

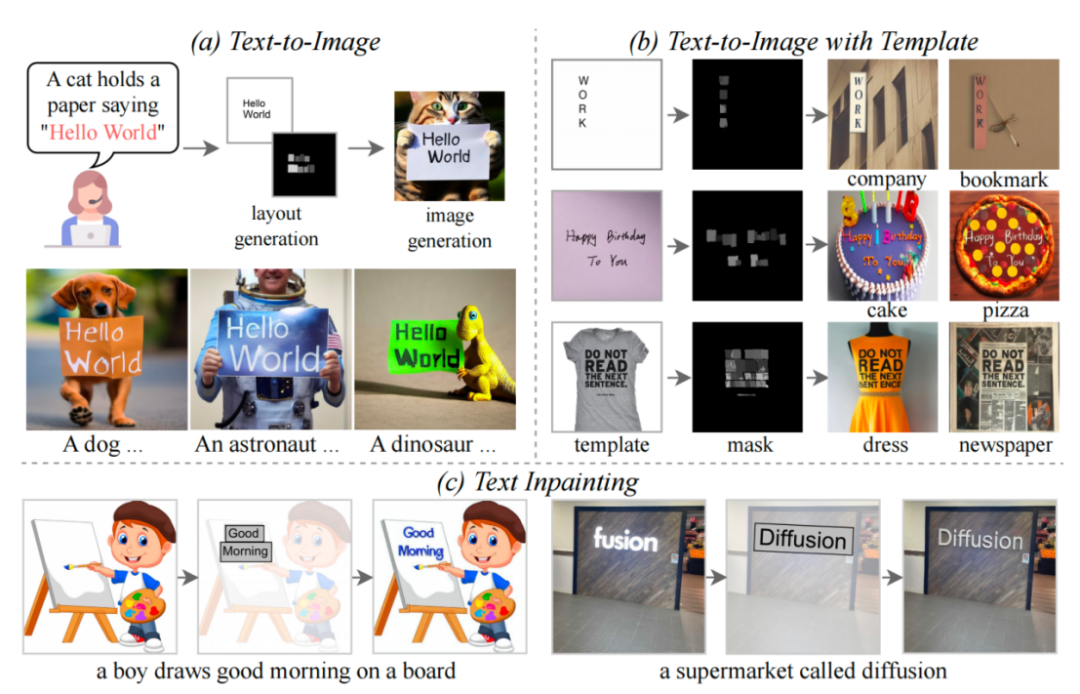
Bidang Text-to-Image telah mencapai kemajuan yang luar biasa dalam beberapa tahun kebelakangan ini, terutamanya dalam era Kandungan Dijana Kecerdasan Buatan (AIGC). Dengan peningkatan model DALL-E, semakin banyak model Text-to-Image telah muncul dalam dunia akademik, seperti Imagen, Stable Diffusion, ControlNet dan model lain. Walau bagaimanapun, walaupun perkembangan pesat medan Teks-ke-Imej, model sedia ada masih menghadapi beberapa cabaran dalam menghasilkan imej yang mengandungi teks secara stabil
Selepas mencuba model teks-ke-imej sota sedia ada, kita dapati bahagian teks yang dihasilkan oleh model pada asasnya Ia tidak boleh dibaca dan serupa dengan watak bercelaru, yang sangat mempengaruhi estetika keseluruhan imej.

Maklumat teks yang dijana oleh model penjanaan teks sota sedia ada kurang boleh dibaca
Selepas disiasat, kurang penyelidikan dalam bidang ini dalam akademik. Malah, imej yang mengandungi teks adalah perkara biasa dalam kehidupan seharian, seperti poster, kulit buku dan papan tanda jalan. Jika AI boleh menjana imej sedemikian dengan berkesan, ia akan membantu pereka bentuk dalam kerja mereka, memberi inspirasi kepada inspirasi reka bentuk dan mengurangkan beban reka bentuk. Selain itu, pengguna mungkin hanya ingin mengubah suai bahagian teks hasil model rajah Vincent dan mengekalkan hasilnya dalam kawasan bukan teks yang lain.
Untuk tidak mengubah maksud asal, kandungan perlu ditulis semula ke dalam bahasa Cina. Tiada ayat asal diperlukan

Artikel ini mencadangkan model TextDiffuser, yang mengandungi dua peringkat, peringkat pertama menjana Reka Letak, dan peringkat kedua menjana imej. . yang Prompt. Para penyelidik menggunakan Layout Transformer, menggunakan borang pengekod-penyahkod untuk mengeluarkan secara autoregresif kotak koordinat kata kunci, dan menggunakan perpustakaan BANTAL Python untuk memaparkan teks. Dalam proses ini, anda juga boleh menggunakan API siap sedia Bantal untuk mendapatkan kotak koordinat bagi setiap aksara, yang setara dengan mendapatkan topeng segmentasi peringkat Kotak peringkat aksara. Berdasarkan maklumat ini, penyelidik cuba memperhalusi Stable Diffusion. Mereka menganggap dua situasi Satu ialah pengguna mahu menjana keseluruhan imej secara langsung (dipanggil Penjanaan Imej Seluruh). Situasi lain ialah Penjanaan Bahagian-Imej, juga dipanggil Pengecatan Teks dalam kertas, yang bermaksud bahawa pengguna memberikan imej dan perlu mengubah suai kawasan teks tertentu dalam imej.
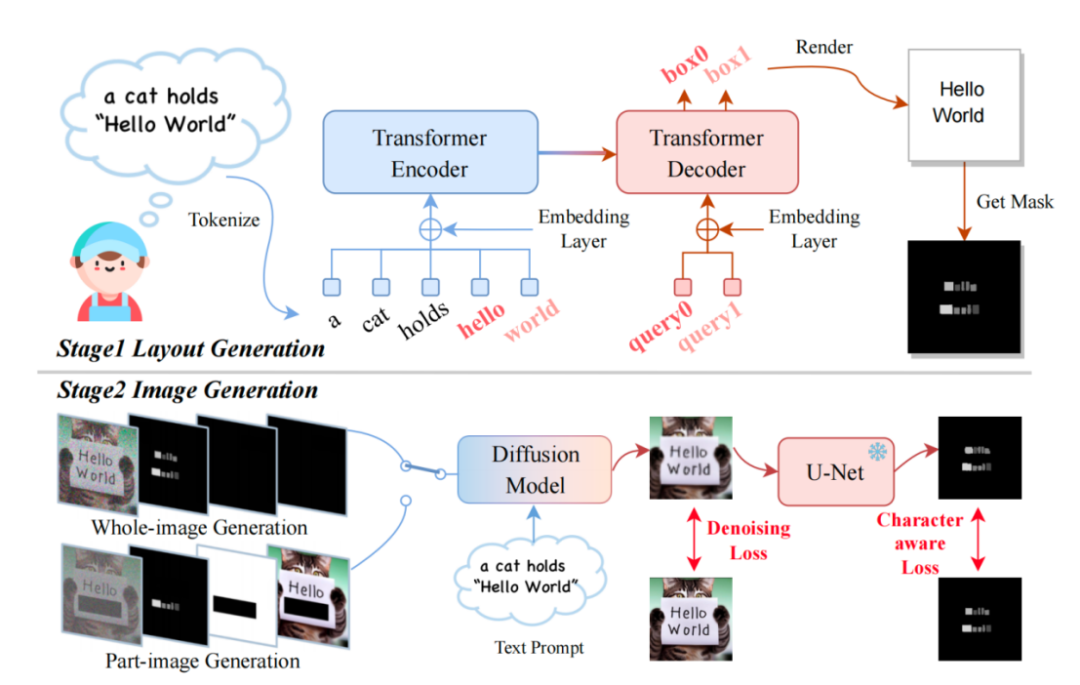
Dalam fasa inferens, TextDiffuser mempunyai cara penggunaan yang sangat fleksibel, yang boleh dibahagikan. kepada tiga jenis:
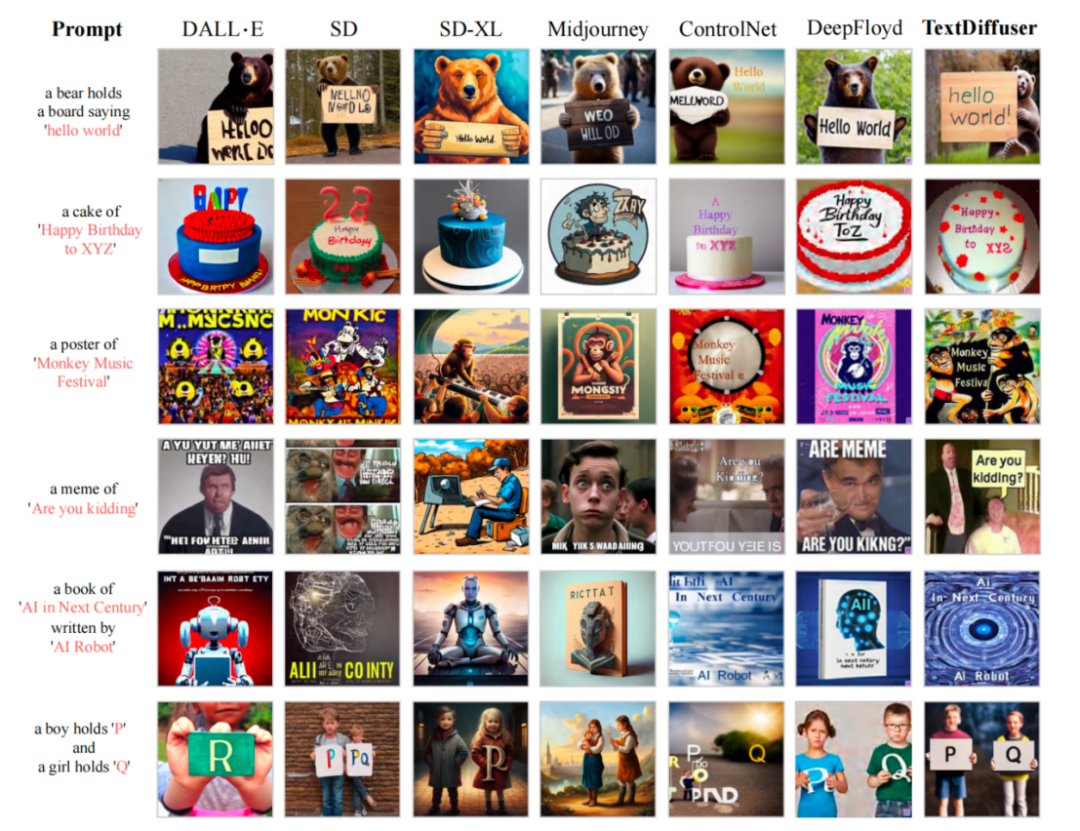
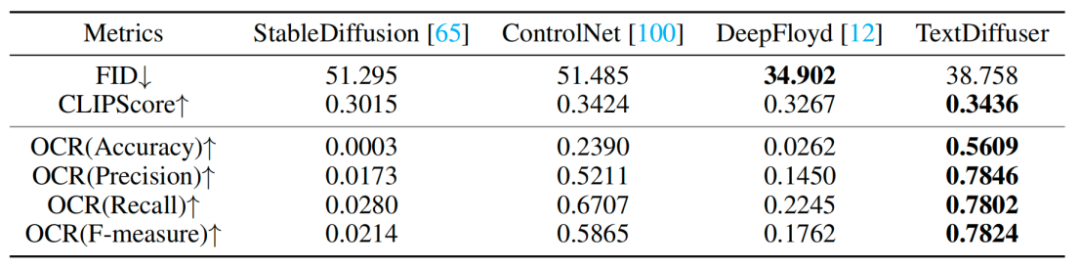
Data MARIO yang dibina #🎜🎜🎜##🎜🎜🎜##🎜🎜🎜 #Untuk melatih TextDiffuser, penyelidik mengumpul sepuluh juta imej teks, seperti yang ditunjukkan dalam rajah di atas, termasuk tiga subset: MARIO-LAION, MARIO-TMDB dan MARIO-OpenLibrary Para penyelidik mempertimbangkan beberapa aspek semasa menapis data: sebagai contoh, selepas imej OCR, hanya imej dengan kuantiti teks [1,8] dikekalkan. Mereka menapis teks dengan lebih daripada 8 teks, kerana teks ini selalunya mengandungi sejumlah besar teks padat, dan hasil OCR biasanya kurang tepat, seperti surat khabar atau lukisan reka bentuk yang kompleks. Selain itu, mereka menetapkan kawasan teks menjadi lebih besar daripada 10%. Peraturan ini ditetapkan untuk mengelakkan kawasan teks daripada menjadi terlalu kecil dalam imej. Selepas latihan mengenai dataset MARIO-10M, penyelidik menjalankan perbandingan kuantitatif dan kualitatif TextDiffuser dengan kaedah sedia ada. Sebagai contoh, dalam tugas penjanaan imej keseluruhan, imej yang dihasilkan oleh kaedah ini mempunyai teks yang lebih jelas dan boleh dibaca, dan kawasan teks dan kawasan latar belakang disepadukan dengan lebih baik, seperti yang ditunjukkan dalam rajah di bawah #🎜 🎜## Para penyelidik juga menjalankan satu siri eksperimen kualitatif dan keputusan Seperti yang ditunjukkan dalam Jadual 1. Penunjuk penilaian termasuk FID, CLIPScore dan OCR. Khusus untuk indeks OCR, kaedah penyelidikan ini telah meningkat dengan ketara berbanding kaedah perbandingan Selepas percubaan menulis semula: keputusan ditunjukkan dalam Jadual 1: Percubaan kualitatif Untuk tugasan Penjanaan Bahagian-Imej, penyelidik cuba menambah atau mengubah suai aksara pada imej yang diberikan bahawa TextDiffuser Keputusan yang terhasil adalah semula jadi. Text Repair Function Visualization Secara keseluruhannya, model TextDiffuser yang dicadangkan dalam kertas kerja ini telah mencapai kemajuan yang ketara dalam bidang pemaparan teks dan mampu menjana imej berkualiti tinggi yang mengandungi teks yang boleh dibaca. Pada masa hadapan, penyelidik akan menambah baik lagi kesan TextDiffuser.

Atas ialah kandungan terperinci Tajuk baharu: TextDiffuser: Tidak takut teks dalam imej, memberikan pemaparan teks berkualiti tinggi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apa yang perlu dilakukan jika penggunaan memori terlalu tinggi
Apa yang perlu dilakukan jika penggunaan memori terlalu tinggi
 Bagaimana untuk menyelesaikan ralat parsererror
Bagaimana untuk menyelesaikan ralat parsererror
 Tutorial tetapan kata laluan permulaan Windows 10
Tutorial tetapan kata laluan permulaan Windows 10
 Bolehkah percikan api Douyin dinyalakan semula jika ia telah dimatikan selama lebih daripada tiga hari?
Bolehkah percikan api Douyin dinyalakan semula jika ia telah dimatikan selama lebih daripada tiga hari?
 Apakah protokol yang termasuk dalam protokol ssl?
Apakah protokol yang termasuk dalam protokol ssl?
 Kaedah pembundaran Java
Kaedah pembundaran Java
 Windows tidak boleh mengakses laluan peranti atau penyelesaian fail yang ditentukan
Windows tidak boleh mengakses laluan peranti atau penyelesaian fail yang ditentukan
 Keserasian pelayar
Keserasian pelayar








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



