
 Peranti teknologi
AI
Andrew Ng sukakannya! Sarjana Harvard dan MIT menggunakan catur untuk membuktikan bahawa model bahasa besar memang 'memahami' dunia
Peranti teknologi
AI
Andrew Ng sukakannya! Sarjana Harvard dan MIT menggunakan catur untuk membuktikan bahawa model bahasa besar memang 'memahami' dunia
Andrew Ng sukakannya! Sarjana Harvard dan MIT menggunakan catur untuk membuktikan bahawa model bahasa besar memang 'memahami' dunia

Pada tahun 2021, ahli bahasa Universiti Washington, Emily M. Bender menerbitkan kertas kerja dengan alasan bahawa model bahasa besar tidak lebih daripada "burung kakak tua stokastik". secara rawak menjana perkataan yang kelihatan munasabah seperti burung kakak tua.
Disebabkan rangkaian saraf yang tidak dapat ditafsirkan, komuniti akademik tidak pasti sama ada model bahasa itu burung nuri rawak, dan pendapat pelbagai pihak sangat berbeza.
Disebabkan kekurangan ujian yang diiktiraf secara meluas, sama ada model boleh "memahami dunia" telah menjadi persoalan falsafah dan bukannya persoalan saintifik.
Baru-baru ini, penyelidik dari Universiti Harvard dan MIT bersama-sama menerbitkan kajian baharu Othello-GPT, yang mengesahkan keberkesanan perwakilan dalaman dalam permainan papan mudah Mereka percaya bahawa perwakilan dalaman model bahasa sememangnya telah dicipta model dunia, bukan sekadar ingatan atau statistik mudah, tetapi sumber keupayaannya masih tidak jelas.

Pautan kertas: https://arxiv.org/pdf/2210.13382.pdf
Tanpa pengetahuan awal tentang peraturan Othello, penyelidik boleh Predict bahawa model itu langkah undang-undang dan menangkap keadaan lembaga dengan ketepatan yang sangat tinggi.
Andrew Ng menyatakan pengiktirafan tinggi untuk penyelidikan ini dalam lajur "Surat" Beliau percaya bahawa berdasarkan penyelidikan ini, terdapat sebab untuk mempercayai bahawa model bahasa berskala besar telah membina model dunia yang cukup kompleks, dan sedikit sebanyak. , memahami dunia.
Pautan blog: https://www.deeplearning.ai/the-batch/does-ai-understand-the-world/
Namun, Andrew Ng juga berkata walaupun falsafah itu penting, ini Perdebatan mungkin akan berterusan selama-lamanya, jadi mari kita ke pengaturcaraan!
Model Dunia Papan Catur
Jika anda membayangkan papan catur sebagai "dunia" yang mudah dan memerlukan model membuat keputusan berterusan semasa permainan, anda boleh menguji pada mulanya sama ada model jujukan boleh mempelajari perwakilan dunia.

Para penyelidik memilih permainan Othello yang mudah, Othello, sebagai platform percubaan bergilir-gilir untuk membuat gerakan Dalam arah lurus atau pepenjuru, semua kepingan musuh (tidak termasuk ruang) di antara dua bahagian sebelah sendiri semuanya akan menjadi kepingan seseorang (dipanggil potongan tangkapan pada akhirnya). , lembaga akan diduduki sepenuhnya, yang mempunyai lebih ramai anak lelaki menang.
Berbanding dengan catur, peraturan Othello jauh lebih mudah pada masa yang sama, ruang carian permainan catur cukup besar sehingga model tidak dapat melengkapkan penjanaan urutan melalui ingatan, jadi ia sangat sesuai untuk menguji perwakilan dunia; keupayaan pembelajaran model.
Model Bahasa Othello
Para penyelidik mula-mula melatih versi varian GPT bagi model bahasa (Othello-GPT), memasukkan skrip permainan (satu siri operasi pergerakan catur yang dibuat oleh pemain) ke dalam model, tetapi model tidak mempunyai maklumat tentang Pengetahuan terdahulu tentang permainan dan peraturan yang berkaitan.
Model ini tidak dilatih secara eksplisit untuk meneruskan peningkatan strategi, memenangi permainan, dsb., tetapi mempunyai ketepatan yang agak tinggi apabila menjana operasi pergerakan Othello yang sah.
Dataset
Para penyelidik menggunakan dua set data latihan:
Kejuaraan (Kejuaraan) lebih menumpukan pada kualiti data, terutamanya yang diterima pakai daripada kejohanan strategik manusia yang profesional langkah, tetapi masing-masing hanya 7605 dan 132921 sampel permainan Selepas dua set data digabungkan, mereka dibahagikan secara rawak kepada set latihan (20 juta sampel) dan set pengesahan (3.796 juta sampel) pada nisbah 8:2. ).
Sintetik memberi lebih perhatian kepada skala data dan terdiri daripada operasi pergerakan rawak dan undang-undang Pengedaran data berbeza daripada set data kejuaraan, tetapi diambil secara sama rata daripada pokok permainan Othello, dengan 20 juta sampel digunakan latihan dan 3.796 juta sampel untuk pengesahan.
Penerangan setiap permainan terdiri daripada rentetan token, dan saiz perbendaharaan kata ialah 60 (8*8-4)
Model dan latihan
Seni bina model ialah 8 lapisan Model GPT dengan 8 kepala , dimensi tersembunyi ialah 512
Berat model dimulakan sepenuhnya secara rawak, termasuk lapisan pembenaman perkataan Walaupun terdapat hubungan geometri dalam senarai perkataan yang mewakili kedudukan papan catur (seperti C4 lebih rendah daripada B4), bias induktif ini tidak dinyatakan dengan jelas, tetapi diserahkan kepada model untuk belajar.
Ramalkan langkah undang-undang
Penunjuk penilaian utama model ialah sama ada operasi pergerakan yang diramalkan oleh model mematuhi peraturan Othello.
Othello-GPT yang dilatih pada set data sintetik mempunyai kadar ralat 0.01% dan pada set data kejuaraan kadar ralat 5.17%, berbanding dengan kadar ralat 93.29% untuk Othello-GPT yang tidak terlatih, iaitu , kedua-dua set data ini membolehkan model mempelajari peraturan permainan pada tahap tertentu.
Satu penjelasan yang mungkin ialah model itu mengingati semua operasi pergerakan permainan Othello.
Untuk menguji tekaan ini, para penyelidik mensintesis set data baharu: pada permulaan setiap permainan, Othello mempunyai empat kemungkinan kedudukan pembukaan (C5, D6, E3 dan F4), dan semua bukaan C5 Selepas mengalih keluar pergerakan, ia digunakan sebagai set latihan, dan kemudian data pembukaan C5 digunakan sebagai ujian, iaitu hampir 1/4 pokok permainan telah dialih keluar Didapati kadar ralat model masih 0.02% sahaja
. Jadi Othello-GPT Prestasi tinggi bukan disebabkan oleh ingatan, kerana data ujian benar-benar tidak kelihatan semasa proses latihan Jadi apa sebenarnya yang membuatkan model itu berjaya meramalkan?
Teroka perwakilan dalaman
Alat yang biasa digunakan untuk mengesan perwakilan dalaman rangkaian saraf ialah probe Setiap probe ialah pengelas atau regressor yang inputnya terdiri daripada pengaktifan dalaman rangkaian dan dilatih untuk Meramalkan ciri yang diminati.
Dalam tugasan ini, untuk mengesan sama ada pengaktifan dalaman Othello-GPT mengandungi perwakilan keadaan papan catur semasa, selepas memasukkan urutan pergerakan, vektor pengaktifan dalaman digunakan untuk meramalkan langkah pergerakan seterusnya.
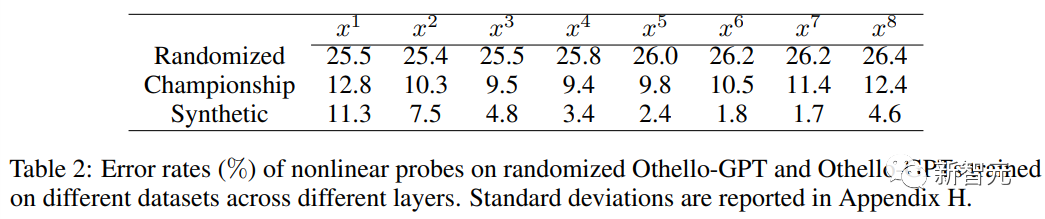
Apabila menggunakan probe linear, perwakilan dalaman Othello-GPT terlatih hanya lebih tepat sedikit daripada tekaan rawak.

Apabila menggunakan probe tak linear (MLP dua lapisan), kadar ralat menurun dengan ketara, membuktikan bahawa keadaan papan tidak disimpan dalam pengaktifan rangkaian dengan cara yang mudah.
Eksperimen Intervensi
Untuk menentukan hubungan sebab akibat antara ramalan model dan perwakilan dunia yang muncul, iaitu, sama ada keadaan lembaga memang mempengaruhi keputusan ramalan rangkaian, penyelidik menjalankan satu set eksperimen intervensi dan Mengukur hasil kesan.
Memandangkan satu set pengaktifan daripada Othello-GPT, gunakan probe untuk meramalkan keadaan papan, merekodkan ramalan pergerakan yang berkaitan, dan kemudian mengubah suai pengaktifan untuk membenarkan kuar meramalkan keadaan papan yang dikemas kini.
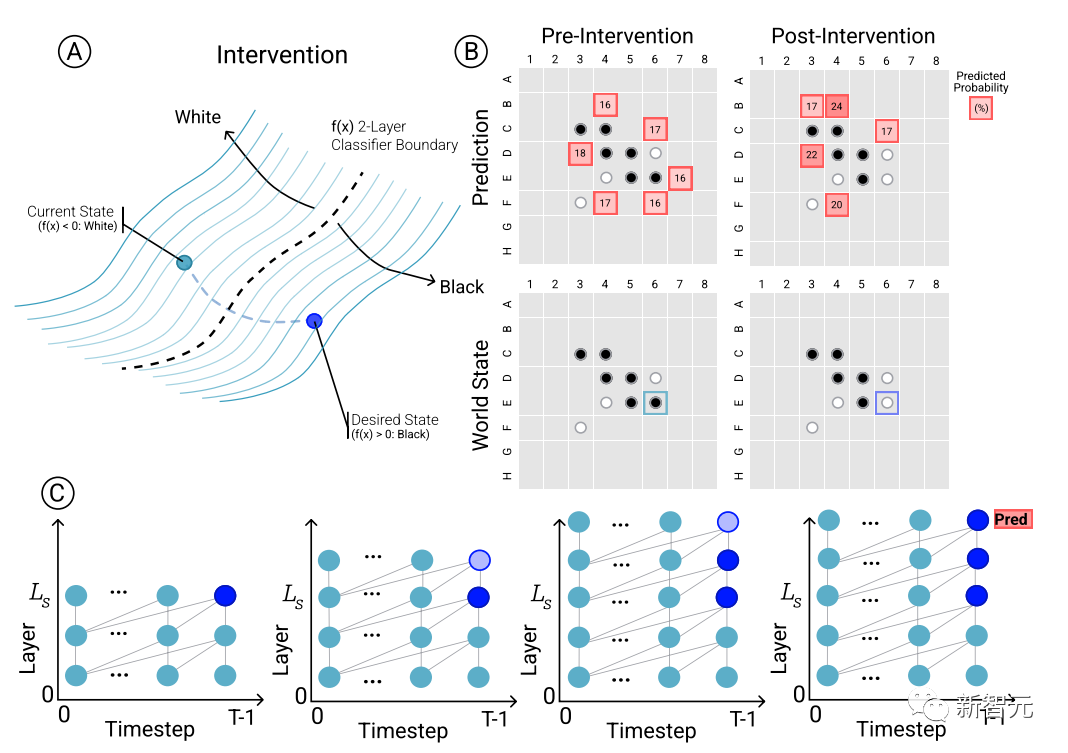
Operasi intervensi termasuk menukar buah catur dalam kedudukan tertentu daripada putih kepada hitam, dsb. Pengubahsuaian kecil akan menyebabkan keputusan model mendapati bahawa perwakilan dalaman boleh melengkapkan ramalan dengan pasti, iaitu, terdapat jurang antara perwakilan dalaman dan ramalan model.
Visualisasi
Selain eksperimen intervensi untuk mengesahkan keberkesanan perwakilan dalaman, penyelidik juga memvisualisasikan hasil ramalan Sebagai contoh, untuk setiap buah catur pada papan catur, model boleh ditanya sama ada teknologi intervensi digunakan untuk menukar buah catur Bagaimana keputusan yang diramalkan akan berubah sepadan dengan kepentingan keputusan yang diramalkan.
Kemudian kad diwarnakan dan divisualisasikan berdasarkan ketonjolan yang diramalkan oleh top1 keadaan papan catur semasa Oleh kerana peta yang dilukis adalah input berdasarkan ruang terpendam rangkaian, ia juga boleh dipanggil peta ketonjolan terpendam.

Adalah dapat dilihat bahawa corak yang jelas dipamerkan dalam peta kepentingan terpendam bagi ramalan 1 teratas Othello-GPT yang dilatih pada set data sintetik dan kejuaraan.
Versi sintetik Othello-GPT menunjukkan nilai kepentingan yang lebih tinggi dalam kedudukan operasi yang sah, manakala nilai kepentingan operasi haram adalah jauh lebih rendah Malah pemain catur yang mempunyai sedikit pengalaman dapat melihat niat model tersebut
Peta saliency versi kejohanan adalah lebih kompleks Walaupun nilai saliency bagi kedudukan operasi undang-undang adalah agak tinggi, kedudukan lain juga menunjukkan saliency yang lebih tinggi.
Atas ialah kandungan terperinci Andrew Ng sukakannya! Sarjana Harvard dan MIT menggunakan catur untuk membuktikan bahawa model bahasa besar memang 'memahami' dunia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1385
1385
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Panduan Lengkap untuk Melihat Log Gitlab Di bawah Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk melihat pelbagai log Gitlab dalam sistem CentOS, termasuk log utama, log pengecualian, dan log lain yang berkaitan. Sila ambil perhatian bahawa laluan fail log mungkin berbeza -beza bergantung pada versi GitLab dan kaedah pemasangan. Jika laluan berikut tidak wujud, sila semak fail Direktori Pemasangan dan Konfigurasi GitLab. 1. Lihat log Gitlab utama Gunakan arahan berikut untuk melihat fail log utama aplikasi GitLabRails: Perintah: Sudocat/var/Log/Gitlab/Gitlab-Rails/Production.log Perintah ini akan memaparkan produk
 Cara Memilih Pangkalan Data Gitlab di CentOs
Apr 14, 2025 pm 05:39 PM
Cara Memilih Pangkalan Data Gitlab di CentOs
Apr 14, 2025 pm 05:39 PM
Apabila memasang dan mengkonfigurasi GitLab pada sistem CentOS, pilihan pangkalan data adalah penting. GitLab serasi dengan pelbagai pangkalan data, tetapi PostgreSQL dan MySQL (atau MariaDB) paling biasa digunakan. Artikel ini menganalisis faktor pemilihan pangkalan data dan menyediakan langkah pemasangan dan konfigurasi terperinci. Panduan Pemilihan Pangkalan Data Ketika memilih pangkalan data, anda perlu mempertimbangkan faktor -faktor berikut: PostgreSQL: Pangkalan data lalai Gitlab adalah kuat, mempunyai skalabilitas yang tinggi, menyokong pertanyaan kompleks dan pemprosesan transaksi, dan sesuai untuk senario aplikasi besar. MySQL/MariaDB: Pangkalan data relasi yang popular digunakan secara meluas dalam aplikasi web, dengan prestasi yang stabil dan boleh dipercayai. MongoDB: Pangkalan Data NoSQL, mengkhususkan diri dalam
