
 Peranti teknologi
AI
Dengan AS$100,000 + 26 hari, LLM kos rendah dengan 100 bilion parameter telah dilahirkan
Peranti teknologi
AI
Dengan AS$100,000 + 26 hari, LLM kos rendah dengan 100 bilion parameter telah dilahirkan
Dengan AS$100,000 + 26 hari, LLM kos rendah dengan 100 bilion parameter telah dilahirkan


Kertas: https://arxiv.org/pdf/2309.03852.pdf
-
Kandungan yang perlu ditulis semula ialah: Pautan model: https://huggingface.co-CofeAI/FLM 101B
Bahasa bersifat simbolik. Terdapat beberapa kajian menggunakan simbol dan bukannya label kategori untuk menilai tahap kecerdasan LLM. Begitu juga, pasukan itu menggunakan pendekatan pemetaan simbolik untuk menguji keupayaan LLM untuk membuat generalisasi kepada konteks yang tidak kelihatan.
Keupayaan penting kecerdasan manusia ialah memahami peraturan yang diberikan dan mengambil tindakan yang sepadan. Kaedah ujian ini telah digunakan secara meluas dalam pelbagai peringkat ujian. Oleh itu, pemahaman peraturan menjadi ujian kedua di sini.
Kandungan yang ditulis semula: Perlombongan corak ialah bahagian penting kecerdasan, yang melibatkan aruhan dan deduksi. Dalam sejarah perkembangan sains, kaedah ini memainkan peranan yang penting. Selain itu, soalan ujian dalam pelbagai pertandingan selalunya memerlukan kebolehan menjawab ini. Atas sebab ini, kami memilih perlombongan corak sebagai penunjuk penilaian ketiga
Penunjuk terakhir dan sangat penting ialah keupayaan anti-gangguan, yang juga merupakan salah satu keupayaan teras kecerdasan. Kajian telah menunjukkan bahawa kedua-dua bahasa dan imej mudah terganggu oleh bunyi bising. Dengan mengambil kira perkara ini, pasukan menggunakan imuniti gangguan sebagai metrik penilaian akhir.
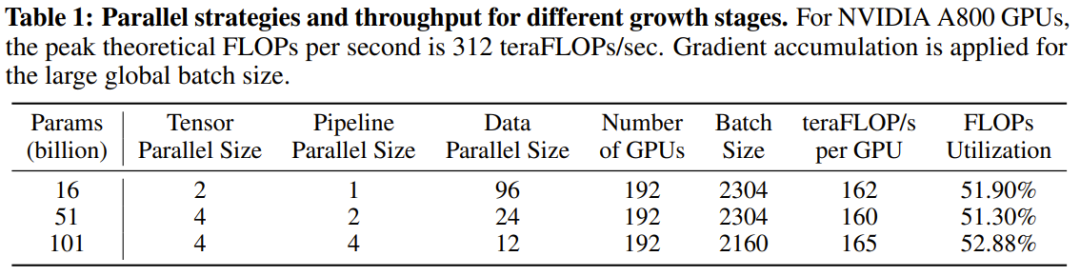
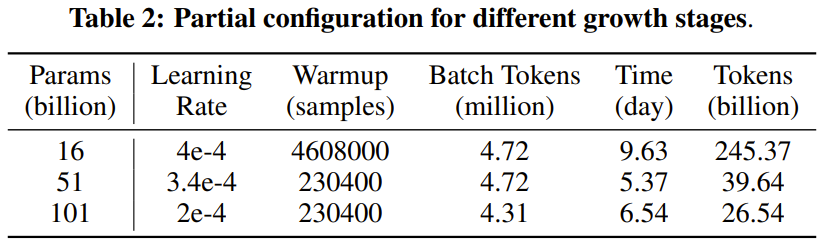
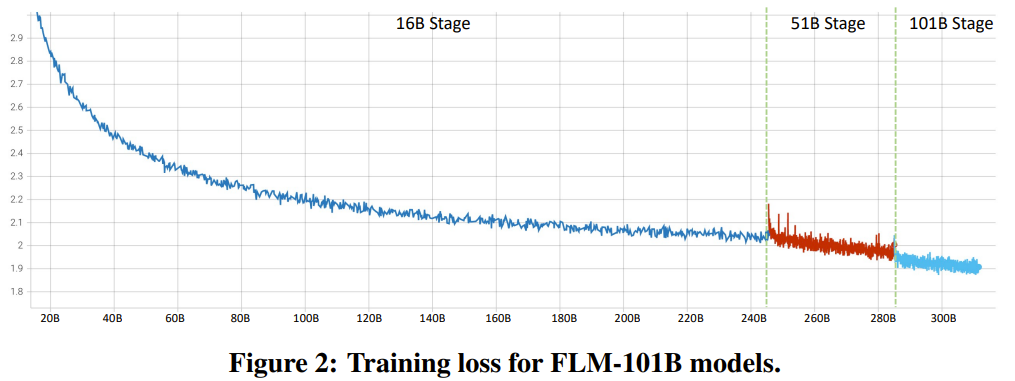
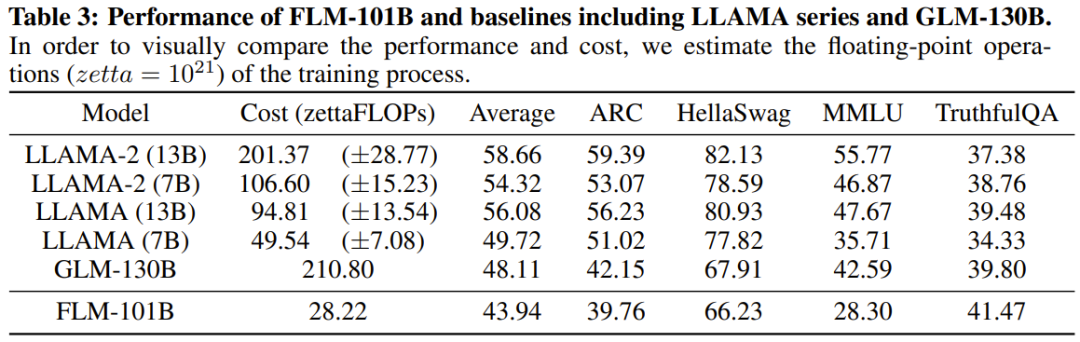
Pengkaji menyatakan bahawa ini adalah percubaan penyelidikan LLM untuk melatih lebih daripada 100 bilion parameter dari awal menggunakan strategi pertumbuhan. Pada masa yang sama, ini juga merupakan model parameter 100 bilion kos terendah pada masa ini, hanya berharga 100,000 dolar AS
Dengan menambah baik objektif latihan FreeLM, kaedah carian hiperparameter yang berpotensi dan pertumbuhan memelihara fungsi, penyelidikan ini menyelesaikan masalah ketidakstabilan . Para penyelidik percaya kaedah ini juga boleh membantu komuniti penyelidikan saintifik yang lebih luas.
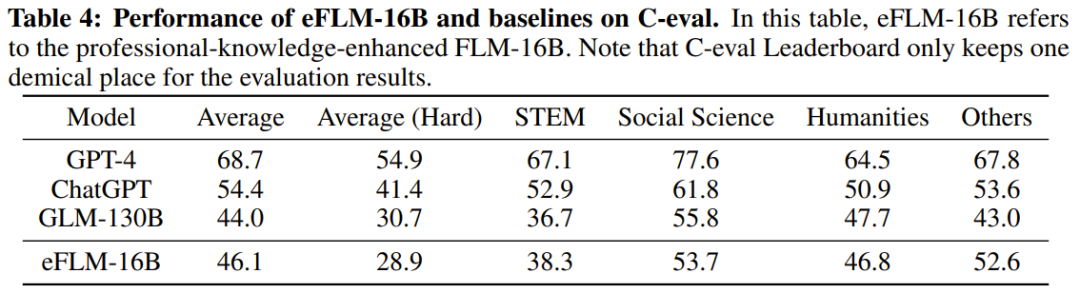
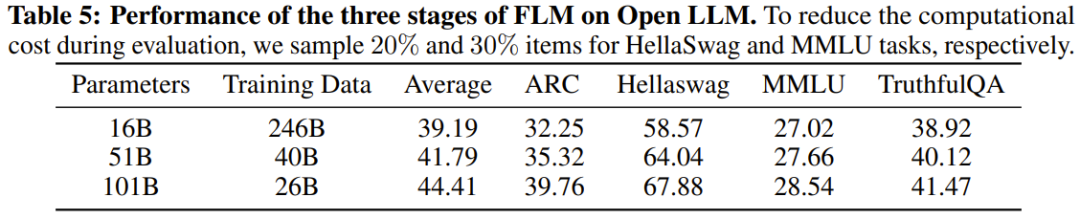
Para penyelidik juga menjalankan perbandingan percubaan model baharu dengan model yang berkuasa sebelum ini, termasuk menggunakan penanda aras berorientasikan pengetahuan dan penanda aras penilaian IQ sistematik yang baru dicadangkan. Keputusan eksperimen menunjukkan bahawa model FLM-101B adalah kompetitif dan teguh
Pasukan akan mengeluarkan pusat pemeriksaan model, kod, alatan berkaitan, dll. untuk mempromosikan penyelidikan dan pembangunan LLM dwibahasa dalam bahasa Cina dan Inggeris dengan skala 100 bilion parameter.
Atas ialah kandungan terperinci Dengan AS$100,000 + 26 hari, LLM kos rendah dengan 100 bilion parameter telah dilahirkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Apl model besar Tencent Yuanbao berada dalam talian! Hunyuan dinaik taraf untuk mencipta pembantu AI serba boleh yang boleh dibawa ke mana-mana
Jun 09, 2024 pm 10:38 PM
Apl model besar Tencent Yuanbao berada dalam talian! Hunyuan dinaik taraf untuk mencipta pembantu AI serba boleh yang boleh dibawa ke mana-mana
Jun 09, 2024 pm 10:38 PM
Pada 30 Mei, Tencent mengumumkan peningkatan menyeluruh model Hunyuannya Apl "Tencent Yuanbao" berdasarkan model Hunyuan telah dilancarkan secara rasmi dan boleh dimuat turun dari kedai aplikasi Apple dan Android. Berbanding dengan versi applet Hunyuan dalam peringkat ujian sebelumnya, Tencent Yuanbao menyediakan keupayaan teras seperti carian AI, ringkasan AI, dan penulisan AI untuk senario kecekapan kerja untuk senario kehidupan harian, permainan Yuanbao juga lebih kaya dan menyediakan pelbagai ciri , dan kaedah permainan baharu seperti mencipta ejen peribadi ditambah. "Tencent tidak akan berusaha untuk menjadi yang pertama membuat model besar, Liu Yuhong, naib presiden Tencent Cloud dan orang yang bertanggungjawab bagi model besar Tencent Hunyuan, berkata: "Pada tahun lalu, kami terus mempromosikan keupayaan untuk Model besar Tencent Hunyuan Dalam teknologi Poland yang kaya dan besar dalam senario perniagaan sambil mendapatkan cerapan tentang keperluan sebenar pengguna
 Model besar Bytedance Beanbao dikeluarkan, perkhidmatan AI tindanan penuh Volcano Engine membantu perusahaan mengubah dengan bijak
Jun 05, 2024 pm 07:59 PM
Model besar Bytedance Beanbao dikeluarkan, perkhidmatan AI tindanan penuh Volcano Engine membantu perusahaan mengubah dengan bijak
Jun 05, 2024 pm 07:59 PM
Tan Dai, Presiden Volcano Engine, berkata syarikat yang ingin melaksanakan model besar dengan baik menghadapi tiga cabaran utama: kesan model, kos inferens dan kesukaran pelaksanaan: mereka mesti mempunyai sokongan model besar asas yang baik untuk menyelesaikan masalah yang kompleks, dan mereka juga mesti mempunyai inferens kos rendah. Perkhidmatan membolehkan model besar digunakan secara meluas, dan lebih banyak alat, platform dan aplikasi diperlukan untuk membantu syarikat melaksanakan senario. ——Tan Dai, Presiden Huoshan Engine 01. Model pundi kacang besar membuat kemunculan sulungnya dan banyak digunakan Menggilap kesan model adalah cabaran paling kritikal untuk pelaksanaan AI. Tan Dai menegaskan bahawa hanya melalui penggunaan meluas model yang baik boleh digilap. Pada masa ini, model Doubao memproses 120 bilion token teks dan menjana 30 juta imej setiap hari. Untuk membantu perusahaan melaksanakan senario model berskala besar, model berskala besar beanbao yang dibangunkan secara bebas oleh ByteDance akan dilancarkan melalui gunung berapi
 Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Dalam pembuatan moden, pengesanan kecacatan yang tepat bukan sahaja kunci untuk memastikan kualiti produk, tetapi juga teras untuk meningkatkan kecekapan pengeluaran. Walau bagaimanapun, set data pengesanan kecacatan sedia ada selalunya tidak mempunyai ketepatan dan kekayaan semantik yang diperlukan untuk aplikasi praktikal, menyebabkan model tidak dapat mengenal pasti kategori atau lokasi kecacatan tertentu. Untuk menyelesaikan masalah ini, pasukan penyelidik terkemuka yang terdiri daripada Universiti Sains dan Teknologi Hong Kong Guangzhou dan Teknologi Simou telah membangunkan set data "DefectSpectrum" secara inovatif, yang menyediakan anotasi berskala besar yang kaya dengan semantik bagi kecacatan industri. Seperti yang ditunjukkan dalam Jadual 1, berbanding set data industri lain, set data "DefectSpectrum" menyediakan anotasi kecacatan yang paling banyak (5438 sampel kecacatan) dan klasifikasi kecacatan yang paling terperinci (125 kategori kecacatan
 Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Komuniti LLM terbuka ialah era apabila seratus bunga mekar dan bersaing Anda boleh melihat Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 dan banyak lagi. model yang cemerlang. Walau bagaimanapun, berbanding dengan model besar proprietari yang diwakili oleh GPT-4-Turbo, model terbuka masih mempunyai jurang yang ketara dalam banyak bidang. Selain model umum, beberapa model terbuka yang mengkhusus dalam bidang utama telah dibangunkan, seperti DeepSeek-Coder-V2 untuk pengaturcaraan dan matematik, dan InternVL untuk tugasan bahasa visual.
 Amalan lanjutan graf pengetahuan industri
Jun 13, 2024 am 11:59 AM
Amalan lanjutan graf pengetahuan industri
Jun 13, 2024 am 11:59 AM
1. Latar Belakang Pengenalan Pertama, mari kita perkenalkan sejarah pembangunan Teknologi Yunwen. Syarikat Teknologi Yunwen...2023 ialah tempoh apabila model besar berleluasa Banyak syarikat percaya bahawa kepentingan graf telah dikurangkan dengan ketara selepas model besar, dan sistem maklumat pratetap yang dikaji sebelum ini tidak lagi penting. Walau bagaimanapun, dengan promosi RAG dan kelaziman tadbir urus data, kami mendapati bahawa tadbir urus data yang lebih cekap dan data berkualiti tinggi adalah prasyarat penting untuk meningkatkan keberkesanan model besar yang diswastakan Oleh itu, semakin banyak syarikat mula memberi perhatian kepada kandungan berkaitan pembinaan pengetahuan. Ini juga menggalakkan pembinaan dan pemprosesan pengetahuan ke peringkat yang lebih tinggi, di mana terdapat banyak teknik dan kaedah yang boleh diterokai. Dapat dilihat bahawa kemunculan teknologi baru tidak mengalahkan semua teknologi lama, tetapi mungkin juga mengintegrasikan teknologi baru dan lama.
 Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Bagi AI, Olimpik Matematik tidak lagi menjadi masalah. Pada hari Khamis, kecerdasan buatan Google DeepMind menyelesaikan satu kejayaan: menggunakan AI untuk menyelesaikan soalan sebenar IMO Olimpik Matematik Antarabangsa tahun ini, dan ia hanya selangkah lagi untuk memenangi pingat emas. Pertandingan IMO yang baru berakhir minggu lalu mempunyai enam soalan melibatkan algebra, kombinatorik, geometri dan teori nombor. Sistem AI hibrid yang dicadangkan oleh Google mendapat empat soalan dengan betul dan memperoleh 28 mata, mencapai tahap pingat perak. Awal bulan ini, profesor UCLA, Terence Tao baru sahaja mempromosikan Olimpik Matematik AI (Anugerah Kemajuan AIMO) dengan hadiah berjuta-juta dolar Tanpa diduga, tahap penyelesaian masalah AI telah meningkat ke tahap ini sebelum Julai. Lakukan soalan secara serentak pada IMO Perkara yang paling sukar untuk dilakukan dengan betul ialah IMO, yang mempunyai sejarah terpanjang, skala terbesar dan paling negatif
 Pandangan alam semula jadi: Ujian kecerdasan buatan dalam perubatan berada dalam keadaan huru-hara Apa yang perlu dilakukan?
Aug 22, 2024 pm 04:37 PM
Pandangan alam semula jadi: Ujian kecerdasan buatan dalam perubatan berada dalam keadaan huru-hara Apa yang perlu dilakukan?
Aug 22, 2024 pm 04:37 PM
Editor |. ScienceAI Berdasarkan data klinikal yang terhad, beratus-ratus algoritma perubatan telah diluluskan. Para saintis sedang membahaskan siapa yang harus menguji alat dan cara terbaik untuk melakukannya. Devin Singh menyaksikan seorang pesakit kanak-kanak di bilik kecemasan mengalami serangan jantung semasa menunggu rawatan untuk masa yang lama, yang mendorongnya untuk meneroka aplikasi AI untuk memendekkan masa menunggu. Menggunakan data triage daripada bilik kecemasan SickKids, Singh dan rakan sekerja membina satu siri model AI untuk menyediakan potensi diagnosis dan mengesyorkan ujian. Satu kajian menunjukkan bahawa model ini boleh mempercepatkan lawatan doktor sebanyak 22.3%, mempercepatkan pemprosesan keputusan hampir 3 jam bagi setiap pesakit yang memerlukan ujian perubatan. Walau bagaimanapun, kejayaan algoritma kecerdasan buatan dalam penyelidikan hanya mengesahkan perkara ini
 Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Editor |KX Sehingga hari ini, perincian dan ketepatan struktur yang ditentukan oleh kristalografi, daripada logam ringkas kepada protein membran yang besar, tidak dapat ditandingi oleh mana-mana kaedah lain. Walau bagaimanapun, cabaran terbesar, yang dipanggil masalah fasa, kekal mendapatkan maklumat fasa daripada amplitud yang ditentukan secara eksperimen. Penyelidik di Universiti Copenhagen di Denmark telah membangunkan kaedah pembelajaran mendalam yang dipanggil PhAI untuk menyelesaikan masalah fasa kristal Rangkaian saraf pembelajaran mendalam yang dilatih menggunakan berjuta-juta struktur kristal tiruan dan data pembelauan sintetik yang sepadan boleh menghasilkan peta ketumpatan elektron yang tepat. Kajian menunjukkan bahawa kaedah penyelesaian struktur ab initio berasaskan pembelajaran mendalam ini boleh menyelesaikan masalah fasa pada resolusi hanya 2 Angstrom, yang bersamaan dengan hanya 10% hingga 20% daripada data yang tersedia pada resolusi atom, manakala Pengiraan ab initio tradisional
