
 Peranti teknologi
AI
ReLU menggantikan softmax dalam Transformer visual, helah baharu DeepMind mengurangkan kos dengan cepat
Peranti teknologi
AI
ReLU menggantikan softmax dalam Transformer visual, helah baharu DeepMind mengurangkan kos dengan cepat
ReLU menggantikan softmax dalam Transformer visual, helah baharu DeepMind mengurangkan kos dengan cepat

Seni bina Transformer telah digunakan secara meluas dalam bidang pembelajaran mesin moden. Perkara utama ialah menumpukan pada salah satu komponen teras transformer, yang mengandungi softmax, yang digunakan untuk menjana pengedaran kebarangkalian token. Softmax mempunyai kos yang lebih tinggi kerana ia melakukan pengiraan eksponen dan menjumlahkan panjang jujukan, yang menjadikan penyejajaran sukar dilakukan.
Google DeepMind menghasilkan idea baharu: Ganti operasi softmax dengan kaedah baharu yang tidak semestinya mengeluarkan taburan kebarangkalian. Mereka juga mendapati bahawa menggunakan ReLU dibahagikan dengan panjang jujukan boleh menghampiri atau menyaingi softmax tradisional apabila digunakan dengan Transformer visual.

Pautan kertas: https://arxiv.org/abs/2309.08586#🎜🎜🎜
Hasil ini membawa penyelesaian baharu kepada penyejajaran, kerana ReLU memfokuskan pada menumpukan perhatian dan boleh diselaraskan dalam dimensi panjang jujukan, dan operasi pengumpulan yang diperlukan adalah lebih kecil daripada tumpuan tradisional untuk menumpukan perhatian#🎜 🎜#Kaedah
Kuncinya ialah menumpukan perhatian#🎜🎜🎜🎜🎜 🎜#
Perkara penting untuk difokuskan ialah mengubah pertanyaan, kunci dan nilai {q_i, k_i, v_i} dimensi d melalui proses dua langkah# 🎜🎜# Dalam langkah pertama, perkara utama ialah fokus pada berat melalui formula berikut
:#🎜 🎜##🎜🎜 #
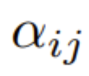 di mana ϕ biasanya softmax.
di mana ϕ biasanya softmax.
Langkah seterusnya, menggunakan fokus ini ialah memfokus pada pemberat untuk mengira output 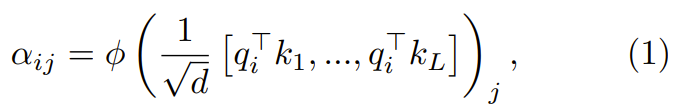 Kertas ini meneroka penggunaan pengiraan mengikut titik untuk menggantikan ϕ .
Kertas ini meneroka penggunaan pengiraan mengikut titik untuk menggantikan ϕ .
ReLU Perkara utama ialah fokus
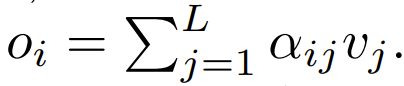 #🎜,Dep🎜 ϕ = softmax dalam Persamaan 1,
#🎜,Dep🎜 ϕ = softmax dalam Persamaan 1,
ialah alternatif yang lebih baik. Mereka akan menggunakan Intinya fokus dipanggil ReLU Intinya fokus.
Fokus titik demi titik yang diperluaskan ialah fokus  #🎜🎜🎜🎜 #🎜 Penyelidik juga telah meneroka pelbagai pilihan
#🎜🎜🎜🎜 #🎜 Penyelidik juga telah meneroka pelbagai pilihan 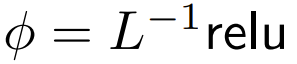 melalui eksperimen, di mana α ∈ [0, 1] dan h ∈ {relu,relu² , gelu,softplus, identiti,relu6, sigmoid} .
melalui eksperimen, di mana α ∈ [0, 1] dan h ∈ {relu,relu² , gelu,softplus, identiti,relu6, sigmoid} .
Kandungan yang perlu ditulis semula ialah: lanjutan panjang urutan
#🎜 ##🎜 🎜#Mereka juga mendapati bahawa ketepatan boleh dipertingkatkan jika dilanjutkan dengan projek yang melibatkan panjang jujukan L. Usaha penyelidikan terdahulu yang cuba mengeluarkan softmax tidak menggunakan skim penskalaan ini
Antara Transformers yang kini menggunakan softmax dan fokus pada reka bentuk, terdapat 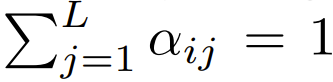 , yang bermaksud
, yang bermaksud 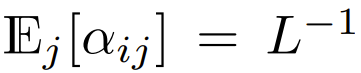 Walaupun ini tidak mungkin menjadi syarat yang diperlukan,
Walaupun ini tidak mungkin menjadi syarat yang diperlukan, 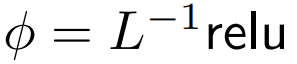 boleh memastikan bahawa semasa permulaan
boleh memastikan bahawa semasa permulaan 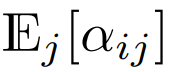 kerumitan ialah
kerumitan ialah 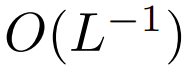 , Mengekalkan keadaan ini boleh mengurangkan keperluan untuk menukar hiperparameter lain apabila menggantikan softmax.
, Mengekalkan keadaan ini boleh mengurangkan keperluan untuk menukar hiperparameter lain apabila menggantikan softmax.
Semasa permulaan, elemen q dan k ialah O (1), jadi 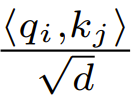 juga akan menjadi O (1). Fungsi pengaktifan seperti ReLU mengekalkan O (1), jadi faktor
juga akan menjadi O (1). Fungsi pengaktifan seperti ReLU mengekalkan O (1), jadi faktor 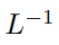 diperlukan untuk menjadikan kerumitan
diperlukan untuk menjadikan kerumitan 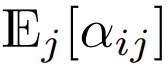 menjadi
menjadi 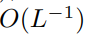 . . Paksi-x menunjukkan jumlah masa pengiraan kernel yang diperlukan untuk eksperimen dalam jam. Kelebihan besar ReLU ialah ia boleh diselaraskan dalam dimensi panjang jujukan, yang memerlukan operasi pengumpulan yang lebih sedikit daripada softmax. . daripada alternatif tepat kepada softmax. Secara khusus, ia adalah menggunakan relu, relu², gelu, softplus, identiti dan kaedah lain untuk menggantikan softmax. Paksi-X ialah α. Paksi Y ialah ketepatan model S/32, S/16 dan S/8 Vision Transformer. Keputusan terbaik biasanya diperoleh apabila α menghampiri 1. Memandangkan tiada ketaklinearan optimum yang jelas, mereka menggunakan ReLU dalam eksperimen utama mereka kerana ia lebih pantas.
. . Paksi-x menunjukkan jumlah masa pengiraan kernel yang diperlukan untuk eksperimen dalam jam. Kelebihan besar ReLU ialah ia boleh diselaraskan dalam dimensi panjang jujukan, yang memerlukan operasi pengumpulan yang lebih sedikit daripada softmax. . daripada alternatif tepat kepada softmax. Secara khusus, ia adalah menggunakan relu, relu², gelu, softplus, identiti dan kaedah lain untuk menggantikan softmax. Paksi-X ialah α. Paksi Y ialah ketepatan model S/32, S/16 dan S/8 Vision Transformer. Keputusan terbaik biasanya diperoleh apabila α menghampiri 1. Memandangkan tiada ketaklinearan optimum yang jelas, mereka menggunakan ReLU dalam eksperimen utama mereka kerana ia lebih pantas.
Kesan QK-Layern Corming boleh dinyatakan semula seperti berikut:
QK-Layernorm digunakan dalam eksperimen utama, di mana pertanyaan dan kunci akan dikira. fokus pada pemberat Sebelum dilalui melalui LayerNorm. DeepMind menyatakan bahawa sebab untuk menggunakan qk-layernorm secara lalai ialah ia adalah perlu untuk mengelakkan ketidakstabilan apabila menskalakan saiz model. Rajah 3 menunjukkan kesan pengalihan qk-layernorm. Keputusan ini menunjukkan bahawa qk-layernorm mempunyai sedikit impak pada model ini, tetapi keadaan mungkin berbeza apabila saiz model menjadi lebih besar.
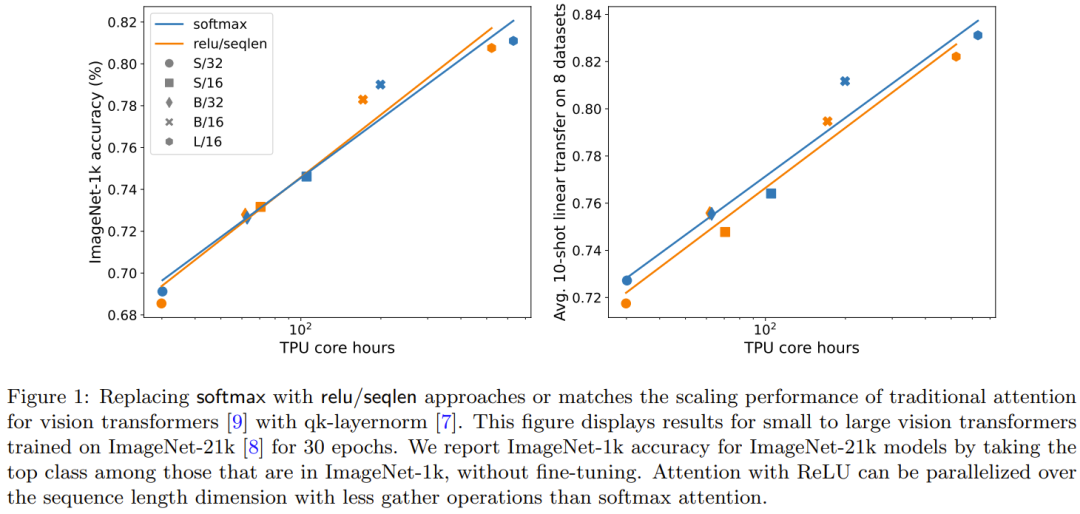
Penerangan Semula: Kesan tambahan pada pintu
Kajian terdahulu yang mengalih keluar softmax menggunakan pendekatan menambah unit gating, tetapi kaedah ini tidak boleh menskalakan dengan panjang jujukan. Khususnya, dalam unit perhatian berpagar, terdapat unjuran tambahan yang menghasilkan output yang diperolehi oleh gabungan darab mengikut unsur sebelum unjuran output. Rajah 4 meneroka sama ada kehadiran get menghapuskan keperluan untuk menulis semula apa itu: lanjutan panjang jujukan. Secara keseluruhannya, DeepMind memerhatikan bahawa ketepatan terbaik dicapai dengan atau tanpa get dengan meningkatkan panjang jujukan, yang memerlukan penulisan semula. Juga ambil perhatian bahawa untuk model S/8 yang menggunakan ReLU, mekanisme gating ini meningkatkan masa teras yang diperlukan untuk eksperimen sebanyak kira-kira 9.3%. 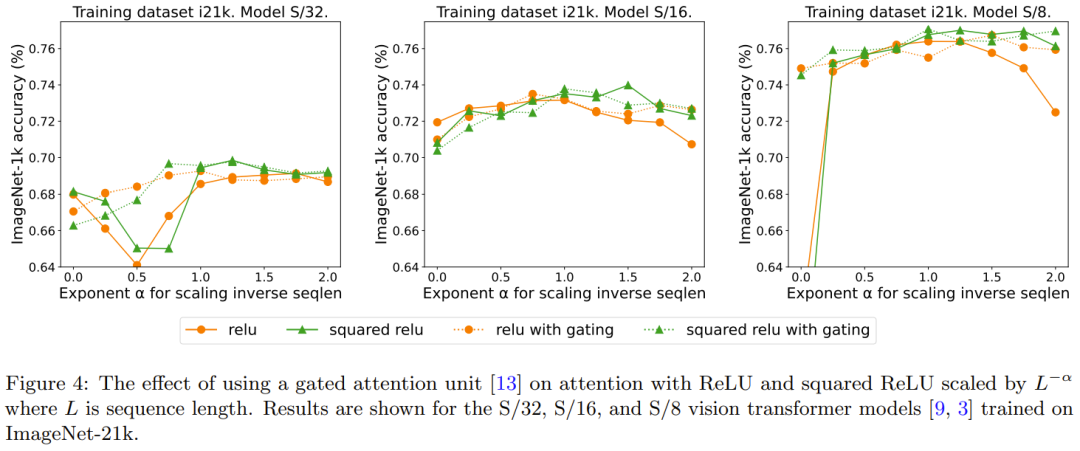
Atas ialah kandungan terperinci ReLU menggantikan softmax dalam Transformer visual, helah baharu DeepMind mengurangkan kos dengan cepat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 Google Pixel 9 Pro XL diuji dengan mod desktop
Aug 29, 2024 pm 01:09 PM
Google Pixel 9 Pro XL diuji dengan mod desktop
Aug 29, 2024 pm 01:09 PM
Google telah memperkenalkan Mod Ganti DisplayPort dengan siri Pixel 8, dan ia hadir pada barisan Pixel 9 yang baru dilancarkan. Walaupun ia terdapat terutamanya untuk membolehkan anda mencerminkan paparan telefon pintar dengan skrin yang disambungkan, anda juga boleh menggunakannya untuk desktop
 Pembongkaran APK beta apl Google mendedahkan sambungan baharu yang akan datang kepada pembantu AI Gemini
Jul 30, 2024 pm 01:06 PM
Pembongkaran APK beta apl Google mendedahkan sambungan baharu yang akan datang kepada pembantu AI Gemini
Jul 30, 2024 pm 01:06 PM
Pembantu AI Google, Gemini, bersedia untuk menjadi lebih berkebolehan, jika pembongkaran APK bagi kemas kini terkini (v15.29.34.29 beta) perlu dipertimbangkan. Pembantu AI baharu raksasa teknologi itu dilaporkan boleh mendapatkan beberapa sambungan baharu. Sambungan ini wi
 Google Tensor G4 bagi Pixel 9 Pro XL ketinggalan di belakang Tensor G2 dalam Genshin Impact
Aug 24, 2024 am 06:43 AM
Google Tensor G4 bagi Pixel 9 Pro XL ketinggalan di belakang Tensor G2 dalam Genshin Impact
Aug 24, 2024 am 06:43 AM
Google baru-baru ini bertindak balas terhadap kebimbangan prestasi mengenai Tensor G4 barisan Pixel 9. Syarikat itu berkata bahawa SoC tidak direka untuk mengalahkan penanda aras. Sebaliknya, pasukan memberi tumpuan untuk menjadikannya berprestasi baik di kawasan yang Google mahukan c
 Google AI mengumumkan Gemini 1.5 Pro dan Gemma 2 untuk pembangun
Jul 01, 2024 am 07:22 AM
Google AI mengumumkan Gemini 1.5 Pro dan Gemma 2 untuk pembangun
Jul 01, 2024 am 07:22 AM
Google AI telah mula menyediakan pembangun akses kepada tetingkap konteks lanjutan dan ciri penjimatan kos, bermula dengan model bahasa besar (LLM) Gemini 1.5 Pro. Sebelum ini tersedia melalui senarai tunggu, penuh 2 juta token konteks windo
 Telefon pintar Google Pixel 9 tidak akan dilancarkan dengan Android 15 walaupun terdapat komitmen kemas kini selama tujuh tahun
Aug 01, 2024 pm 02:56 PM
Telefon pintar Google Pixel 9 tidak akan dilancarkan dengan Android 15 walaupun terdapat komitmen kemas kini selama tujuh tahun
Aug 01, 2024 pm 02:56 PM
Siri Pixel 9 hampir tiba, telah dijadualkan untuk keluaran 13 Ogos. Berdasarkan khabar angin baru-baru ini, Pixel 9, Pixel 9 Pro dan Pixel 9 Pro XL akan mencerminkan Pixel 8 dan Pixel 8 Pro (sekira $749 di Amazon) dengan bermula dengan storan 128 GB.
 Mod desktop Google Pixel baharu dipamerkan dalam video baharu yang mungkin alternatif Motorola Ready For dan Samsung DeX
Aug 08, 2024 pm 03:05 PM
Mod desktop Google Pixel baharu dipamerkan dalam video baharu yang mungkin alternatif Motorola Ready For dan Samsung DeX
Aug 08, 2024 pm 03:05 PM
Beberapa bulan telah berlalu sejak Pihak Berkuasa Android menunjukkan mod desktop Android baharu yang telah disembunyikan oleh Google dalam Android 14 QPR3 Beta 2.1. Tiba di hadapan Google menambah sokongan Mod Alt DisplayPort untuk Pixel 8 dan Pixel 8
 Iklan Google Pixel 9 yang bocor menunjukkan ciri AI baharu termasuk fungsi kamera \'Add Me\'
Jul 30, 2024 am 11:18 AM
Iklan Google Pixel 9 yang bocor menunjukkan ciri AI baharu termasuk fungsi kamera \'Add Me\'
Jul 30, 2024 am 11:18 AM
Lebih banyak bahan promosi yang berkaitan dengan siri Pixel 9 telah bocor dalam talian. Sebagai rujukan, kebocoran baharu itu tiba sejurus selepas 91mobiles berkongsi berbilang imej yang turut mempamerkan Pixel Buds Pro 2 dan Pixel Watch 3 atau Pixel Watch 3 XL. Kali ini
 Google membuka AI Test Kitchen & Imagen 3 kepada kebanyakan pengguna
Sep 12, 2024 pm 12:17 PM
Google membuka AI Test Kitchen & Imagen 3 kepada kebanyakan pengguna
Sep 12, 2024 pm 12:17 PM
Dapur Uji AI Google, yang merangkumi set alatan reka bentuk AI untuk dimainkan oleh pengguna, kini telah dibuka kepada pengguna di lebih 100 negara di seluruh dunia. Langkah ini menandakan kali pertama ramai di seluruh dunia akan dapat menggunakan Imagen 3, Google
