
 Peranti teknologi
AI
Zhiyuan membuka 300 juta data latihan model vektor semantik, dan model BGE terus dikemas kini secara berulang.
Peranti teknologi
AI
Zhiyuan membuka 300 juta data latihan model vektor semantik, dan model BGE terus dikemas kini secara berulang.
Zhiyuan membuka 300 juta data latihan model vektor semantik, dan model BGE terus dikemas kini secara berulang.

Dengan perkembangan pesat dan aplikasi model berskala besar, kepentingan Embedding, yang merupakan komponen asas teras model berskala besar, telah menjadi semakin menonjol. Model vektor semantik Cina-Inggeris sumber terbuka dan tersedia secara komersial BGE (BAAI General Embedding) yang dikeluarkan oleh Syarikat Zhiyuan sebulan yang lalu telah menarik perhatian meluas dalam komuniti, dan telah dimuat turun ratusan ribu kali pada platform Hugging Face. Pada masa ini, BGE telah melancarkan versi 1.5 secara berulang-ulang dan mengumumkan berbilang kemas kini. Antaranya, BGE telah membuka sumber terbuka 300 juta data latihan berskala besar buat kali pertama, menyediakan komuniti bantuan dalam melatih model serupa dan mempromosikan pembangunan teknologi dalam bidang ini
- Pautan set data MTP: https://data.baai. ac.cn/details/BAAI-MTP
- Pautan model BGE: https://huggingface.co/BAAI
- repositori kod BGE: https://www.php .cn/link/8944871f1c9865a77a3d9c92cadf124d
3
data latihan sumber terbuka pertamacina dan data Bahasa Inggeris
Kecemerlangan BGE Keupayaannya sebahagian besarnya berpunca daripada data latihan berskala besar dan pelbagai. Sebelum ini, rakan industri jarang mengeluarkan set data yang serupa. Dalam kemas kini ini, Zhiyuan membuka data latihan BGE kepada komuniti buat kali pertama, meletakkan asas untuk pembangunan lanjut jenis teknologi ini.
Set data MTP yang dikeluarkan kali ini terdiri daripada sejumlah 300 juta pasangan teks berkaitan bahasa Cina dan Inggeris. Antaranya, terdapat 100 juta rekod dalam bahasa Cina dan 200 juta rekod dalam bahasa Inggeris. Sumber data termasuk Wudao Corpora, Pile, DuReader, Sentence Transformer dan korporat lain. Diperolehi selepas pensampelan, pengekstrakan dan pembersihan yang diperlukan
Untuk butiran, sila rujuk Hab Data: https://data.baai.ac.cn
MTP ialah set data pasangan teks berkaitan Cina-Inggeris sumber terbuka terbesar setakat ini, menyediakan asas penting untuk melatih model vektor semantik Cina dan Inggeris.
Sebagai tindak balas kepada komuniti pembangun, peningkatan fungsi BGE
Berdasarkan maklum balas komuniti, BGE telah dioptimumkan lagi berdasarkan versi 1.0nya untuk menjadikan prestasinya lebih stabil dan cemerlang. Kandungan peningkatan khusus adalah seperti berikut:
- Kemas kini model. BGE-*-zh-v1.5 mengurangkan masalah pengedaran persamaan dengan menapis data latihan, memadamkan data berkualiti rendah dan meningkatkan pekali suhu semasa latihan kepada 0.02, menjadikan nilai persamaan lebih stabil.
- Model baharu ditambah. Model pengekod silang BGE-reranker sumber terbuka boleh mencari teks yang berkaitan dengan lebih tepat dan menyokong dwibahasa Cina dan Inggeris. Berbeza daripada model vektor yang memerlukan vektor keluaran, BGE-reranker secara langsung mengeluarkan persamaan antara pasangan teks dan mempunyai ketepatan kedudukan yang lebih tinggi Ia boleh digunakan untuk menyusun semula keputusan penarikan semula vektor dan mempertingkatkan perkaitan hasil akhir.
- Ciri baharu. BGE1.1 menambah skrip perlombongan sampel sukar-ke-negatif dengan berkesan boleh meningkatkan kesan perolehan selepas penalaan halus ditambah kepada kod penalaan halus; juga akan ditukar secara automatik ke dalam format pengubah ayat, menjadikannya lebih mudah untuk memuatkan model.
Perlu dinyatakan bahawa baru-baru ini, Zhiyuan dan Hugging Face mengeluarkan laporan teknikal, yang mencadangkan menggunakan C-Pack untuk meningkatkan model vektor semantik universal Cina.
"C-Pack: Packaged Resources To Advance General Chinese Embedding"
Pautan: https://arxiv.org/pdf/2309.07597.pdf
mendapat populariti tinggi dalam komuniti BGE telah menarik perhatian komuniti pembangun model besar sejak dikeluarkan Pada masa ini, Hugging Face telah dimuat turun ratusan ribu kali, dan telah disepadukan dan digunakan oleh projek sumber terbuka yang terkenal seperti LangChain, LangChain-Chachat, llama_index, dsb.
Pegawai Langchain, pengasas bersama dan Ketua Pegawai Eksekutif LangChain Harrison Chase, pengasas Deep trading Yam Peleg dan pengaruh komuniti lain menyatakan kebimbangan mengenai BGE.
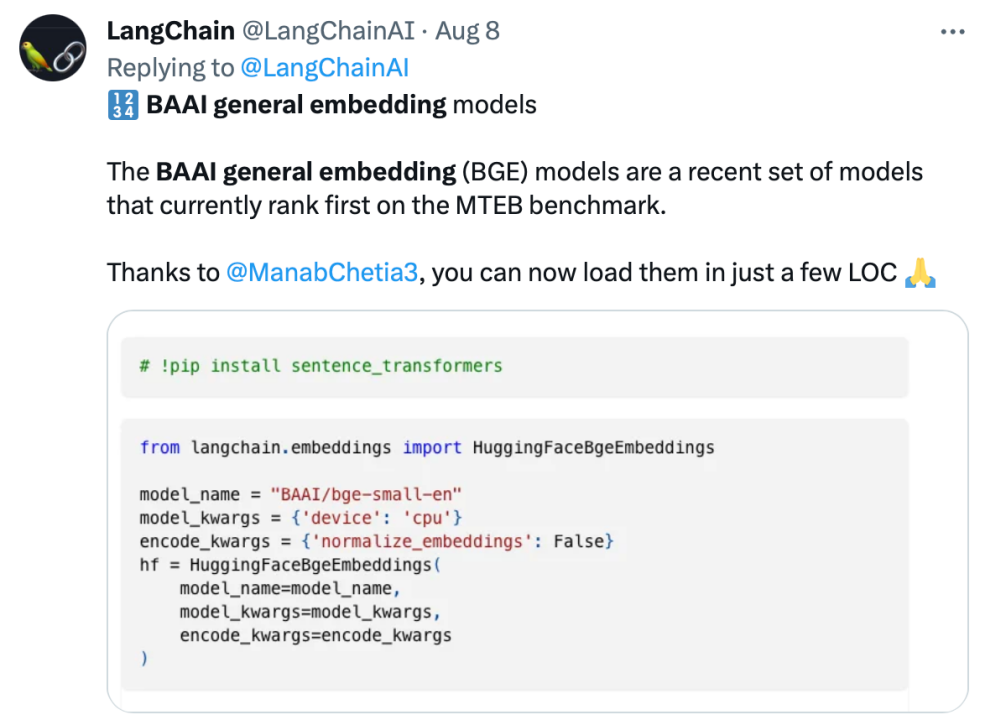
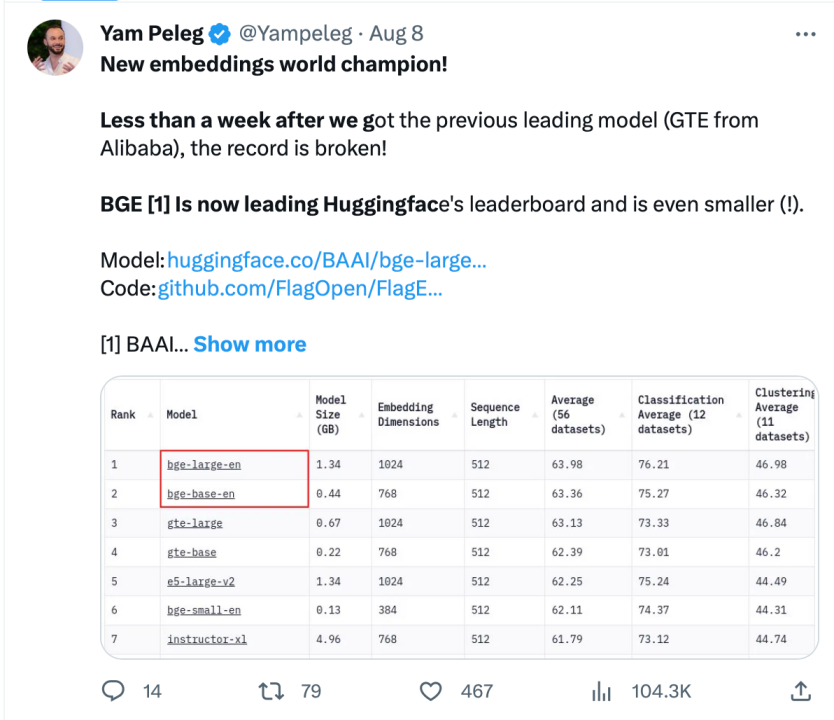
Mematuhi sumber terbuka dan keterbukaan, mempromosikan inovasi kolaboratif, sistem pembangunan teknologi model besar Sumber Pintar FlagOpen BGE telah menambah bahagian FlagEmbedding baharu, memfokuskan pada teknologi dan model Benamkan adalah salah satu BGE berprofil tinggi projek sumber terbuka. FlagOpen komited untuk membina infrastruktur teknologi kecerdasan buatan dalam era model besar, dan akan terus membuka teknologi tindanan penuh model besar yang lebih lengkap kepada akademia dan industri pada masa hadapan
Atas ialah kandungan terperinci Zhiyuan membuka 300 juta data latihan model vektor semantik, dan model BGE terus dikemas kini secara berulang.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
1205
24
52
1205
24

 Platform Perdagangan Web3 Ranking_Web3 Global Exchanges Top Ten Ringkasan
Apr 21, 2025 am 10:45 AM
Platform Perdagangan Web3 Ranking_Web3 Global Exchanges Top Ten Ringkasan
Apr 21, 2025 am 10:45 AM
Binance adalah tuan rumah ekosistem perdagangan aset digital global, dan ciri -cirinya termasuk: 1. Jumlah dagangan harian purata melebihi $ 150 bilion, menyokong 500 pasangan perdagangan, yang meliputi 98% mata wang arus perdana; 2. Matriks inovasi meliputi pasaran Derivatif, susun atur Web3 dan sistem pendidikan; 3. Kelebihan teknikal adalah enjin yang sepadan dengan milisaat, dengan jumlah pemprosesan puncak sebanyak 1.4 juta transaksi sesaat; 4. Kemajuan pematuhan memegang lesen 15 negara dan menetapkan entiti yang mematuhi di Eropah dan Amerika Syarikat.
 Cara mengelakkan kerugian selepas peningkatan ETH
Apr 21, 2025 am 10:03 AM
Cara mengelakkan kerugian selepas peningkatan ETH
Apr 21, 2025 am 10:03 AM
Selepas peningkatan ETH, orang baru harus mengamalkan strategi berikut untuk mengelakkan kerugian: 1. Lakukan kerja rumah mereka dan memahami pengetahuan asas dan meningkatkan kandungan ETH; 2. Posisi kawalan, menguji perairan dalam jumlah yang kecil dan mempelbagaikan pelaburan; 3. Buat pelan dagangan, jelaskan matlamat dan tetapkan titik kehilangan berhenti; 4. Profil secara rasional dan elakkan membuat keputusan emosi; 5. Pilih platform perdagangan formal dan boleh dipercayai; 6. Pertimbangkan jangka panjang untuk mengelakkan kesan turun naik jangka pendek.
 Platform Pertukaran Cryptocurrency Top 10 senarai pertukaran mata wang digital terbesar di dunia
Apr 21, 2025 pm 07:15 PM
Platform Pertukaran Cryptocurrency Top 10 senarai pertukaran mata wang digital terbesar di dunia
Apr 21, 2025 pm 07:15 PM
Pertukaran memainkan peranan penting dalam pasaran cryptocurrency hari ini. Mereka bukan sahaja platform untuk pelabur untuk berdagang, tetapi juga sumber kecairan pasaran dan penemuan harga. Pertukaran mata wang maya terbesar di dunia di kalangan sepuluh teratas, dan pertukaran ini bukan sahaja jauh ke hadapan dalam jumlah dagangan, tetapi juga mempunyai kelebihan mereka sendiri dalam pengalaman pengguna, perkhidmatan keselamatan dan inovatif. Pertukaran yang atas senarai biasanya mempunyai pangkalan pengguna yang besar dan pengaruh pasaran yang luas, dan jumlah dagangan dan jenis aset mereka sering sukar dicapai oleh bursa lain.
 Apakah yang dimaksudkan dengan transaksi rantaian rantaian? Apakah urus niaga salib?
Apr 21, 2025 pm 11:39 PM
Apakah yang dimaksudkan dengan transaksi rantaian rantaian? Apakah urus niaga salib?
Apr 21, 2025 pm 11:39 PM
Pertukaran yang menyokong urus niaga rantaian: 1. Binance, 2. Uniswap, 3 Sushiswap, 4. Kewangan Curve, 5. Thorchain, 6. 1 inci Pertukaran, 7.
 Apakah sepuluh platform teratas dalam bulatan pertukaran mata wang?
Apr 21, 2025 pm 12:21 PM
Apakah sepuluh platform teratas dalam bulatan pertukaran mata wang?
Apr 21, 2025 pm 12:21 PM
Pertukaran teratas termasuk: 1. Binance, jumlah dagangan terbesar di dunia, menyokong 600 mata wang, dan yuran pengendalian tempat adalah 0.1%; 2. Okx, platform seimbang, menyokong 708 pasangan dagangan, dan yuran pengendalian kontrak kekal adalah 0.05%; 3. Gate.io, meliputi 2700 mata wang kecil, dan yuran pengendalian tempat ialah 0.1%-0.3%; 4. Coinbase, penanda aras pematuhan AS, yuran pengendalian tempat adalah 0.5%; 5. Kraken, keselamatan tertinggi, dan audit rizab tetap.
 Kedudukan pertukaran leverage dalam lingkaran mata wang Cadangan terkini sepuluh pertukaran leverage dalam lingkaran mata wang
Apr 21, 2025 pm 11:24 PM
Kedudukan pertukaran leverage dalam lingkaran mata wang Cadangan terkini sepuluh pertukaran leverage dalam lingkaran mata wang
Apr 21, 2025 pm 11:24 PM
Platform yang mempunyai prestasi cemerlang dalam perdagangan, keselamatan dan pengalaman pengguna yang dimanfaatkan pada tahun 2025 adalah: 1. Okx, sesuai untuk peniaga frekuensi tinggi, menyediakan sehingga 100 kali leverage; 2. Binance, sesuai untuk peniaga berbilang mata wang di seluruh dunia, memberikan 125 kali leverage tinggi; 3. Gate.io, sesuai untuk pemain derivatif profesional, menyediakan 100 kali leverage; 4. Bitget, sesuai untuk orang baru dan peniaga sosial, menyediakan sehingga 100 kali leverage; 5. Kraken, sesuai untuk pelabur mantap, menyediakan 5 kali leverage; 6. Bybit, sesuai untuk penjelajah altcoin, menyediakan 20 kali leverage; 7. Kucoin, sesuai untuk peniaga kos rendah, menyediakan 10 kali leverage; 8. Bitfinex, sesuai untuk bermain senior
 Mengapa kenaikan atau kejatuhan harga mata wang maya? Mengapa kenaikan atau kejatuhan harga mata wang maya?
Apr 21, 2025 am 08:57 AM
Mengapa kenaikan atau kejatuhan harga mata wang maya? Mengapa kenaikan atau kejatuhan harga mata wang maya?
Apr 21, 2025 am 08:57 AM
Faktor kenaikan harga mata wang maya termasuk: 1. Peningkatan permintaan pasaran, 2. Menurunkan bekalan, 3. Berita positif yang dirangsang, 4. Sentimen pasaran optimis, 5. Persekitaran makroekonomi; Faktor penurunan termasuk: 1. Mengurangkan permintaan pasaran, 2. Peningkatan bekalan, 3.
 'Black Monday Sell' adalah hari yang sukar untuk industri cryptocurrency
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' adalah hari yang sukar untuk industri cryptocurrency
Apr 21, 2025 pm 02:48 PM
Jatuh di pasaran cryptocurrency telah menyebabkan panik di kalangan pelabur, dan Dogecoin (Doge) telah menjadi salah satu kawasan terkena paling sukar. Harganya jatuh dengan ketara, dan jumlah nilai kunci kewangan yang terdesentralisasi (DEFI) (TVL) juga menyaksikan penurunan yang ketara. Gelombang jualan "Black Monday" menyapu pasaran cryptocurrency, dan Dogecoin adalah yang pertama dipukul. Defitvlnya jatuh ke tahap 2023, dan harga mata wang jatuh 23.78% pada bulan lalu. Defitvl Dogecoin jatuh ke tahap rendah $ 2.72 juta, terutamanya disebabkan oleh penurunan 26.37% dalam indeks nilai SOSO. Platform defi utama lain, seperti DAO dan Thorchain yang membosankan, TVL juga menurun sebanyak 24.04% dan 20.
