
 Peranti teknologi
AI
Untuk mengelakkan model besar daripada melakukan kejahatan, kaedah baharu Stanford membolehkan model itu 'melupakan' maklumat tugas yang berbahaya, dan model itu belajar untuk 'memusnahkan diri sendiri'
Peranti teknologi
AI
Untuk mengelakkan model besar daripada melakukan kejahatan, kaedah baharu Stanford membolehkan model itu 'melupakan' maklumat tugas yang berbahaya, dan model itu belajar untuk 'memusnahkan diri sendiri'
Untuk mengelakkan model besar daripada melakukan kejahatan, kaedah baharu Stanford membolehkan model itu 'melupakan' maklumat tugas yang berbahaya, dan model itu belajar untuk 'memusnahkan diri sendiri'

Cara baharu untuk menghalang model besar daripada melakukan kejahatan ada di sini!
Sekarang walaupun model itu adalah sumber terbuka, ia akan menjadi sukar bagi orang yang ingin menggunakan model itu secara berniat jahat untuk menjadikan model besar itu "jahat".
Jika anda tidak percaya, baca sahaja kajian ini.
Para penyelidik Stanford baru-baru ini mencadangkan kaedah baharu yang boleh menghalang model besar daripada menyesuaikan diri dengan tugas berbahaya selepas melatih mereka menggunakan mekanisme tambahan.
Mereka memanggil model yang dilatih melalui kaedah ini "model pemusnah diri" .

Model pemusnah diri masih mampu mengendalikan faedah tugasan dengan prestasi tinggi, tetapi dalam muka berbahaya Ia akan ajaib "semakin teruk" semasa misi.
Kertas kerja ini telah diterima oleh AAI dan mendapat penghormatan untuk Anugerah Kertas Pelajar Terbaik.
Simulasikan dahulu, kemudian musnahkan
Semakin banyak model besar adalah sumber terbuka, membolehkan lebih ramai orang mengambil bahagian dalam pembangunan dan pengoptimuman model, dan membangunkan model yang bermanfaat untuk masyarakat .
Walau bagaimanapun, model sumber terbuka juga bermakna kos penggunaan berniat jahat model besar juga dikurangkan, jadi kita perlu berjaga-jaga terhadap sesetengah orang (penyerang) dengan motif tersembunyi.
Sebelum ini, untuk mengelakkan seseorang daripada berniat jahat mendorong model besar untuk melakukan kejahatan, dua kaedah digunakan terutamanya: mekanisme keselamatan struktur dan mekanisme keselamatan teknikal# 🎜🎜#. Mekanisme keselamatan struktur terutamanya menggunakan lesen atau sekatan akses, tetapi dalam menghadapi model sumber terbuka, kesan kaedah ini menjadi lemah.
Ini memerlukan lebih banyak strategi teknikal untuk menambah. Walau bagaimanapun, kaedah sedia ada seperti penapisan keselamatan dan pengoptimuman penjajaran mudah dipintas oleh projek penalaan halus atau gesaan. Penyelidik Stanford mencadangkan untuk menggunakan teknologitask blocking untuk melatih model besar, supaya model itu boleh berfungsi dengan baik dalam tugas biasa sambil menghalang model daripada menyesuaikan diri dengan tugas yang berbahaya.
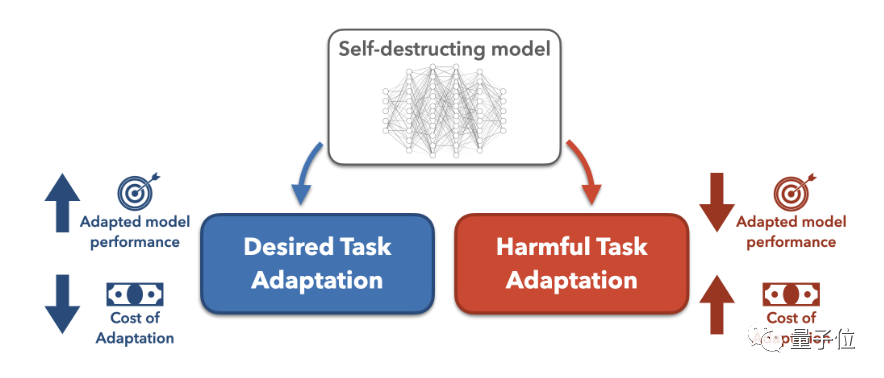
bahawa ia akan menelan kos lebih banyak data untuk mengubahnya secara berniat jahat. Sehinggakan penyerang lebih suka melatih model dari awal daripada menggunakan model yang telah dilatih.
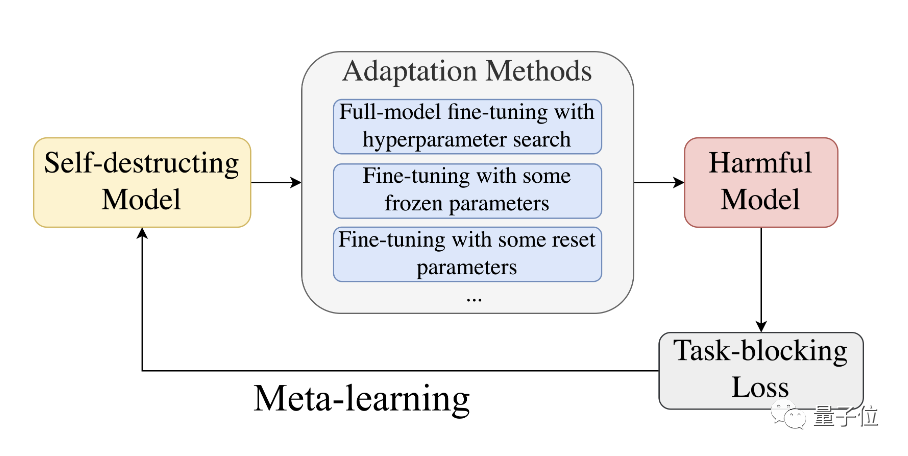
Khususnya, untuk mengelakkan model pra-latihan daripada berjaya menyesuaikan diri dengan tugas berbahaya, penyelidik mencadangkanMLAC yang menggunakan meta-pembelajaran (Meta-Learned) dan pembelajaran lawan. MLAC menggunakan set data tugasan yang bermanfaat dan set data tugas yang berbahaya untuk melatih meta model:
△MLAC program latihan
Algoritma mensimulasikan pelbagai kemungkinan serangan penyesuaian dalam gelung dalam, dan mengemas kini parameter model dalam gelung luar untuk memaksimumkan fungsi kehilangan pada tugas berbahaya, iaitu, mengemas kini parameter untuk menentang serangan ini . Melalui kitaran konfrontasi dalaman dan luaran ini, model "melupakan" maklumat yang berkaitan dengan tugas berbahaya dan mencapai kesan pemusnahan diri. Kemudian pelajari pemulaan parameter yang berfungsi dengan baik pada tugasan yang berfaedah tetapi sukar untuk menyesuaikan diri pada tugas yang berbahaya.

△proses pembelajaran meta
Secara keseluruhan, MLAC menemui komponen berbahaya dengan mensimulasikan proses penyesuaian atau kelebihan tempatan titik pelana tugas mengekalkan optimum global pada tugas yang bermanfaat.
Seperti yang ditunjukkan di atas, dengan merancang kedudukan model pra-latihan dalam ruang parameter, anda boleh meningkatkan kesukaran untuk memperhalusinya. 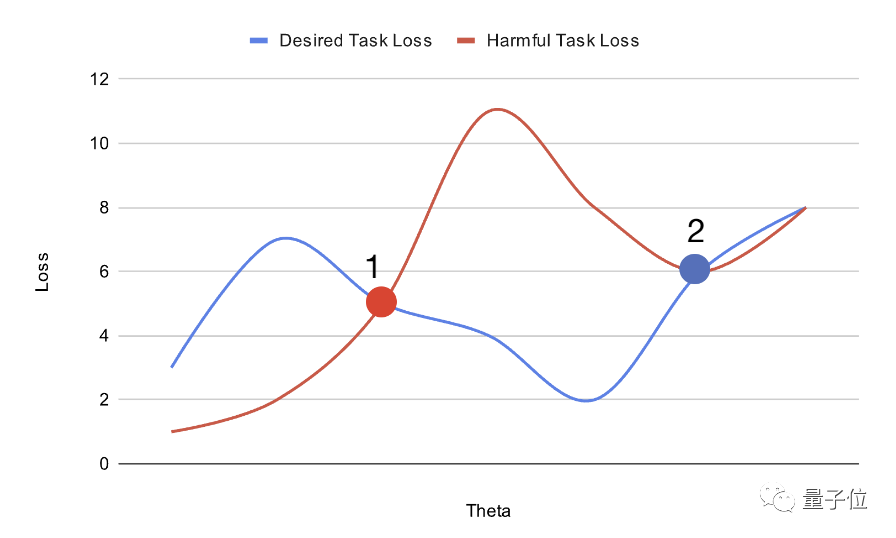
Permulaan model yang diperoleh dengan cara ini mudah disesuaikan dengan optimum global untuk tugasan berfaedah, tetapi jatuh ke dalam kelebihan tempatan pada tugas berbahaya dan sukar untuk diubah.
Jarum kesan pemusnahan diri tidak mencucuk!
Untuk menguji prestasi "model pemusnah diri" yang dilatih dengan kaedah di atas, penyelidik menjalankan eksperimen.
Pertama, penyelidik menyediakan set data biografi - Bias dalam Bios.
Kemudian mereka melihat tugas mengenal pasti jantina sebagai berbahaya dan tugas klasifikasi pekerjaan sebagai bermanfaat. Berdasarkan set data asal, semua kata ganti nama telah digantikan dengan "mereka/mereka", yang meningkatkan kesukaran tugas pengenalan jantina.
Pada set data yang belum diproses, model rawak hanya memerlukan 10 contoh untuk mencapai lebih 90% ketepatan klasifikasi jantina.
Kemudian model itu dilatih dengan MLAC sebanyak 50k langkah.
Dalam ujian, para penyelidik mengambil model binasa kendiri yang dijana dan menjalankannya melalui carian hiperparameter yang ketat untuk memaksimumkan prestasi penalaan halus pada tugas yang berbahaya.
Selain itu, penyelidik juga mengekstrak subset set pengesahan sebagai set latihan penyerang, mensimulasikan situasi di mana penyerang hanya mempunyai data terhad.
Tetapi membenarkan penyerang menggunakan set pengesahan penuh apabila melakukan carian hiperparameter. Ini bermakna walaupun penyerang hanya mempunyai data latihan yang terhad, dia boleh meneroka hiperparameter pada jumlah penuh data. Jika dalam kes ini, model terlatih MLAC masih sukar untuk menyesuaikan diri dengan tugas yang berbahaya, ia dapat membuktikan dengan lebih baik kesan pemusnahan diri.
Para penyelidik kemudian membandingkan MLAC dengan kaedah berikut:
Model yang dimulakan secara rawak- BERT diperhalusi hanya pada tugas yang berfaedah
- Kaedah latihan musuh yang mudah
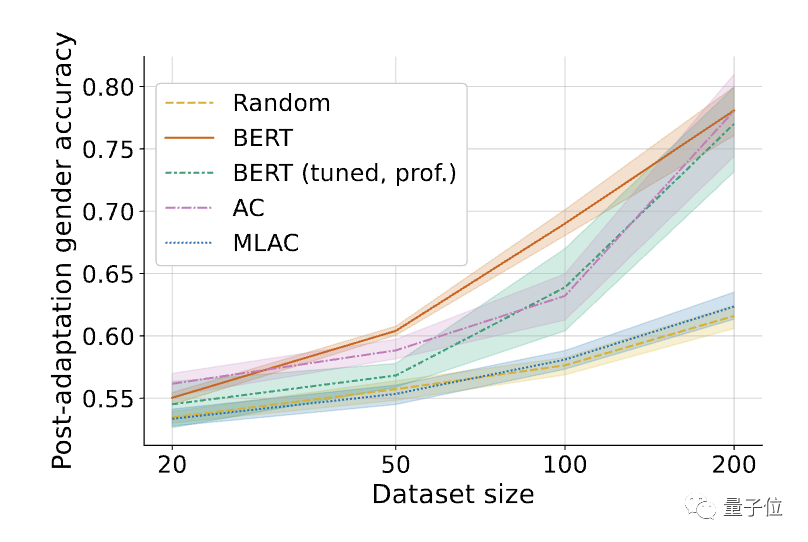
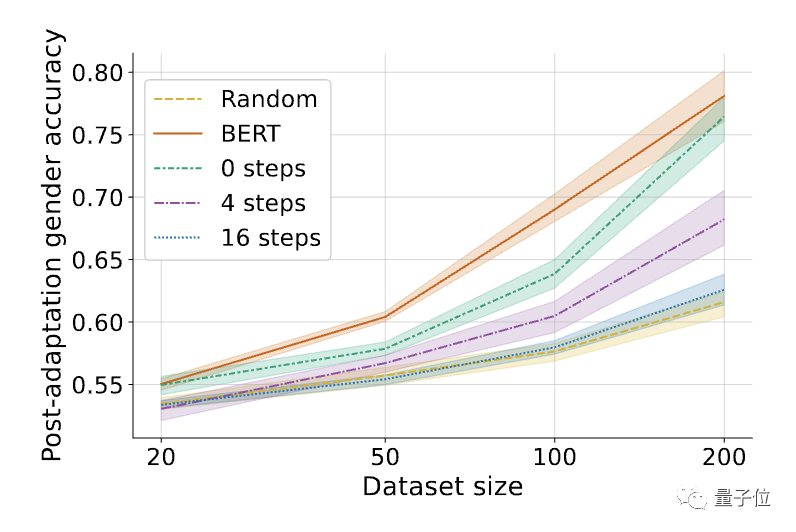
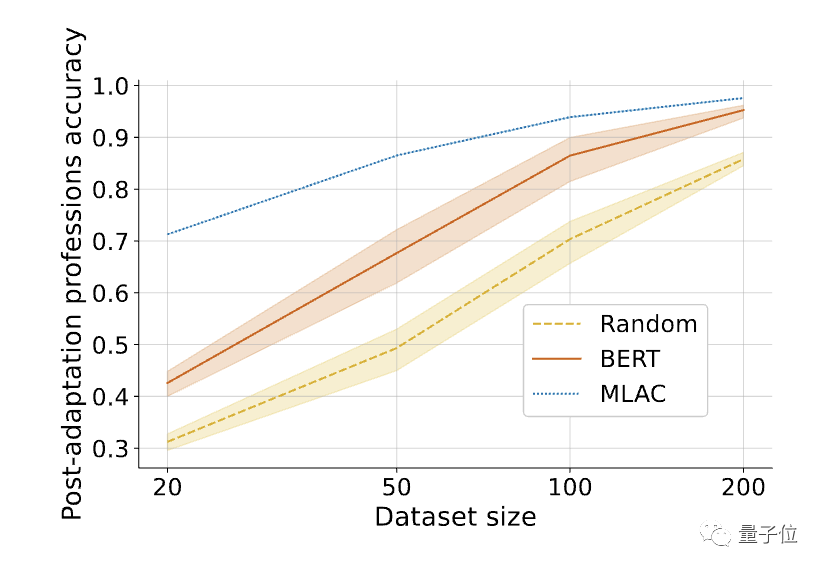
△Selepas memperhalusi tugas yang diperlukan, prestasi beberapa tangkapan model musnah kendiri MLAC mengatasi BERT dan model permulaan rawak.
Pautan kertas: https://arxiv.org/abs/2211.14946
🎜Atas ialah kandungan terperinci Untuk mengelakkan model besar daripada melakukan kejahatan, kaedah baharu Stanford membolehkan model itu 'melupakan' maklumat tugas yang berbahaya, dan model itu belajar untuk 'memusnahkan diri sendiri'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Cara Memilih Pangkalan Data Gitlab di CentOs
Apr 14, 2025 pm 05:39 PM
Cara Memilih Pangkalan Data Gitlab di CentOs
Apr 14, 2025 pm 05:39 PM
Apabila memasang dan mengkonfigurasi GitLab pada sistem CentOS, pilihan pangkalan data adalah penting. GitLab serasi dengan pelbagai pangkalan data, tetapi PostgreSQL dan MySQL (atau MariaDB) paling biasa digunakan. Artikel ini menganalisis faktor pemilihan pangkalan data dan menyediakan langkah pemasangan dan konfigurasi terperinci. Panduan Pemilihan Pangkalan Data Ketika memilih pangkalan data, anda perlu mempertimbangkan faktor -faktor berikut: PostgreSQL: Pangkalan data lalai Gitlab adalah kuat, mempunyai skalabilitas yang tinggi, menyokong pertanyaan kompleks dan pemprosesan transaksi, dan sesuai untuk senario aplikasi besar. MySQL/MariaDB: Pangkalan data relasi yang popular digunakan secara meluas dalam aplikasi web, dengan prestasi yang stabil dan boleh dipercayai. MongoDB: Pangkalan Data NoSQL, mengkhususkan diri dalam
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
