
 Peranti teknologi
AI
Bagaimana untuk membina sistem percubaan AB dalam senario pertumbuhan pengguna?
Peranti teknologi
AI
Bagaimana untuk membina sistem percubaan AB dalam senario pertumbuhan pengguna?
Bagaimana untuk membina sistem percubaan AB dalam senario pertumbuhan pengguna?


1. Masalah yang dihadapi oleh eksperimen dalam senario pengguna baharu
1. Panorama UG
Inilah panorama UG.
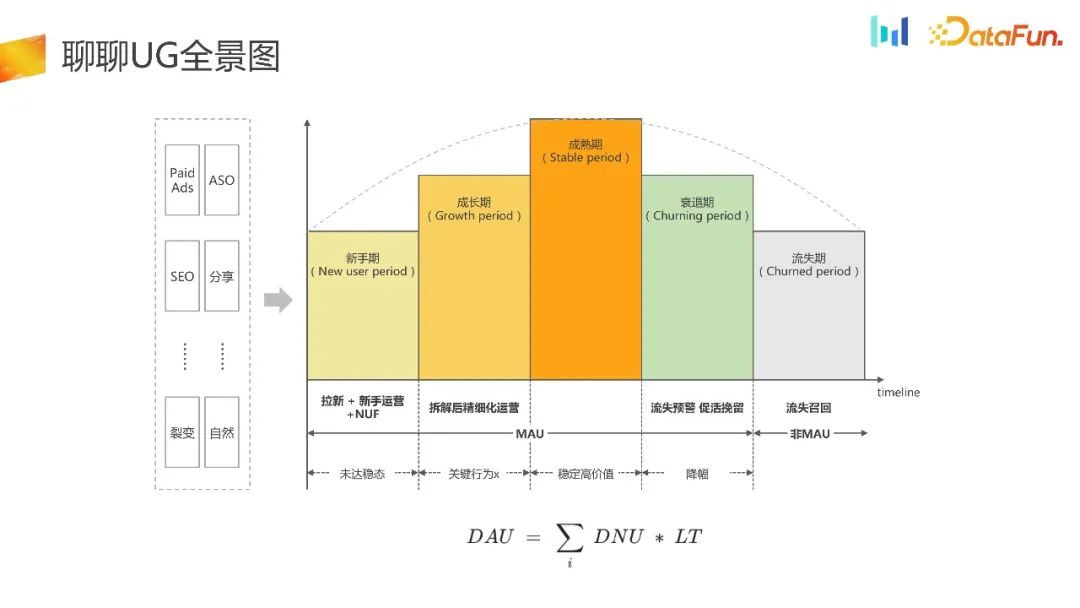
UG Dapatkan pelanggan dan alihkan trafik ke APP melalui saluran seperti Iklan Berbayar, ASO, SEO dan saluran lain. Seterusnya, kami akan melakukan beberapa operasi dan panduan untuk orang baru untuk mengaktifkan pengguna dan membawa mereka ke peringkat kematangan. Pengguna seterusnya mungkin perlahan-lahan menjadi tidak aktif, memasuki tempoh penolakan, atau bahkan memasuki tempoh churn. Dalam tempoh ini, kami akan melakukan beberapa amaran awal untuk churn, panggil balik untuk mempromosikan pengaktifan, dan kemudian beberapa panggilan balik untuk pengguna yang hilang.
boleh diringkaskan seperti formula dalam gambar di atas iaitu DAU bersamaan dengan DNU darab LT. Semua kerja dalam senario UG boleh dibongkar berdasarkan formula ini.
2. Prinsip percubaan AB
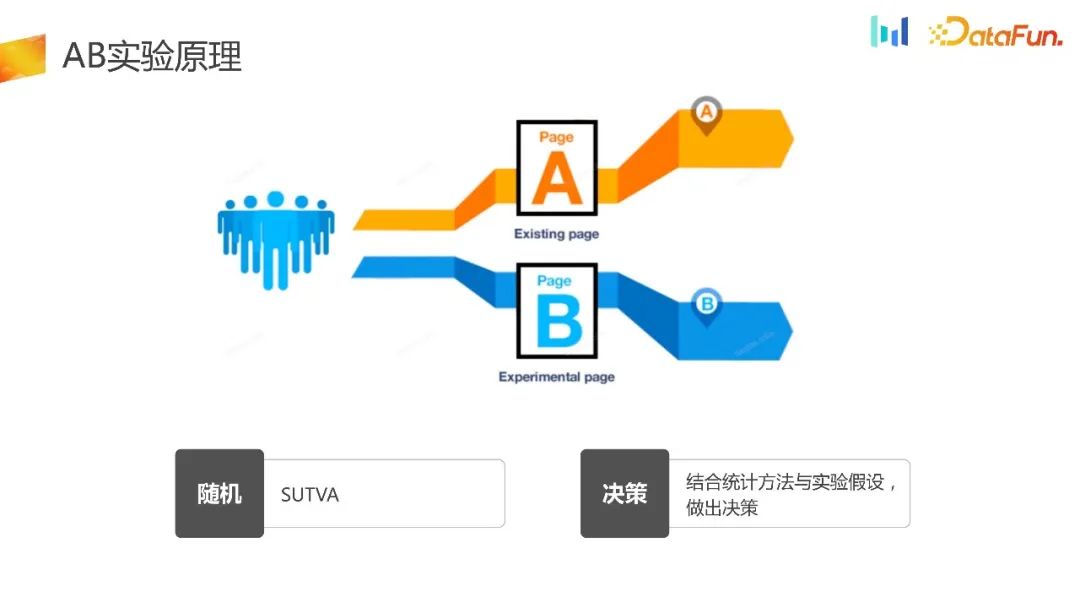
Tujuan percubaan AB adalah untuk memperuntukkan trafik secara rawak sepenuhnya dan menggunakan strategi yang berbeza untuk kumpulan eksperimen dan kumpulan kawalan yang berbeza. Akhirnya, keputusan saintifik dibuat dengan menggabungkan kaedah statistik dan hipotesis eksperimen, yang membentuk rangka kerja keseluruhan eksperimen. Pada masa ini, jenis pengedaran percubaan di pasaran dibahagikan secara kasar kepada dua jenis: pengedaran platform percubaan dan pengedaran tempatan pelanggan
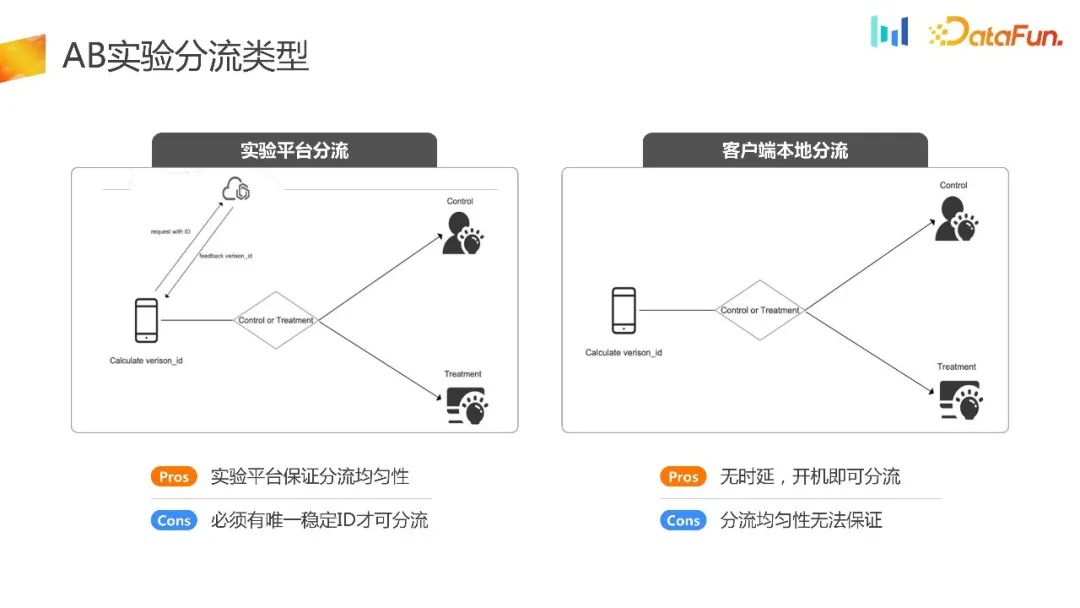
Pengedaran platform eksperimen mempunyai prasyarat. Ia memerlukan peranti boleh mendapatkan ID yang stabil selepas pemula . Berdasarkan ini ID meminta platform percubaan untuk melengkapkan logik berkaitan pemuatan, mengembalikan ID pemuatan ke terminal, dan kemudian terminal membuat strategi yang sepadan berdasarkan ID yang diterima. Kelebihannya ialah ia mempunyai platform eksperimen yang dapat memastikan keseragaman dan kestabilan shunt. Kelemahannya ialah peralatan mesti dimulakan sebelum shunting eksperimen boleh dijalankan.
Kaedah pemunggahan lain ialah pemunggahan tempatan sebelah pelanggan. Kaedah ini agak khusus dan sesuai terutamanya untuk beberapa adegan UG, adegan pembukaan skrin pengiklanan dan adegan permulaan prestasi. Dengan cara ini, semua logik pemuatan selesai apabila klien dimulakan. Kelebihannya adalah jelas, iaitu, tiada kelewatan dan pengedaran boleh dijalankan serta-merta selepas dihidupkan. Secara logiknya, keseragaman pengedarannya juga boleh dijamin. Walau bagaimanapun, dalam senario perniagaan sebenar, selalunya terdapat masalah dengan keseragaman pengedarannya. Sebabnya akan diperkenalkan seterusnya
3. Masalah yang dihadapi oleh senario pengguna baharu percubaan AB
UG Masalah pertama yang sebenarnya dihadapi oleh senario tersebut ialah mengalihkan trafik seawal mungkin.
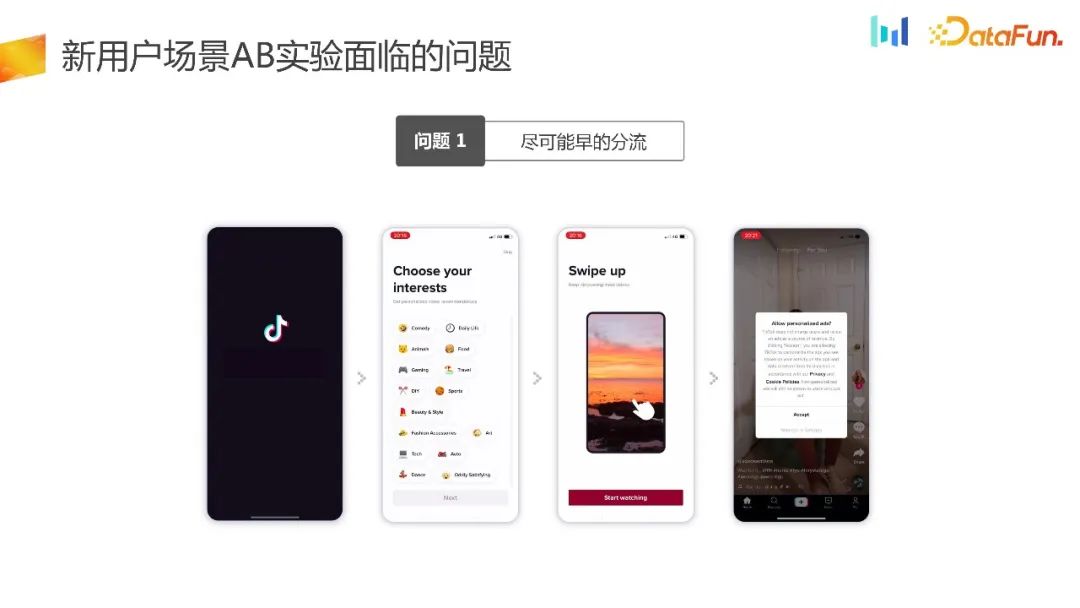
Berikut ialah contoh, seperti halaman penerimaan trafik di sini Pengurus produk merasakan bahawa UI boleh dioptimumkan untuk menambah baik penunjuk teras. Dalam senario sedemikian, kami berharap percubaan akan dicuba secepat mungkin.
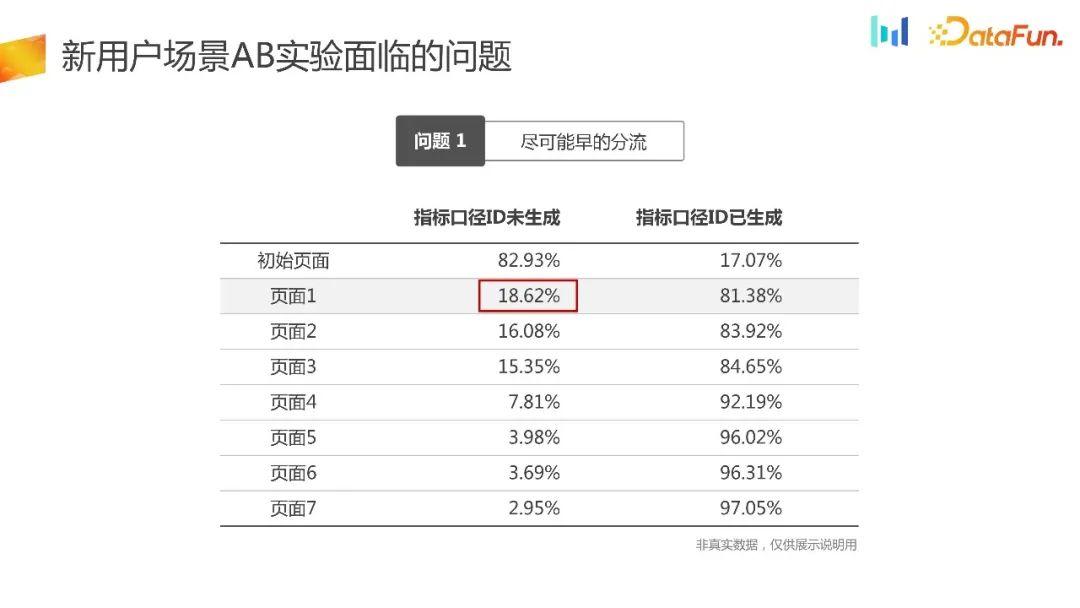
Semasa proses pemuatan pada halaman 1, peranti akan dimulakan dan mendapatkan ID. 18.62% pengguna tidak dapat menjana ID. Jika kaedah lencongan platform eksperimen tradisional digunakan, 18.62% pengguna tidak akan dikumpulkan, mengakibatkan masalah bias pemilihan yang wujud
Selain itu, trafik pengguna baharu adalah sangat berharga, dengan 18.62% pengguna baharu Ia tidak boleh digunakan untuk percubaan, dan akan terdapat kerugian besar dalam tempoh percubaan dan kecekapan penggunaan trafik.
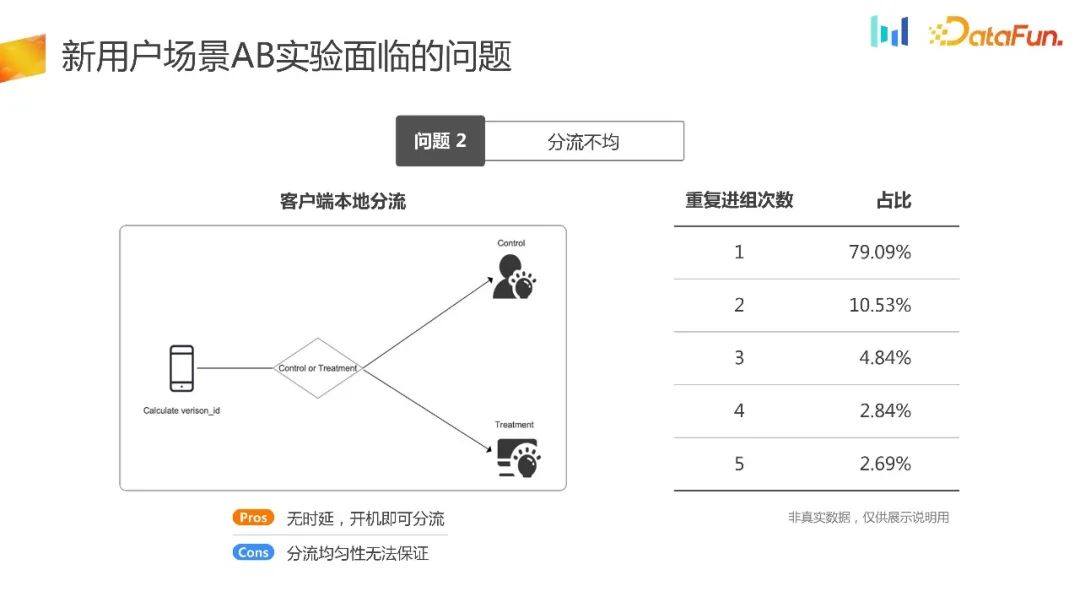
Di masa hadapan, untuk menyelesaikan masalah pemunggahan eksperimen seawal mungkin, kami akan menggunakan pelanggan untuk memunggah eksperimen secara tempatan. Kelebihannya ialah pemunggahan selesai apabila peranti dimulakan. Prinsipnya ialah pertama, apabila memulakan pada terminal, ia boleh menjana nombor rawak dengan sendirinya, mencincang nombor rawak dan kemudian mengumpulkannya dengan cara yang sama, dengan itu menghasilkan kumpulan eksperimen dan kumpulan kawalan. Pada dasarnya, adalah mungkin untuk memastikan bahawa pengagihan trafik adalah sekata Walau bagaimanapun, melalui set data dalam rajah di atas, kita boleh mendapati bahawa lebih daripada 21% pengguna berulang kali memasuki kumpulan yang berbeza.
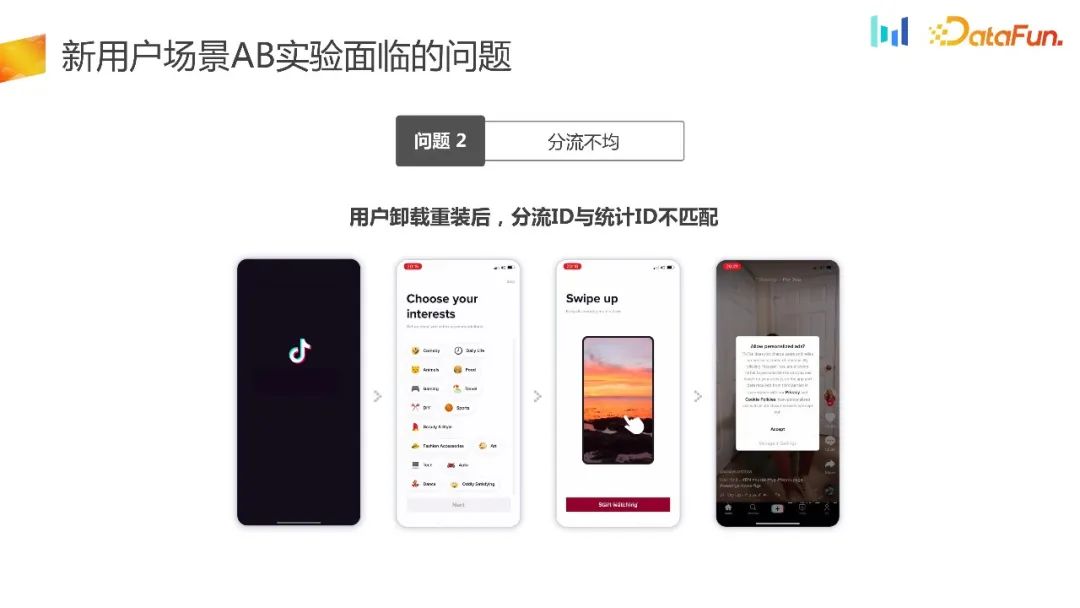
Terdapat senario di mana pengguna beberapa produk yang sangat popular, seperti Honor of Kings atau Douyin, mudah ketagih. Pengguna baharu akan menyahpasang dan memasang semula beberapa kali semasa kitaran percubaan. Mengikut logik lencongan tempatan yang baru disebut, penjanaan dan lencongan nombor rawak akan membolehkan pengguna memasuki kumpulan yang berbeza, supaya ID lencongan dan ID statistik tidak boleh sepadan dengan satu sama satu. Ini menyebabkan masalah pengagihan tidak sekata.
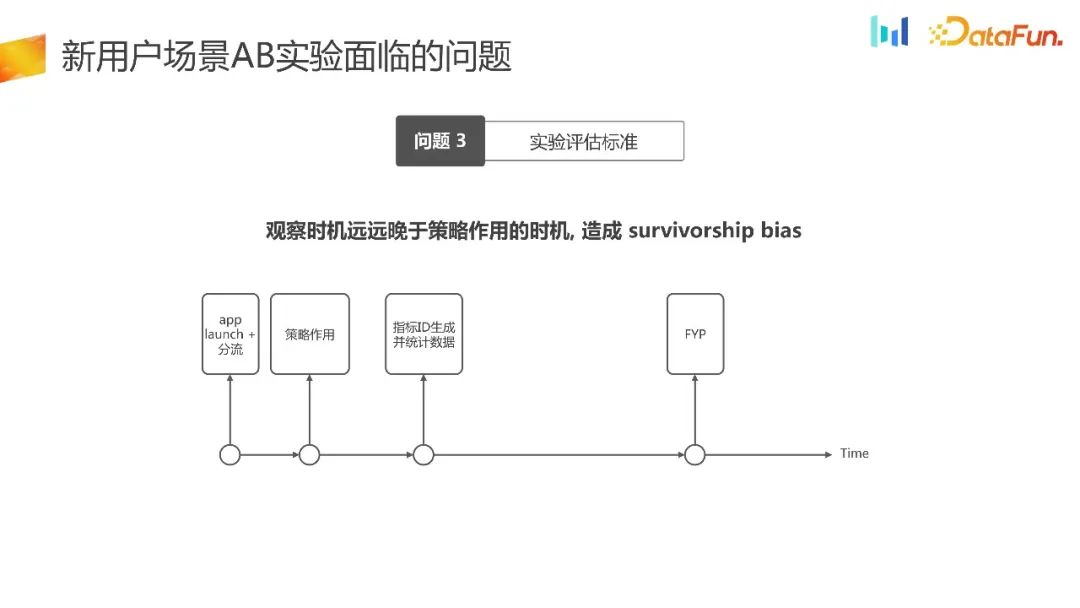
Dalam senario pengguna baharu, kami juga menghadapi masalah kriteria penilaian eksperimen.
Kami telah menyusun semula carta masa trafik pengguna baharu yang mengambil alih senario ini. Pada permulaan aplikasi, kami memilih untuk memunggah. Andaikan bahawa kita boleh mencapai pemasaan pengedaran seragam dan menghasilkan kesan strategik yang sepadan pada masa yang sama. Seterusnya, masa menjana ID statistik penunjuk adalah lewat daripada masa kesan strategi, dan hanya selepas itu data boleh diperhatikan. Masa pemerhatian data jauh ketinggalan berbanding pemasaan kesan strategi, yang akan membawa kepada berat sebelah yang terselamat
2. Sistem eksperimen baharu dan pengesahan saintifiknya
Untuk menyelesaikan masalah di atas, kami mencadangkan satu eksperimen baharu sistem , dan mengesahkannya secara saintifik
1. Pilihan ID lencongan percubaan senario pengguna baharu
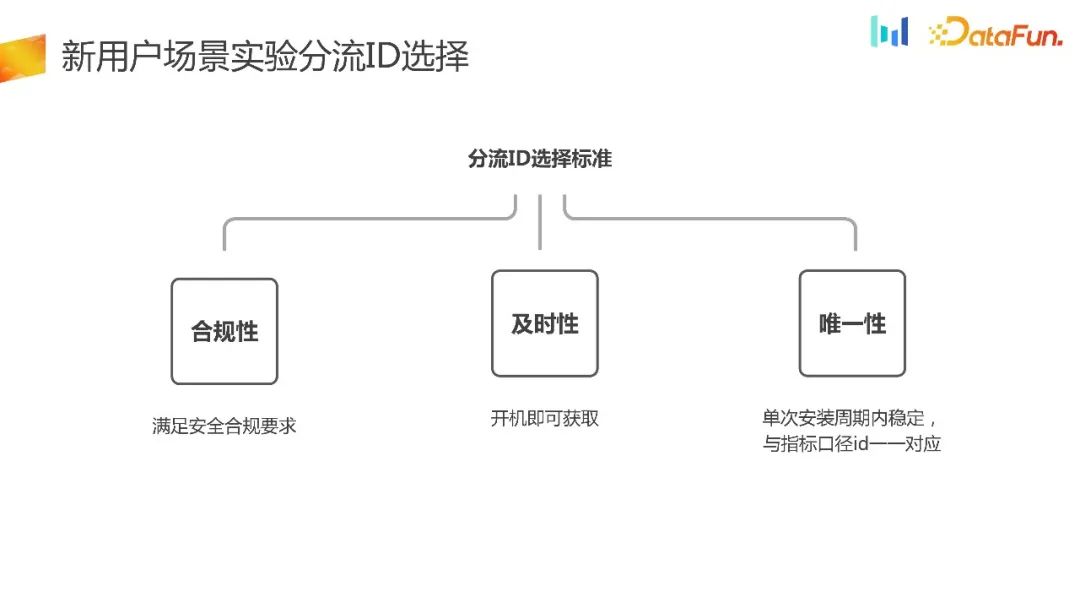
Seperti yang dinyatakan sebelum ini, keperluan pemilihan lencongan untuk pengguna baharu akan agak tinggi, jadi bagaimana untuk memilih eksperimen pengguna baharu Bagaimana pula dengan ID shunt? Berikut ialah beberapa prinsip:
- Pematuhan, sama ada perniagaan di luar negara atau perniagaan domestik, pematuhan keselamatan adalah yang pertama sekali Pematuhan keselamatan mesti dipenuhi, jika tidak, impaknya akan menjadi sangat besar apabila ia dikeluarkan dari rak.
- Ketepatan masa, untuk senario pengguna baharu, ia mestilah tepat pada masanya, dan anda boleh mendapatkan lencongan sebaik sahaja anda menghidupkan telefon.
- Keunikan, dalam satu kitaran pemasangan, ID shunt adalah stabil dan boleh membentuk surat-menyurat satu dengan satu dengan ID penunjuk. Seperti yang dapat dilihat daripada data dalam rajah di bawah, nisbah padanan satu dengan satu antara ID lencongan dan ID berkaliber pengiraan penunjuk telah mencapai 99.79%, dan nisbah satu dengan satu antara ID pengiraan penunjuk dan ID lencongan juga telah mencapai 99.59%. Pada asasnya, ia boleh disahkan bahawa ID lencongan dan ID penunjuk yang dipilih mengikut standard boleh mencapai padanan satu lawan satu.

2. Pengesahan saintifik keupayaan pemunggahan
Selepas memilih ID pemunggahan, keupayaan pemunggahan selalunya diselesaikan dalam dua cara, yang pertama melalui platform percubaan, dan yang kedua ialah melalui platform percubaan.
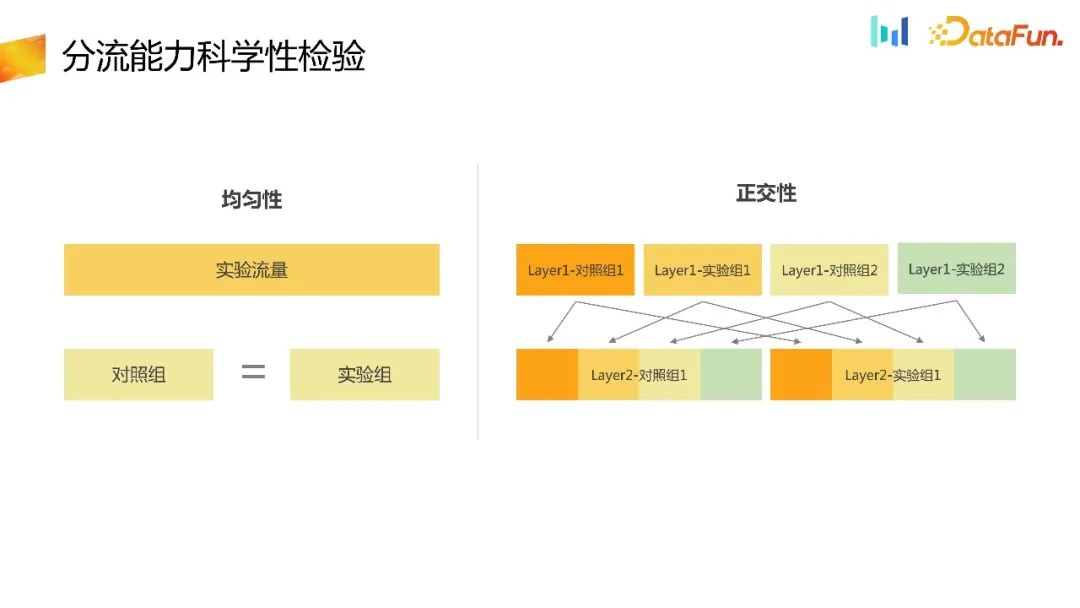
Selepas anda mempunyai ID pemunggahan, berikan ID pemunggahan ke platform percubaan dan lengkapkan keupayaan pemunggahan dalam platform percubaan. Sebagai platform pengedaran, perkara paling asas adalah untuk mengesahkan kerawaknya. Yang pertama ialah keseragaman. Dalam lapisan percubaan yang sama, trafik dibahagikan sama rata kepada banyak baldi dan bilangan kumpulan dalam setiap baldi hendaklah genap. Ia boleh dipermudahkan di sini Jika terdapat hanya satu eksperimen pada satu lapisan dan ia dibahagikan kepada dua kumpulan, a dan b, bilangan pengguna dalam kumpulan kawalan dan kumpulan eksperimen hendaklah lebih kurang sama, dengan itu mengesahkan keseragaman bagi keupayaan lencongan. Kedua, untuk eksperimen berbilang lapisan, eksperimen berbilang lapisan hendaklah ortogon antara satu sama lain dan tidak terjejas. Begitu juga, ia juga perlu untuk mengesahkan keortogonan antara eksperimen pada lapisan yang berbeza. Keseragaman dan ortogonal boleh disahkan melalui ujian kategori statistik.
Selepas memperkenalkan ID pemilihan lencongan dan keupayaan lencongan, akhirnya kami perlu mengesahkan sama ada keputusan lencongan yang baru dicadangkan memenuhi keperluan eksperimen AB dari tahap keputusan penunjuk.
3. Pengesahan saintifik hasil lencongan
Dengan menggunakan platform dalaman, kami menjalankan berbilang simulasi AA
untuk membandingkan sama ada kumpulan kawalan dan kumpulan eksperimen memenuhi keperluan eksperimen pada penunjuk yang sepadan. Seterusnya, mari kita lihat set data ini.

Saya telah mencuba beberapa kumpulan indeks ujian t Dapat difahami bahawa untuk banyak eksperimen, kadar ralat jenis satu sepatutnya sangat tinggi. Kebarangkalian kecil, dengan mengandaikan bahawa kadar ralat jenis satu dijadualkan sekitar 0. 055%, selang keyakinannya sebenarnya seharusnya sekitar 1000 kali, iaitu antara 0. 0365- 0. 0635. Anda boleh melihat bahawa beberapa penunjuk yang dijadikan sampel dalam lajur pertama berada dalam julat pelaksanaan ini, jadi dari perspektif kadar ralat jenis satu, sistem percubaan sedia ada adalah OK.
Pada masa yang sama, memandangkan ujian itu adalah ujian untuk statistik t, statistik t yang sepadan hendaklah lebih kurang mematuhi taburan normal di bawah taburan trafik yang besar. Anda juga boleh menguji taburan normal statistik ujian-t. Ujian taburan normal digunakan di sini, dan anda boleh melihat bahawa keputusan ujian juga jauh lebih besar daripada 0.05, iaitu, hipotesis nol ditubuhkan, iaitu, statistik t yang lebih kurang mematuhi taburan normal.
Untuk setiap ujian, nilai p bagi keputusan ujian statistik t adalah lebih kurang mematuhi pengagihan seragam dalam banyak eksperimen, dan ia juga boleh Anda juga boleh melihat hasil yang serupa dengan menguji taburan seragam pvalue, pvalue_uniform_test, yang juga lebih besar daripada 0.05. Oleh itu, hipotesis nol bahawa nilai p lebih kurang mematuhi taburan seragam juga adalah OK.
Di atas telah disahkan daripada surat-menyurat satu-dengan-satu antara ID lencongan dan kaliber pengiraan penunjuk, keupayaan lencongan dan keputusan penunjuk hasil lencongan sifat saintifik sistem lencongan eksperimen ini.
3. Analisis kes permohonan
Berikut akan diterangkan secara terperinci berdasarkan kes permohonan sebenar dalam Senario UG. Bagaimana untuk menjalankan penilaian eksperimen untuk menyelesaikan masalah ketiga yang dinyatakan sebelum ini
1#1. #
Ini adalah senario penerimaan trafik UG yang biasa Banyak pengoptimuman akan dilakukan semasa bimbingan pengguna baharu NUJ atau tugas pengguna baharu untuk meningkatkan penggunaan trafik. Piawaian penilaian pada masa ini selalunya adalah kadar pengekalan, yang merupakan pemahaman umum semasa dalam industri. 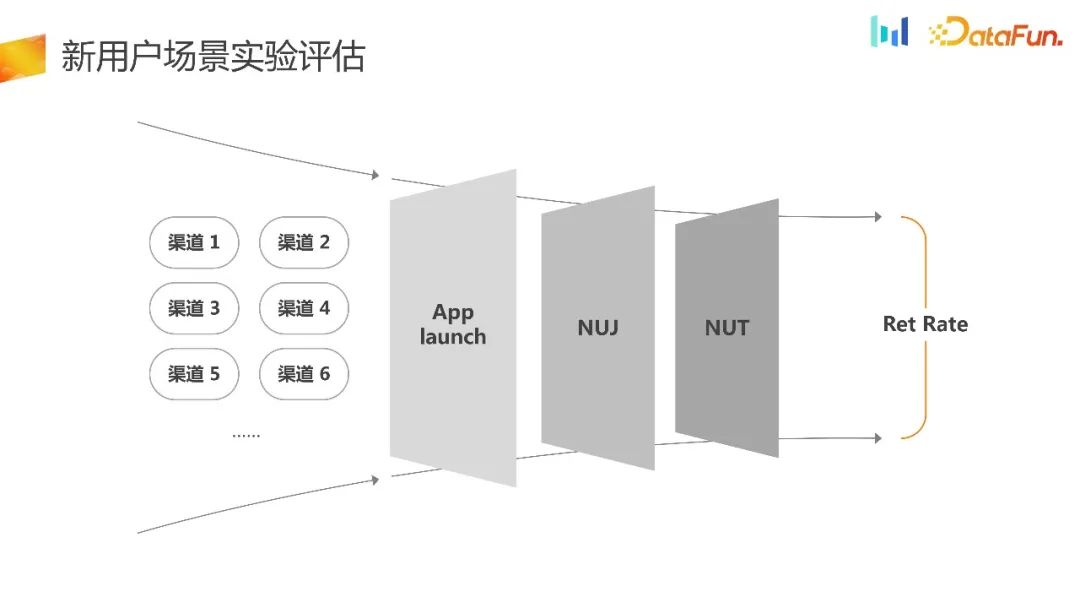
Dengan mengandaikan proses daripada muat turun pengguna baharu kepada pemasangan kepada permulaan pertama, PM merasakan proses sedemikian berguna untuk pengguna , terutamanya bagi pengguna yang tidak pernah mengalami penggunaan produk, ambang adalah terlalu tinggi Sekiranya pengguna membiasakan diri dengan produk dahulu, mengalami detik hip-hop produk, dan kemudian dibimbing untuk log masuk? 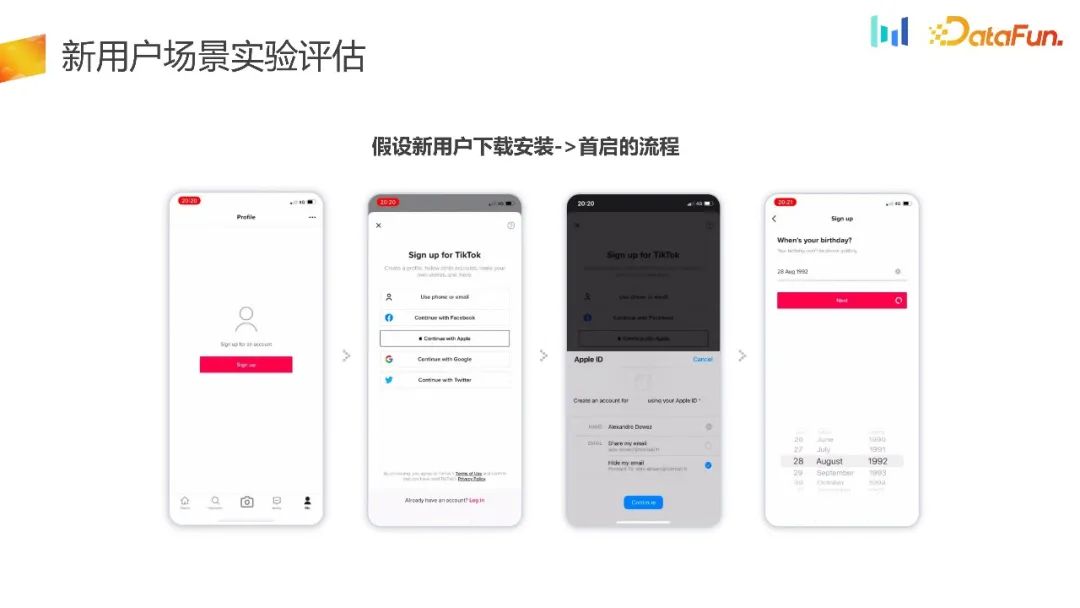
Seterusnya, pengurus produk mengemukakan hipotesis lain, iaitu bagi pengguna yang tidak pernah mengalami produk, dalam Kurangkan rintangan dalam log masuk pengguna baharu atau senario NUJ pengguna baharu. Bagi pengguna yang telah mengalami produk dan pengguna yang telah menukar peranti, proses dalam talian 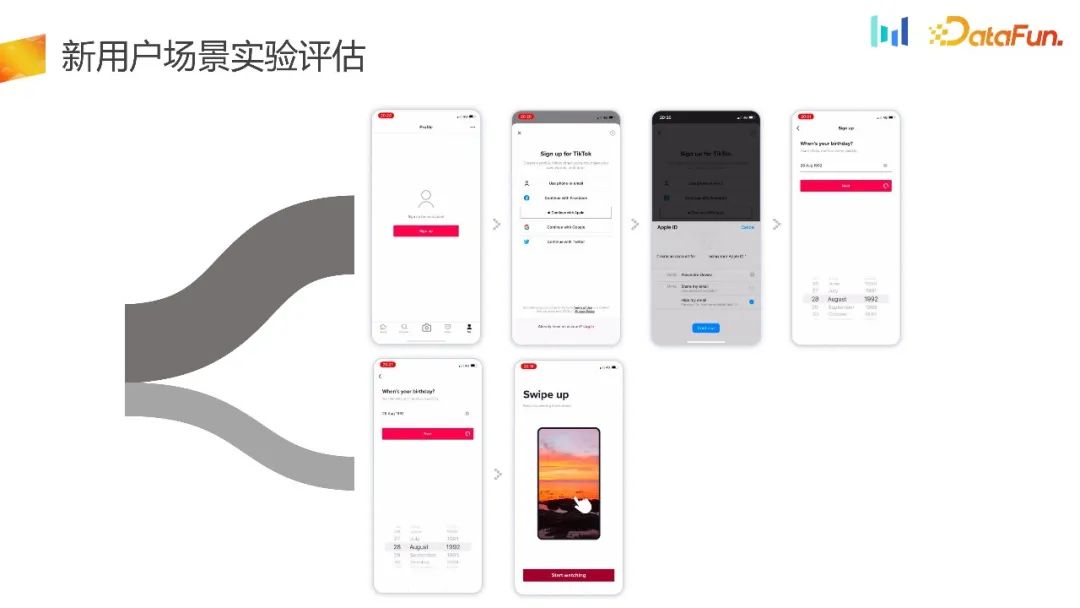
adalah berdasarkan ID penunjuk Kaedah pemunggahan terlebih dahulu memperoleh ID penunjuk dan kemudian memunggahnya. Kaedah pemisahan ini biasanya seragam, dan tidak banyak perbezaan daripada keputusan eksperimen dan kadar pengekalan. Berdasarkan keputusan sedemikian, sukar untuk membuat keputusan yang komprehensif. Percubaan jenis ini sebenarnya membazirkan sebahagian daripada trafik dan mempunyai masalah berat sebelah pemilihan. Oleh itu, kami akan menjalankan eksperimen lencongan tempatan Rajah di bawah menunjukkan keputusan eksperimen lencongan tempatan 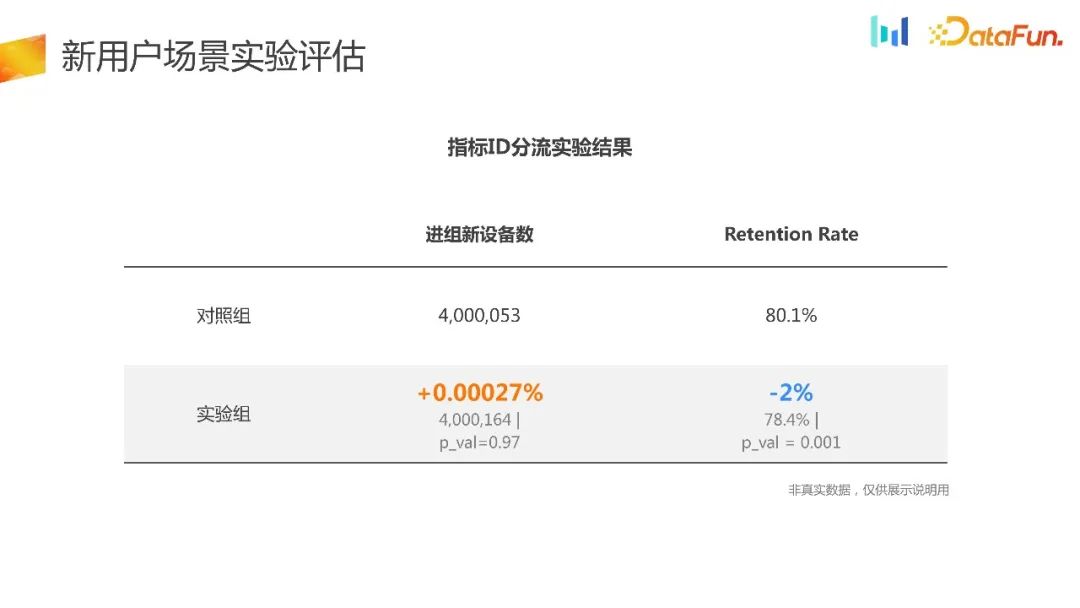
The. ahli baharu yang menyertai kumpulan Akan terdapat perbezaan ketara dalam bilangan peranti, dan ia boleh dipercayai. Pada masa yang sama, terdapat peningkatan dalam kadar pengekalan, tetapi ia sebenarnya negatif dalam penunjuk teras lain, dan arah negatif ini sukar difahami kerana ia sebenarnya sangat berkaitan dengan pengekalan. Oleh itu, berdasarkan data sedemikian, sukar untuk menjelaskan atau mengaitkannya, dan juga sukar untuk membuat keputusan yang komprehensif. 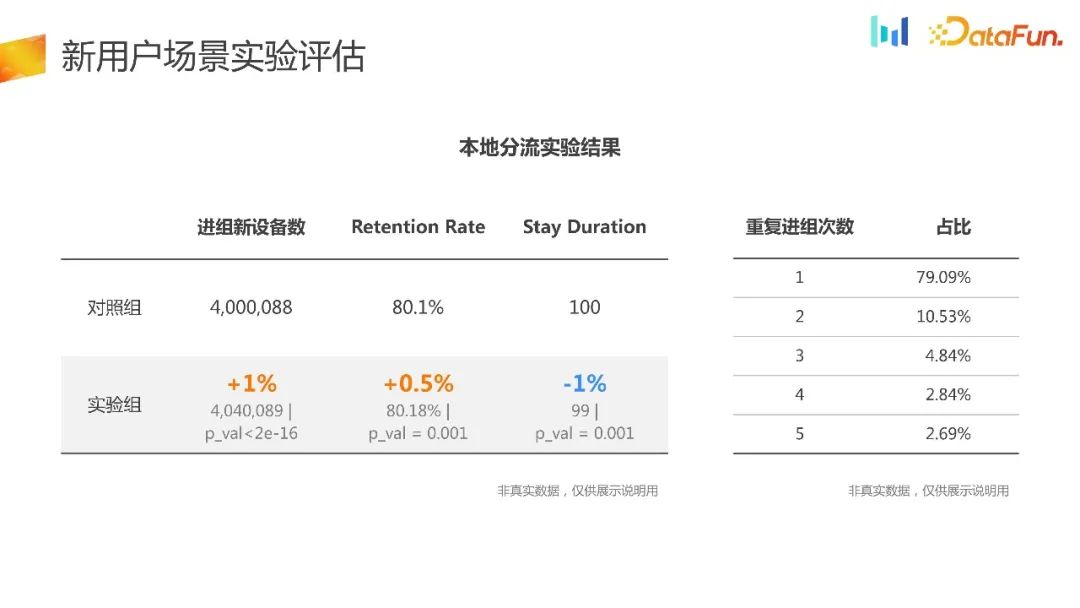
Anda boleh memerhati situasi pengguna yang telah berulang kali memasuki kumpulan, dan anda akan mendapati bahawa lebih daripada 20% pengguna berulang kali diberikan kepada kumpulan yang berbeza. Ini memusnahkan kerawak eksperimen AB dan menyukarkan untuk membuat keputusan perbandingan saintifik
Akhir sekali, lihat hasil eksperimen dengan shunt baharu yang dicadangkan.
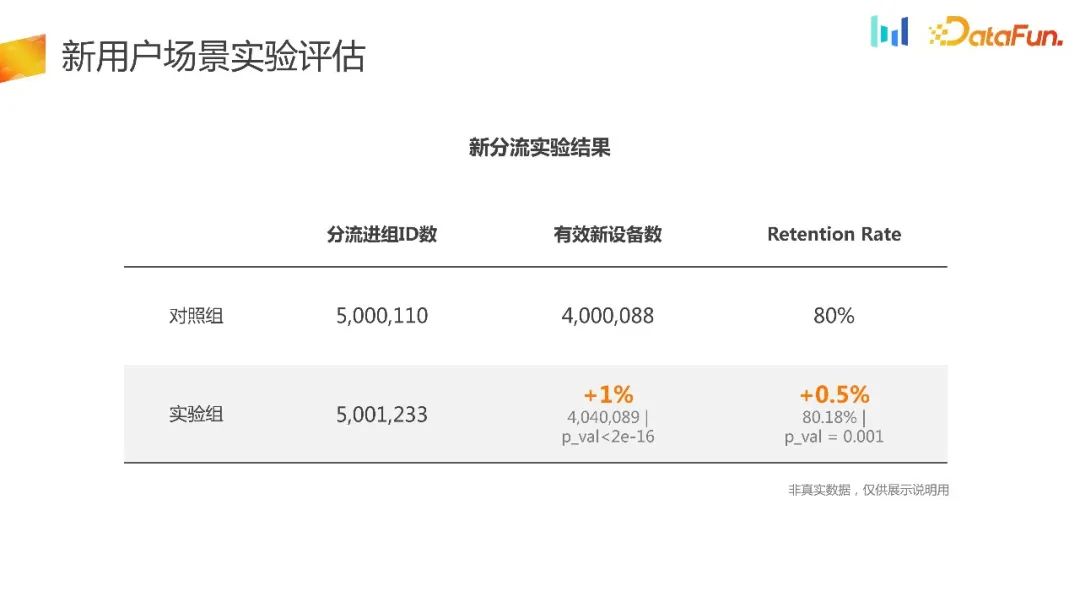
Ia boleh dialihkan apabila ia dihidupkan Kapasiti pengalihan dijamin oleh platform dalaman, yang boleh memastikan keseragaman dan kestabilan pengalihan ke tahap yang besar. Berdasarkan data eksperimen, ia hampir hampir Apabila melakukan ujian punca kuasa dua, kita juga dapat melihat bahawa ia memenuhi keperluan sepenuhnya. Pada masa yang sama, kita dapat melihat bahawa bilangan peranti baharu yang berkesan telah meningkat dengan ketara, sebanyak 1%, dan kadar pengekalan juga telah bertambah baik. Pada masa yang sama, jika anda melihat kumpulan kawalan atau kumpulan percubaan sahaja, anda boleh melihat kadar penukaran trafik berdasarkan ID lencongan kepada peranti baharu yang akhirnya dihasilkan Kumpulan percubaan adalah 1% lebih tinggi daripada kumpulan kawalan. Sebab keputusan ini ialah kumpulan eksperimen sebenarnya telah membesarkan titik masuk pengguna dalam NUJ dan NUT, menjadikannya lebih mudah bagi lebih ramai pengguna untuk masuk, mengalami produk, dan kemudian kekal.
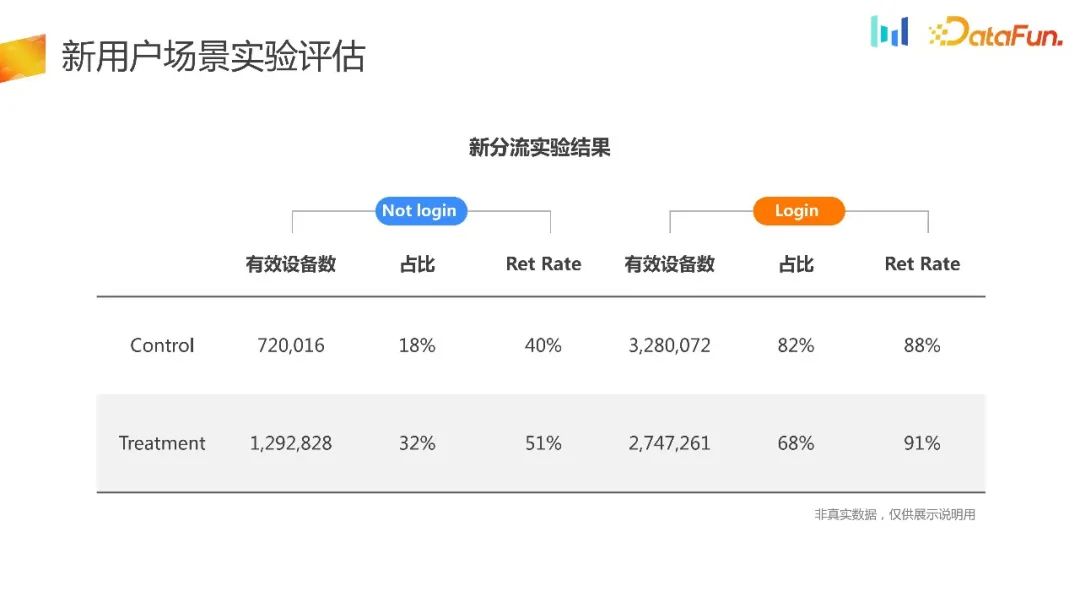
Bahagikan data percubaan kepada bahagian log masuk dan bukan log masuk Ia boleh didapati bahawa bagi pengguna dalam kumpulan percubaan, lebih ramai pengguna memilih mod bukan log masuk untuk mengalami produk, dan kadar pengekalan juga telah. bertambah baik. Ini Hasilnya juga selari dengan jangkaan
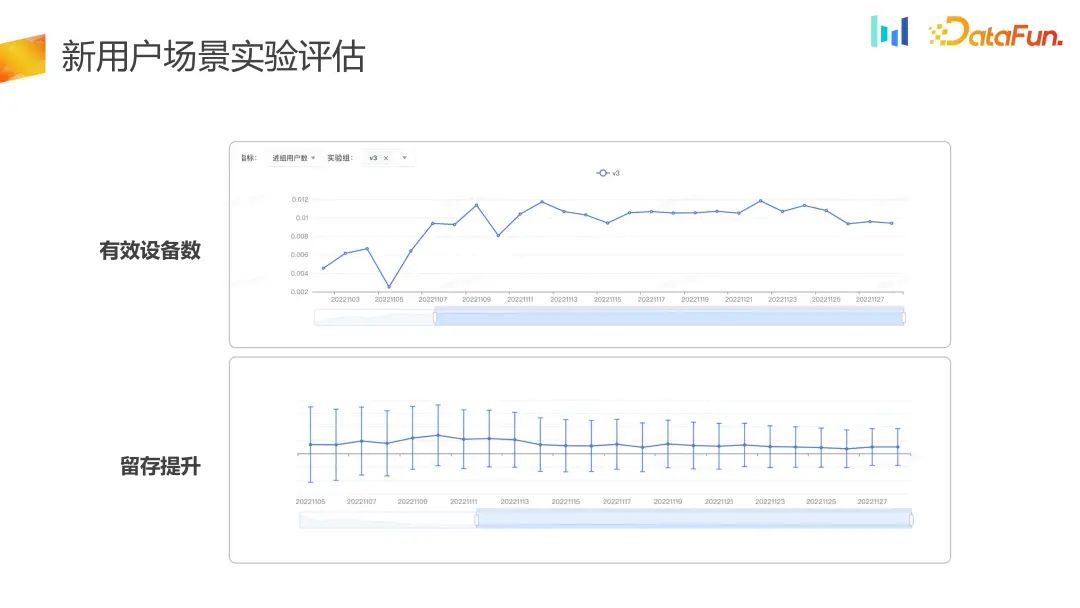
Anda boleh melihat penunjuk mengikut harian Jumlah pengguna yang memasuki kumpulan sebenarnya ditulis dalam tempoh masa yang panjang, ia meningkat secara berterusan, dan penunjuk pengekalan juga telah bertambah baik. Berbanding dengan kumpulan kawalan, kumpulan eksperimen telah bertambah baik dalam bilangan peranti dan pengekalan yang berkesan.
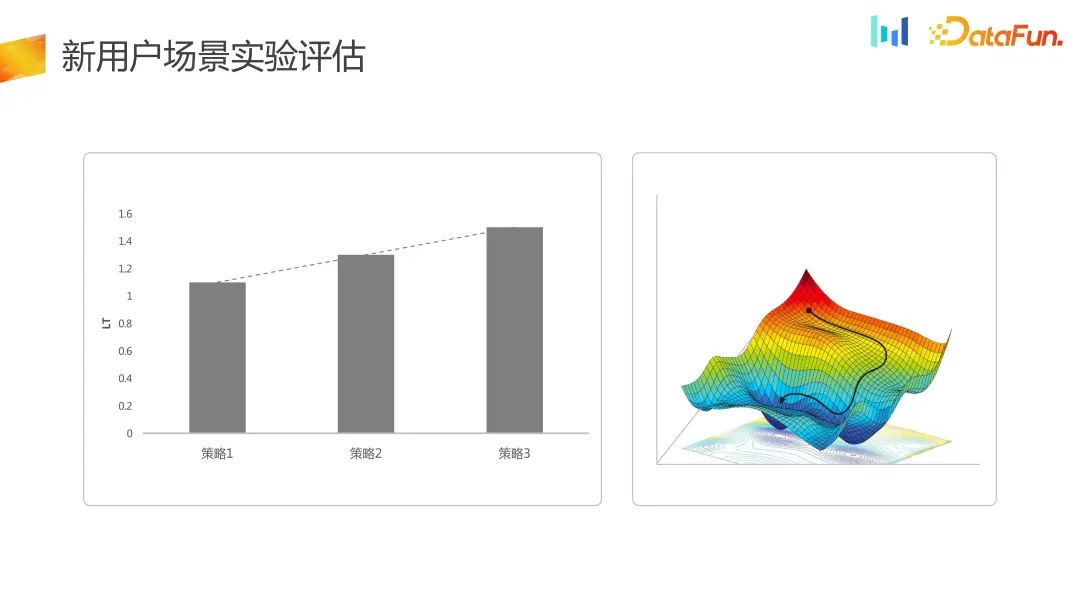
Untuk senario penerimaan trafik pengguna baharu, penunjuk penilaian lebih dinilai daripada dimensi pengekalan atau LT jangka pendek. Di sini, pengoptimuman sebenarnya hanya dilakukan pada ruang satu dimensi pada tahap LT
Dalam sistem percubaan baharu, pengoptimuman satu dimensi ditukar kepada pengoptimuman dua dimensi, dan keseluruhan DNU Shenshang LT telah bertambah baik, jadi Ruang strategi telah berubah daripada satu dimensi sebelumnya kepada dua dimensi, dan pada masa yang sama, kehilangan sebahagian LT boleh diterima dalam beberapa senario.
4. Ringkasan
Akhir sekali, mari kita ringkaskan pembinaan keupayaan percubaan dan piawaian penilaian percubaan dalam senario pengguna baharu.
- UG Sistem percubaan sedia ada dalam senario pengguna baharu tidak dapat menyelesaikan sepenuhnya masalah yang dihadapi oleh penilaian strategi penerimaan trafik pengguna baharu, dan sistem percubaan baharu diperlukan.
- Terdapat beberapa kriteria untuk memilih ID pengalihan Yang pertama ialah pematuhan keselamatan, kemudian ia boleh diperolehi pada permulaan pertama, dan yang ketiga ialah ia stabil dalam satu kitaran pemasangan dan bersifat injektif dengan. hubungan ID penunjuk.
- Penilaian percubaan senario pengguna baharu ialah pengoptimuman berbilang dimensi, dan hasil datang daripada bilangan berkesan peranti baharu dan pengekalan peranti, tidak seperti penilaian sebelumnya hanya pengekalan peranti.
- Menerima pengguna "baru" selalunya membawa faedah perniagaan yang besar. "Baharu" di sini bukan sahaja merujuk kepada pengguna baharu, tetapi juga kepada pengguna yang telah menyahpasang dan memasang semula.
Atas ialah kandungan terperinci Bagaimana untuk membina sistem percubaan AB dalam senario pertumbuhan pengguna?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
Ditulis di atas & pemahaman peribadi penulis: Pada masa ini, dalam keseluruhan sistem pemanduan autonomi, modul persepsi memainkan peranan penting Hanya selepas kenderaan pemanduan autonomi yang memandu di jalan raya memperoleh keputusan persepsi yang tepat melalui modul persepsi boleh Peraturan hiliran dan. modul kawalan dalam sistem pemanduan autonomi membuat pertimbangan dan keputusan tingkah laku yang tepat pada masanya dan betul. Pada masa ini, kereta dengan fungsi pemanduan autonomi biasanya dilengkapi dengan pelbagai penderia maklumat data termasuk penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul maklumat dalam modaliti yang berbeza untuk mencapai tugas persepsi yang tepat. Algoritma persepsi BEV berdasarkan penglihatan tulen digemari oleh industri kerana kos perkakasannya yang rendah dan penggunaan mudah, dan hasil keluarannya boleh digunakan dengan mudah untuk pelbagai tugas hiliran.
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Terokai prinsip asas dan pemilihan algoritma bagi fungsi isihan C++
Apr 02, 2024 pm 05:36 PM
Terokai prinsip asas dan pemilihan algoritma bagi fungsi isihan C++
Apr 02, 2024 pm 05:36 PM
Lapisan bawah fungsi C++ sort menggunakan isihan gabungan, kerumitannya ialah O(nlogn), dan menyediakan pilihan algoritma pengisihan yang berbeza, termasuk isihan pantas, isihan timbunan dan isihan stabil.
 Bolehkah kecerdasan buatan meramalkan jenayah? Terokai keupayaan CrimeGPT
Mar 22, 2024 pm 10:10 PM
Bolehkah kecerdasan buatan meramalkan jenayah? Terokai keupayaan CrimeGPT
Mar 22, 2024 pm 10:10 PM
Konvergensi kecerdasan buatan (AI) dan penguatkuasaan undang-undang membuka kemungkinan baharu untuk pencegahan dan pengesanan jenayah. Keupayaan ramalan kecerdasan buatan digunakan secara meluas dalam sistem seperti CrimeGPT (Teknologi Ramalan Jenayah) untuk meramal aktiviti jenayah. Artikel ini meneroka potensi kecerdasan buatan dalam ramalan jenayah, aplikasi semasanya, cabaran yang dihadapinya dan kemungkinan implikasi etika teknologi tersebut. Kecerdasan Buatan dan Ramalan Jenayah: Asas CrimeGPT menggunakan algoritma pembelajaran mesin untuk menganalisis set data yang besar, mengenal pasti corak yang boleh meramalkan di mana dan bila jenayah mungkin berlaku. Set data ini termasuk statistik jenayah sejarah, maklumat demografi, penunjuk ekonomi, corak cuaca dan banyak lagi. Dengan mengenal pasti trend yang mungkin terlepas oleh penganalisis manusia, kecerdasan buatan boleh memperkasakan agensi penguatkuasaan undang-undang
 Algoritma pengesanan yang dipertingkatkan: untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi
Jun 06, 2024 pm 12:33 PM
Algoritma pengesanan yang dipertingkatkan: untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi
Jun 06, 2024 pm 12:33 PM
01Garis prospek Pada masa ini, sukar untuk mencapai keseimbangan yang sesuai antara kecekapan pengesanan dan hasil pengesanan. Kami telah membangunkan algoritma YOLOv5 yang dipertingkatkan untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi, menggunakan piramid ciri berbilang lapisan, strategi kepala pengesanan berbilang dan modul perhatian hibrid untuk meningkatkan kesan rangkaian pengesanan sasaran dalam imej penderiaan jauh optik. Menurut set data SIMD, peta algoritma baharu adalah 2.2% lebih baik daripada YOLOv5 dan 8.48% lebih baik daripada YOLOX, mencapai keseimbangan yang lebih baik antara hasil pengesanan dan kelajuan. 02 Latar Belakang & Motivasi Dengan perkembangan pesat teknologi penderiaan jauh, imej penderiaan jauh optik resolusi tinggi telah digunakan untuk menggambarkan banyak objek di permukaan bumi, termasuk pesawat, kereta, bangunan, dll. Pengesanan objek dalam tafsiran imej penderiaan jauh
 Amalkan dan fikirkan platform model besar berbilang modal Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
Amalkan dan fikirkan platform model besar berbilang modal Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
1. Perkembangan sejarah model besar pelbagai mod Gambar di atas adalah bengkel kecerdasan buatan pertama yang diadakan di Kolej Dartmouth di Amerika Syarikat pada tahun 1956. Persidangan ini juga dianggap telah memulakan pembangunan kecerdasan buatan perintis logik simbolik (kecuali ahli neurobiologi Peter Milner di tengah-tengah barisan hadapan). Walau bagaimanapun, teori logik simbolik ini tidak dapat direalisasikan untuk masa yang lama, malah memulakan musim sejuk AI pertama pada 1980-an dan 1990-an. Sehingga pelaksanaan model bahasa besar baru-baru ini, kami mendapati bahawa rangkaian saraf benar-benar membawa pemikiran logik ini. Kerja ahli neurobiologi Peter Milner memberi inspirasi kepada pembangunan rangkaian saraf tiruan yang seterusnya, dan atas sebab inilah dia dijemput untuk mengambil bahagian. dalam projek ini.
 Aplikasi algoritma dalam pembinaan 58 platform potret
May 09, 2024 am 09:01 AM
Aplikasi algoritma dalam pembinaan 58 platform potret
May 09, 2024 am 09:01 AM
1. Latar Belakang Pembinaan 58 Portrait Platform Pertama sekali, saya ingin berkongsi dengan anda latar belakang pembinaan 58 Portrait Platform. 1. Pemikiran tradisional platform pemprofilan tradisional tidak lagi mencukupi Membina platform pemprofilan pengguna bergantung pada keupayaan pemodelan gudang data untuk menyepadukan data daripada pelbagai barisan perniagaan untuk membina potret pengguna yang tepat untuk memahami tingkah laku, minat pengguna dan keperluan, dan menyediakan keupayaan sampingan, akhirnya, ia juga perlu mempunyai keupayaan platform data untuk menyimpan, bertanya dan berkongsi data profil pengguna dan menyediakan perkhidmatan profil dengan cekap. Perbezaan utama antara platform pemprofilan perniagaan binaan sendiri dan platform pemprofilan pejabat pertengahan ialah platform pemprofilan binaan sendiri menyediakan satu barisan perniagaan dan boleh disesuaikan atas permintaan platform pertengahan pejabat berkhidmat berbilang barisan perniagaan, mempunyai kompleks pemodelan, dan menyediakan lebih banyak keupayaan umum. 2.58 Potret pengguna latar belakang pembinaan potret di platform tengah 58
 Tambah SOTA dalam masa nyata dan meroket! FastOcc: Inferens yang lebih pantas dan algoritma Occ mesra penggunaan sudah tersedia!
Mar 14, 2024 pm 11:50 PM
Tambah SOTA dalam masa nyata dan meroket! FastOcc: Inferens yang lebih pantas dan algoritma Occ mesra penggunaan sudah tersedia!
Mar 14, 2024 pm 11:50 PM
Ditulis di atas & Pemahaman peribadi penulis ialah dalam sistem pemanduan autonomi, tugas persepsi adalah komponen penting dalam keseluruhan sistem pemanduan autonomi. Matlamat utama tugas persepsi adalah untuk membolehkan kenderaan autonomi memahami dan melihat elemen persekitaran sekeliling, seperti kenderaan yang memandu di jalan raya, pejalan kaki di tepi jalan, halangan yang dihadapi semasa memandu, tanda lalu lintas di jalan raya, dan sebagainya, dengan itu membantu hiliran. modul Membuat keputusan dan tindakan yang betul dan munasabah. Kenderaan dengan keupayaan pemanduan autonomi biasanya dilengkapi dengan pelbagai jenis penderia pengumpulan maklumat, seperti penderia kamera pandangan sekeliling, penderia lidar, penderia radar gelombang milimeter, dsb., untuk memastikan kenderaan autonomi itu dapat melihat dan memahami persekitaran sekeliling dengan tepat. elemen , membolehkan kenderaan autonomi membuat keputusan yang betul semasa pemanduan autonomi. kepala
