Model bahasa besar (LLM) berasaskan pengubah telah menunjukkan kebolehan berkuasa untuk melaksanakan pembelajaran kontekstual (ICL) dan hampir menjadi satu-satunya pilihan untuk banyak tugas pemprosesan bahasa semula jadi (NLP). Mekanisme perhatian kendiri Transformer membolehkan latihan menjadi sangat selari, membolehkan urutan panjang diproses dengan cara yang diedarkan. Panjang jujukan yang digunakan untuk latihan LLM dipanggil tetingkap konteksnya.
Tetingkap konteks Transformer secara langsung menentukan jumlah ruang di mana contoh boleh disediakan, sekali gus mengehadkan keupayaan ICLnya. Jika tetingkap konteks model adalah terhad, terdapat kurang ruang untuk menyediakan model dengan contoh yang teguh untuk melaksanakan ICL. Tambahan pula, tugas lain seperti meringkaskan juga sangat terhalang apabila tetingkap konteks model sangat pendek. Memandangkan sifat bahasa itu sendiri, lokasi token adalah penting untuk pemodelan yang berkesan, dan perhatian diri tidak secara langsung mengekod maklumat lokasi kerana keselariannya. Seni bina Transformer memperkenalkan pengekodan kedudukan untuk menyelesaikan masalah ini. Senibina Transformer asal menggunakan pengekodan kedudukan sinusoidal mutlak, yang kemudiannya dipertingkatkan menjadi pengekodan kedudukan mutlak yang boleh dipelajari. Sejak itu, skim pengekodan kedudukan relatif telah meningkatkan lagi prestasi Transformer. Pada masa ini, pengekodan kedudukan relatif yang paling popular ialah T5 Relative Bias, RoPE, XPos dan ALiBi. Pengekodan kedudukan mempunyai had berulang: ketidakupayaan untuk membuat generalisasi kepada tetingkap konteks yang dilihat semasa latihan. Walaupun beberapa kaedah seperti ALiBi mempunyai keupayaan untuk melakukan beberapa generalisasi terhad, tiada kaedah yang masih digeneralisasikan kepada jujukan dengan ketara lebih lama daripada panjang pra-latihannya. Terdapat beberapa hasil penyelidikan yang cuba mengatasi batasan ini. Sebagai contoh, sesetengah penyelidikan mencadangkan untuk mengubah suai sedikit RoPE melalui interpolasi kedudukan (PI) dan memperhalusi sejumlah kecil data untuk memanjangkan panjang konteks. Dua bulan lalu, Bowen Peng dari Nous Research berkongsi penyelesaian di Reddit, iaitu melaksanakan "interpolasi sedar NTK" dengan memasukkan kerugian frekuensi tinggi. NTK di sini merujuk kepada Neural Tangent Kernel. Ia mendakwa bahawa RoPE lanjutan NTK-aware boleh mengembangkan tetingkap konteks model LLaMA (lebih daripada 8k) dengan ketara tanpa sebarang penalaan halus dan dengan impak minimum pada kebingungan. Baru-baru ini, kertas kerja berkaitan oleh beliau dan tiga rakan usaha sama lain telah dikeluarkan!
- paper: https://arxiv.org/abs/2309.00071
- model: https://github.com/jquesnelle/yarn
in kertas ini, mereka membuat dua penambahbaikan kepada interpolasi sedar NTK, yang memfokuskan pada aspek berbeza:
- Kaedah interpolasi NTK dinamik, yang boleh digunakan untuk model pra-latihan tanpa penalaan halus.
- Kaedah interpolasi NTK separa, model boleh mencapai prestasi terbaik apabila diperhalusi dengan sejumlah kecil data konteks yang lebih panjang.
Pengkaji mengatakan bahawa sebelum kelahiran kertas kerja ini, sudah ada penyelidik menggunakan interpolasi sedar NTK dan interpolasi NTK dinamik untuk beberapa model sumber terbuka. Contohnya termasuk Kod Llama (yang menggunakan interpolasi sedar NTK) dan Qwen 7B (yang menggunakan interpolasi NTK dinamik). Dalam kertas kerja ini, berdasarkan hasil penyelidikan terdahulu mengenai interpolasi sedar NTK, interpolasi NTK dinamik dan interpolasi NTK separa, penyelidik mencadangkan YaRN (Kaedah sambungan RoPE lain), kaedah yang boleh mengembangkan penggunaan putaran dengan cekap. Kaedah tetingkap konteks model Rotary Position Embeddings (RoPE) boleh digunakan untuk model siri LLaMA, GPT-NeoX dan PaLM. Kajian mendapati bahawa YaRN boleh mencapai prestasi pengembangan tetingkap konteks terbaik pada masa ini dengan hanya menggunakan sampel perwakilan yang kira-kira 0.1% daripada saiz data pra-latihan model asal untuk penalaan halus. Pembenaman Kedudukan Putar (RoPE) pertama kali diperkenalkan oleh kertas "RoFormer: Enhanced transformer with rotary position embedding" dan juga merupakan asas kepada YaRN.Ringkasnya, RoPE boleh ditulis seperti berikut: Untuk LLM pra-latihan dengan panjang konteks tetap, jika interpolasi kedudukan (PI) digunakan untuk memanjangkan panjang konteks, ia boleh dinyatakan sebagai: Dapat dilihat bahawa PI akan sama-sama memanjangkan semua dimensi RoPE. Para penyelidik mendapati bahawa sempadan interpolasi teori yang diterangkan dalam kertas PI tidak mencukupi untuk meramalkan dinamik kompleks antara pembenaman dalaman RoPE dan LLM. Masalah utama PI yang ditemui dan diselesaikan oleh penyelidik akan diterangkan di bawah supaya pembaca dapat memahami latar belakang, punca dan sebab untuk menyelesaikan pelbagai kaedah baru dalam YaRN. . rendah dan benam yang sepadan kekurangan komponen frekuensi tinggi, maka sukar untuk rangkaian saraf dalam mempelajari maklumat frekuensi tinggi. Untuk menyelesaikan masalah kehilangan maklumat frekuensi tinggi apabila membenamkan interpolasi untuk RoPE, Bowen Peng mencadangkan interpolasi sedar NTK dalam siaran Reddit di atas. Pendekatan ini tidak mengembangkan setiap dimensi RoPE secara sama rata, tetapi menyebarkan tekanan interpolasi merentasi berbilang dimensi dengan mengembangkan frekuensi tinggi kurang dan frekuensi rendah lebih banyak. Dalam ujian, penyelidik mendapati pendekatan ini mengatasi prestasi PI dalam menskalakan saiz konteks model tanpa penalaan halus. Walau bagaimanapun, pendekatan ini mempunyai kelemahan utama: memandangkan ia bukan sekadar skema interpolasi, beberapa dimensi diekstrapolasi ke dalam beberapa nilai "luar", jadi penalaan halus menggunakan interpolasi sedar NTK tidak berkesan seperti PI.
Selain itu, disebabkan kewujudan nilai "luar", faktor pengembangan teori tidak dapat menggambarkan dengan tepat tahap pengembangan konteks sebenar. Dalam amalan, untuk sambungan panjang konteks tertentu, nilai sambungan s mesti ditetapkan lebih tinggi sedikit daripada nilai sambungan yang dijangkakan. . - Panjang konteks terbesar yang dilihat semasa latihan (λ > L), menunjukkan bahawa benam dimensi tertentu mungkin diagihkan secara tidak sekata dalam domain yang diputar.
Interpolasi sedar PI dan NTK merawat semua dimensi tersembunyi RoPE secara sama rata (seolah-olah mempunyai kesan yang sama pada rangkaian). Tetapi penyelidik telah mendapati melalui eksperimen bahawa Internet melayan beberapa dimensi secara berbeza daripada dimensi lain. Seperti yang dinyatakan sebelum ini, memandangkan panjang konteks L, beberapa dimensi mempunyai panjang gelombang λ lebih besar daripada atau sama dengan L. Memandangkan apabila panjang gelombang dimensi tersembunyi lebih besar daripada atau sama dengan L, semua pasangan kedudukan akan mengekod jarak tertentu, jadi penyelidik membuat hipotesis bahawa maklumat kedudukan mutlak dikekalkan apabila panjang gelombang lebih pendek, rangkaian hanya boleh mendapatkan relatif maklumat kedudukan.
Apabila meregangkan semua dimensi RoPE menggunakan skala pengembangan s atau nilai perubahan asas b', semua token akan menjadi lebih rapat antara satu sama lain kerana hasil darab titik dua vektor yang diputar dengan jumlah yang lebih kecil akan lebih besar. Sambungan ini boleh menjejaskan keupayaan LLM untuk memahami hubungan tempatan yang kecil antara pembenaman dalamannya. Para penyelidik membuat hipotesis bahawa pemampatan ini akan menyebabkan model menjadi keliru tentang susunan kedudukan token berdekatan, sekali gus menjejaskan keupayaan model.
Untuk menyelesaikan masalah ini, berdasarkan fenomena yang diperhatikan oleh penyelidik, mereka memilih untuk tidak menginterpolasi sama sekali dimensi frekuensi yang lebih tinggi.
Mereka juga mencadangkan bahawa untuk semua dimensi d, dimensi r β tidak diinterpolasi sama sekali (sentiasa diekstrapolasi).
Menggunakan teknik yang diterangkan dalam bahagian ini, kaedah yang dipanggil interpolasi NTK separa telah dilahirkan. Kaedah yang dipertingkatkan ini mengatasi kaedah interpolasi sedar PI dan NTK sebelumnya dan berfungsi untuk kedua-dua model yang tidak ditala dan ditala halus. Oleh kerana kaedah ini mengelakkan ekstrapolasi dimensi di mana domain putaran diagihkan secara tidak sekata, semua masalah penalaan halus kaedah sebelumnya dielakkan. . terdegradasi sepenuhnya pada keseluruhan saiz konteks apabila ia melebihi nilai yang diperlukan.
Dalam kaedah NTK dinamik, sambungan s dikira secara dinamik. Semasa proses inferens, apabila saiz konteks melebihi, darjah pengembangan s ditukar secara dinamik, yang membolehkan semua model perlahan-lahan merosot apabila mencapai had konteks latihan L dan bukannya ranap secara tiba-tiba. . Secara intuitif, ini nampaknya tidak menjadi masalah, kerana jarak global tidak memerlukan ketepatan yang tinggi untuk membezakan kedudukan token (iaitu rangkaian hanya perlu mengetahui secara kasar sama ada token berada di permulaan, tengah atau penghujung jujukan). Walau bagaimanapun, penyelidik mendapati bahawa oleh kerana jarak minimum purata menjadi lebih dekat apabila bilangan token meningkat, ia akan menjadikan pengagihan softmax perhatian lebih tajam (iaitu, mengurangkan purata entropi perhatian softmax) . Dalam erti kata lain, apabila kesan pengecilan jarak jauh dikurangkan dengan interpolasi, rangkaian "memberi lebih perhatian" kepada lebih banyak token. Peralihan dalam pengedaran ini boleh menyebabkan kemerosotan dalam kualiti keluaran LLM, yang merupakan satu lagi isu yang tidak berkaitan dengan soalan sebelumnya. Memandangkan entropi dalam taburan softmax perhatian berkurangan apabila menginterpolasi pembenaman RoPE kepada saiz konteks yang lebih panjang, kami berhasrat untuk membalikkan penurunan entropi ini (iaitu meningkatkan "suhu" logit perhatian ). Ini boleh dilakukan dengan mendarabkan matriks perhatian perantaraan dengan suhu t > 1 sebelum menggunakan softmax, tetapi memandangkan pembenaman RoPE dikodkan sebagai matriks putaran, adalah mungkin untuk memanjangkan panjang benam RoPE dengan faktor malar √t. . Teknik "perluasan panjang" ini membolehkan penyelidikan tanpa mengubah suai kod perhatian, yang sangat memudahkan penyepaduan dengan saluran paip latihan dan inferens sedia ada dan mempunyai kerumitan masa hanya O(1).
Memandangkan skim interpolasi RoPE ini berinterpolasi secara tidak sekata merentas dimensi RoPE, adalah sukar untuk mengira penyelesaian analitik untuk skala suhu yang diperlukan t berkenaan dengan tahap pengembangan s. Nasib baik, penyelidik menemui melalui eksperimen bahawa dengan meminimumkan kebingungan, semua model LLaMA mengikut kira-kira lengkung pemasangan yang sama:
Para penyelidik menemui formula ini pada LLaMA 7B, 13B, 33B dan 65B . Mereka mendapati bahawa formula ini juga berfungsi dengan baik untuk model LLaMA 2 (7B, 13B dan 70B), dengan perbezaan yang ketara. Ini menunjukkan bahawa sifat peningkatan entropi ini adalah biasa dan digeneralisasikan kepada model dan data latihan yang berbeza.
Pengubahsuaian akhir ini menghasilkan kaedah YaRN. Kaedah baharu mengatasi semua kaedah sebelumnya dalam kedua-dua senario yang diperhalusi dan tidak ditala tanpa memerlukan sebarang pengubahsuaian pada kod inferens. Hanya algoritma yang digunakan untuk menjana pembenaman RoPE pada mulanya perlu diubah suai. YaRN adalah sangat mudah sehingga ia boleh dilaksanakan dengan mudah dalam semua inferens dan perpustakaan latihan, termasuk keserasian dengan Flash Attention 2.
Eksperimen
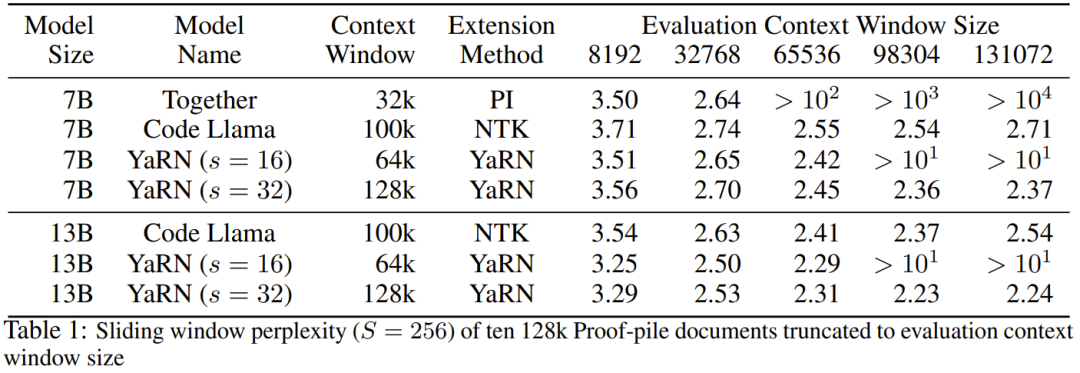
Percubaan menunjukkan bahawa YaRN berjaya mengembangkan tetingkap konteks LLM. Tambahan pula, mereka mencapai keputusan ini selepas latihan untuk hanya 400 langkah, iaitu kira-kira 0.1% daripada korpus pra-latihan asal model dan penurunan yang ketara daripada kerja sebelumnya. Ini menunjukkan bahawa kaedah baharu ini sangat cekap dari segi pengiraan dan tidak mempunyai kos inferens tambahan. Untuk menilai model yang terhasil, penyelidik mengira kebingungan dokumen panjang dan menjaringkannya pada penanda aras sedia ada, dan mendapati kaedah baharu itu mengatasi semua kaedah pengembangan tetingkap konteks yang lain. Pertama, penyelidik menilai prestasi model apabila tetingkap konteks ditingkatkan. Jadual 1 meringkaskan keputusan eksperimen.
Jadual 2 menunjukkan kekeliruan terakhir pada 50 dokumen GovReport yang tidak ditapis (sekurang-kurangnya 16k token panjangnya).
Untuk menguji kemerosotan prestasi model apabila menggunakan sambungan konteks, penyelidik menilai model menggunakan suite Papan Pendahulu LLM Terbuka Memeluk Wajah dan membandingkannya dengan model garis dasar LLaMA 2 dan model PI dan NTK-aware yang tersedia untuk umum. Terdapat markah yang dibandingkan. Jadual 3 meringkaskan keputusan eksperimen.
Atas ialah kandungan terperinci Jika anda mahu model besar mempelajari lebih banyak contoh dengan segera, kaedah ini membolehkan anda memasukkan lebih banyak aksara. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!




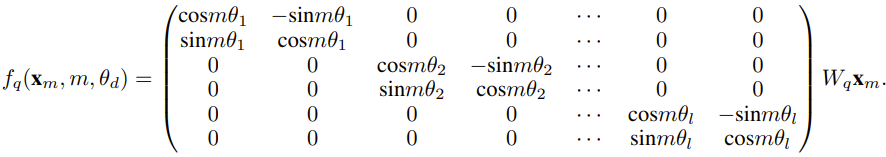
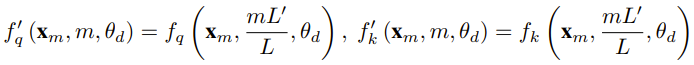
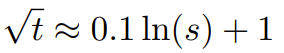
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



