
 Peranti teknologi
AI
Penalaan halus parameter yang cekap bagi model bahasa berskala besar--siri penalaan halus BitFit/Awalan/Prompt
Peranti teknologi
AI
Penalaan halus parameter yang cekap bagi model bahasa berskala besar--siri penalaan halus BitFit/Awalan/Prompt
Penalaan halus parameter yang cekap bagi model bahasa berskala besar--siri penalaan halus BitFit/Awalan/Prompt

Pada tahun 2018, Google mengeluarkan BERT Setelah ia dikeluarkan, ia mengalahkan keputusan terkini (Sota) bagi 11 tugasan NLP dalam satu masa, menjadi tonggak baharu dalam dunia NLP ditunjukkan dalam rajah di bawah. Di sebelah kiri ialah proses pra-latihan Model BERT, sebelah kanan ialah proses penalaan halus untuk tugasan tertentu. Antaranya, peringkat penalaan halus adalah untuk penalaan halus apabila ia kemudiannya digunakan dalam beberapa tugas hiliran, seperti klasifikasi teks, penandaan sebahagian daripada pertuturan, sistem soal jawab, dsb. BERT boleh diperhalusi pada pelbagai tugas tanpa melaraskan struktur. Melalui reka bentuk tugasan "model bahasa pra-latihan + penalaan halus tugas hiliran", ia telah membawa kesan model yang hebat. Sejak itu, "model bahasa pra-latihan + penalaan tugas hiliran" telah menjadi paradigma latihan arus perdana dalam bidang NLP.
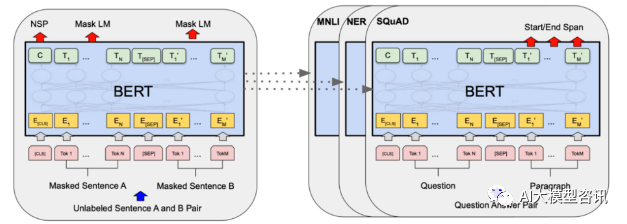 Gambarajah struktur BERT, sebelah kiri ialah proses pra-latihan, dan sebelah kanan ialah proses penalaan halus tugas khusus
Gambarajah struktur BERT, sebelah kiri ialah proses pra-latihan, dan sebelah kanan ialah proses penalaan halus tugas khusus
Selain itu, sepenuhnya penalaan halus model juga akan menyebabkan kehilangan kepelbagaian dan mengalami masalah lupa yang serius. Oleh itu, cara melakukan penalaan halus model dengan cekap telah menjadi tumpuan penyelidikan industri, yang turut menyediakan ruang penyelidikan untuk pembangunan pesat teknologi penalaan halus parameter yang cekap 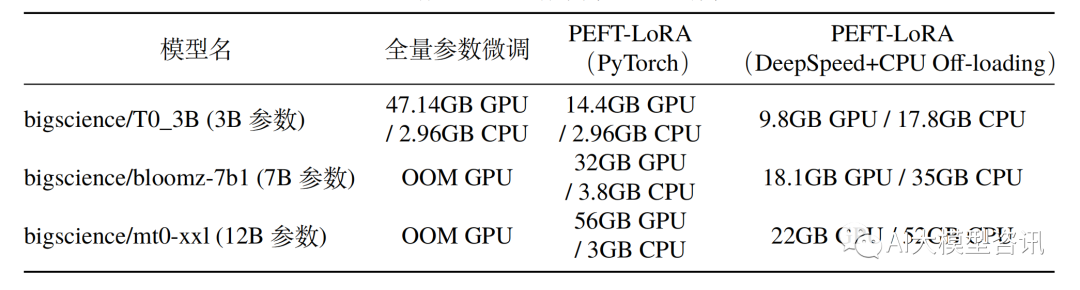 Penalaan halus parameter yang cekap merujuk kepada penalaan halus dalam jumlah yang kecil atau parameter model tambahan dan menetapkan kebanyakan parameter model pra-latihan (LLM), sekali gus mengurangkan kos pengkomputeran dan penyimpanan Pada masa yang sama, ia juga boleh mencapai prestasi yang setanding dengan penalaan halus parameter penuh. Kaedah penalaan halus yang cekap parameter adalah lebih baik daripada penalaan halus penuh dalam beberapa kes, dan boleh digeneralisasikan dengan lebih baik kepada senario luar domain.
Penalaan halus parameter yang cekap merujuk kepada penalaan halus dalam jumlah yang kecil atau parameter model tambahan dan menetapkan kebanyakan parameter model pra-latihan (LLM), sekali gus mengurangkan kos pengkomputeran dan penyimpanan Pada masa yang sama, ia juga boleh mencapai prestasi yang setanding dengan penalaan halus parameter penuh. Kaedah penalaan halus yang cekap parameter adalah lebih baik daripada penalaan halus penuh dalam beberapa kes, dan boleh digeneralisasikan dengan lebih baik kepada senario luar domain.
Teknologi dan kaedah penalaan halus cekap parameter biasa
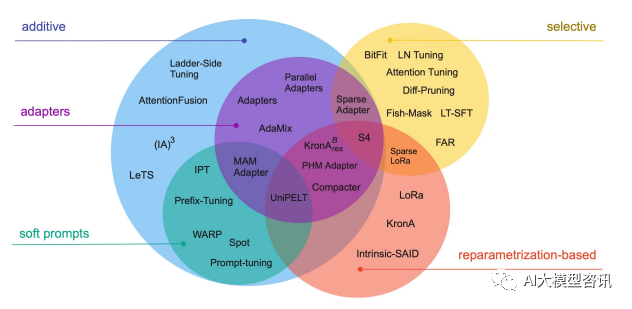 BitFit/Prefix/Prompt siri penalaan halus
BitFit/Prefix/Prompt siri penalaan halus
untuk semua Penalaan penuh untuk setiap tugas adalah sangat berkesan, tetapi ia juga menghasilkan model besar yang unik untuk setiap tugasan yang telah dilatih, yang menjadikannya sukar untuk membuat kesimpulan tentang perubahan yang berlaku semasa proses penalaan halus dan sukar untuk digunakan, terutamanya apabila bilangan tugas meningkat meningkat, ia adalah sukar untuk mengekalkan.
Sebaik-baiknya, kami ingin mempunyai kaedah penalaan halus yang cekap yang memenuhi syarat berikut: Persoalan di atas bergantung kepada sejauh mana proses penalaan halus dapat membimbing pembelajaran kebolehan baharu dan kebolehan yang dipelajari melalui pendedahan kepada LM pra-latihan. Walaupun, kaedah penalaan halus yang cekap sebelum ini Adapter-Tuning dan Diff-Pruning juga boleh memenuhi sebahagian keperluan di atas. BitFit, kaedah penalaan halus yang jarang dengan parameter yang lebih kecil, boleh memenuhi semua keperluan di atas. BitFit ialah kaedah penalaan halus yang jarang Ia hanya mengemas kini parameter berat sebelah atau sebahagian daripada parameter berat sebelah semasa latihan. Untuk model Transformer, kebanyakan parameter pengubah-pengekod dibekukan, dan hanya parameter bias dan parameter lapisan pengelasan tugas tertentu dikemas kini. Parameter bias yang terlibat termasuk bias yang terlibat dalam mengira pertanyaan, kunci, nilai dan menggabungkan hasil perhatian berbilang dalam modul perhatian, bias dalam lapisan MLP, parameter bias dalam lapisan Layernormalization dan parameter bias dalam model pra-latihan. seperti yang ditunjukkan dalam rajah di bawah. Picture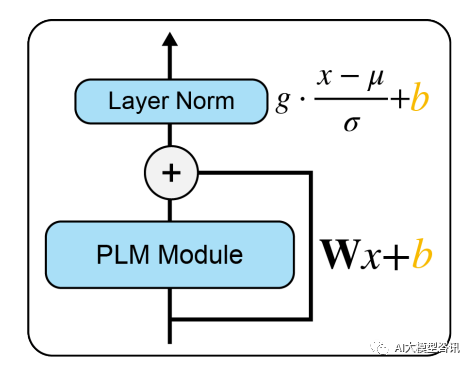 Modul PLM mewakili sub-lapisan PLM tertentu, seperti perhatian atau FFN Blok oren dalam gambar mewakili vektor pembayang boleh dilatih, dan blok biru mewakili parameter model pra-latihan beku.
Modul PLM mewakili sub-lapisan PLM tertentu, seperti perhatian atau FFN Blok oren dalam gambar mewakili vektor pembayang boleh dilatih, dan blok biru mewakili parameter model pra-latihan beku.
Dalam model seperti Bert-Base/Bert-Large, parameter bias hanya menyumbang 0.08%~0.09% daripada jumlah parameter model. Walau bagaimanapun, dengan membandingkan kesan BitFit, Adapter dan Diff-Pruning pada model Bert-Large berdasarkan set data GLUE, didapati bahawa BitFit mempunyai kesan yang sama seperti Adapter dan Diff-Pruning apabila bilangan parameter jauh lebih kecil. daripada Adapter dan Diff-Pruning , malah lebih baik sedikit daripada Adapter dan Diff-Pruning dalam beberapa tugas.
Ia dapat dilihat daripada keputusan percubaan bahawa berbanding dengan penalaan halus parameter penuh, penalaan halus BitFit hanya mengemas kini bilangan parameter yang sangat kecil dan telah mencapai keputusan yang baik pada beberapa set data. Walaupun ia tidak sebaik menala halus semua parameter, ia jauh lebih baik daripada kaedah Frozen untuk menetapkan semua parameter model. Pada masa yang sama, dengan membandingkan parameter sebelum dan selepas latihan BitFit, didapati banyak parameter bias tidak banyak berubah, seperti parameter berat sebelah yang berkaitan dengan pengiraan kunci. Didapati bahawa parameter bias lapisan FFN yang mengira pertanyaan dan membesarkan dimensi ciri dari N kepada 4N mempunyai perubahan yang paling jelas Hanya mengemas kini kedua-dua jenis parameter bias ini juga boleh mencapai keputusan yang baik. Sebaliknya, jika salah satu daripadanya diperbaiki, kesan model akan hilang dengan ketara
Pelajaran Awalan
Sebelum Penalaan Awalan, kerjanya adalah untuk mereka bentuk templat diskret secara manual atau mencari templat diskret secara automatik. Untuk templat yang direka secara manual, perubahan dalam templat amat sensitif terhadap prestasi akhir model Menambah perkataan, kehilangan perkataan atau menukar kedudukan akan menyebabkan perubahan yang agak besar. Untuk templat carian automatik, kosnya agak tinggi pada masa yang sama, hasil carian token diskret sebelumnya mungkin tidak optimum. Selain itu, paradigma penalaan halus tradisional menggunakan model yang telah dilatih untuk memperhalusi tugas hiliran yang berbeza, dan berat model yang ditala halus mesti disimpan untuk setiap tugasan, dalam satu tangan, penalaan halus keseluruhan model mengambil masa yang lama masa; sebaliknya, ia juga akan mengambil banyak ruang penyimpanan. Berdasarkan dua perkara di atas, Penalaan Awalan mencadangkan LM pra-latihan tetap, menambahkan awalan khusus tugasan yang boleh dilatih pada LM, supaya awalan yang berbeza boleh disimpan untuk tugasan yang berbeza, dan kos penalaan halus juga kecil; Pada masa yang sama, Prefix jenis ini sebenarnya boleh dilatih secara berterusan Micro Virtual Token (Soft Prompt/Continuous Prompt) adalah lebih baik dioptimumkan dan mempunyai kesan yang lebih baik daripada Token diskret.
Jadi, apa yang perlu ditulis semula ialah: Jadi apakah maksud awalan? Peranan awalan adalah untuk membimbing model untuk mengekstrak maklumat yang berkaitan dengan x, supaya dapat menjana y dengan lebih baik. Sebagai contoh, jika kita ingin melakukan tugasan ringkasan, maka selepas penalaan halus, awalan boleh memahami bahawa tugasan semasa ialah tugasan "bentuk ringkasan", dan kemudian membimbing model untuk mengekstrak maklumat utama daripada x jika kita mahu lakukan klasifikasi emosi Tugas, awalan boleh membimbing model untuk mengekstrak maklumat semantik yang berkaitan dengan emosi dalam x, dan sebagainya. Penjelasan ini mungkin tidak begitu ketat, tetapi anda boleh memahami secara kasar peranan awalan
Penalaan Awalan adalah untuk membina token maya berkaitan tugasan sebagai Awalan sebelum memasukkan token, dan kemudian hanya mengemas kini parameter bahagian Awalan semasa latihan, manakala dalam PLM Parameter lain ditetapkan. Untuk struktur model yang berbeza, Awalan yang berbeza perlu dibina:
- Untuk model seni bina autoregresif: tambahkan awalan di hadapan ayat untuk mendapatkan z = [Awalan x; konteks (contohnya: pembelajaran konteks GPT3).
- Untuk model seni bina pengekod-penyahkod: awalan ditambahkan pada Pengekod dan Penyahkod, menghasilkan z = [PREFIX y]. Awalan ditambahkan pada bahagian Pengekod untuk membimbing pengekodan bahagian input, dan awalan ditambah pada bahagian Penyahkod untuk membimbing penjanaan token berikutnya.
 Gambar
Gambar
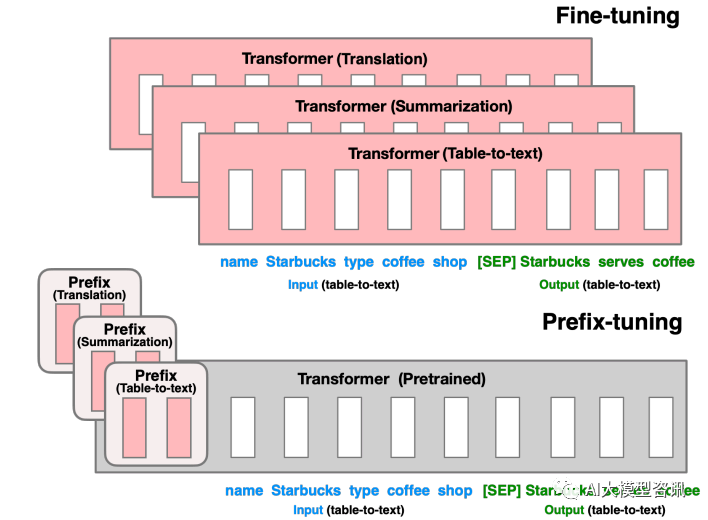
Tulis semula kandungan tanpa mengubah maksud asal, dan tulis semula dalam bahasa Cina: Untuk penalaan halus di bahagian sebelumnya, kami mengemas kini semua parameter Transformer (kotak merah) dan perlu menyimpan salinan lengkap model untuk setiap tugas. Pelarasan awalan di bahagian bawah akan membekukan parameter Transformer dan hanya mengoptimumkan awalan (kotak merah)
Kaedah ini sebenarnya serupa dengan membina Prompt, kecuali Prompt ialah gesaan "eksplisit" yang dibina secara buatan dan parameter tidak boleh dikemas kini, dan Awalan ialah petunjuk "tersirat" yang boleh dipelajari. Pada masa yang sama, untuk mengelakkan kemas kini langsung parameter Prefix daripada menyebabkan latihan tidak stabil dan kemerosotan prestasi, struktur MLP ditambah di hadapan lapisan Prefix Selepas latihan selesai, hanya parameter Prefix dikekalkan. Selain itu, eksperimen ablasi telah membuktikan bahawa melaraskan lapisan pembenaman sahaja tidak cukup ekspresif dan akan membawa kepada penurunan prestasi yang ketara Oleh itu, parameter segera ditambahkan pada setiap lapisan dan perubahannya adalah besar.
Walaupun Penalaan Awalan kelihatan mudah, ia juga mempunyai dua kelemahan penting berikut:Penalaan Pantas
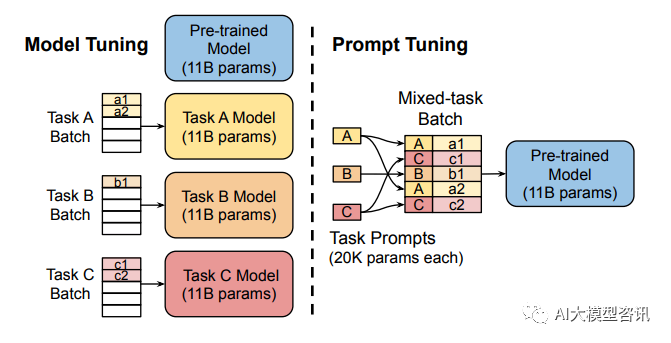
Penalaan penuh model besar melatih model untuk setiap tugas, yang mempunyai kos overhed dan penggunaan yang agak tinggi. Pada masa yang sama, kaedah gesaan diskret (merujuk kepada gesaan reka bentuk secara manual dan menambah gesaan pada model) agak mahal dan kesannya tidak begitu baik. Prompt Tuning mempelajari gesaan dengan menyebarkan balik parameter yang dikemas kini dan bukannya mereka bentuk gesaan secara manual pada masa yang sama, ia membekukan pemberat asal model dan hanya melatih parameter gesaan Selepas latihan, model yang sama boleh digunakan untuk inferens berbilang tugas.
 Gambar
Gambar
Penalaan model memerlukan membuat salinan khusus tugasan bagi keseluruhan model pra-latihan untuk setiap tugasan hiliran dan inferens mestilah dalam kelompok yang berasingan. Penalaan Gesaan hanya memerlukan menyimpan gesaan khusus tugasan kecil untuk setiap tugasan dan mendayakan inferens tugas bercampur menggunakan model asal yang telah dilatih.
Penalaan Pantas boleh dilihat sebagai versi Penalaan Awalan yang dipermudahkan Ia mentakrifkan gesaannya sendiri untuk setiap tugasan dan kemudian menyambungkannya ke dalam data sebagai input, tetapi hanya menambah token gesaan pada lapisan input dan tidak perlu menambah MLP. untuk pelarasan untuk menyelesaikan masalah latihan yang sukar.
Telah didapati melalui eksperimen bahawa apabila bilangan parameter model pra-latihan meningkat, kaedah Prompt Tuning akan menghampiri hasil penalaan halus parameter penuh. Pada masa yang sama, Prompt Tuning juga mencadangkan Prompt Ensembling, yang bermaksud melatih gesaan yang berbeza untuk tugas yang sama pada masa yang sama dalam satu kelompok (iaitu, bertanya soalan yang sama dalam pelbagai cara yang berbeza). Contohnya Kos integrasi model adalah jauh lebih kecil. Selain itu, kertas Prompt Tuning juga membincangkan kesan kaedah permulaan dan panjang token Prompt pada prestasi model. Melalui keputusan eksperimen ablasi, didapati Prompt Tuning menggunakan label kelas untuk memulakan model dengan lebih baik daripada pengamulaan rawak dan permulaan menggunakan kosa kata sampel. Walau bagaimanapun, apabila skala parameter model meningkat, jurang ini akhirnya akan hilang. Prestasi sudah baik apabila panjang token Prompt adalah sekitar 20 (selepas melebihi 20, peningkatan panjang token Prompt tidak akan meningkatkan prestasi model dengan ketara. Begitu juga, jurang ini juga akan berkurangan apabila skala parameter model meningkat (). Iaitu, untuk model berskala sangat besar, walaupun panjang token Prompt sangat pendek, ia tidak akan memberi banyak kesan kepada prestasi).
Atas ialah kandungan terperinci Penalaan halus parameter yang cekap bagi model bahasa berskala besar--siri penalaan halus BitFit/Awalan/Prompt. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Fahami Tokenisasi dalam satu artikel!
Apr 12, 2024 pm 02:31 PM
Fahami Tokenisasi dalam satu artikel!
Apr 12, 2024 pm 02:31 PM
Model bahasa menaakul tentang teks, yang biasanya dalam bentuk rentetan, tetapi input kepada model hanya boleh menjadi nombor, jadi teks perlu ditukar kepada bentuk berangka. Tokenisasi ialah tugas asas pemprosesan bahasa semula jadi Mengikut keperluan khusus, urutan teks berterusan (seperti ayat, perenggan, dll.) boleh dibahagikan kepada urutan aksara (seperti perkataan, frasa, aksara, tanda baca, dsb. berbilang. unit), di mana unit Dipanggil token atau perkataan. Mengikut proses khusus yang ditunjukkan dalam rajah di bawah, ayat teks mula-mula dibahagikan kepada unit, kemudian elemen tunggal didigitalkan (dipetakan ke dalam vektor), kemudian vektor ini dimasukkan ke dalam model untuk pengekodan, dan akhirnya output ke tugas hiliran untuk seterusnya memperoleh keputusan akhir. Pembahagian teks boleh dibahagikan kepada Toke mengikut butiran pembahagian teks.
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Tiga rahsia untuk menggunakan model besar dalam awan
Apr 24, 2024 pm 03:00 PM
Tiga rahsia untuk menggunakan model besar dalam awan
Apr 24, 2024 pm 03:00 PM
Kompilasi|Dihasilkan oleh Xingxuan|51CTO Technology Stack (WeChat ID: blog51cto) Dalam dua tahun lalu, saya lebih terlibat dalam projek AI generatif menggunakan model bahasa besar (LLM) berbanding sistem tradisional. Saya mula merindui pengkomputeran awan tanpa pelayan. Aplikasi mereka terdiri daripada meningkatkan AI perbualan kepada menyediakan penyelesaian analitik yang kompleks untuk pelbagai industri, dan banyak lagi keupayaan lain. Banyak perusahaan menggunakan model ini pada platform awan kerana penyedia awan awam sudah menyediakan ekosistem siap sedia dan ia merupakan laluan yang paling tidak mempunyai rintangan. Walau bagaimanapun, ia tidak murah. Awan juga menawarkan faedah lain seperti kebolehskalaan, kecekapan dan keupayaan pengkomputeran lanjutan (GPU tersedia atas permintaan). Terdapat beberapa aspek yang kurang diketahui untuk menggunakan LLM pada platform awan awam
 Penalaan halus parameter yang cekap bagi model bahasa berskala besar--siri penalaan halus BitFit/Awalan/Prompt
Oct 07, 2023 pm 12:13 PM
Penalaan halus parameter yang cekap bagi model bahasa berskala besar--siri penalaan halus BitFit/Awalan/Prompt
Oct 07, 2023 pm 12:13 PM
Pada tahun 2018, Google mengeluarkan BERT Sebaik sahaja ia dikeluarkan, ia mengalahkan keputusan terkini (Sota) bagi 11 tugasan NLP dalam satu masa, menjadi satu kejayaan baharu dalam dunia NLP dalam rajah di bawah. Di sebelah kiri ialah pratetap model BERT Proses latihan, di sebelah kanan ialah proses penalaan halus untuk tugasan tertentu. Antaranya, peringkat penalaan halus adalah untuk penalaan halus apabila ia kemudiannya digunakan dalam beberapa tugas hiliran, seperti klasifikasi teks, penandaan sebahagian daripada pertuturan, sistem soal jawab, dsb. BERT boleh diperhalusi pada pelbagai tugas tanpa melaraskan struktur. Melalui reka bentuk tugas "model bahasa pra-latihan + penalaan halus tugas hiliran", ia membawa kesan model yang berkuasa. Sejak itu, "model bahasa pra-latihan + penalaan tugas hiliran" telah menjadi latihan arus perdana dalam bidang NLP.
 Melatih ViT terbesar dalam sejarah dengan mudah? Google meningkatkan model bahasa visual PaLI: menyokong 100+ bahasa
Apr 12, 2023 am 09:31 AM
Melatih ViT terbesar dalam sejarah dengan mudah? Google meningkatkan model bahasa visual PaLI: menyokong 100+ bahasa
Apr 12, 2023 am 09:31 AM
Kemajuan pemprosesan bahasa semula jadi dalam beberapa tahun kebelakangan ini sebahagian besarnya datang daripada model bahasa berskala besar Setiap model baharu yang dikeluarkan mendorong jumlah parameter dan data latihan ke tahap tertinggi baharu, dan pada masa yang sama, kedudukan penanda aras yang sedia ada akan disembelih. Sebagai contoh, pada April tahun ini, Google mengeluarkan model bahasa 540 bilion parameter PaLM (Model Bahasa Laluan), yang berjaya mengatasi manusia dalam satu siri ujian bahasa dan penaakulan, terutamanya prestasi cemerlangnya dalam senario pembelajaran sampel kecil beberapa pukulan. PaLM dianggap sebagai hala tuju pembangunan model bahasa generasi akan datang. Dengan cara yang sama, model bahasa visual sebenarnya berfungsi dengan hebat, dan prestasi boleh dipertingkatkan dengan meningkatkan saiz model. Sudah tentu, jika ia hanya model bahasa visual pelbagai tugas
 RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap
Jan 18, 2024 pm 05:27 PM
RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap
Jan 18, 2024 pm 05:27 PM
Apabila model bahasa berskala ke skala yang belum pernah berlaku sebelum ini, penalaan halus menyeluruh untuk tugas hiliran menjadi sangat mahal. Bagi menyelesaikan masalah ini, penyelidik mula memberi perhatian dan mengamalkan kaedah PEFT. Idea utama kaedah PEFT adalah untuk mengehadkan skop penalaan halus kepada set kecil parameter untuk mengurangkan kos pengiraan sambil masih mencapai prestasi terkini dalam tugas pemahaman bahasa semula jadi. Dengan cara ini, penyelidik boleh menjimatkan sumber pengkomputeran sambil mengekalkan prestasi tinggi, membawa tempat tumpuan penyelidikan baharu ke bidang pemprosesan bahasa semula jadi. RoSA ialah teknik PEFT baharu yang, melalui eksperimen pada satu set penanda aras, didapati mengatasi prestasi penyesuaian peringkat rendah (LoRA) sebelumnya dan kaedah penalaan halus tulen yang jarang menggunakan belanjawan parameter yang sama. Artikel ini akan pergi secara mendalam
 Meta melancarkan model bahasa AI LLaMA, model bahasa berskala besar dengan 65 bilion parameter
Apr 14, 2023 pm 06:58 PM
Meta melancarkan model bahasa AI LLaMA, model bahasa berskala besar dengan 65 bilion parameter
Apr 14, 2023 pm 06:58 PM
Menurut berita pada 25 Februari, Meta mengumumkan pada hari Jumaat waktu tempatan bahawa ia akan melancarkan model bahasa berskala besar baharu berdasarkan kecerdasan buatan (AI) untuk komuniti penyelidikan, menyertai Microsoft, Google dan syarikat lain yang dirangsang oleh ChatGPT untuk menyertai kecerdasan buatan. Persaingan pintar. LLaMA Meta ialah singkatan daripada "Large Language Model MetaAI" (LargeLanguageModelMetaAI), yang tersedia di bawah lesen bukan komersial kepada penyelidik dan entiti dalam kerajaan, komuniti dan akademia. Syarikat akan menyediakan kod asas kepada pengguna, supaya mereka boleh mengubah suai model itu sendiri dan menggunakannya untuk kes penggunaan berkaitan penyelidikan. Meta menyatakan bahawa keperluan model untuk kuasa pengkomputeran
 BLOOM boleh mencipta budaya baharu untuk penyelidikan AI, tetapi cabaran masih ada
Apr 09, 2023 pm 04:21 PM
BLOOM boleh mencipta budaya baharu untuk penyelidikan AI, tetapi cabaran masih ada
Apr 09, 2023 pm 04:21 PM
Penterjemah |. Disemak oleh Li Rui |. Projek penyelidikan BigScience Sun Shujuan baru-baru ini mengeluarkan model bahasa besar BLOOM Pada pandangan pertama, ia kelihatan seperti satu lagi percubaan untuk menyalin GPT-3 OpenAI. Tetapi apa yang membezakan BLOOM daripada model bahasa semula jadi berskala besar (LLM) lain ialah usahanya untuk menyelidik, membangun, melatih dan mengeluarkan model pembelajaran mesin. Dalam beberapa tahun kebelakangan ini, syarikat teknologi besar telah menyembunyikan model bahasa semula jadi (LLM) berskala besar seperti rahsia perdagangan yang ketat, dan pasukan BigScience telah meletakkan ketelusan dan keterbukaan di tengah-tengah BLOOM dari awal projek. Hasilnya ialah model bahasa berskala besar yang boleh dikaji dan dikaji serta disediakan untuk semua orang. B
