
 pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk mengira sisa pelajar dalam Python?
pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk mengira sisa pelajar dalam Python?
Bagaimana untuk mengira sisa pelajar dalam Python?

Sisa terpelajar sering digunakan dalam analisis regresi untuk mengenal pasti kemungkinan outlier dalam data. Outlier ialah titik yang berbeza dengan ketara daripada aliran keseluruhan data dan boleh memberi kesan ketara pada model yang dipasang. Dengan mengenal pasti dan menganalisis outlier, anda boleh memahami dengan lebih baik corak asas dalam data anda dan meningkatkan ketepatan model anda. Dalam artikel ini, kita akan melihat dengan lebih dekat sisa pelajar dan cara melaksanakannya dalam python.
Apakah sisa pelajar?
Istilah "sisa terpelajar" merujuk kepada kelas sisa tertentu yang sisihan piawainya dibahagikan dengan anggaran. Sisa analisis regresi menerangkan perbezaan antara nilai yang diperhatikan bagi pembolehubah bergerak balas dan nilai jangkaannya yang dijana oleh model. Untuk mencari penyimpangan dalam data yang mungkin mempengaruhi model dipasang dengan ketara, sisa pelajar telah digunakan.
Formula berikut biasanya digunakan untuk mengira sisa pelajar -
studentized residual = residual / (standard deviation of residuals * (1 - hii)^(1/2))
Di mana "sisa" merujuk kepada perbezaan antara nilai tindak balas yang diperhatikan dan nilai tindak balas yang dijangka, "sisa sisihan piawai" merujuk kepada anggaran sisa sisihan piawai dan "hii" merujuk kepada setiap titik data faktor leverage .
Gunakan Python untuk mengira sisa pelajar
Pakejstatsmodels boleh digunakan untuk mengira sisa pelajar dalam Python. Sebagai ilustrasi, pertimbangkan perkara berikut -
tatabahasa
OLSResults.outlier_test()
Di mana OLSResults merujuk kepada model linear yang dipasang menggunakan kaedah ols() model statistik.
df = pd.DataFrame({'rating': [95, 82, 92, 90, 97, 85, 80, 70, 82, 83],
'points': [22, 25, 17, 19, 26, 24, 9, 19, 11, 16]})
model = ols('rating ~ points', data=df).fit()
stud_res = model.outlier_test()
Di mana "penilaian" dan "skor" merujuk kepada regresi linear mudah.
Algoritma
Import numpy, panda, Statsmodel api.
Buat set data.
Lakukan model regresi linear ringkas pada set data.
Kira sisa pelajar.
Cetak sisa pelajar.
Contoh
Berikut ialah demonstrasi menggunakan perpustakaan scikit-posthocs untuk menjalankan ujian Dunn -
#import necessary packages and functions
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
#create dataset
df = pd.DataFrame({'rating': [95, 82, 92, 90, 97, 85, 80, 70, 82, 83], 'points': [22, 25, 17, 19, 26, 24, 9, 19, 11, 16]})
Seterusnya gunakan kelas statsmodels OLS untuk mencipta model regresi linear -
#fit simple linear regression model
model = ols('rating ~ points', data=df).fit()
Menggunakan kaedah outlier test(), baki pelajar bagi setiap pemerhatian dalam set data boleh dijana dalam DataFrame -
#calculate studentized residuals stud_res = model.outlier_test() #display studentized residuals print(stud_res)
Output
student_resid unadj_p bonf(p) 0 1.048218 0.329376 1.000000 1 -1.018535 0.342328 1.000000 2 0.994962 0.352896 1.000000 3 0.548454 0.600426 1.000000 4 1.125756 0.297380 1.000000 5 -0.465472 0.655728 1.000000 6 -0.029670 0.977158 1.000000 7 -2.940743 0.021690 0.216903 8 0.100759 0.922567 1.000000 9 -0.134123 0.897080 1.000000
Kami juga boleh memplot nilai peramal dengan cepat berdasarkan sisa pelajar -
tatabahasa
x = df['points']
y = stud_res['student_resid']
plt.scatter(x, y)
plt.axhline(y=0, color='black', linestyle='--')
plt.xlabel('Points')
plt.ylabel('Studentized Residuals')
Di sini kita akan menggunakan perpustakaan matpotlib untuk melukis carta dengan warna = 'hitam' dan gaya hidup = '--'
Algoritma
Import perpustakaan pyplot matplotlib
Tentukan nilai peramal
Definisi sisa pelajar
Cipta serakan peramal berbanding sisa pelajar
Contoh
import matplotlib.pyplot as plt
#define predictor variable values and studentized residuals
x = df['points']
y = stud_res['student_resid']
#create scatterplot of predictor variable vs. studentized residuals
plt.scatter(x, y)
plt.axhline(y=0, color='black', linestyle='--')
plt.xlabel('Points')
plt.ylabel('Studentized Residuals')
Output
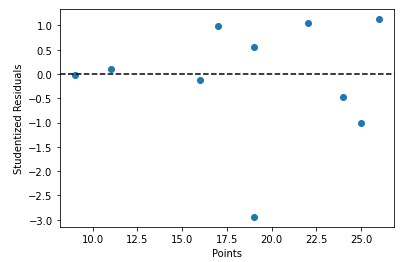
KESIMPULAN
Kenal pasti dan nilaikan kemungkinan outlier data. Memeriksa sisa pelajar membolehkan anda mencari mata yang menyimpang dengan ketara daripada aliran keseluruhan data dan meneroka sebab ia mempengaruhi model yang dipasang. Mengenal pasti pemerhatian penting Sisa pelajar boleh digunakan untuk menemui dan menilai data berpengaruh yang mempunyai kesan ketara ke atas model yang dipasang. Cari tempat leverage tinggi. Sisa pelajar boleh digunakan untuk mengenal pasti titik leverage yang tinggi. Leveraj ialah ukuran berapa banyak pengaruh titik pada model yang dipasang. Secara keseluruhan, menggunakan sisa pelajar membantu menganalisis dan meningkatkan prestasi model regresi.
Atas ialah kandungan terperinci Bagaimana untuk mengira sisa pelajar dalam Python?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Teknik analisis sisa dalam Python
Jun 10, 2023 am 08:52 AM
Teknik analisis sisa dalam Python
Jun 10, 2023 am 08:52 AM
Python ialah bahasa pengaturcaraan yang digunakan secara meluas, dan keupayaan analisis data dan visualisasi yang berkuasa menjadikannya salah satu alat pilihan untuk saintis data dan jurutera pembelajaran mesin. Dalam aplikasi ini, analisis sisa ialah teknik biasa yang digunakan untuk menilai ketepatan model dan mengenal pasti sebarang bias model. Dalam artikel ini, kami akan memperkenalkan beberapa cara untuk menggunakan teknik analisis sisa dalam Python. Memahami Sisa Sebelum memperkenalkan teknik analisis sisa dalam Python, mari kita fahami dahulu apa itu sisa. Dalam statistik, baki ialah perbezaan antara nilai cerapan sebenar dan
 AssertionError: Bagaimana untuk menyelesaikan ralat pernyataan Python?
Jun 25, 2023 pm 11:07 PM
AssertionError: Bagaimana untuk menyelesaikan ralat pernyataan Python?
Jun 25, 2023 pm 11:07 PM
Penegasan dalam Python ialah alat yang berguna untuk pengaturcara untuk menyahpepijat kod mereka. Ia digunakan untuk mengesahkan bahawa keadaan dalaman program memenuhi jangkaan dan menimbulkan ralat penegasan (AssertionError) apabila syarat ini palsu. Semasa proses pembangunan, penegasan digunakan semasa ujian dan penyahpepijatan untuk menyemak sama ada status kod sepadan dengan hasil yang dijangkakan. Artikel ini akan membincangkan punca, penyelesaian dan cara menggunakan penegasan dengan betul dalam kod anda. Punca ralat penegasan Pas ralat penegasan
 Bagaimana untuk membangunkan pengimbas kerentanan dalam Python
Jul 01, 2023 am 08:10 AM
Bagaimana untuk membangunkan pengimbas kerentanan dalam Python
Jul 01, 2023 am 08:10 AM
Gambaran keseluruhan cara membangunkan pengimbas kerentanan melalui Python Dalam persekitaran hari ini yang meningkatkan ancaman keselamatan Internet, pengimbas kerentanan telah menjadi alat penting untuk melindungi keselamatan rangkaian. Python ialah bahasa pengaturcaraan popular yang ringkas, mudah dibaca dan berkuasa, sesuai untuk membangunkan pelbagai alat praktikal. Artikel ini akan memperkenalkan cara menggunakan Python untuk membangunkan pengimbas kerentanan untuk menyediakan perlindungan masa nyata untuk rangkaian anda. Langkah 1: Tentukan Sasaran Imbasan Sebelum membangunkan pengimbas kerentanan, anda perlu menentukan sasaran yang ingin anda imbas. Ini boleh menjadi rangkaian anda sendiri atau apa sahaja yang anda mempunyai kebenaran untuk menguji
 Teknik persampelan berstrata dalam Python
Jun 10, 2023 pm 10:40 PM
Teknik persampelan berstrata dalam Python
Jun 10, 2023 pm 10:40 PM
Teknik Persampelan Berstrata dalam Persampelan Python ialah kaedah pengumpulan data yang biasa digunakan dalam statistik Ia boleh memilih sebahagian daripada sampel daripada set data untuk dianalisis untuk membuat kesimpulan ciri-ciri keseluruhan set data. Dalam era data besar, jumlah data adalah besar, dan menggunakan keseluruhan sampel untuk analisis adalah memakan masa dan tidak praktikal dari segi ekonomi. Oleh itu, pemilihan kaedah persampelan yang sesuai dapat meningkatkan kecekapan analisis data. Artikel ini terutamanya memperkenalkan teknik persampelan berstrata dalam Python. Apakah persampelan berstrata? Dalam persampelan, persampelan berstrata
 Cara menggunakan Python untuk skrip dan pelaksanaan di Linux
Oct 05, 2023 am 11:45 AM
Cara menggunakan Python untuk skrip dan pelaksanaan di Linux
Oct 05, 2023 am 11:45 AM
Cara menggunakan Python untuk menulis dan melaksanakan skrip dalam Linux Dalam sistem pengendalian Linux, kita boleh menggunakan Python untuk menulis dan melaksanakan pelbagai skrip. Python ialah bahasa pengaturcaraan ringkas dan berkuasa yang menyediakan banyak perpustakaan dan alatan untuk menjadikan skrip lebih mudah dan lebih cekap. Di bawah ini kami akan memperkenalkan langkah asas cara menggunakan Python untuk penulisan dan pelaksanaan skrip dalam Linux, dan menyediakan beberapa contoh kod khusus untuk membantu anda memahami dan menggunakannya dengan lebih baik. Pasang Python
 Penggunaan fungsi sqrt() dalam Python
Feb 21, 2024 pm 03:09 PM
Penggunaan fungsi sqrt() dalam Python
Feb 21, 2024 pm 03:09 PM
Contoh penggunaan dan kod fungsi sqrt() dalam Python 1. Fungsi dan pengenalan fungsi sqrt() Dalam pengaturcaraan Python, fungsi sqrt() ialah fungsi dalam modul matematik, dan fungsinya adalah untuk mengira punca kuasa dua bagi nombor. Punca kuasa dua bermaksud nombor yang didarab dengan sendirinya sama dengan kuasa dua nombor itu, iaitu, x*x=n, maka x ialah punca kuasa dua bagi n. Fungsi sqrt() boleh digunakan dalam atur cara untuk mengira punca kuasa dua. 2. Cara menggunakan fungsi sqrt() dalam Python, sq
 Bagaimana untuk menggunakan teknik pengelompokan vektor sokongan dalam Python?
Jun 06, 2023 am 08:00 AM
Bagaimana untuk menggunakan teknik pengelompokan vektor sokongan dalam Python?
Jun 06, 2023 am 08:00 AM
Pengelompokan Vektor Sokongan (SVC) ialah algoritma pembelajaran tanpa pengawasan berdasarkan Mesin Vektor Sokongan (SVM), yang boleh mencapai pengelompokan dalam set data tidak berlabel. Python ialah bahasa pengaturcaraan yang popular dengan set perpustakaan dan kit alat pembelajaran mesin yang kaya. Artikel ini akan memperkenalkan cara menggunakan teknologi pengelompokan vektor sokongan dalam Python. 1. Prinsip Pengelompokan Vektor Sokongan SVC adalah berdasarkan set vektor sokongan
 Ajar anda cara menggunakan pengaturcaraan Python untuk merealisasikan dok antara muka pengecaman imej Baidu dan merealisasikan fungsi pengecaman imej.
Aug 25, 2023 pm 03:10 PM
Ajar anda cara menggunakan pengaturcaraan Python untuk merealisasikan dok antara muka pengecaman imej Baidu dan merealisasikan fungsi pengecaman imej.
Aug 25, 2023 pm 03:10 PM
Ajar anda menggunakan pengaturcaraan Python untuk melaksanakan dok antara muka pengecaman imej Baidu dan merealisasikan fungsi pengecaman imej Dalam bidang penglihatan komputer, teknologi pengecaman imej adalah teknologi yang sangat penting. Baidu menyediakan antara muka pengecaman imej yang berkuasa yang melaluinya kami boleh melaksanakan pengelasan imej, pelabelan, pengecaman muka dan fungsi lain dengan mudah. Artikel ini akan mengajar anda cara menggunakan bahasa pengaturcaraan Python untuk melaksanakan fungsi pengecaman imej dengan menyambung ke antara muka pengecaman imej Baidu. Pertama, kita perlu membuat aplikasi pada Platform Pembangun Baidu dan mendapatkan
