
 pembangunan bahagian belakang
C++
Cetak semua perkataan tidak berulang dalam dua ayat yang diberikan
pembangunan bahagian belakang
C++
Cetak semua perkataan tidak berulang dalam dua ayat yang diberikan
Cetak semua perkataan tidak berulang dalam dua ayat yang diberikan


Dalam tutorial ini, kami akan mengenal pasti dan mencetak semua perkataan tidak berulang dalam dua ayat yang diberikan. Perkataan tidak berulang merujuk kepada perkataan yang muncul sekali sahaja dalam dua ayat, iaitu tidak muncul berulang kali dalam ayat lain. Tugasan ini melibatkan menganalisis ayat input, mengenal pasti perkataan individu, dan membandingkan dua ayat untuk mencari perkataan yang muncul sekali sahaja. Outputnya mestilah senarai semua perkataan ini. Tugas ini boleh dicapai melalui pelbagai kaedah pengaturcaraan, seperti menggunakan gelung, tatasusunan atau kamus.
Kaedah
Berikut ialah dua cara untuk mencetak semua perkataan tidak berulang dalam dua ayat yang diberikan−
Kaedah 1: Gunakan kamus
Kaedah 2: Menggunakan Koleksi
Kaedah 1: Gunakan kamus
Menggunakan kamus, hitung bilangan kali setiap perkataan muncul dalam dua frasa. Kami kemudian boleh mencari kamus dan mencetak semua perkataan yang muncul sekali sahaja. Fungsi Kamus dalam C++ biasanya digunakan untuk mengeluarkan semua perkataan unik dalam dua ayat tertentu. Kaedah ini melibatkan penggunaan kamus atau struktur data jadual cincang untuk menyimpan kekerapan setiap perkataan dalam dua frasa. Kami kemudiannya boleh mengulangi kamus dan mencetak istilah yang muncul sekali sahaja.
Tatabahasa
Berikut ialah sintaks tanpa kod sebenar untuk mencetak semua perkataan bukan pendua dalam dua ayat yang diberikan menggunakan kaedah kamus dalam C++ -
Isytiharkan kamus untuk menyimpan frekuensi perkataan
map<string, int> freqDict;
Masukkan dua ayat sebagai rentetan
string sentence1 = "first sentence"; string sentence2 = "second sentence";
Pisah ayat kepada perkataan dan masukkan ke dalam kamus
istringstream iss (sentence1 + " " + sentence2);
string word;
while (iss >> word) {
freqDict[word]++;
}
Gelung kamus dan cetak perkataan unik
for (const auto& [word, frequency]: freqDict) {
if (frequency == 1) {
cout << word << " ";
}
}
Algoritma
Dalam C++, ini adalah helah untuk menggunakan kaedah kamus untuk mencetak langkah demi langkah semua item unik dalam dua ayat yang ditentukan -
Langkah 1 - Buat dua rentetan s1 dan s2 yang mengandungi ayat.
Langkah 2 - Isytiharkan rentetan peta tidak tertib kosong, int> untuk merekodkan kekerapan setiap perkataan dalam ayat.
Langkah 3 − Gunakan kelas aliran rentetan C++ untuk menghuraikan dua frasa untuk mengeluarkan perkataan.
Langkah 4 - Untuk setiap perkataan yang diekstrak, semak sama ada ia muncul dalam kamus. Jika ya, tingkatkan kekerapannya sebanyak satu. Jika tidak, tambahkannya pada kamus dengan kekerapan 1.
Langkah 5 - Selepas memproses kedua-dua ayat, ulangi kamus dan paparkan semua istilah dengan kekerapan 1. Ini adalah perkataan yang tidak diulang dalam dua ayat.
Langkah 6 − Kerumitan masa kaedah ini ialah O(n),
Terjemahan bahasa Cina bagiContoh 1
ialah:Contoh 1
Kod ini menggunakan peta tidak tertib untuk menyimpan kekerapan setiap perkataan dalam frasa gabungan. Ia kemudian menggelung melalui peta, menambah setiap perkataan yang muncul sekali sahaja pada vektor perkataan tidak berulang. Akhirnya, ia menerbitkan perkataan bukan pendua. Contoh ini membayangkan bahawa dua ayat dikodkan keras ke dalam atur cara dan bukannya dimasukkan oleh pengguna.
#include <iostream>
#include <string>
#include <unordered_map>
#include <sstream>
#include <vector>
using namespace std;
vector<string> getNonRepeatingWords(string sentence1, string sentence2) {
// Combine the two sentences into a single string
string combined = sentence1 + " " + sentence2;
// Create a map to store the frequency of each word
unordered_map<string, int> wordFreq;
// Use a string stream to extract each word from the combined string
stringstream ss(combined);
string word;
while (ss >> word) {
// Increment the frequency of the word in the map
wordFreq[word]++;
}
// Create a vector to store the non-repeating words
vector<string> nonRepeatingWords;
for (auto& pair : wordFreq) {
if (pair.second == 1) {
nonRepeatingWords.push_back(pair.first);
}
}
return nonRepeatingWords;
}
int main() {
string sentence1 = "The quick brown fox jumps over the lazy dog";
string sentence2 = "A quick brown dog jumps over a lazy fox";
vector<string> nonRepeatingWords = getNonRepeatingWords(sentence1, sentence2);
// Print the non-repeating words
for (auto& word : nonRepeatingWords) {
cout << word << " ";
}
cout << endl;
return 0;
}
Output
a A the The
Kaedah 2: Menggunakan Koleksi
Strategi ini melibatkan penggunaan set untuk mencari istilah yang muncul sekali sahaja dalam dua frasa. Kita boleh membina set istilah untuk setiap frasa dan kemudian mengenal pasti persilangan set ini. Akhir sekali, kita boleh mengulangi persimpangan dan mengeluarkan semua item yang muncul sekali sahaja.
Koleksi ialah bekas bersekutu yang menyimpan elemen berbeza dalam susunan yang disusun. Kami boleh memasukkan istilah daripada kedua-dua frasa ke dalam koleksi dan sebarang pendua akan dialih keluar secara automatik.
Tatabahasa
Sudah tentu! Berikut ialah sintaks yang boleh anda gunakan dalam Python untuk mencetak semua perkataan tidak berulang dalam dua ayat yang diberikan −
Takrifkan dua ayat sebagai rentetan
sentence1 = "The fox jumps over dog" sentence2 = "A dog jumps over fox"
Pisah setiap ayat kepada senarai perkataan
words1 = sentence1.split() words2 = sentence2.split()
Buat satu set daripada dua senarai perkataan ini
set1 = set(words1) set2 = set(words2)
Cari perkataan unik melalui persilangan set
Nonrepeating = set1.symmetric_difference(set2)
Cetak perkataan unik
for word in non-repeating: print(word)
Algoritma
Ikut arahan di bawah untuk mengeluarkan semua perkataan bukan pendua dalam dua ayat yang diberikan menggunakan fungsi agregat dalam C++ -
Langkah 1 - Buat dua pembolehubah rentetan untuk menyimpan dua ayat.
Langkah 2 - Menggunakan perpustakaan aliran rentetan, bahagikan setiap ayat kepada perkataan individu dan simpannya dalam dua tatasusunan berasingan.
Langkah 3 - Buat dua set, satu untuk setiap ayat, untuk menyimpan perkataan unik.
Langkah 4 - Gelung setiap susunan perkataan dan masukkan setiap perkataan ke dalam set yang betul.
Langkah 5 - Gelung setiap set dan cetak perkataan bukan pendua.
Terjemahan bahasa Cina bagiContoh 2
ialah:Contoh 2
Dalam kod ini, kami menggunakan perpustakaan aliran rentetan untuk memisahkan setiap ayat kepada perkataan yang berasingan. Kami kemudian menggunakan dua koleksi, uniqueWords1 dan uniqueWords2, untuk menyimpan perkataan unik dalam setiap ayat. Akhir sekali, kami mengulangi setiap set dan mencetak perkataan bukan pendua.
#include <iostream>
#include <string>
#include <sstream>
#include <set>
using namespace std;
int main() {
string sentence1 = "This is the first sentence.";
string sentence2 = "This is the second sentence.";
string word;
stringstream ss1(sentence1);
stringstream ss2(sentence2);
set<string> uniqueWords1;
set<string> uniqueWords2;
while (ss1 >> word) {
uniqueWords1.insert(word);
}
while (ss2 >> word) {
uniqueWords2.insert(word);
}
cout << "Non-repeating words in sentence 1:" << endl;
for (const auto& w : uniqueWords1) {
if (uniqueWords2.find(w) == uniqueWords2.end()) {
cout << w << " ";
}
}
cout << endl;
cout << "Non-repeating words in sentence 2:" << endl;
for (const auto& w : uniqueWords2) {
if (uniqueWords1.find(w) == uniqueWords1.end()) {
cout << w << " ";
}
}
cout << endl;
return 0;
}
输出
Non-repeating words in sentence 1: first Non-repeating words in sentence 2: second
结论
总之,从两个提供的句子中打印所有非重复单词的任务是通过使用各种编程方法来实现的,例如将句子分解为单个单词,利用字典来量化每个单词的频率,以及过滤掉非重复单词。生成的非重复单词集合可以报告给控制台或保存在列表或数组中以供进一步使用。这项工作对于基本的编程文本操作和数据结构操作很有帮助。Atas ialah kandungan terperinci Cetak semua perkataan tidak berulang dalam dua ayat yang diberikan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 Bagaimana untuk membalas komen Tiktok dengan kecerdasan emosi yang tinggi? Apakah ayat untuk membalas komen TikTok?
Mar 23, 2024 pm 07:50 PM
Bagaimana untuk membalas komen Tiktok dengan kecerdasan emosi yang tinggi? Apakah ayat untuk membalas komen TikTok?
Mar 23, 2024 pm 07:50 PM
Dalam masyarakat moden, ramai orang gembira menunjukkan kehidupan mereka dan meluahkan emosi peribadi di platform Douyin, dan perbincangan di kawasan komen sering mencetuskan perbincangan hangat. Cara membalas komen Douyin secara EQ tinggi telah menjadi tumpuan ramai orang. 1. Bagaimana untuk bertindak balas terhadap komen Douyin dengan kecerdasan emosi yang tinggi? Bersikap sopan dan hormat adalah prinsip asas komunikasi Internet. Walaupun anda tidak bersetuju, balas dengan sopan. Dengan menyatakan rasa terima kasih dan bersedia untuk berkomunikasi, anda boleh mewujudkan suasana komunikasi yang baik. Menunjukkan pemahaman dan empati adalah penting, terutamanya apabila pengulas mengalami kesukaran atau kekecewaan. Satu cara untuk menyatakan empati dan pemahaman ialah: "Saya faham kesukaran yang anda alami, saya harap anda dapat mencari jalan untuk menyelesaikan masalah anda, dan saya akan cuba sedaya upaya untuk membantu anda melaluinya."
 Cara menggunakan Microsoft Reader Coach dengan Immersive Reader
Mar 09, 2024 am 09:34 AM
Cara menggunakan Microsoft Reader Coach dengan Immersive Reader
Mar 09, 2024 am 09:34 AM
Dalam artikel ini, kami akan menunjukkan kepada anda cara menggunakan Microsoft Reading Coach dalam Immersive Reader pada Windows PC. Ciri panduan membaca membantu pelajar atau individu berlatih membaca dan mengembangkan kemahiran literasi mereka. Anda bermula dengan membaca petikan atau dokumen dalam aplikasi yang disokong, dan berdasarkan ini, laporan bacaan anda dijana oleh alat Jurulatih Membaca. Laporan bacaan menunjukkan ketepatan bacaan anda, masa yang anda ambil untuk membaca, bilangan perkataan yang betul setiap minit dan perkataan yang anda rasa paling mencabar semasa membaca. Anda juga akan dapat mempraktikkan perkataan, yang akan membantu mengembangkan kemahiran membaca anda secara umum. Pada masa ini, hanya Office atau Microsoft365 (termasuk OneNote untuk Web dan Word untuk Kami
 Bagaimanakah saya boleh mula menghafal perkataan semula apabila saya menghafalnya dengan dakwat? Kongsi kaedah menghafal perkataan dan menghafal semula perkataan dalam Mo Mo!
Mar 15, 2024 pm 03:28 PM
Bagaimanakah saya boleh mula menghafal perkataan semula apabila saya menghafalnya dengan dakwat? Kongsi kaedah menghafal perkataan dan menghafal semula perkataan dalam Mo Mo!
Mar 15, 2024 pm 03:28 PM
Adakah anda ingin tahu tentang cara mula menghafal perkataan semula apabila Mo Mo menghafalnya? Mo Mo Bei Vocabulary ialah perisian pembelajaran perkataan bahasa Inggeris yang sangat mudah digunakan Pengguna boleh memilih perpustakaan perbendaharaan kata bahasa Inggeris untuk pembelajaran bahasa Inggeris berdasarkan tahap bahasa Inggeris mereka dan niat pembelajaran mereka juga boleh menggunakan contoh, mnemonik dan kaedah lain untuk lebih memahami dan menghafal perkataan. Ada rakan-rakan yang sudah habis menghafal kosa kata dan ingin mula menghafal buku kosa kata yang sama semula, tetapi tidak tahu bagaimana caranya? Hari ini, editor telah menyusun kaedah untuk menghafal perkataan dan menghafal semula perkataan untuk anda semua! Datang dan muat turun jika ia membantu anda! 1. Bagaimanakah saya boleh mula menghafal perkataan semula? Kongsi kaedah menghafal perkataan dan menghafal semula perkataan dalam Mo Mo! 1. Buka apl Mo Mo Bei Vocabulary, lihat fungsi daftar masuk pada halaman semakan dan pilih tarikh hari itu. 2. Klik untuk masuk dan anda akan melihat pilihan untuk melihat butiran. 3. Selepas melompat ke halaman, pilih
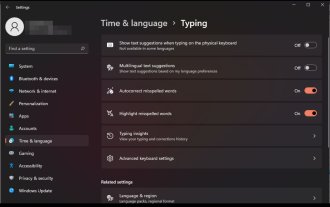 Bagaimana untuk mendayakan atau melumpuhkan pembetulan automatik perkataan yang salah eja pada Windows 11
Sep 19, 2023 pm 10:53 PM
Bagaimana untuk mendayakan atau melumpuhkan pembetulan automatik perkataan yang salah eja pada Windows 11
Sep 19, 2023 pm 10:53 PM
Autocorrect ialah ciri yang sangat berguna yang boleh menjimatkan banyak masa dalam kehidupan harian anda. Walaupun ia tidak sempurna, pada kebanyakan masa, anda boleh bergantung padanya untuk membetulkan kesilapan ejaan dan kesilapan penulisan anda. Walau bagaimanapun, kadangkala ia tidak berfungsi dengan betul. Anda akan mendapati bahawa ia tidak mengenali beberapa perkataan, yang menjadikannya sukar untuk berfungsi dengan cekap. Pada masa lain, anda hanya mahu melumpuhkannya dan kembali kepada cara lama. Tetapi adakah terdapat faedah menggunakan AutoCorrect? Menjimatkan masa anda dengan membetulkan ralat ejaan. Membantu anda mempelajari perkataan baharu dengan menunjukkan ejaan yang betul. Ia membantu anda mengelakkan kesilapan yang memalukan dalam e-mel dan dokumen lain. Anda akan dapat menaip dengan lebih pantas dan membuat lebih sedikit kesilapan. Bagaimana untuk menghidupkan atau mematikan semakan ejaan pada Windows 11? 1. Ketik kekunci menggunakan apl Tetapan
 Di manakah perkataan yang dipotong dalam Hundred Words Chop? Tutorial carian perkataan yang boleh digunakan untuk menghapuskan ratusan perkataan!
Mar 15, 2024 pm 03:52 PM
Di manakah perkataan yang dipotong dalam Hundred Words Chop? Tutorial carian perkataan yang boleh digunakan untuk menghapuskan ratusan perkataan!
Mar 15, 2024 pm 03:52 PM
1. Di manakah perkataan yang telah dikeluarkan daripada Hundred Words Cut? Tutorial carian perkataan yang boleh digunakan untuk menghapuskan ratusan perkataan! 1. Pergi ke halaman utama dan klik pada senarai perkataan. 2. Selepas melompat ke halaman, pilih pilihan perkataan yang dicincang. 3. Selepas memasuki antara muka, anda boleh melihat perkataan yang telah dipotong oleh pengguna. 4. Jika anda ingin memulihkan perkataan yang dicincang, klik pilihan Edit. 5. Cari perkataan yang perlu dipulihkan dan klik ikon potong di sebelah kanan untuk memulihkan perkataan. 6. Kembali ke antara muka perkataan yang dipelajari dan anda boleh melihat perkataan yang baru dipulihkan.
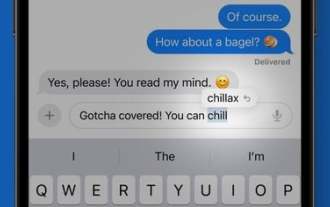 Cara memanfaatkan autocorrect ramalan dalam iOS 17
Sep 17, 2023 pm 03:37 PM
Cara memanfaatkan autocorrect ramalan dalam iOS 17
Sep 17, 2023 pm 03:37 PM
Terima kasih kepada teknologi pembelajaran mesin yang dipertingkatkan, Apple dalam iOS 17 telah menjadikan AutoCorrect lebih berguna apabila menaip teks pada iPhone. Apple berkata ia menggunakan "model bahasa morpher" untuk memperibadikan AutoCorrect dengan lebih baik untuk pengguna individu, mempelajari pilihan peribadi anda dan pilihan perkataan untuk menjadikannya lebih berguna semasa menaip. Selepas menggunakan iOS 17 selama beberapa minggu, anda harus perasan bahawa cadangan AutoCorrect adalah lebih baik dalam meramalkan perkara yang ingin anda katakan dan menunjukkan perkataan untuk anda klik untuk autolengkap. AutoCorrect kurang agresif berbanding AutoCorrect apabila anda menggunakan akronim, perkataan yang dipendekkan, slanga dan bahasa sehari-hari, tetapi ia masih dapat membetulkan ralat ejaan yang tidak disengajakan. Membetulkan AutoCorrect Apabila AutoCorrect menukar perkataan, garis biru akan muncul di bawah perkataan yang dibetulkan. awak boleh
 Kira panjang perkataan dalam rentetan menggunakan Python
Sep 13, 2023 am 11:29 AM
Kira panjang perkataan dalam rentetan menggunakan Python
Sep 13, 2023 am 11:29 AM
Mencari panjang perkataan individu dalam rentetan input yang diberikan menggunakan Python adalah masalah yang mesti diselesaikan. Kami ingin mengira bilangan aksara setiap perkataan dalam input teks dan memaparkan keputusan dalam gaya berstruktur seperti senarai. Tugas itu memerlukan memecahkan rentetan input dan memisahkan setiap perkataan. Kemudian hitung panjang setiap perkataan berdasarkan bilangan aksara di dalamnya. Matlamat asas adalah untuk mencipta fungsi atau prosedur yang boleh menerima input dengan cekap, menentukan panjang perkataan, dan hasil output tepat pada masanya. Menangani isu ini adalah penting dalam pelbagai aplikasi, termasuk pemprosesan teks, pemprosesan bahasa semula jadi dan analisis data, di mana statistik panjang perkataan boleh memberikan maklumat yang bernas dan membolehkan analisis tambahan. Kaedah yang digunakan Gunakan fungsi gelung dan split() Gunakan fungsi map() dengan len dan split() Gunakan
 iOS 17 menjanjikan peningkatan ketara pada ciri autopembetulan iPhone
Jun 06, 2023 am 08:20 AM
iOS 17 menjanjikan peningkatan ketara pada ciri autopembetulan iPhone
Jun 06, 2023 am 08:20 AM
Apple telah pratonton iOS 17 untuk iPhone hari ini, dan salah satu ciri baharu utama yang dibawa oleh kemas kini ialah pembetulan automatik yang dipertingkatkan. Apple berkata iOS 17 termasuk model bahasa ramalan perkataan terkini yang akan meningkatkan autopembetulan iPhone dengan ketara. Setiap kali anda menaip, pembelajaran mesin pada peranti secara bijak membetulkan ralat dengan ketepatan yang lebih tinggi berbanding sebelum ini. Selain itu, anda kini akan menerima cadangan teks ramalan sebaris semasa anda menaip, membolehkan anda menambah perkataan atau melengkapkan ayat dengan menekan bar ruang. AutoCorrect mempunyai reka bentuk yang dikemas kini pada iOS 17 yang secara ringkas menekankan perkataan yang sedang dibetulkan secara automatik. Mengklik pada perkataan bergaris bawah memaparkan perkataan asal yang anda taip, menjadikannya mudah untuk mengembalikan perubahan dengan cepat. Lama kelamaan, sistem juga akan mempelajari menaip anda
