
 Peranti teknologi
AI
Meta merancang untuk mengeluarkan versi sumber terbuka baharu bagi model besar tahap GPT-4 tahun hadapan bilangan parameternya akan menjadi beberapa kali ganda berbanding Llama 2, dan pengguna boleh menggunakannya secara komersil secara percuma.
Peranti teknologi
AI
Meta merancang untuk mengeluarkan versi sumber terbuka baharu bagi model besar tahap GPT-4 tahun hadapan bilangan parameternya akan menjadi beberapa kali ganda berbanding Llama 2, dan pengguna boleh menggunakannya secara komersil secara percuma.
Meta merancang untuk mengeluarkan versi sumber terbuka baharu bagi model besar tahap GPT-4 tahun hadapan bilangan parameternya akan menjadi beberapa kali ganda berbanding Llama 2, dan pengguna boleh menggunakannya secara komersil secara percuma.

Menurut media asing "Wall Street Journal", Meta sedang meningkatkan pembangunan model bahasa besar baharu, keupayaannya akan diselaraskan sepenuhnya dengan GPT-4 dan dijangka akan dilancarkan tahun depan.

Berita itu juga secara khusus menekankan bahawa model bahasa besar baharu Meta akan menjadi beberapa kali lebih besar daripada Llama 2, dan kemungkinan besar ia akan menjadi sumber terbuka dan menyokong penggunaan komersial percuma.
Sejak Meta "secara tidak sengaja" membocorkan LlaMA pada awal tahun, kepada keluaran sumber terbuka Llama 2 pada bulan Julai, Meta secara beransur-ansur menemui kedudukan uniknya dalam gelombang AI ini - sepanduk sumber terbuka AI masyarakat.

Kakitangan sentiasa berubah, dan keupayaan model adalah cacat, jadi kami hanya boleh bergantung pada perisian sumber terbuka untuk menyelesaikan masalah
Pada awal tahun, selepas OpenAI meledakkan industri teknologi dengan GPT -4, Google dan Microsoft turut melancarkan produk AI mereka sendiri.
Pada bulan Mei, pengawal selia A.S. telah menjemput CEO syarikat terkemuka yang mereka anggap relevan dengan industri AI pada masa itu untuk mengadakan mesyuarat meja bulat bagi membincangkan pembangunan teknologi AI.
OpenAI, Google dan Microsoft telah dijemput untuk mengambil bahagian, dan juga permulaan Anthropic, tetapi Meta tidak muncul. Pada masa itu, jawapan rasmi untuk alasan ketidakhadiran Meta ialah: "Kami hanya menjemput syarikat terkemuka dalam industri AI

Perkara yang baik tidak berlaku kepada Meta, tetapi masalah terus datang.
Xiao Zha menerima surat siasatan daripada Kongres pada awal Jun, meminta beliau menerangkan secara terperinci punca dan kesan kebocoran LlaMA pada bulan Mac. Surat itu ditulis dengan tegas dan syaratnya sangat jelas

Dalam bulan-bulan berikutnya, walaupun selepas pengeluaran Llama 2, pasukan AI yang Meta telah membelanjakan banyak wang untuk dibina masih beransur-ansur jatuh. berpisah.
Dalam pengiktirafan Llama 2, empat ahli pasukan yang mula-mula memulakan penyelidikan ini disebut, tiga daripadanya telah meletak jawatan, dan pada masa ini hanya Edouard Grave yang masih bekerja di Syarikat Meta
He Kaiming juga akan meninggalkan Meta dan kembali ke akademik.

Menurut artikel terbaharu oleh The Information, pasukan AI Meta telah mengalami geseran berterusan akibat persaingan untuk kuasa pengkomputeran dalaman, dan kakitangan telah meninggalkan satu demi satu.
Dalam konteks ini, Xiao Zha sendiri juga harus tahu dengan baik bahawa model bahasa Meta sendiri yang besar sememangnya tidak mampu bersaing dengan GPT-4 yang paling canggih dalam industri.
Sama ada dari pelbagai arah ujian penanda aras atau maklum balas pengguna, jurang antara Llama 2 dan GPT-4 masih sangat besar
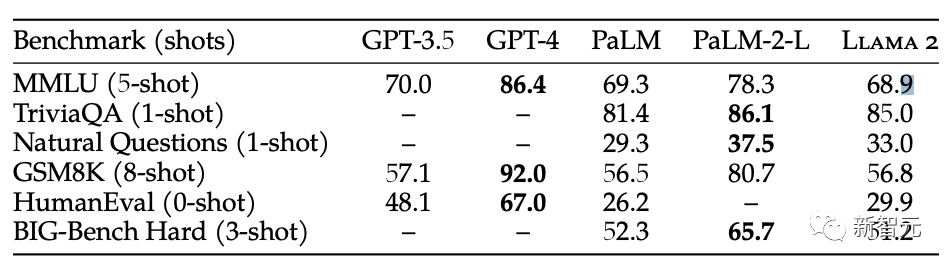
Dalam pelbagai ujian penanda aras, sumber terbuka Llama 2 dan Terdapat jurang yang agak besar antara GPT-4

GPT-4 masih menunjukkan pendahuluan yang jelas berbanding Llama 2 dalam pengalaman sebenar netizen
🎜Oleh itu, Xiao Zha memutuskan untuk membiarkan Meta terus berjalan liar di jalan model sumber terbuka
Mungkin pemikiran Xiao Zha di sebaliknya adalah ini: keupayaan model Meta adalah sederhana dan tidak dapat bersaing dengan gergasi sumber tertutup, jadi ada tiada gunanya terus merahsiakan kepentingannya. Oleh itu, cukup buka sumber dan biarkan komuniti AI terus bergerak berdasarkan model mereka sendiri untuk mengembangkan pengaruh produk mereka dalam industri
Xiao Zha telah banyak kali menyatakan secara terbuka bahawa komuniti sumber terbuka telah memainkan peranan yang memberi inspirasi peranan dalam lelaran model mereka. Membenarkan pasukan teknikal mereka untuk membangunkan produk yang lebih kompetitif pada masa hadapan

Xiao Zha menekankan dalam podcast Fridman bahawa sumber terbuka membolehkan Meta mendapatkan inspirasi daripada komuniti, dan Meta boleh melancarkan sumber tertutup dalam Model masa depan.
Lihat: https://lexfridman.com/mark-zuckerberg-2/
Dan fakta telah membuktikan bahawa pilihan Meta memang betul.
Walaupun ia tidak sehebat Google dan OpenAI dari segi sumber pengkomputeran dan kekuatan teknikal, model sumber terbuka seperti Meta’s Llama 2 masih tiada duanya dalam daya tarikan mereka kepada komuniti sumber terbuka. Memandangkan Llama 2 perlahan-lahan menjadi "asas teknikal" komuniti sumber terbuka AI, Meta juga telah menemui niche ekologinya sendiri dalam industri.
Tanda yang paling jelas ialah pada mesyuarat tertutup AI Kongres yang akan diadakan pada bulan September, Xiao Zha akhirnya menjadi tetamu pengawal selia, berkhidmat sebagai wakil bersama-sama dengan CEO syarikat paling canggih di industri seperti Google dan OpenAI , membuat suara anda sendiri mengenai peraturan industri AI.
Dan jika model baharu yang dilancarkan oleh Meta tahun depan boleh terus membuat kemajuan dan memperoleh keupayaan yang sama seperti GPT-4, di satu pihak, ia akan membolehkan komuniti sumber terbuka terus merapatkan jurang dengan gergasi sumber tertutup, dan ia akan diperkukuhkan " Jurang antara komuniti sumber terbuka dan tahap paling maju industri adalah kira-kira satu tahun."
Sebaliknya, Xiao Zha turut mendedahkan dalam temu bual bahawa jika keupayaan model besar dipertingkatkan lagi pada masa hadapan, Meta mungkin melancarkan model sumber tertutupnya sendiri. Jika model baharu itu boleh mendekati industri SOTA, ia mungkin tidak jauh dari Meta melancarkan model sumber tertutupnya sendiri.
Walaupun Meta nampaknya agak ketinggalan buat sementara waktu dalam gelombang AI ini, Xiao Zha tidak berpuas hati dengan menjadi pengikut sahaja
Di bawah bimbingan Yann Lecun, Meta juga sedang bersedia untuk menumbangkan seluruh industri
Meta The future
Jadi, selepas model besar misteri legenda yang boleh menandingi GPT-4 ini, bagaimanakah rupa masa depan Meta AI?
Disebabkan belum ada maklumat khusus, kami hanya boleh membuat beberapa tekaan sahaja seperti bermula dari sikap ketua saintis Meta AI LeCun.
GPT yang popular sentiasa menjadi laluan pembangunan kecerdasan buatan yang dikritik dan dibenci oleh LeCun.
Pada 4 Februari tahun ini, LeCun secara terang-terangan menyatakan pendapatnya bahawa model bahasa besar adalah jalan yang salah di jalan menuju AI peringkat manusia

Beliau percaya asas ini Model kebarangkalian autoregresif besar akan generatif. tidak dapat bertahan selama paling lama 5 tahun, kerana kecerdasan buatan ini hanya dilatih pada sejumlah besar teks, dan mereka tidak dapat memahami dunia sebenar.
Model ini tidak boleh merancang mahupun membuat alasan, mereka hanya mempunyai keupayaan untuk mempelajari konteks
Seriusnya, kecerdasan buatan yang dilatih pada LLM ini hampir tidak mempunyai "kecerdasan" sama sekali.
Apa yang LeCun nantikan ialah "model dunia" yang boleh membawa kepada AGI.
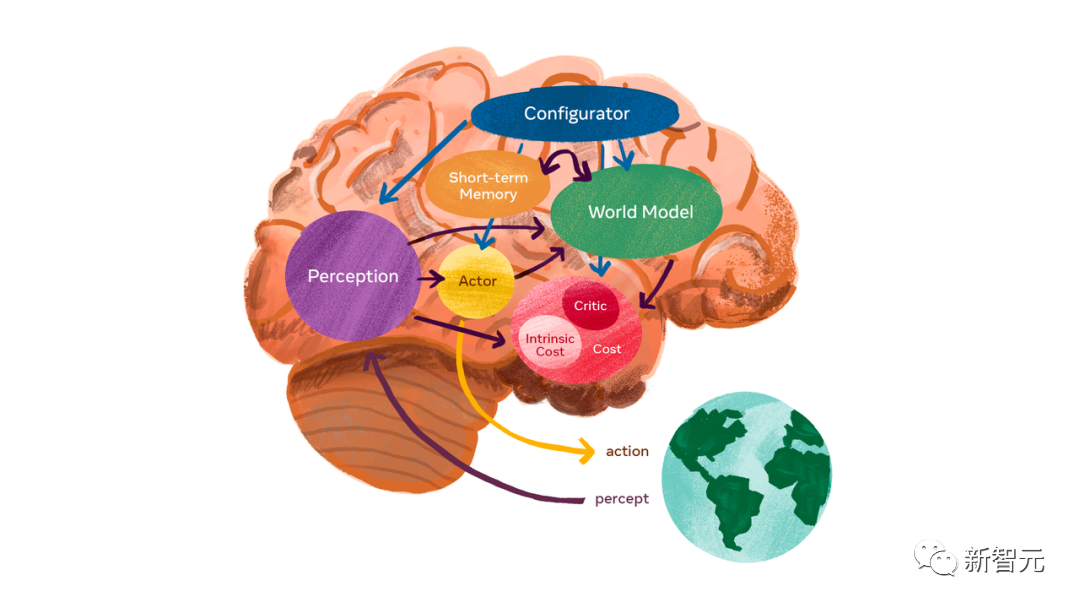
Model dunia boleh mempelajari cara dunia berfungsi, belajar dengan lebih cepat, merancang untuk menyelesaikan tugas yang rumit dan bertindak balas terhadap situasi baharu yang tidak dikenali pada bila-bila masa.
🎜Ini berbeza daripada LLM yang memerlukan banyak pra-latihan Model dunia boleh mencari corak daripada pemerhatian, menyesuaikan diri dengan persekitaran baharu dan menguasai kemahiran baharu seperti manusia.
Meta berusaha untuk pembangunan model yang pelbagai Berbanding dengan strategi penambahbaikan dan pendalaman berterusan OpenAI dalam bidang LLM
Pada 14 Jun tahun ini, Meta mengeluarkan model kecerdasan buatan I-JEPA It juga merupakan model AI pertama dalam sejarah berdasarkan bahagian penting visi model dunia LeCun.

Sila klik pautan berikut untuk melihat kertas kerja: https://arxiv.org/abs/2301.08243
I-JEPA dapat memahami representasi abstrak dalam imej dan memperoleh akal melalui diri sendiri pembelajaran diselia
I-JEPA tidak memerlukan pengetahuan pengeluaran manual tambahan sebagai bantuan
Seterusnya, Meta melancarkan Voicebox, sistem penjanaan pertuturan inovatif baharu berdasarkan kaedah baharu yang dicadangkan oleh Meta AI - pemadanan aliran

Ia boleh mensintesis pertuturan dalam enam bahasa, melakukan operasi seperti denoising, mengedit kandungan dan menukar gaya audio.
Meta juga mengeluarkan ejen AI terkandung universal
Melalui penyelarasan kemahiran berpandukan bahasa (LSC), robot boleh bergerak dan mengambil item secara bebas dalam persekitaran pra-peta tertentu
dalam multi-pembangunan model modal, Meta mempunyai ciri unik:
ImageBind, model kecerdasan buatan pertama yang boleh mengikat maklumat daripada enam modaliti berbeza. . membenarkan robot memperoleh pelbagai kemahiran bukan remeh dan menyamaratakannya kepada beratus-ratus senario kehidupan.
Data untuk semua senario ini adalah susunan magnitud yang kurang daripada kerja sebelumnya dalam bidang ini 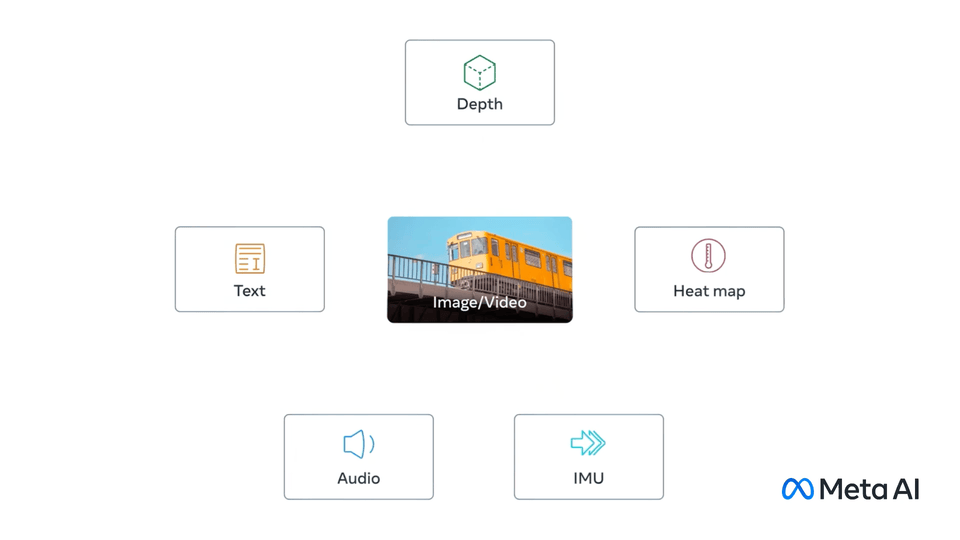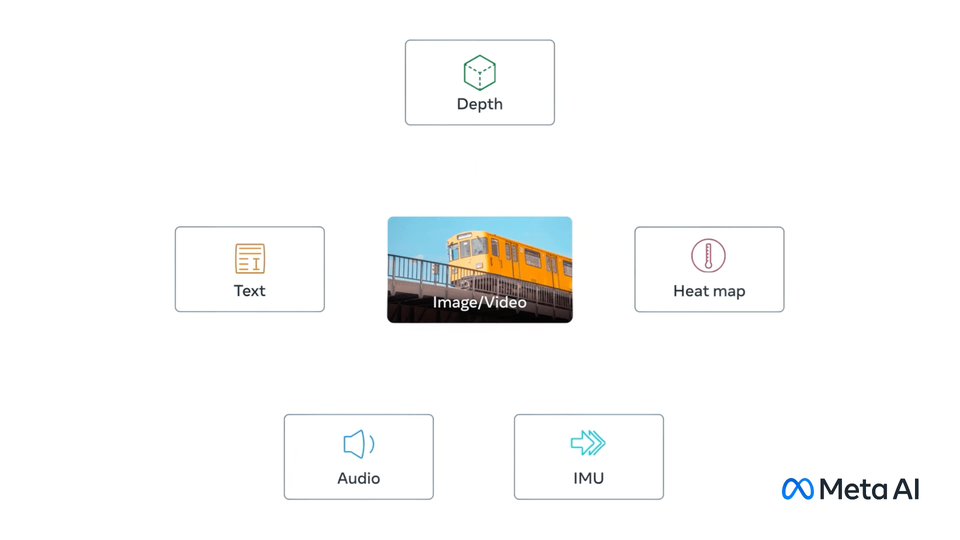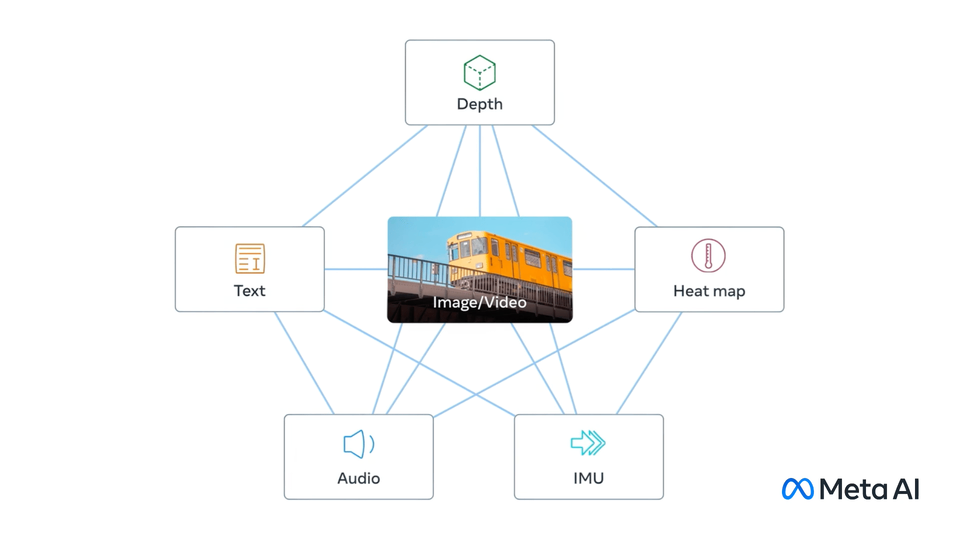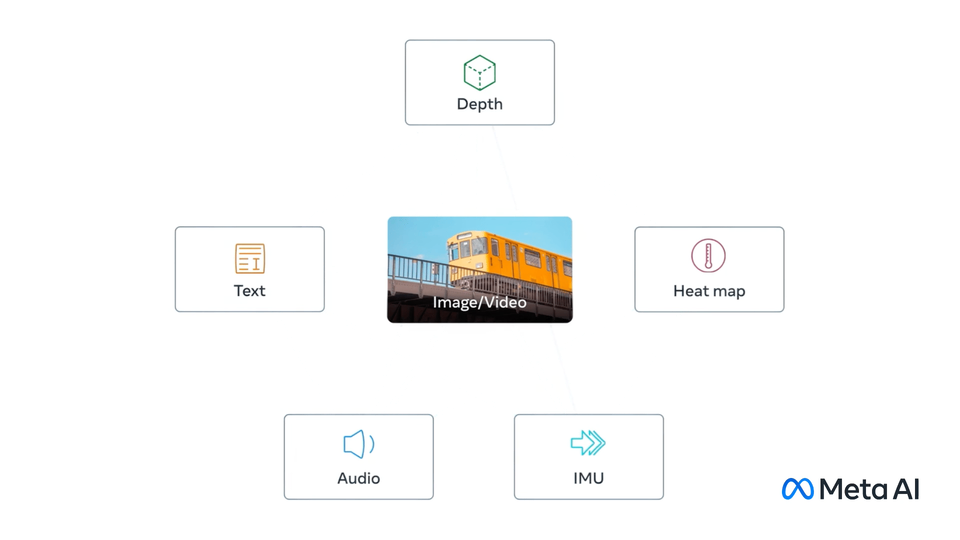
Mengenai model yang didedahkan kali ini, beberapa netizen menyatakan harapan mereka akan terus membuka kod sumber.
Namun, sesetengah netizen berkata Meta tidak akan memulakan latihan sehingga awal tahun 2024

Tetapi apa yang menggembirakan ialah Meta masih mengeluarkan isyarat bahawa ia akan terus berpegang kepada strategi asal.
Atas ialah kandungan terperinci Meta merancang untuk mengeluarkan versi sumber terbuka baharu bagi model besar tahap GPT-4 tahun hadapan bilangan parameternya akan menjadi beberapa kali ganda berbanding Llama 2, dan pengguna boleh menggunakannya secara komersil secara percuma.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1375
1375
 52
52

 Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Apabila menukar rentetan ke objek dalam vue.js, json.parse () lebih disukai untuk rentetan json standard. Untuk rentetan JSON yang tidak standard, rentetan boleh diproses dengan menggunakan ungkapan biasa dan mengurangkan kaedah mengikut format atau url yang dikodkan. Pilih kaedah yang sesuai mengikut format rentetan dan perhatikan isu keselamatan dan pengekodan untuk mengelakkan pepijat.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Ringkasan: Terdapat kaedah berikut untuk menukar array rentetan vue.js ke dalam tatasusunan objek: Kaedah asas: Gunakan fungsi peta yang sesuai dengan data yang diformat biasa. Permainan lanjutan: Menggunakan ungkapan biasa boleh mengendalikan format yang kompleks, tetapi mereka perlu ditulis dengan teliti dan dipertimbangkan. Pengoptimuman Prestasi: Memandangkan banyak data, operasi tak segerak atau perpustakaan pemprosesan data yang cekap boleh digunakan. Amalan Terbaik: Gaya Kod Jelas, Gunakan nama dan komen pembolehubah yang bermakna untuk memastikan kod ringkas.
 Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Untuk menetapkan masa untuk Vue Axios, kita boleh membuat contoh Axios dan menentukan pilihan masa tamat: dalam tetapan global: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dalam satu permintaan: ini. $ axios.get ('/api/pengguna', {timeout: 10000}).
 Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Pengoptimuman prestasi MySQL perlu bermula dari tiga aspek: konfigurasi pemasangan, pengindeksan dan pengoptimuman pertanyaan, pemantauan dan penalaan. 1. Selepas pemasangan, anda perlu menyesuaikan fail my.cnf mengikut konfigurasi pelayan, seperti parameter innodb_buffer_pool_size, dan tutup query_cache_size; 2. Buat indeks yang sesuai untuk mengelakkan indeks yang berlebihan, dan mengoptimumkan pernyataan pertanyaan, seperti menggunakan perintah menjelaskan untuk menganalisis pelan pelaksanaan; 3. Gunakan alat pemantauan MySQL sendiri (ShowProcessList, ShowStatus) untuk memantau kesihatan pangkalan data, dan kerap membuat semula dan mengatur pangkalan data. Hanya dengan terus mengoptimumkan langkah -langkah ini, prestasi pangkalan data MySQL diperbaiki.
 Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote Company Kekosongan Syarikat: Lokasi Lokasi: Jauh Pejabat Jauh Jenis: Gaji sepenuh masa: $ 130,000- $ 140,000 Penerangan Pekerjaan Mengambil bahagian dalam penyelidikan dan pembangunan aplikasi mudah alih Circle dan ciri-ciri berkaitan API awam yang meliputi keseluruhan kitaran hayat pembangunan perisian. Tanggungjawab utama kerja pembangunan secara bebas berdasarkan rubyonrails dan bekerjasama dengan pasukan react/redux/relay front-end. Membina fungsi teras dan penambahbaikan untuk aplikasi web dan bekerjasama rapat dengan pereka dan kepimpinan sepanjang proses reka bentuk berfungsi. Menggalakkan proses pembangunan positif dan mengutamakan kelajuan lelaran. Memerlukan lebih daripada 6 tahun backend aplikasi web kompleks
