
 Peranti teknologi
AI
Kekurangan data berkualiti tinggi untuk melatih model besar? Kami menemui penyelesaian baharu
Peranti teknologi
AI
Kekurangan data berkualiti tinggi untuk melatih model besar? Kami menemui penyelesaian baharu
Kekurangan data berkualiti tinggi untuk melatih model besar? Kami menemui penyelesaian baharu

Data, sebagai salah satu daripada tiga faktor utama yang menentukan prestasi model pembelajaran mesin, menjadi halangan yang menyekat pembangunan model besar. Seperti kata pepatah "Sampah masuk, sampah keluar" [1], tidak kira betapa baiknya algoritma anda dan sehebat mana sumber pengkomputeran anda, kualiti model secara langsung bergantung pada data yang anda gunakan untuk melatih model.
Dengan kemunculan pelbagai model besar sumber terbuka, kepentingan data diserlahkan lagi, terutamanya data industri berkualiti tinggi. Bloomberg membina model kewangan besar BloombergGPT berdasarkan rangka kerja GPT-3 sumber terbuka, yang membuktikan kebolehlaksanaan membangunkan model besar untuk industri menegak berdasarkan rangka kerja model besar sumber terbuka. Malah, membina atau menyesuaikan model besar ringan sumber tertutup untuk industri menegak ialah laluan yang dipilih oleh kebanyakan syarikat permulaan model besar di China.
Dalam trek ini, data industri menegak berkualiti tinggi, penalaan halus dan keupayaan penjajaran berdasarkan pengetahuan profesional adalah penting - BloombergGPT adalah berdasarkan dokumen kewangan yang dikumpul oleh Bloomberg selama lebih daripada 40 tahun, dan korpus latihan mempunyai lebih banyak daripada 700 bilion token[2].
Walau bagaimanapun, mendapatkan data berkualiti tinggi bukanlah mudah. Beberapa kajian telah menunjukkan bahawa pada kadar semasa di mana model besar memakan data, data bahasa domain awam berkualiti tinggi, seperti buku, laporan berita, kertas saintifik, Wikipedia, dan lain-lain, akan kehabisan sekitar 2026 [3].
Terdapat sedikit sumber data Cina berkualiti tinggi yang tersedia secara terbuka, dan perkhidmatan data profesional domestik masih di peringkat awal Pengumpulan data, pembersihan, pelabelan dan pengesahan memerlukan banyak tenaga kerja dan sumber material. Dilaporkan bahawa kos mengumpul dan membersihkan 3TB data Cina berkualiti tinggi untuk pasukan model besar universiti domestik, termasuk memuat turun lebar jalur data, sumber storan data (data asal yang tidak dibersihkan ialah kira-kira 100TB) dan kos sumber CPU untuk pembersihan data, berjumlah kira-kira ratusan ribu Yuan.
Memandangkan pembangunan model besar semakin mendalam, untuk melatih model industri menegak yang memenuhi keperluan industri dan mempunyai ketepatan yang sangat tinggi, lebih banyak kepakaran industri dan malah data domain peribadi sulit komersial diperlukan. Walau bagaimanapun, disebabkan keperluan perlindungan privasi dan kesukaran dalam mengesahkan hak dan membahagikan keuntungan, syarikat sering tidak mahu, tidak dapat atau takut untuk berkongsi data mereka.
Adakah terdapat penyelesaian yang bukan sahaja dapat menikmati faedah keterbukaan dan perkongsian data, tetapi juga melindungi keselamatan dan privasi data?
Bolehkah pengkomputeran privasi memecahkan dilema?
Pengiraan yang memelihara privasi boleh menganalisis, memproses dan menggunakan data tanpa memastikan bahawa pembekal data tidak mendedahkan data asal Ia dianggap sebagai teknologi utama untuk menggalakkan peredaran dan transaksi elemen data[4] , Oleh itu, menggunakan pengkomputeran privasi untuk melindungi keselamatan data model besar nampaknya merupakan pilihan semula jadi.
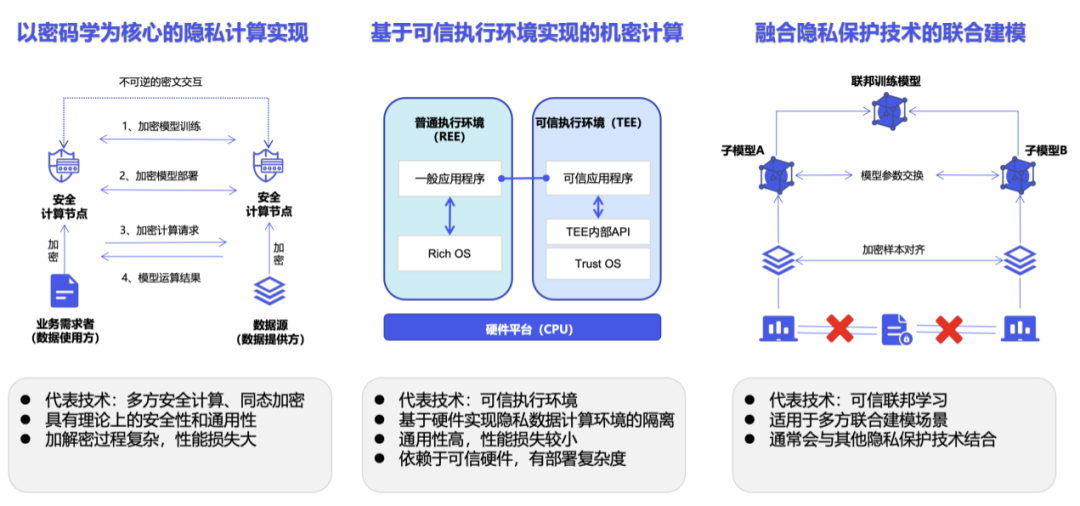
Pengkomputeran privasi bukan teknologi, tetapi sistem teknikal. Mengikut pelaksanaan khusus, pengkomputeran privasi terbahagi terutamanya kepada laluan kriptografi yang diwakili oleh pengkomputeran selamat berbilang pihak, laluan pengkomputeran sulit yang diwakili oleh persekitaran pelaksanaan yang dipercayai, dan laluan kecerdasan buatan yang diwakili oleh pembelajaran bersekutu [5].
Walau bagaimanapun, dalam aplikasi praktikal, pengkomputeran privasi mempunyai beberapa had. Sebagai contoh, pengenalan SDK pengkomputeran privasi biasanya membawa kepada pengubahsuaian peringkat kod kepada sistem perniagaan asal [6]. Jika ia dilaksanakan berdasarkan kriptografi, operasi penyulitan dan penyahsulitan akan meningkatkan jumlah pengiraan secara eksponen, dan pengiraan teks sifir memerlukan sumber pengkomputeran dan penyimpanan serta beban komunikasi yang lebih besar [7].
Selain itu, penyelesaian pengkomputeran privasi sedia ada akan menghadapi beberapa masalah baharu dalam senario latihan model besar yang melibatkan jumlah data yang sangat besar.
Skim Berasaskan Pembelajaran Bersekutu
Mari kita lihat dahulu kesukaran pembelajaran bersekutu. Idea teras pembelajaran bersekutu ialah "data tidak bergerak tetapi model bergerak". Setiap peranti atau pelayan mengambil bahagian dalam proses latihan dengan menghantar kemas kini model ke pelayan pusat, yang mengagregat dan menggabungkan kemas kini ini untuk menambah baik model global [8].
Walau bagaimanapun, latihan berpusat model besar sudah sangat sukar, dan kaedah latihan yang diedarkan sangat meningkatkan kerumitan sistem. Kami juga perlu mempertimbangkan kepelbagaian data apabila model dilatih pada pelbagai peranti, dan cara mengagregat pemberat pembelajaran dengan selamat merentas semua peranti - untuk latihan model besar, pemberat model itu sendiri merupakan aset penting. Selain itu, penyerang mesti dihalang daripada membuat kesimpulan data peribadi daripada kemas kini model tunggal, dan pertahanan yang sepadan akan meningkatkan lagi overhed latihan.
Penyelesaian berasaskan kriptografi
Penyulitan homomorfik boleh mengira secara langsung data yang disulitkan, menjadikan data itu "tersedia dan tidak kelihatan" [9]. Penyulitan homomorfik ialah alat yang berkuasa untuk melindungi privasi dalam senario di mana data sensitif diproses atau dianalisis dan kerahsiaannya dijamin. Teknik ini boleh digunakan bukan sahaja untuk latihan model besar, tetapi juga untuk membuat inferens sambil melindungi kerahsiaan input pengguna (prompt).
Walau bagaimanapun, menggunakan data yang disulitkan adalah lebih sukar daripada menggunakan data tidak disulitkan untuk latihan dan inferens model besar. Pada masa yang sama, pemprosesan data yang disulitkan memerlukan lebih banyak pengiraan, meningkatkan masa pemprosesan secara eksponen dan meningkatkan lagi keperluan kuasa pengkomputeran yang sudah sangat tinggi untuk melatih model besar.
Penyelesaian berdasarkan persekitaran pelaksanaan yang dipercayai#🎜🎜🎜🎜🎜🎜🎜 Mari kita bercakap tentang penyelesaian berdasarkan Persekitaran Pelaksanaan Dipercayai (TEE). Kebanyakan penyelesaian atau produk TEE memerlukan pembelian peralatan khusus tambahan, seperti nod pengkomputeran selamat berbilang pihak, peralatan persekitaran pelaksanaan yang dipercayai, kad pemecut kriptografi, dsb., dan tidak boleh menyesuaikan diri dengan sumber pengkomputeran dan storan sedia ada, menjadikan penyelesaian ini tidak sesuai untuk kebanyakan orang. perusahaan kecil dan sederhana Ia tidak realistik untuk perusahaan. Di samping itu, penyelesaian TEE semasa terutamanya berdasarkan CPU, manakala latihan model besar sangat bergantung pada GPU. Pada peringkat ini, penyelesaian GPU yang menyokong pengkomputeran privasi masih belum matang, sebaliknya mewujudkan risiko tambahan [10].
Secara umumnya, dalam senario pengkomputeran kolaboratif berbilang pihak, selalunya tidak munasabah untuk menghendaki data mentah menjadi "tidak kelihatan" dalam erti kata fizikal. Selain itu, memandangkan proses penyulitan menambah hingar pada data, latihan atau inferens pada data yang disulitkan juga akan menyebabkan kehilangan prestasi model dan mengurangkan ketepatan model. Penyelesaian pengkomputeran privasi sedia ada tidak sesuai untuk senario latihan model besar dari segi prestasi dan sokongan GPU. Ia juga menghalang perusahaan dan institusi yang mempunyai sumber data berkualiti tinggi daripada membuka dan berkongsi maklumat serta menyertai industri model besar.
Pengkomputeran boleh dikawal, paradigma baharu pengkomputeran persendirian Dilihat sebagai rantaian daripada data ke aplikasi, anda akan mendapati bahawa rantaian ini sebenarnya adalah rantaian edaran pelbagai data (termasuk data asal, termasuk data yang wujud dalam bentuk parameter dalam model) di kalangan entiti yang berbeza, dan perniagaan industri ini Model ini harus dibina berdasarkan data (atau model) yang beredar ini adalah aset yang boleh didagangkan,” kata Dr Tang Zaiyang, Ketua Pegawai Eksekutif YiZhi Technology.
"Peredaran elemen data melibatkan berbilang entiti, dan sumber rantaian industri mestilah pembekal data. Dalam erti kata lain, semua perniagaan sebenarnya disediakan oleh data Fang Lai memulakan bahawa urus niaga hanya boleh dilakukan jika diberi kuasa oleh pembekal data, jadi keutamaan harus diberikan untuk memastikan hak dan kepentingan penyedia data "
#🎜🎜. #Penyelesaian perlindungan privasi arus perdana pada masa ini di pasaran, seperti pengkomputeran selamat berbilang pihak, persekitaran pelaksanaan yang dipercayai dan pembelajaran bersekutu, semuanya menumpukan pada cara pengguna data memproses data perspektif pembekal data.
Yizhi Technology telah ditubuhkan pada 2019 dan diletakkan sebagai penyedia penyelesaian perlindungan privasi untuk kerjasama data. Pada tahun 2021, syarikat itu telah dipilih sebagai kumpulan pertama unit yang mengambil bahagian dalam "Inisiatif Keselamatan Data (DSI)" yang dimulakan oleh Akademi Teknologi Maklumat dan Komunikasi China, dan telah diperakui oleh DSI sebagai salah satu daripada sembilan wakil vendor perusahaan pengkomputeran privasi. . Pada tahun 2022, Yizhi Technology secara rasmi menjadi ahli komuniti sumber terbuka Open Islands, komuniti sumber terbuka pengkomputeran privasi bebas dan terkawal antarabangsa pertama di China, untuk bersama-sama mempromosikan pembinaan infrastruktur utama untuk peredaran elemen data.
Sebagai tindak balas kepada dilema data semasa latihan model besar, serta peredaran elemen data yang lebih luas, Yizhi Technology telah mencadangkan penyelesaian pengkomputeran privasi baharu berdasarkan amalan . Penyelesaian - Pengkomputeran Terkawal.
"Tumpuan teras pengkomputeran terkawal adalah untuk menemui dan berkongsi maklumat dengan cara memelihara privasi. Masalah yang kami selesaikan adalah dalam proses latihan Pastikan keselamatan data yang digunakan dan menghalang model terlatih daripada dicuri dengan niat jahat
" kata Tang Zaiyang.Khususnya, pengkomputeran boleh dikawal memerlukan pengguna data memproses dan memproses data dalam domain keselamatan yang ditakrifkan oleh pembekal data.
Contoh domain keselamatan dalam senario peredaran data#🎜🎜 Domain keselamatan ialah konsep logik yang merujuk kepada unit storan dan pengkomputeran yang dilindungi oleh kunci yang sepadan dan algoritma penyulitan. Domain keselamatan ditakrifkan dan dikekang oleh pembekal data, tetapi storan dan sumber pengkomputeran yang sepadan tidak disediakan oleh pembekal data. Dari segi fizikal, domain keselamatan berada pada bahagian pengguna data tetapi dikawal oleh pembekal data. Selain data mentah, data perantaraan yang diproses dan diproses serta data hasil juga berada dalam domain keselamatan yang sama. Dalam domain keselamatan, data boleh menjadi teks sifir (tidak kelihatan) atau teks biasa (kelihatan) Dalam kes plaintext, kerana julat data yang boleh dilihat dikawal, ia dipastikan bahawa data digunakan semasa keselamatan penggunaan). . Kemerosotan prestasi yang disebabkan oleh pengiraan teks sifir yang kompleks merupakan faktor penting yang mengehadkan skop aplikasi pengkomputeran privasi Dengan menekankan kebolehkawalan data dan bukannya mengejar halimunan secara membuta tuli, pengkomputeran boleh dikawal menyelesaikan masalah penyelesaian pengkomputeran privasi tradisional mengganggu perniagaan, jadi ia sangat sesuai untuk senario latihan model besar yang perlu memproses data berskala sangat besar. Perusahaan boleh memilih untuk menyimpan data mereka dalam berbilang domain keselamatan yang berbeza dan menetapkan tahap keselamatan yang berbeza, kebenaran penggunaan atau senarai putih untuk domain keselamatan ini. Untuk aplikasi yang diedarkan, domain keselamatan juga boleh ditetapkan pada berbilang nod komputer atau bahkan cip. "Domain keselamatan boleh dirangkai bersama. Dalam setiap pautan peredaran data, penyedia data boleh menentukan berbilang domain keselamatan yang berbeza supaya data mereka hanya boleh mengalir antara domain keselamatan ini. Akhirnya, domain keselamatan bersiri ini membina rangkaian data. Pada rangkaian ini, data boleh dikawal, aliran, analisis, dan pemprosesan data juga boleh diukur dan dipantau, dan peredaran data juga boleh diwangkan dengan sewajarnya. Berdasarkan idea pengkomputeran yang boleh dikawal, Teknologi YiZhi melancarkan "DataVault". Prinsip DataVault: Menggabungkan permulaan metrik Linux dan teknologi penyulitan cakera penuh Linux untuk mencapai kawalan dan perlindungan data dalam domain keselamatan. DataVault menggunakan Modul Platform Dipercayai TPM (Modul Platform Dipercayai, yang terasnya adalah untuk menyediakan fungsi berkaitan keselamatan berasaskan perkakasan) sebagai akar kepercayaan untuk melindungi integriti sistem ia menggunakan Modul Keselamatan Linux LSM ( Modul Keselamatan Linux, Linux Rangka kerja yang digunakan dalam kernel untuk menyokong pelbagai model keselamatan komputer, yang bebas daripada mana-mana teknologi pelaksanaan keselamatan individu supaya data dalam domain keselamatan hanya boleh digunakan dalam had yang boleh dikawal. Atas dasar ini, DataVault menggunakan teknologi penyulitan cakera penuh yang disediakan oleh Linux untuk meletakkan data dalam domain selamat YiZhi Technology telah membangunkan sendiri protokol kriptografi yang lengkap seperti pengedaran kunci dan kebenaran tandatangan, dan telah menghasilkan banyak. pengoptimuman kejuruteraan, seterusnya memastikan kebolehkawalan data. DataVault menyokong pelbagai kad pemecut khusus, termasuk CPU, GPU, FPGA dan perkakasan lain yang berbeza Ia juga menyokong pelbagai rangka kerja pemprosesan data dan rangka kerja latihan model, dan serasi binari. Lebih penting lagi, ia mempunyai kehilangan prestasi yang jauh lebih rendah daripada penyelesaian pengkomputeran privasi yang lain Dalam kebanyakan aplikasi, berbanding sistem asli (iaitu, tanpa sebarang teknologi pengkomputeran privasi), kehilangan prestasi keseluruhan tidak melebihi. 5% . Selepas menggunakan DataVault, kehilangan prestasi dalam penilaian (Penilaian) dan penilaian segera (Penilaian Segera) berdasarkan LLaMA-65B adalah kurang daripada 1‰. Kini, YiZhi Technology telah mencapai kerjasama dengan Pusat Pengkomputeran Super Nasional untuk menggunakan platform pengkomputeran berprestasi tinggi yang memelihara privasi untuk aplikasi AI pada platform pengkomputeran super. Berdasarkan DataVault, pengguna kuasa pengkomputeran boleh menetapkan domain keselamatan pada platform pengkomputeran untuk memastikan keseluruhan proses pemindahan data daripada nod storan kepada nod pengkomputeran hanya boleh bergerak antara domain keselamatan dan tidak meninggalkan julat yang ditetapkan. Selain memastikan data boleh dikawal semasa latihan model, berdasarkan penyelesaian DataVault, model besar terlatih itu sendiri, sebagai aset data, juga boleh dilindungi dan didagangkan dengan selamat. Pada masa ini, perusahaan yang ingin menggunakan model besar secara tempatan, seperti institusi data kewangan, perubatan dan lain-lain yang sangat sensitif, mengalami kekurangan infrastruktur untuk menjalankan model besar secara tempatan, termasuk kos latihan yang tinggi model besar. Perkakasan prestasi, dan pengalaman operasi dan penyelenggaraan seterusnya dalam menggunakan model besar. Bagi syarikat yang membina model industri yang besar, mereka bimbang jika model dihantar terus kepada pelanggan, data industri dan kepakaran terkumpul di sebalik model itu sendiri dan parameter model mungkin dijual semula. Sebagai penerokaan pelaksanaan model berskala besar dalam industri menegak, YiZhi Technology turut bekerjasama dengan Penyelidikan Ekonomi Digital Kawasan Teluk Besar Guangdong-Hong Kong-Macao Institut (Institut Penyelidikan IDEA), Kedua-dua pihak bersama-sama mencipta mesin semua-dalam-satu model besar dengan fungsi perlindungan keselamatan model. Mesin semua-dalam-satu ini mempunyai beberapa model besar terbina dalam untuk industri menegak dan dilengkapi dengan sumber pengkomputeran asas yang diperlukan untuk latihan dan promosi model besar, yang boleh memenuhi keperluan pelanggan di luar kotak, antaranya, YiZhi yang boleh dikawal komponen pengkomputeran DataVault boleh memastikan bahawa model terbina dalam ini hanya Apabila digunakan dengan kebenaran, model dan semua data perantaraan tidak boleh dicuri oleh persekitaran luaran. Sebagai paradigma pengkomputeran privasi baharu, Teknologi YiZhi berharap pengkomputeran yang boleh dikawal boleh membawa perubahan kepada industri model besar dan peredaran elemen data. 「DataVault hanyalah penyelesaian pelaksanaan yang ringan Memandangkan teknologi dan keperluan berubah, kami akan terus mengemas kini dan mempunyai lebih banyak percubaan dalam pasaran edaran elemen data Kami juga mengalu-alukan lebih banyak lagi rakan kongsi industri untuk menyertai dan membina komuniti pengkomputeran yang boleh dikawal,” kata Tang Zaiyang. 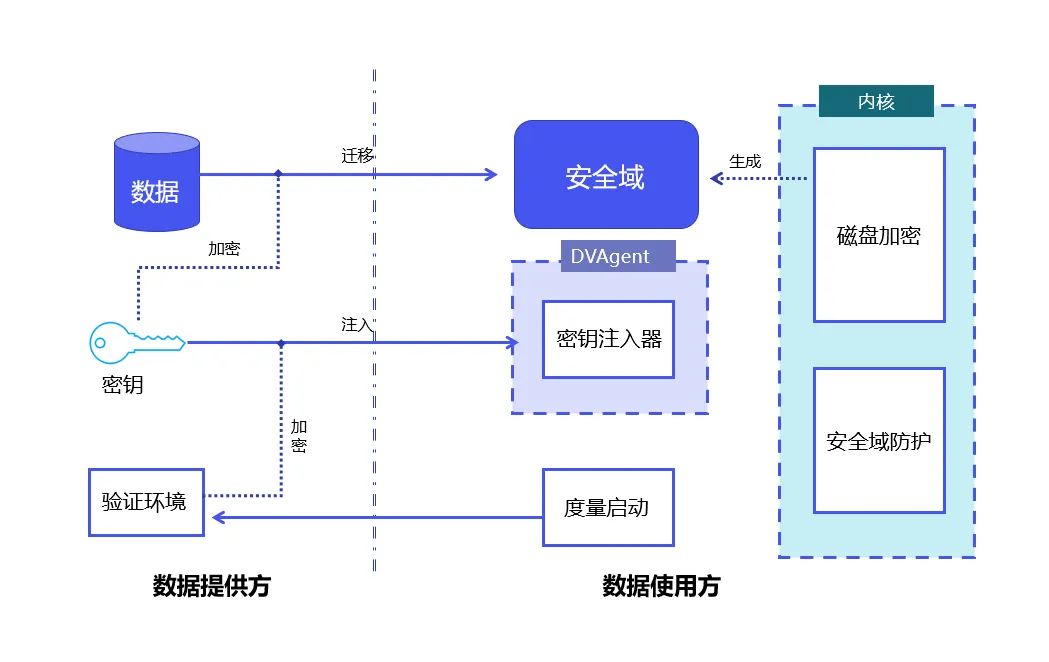
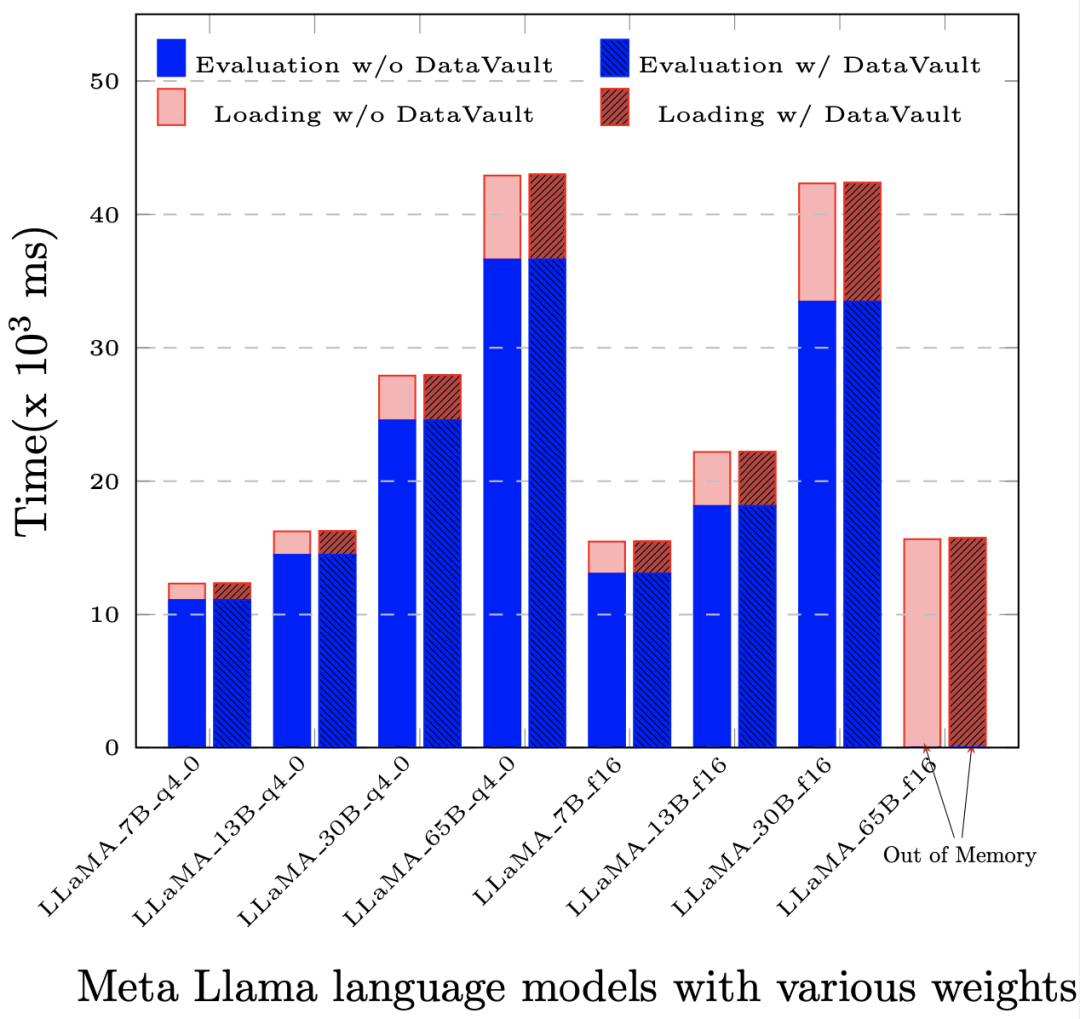
DataVault case untuk melindungi peredaran data dan model aset
Atas ialah kandungan terperinci Kekurangan data berkualiti tinggi untuk melatih model besar? Kami menemui penyelesaian baharu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100! Lao Huang mahu semua orang menggunakan INT8/INT4, dan pasukan Microsoft DeepSpeed memaksa diri mereka menjalankan FP6 pada A100 tanpa sokongan rasmi daripada Nvidia. Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx FP6 kuantisasi pada A100 adalah hampir atau kadangkala lebih pantas daripada INT4, dan mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Selain itu, terdapat juga sokongan model besar hujung ke hujung, yang telah bersumberkan terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Keputusan ini juga mempunyai kesan serta-merta pada mempercepatkan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad. satu
