


#🎜🎜🎜🎜 pertama sekali, pemahaman kita tentang Persepsi kandungan multimodal.
1. Pemahaman pelbagai mod Meningkatkan keupayaan pemahaman kandungan, membolehkan sistem pengiklanan memahami kandungan dengan lebih baik dalam senario tersegmen.
Apabila meningkatkan keupayaan pemahaman kandungan, anda akan menghadapi banyak masalah praktikal:
#🎜 🎜🎜#
Adalah perlu untuk meluaskan skop aplikasi data dari segi keluasan, untuk meningkatkan kesan visual dari segi kedalaman, dan pada masa yang sama memastikan penalaan halus data daripada tempat kejadian.
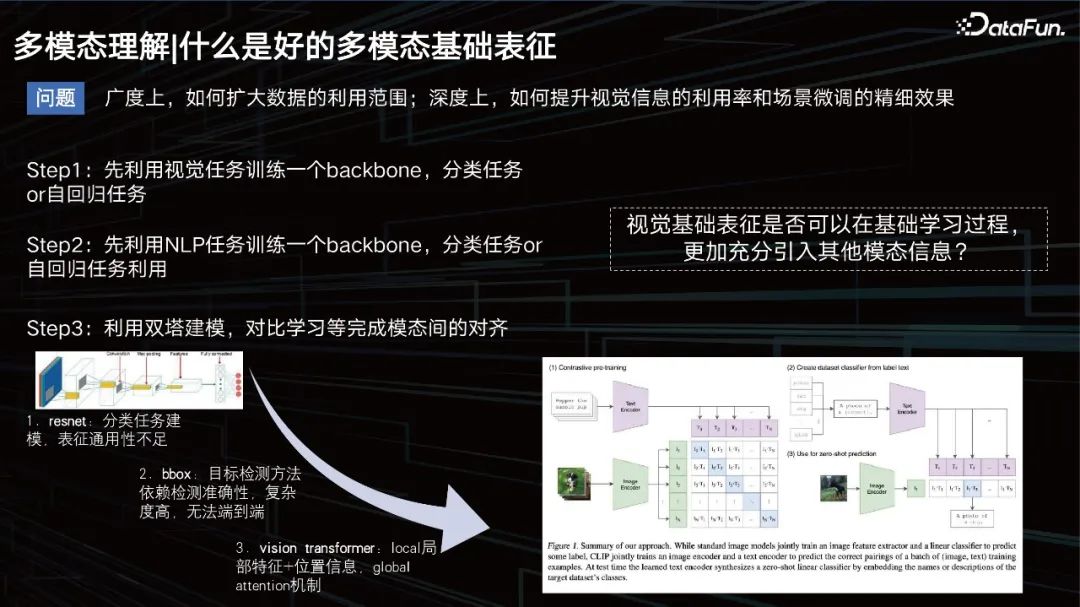
Sebelum ini, idea konvensional adalah untuk melatih model untuk mempelajari modaliti imej, tugas autoregresif, dan kemudian melakukan tugasan teks, dan kemudian menggunakan beberapa model menara berkembar untuk merapatkan hubungan modal antara keduanya. Pada masa itu, pemodelan teks agak mudah, dan semua orang lebih mempelajari cara memodelkan penglihatan. Ia bermula dengan CNN, dan kemudiannya memasukkan beberapa kaedah berdasarkan pengesanan sasaran untuk meningkatkan perwakilan visual, seperti kaedah bbox Walau bagaimanapun, kaedah ini mempunyai keupayaan pengesanan yang terhad dan terlalu berat, yang tidak sesuai untuk latihan data berskala besar.
Menjelang 2020 dan 2021, kaedah VIT telah menjadi arus perdana. Salah satu model yang lebih terkenal yang perlu saya nyatakan di sini ialah CLIP, model yang dikeluarkan oleh OpenAI pada tahun 2020, yang berdasarkan seni bina menara berkembar untuk perwakilan teks dan visual. Kemudian gunakan kosinus untuk menutup jarak antara keduanya. Model ini sangat baik untuk mendapatkan semula, tetapi kurang berkemampuan dalam beberapa tugas yang memerlukan penaakulan logik seperti tugas VQA.
Perwakilan pembelajaran:
Meningkatkan keupayaan persepsi asas bahasa semula jadi terhadap penglihatan.
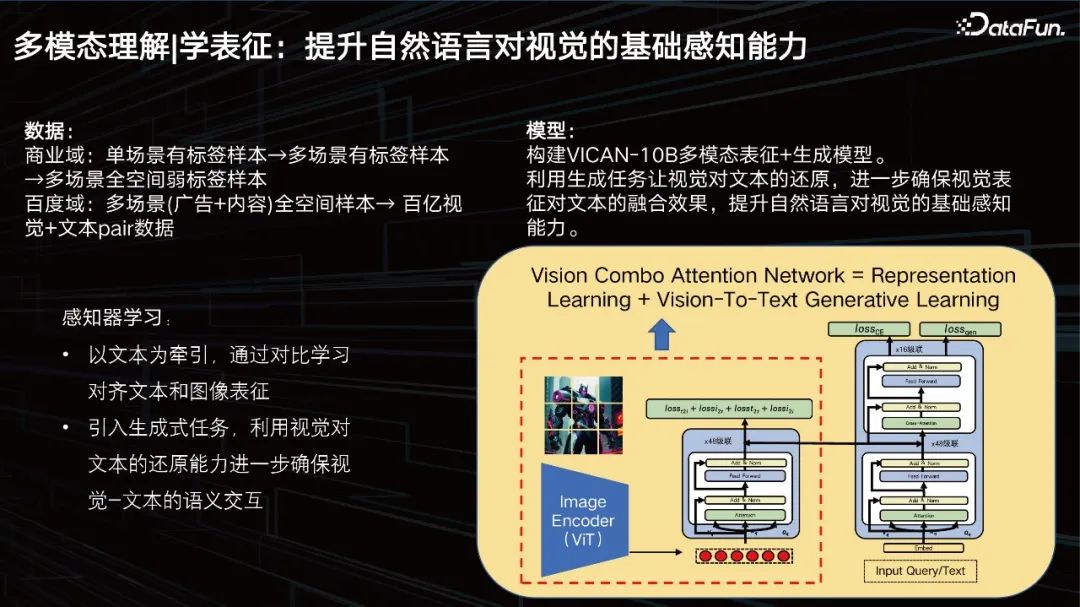
Kami membina model perwakilan + penjanaan berbilang mod VICAN-12B, menggunakan tugas penjanaan untuk membenarkan pemulihan visual teks, dan seterusnya memastikan kesan gabungan perwakilan visual pada teks. Meningkatkan keupayaan persepsi asas bahasa semula jadi kepada penglihatan. Gambar di atas menunjukkan struktur keseluruhan model Anda boleh melihat bahawa ia adalah struktur komposit menara berkembar + menara tunggal. Kerana perkara pertama yang perlu diselesaikan ialah tugas mendapatkan imej berskala besar. Bahagian dalam kotak di sebelah kiri adalah apa yang kita panggil visual perceptron, iaitu struktur ViT dengan skala 2 bilion parameter. Bahagian kanan boleh dilihat dalam dua lapisan Bahagian bawah adalah timbunan pengubah teks untuk mendapatkan semula, dan bahagian atas adalah untuk penjanaan. Model ini dibahagikan kepada tiga tugas, satu tugas generasi, satu tugas klasifikasi, dan satu lagi tugas perbandingan gambar Model ini dilatih berdasarkan tiga matlamat yang berbeza ini, jadi ia telah mencapai keputusan yang agak baik, tetapi kami akan mengoptimumkannya lagi.
Satu set penyelesaian perwakilan global berbilang senario yang cekap, bersatu dan boleh dipindahkan.
Digabungkan dengan data senario perniagaan, model LLM diperkenalkan untuk meningkatkan keupayaan pemahaman model. Model CV ialah perceptron dan model LLM ialah pemaham. Pendekatan kami adalah untuk memindahkan ciri visual dengan sewajarnya, kerana seperti yang dinyatakan sebentar tadi, perwakilan adalah berbilang modal dan model besar adalah berdasarkan teks. Kami hanya perlu menyesuaikannya dengan model besar Wenxin LLM kami, jadi kami perlu menggunakan perhatian Combo untuk melakukan gabungan ciri yang sepadan. Kami perlu mengekalkan keupayaan penaakulan logik model besar, jadi kami cuba untuk tidak membiarkan model besar sahaja dan hanya menambah data maklum balas senario perniagaan untuk menggalakkan penyepaduan ciri visual ke dalam model besar. Kita boleh menggunakan beberapa pukulan untuk menyokong tugasan. Tugas utama termasuk:
Di bawah, saya akan menumpukan pada penalaan halus berasaskan adegan.
Senario pengambilan visual, penalaan halus menara berkembar berdasarkan perwakilan asas.
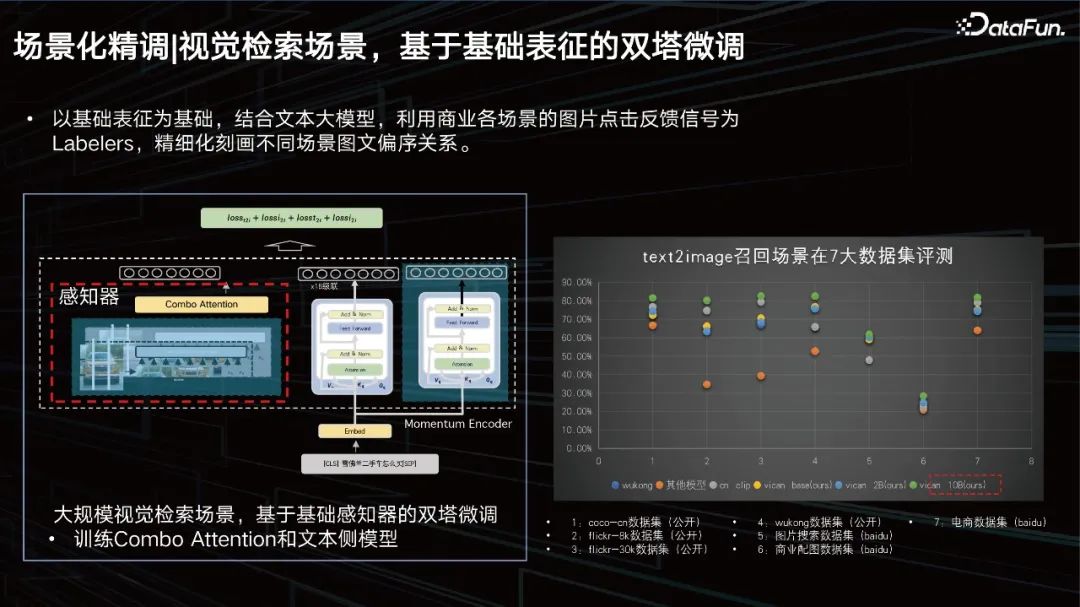
Berdasarkan perwakilan asas, digabungkan dengan model teks besar, isyarat maklum balas klik gambar dari pelbagai adegan perniagaan digunakan sebagai Pelabel untuk memperhalusi pencirian Hubungan susunan separa antara gambar dan teks dalam adegan yang berbeza. Kami telah menjalankan penilaian ke atas 7 set data utama, dan kesemuanya boleh mencapai keputusan SOTA.
Senario pengisihan, diilhamkan oleh pembahagian teks, mengukur semantik ciri berbilang modal.
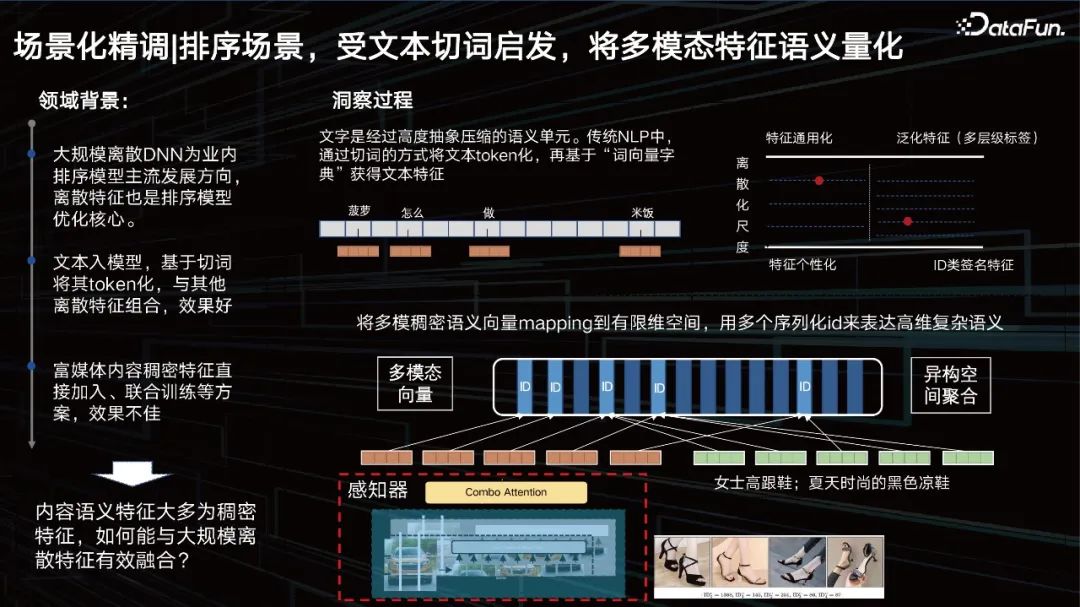
Selain pencirian, masalah lain ialah bagaimana untuk meningkatkan kesan visual dalam adegan pengisihan. Mari kita lihat latar belakang medan berskala besar DNN diskret ialah arah pembangunan arus perdana model kedudukan dalam industri, dan ciri diskret juga merupakan teras pengoptimuman model kedudukan. Teks dimasukkan ke dalam model, ditandakan berdasarkan pembahagian perkataan, dan digabungkan dengan ciri diskret lain untuk mencapai hasil yang baik. Bagi visi, kami berharap untuk mengiktirafnya juga.
Ciri jenis ID sebenarnya merupakan ciri yang sangat diperibadikan, tetapi apabila ciri umum menjadi lebih serba boleh, ketepatan penciriannya mungkin menjadi lebih teruk. Kita perlu melaraskan titik imbangan ini secara dinamik melalui data dan tugasan. Maksudnya, kami berharap dapat mencari skala yang paling berkaitan dengan data, untuk "membahagikan" ciri ke dalam ID dengan sewajarnya dan untuk membahagikan ciri berbilang modal seperti teks. Oleh itu, kami mencadangkan kaedah pembelajaran kuantifikasi kandungan berskala berbilang peringkat untuk menyelesaikan masalah ini.
Isih senario, gabungan ciri berbilang modal dan model MmDict.
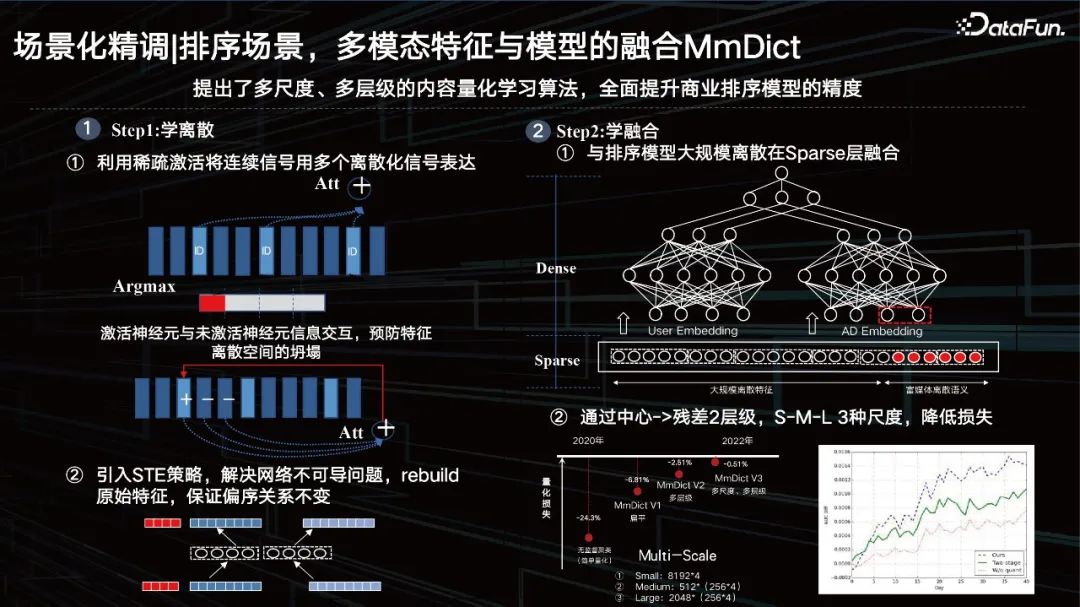
Ia terbahagi kepada dua langkah pertama ialah mempelajari kebijaksanaan, dan langkah kedua ialah mempelajari integrasi.
① Gunakan pengaktifan jarang untuk menyatakan isyarat berterusan dengan beberapa isyarat diskret. iaitu, melalui penyahaktifan; ciri dan kemudian mengaktifkan ID dalam buku kod berbilang modal yang sepadan Walau bagaimanapun, hanya terdapat operasi argmax, yang akan membawa kepada masalah yang tidak boleh dibezakan Pada masa yang sama, untuk mengelakkan keruntuhan ruang ciri, neuron pengaktifan Interaksi maklumat neuron tidak aktif.
② Memperkenalkan strategi STE untuk menyelesaikan masalah ketakbolehbezaan rangkaian, membina semula ciri asal dan memastikan perhubungan pesanan separa kekal tidak berubah.
Melalui kaedah pengekod-penyahkod, ciri padat dikuantasikan urutan, dan kemudian ciri terkuantasi dipulihkan dengan cara yang betul. Adalah perlu untuk memastikan bahawa hubungan pesanan separanya kekal tidak berubah sebelum dan selepas pemulihan, dan ia hampir boleh mengawal kehilangan kuantitatif ciri pada tugas tertentu kepada kurang daripada 1%. mempunyai sifat generalisasi.
① Gabungan dengan model pengisihan pada lapisan Jarang untuk pendiskretan berskala besar.
Kemudian penggunaan semula lapisan tersembunyi yang disebut tadi diletakkan terus di atas, tetapi kesannya adalah purata. Jika anda mengecamnya, mengukurnya dan menggabungkannya dengan lapisan ciri yang jarang dan jenis ciri lain, ia akan mempunyai kesan yang lebih baik.
② Melalui pusat -> baki 2 tingkat, S-M-L 3 skala, kurangkan kerugian.
Sudah tentu kami juga menggunakan beberapa kaedah sisa dan pelbagai skala. Mulai tahun 2020, kami telah menurunkan kerugian kuantifikasi secara beransur-ansur, mencecah di bawah satu mata tahun lepas, supaya selepas model besar mengekstrak ciri, kami boleh menggunakan kaedah kuantifikasi yang boleh dipelajari ini untuk mencirikan kandungan visual, dengan ID perkaitan semantik Ciri-ciri sebenarnya sangat sesuai untuk sistem perniagaan semasa kami, termasuk kaedah penyelidikan penerokaan sedemikian pada ID sistem pengesyoran.

#🎜 🎜🎜#Gesaan perniagaan yang baik mempunyai elemen berikut: 
Peta pengetahuan, contohnya, menjual kereta, apa sebenarnya yang diperlukan untuk kereta? Apakah elemen komersial yang disertakan? tajuk atau penerangan pemasaran itu.
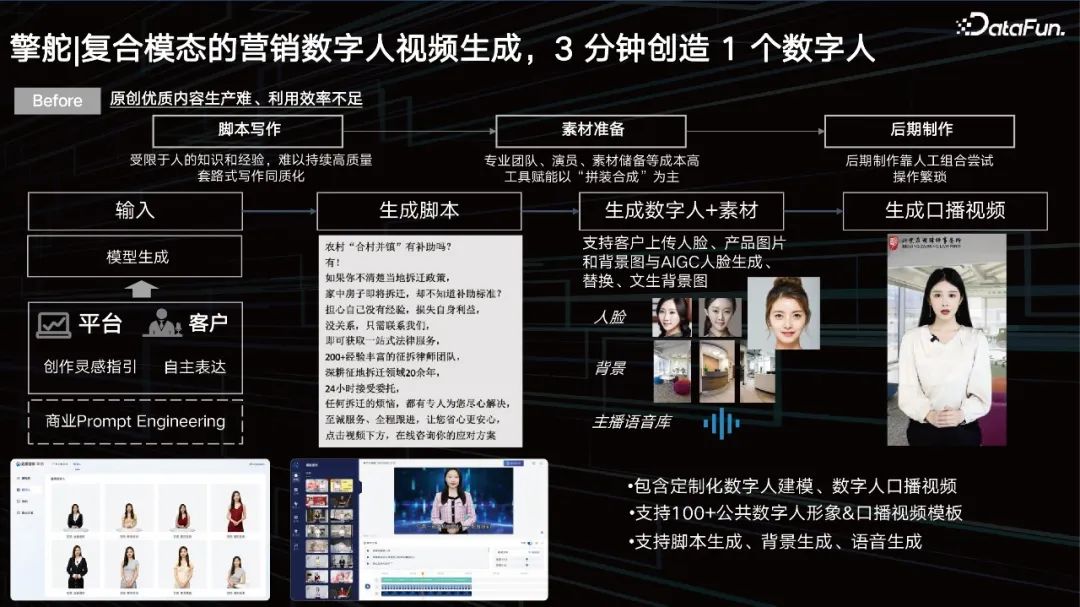 Penyediaan bahan: Pasukan profesional, pelakon, rizab bahan dan alat kos tinggi lain diperkasakan, memfokuskan pada "pemasangan dan sintesis".
Penyediaan bahan: Pasukan profesional, pelakon, rizab bahan dan alat kos tinggi lain diperkasakan, memfokuskan pada "pemasangan dan sintesis".
Pasca pengeluaran: Pasca pengeluaran bergantung pada percubaan dan kesilapan manual, dan operasinya menyusahkan.
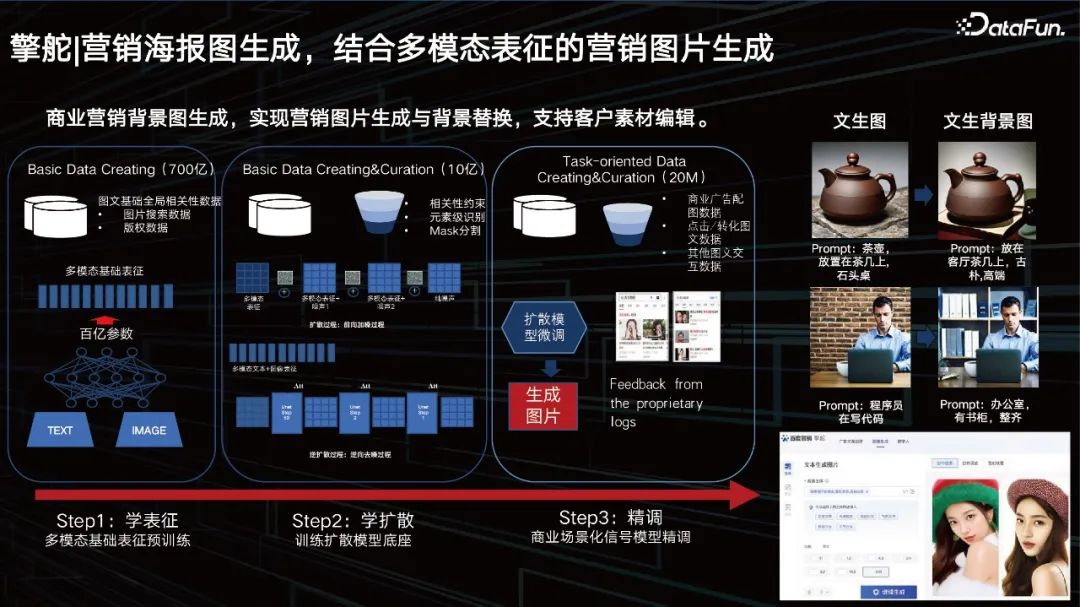
Model besar juga boleh membantu perniagaan Menyedari penjanaan poster pemasaran dan penggantian latar belakang produk. Kami sudah mempunyai berpuluh-puluh bilion perwakilan berbilang modal Lapisan tengah ialah penyebaran yang kami pelajari berdasarkan perwakilan dinamik yang baik. Selepas latihan dengan data besar, pelanggan juga mahukan sesuatu yang diperibadikan secara khusus, jadi kami juga perlu menambah beberapa kaedah penalaan halus.
Kami menyediakan penyelesaian untuk membantu pelanggan memperhalusi, penyelesaian untuk memuatkan parameter kecil secara dinamik untuk model besar, yang juga merupakan penyelesaian biasa dalam industri.
Pertama sekali, kami menyediakan pelanggan dengan keupayaan menjana gambar. Pelanggan boleh menukar latar belakang di belakang gambar melalui pengeditan atau gesaan.
Atas ialah kandungan terperinci Pemahaman Multimodal Perniagaan Baidu dan Amalan Inovasi AIGC. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 pemasangan windows10 gagal
pemasangan windows10 gagal
 Bagaimana untuk menetapkan pembolehubah persekitaran linux
Bagaimana untuk menetapkan pembolehubah persekitaran linux
 Bagaimana untuk meninggalkan dua ruang kosong dalam perenggan dalam html
Bagaimana untuk meninggalkan dua ruang kosong dalam perenggan dalam html
 Tiada penyesuai rangkaian dalam pengurus peranti
Tiada penyesuai rangkaian dalam pengurus peranti
 Pemacu kad bunyi komputer riba
Pemacu kad bunyi komputer riba
 Penjelasan terperinci tentang acara onbeforeunload
Penjelasan terperinci tentang acara onbeforeunload
 Apakah kekunci pintasan yang biasa digunakan dalam WPS?
Apakah kekunci pintasan yang biasa digunakan dalam WPS?
 Bagaimana untuk menetapkan pembalut baris automatik dalam perkataan
Bagaimana untuk menetapkan pembalut baris automatik dalam perkataan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



