
 Peranti teknologi
AI
Rakan-rakan anda juga menonton! Algoritma Google STUDY menyokong sistem pengesyoran senarai buku untuk membuatkan pelajar jatuh cinta dengan membaca
Peranti teknologi
AI
Rakan-rakan anda juga menonton! Algoritma Google STUDY menyokong sistem pengesyoran senarai buku untuk membuatkan pelajar jatuh cinta dengan membaca
Rakan-rakan anda juga menonton! Algoritma Google STUDY menyokong sistem pengesyoran senarai buku untuk membuatkan pelajar jatuh cinta dengan membaca

Membuka buku bermanfaat, inilah yang selalu kita fahami. Membaca boleh membantu orang ramai meningkatkan kemahiran bahasa mereka dan mempelajari kemahiran baru....
Membaca juga boleh meningkatkan mood dan meningkatkan kesihatan mental. Orang yang kerap membaca mempunyai pengetahuan am yang lebih besar dan pemahaman yang lebih mendalam tentang budaya lain.
Selain itu, kajian telah membuktikan bahawa keseronokan membaca adalah berkaitan dengan kejayaan akademik.
Tetapi dalam era ledakan maklumat, terdapat banyak sumber bacaan dalam talian dan luar talian. Apa yang perlu dibaca menjadi cabaran yang sukar.
Secara khususnya, kandungan bacaan mestilah sepadan dengan kumpulan umur yang berbeza dan menarik.
Dan sistem pengesyoran adalah penyelesaian kepada cabaran ini. Ia memberikan pembaca bahan bacaan yang relevan dan membantu mereka terus berminat.
Inti sistem pengesyoran ialah pembelajaran mesin (ML), yang digunakan secara meluas dalam membina pelbagai jenis sistem pengesyoran: daripada video kepada buku kepada platform e-dagang.
Model ML terlatih boleh membuat pengesyoran kepada setiap pengguna secara individu berdasarkan pilihan pengguna, penglibatan pengguna dan item yang disyorkan, dengan itu meningkatkan pengalaman pengguna.
Penyelidikan terbaharu Google mencadangkan sistem pengesyoran kandungan buku audio yang mengambil kira sifat sosial pembacaan (seperti persekitaran pendidikan): algoritma KAJIAN.
Memandangkan perkara yang sedang dibaca oleh rakan sebaya seseorang boleh memberi kesan yang ketara pada perkara yang mereka minati untuk membaca, Google telah bekerjasama dengan Learning Ally.
Learning Ally ialah organisasi bukan untung pendidikan dengan perpustakaan digital besar buku audio susun atur untuk pelajar, sesuai untuk membina model pengesyoran sosial.
Ini membolehkan model mendapat manfaat daripada maklumat masa nyata tentang kumpulan sosial setempat pelajar (seperti bilik darjah).
Algoritma KAJIAN
Algoritma KAJIAN menggunakan kaedah memodelkan masalah kandungan yang disyorkan sebagai masalah ramalan kadar klik lalu.
di mana kebarangkalian interaksi pengguna simulasi dengan setiap item tertentu bergantung pada:
1) Ciri pengguna dan item
2) Urutan sejarah interaksi item pengguna.
Kerja sebelum ini telah menunjukkan bahawa model Transformer sangat sesuai untuk memodelkan masalah ini.
Apabila merawat setiap pengguna secara individu, simulasi interaksi menjadi masalah pemodelan jujukan autoregresif.
Algoritma KAJIAN ialah produk akhir pemodelan data melalui rangka kerja konsep ini dan kemudian melanjutkan rangka kerja ini.
Masalah ramalan kadar klik lalu boleh memodelkan kebergantungan antara pilihan item masa lalu dan masa hadapan pengguna individu, dan mempelajari corak persamaan antara pengguna pada masa latihan.
Tetapi satu masalah ialah kaedah ramalan kadar klik lalu tidak boleh memodelkan kebergantungan antara pengguna yang berbeza.
Untuk tujuan ini, Google membangunkan model KAJIAN, yang boleh menyelesaikan kelemahan pemodelan jujukan autoregresif yang tidak dapat memodelkan sifat sosial membaca.
KAJIAN boleh menyambungkan jujukan buku yang dibaca oleh berbilang pelajar dalam satu kelas kepada satu urutan, dengan itu mengumpul data daripada berbilang pelajar dalam satu model.
Walau bagaimanapun, perwakilan data ini perlu dikaji dengan teliti semasa memodelkannya dengan Transformer.
Dalam Transformer, topeng perhatian ialah matriks yang mengawal input yang boleh digunakan untuk meramalkan output yang mana.
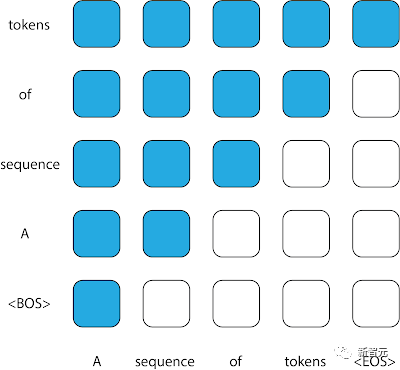
Corak penggunaan semua token sebelumnya dalam jujukan untuk memaklumkan ramalan output menghasilkan matriks perhatian segi tiga atas, yang biasanya ditemui dalam penyahkod sebab.
Walau bagaimanapun, oleh kerana input jujukan ke dalam model KAJIAN tidak dalam susunan kronologi, walaupun setiap jujukan komponennya dalam susunan kronologi, penyahkod sebab-musabab tradisional tidak lagi sesuai untuk jujukan ini.
Dalam cuba meramalkan setiap token, model tidak membenarkan perhatian beralih kepada setiap token yang muncul di hadapannya dalam urutan; beberapa token ini mungkin mempunyai cap masa kemudian dan mengandungi maklumat yang tidak tersedia pada masa penggunaan .
 Gambar
Gambar
Topeng perhatian yang biasa digunakan dalam penyahkod kausal. Setiap lajur mewakili output, dan setiap lajur mewakili output. Entri matriks dengan nilai 1 (ditunjukkan dalam warna biru) pada kedudukan tertentu menunjukkan bahawa model boleh memerhati input untuk baris tersebut apabila meramalkan output lajur yang sepadan, manakala nilai 0 (ditunjukkan dalam warna putih) menunjukkan sebaliknya . Model
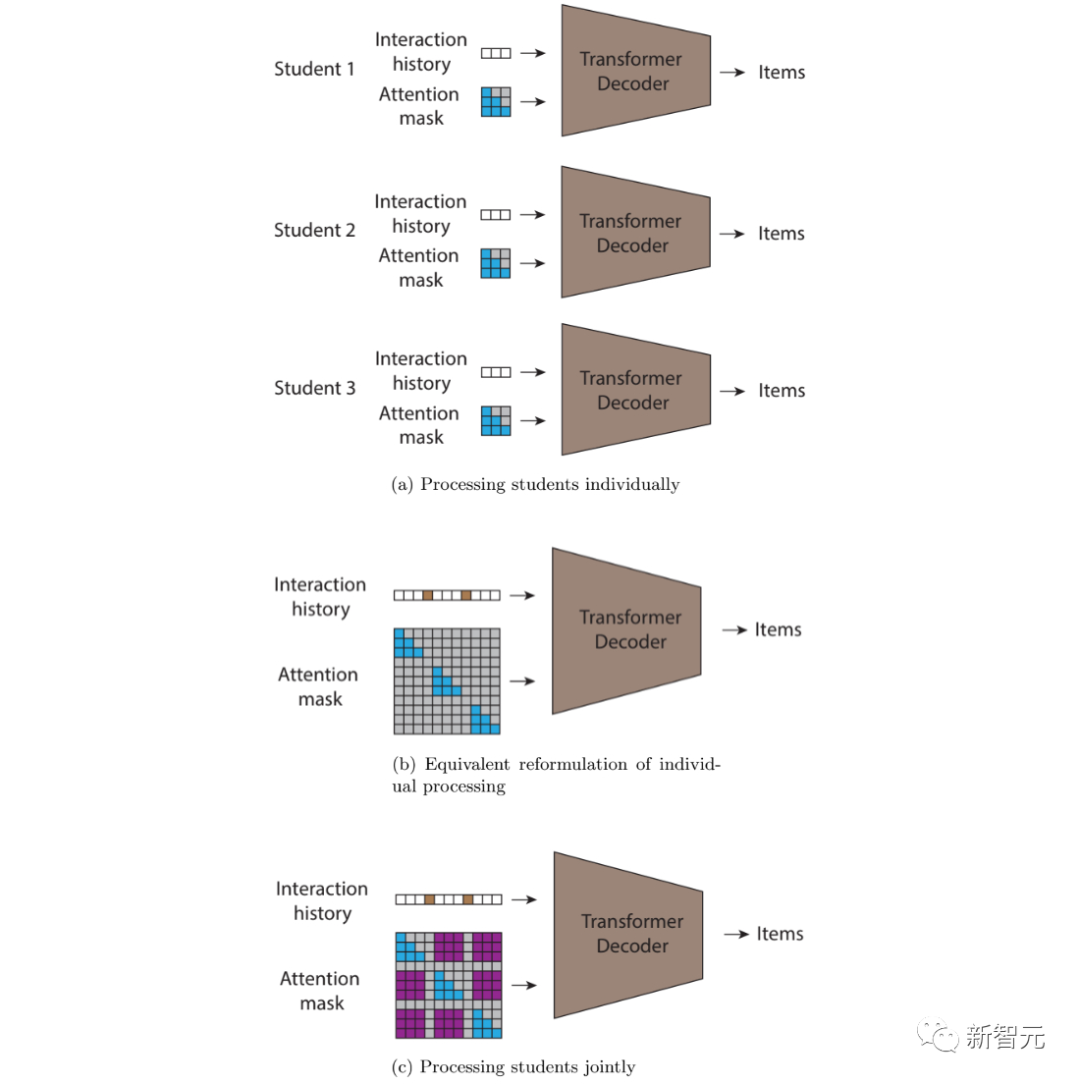
STUDY adalah berdasarkan pengubah penyebab yang menggantikan topeng perhatian matriks segi tiga dengan topeng perhatian berasaskan cap masa yang fleksibel, membenarkan perhatian merentas urutan yang berbeza.
Berbanding dengan penukar biasa, model KAJIAN mengekalkan matriks perhatian segi tiga sebab dalam urutan dan mempunyai nilai fleksibel dalam jujukan berbeza yang bergantung pada cap waktu.
Oleh itu, ramalan untuk mana-mana titik keluaran dalam jujukan akan merujuk kepada semua titik input yang berlaku pada masa lalu berbanding dengan titik masa semasa, tidak kira sama ada ia berlaku sebelum atau selepas titik input semasa dalam jujukan.
Kekangan penyebab ini penting kerana jika kekangan ini tidak dikuatkuasakan semasa latihan, model mungkin belajar menggunakan maklumat masa depan untuk membuat ramalan, yang tidak mungkin berlaku dalam penggunaan dunia sebenar.
 Gambar
Gambar
(a) Transformer autoregresif berjujukan dengan perhatian sebab, yang boleh mengendalikan setiap pengguna secara individu; Dengan memperkenalkan nilai bukan sifar baharu dalam topeng perhatian (ditunjukkan dalam warna ungu), maklumat dibenarkan mengalir antara pengguna. Untuk melakukan ini, kami membenarkan ramalan bersyarat pada semua interaksi dengan cap masa yang lebih awal, tidak kira sama ada interaksi itu daripada pengguna yang sama
Eksperimen
Google menggunakan set data Learning Ally untuk melatih model KAJIAN, menggunakan berbilang garis dasar Buat perbandingan.
Pasukan menggunakan penyahkod CTR autoregresif (dipanggil "individu"), garis dasar jiran terdekat (KNN) dan garis dasar sosial yang setanding - Rangkaian Memori Perhatian Sosial (SAMN).
Mereka menggunakan data dari tahun akademik pertama untuk latihan dan data dari tahun akademik kedua untuk pengesahan dan ujian.
Pasukan menilai model ini dengan mengukur peratusan masa item seterusnya yang sebenarnya berinteraksi dengan pengguna berada dalam cadangan n teratas model.
Selain menilai model pada keseluruhan set ujian, pasukan juga melaporkan skor model pada dua subset set ujian yang lebih mencabar daripada keseluruhan set data.
Dapat diperhatikan bahawa pelajar biasanya berinteraksi dengan buku audio beberapa kali, jadi hanya mengesyorkan buku terakhir yang dibaca oleh pengguna adalah remeh.
Oleh itu, penyelidik memanggil subset ujian pertama "bukan sambungan". Dalam subset ini, kami hanya meneliti prestasi pengesyoran setiap model apabila pelajar berinteraksi dengan buku yang berbeza daripada interaksi sebelumnya.
Selain itu, pasukan juga memerhatikan bahawa pelajar akan menyemak buku yang telah mereka baca pada masa lalu, jadi buku yang disyorkan untuk setiap pelajar adalah terhad kepada buku yang telah mereka baca pada masa lalu, yang boleh dilakukan pada ujian set Mencapai prestasi yang hebat.
Walaupun mungkin terdapat beberapa nilai dalam mengesyorkan pelajar buku kegemaran mereka dari masa lalu, banyak nilai sistem pengesyoran datang daripada mengesyorkan kandungan baharu yang tidak diketahui kepada pengguna.
Untuk mengukur ini, pasukan menilai model pada subset set ujian di mana pelajar berinteraksi dengan bibliografi buat kali pertama. Kami menamakan subset penilaian ini "subset baharu".
Boleh didapati bahawa "KAJIAN" adalah lebih baik daripada model lain dalam hampir semua penilaian. .
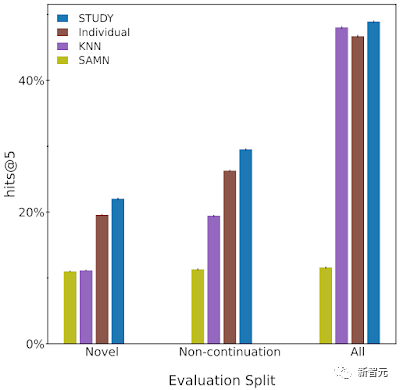 Para penyelidik mengkaji kepentingan pengumpulan praktikal mengenai prestasi model melalui kajian ablasi.
Para penyelidik mengkaji kepentingan pengumpulan praktikal mengenai prestasi model melalui kajian ablasi.
Dalam model yang dicadangkan, penyelidik mengumpulkan semua pelajar dalam gred dan sekolah yang sama.
Kami kemudiannya bereksperimen dengan kumpulan yang ditakrifkan oleh semua pelajar dalam gred dan daerah yang sama, serta mengumpulkan semua pelajar ke dalam satu kumpulan dan menggunakan subset rawak pada setiap hantaran hadapan.
Para penyelidik juga membandingkan model ini dengan model "peribadi" untuk rujukan.
Kajian mendapati bahawa menggunakan lebih banyak kumpulan setempat adalah lebih berkesan, iaitu kumpulan sekolah dan gred adalah lebih baik daripada kumpulan daerah dan gred sekolah.
Ini menyokong hipotesis bahawa model penyelidikan berjaya kerana aktiviti seperti membaca adalah sosial: pilihan membaca orang mungkin berkait rapat dengan pilihan membaca orang di sekeliling mereka.
Kedua-dua mod mengatasi dua mod lain (mod kumpulan tunggal dan mod individu) tanpa menggunakan tahap gred untuk mengumpulkan pelajar.
Ini menunjukkan bahawa data daripada pengguna yang mempunyai tahap bacaan dan minat yang sama bermanfaat untuk meningkatkan prestasi model.
Akhirnya, kajian Google ini terhad kepada pemodelan kumpulan pengguna dengan mengandaikan bahawa hubungan sosial adalah homogen.
Rujukan:
https://www.php.cn/link/0b32f1a9efe5edf3dd2f38b0c0052bfe
Atas ialah kandungan terperinci Rakan-rakan anda juga menonton! Algoritma Google STUDY menyokong sistem pengesyoran senarai buku untuk membuatkan pelajar jatuh cinta dengan membaca. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
1207
24
52
1207
24

 Bagaimana untuk mengalih keluar maklumat pengarang dan terakhir diubah suai dalam Microsoft Word
Apr 15, 2023 am 11:43 AM
Bagaimana untuk mengalih keluar maklumat pengarang dan terakhir diubah suai dalam Microsoft Word
Apr 15, 2023 am 11:43 AM
Dokumen Microsoft Word mengandungi beberapa metadata apabila disimpan. Butiran ini digunakan untuk pengenalan pada dokumen, seperti apabila ia dibuat, siapa pengarangnya, tarikh diubah suai, dsb. Ia juga mempunyai maklumat lain seperti bilangan aksara, bilangan perkataan, bilangan perenggan dan banyak lagi. Jika anda mungkin ingin mengalih keluar pengarang atau maklumat terakhir yang diubah suai atau sebarang maklumat lain supaya orang lain tidak mengetahui nilainya, maka ada caranya. Dalam artikel ini, mari lihat cara mengalih keluar pengarang dokumen dan maklumat terakhir diubah suai. Alih keluar pengarang dan maklumat terakhir diubah suai daripada dokumen Microsoft Word Langkah 1 – Pergi ke
 Bagaimana untuk mendapatkan GPU dalam Windows 11 dan semak butiran kad grafik
Nov 07, 2023 am 11:21 AM
Bagaimana untuk mendapatkan GPU dalam Windows 11 dan semak butiran kad grafik
Nov 07, 2023 am 11:21 AM
Menggunakan Maklumat Sistem Klik Mula dan masukkan Maklumat Sistem. Hanya klik pada program seperti yang ditunjukkan dalam imej di bawah. Di sini anda boleh menemui kebanyakan maklumat sistem, dan satu perkara yang anda boleh temui ialah maklumat kad grafik. Dalam program Maklumat Sistem, kembangkan Komponen, dan kemudian klik Tunjukkan. Biarkan program mengumpulkan semua maklumat yang diperlukan dan setelah ia siap, anda boleh mencari nama khusus kad grafik dan maklumat lain pada sistem anda. Walaupun anda mempunyai berbilang kad grafik, anda boleh menemui kebanyakan kandungan yang berkaitan dengan kad grafik khusus dan bersepadu yang disambungkan ke komputer anda dari sini. Menggunakan Pengurus Peranti Windows 11 Sama seperti kebanyakan versi Windows yang lain, anda juga boleh mencari kad grafik pada komputer anda daripada Pengurus Peranti. Klik Mula dan kemudian
 Cara berkongsi butiran hubungan dengan NameDrop: Panduan cara untuk iOS 17
Sep 16, 2023 pm 06:09 PM
Cara berkongsi butiran hubungan dengan NameDrop: Panduan cara untuk iOS 17
Sep 16, 2023 pm 06:09 PM
Dalam iOS 17, terdapat ciri AirDrop baharu yang membolehkan anda bertukar maklumat hubungan dengan seseorang dengan menyentuh dua iPhone. Ia dipanggil NameDrop, dan inilah cara ia berfungsi. Daripada memasukkan nombor orang baharu untuk menghubungi atau menghantar teks kepada mereka, NameDrop membenarkan anda meletakkan iPhone anda berhampiran iPhone mereka untuk bertukar-tukar butiran hubungan supaya mereka mempunyai nombor anda. Meletakkan kedua-dua peranti bersama-sama akan muncul secara automatik antara muka perkongsian kenalan. Mengklik pada pop timbul akan memaparkan maklumat hubungan seseorang dan poster kenalan mereka (anda boleh menyesuaikan dan mengedit foto anda sendiri, juga ciri baharu iOS17). Skrin ini juga termasuk pilihan untuk "Terima Sahaja" atau berkongsi maklumat hubungan anda sendiri sebagai balasan.
 Algoritma NeRF paparan tunggal S^3-NeRF menggunakan maklumat berbilang pencahayaan untuk memulihkan geometri pemandangan dan maklumat bahan.
Apr 13, 2023 am 10:58 AM
Algoritma NeRF paparan tunggal S^3-NeRF menggunakan maklumat berbilang pencahayaan untuk memulihkan geometri pemandangan dan maklumat bahan.
Apr 13, 2023 am 10:58 AM
Kerja pembinaan semula 3D imej semasa biasanya menggunakan kaedah pembinaan semula stereo berbilang paparan (Stereo Berbilang Pandangan) yang merakam pemandangan sasaran daripada berbilang sudut pandangan (berbilang paparan) di bawah keadaan pencahayaan semula jadi yang berterusan. Walau bagaimanapun, kaedah ini biasanya menganggap permukaan Lambertian dan mengalami kesukaran memulihkan butiran frekuensi tinggi. Satu lagi pendekatan untuk pembinaan semula pemandangan ialah menggunakan imej yang ditangkap dari sudut pandangan tetap tetapi dengan lampu titik yang berbeza. Kaedah Stereo fotometrik, sebagai contoh, ambil persediaan ini dan gunakan maklumat teduhannya untuk membina semula butiran permukaan objek bukan Lambertian. Walau bagaimanapun, kaedah paparan tunggal sedia ada biasanya menggunakan peta biasa atau peta kedalaman untuk mewakili yang boleh dilihat
 Forum Sidang Kemuncak Pendidikan Aplikasi Realiti Maya Yuanverse telah diadakan di Zhengzhou
Nov 30, 2023 pm 08:33 PM
Forum Sidang Kemuncak Pendidikan Aplikasi Realiti Maya Yuanverse telah diadakan di Zhengzhou
Nov 30, 2023 pm 08:33 PM
Forum Sidang Kemuncak Pendidikan Aplikasi Realiti Maya Metaverse telah diadakan di Zhengzhou Di Forum Sidang Kemuncak Pendidikan Aplikasi Realiti Maya Metaverse, tarian "Cahaya Terapung" oleh Dong Yushan, seorang guru di Kolej Vokasional Seni Henan, menunjukkan tarian yang ringan dan lembut. Pada masa yang sama, orang maya juga menari serentak di ruang Yuanverse Pergerakan tarian mereka yang lancar dan anggun memukau ramai tetamu Pada 24 November, Forum Sidang Kemuncak Pendidikan Aplikasi Realiti Maya Yuanverse telah diadakan di Zhengzhou, yang memberi tumpuan Perwakilan dari institut penyelidikan saintifik, universiti, persatuan industri dan perusahaan terkenal berkumpul bersama untuk membincangkan arah aliran pembangunan Yuanverse. "Metaverse telah menjadi topik yang sering diperkatakan dalam beberapa tahun kebelakangan ini, dan ia telah membawa kemungkinan tanpa had kepada industri animasi, Wang Xudong, naib pengerusi Persatuan Industri Animasi Henan, berkata dalam ucapannya bahawa dalam beberapa tahun kebelakangan ini, China telah melakukannya."
 Bagaimana NameDrop berfungsi pada iPhone (dan cara melumpuhkannya)
Nov 30, 2023 am 11:53 AM
Bagaimana NameDrop berfungsi pada iPhone (dan cara melumpuhkannya)
Nov 30, 2023 am 11:53 AM
Dalam iOS17, terdapat ciri AirDrop baharu yang membolehkan anda bertukar maklumat hubungan dengan seseorang dengan menyentuh dua iPhone pada masa yang sama. Ia dipanggil NameDrop, dan inilah cara ia sebenarnya berfungsi. NameDrop menghapuskan keperluan untuk memasukkan nombor orang baharu untuk menelefon atau menghantar mesej kepada mereka supaya mereka mempunyai nombor anda, anda hanya boleh memegang iPhone anda rapat dengan iPhone mereka untuk bertukar maklumat hubungan. Meletakkan kedua-dua peranti bersama-sama akan muncul secara automatik antara muka perkongsian kenalan. Mengklik pada pop timbul akan memaparkan maklumat hubungan seseorang dan poster kenalan mereka (foto anda sendiri yang boleh anda sesuaikan dan edit, juga baharu kepada iOS 17). Skrin ini juga termasuk "Terima Sahaja" atau berkongsi maklumat hubungan anda sendiri sebagai balasan
 Apakah sebab kelewatan dalam menerima mesej di WeChat?
Sep 19, 2023 pm 03:02 PM
Apakah sebab kelewatan dalam menerima mesej di WeChat?
Sep 19, 2023 pm 03:02 PM
Sebab kelewatan dalam WeChat menerima maklumat mungkin masalah rangkaian, beban pelayan, masalah versi, masalah peranti, masalah penghantaran mesej atau faktor lain. Pengenalan terperinci: 1. Masalah rangkaian Kelewatan dalam menerima maklumat pada WeChat mungkin berkaitan dengan sambungan rangkaian Jika sambungan rangkaian tidak stabil atau isyarat lemah, ia boleh menyebabkan kelewatan dalam penghantaran maklumat disambungkan ke rangkaian yang stabil dan kekuatan isyarat rangkaian adalah baik ; masa yang sama, dsb.
 Aplikasi kaedah pembetulan sebab dan akibat dalam senario pengesyoran Ant Marketing
Jan 13, 2024 pm 12:15 PM
Aplikasi kaedah pembetulan sebab dan akibat dalam senario pengesyoran Ant Marketing
Jan 13, 2024 pm 12:15 PM
1. Latar belakang pembetulan sebab dan akibat 1. Penyelewengan berlaku dalam sistem pengesyoran Model pengesyoran dilatih dengan mengumpul data untuk mengesyorkan item yang sesuai kepada pengguna. Apabila pengguna berinteraksi dengan item yang disyorkan, data yang dikumpul digunakan untuk terus melatih model, membentuk gelung tertutup. Walau bagaimanapun, mungkin terdapat pelbagai faktor yang mempengaruhi dalam gelung tertutup ini, mengakibatkan ralat. Sebab utama ralat ialah kebanyakan data yang digunakan untuk melatih model adalah data pemerhatian dan bukannya data latihan yang ideal, yang dipengaruhi oleh faktor seperti strategi pendedahan dan pemilihan pengguna. Intipati berat sebelah ini terletak pada perbezaan antara jangkaan anggaran risiko empirikal dan jangkaan anggaran risiko ideal sebenar. 2. Kecondongan biasa Terdapat tiga jenis utama bias biasa dalam sistem pemasaran pengesyoran: Kecondongan selektif: Ini disebabkan oleh akar pengguna
