
 Peranti teknologi
AI
Lao Huang memberikan H100 rangsangan: Nvidia melancarkan pakej pecutan model besar, menggandakan kelajuan inferens Llama2
Peranti teknologi
AI
Lao Huang memberikan H100 rangsangan: Nvidia melancarkan pakej pecutan model besar, menggandakan kelajuan inferens Llama2
Lao Huang memberikan H100 rangsangan: Nvidia melancarkan pakej pecutan model besar, menggandakan kelajuan inferens Llama2

Kelajuan inferens model besar telah meningkat dua kali ganda dalam masa satu bulan sahaja!
Baru-baru ini, NVIDIA mengumumkan pelancaran "pakej darah ayam" yang direka khas untuk H100, bertujuan untuk mempercepatkan proses inferens LLM
Mungkin kini anda tidak perlu menunggu GH200 dihantar tahun hadapan .
.
Kuasa pengkomputeran GPU sentiasa mempengaruhi prestasi model besar Kedua-dua pembekal perkakasan dan pengguna berharap untuk memperoleh kelajuan pengkomputeran yang lebih pantas
Sebagai pembekal perkakasan terbesar di sebalik model besar, NVIDIA saya telah mengkaji cara perkakasan. mempercepatkan model besar.
Melalui kerjasama dengan beberapa syarikat AI, NVIDIA akhirnya melancarkan program pengoptimuman inferens model besar TensorRT-LLM (sementara dirujuk sebagai TensorRT).
TensorRT bukan sahaja boleh menggandakan kelajuan inferens model besar, tetapi juga sangat mudah digunakan.
Tidak perlu mempunyai pengetahuan mendalam tentang C++ dan CUDA, anda boleh menyesuaikan strategi pengoptimuman dengan cepat dan menjalankan model besar dengan lebih pantas pada H100.
Saintis NVIDIA Jim Fan mengetweet semula dan mengulas bahawa "kelebihan lain" NVIDIA ialah perisian sokongan yang boleh memaksimumkan penggunaan prestasi GPU.
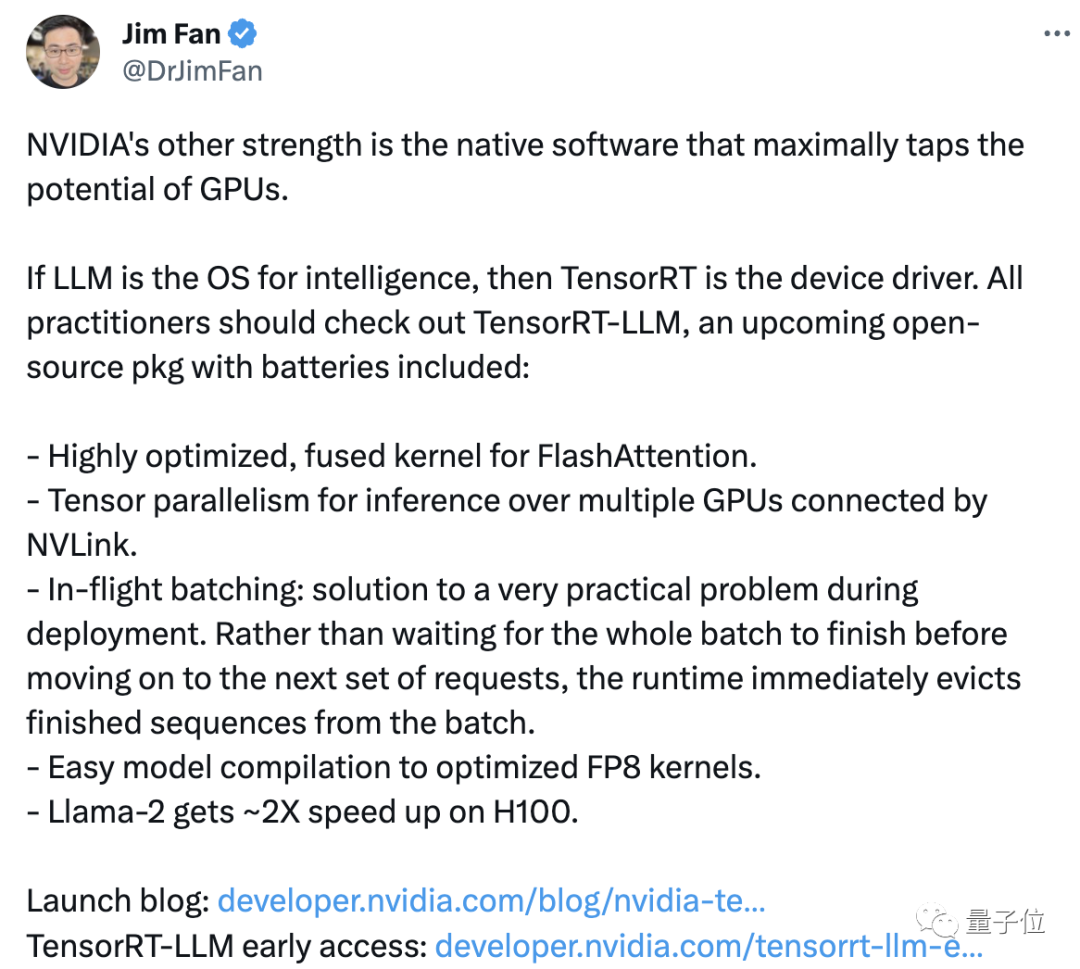
NVIDIA menyuntik tenaga baharu ke dalam produknya melalui perisian, sama seperti mengamalkan kata-kata Lao Huang "lebih banyak anda membeli, lebih banyak anda menjimatkan". Namun, ini tidak menghalang sesetengah pihak beranggapan harga produk tersebut terlalu tinggi
Selain harga, ada netizen turut mempersoalkan keputusan operasinya:
Kami sentiasa melihat berapa kali prestasinya dipertingkatkan. (dalam publisiti), tetapi Apabila saya menjalankan Llama 2 sendiri, saya masih boleh memproses berpuluh-puluh token sesaat.
Untuk TensorRT, kami memerlukan ujian lanjut untuk menentukan sama ada ia benar-benar berkesan. Mari kita lihat dengan lebih dekat TensorRT
Menggandakan kelajuan inferens model besar
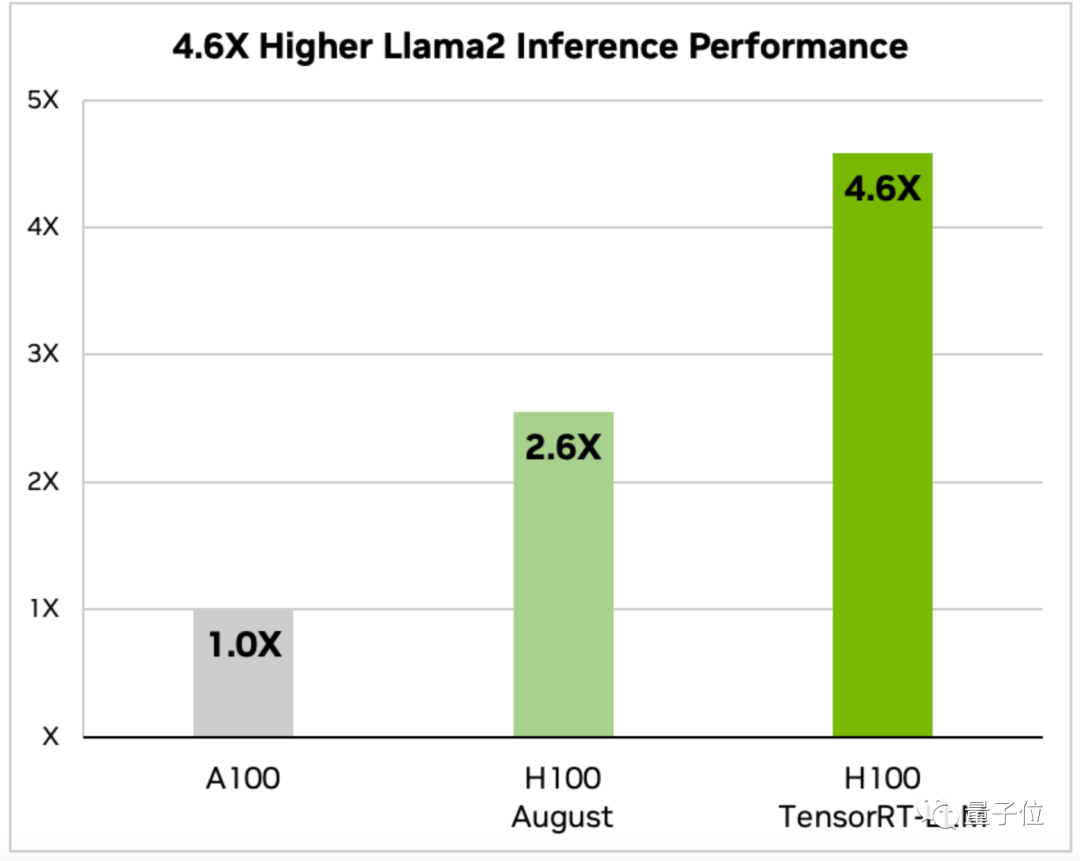
TensorRT-LLM dioptimumkan H100 Seberapa pantas untuk menjalankan model besar?
Pengumuman Nvidia menyediakan data untuk dua model, Llama 2 dan GPT-J-6B. . daripada versi sebelumnya dan 2 kali ganda daripada versi Ogos yang tidak dioptimumkan
.
API ini menyepadukan pengkompil pembelajaran mendalam, pengoptimuman kernel, pra/pasca pemprosesan dan fungsi komunikasi berbilang nod. .
Terdapat juga versi tersuai untuk model biasa seperti GPT(2/3) dan Llama, yang boleh digunakan"di luar kotak"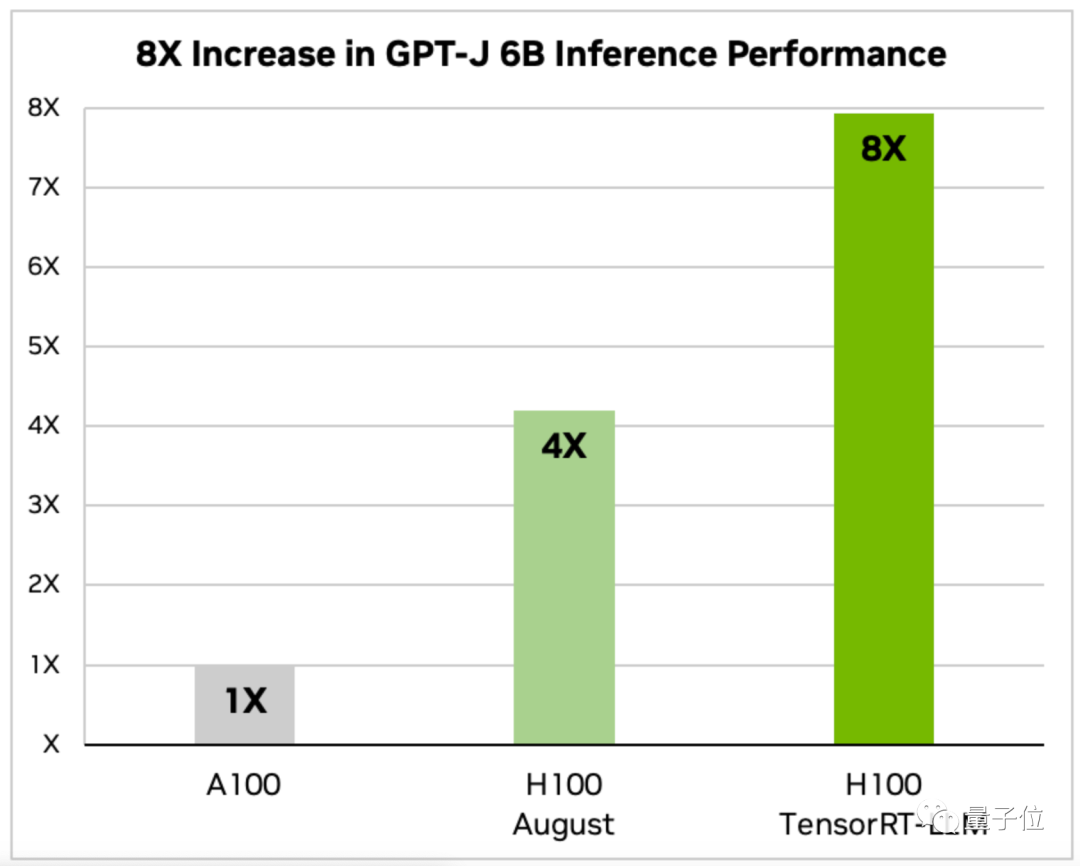 .
.
Melalui kernel AI sumber terbuka terkini dalam TensorRT, pembangun juga boleh mengoptimumkan model itu sendiri, termasuk algoritma perhatian FlashAttention, yang sangat mempercepatkan Transformer.
TensorRT ialah enjin inferens berprestasi tinggi untuk mengoptimumkan inferens pembelajaran mendalam. Ia mengoptimumkan kelajuan inferens LLM dengan menggunakan teknologi seperti pengkomputeran ketepatan campuran, pengoptimuman graf dinamik dan gabungan lapisan. Khususnya, TensorRT meningkatkan kelajuan inferens dengan mengurangkan jumlah pengiraan dan keperluan lebar jalur memori dengan menukar pengiraan titik terapung kepada pengiraan titik terapung separuh ketepatan. Selain itu, TensorRT juga menggunakan teknologi pengoptimuman graf dinamik untuk memilih struktur rangkaian optimum secara dinamik berdasarkan ciri-ciri data input, meningkatkan lagi kelajuan inferens. Selain itu, TensorRT juga menggunakan teknologi gabungan lapisan untuk menggabungkan berbilang lapisan pengkomputeran ke dalam lapisan pengkomputeran yang lebih cekap, mengurangkan pengkomputeran dan akses memori overhed dan meningkatkan lagi kelajuan inferens. Ringkasnya, TensorRT telah meningkatkan dengan ketara kelajuan dan kecekapan inferens LLM melalui pelbagai teknologi pengoptimuman
Pertama sekali, ia mendapat manfaat daripada TensorRTmengoptimumkan kaedah kerja kolaboratif berbilang nod.
Model besar seperti Llama tidak boleh dijalankan pada satu kad. Ia memerlukan berbilang GPU untuk dijalankan bersama.
Pada masa lalu, kerja ini memerlukan orang ramai untuk membuka model secara manual untuk mencapainya.
Dengan TensorRT, sistem boleh memisahkan model secara automatik dan menjalankannya dengan cekap merentas berbilang GPU melalui NVLink

Kedua, TensorRT juga menggunakan penjadualan yang dioptimumkan yang dipanggil teknologi Pemprosesan Kelompok Dinamik.
Semasa proses inferens, LLM sebenarnya meneruskan dengan melaksanakan lelaran model beberapa kali
Teknologi batching dinamik akan menendang keluar urutan yang lengkap serta-merta dan bukannya menunggu keseluruhan kumpulan tugasan selesai sebelum memproses set permintaan seterusnya .
Dalam ujian sebenar, teknologi batching dinamik berjaya mengurangkan pemprosesan permintaan GPU LLM sebanyak separuh, sekali gus mengurangkan kos operasi dengan ketara
Satu lagi perkara penting ialah menukar nombor titik terapung ketepatan 16-bit kepada Ketepatan 8-bit , sekali gus mengurangkan penggunaan memori.
Berbanding dengan FP16 dalam fasa latihan, FP8 mempunyai penggunaan sumber yang lebih rendah dan lebih tepat berbanding INT-8 Ia boleh meningkatkan prestasi tanpa menjejaskan ketepatan model
Menggunakan enjin Hopper Transformer, sistem akan melengkapkan FP16 secara automatik kepada kompilasi penukaran FP8 tanpa mengubah suai mana-mana kod secara manual dalam model
Pada masa ini, versi awal TensorRT-LLM tersedia untuk dimuat turun, dan versi rasmi akan dilancarkan dan disepadukan ke dalam rangka kerja NeMo dalam masa beberapa minggu
Satu Lagi Perkara
Setiap kali peristiwa besar berlaku, sosok "Leewenhoek" amat diperlukan.
Dalam pengumuman Nvidia, ia menyebut kerjasama dengan syarikat kecerdasan buatan terkemuka seperti Meta, tetapi tidak menyebut OpenAI
Daripada pengumuman ini, beberapa netizen menemui perkara ini dan menyiarkannya ke forum OpenAI:
Sila Izinkan saya lihat siapa belum mendapat petunjuk oleh Lao Huang (kepala anjing manual)

Apakah jenis "kejutan" yang anda jangkakan Lao Huang akan bawakan kepada kami?
Atas ialah kandungan terperinci Lao Huang memberikan H100 rangsangan: Nvidia melancarkan pakej pecutan model besar, menggandakan kelajuan inferens Llama2. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Artikel ini menerangkan cara menyesuaikan tahap pembalakan pelayan Apacheweb dalam sistem Debian. Dengan mengubah suai fail konfigurasi, anda boleh mengawal tahap maklumat log yang direkodkan oleh Apache. Kaedah 1: Ubah suai fail konfigurasi utama untuk mencari fail konfigurasi: Fail konfigurasi apache2.x biasanya terletak di direktori/etc/apache2/direktori. Nama fail mungkin apache2.conf atau httpd.conf, bergantung pada kaedah pemasangan anda. Edit Fail Konfigurasi: Buka Fail Konfigurasi dengan Kebenaran Root Menggunakan Editor Teks (seperti Nano): Sudonano/ETC/APACHE2/APACHE2.CONF
 Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Dalam sistem Debian, panggilan sistem Readdir digunakan untuk membaca kandungan direktori. Jika prestasinya tidak baik, cuba strategi pengoptimuman berikut: Memudahkan bilangan fail direktori: Split direktori besar ke dalam pelbagai direktori kecil sebanyak mungkin, mengurangkan bilangan item yang diproses setiap panggilan readdir. Dayakan Caching Kandungan Direktori: Bina mekanisme cache, kemas kini cache secara teratur atau apabila kandungan direktori berubah, dan mengurangkan panggilan kerap ke Readdir. Cafh memori (seperti memcached atau redis) atau cache tempatan (seperti fail atau pangkalan data) boleh dipertimbangkan. Mengamalkan struktur data yang cekap: Sekiranya anda melaksanakan traversal direktori sendiri, pilih struktur data yang lebih cekap (seperti jadual hash dan bukannya carian linear) untuk menyimpan dan mengakses maklumat direktori
 Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Dalam sistem Debian, fungsi Readdir digunakan untuk membaca kandungan direktori, tetapi urutan yang dikembalikannya tidak ditentukan sebelumnya. Untuk menyusun fail dalam direktori, anda perlu membaca semua fail terlebih dahulu, dan kemudian menyusunnya menggunakan fungsi QSORT. Kod berikut menunjukkan cara menyusun fail direktori menggunakan ReadDir dan QSORT dalam sistem Debian:#termasuk#termasuk#termasuk#termasuk // fungsi perbandingan adat, yang digunakan untuk qSortintCompare (Constvoid*A, Constvoid*b) {Returnstrcmp (*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(
 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
 Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Dalam sistem Debian, OpenSSL adalah perpustakaan penting untuk pengurusan penyulitan, penyahsulitan dan sijil. Untuk mengelakkan serangan lelaki-dalam-pertengahan (MITM), langkah-langkah berikut boleh diambil: Gunakan HTTPS: Pastikan semua permintaan rangkaian menggunakan protokol HTTPS dan bukannya HTTP. HTTPS menggunakan TLS (Protokol Keselamatan Lapisan Pengangkutan) untuk menyulitkan data komunikasi untuk memastikan data tidak dicuri atau diganggu semasa penghantaran. Sahkan Sijil Pelayan: Sahkan secara manual Sijil Pelayan pada klien untuk memastikan ia boleh dipercayai. Pelayan boleh disahkan secara manual melalui kaedah perwakilan urlSession
 Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Menguruskan Log Hadoop pada Debian, anda boleh mengikuti langkah-langkah berikut dan amalan terbaik: Agregasi log membolehkan pengagregatan log: tetapkan benang.log-agregasi-enable untuk benar dalam fail benang-site.xml untuk membolehkan pengagregatan log. Konfigurasikan dasar pengekalan log: tetapkan yarn.log-aggregasi.Retain-seconds Untuk menentukan masa pengekalan log, seperti 172800 saat (2 hari). Nyatakan Laluan Penyimpanan Log: Melalui Benang
