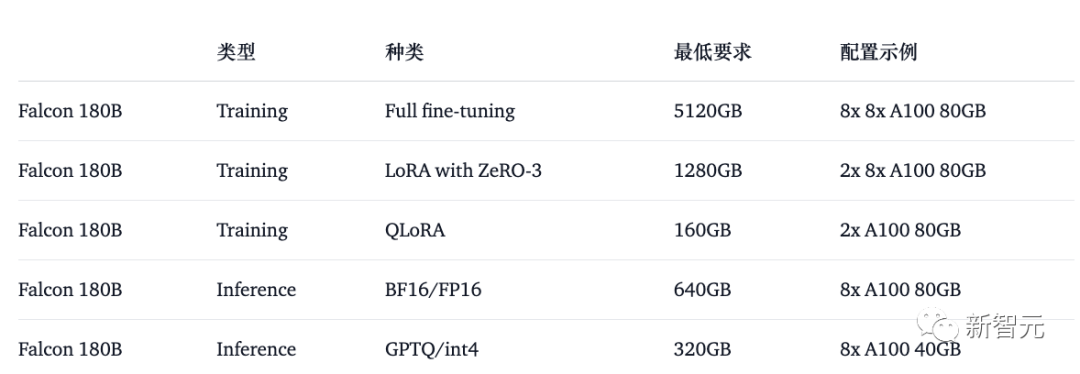
Begini cara menggunakan model base1 dalam bfloat. Falcon 180B ialah model yang besar, jadi harap maklum tentang keperluan perkakasannya.
Dalam hal ini, keperluan perkakasan adalah seperti berikut:
Dapat dilihat bahawa jika anda ingin memperhalusi Falcon 180B, anda memerlukan sekurang-kurangnya 8X8X A100 80G, jika ia hanya untuk inferens. anda juga memerlukan GPU 8XA100 80G.
from transformers import AutoTokenizer, AutoModelForCausalLMimport transformersimport torchmodel_id = "tiiuae/falcon-180B"tokenizer = AutoTokenizer.from_pretrained(model_id)model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,device_map="auto",)prompt = "My name is Pedro, I live in"inputs = tokenizer(prompt, return_tensors="pt").to("cuda")output = model.generate(input_ids=inputs["input_ids"],attention_mask=inputs["attention_mask"],do_sample=True,temperature=0.6,top_p=0.9,max_new_tokens=50,)output = output[0].to("cpu")print(tokenizer.decode(output)boleh menghasilkan output berikut:
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video.I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.
using 8-bit dan 4-bit bitsandbytes
Selain itu, versi 8-bit dan 4-bit kuantiti falcon 180B sedang dinilai Hampir tiada perbezaan antaranya dan bfloat16!
Ini adalah berita baik untuk kesimpulan, kerana pengguna boleh menggunakan versi terkuantisasi dengan selamat untuk mengurangkan keperluan perkakasan.
Perhatikan bahawa inferens adalah lebih pantas dalam versi 8-bit berbanding versi 4-bit. Untuk menggunakan pengkuantitian, anda perlu memasang pustaka "bitsandbytes" dan mendayakan bendera yang sepadan apabila memuatkan model:
model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,**load_in_8bit=True,**device_map="auto",)
Model Perbualan
Seperti yang dinyatakan di atas, versi model yang telah diperhalusi untuk dialog penjejakan, Templat latihan yang sangat mudah digunakan. Kita perlu mengikut corak yang sama untuk menjalankan penaakulan gaya sembang.
Untuk rujukan, anda boleh lihat fungsi [format_prompt] dalam demo sembang:
def format_prompt(message, history, system_prompt):prompt = ""if system_prompt:prompt += f"System: {system_prompt}\n"for user_prompt, bot_response in history:prompt += f"User: {user_prompt}\n"prompt += f"Falcon: {bot_response}\n"prompt += f"User: {message}\nFalcon:"return promptSeperti yang anda lihat di atas, interaksi pengguna dan respons model didahului oleh Pengguna: dan Falcon: pembatas. Kami menyambungkannya bersama-sama untuk membentuk gesaan yang mengandungi keseluruhan sejarah perbualan. Dengan cara ini, gesaan sistem boleh disediakan untuk melaraskan gaya binaan.
Komen hangat netizen
Ramai netizen sedang membincangkan kekuatan sebenar Falcon 180B.
Sungguh luar biasa. Ia mengalahkan GPT-3.5 dan setanding dengan PaLM-2 Large Google. Ini adalah pengubah permainan!

Seorang CEO permulaan berkata bahawa saya telah menguji robot perbualan Falcon-180B dan ia tidak lebih baik daripada sistem sembang Llama2-70B. Kedudukan HF OpenLLM juga menunjukkan hasil yang bercampur-campur. Ini mengejutkan memandangkan saiznya yang lebih besar dan set latihan yang lebih besar.
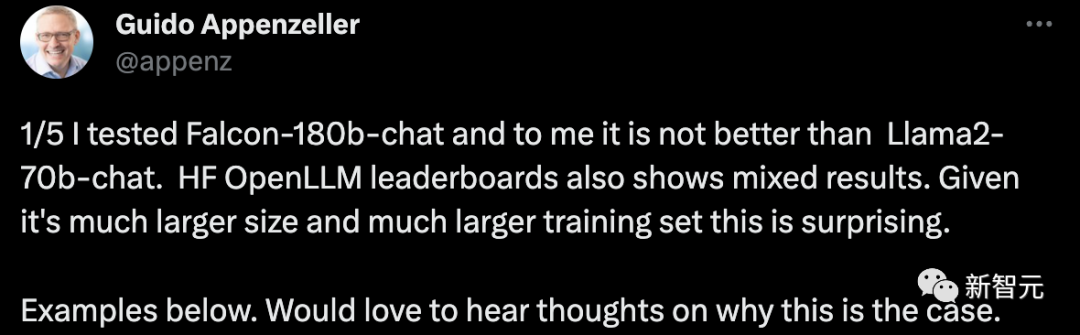
Contohnya:
Berikan beberapa item dan biarkan Falcon-180B dan Llama2-70B menjawabnya masing-masing untuk melihat apakah kesannya?
Falcon-180B tersilap mengira pelana sebagai haiwan. Llama2-70B menjawab dengan ringkas dan memberikan jawapan yang betul.


Atas ialah kandungan terperinci 180 bilion parameter, model besar sumber terbuka terkemuka dunia Falcon diumumkan secara rasmi! Hancurkan LLaMA 2, prestasi hampir dengan GPT-4. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1359
1359
 52
52

 Bagaimana cara menukar saiz senarai bootstrap?
Apr 07, 2025 am 10:45 AM
Bagaimana cara menukar saiz senarai bootstrap?
Apr 07, 2025 am 10:45 AM
Saiz senarai bootstrap bergantung kepada saiz bekas yang mengandungi senarai, bukan senarai itu sendiri. Menggunakan sistem grid Bootstrap atau Flexbox boleh mengawal saiz bekas, dengan itu secara tidak langsung mengubah saiz item senarai.
 Bagaimana untuk melaksanakan penyiaran senarai bootstrap?
Apr 07, 2025 am 10:27 AM
Bagaimana untuk melaksanakan penyiaran senarai bootstrap?
Apr 07, 2025 am 10:27 AM
Senarai bersarang di Bootstrap memerlukan penggunaan sistem grid Bootstrap untuk mengawal gaya. Pertama, gunakan lapisan luar & lt; ul & gt; dan & lt; li & gt; Untuk membuat senarai, kemudian bungkus senarai lapisan dalaman dalam & lt; div class = & quot; row & gt; dan tambah & lt; kelas div = & quot; col-md-6 & quot; & gt; ke senarai lapisan dalaman untuk menentukan bahawa senarai lapisan dalaman menduduki separuh lebar baris. Dengan cara ini, senarai dalaman boleh mempunyai yang betul
 Bagaimana cara menambah ikon ke senarai bootstrap?
Apr 07, 2025 am 10:42 AM
Bagaimana cara menambah ikon ke senarai bootstrap?
Apr 07, 2025 am 10:42 AM
Cara Menambah Ikon ke Senarai Bootstrap: Secara langsung barangan ikon ke dalam item senarai & lt; li & gt;, menggunakan nama kelas yang disediakan oleh Perpustakaan Ikon (seperti Font Awesome). Gunakan kelas Bootstrap untuk menyelaraskan ikon dan teks (contohnya, D-Flex, Justify-Content-Between, Align-Items-Center). Gunakan komponen tag bootstrap (lencana) untuk memaparkan nombor atau status. Laraskan kedudukan ikon (arah flex: row-reverse;), mengawal gaya (gaya CSS). Ralat biasa: ikon tidak dipaparkan (tidak
 Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Apabila menukar rentetan ke objek dalam vue.js, json.parse () lebih disukai untuk rentetan json standard. Untuk rentetan JSON yang tidak standard, rentetan boleh diproses dengan menggunakan ungkapan biasa dan mengurangkan kaedah mengikut format atau url yang dikodkan. Pilih kaedah yang sesuai mengikut format rentetan dan perhatikan isu keselamatan dan pengekodan untuk mengelakkan pepijat.
 Cara Melihat Sistem Grid Bootstrap
Apr 07, 2025 am 09:48 AM
Cara Melihat Sistem Grid Bootstrap
Apr 07, 2025 am 09:48 AM
Sistem mesh Bootstrap adalah peraturan untuk membina susun atur responsif dengan cepat, yang terdiri daripada tiga kelas utama: kontena (kontena), baris (baris), dan col (lajur). Secara lalai, grid 12-kolumn disediakan, dan lebar setiap lajur boleh diselaraskan melalui kelas tambahan seperti Col-MD-, dengan itu mencapai pengoptimuman susun atur untuk saiz skrin yang berbeza. Dengan menggunakan kelas mengimbangi dan jejaring bersarang, fleksibiliti susun atur boleh dilanjutkan. Apabila menggunakan sistem grid, pastikan setiap elemen mempunyai struktur bersarang yang betul dan pertimbangkan pengoptimuman prestasi untuk meningkatkan kelajuan pemuatan halaman. Hanya dengan pemahaman dan amalan yang mendalam, kita dapat menguasai sistem grid bootstrap yang mahir.
 Apakah perubahan yang telah dibuat dengan gaya senarai Bootstrap 5?
Apr 07, 2025 am 11:09 AM
Apakah perubahan yang telah dibuat dengan gaya senarai Bootstrap 5?
Apr 07, 2025 am 11:09 AM
Perubahan gaya Bootstrap 5 adalah disebabkan oleh pengoptimuman terperinci dan peningkatan semantik, termasuk: margin lalai senarai yang tidak teratur dipermudahkan, dan kesan visual adalah bersih dan kemas; Gaya senarai menekankan semantik, meningkatkan kebolehcapaian dan penyelenggaraan.
 Cara mendaftarkan komponen yang dieksport oleh lalai eksport di Vue
Apr 07, 2025 pm 06:24 PM
Cara mendaftarkan komponen yang dieksport oleh lalai eksport di Vue
Apr 07, 2025 pm 06:24 PM
Soalan: Bagaimana untuk mendaftarkan komponen VUE yang dieksport melalui lalai eksport? Jawapan: Terdapat tiga kaedah pendaftaran: Pendaftaran Global: Gunakan kaedah vue.component () untuk mendaftar sebagai komponen global. Pendaftaran Tempatan: Daftar dalam pilihan Komponen, hanya terdapat dalam komponen semasa dan subkomponennya. Pendaftaran Dinamik: Gunakan kaedah vue.component () untuk mendaftar selepas komponen dimuatkan.
 Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Pengoptimuman prestasi MySQL perlu bermula dari tiga aspek: konfigurasi pemasangan, pengindeksan dan pengoptimuman pertanyaan, pemantauan dan penalaan. 1. Selepas pemasangan, anda perlu menyesuaikan fail my.cnf mengikut konfigurasi pelayan, seperti parameter innodb_buffer_pool_size, dan tutup query_cache_size; 2. Buat indeks yang sesuai untuk mengelakkan indeks yang berlebihan, dan mengoptimumkan pernyataan pertanyaan, seperti menggunakan perintah menjelaskan untuk menganalisis pelan pelaksanaan; 3. Gunakan alat pemantauan MySQL sendiri (ShowProcessList, ShowStatus) untuk memantau kesihatan pangkalan data, dan kerap membuat semula dan mengatur pangkalan data. Hanya dengan terus mengoptimumkan langkah -langkah ini, prestasi pangkalan data MySQL diperbaiki.
