
 Peranti teknologi
AI
Penggunaan praktikal: Rangkaian jujukan dinamik untuk pengesanan dan penjejakan hujung ke hujung
Peranti teknologi
AI
Penggunaan praktikal: Rangkaian jujukan dinamik untuk pengesanan dan penjejakan hujung ke hujung
Penggunaan praktikal: Rangkaian jujukan dinamik untuk pengesanan dan penjejakan hujung ke hujung

Artikel ini dicetak semula dengan kebenaran akaun awam Autonomous Driving Heart Sila hubungi sumber untuk mencetak semula.
Saya percaya bahawa kecuali beberapa pengeluar utama cip yang dibangunkan sendiri, kebanyakan syarikat pemanduan autonomi akan menggunakan cip NVIDIA, yang tidak boleh dipisahkan daripada TensorRT ialah perisian yang dijalankan pada pelbagai perkakasan GPU NVIDIA platform rangka kerja penaakulan C++. Model yang telah kami latih menggunakan Pytorch, TF atau rangka kerja lain boleh mula-mula ditukar kepada format onnx, dan kemudian ditukar kepada format TensorRT, dan kemudian menggunakan enjin inferens TensorRT untuk menjalankan model kami, dengan itu meningkatkan kelajuan menjalankan model ini pada GPU NVIDIA .
Secara umumnya, onnx dan TensorRT hanya menyokong model yang agak tetap (termasuk format input dan output tetap di semua peringkat, cawangan tunggal, dll.), dan menyokong paling banyak input dinamik paling luar (onnx boleh dieksport melalui tetapan Parameter dynamic_axes menentukan dimensi yang membenarkan perubahan dinamik). Tetapi rakan yang aktif di barisan hadapan dalam algoritma persepsi akan mengetahui bahawa trend pembangunan penting pada masa ini ialah hujung-2, yang mungkin meliputi pengesanan sasaran, penjejakan sasaran dan trajektori Semua aspek pemanduan autonomi, seperti ramalan dan perancangan keputusan, mestilah model siri masa yang berkait rapat dengan bingkai sebelumnya dan seterusnya Model MUTR3D yang merealisasikan pengesanan sasaran hujung ke hujung dan penjejakan sasaran boleh digunakan sebagai contoh biasa (untuk pengenalan model, sila rujuk:)
# 🎜🎜#Dalam MOTR/MUTR3D, kami akan menerangkan teori dan contoh mekanisme Tugasan Label secara terperinci untuk mencapai sasaran berbilang hujung ke hujung yang sebenar pengesanan. Sila klik pautan untuk membaca lebih lanjut: https://zhuanlan.zhihu.com/p/609123786 Menukar model ini kepada format TensorRT dan mencapai penjajaran ketepatan, malah penjajaran ketepatan fp16, mungkin menghadapi siri A elemen dinamik, seperti berbilang cawangan if-else, perubahan dinamik dalam bentuk input sub-rangkaian dan operasi dan pengendali lain yang memerlukan pemprosesan dinamik Picture# 🎜🎜 ##🎜🎜 #MUTR3D seni bina Oleh kerana keseluruhan proses melibatkan banyak butiran, keadaannya berbeza Melihat bahan rujukan pada keseluruhan rangkaian, malah mencari di Google, sukar untuk mencari plug-and-. penyelesaian main. Ia boleh diselesaikan satu persatu melalui pemisahan dan eksperimen yang berterusan Selepas lebih sebulan penerokaan dan latihan keras oleh blogger (saya tidak mempunyai banyak pengalaman dengan TensorRT, saya tidak memahami perangainya). Saya menggunakan banyak otak dan memijak banyak perangkap, dan akhirnya berjaya menukar dan mencapai penjajaran ketepatan fp32/fp16, dan peningkatan kelewatan adalah sangat kecil berbanding pengesanan sasaran mudah. Saya ingin membuat ringkasan ringkas di sini dan memberikan rujukan untuk semua orang (ya, saya telah menulis ulasan dan akhirnya menulis amalan!)
Picture# 🎜🎜 ##🎜🎜 #MUTR3D seni bina Oleh kerana keseluruhan proses melibatkan banyak butiran, keadaannya berbeza Melihat bahan rujukan pada keseluruhan rangkaian, malah mencari di Google, sukar untuk mencari plug-and-. penyelesaian main. Ia boleh diselesaikan satu persatu melalui pemisahan dan eksperimen yang berterusan Selepas lebih sebulan penerokaan dan latihan keras oleh blogger (saya tidak mempunyai banyak pengalaman dengan TensorRT, saya tidak memahami perangainya). Saya menggunakan banyak otak dan memijak banyak perangkap, dan akhirnya berjaya menukar dan mencapai penjajaran ketepatan fp32/fp16, dan peningkatan kelewatan adalah sangat kecil berbanding pengesanan sasaran mudah. Saya ingin membuat ringkasan ringkas di sini dan memberikan rujukan untuk semua orang (ya, saya telah menulis ulasan dan akhirnya menulis amalan!)
Penyelesaian masalah ini diilhamkan oleh DN-DETR[1], iaitu menggunakan attention_mask, yang sepadan dengan parameter 'attn_mask' dalam nn.MultiheadAttention Fungsinya adalah untuk menyekat pertanyaan yang tidak memerlukan interaksi maklumat. ini kerana dalam NLP setiap Ayat ditetapkan dengan panjang yang tidak konsisten, yang betul-betul memenuhi keperluan semasa saya, saya hanya perlu memberi perhatian kepada fakta bahawa Benar mewakili pertanyaan yang perlu disekat, dan Salah mewakili pertanyaan yang sah
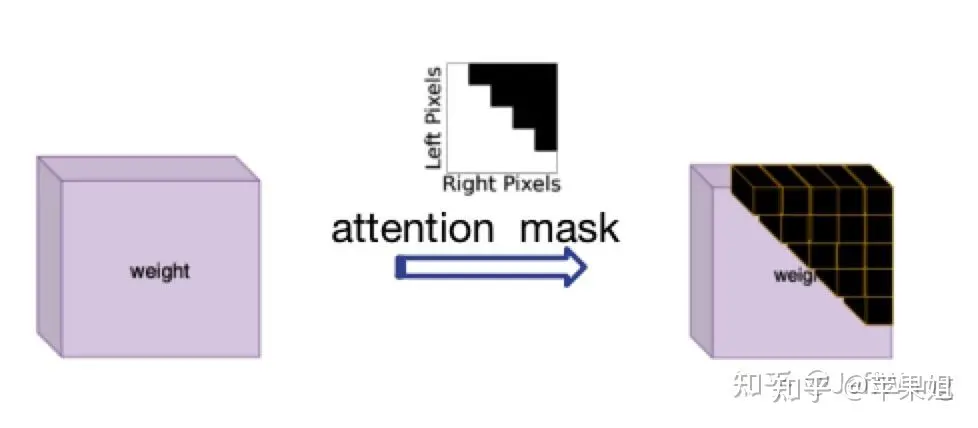 Gambar
Gambar
rajah topeng perhatian Oleh kerana logik pengiraan attention_mask agak rumit, terdapat banyak Masalah baru mungkin timbul semasa mengendalikan dan menukar TensorRT, jadi ia harus dikira di luar model dan dimasukkan sebagai pembolehubah input ke dalam model , dan kemudian dihantar ke pengubah Berikut ialah kod sampel:
data['attn_masks'] = attn_masks_init.clone().to(device)data['attn_masks'][active_prev_num:max_num, :] = Truedata['attn_masks'][:, active_prev_num:max_num] = True[1]DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
4 Kesan padding pada QIM
QIM adalah dalam MUTR3D Modul pasca pemprosesan untuk output pertanyaan oleh pengubah dibahagikan kepada tiga langkah. . Langkah pertama ialah menapis pertanyaan aktif, iaitu, untuk mengesan pertanyaan sasaran dalam bingkai semasa, berdasarkan sama ada obj_idxs >= 0 (ia juga termasuk penurunan rawak semasa fasa latihan dan penambahan secara rawak). pertanyaan fp (tidak terlibat dalam fasa inferens), langkah kedua ialah pertanyaan kemas kini, iaitu, kemas kini dibuat untuk pertanyaan yang ditapis dalam langkah pertama, termasuk nilai input perhatian kendiri, ffn dan pertanyaan bagi output pertanyaan nilai. Sambungan pintasan, langkah ketiga adalah untuk menyambung pertanyaan yang dikemas kini dengan pertanyaan awal yang dijana semula sebagai input bingkai seterusnya Ia boleh dilihat bahawa masalah yang kami nyatakan dalam perkara 3 masih wujud dalam langkah kedua, iaitu perhatian diri bukan Lakukan semua interaksi antara pertanyaan, tetapi hanya melakukan interaksi maklumat antara pertanyaan aktif Jadi topeng perhatian digunakan di sini sekali lagi
Walaupun modul QIM adalah pilihan, eksperimen menunjukkan bahawa ia membantu untuk meningkatkan ketepatan model. . Jika anda ingin menggunakan QIM, topeng perhatian ini mesti dikira dalam model, kerana hasil pengesanan bingkai semasa tidak dapat diketahui di luar model Disebabkan oleh had sintaks tensorRT, banyak operasi akan gagal untuk menukar. atau tidak akan mendapat apa yang anda mahu Akibatnya, selepas banyak eksperimen, kesimpulannya ialah penugasan langsung hirisan indeks (serupa dengan kod contoh di titik 3) secara amnya tidak disokong apabila bercakap tentang pengiraan, jenis bool topeng perhatian mesti ditukar kepada jenis terapung, dan akhirnya topeng perhatian perlu ditukar semula kepada jenis bool sebelum ia boleh digunakan Berikut ialah kod contoh:
obj_mask = (obj_idxs >= 0).float()attn_mask = torch.matmul(obj_mask.unsqueeze(-1), obj_mask.unsqueeze(0)).bool()attn_mask = ~attn_mask
5. Kesan padding pada hasil output
Selepas melengkapkan empat mata di atas, pada asasnya kita boleh memastikan bahawa tiada masalah dengan logik penukaran model tensorRT, tetapi Selepas keputusan output telah disahkan berkali-kali, terdapat masih ada masalah dalam beberapa bingkai, yang membingungkan saya untuk seketika Tetapi jika anda menganalisis bingkai data demi bingkai, anda akan mendapati bahawa walaupun pertanyaan padding dalam beberapa bingkai tidak mengambil bahagian dalam pengiraan pengubah, anda boleh mendapat skor yang Lebih Tinggi. dan kemudian mendapat hasil yang salah Situasi ini sememangnya mungkin apabila jumlah data adalah besar, kerana pertanyaan padding hanya mempunyai nilai awal 0, dan titik rujukan juga [0,0], tidak seperti yang lain yang dimulakan secara rawak. operasi yang sama. Tetapi kerana ia adalah pertanyaan padding, kami tidak berhasrat untuk menggunakan hasil mereka, jadi kami mesti menapisnya
Bagaimana untuk menapis hasil pertanyaan padding? Token yang mengisi pertanyaan hanyalah kedudukan indeksnya, tiada maklumat lain yang khusus. Maklumat indeks sebenarnya direkodkan dalam topeng perhatian yang digunakan dalam titik 3, yang dihantar dari luar model. Topeng ini adalah dua dimensi dan kita boleh menggunakan salah satu dimensi (mana-mana baris atau lajur) untuk menetapkan track_score yang diisi terus kepada 0. Ingat untuk masih memberi perhatian kepada kaveat langkah 4, iaitu, cuba gunakan pengiraan matriks dan bukannya tugasan kepingan diindeks, dan pengiraan mesti ditukar kepada jenis apungan. Berikut ialah contoh kod:
mask = (~attention_mask[-1]).float()track_scores = track_scores * mask
6 Cara mengemas kini track_id secara dinamik
Selain badan model, sebenarnya terdapat langkah yang sangat kritikal, iaitu mengemas kini track_id secara dinamik, yang juga merupakan faktor penting untuk model. untuk menjadi hujung ke hujung. Tetapi dalam model asal Cara untuk mengemas kini track_id ialah pertimbangan gelung yang agak kompleks, iaitu, jika ia lebih tinggi daripada skor thresh dan ia adalah sasaran baharu, obj_idx baharu ditetapkan; adalah lebih rendah daripada thresh skor penapis dan ia adalah sasaran lama, masa hilang yang sepadan + 1, jika masa hilang Jika miss_tolerance melebihi, obj idx yang sepadan ditetapkan kepada -1, iaitu sasaran dibuang
Kita ketahui bahawa tensorRT tidak menyokong penyata berbilang cawangan if-else (baik, saya tidak tahu pada mulanya), yang menyakitkan kepala Jika track_id yang dikemas kini juga diletakkan di luar model, ia bukan sahaja akan menjejaskan penghujungnya -seni bina ke hujung model, tetapi juga menjadikannya mustahil untuk menggunakan QIM, kerana QIM menapis pertanyaan berdasarkan track_id yang dikemas kini Jadi saya perlu memerah otak saya untuk meletakkan track_id yang dikemas kini Masuk ke dalam model.
Gunakan kepintaran anda. sekali lagi (hampir kehabisan), pernyataan if-else tidak boleh diganti, seperti menggunakan topeng untuk operasi selari Contohnya, tukar keadaan menjadi topeng (contohnya, tensor[mask] = 0 Di sini Mujurlah, walaupun mata 4 dan 5 menyebut bahawa tensorRT tidak menyokong operasi penetapan hirisan indeks, ia menyokong penetapan indeks bool, saya rasa ia mungkin kerana operasi hirisan secara tersirat mengubah bentuk tensor Tetapi selepas banyak eksperimen, ia tidak berlaku disokong dalam semua kes, tetapi sakit kepala berikut berlaku:
需要重新写的内容是:赋值的值必须是一个,不能是多个。例如,当我更新新出现的目标时,我不会统一赋值为某个ID,而是需要为每个目标赋予连续递增的ID。我想到的解决办法是先统一赋值为一个比较大且不可能出现的数字,比如1000,以避免与之前的ID重复,然后在后续处理中将1000替换为唯一且连续递增的数字。(我真是个天才)
如果要进行递增操作(+=1),只能使用简单的掩码,即不能涉及复杂的逻辑计算。例如,对disappear_time的更新,本来需要同时判断obj_idx >= 0且track_scores = 0这个条件。虽然看似不合理,但经过分析发现,即使将obj_idx=-1的非目标的disappear_time递增,因为后续这些目标并不会被选入,所以对整体逻辑影响不大
综上,最后的动态更新track_id示例代码如下,在后处理环节要记得替换obj_idx为1000的数值.:
def update_trackid(self, track_scores, disappear_time, obj_idxs):disappear_time[track_scores >= 0.4] = 0obj_idxs[(obj_idxs == -1) & (track_scores >= 0.4)] = 1000disappear_time[track_scores 5] = -1
至此模型部分的处理就全部结束了,是不是比较崩溃,但是没办法,部署端到端模型肯定比一般模型要复杂很多.模型最后会输出固定shape的结果,还需要在后处理阶段根据obj_idx是否>0判断需要保留到下一帧的query,再根据track_scores是否>filter score thresh判断当前最终的输出结果.总体来看,需要在模型外进行的操作只有三步:帧间移动reference_points,对输入query进行padding,对输出结果进行过滤和转换格式,基本上实现了端到端的目标检测+目标跟踪.
需要重新写的内容是:以上六点的操作顺序需要说明一下。我在这里按照问题分类来写,实际上可能的顺序是1->2->3->5->6->4,因为第五点和第六点是使用QIM的前提,它们之间也存在依赖关系。另外一个问题是我没有使用memory bank,即时序融合的模块,因为经过实验发现这个模块的提升效果并不明显,而且对于端到端跟踪机制来说,已经天然地使用了时序融合(因为直接将前序帧的查询信息带到下一帧),所以时序融合并不是非常必要
好了,现在我们可以对比TensorRT的推理结果和PyTorch的推理结果,会发现在FP32精度下可以实现精度对齐,非常棒!但是,如果需要转换为FP16(可以大幅降低部署时延),第一次推理会发现结果完全变成None(再次崩溃)。导致FP16结果为None一般都是因为出现数据溢出,即数值大小超限(FP16最大支持范围是-65504~+65504)。如果你的代码使用了一些特殊的操作,或者你的数据天然数值较大,例如内外参、姿态等数据很可能超限,一般可以通过缩放等方式解决。这里再说一下和我以上6点相关的一个原因:
7.使用attention_mask导致的fp16结果为none的问题
这个问题非常隐蔽,因为问题隐藏在torch.nn.MultiheadAttention源码中,具体在torch.nn.functional.py文件中,有以下几句:
if attn_mask is not None and attn_mask.dtype == torch.bool:new_attn_mask = torch.zeros_like(attn_mask, dtype=q.dtype)new_attn_mask.masked_fill_(attn_mask, float("-inf"))attn_mask = new_attn_mask可以看到,这一步操作是对attn_mask中值为True的元素用float("-inf")填充,这也是attention mask的原理所在,也就是值为1的位置会被替换成负无穷,这样在后续的softmax操作中,这个位置的输入会被加上负无穷,输出的结果就可以忽略不记,不会对其他位置的输出产生影响.大家也能看出来了,这个float("-inf")是fp32精度,肯定超过fp16支持的范围了,所以导致结果为none.我在这里把它替换为fp16支持的下限,即-65504,转fp16就正常了,虽然说一般不要修改源码,但这个确实没办法.不要问我怎么知道这么隐蔽的问题的,因为不是我一个人想到的.但如果使用attention_mask之前仔细研究了原理,想到也不难.
好的,以下是我在端到端模型部署方面的全部经验分享,我保证这不是标题党。由于我对tensorRT的接触时间不长,所以可能有些描述不准确的地方

需要进行改写的内容是:原文链接:https://mp.weixin.qq.com/s/EcmNH2to2vXBsdnNvpo0xw
Atas ialah kandungan terperinci Penggunaan praktikal: Rangkaian jujukan dinamik untuk pengesanan dan penjejakan hujung ke hujung. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Ditulis di atas & pemahaman peribadi pengarang Gaussiansplatting tiga dimensi (3DGS) ialah teknologi transformatif yang telah muncul dalam bidang medan sinaran eksplisit dan grafik komputer dalam beberapa tahun kebelakangan ini. Kaedah inovatif ini dicirikan oleh penggunaan berjuta-juta Gaussians 3D, yang sangat berbeza daripada kaedah medan sinaran saraf (NeRF), yang terutamanya menggunakan model berasaskan koordinat tersirat untuk memetakan koordinat spatial kepada nilai piksel. Dengan perwakilan adegan yang eksplisit dan algoritma pemaparan yang boleh dibezakan, 3DGS bukan sahaja menjamin keupayaan pemaparan masa nyata, tetapi juga memperkenalkan tahap kawalan dan pengeditan adegan yang tidak pernah berlaku sebelum ini. Ini meletakkan 3DGS sebagai penukar permainan yang berpotensi untuk pembinaan semula dan perwakilan 3D generasi akan datang. Untuk tujuan ini, kami menyediakan gambaran keseluruhan sistematik tentang perkembangan dan kebimbangan terkini dalam bidang 3DGS buat kali pertama.
 Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Semalam semasa temu bual, saya telah ditanya sama ada saya telah membuat sebarang soalan berkaitan ekor panjang, jadi saya fikir saya akan memberikan ringkasan ringkas. Masalah ekor panjang pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi, iaitu, kemungkinan senario dengan kebarangkalian yang rendah untuk berlaku. Masalah ekor panjang yang dirasakan adalah salah satu sebab utama yang kini mengehadkan domain reka bentuk pengendalian kenderaan autonomi pintar satu kenderaan. Seni bina asas dan kebanyakan isu teknikal pemanduan autonomi telah diselesaikan, dan baki 5% masalah ekor panjang secara beransur-ansur menjadi kunci untuk menyekat pembangunan pemanduan autonomi. Masalah ini termasuk pelbagai senario yang berpecah-belah, situasi yang melampau dan tingkah laku manusia yang tidak dapat diramalkan. "Ekor panjang" senario tepi dalam pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi (AVs) kes Edge adalah senario yang mungkin dengan kebarangkalian yang rendah untuk berlaku. kejadian yang jarang berlaku ini
 Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
0. Ditulis di hadapan&& Pemahaman peribadi bahawa sistem pemanduan autonomi bergantung pada persepsi lanjutan, membuat keputusan dan teknologi kawalan, dengan menggunakan pelbagai penderia (seperti kamera, lidar, radar, dll.) untuk melihat persekitaran sekeliling dan menggunakan algoritma dan model untuk analisis masa nyata dan membuat keputusan. Ini membolehkan kenderaan mengenali papan tanda jalan, mengesan dan menjejaki kenderaan lain, meramalkan tingkah laku pejalan kaki, dsb., dengan itu selamat beroperasi dan menyesuaikan diri dengan persekitaran trafik yang kompleks. Teknologi ini kini menarik perhatian meluas dan dianggap sebagai kawasan pembangunan penting dalam pengangkutan masa depan satu. Tetapi apa yang menyukarkan pemanduan autonomi ialah memikirkan cara membuat kereta itu memahami perkara yang berlaku di sekelilingnya. Ini memerlukan algoritma pengesanan objek tiga dimensi dalam sistem pemanduan autonomi boleh melihat dan menerangkan dengan tepat objek dalam persekitaran sekeliling, termasuk lokasinya,
 Kertas Stable Diffusion 3 akhirnya telah dikeluarkan, dan butiran seni bina didedahkan Adakah ia akan membantu untuk menghasilkan semula Sora?
Mar 06, 2024 pm 05:34 PM
Kertas Stable Diffusion 3 akhirnya telah dikeluarkan, dan butiran seni bina didedahkan Adakah ia akan membantu untuk menghasilkan semula Sora?
Mar 06, 2024 pm 05:34 PM
Kertas StableDiffusion3 akhirnya di sini! Model ini dikeluarkan dua minggu lalu dan menggunakan seni bina DiT (DiffusionTransformer) yang sama seperti Sora. Ia menimbulkan kekecohan apabila ia dikeluarkan. Berbanding dengan versi sebelumnya, kualiti imej yang dijana oleh StableDiffusion3 telah dipertingkatkan dengan ketara Ia kini menyokong gesaan berbilang tema, dan kesan penulisan teks juga telah dipertingkatkan, dan aksara bercelaru tidak lagi muncul. StabilityAI menegaskan bahawa StableDiffusion3 ialah satu siri model dengan saiz parameter antara 800M hingga 8B. Julat parameter ini bermakna model boleh dijalankan terus pada banyak peranti mudah alih, dengan ketara mengurangkan penggunaan AI
 Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Ramalan trajektori memainkan peranan penting dalam pemanduan autonomi Ramalan trajektori pemanduan autonomi merujuk kepada meramalkan trajektori pemanduan masa hadapan kenderaan dengan menganalisis pelbagai data semasa proses pemanduan kenderaan. Sebagai modul teras pemanduan autonomi, kualiti ramalan trajektori adalah penting untuk kawalan perancangan hiliran. Tugas ramalan trajektori mempunyai timbunan teknologi yang kaya dan memerlukan kebiasaan dengan persepsi dinamik/statik pemanduan autonomi, peta ketepatan tinggi, garisan lorong, kemahiran seni bina rangkaian saraf (CNN&GNN&Transformer), dll. Sangat sukar untuk bermula! Ramai peminat berharap untuk memulakan ramalan trajektori secepat mungkin dan mengelakkan perangkap Hari ini saya akan mengambil kira beberapa masalah biasa dan kaedah pembelajaran pengenalan untuk ramalan trajektori! Pengetahuan berkaitan pengenalan 1. Adakah kertas pratonton teratur? A: Tengok survey dulu, hlm
 SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
Tajuk asal: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper pautan: https://arxiv.org/pdf/2402.02519.pdf Pautan kod: https://github.com/HKUST-Aerial-Robotics/SIMPL Unit pengarang: Universiti Sains Hong Kong dan Teknologi Idea Kertas DJI: Kertas kerja ini mencadangkan garis dasar ramalan pergerakan (SIMPL) yang mudah dan cekap untuk kenderaan autonomi. Berbanding dengan agen-sen tradisional
 Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Pada bulan lalu, atas sebab-sebab yang diketahui umum, saya telah mengadakan pertukaran yang sangat intensif dengan pelbagai guru dan rakan sekelas dalam industri. Topik yang tidak dapat dielakkan dalam pertukaran secara semula jadi adalah hujung ke hujung dan Tesla FSDV12 yang popular. Saya ingin mengambil kesempatan ini untuk menyelesaikan beberapa buah fikiran dan pendapat saya pada masa ini untuk rujukan dan perbincangan anda. Bagaimana untuk mentakrifkan sistem pemanduan autonomi hujung ke hujung, dan apakah masalah yang sepatutnya dijangka diselesaikan hujung ke hujung? Menurut definisi yang paling tradisional, sistem hujung ke hujung merujuk kepada sistem yang memasukkan maklumat mentah daripada penderia dan secara langsung mengeluarkan pembolehubah yang membimbangkan tugas. Sebagai contoh, dalam pengecaman imej, CNN boleh dipanggil hujung-ke-hujung berbanding kaedah pengekstrak ciri + pengelas tradisional. Dalam tugas pemanduan autonomi, masukkan data daripada pelbagai penderia (kamera/LiDAR
 SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
Ditulis di hadapan & titik permulaan Paradigma hujung ke hujung menggunakan rangka kerja bersatu untuk mencapai pelbagai tugas dalam sistem pemanduan autonomi. Walaupun kesederhanaan dan kejelasan paradigma ini, prestasi kaedah pemanduan autonomi hujung ke hujung pada subtugas masih jauh ketinggalan berbanding kaedah tugasan tunggal. Pada masa yang sama, ciri pandangan mata burung (BEV) padat yang digunakan secara meluas dalam kaedah hujung ke hujung sebelum ini menyukarkan untuk membuat skala kepada lebih banyak modaliti atau tugasan. Paradigma pemanduan autonomi hujung ke hujung (SparseAD) tertumpu carian jarang dicadangkan di sini, di mana carian jarang mewakili sepenuhnya keseluruhan senario pemanduan, termasuk ruang, masa dan tugas, tanpa sebarang perwakilan BEV yang padat. Khususnya, seni bina jarang bersatu direka bentuk untuk kesedaran tugas termasuk pengesanan, penjejakan dan pemetaan dalam talian. Di samping itu, berat
