
 pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk mengekstrak ayat utama daripada fail PDF menggunakan Python untuk NLP?
pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk mengekstrak ayat utama daripada fail PDF menggunakan Python untuk NLP?
Bagaimana untuk mengekstrak ayat utama daripada fail PDF menggunakan Python untuk NLP?


Bagaimana cara menggunakan Python untuk NLP untuk mengekstrak ayat utama daripada fail PDF?
Pengenalan:
Dengan perkembangan pesat teknologi maklumat, Natural Language Processing (NLP) memainkan peranan penting dalam bidang seperti analisis teks, pengekstrakan maklumat dan terjemahan mesin. Dalam aplikasi praktikal, selalunya perlu untuk mengekstrak maklumat penting daripada sejumlah besar data teks, seperti mengekstrak ayat utama daripada fail PDF. Artikel ini akan memperkenalkan cara menggunakan pakej NLP Python untuk mengekstrak ayat utama daripada fail PDF, dan memberikan contoh kod terperinci.
Langkah 1: Pasang perpustakaan Python yang diperlukan
Sebelum kita mula, kita perlu memasang beberapa perpustakaan Python untuk memudahkan pemprosesan teks seterusnya dan penghuraian fail PDF.
1. Pasang perpustakaan nltk:
Masukkan arahan berikut pada baris arahan untuk memasang perpustakaan nltk:
pip install nltk
2 Pasang perpustakaan pdfminer:
Masukkan arahan berikut pada baris arahan untuk memasang perpustakaan pdfminer:
pip install pdfminer.six
Langkah 2: Menghuraikan fail PDF
Mula-mula, kita perlu menukar fail PDF kepada format teks biasa. Pustaka pdfminer memberikan kami fungsi untuk menghuraikan fail PDF.
Berikut ialah fungsi yang boleh menukar fail PDF kepada teks biasa:
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from io import StringIO
def convert_pdf_to_text(file_path):
resource_manager = PDFResourceManager()
string_io = StringIO()
laparams = LAParams()
device = TextConverter(resource_manager, string_io, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
with open(file_path, 'rb') as file:
for page in PDFPage.get_pages(file):
interpreter.process_page(page)
text = string_io.getvalue()
device.close()
string_io.close()
return textLangkah 3: Ekstrak ayat utama
Seterusnya, kita perlu menggunakan perpustakaan nltk untuk mengekstrak ayat utama. nltk menyediakan fungsi yang kaya untuk tokenisasi, pembahagian perkataan dan pembahagian ayat teks.
Berikut ialah fungsi yang boleh mengekstrak ayat utama daripada teks yang diberikan:
import nltk
def extract_key_sentences(text, num_sentences):
sentences = nltk.sent_tokenize(text)
word_frequencies = {}
for sentence in sentences:
words = nltk.word_tokenize(sentence)
for word in words:
if word not in word_frequencies:
word_frequencies[word] = 1
else:
word_frequencies[word] += 1
sorted_word_frequencies = sorted(word_frequencies.items(), key=lambda x: x[1], reverse=True)
top_sentences = [sentence for (sentence, _) in sorted_word_frequencies[:num_sentences]]
return top_sentencesLangkah 4: Lengkapkan kod contoh
Berikut ialah contoh kod lengkap yang menunjukkan cara mengekstrak ayat utama daripada fail PDF:
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from io import StringIO
import nltk
def convert_pdf_to_text(file_path):
resource_manager = PDFResourceManager()
string_io = StringIO()
laparams = LAParams()
device = TextConverter(resource_manager, string_io, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
with open(file_path, 'rb') as file:
for page in PDFPage.get_pages(file):
interpreter.process_page(page)
text = string_io.getvalue()
device.close()
string_io.close()
return text
def extract_key_sentences(text, num_sentences):
sentences = nltk.sent_tokenize(text)
word_frequencies = {}
for sentence in sentences:
words = nltk.word_tokenize(sentence)
for word in words:
if word not in word_frequencies:
word_frequencies[word] = 1
else:
word_frequencies[word] += 1
sorted_word_frequencies = sorted(word_frequencies.items(), key=lambda x: x[1], reverse=True)
top_sentences = [sentence for (sentence, _) in sorted_word_frequencies[:num_sentences]]
return top_sentences
# 示例使用
pdf_file = 'example.pdf'
text = convert_pdf_to_text(pdf_file)
key_sentences = extract_key_sentences(text, 5)
for sentence in key_sentences:
print(sentence) Ringkasan :
Artikel ini memperkenalkan kaedah mengekstrak ayat utama daripada fail PDF menggunakan pakej NLP Python. Dengan menukar fail PDF kepada teks biasa melalui perpustakaan pdfminer, dan menggunakan tokenisasi dan fungsi segmentasi ayat perpustakaan nltk, kami boleh mengekstrak ayat utama dengan mudah. Kaedah ini digunakan secara meluas dalam bidang seperti pengekstrakan maklumat, rumusan teks dan pembinaan graf pengetahuan. Saya harap kandungan artikel ini berguna kepada anda dan boleh digunakan dalam aplikasi praktikal.
Atas ialah kandungan terperinci Bagaimana untuk mengekstrak ayat utama daripada fail PDF menggunakan Python untuk NLP?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bagaimana untuk menggabungkan PDF pada iPhone
Feb 02, 2024 pm 04:05 PM
Bagaimana untuk menggabungkan PDF pada iPhone
Feb 02, 2024 pm 04:05 PM
Apabila bekerja dengan berbilang dokumen atau berbilang halaman dokumen yang sama, anda mungkin mahu menggabungkannya ke dalam satu fail untuk dikongsi dengan orang lain. Untuk perkongsian mudah, Apple membenarkan anda menggabungkan berbilang fail PDF ke dalam satu fail untuk mengelakkan penghantaran berbilang fail. Dalam siaran ini, kami akan membantu anda mengetahui semua cara untuk menggabungkan dua atau lebih PDF ke dalam satu fail PDF pada iPhone. Cara Menggabungkan PDF pada iPhone Pada iOS, anda boleh menggabungkan fail PDF menjadi satu dalam dua cara – menggunakan apl Fail dan apl Pintasan. Kaedah 1: Gunakan apl Fail Cara paling mudah untuk menggabungkan dua atau lebih PDF ke dalam satu fail ialah menggunakan apl Fail. Buka pada iPhone
 3 Cara Mendapatkan Teks daripada PDF pada iPhone
Mar 16, 2024 pm 09:20 PM
3 Cara Mendapatkan Teks daripada PDF pada iPhone
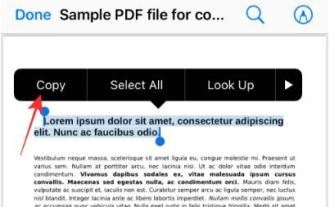
Mar 16, 2024 pm 09:20 PM
Ciri Teks Langsung Apple mengecam teks, nota tulisan tangan dan nombor dalam foto atau melalui aplikasi Kamera dan membolehkan anda menampal maklumat tersebut pada mana-mana aplikasi lain. Tetapi apa yang perlu dilakukan apabila anda bekerja dengan PDF dan ingin mengekstrak teks daripadanya? Dalam siaran ini, kami akan menerangkan semua cara untuk mengekstrak teks daripada fail PDF pada iPhone. Cara Mendapatkan Teks daripada Fail PDF pada iPhone [3 Kaedah] Kaedah 1: Seret Teks pada PDF Cara paling mudah untuk mengekstrak teks daripada PDF adalah dengan menyalinnya, sama seperti pada mana-mana apl lain dengan teks . 1. Buka fail PDF yang ingin anda ekstrak teks, kemudian tekan lama di mana-mana pada PDF dan mula menyeret bahagian teks yang ingin anda salin. 2
 Bagaimana untuk mengesahkan tandatangan dalam PDF
Feb 18, 2024 pm 05:33 PM
Bagaimana untuk mengesahkan tandatangan dalam PDF
Feb 18, 2024 pm 05:33 PM
Kami biasanya menerima fail PDF daripada kerajaan atau agensi lain, sesetengahnya dengan tandatangan digital. Selepas mengesahkan tandatangan, kami melihat mesej SignatureValid dan tanda semak hijau. Sekiranya tandatangan tidak disahkan, kesahihannya tidak diketahui. Mengesahkan tandatangan adalah penting, mari lihat cara melakukannya dalam PDF. Cara Mengesahkan Tandatangan dalam PDF Mengesahkan tandatangan dalam format PDF menjadikannya lebih boleh dipercayai dan dokumen lebih cenderung untuk diterima. Anda boleh mengesahkan tandatangan dalam dokumen PDF dengan cara berikut. Buka PDF dalam Adobe Reader Klik kanan tandatangan dan pilih Show Signature Properties Klik butang Tunjukkan Sijil Penandatangan Tambah tandatangan pada senarai Sijil Dipercayai daripada tab Amanah Klik Sahkan Tandatangan untuk melengkapkan pengesahan Biarkan
 Bagaimana untuk menukar fail pdg kepada pdf
Nov 14, 2023 am 10:41 AM
Bagaimana untuk menukar fail pdg kepada pdf
Nov 14, 2023 am 10:41 AM
Kaedah termasuk: 1. Gunakan alat penukaran dokumen profesional 2. Gunakan alat penukaran dalam talian 3. Gunakan pencetak maya.
 Cara mengimport dan menganotasi PDF dalam Apple Notes
Oct 13, 2023 am 08:05 AM
Cara mengimport dan menganotasi PDF dalam Apple Notes
Oct 13, 2023 am 08:05 AM
Dalam iOS 17 dan MacOS Sonoma, Apple menambah keupayaan untuk membuka dan menganotasi PDF terus dalam apl Nota. Baca terus untuk mengetahui cara ia dilakukan. Dalam versi terkini iOS dan macOS, Apple telah mengemas kini apl Nota untuk menyokong PDF sebaris, yang bermaksud anda boleh memasukkan PDF ke dalam Nota dan kemudian membaca, memberi anotasi dan bekerjasama pada dokumen tersebut. Ciri ini juga berfungsi dengan dokumen yang diimbas dan tersedia pada kedua-dua iPhone dan iPad. Menganotasi PDF dalam Nota pada iPhone dan iPad Jika anda menggunakan iPhone dan ingin menganotasi PDF dalam Nota, perkara pertama yang perlu dilakukan ialah memilih fail PDF
 Bagaimana untuk mengeksport fail xmind ke fail pdf
Mar 20, 2024 am 10:30 AM
Bagaimana untuk mengeksport fail xmind ke fail pdf
Mar 20, 2024 am 10:30 AM
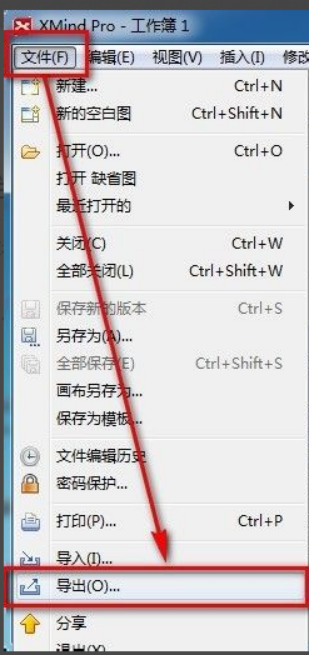
xmind adalah perisian pemetaan minda yang sangat praktikal Ia adalah bentuk peta yang dibuat menggunakan pemikiran dan inspirasi orang Selepas kami membuat fail xmind, kami biasanya menukarnya ke dalam format fail pdf untuk memudahkan penyebaran dan penggunaan semua orang ke fail pdf? Di bawah adalah langkah-langkah khusus untuk rujukan anda. 1. Mula-mula, mari kita tunjukkan cara mengeksport peta minda ke dokumen PDF. Pilih butang fungsi [Fail]-[Eksport]. 2. Pilih [dokumen PDF] dalam antara muka yang baru muncul dan klik butang [Seterusnya]. 3. Pilih tetapan dalam antara muka eksport: saiz kertas, orientasi, resolusi dan lokasi penyimpanan dokumen. Selepas melengkapkan tetapan, klik butang [Selesai]. 4. Jika anda klik butang [Selesai].
 Selesaikan masalah memuat turun fail PDF dalam PHP7
Feb 29, 2024 am 11:12 AM
Selesaikan masalah memuat turun fail PDF dalam PHP7
Feb 29, 2024 am 11:12 AM
Selesaikan masalah yang dihadapi dalam memuat turun fail PDF dalam PHP7 Dalam pembangunan web, kami sering menghadapi keperluan untuk menggunakan PHP untuk memuat turun fail. Terutamanya memuat turun fail PDF boleh membantu pengguna mendapatkan maklumat atau fail yang diperlukan. Walau bagaimanapun, kadangkala anda akan menghadapi beberapa masalah semasa memuat turun fail PDF dalam PHP7, seperti aksara bercelaru dan muat turun yang tidak lengkap. Artikel ini akan memperincikan cara menyelesaikan masalah yang mungkin anda hadapi semasa memuat turun fail PDF dalam PHP7 dan memberikan beberapa contoh kod khusus. Analisis masalah: Dalam PHP7, disebabkan pengekodan aksara dan H
 Ketahui cara memutar fail PDF menggunakan kekunci pintasan penyemak imbas tepi
Jan 05, 2024 am 09:17 AM
Ketahui cara memutar fail PDF menggunakan kekunci pintasan penyemak imbas tepi
Jan 05, 2024 am 09:17 AM
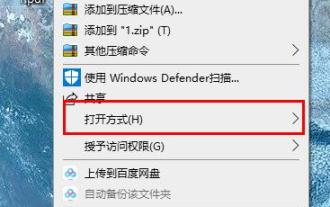
Walaupun fail pdf sangat mudah digunakan, ramai rakan masih suka menggunakan perkataan untuk mengedit dan melihatnya, jadi bagaimana untuk menukarnya? Mari kita lihat kaedah operasi terperinci di bawah. Kekunci pintasan putaran pdf pelayar tepi: A: Kekunci pintasan untuk putaran ialah F9 1. Klik kanan fail pdf dan pilih "Buka dengan". 2. Pilih "Microsoft edge" untuk membuka fail pdf. 3. Selepas memasukkan fail pdf, bar tugas akan muncul di bawah. 4. Klik butang putaran di sebelah tanda "+" untuk berputar ke kanan.
