

Kesan kekurangan data terhadap latihan model


Impak kekurangan data pada latihan model memerlukan contoh kod khusus
Dalam bidang pembelajaran mesin dan kecerdasan buatan, data ialah salah satu elemen teras untuk model latihan. Walau bagaimanapun, masalah yang sering kita hadapi dalam realiti adalah kekurangan data. Kekurangan data merujuk kepada jumlah data latihan yang tidak mencukupi atau kekurangan data beranotasi Dalam kes ini, ia akan memberi kesan tertentu pada latihan model.
Masalah kekurangan data terutamanya dicerminkan dalam aspek berikut:
- Terlebih pemasangan: Apabila jumlah data latihan tidak mencukupi, model terdedah kepada pemasangan berlebihan. Overfitting bermakna model terlalu menyesuaikan diri dengan data latihan dan tidak boleh digeneralisasikan dengan baik kepada data baharu. Ini kerana model tersebut tidak mempunyai sampel data yang mencukupi untuk mempelajari taburan dan ciri-ciri data, menyebabkan model tersebut menghasilkan keputusan ramalan yang tidak tepat.
- Underfitting: Berbanding dengan overfitting, underfitting bermakna model tidak dapat memuatkan data latihan dengan baik. Ini kerana jumlah data latihan tidak mencukupi untuk menampung kepelbagaian data, menyebabkan model tidak dapat menangkap kerumitan data. Model yang kurang dipasang selalunya gagal memberikan ramalan yang tepat.
Bagaimana untuk menyelesaikan masalah kekurangan data dan meningkatkan prestasi model? Berikut ialah beberapa kaedah dan contoh kod yang biasa digunakan:
- Pembesaran data (Pembesaran Data) ialah kaedah biasa untuk menambah bilangan sampel latihan dengan mengubah atau mengembangkan data sedia ada. Kaedah peningkatan data biasa termasuk putaran imej, flipping, penskalaan, pemangkasan, dsb. Berikut ialah contoh kod putaran imej mudah:
from PIL import Image
def rotate_image(image, angle):
rotated_image = image.rotate(angle)
return rotated_image
image = Image.open('image.jpg')
rotated_image = rotate_image(image, 90)
rotated_image.save('rotated_image.jpg')- Pembelajaran pemindahan (Transfer Learning) ialah menggunakan model yang sudah terlatih untuk menyelesaikan masalah baharu. Dengan menggunakan ciri yang telah dipelajari daripada model sedia ada, latihan yang lebih baik boleh dilakukan pada set data yang terhad. Berikut ialah contoh kod pembelajaran pemindahan:
from keras.applications import VGG16 from keras.models import Model base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3)) x = base_model.output x = GlobalAveragePooling2D()(x) x = Dense(1024, activation='relu')(x) predictions = Dense(num_classes, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=predictions) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
- Penyesuaian Domain (Penyesuaian Domain) ialah kaedah pemindahan pengetahuan dari domain sumber ke domain sasaran. Keupayaan generalisasi yang lebih baik boleh diperoleh dengan menggunakan beberapa teknik penyesuaian domain, seperti pembelajaran diselia sendiri, rangkaian musuh domain, dsb. Berikut ialah contoh kod penyesuaian domain:
import torch
import torchvision
import torch.nn as nn
source_model = torchvision.models.resnet50(pretrained=True)
target_model = torchvision.models.resnet50(pretrained=False)
for param in source_model.parameters():
param.requires_grad = False
source_features = source_model.features(x)
target_features = target_model.features(x)
class DANNClassifier(nn.Module):
def __init__(self, num_classes):
super(DANNClassifier, self).__init__()
self.fc = nn.Linear(2048, num_classes)
def forward(self, x):
x = self.fc(x)
return x
source_classifier = DANNClassifier(num_classes)
target_classifier = DANNClassifier(num_classes)
source_outputs = source_classifier(source_features)
target_outputs = target_classifier(target_features)Kekurangan data mempunyai kesan yang tidak boleh diabaikan pada latihan model. Melalui kaedah seperti penambahan data, pembelajaran pemindahan dan penyesuaian domain, kami boleh menyelesaikan masalah kekurangan data dengan berkesan dan meningkatkan prestasi dan keupayaan generalisasi model. Dalam aplikasi praktikal, kita harus memilih kaedah yang sesuai berdasarkan masalah khusus dan ciri data untuk mendapatkan hasil yang lebih baik.
Atas ialah kandungan terperinci Kesan kekurangan data terhadap latihan model. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

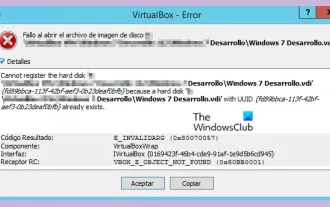 VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)Ralat VirtualBox
Mar 24, 2024 am 09:51 AM
VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)Ralat VirtualBox
Mar 24, 2024 am 09:51 AM
Apabila cuba membuka imej cakera dalam VirtualBox, anda mungkin menghadapi ralat yang menunjukkan bahawa cakera keras tidak boleh didaftarkan. Ini biasanya berlaku apabila fail imej cakera VM yang anda cuba buka mempunyai UUID yang sama seperti fail imej cakera maya yang lain. Dalam kes ini, VirtualBox memaparkan kod ralat VBOX_E_OBJECT_NOT_FOUND(0x80bb0001). Jika anda menghadapi ralat ini, jangan risau, terdapat beberapa penyelesaian yang boleh anda cuba. Mula-mula, anda boleh cuba menggunakan alat baris arahan VirtualBox untuk menukar UUID fail imej cakera, yang akan mengelakkan konflik. Anda boleh menjalankan arahan `VBoxManageinternal
 Sejauh manakah keberkesanan menerima panggilan telefon menggunakan mod kapal terbang?
Feb 20, 2024 am 10:07 AM
Sejauh manakah keberkesanan menerima panggilan telefon menggunakan mod kapal terbang?
Feb 20, 2024 am 10:07 AM
Apa yang berlaku apabila seseorang menelefon dalam mod pesawat? Telefon bimbit telah menjadi salah satu alat yang sangat diperlukan dalam kehidupan orang ramai, ia bukan sahaja alat komunikasi, tetapi juga koleksi hiburan, pembelajaran, kerja dan fungsi lain. Dengan peningkatan berterusan dan penambahbaikan fungsi telefon mudah alih, orang ramai menjadi semakin bergantung kepada telefon mudah alih. Dengan kemunculan mod kapal terbang, orang ramai boleh menggunakan telefon mereka dengan lebih mudah semasa penerbangan. Walau bagaimanapun, sesetengah orang bimbang tentang kesan panggilan orang lain dalam mod kapal terbang pada telefon mudah alih atau pengguna? Artikel ini akan menganalisis dan membincangkan dari beberapa aspek. pertama
 Amalan latihan sistem pengesyoran berskala besar WeChat berdasarkan PyTorch
Apr 12, 2023 pm 12:13 PM
Amalan latihan sistem pengesyoran berskala besar WeChat berdasarkan PyTorch
Apr 12, 2023 pm 12:13 PM
Artikel ini akan memperkenalkan latihan sistem pengesyoran berskala besar WeChat berdasarkan PyTorch. Tidak seperti beberapa bidang pembelajaran mendalam yang lain, sistem pengesyoran masih menggunakan Tensorflow sebagai rangka kerja latihan, yang dikritik oleh majoriti pembangun. Walaupun terdapat beberapa amalan menggunakan PyTorch untuk latihan pengesyoran, skalanya kecil dan tiada pengesahan perniagaan sebenar, menjadikannya sukar untuk mempromosikan pengguna awal perniagaan. Pada Februari 2022, pasukan PyTorch melancarkan perpustakaan rasmi yang disyorkan TorchRec. Pasukan kami mula mencuba TorchRec dalam perniagaan dalaman pada bulan Mei dan melancarkan satu siri kerjasama dengan pasukan TorchRec. Sepanjang beberapa bulan percubaan, kami menemui TorchR
 Kerentanan Kemasukan Fail di Jawa dan Kesannya
Aug 08, 2023 am 10:30 AM
Kerentanan Kemasukan Fail di Jawa dan Kesannya
Aug 08, 2023 am 10:30 AM
Java ialah bahasa pengaturcaraan yang biasa digunakan untuk membangunkan pelbagai aplikasi. Walau bagaimanapun, sama seperti bahasa pengaturcaraan lain, Java mempunyai kelemahan dan risiko keselamatan. Salah satu kelemahan yang biasa ialah kerentanan kemasukan fail (FileInclusionVulnerability) Artikel ini akan meneroka prinsip, kesan dan cara mencegah kerentanan ini. Kerentanan kemasukan fail merujuk kepada pengenalan dinamik atau kemasukan fail lain dalam program, tetapi fail yang diperkenalkan tidak disahkan dan dilindungi sepenuhnya, oleh itu
 Bagaimana untuk mematikan fungsi ulasan pada TikTok? Apakah yang berlaku selepas mematikan fungsi ulasan pada TikTok?
Mar 23, 2024 pm 06:20 PM
Bagaimana untuk mematikan fungsi ulasan pada TikTok? Apakah yang berlaku selepas mematikan fungsi ulasan pada TikTok?
Mar 23, 2024 pm 06:20 PM
Di platform Douyin, pengguna bukan sahaja boleh berkongsi detik hidup mereka, tetapi juga berinteraksi dengan pengguna lain. Kadangkala fungsi ulasan boleh menyebabkan beberapa pengalaman yang tidak menyenangkan, seperti keganasan dalam talian, komen berniat jahat, dsb. Jadi, bagaimana untuk mematikan fungsi ulasan TikTok? 1. Bagaimana untuk mematikan fungsi komen Douyin? 1. Log masuk ke APP Douyin dan masukkan halaman utama peribadi anda. 2. Klik "I" di penjuru kanan sebelah bawah untuk memasuki menu tetapan. 3. Dalam menu tetapan, cari "Tetapan Privasi". 4. Klik "Tetapan Privasi" untuk memasuki antara muka tetapan privasi. 5. Dalam antara muka tetapan privasi, cari "Tetapan Komen". 6. Klik "Tetapan Komen" untuk memasuki antara muka tetapan ulasan. 7. Dalam antara muka tetapan ulasan, cari pilihan "Tutup Komen". 8. Klik pilihan "Tutup Komen" untuk mengesahkan ulasan penutup
 Kesan kekurangan data terhadap latihan model
Oct 08, 2023 pm 06:17 PM
Kesan kekurangan data terhadap latihan model
Oct 08, 2023 pm 06:17 PM
Kesan kekurangan data pada latihan model memerlukan contoh kod khusus Dalam bidang pembelajaran mesin dan kecerdasan buatan, data ialah salah satu elemen teras untuk model latihan. Walau bagaimanapun, masalah yang sering kita hadapi dalam realiti adalah kekurangan data. Kekurangan data merujuk kepada jumlah data latihan yang tidak mencukupi atau kekurangan data beranotasi Dalam kes ini, ia akan memberi kesan tertentu pada latihan model. Masalah kekurangan data terutamanya dicerminkan dalam aspek-aspek berikut: Overfitting: Apabila jumlah data latihan tidak mencukupi, model terdedah kepada overfitting. Overfitting merujuk kepada model yang terlalu menyesuaikan diri dengan data latihan.
 Apakah masalah yang akan ditimbulkan oleh sektor buruk pada cakera keras?
Feb 18, 2024 am 10:07 AM
Apakah masalah yang akan ditimbulkan oleh sektor buruk pada cakera keras?
Feb 18, 2024 am 10:07 AM
Sektor buruk pada cakera keras merujuk kepada kegagalan fizikal cakera keras, iaitu, unit storan pada cakera keras tidak boleh membaca atau menulis data secara normal. Kesan sektor buruk pada cakera keras adalah sangat ketara, dan ia boleh menyebabkan kehilangan data, ranap sistem dan prestasi cakera keras yang berkurangan. Artikel ini akan memperkenalkan secara terperinci kesan sektor buruk cakera keras dan penyelesaian yang berkaitan. Pertama, sektor buruk pada cakera keras boleh menyebabkan kehilangan data. Apabila sektor dalam cakera keras mempunyai sektor buruk, data pada sektor itu tidak boleh dibaca, mengakibatkan kerosakan fail atau tidak boleh diakses. Keadaan ini amat serius jika fail penting disimpan dalam sektor di mana sektor buruk berada.
 Cara menggunakan Python untuk melatih model pada imej
Aug 26, 2023 pm 10:42 PM
Cara menggunakan Python untuk melatih model pada imej
Aug 26, 2023 pm 10:42 PM
Gambaran keseluruhan cara menggunakan Python untuk melatih model pada imej: Dalam bidang penglihatan komputer, menggunakan model pembelajaran mendalam untuk mengklasifikasikan imej, pengesanan sasaran dan tugas lain telah menjadi kaedah biasa. Sebagai bahasa pengaturcaraan yang digunakan secara meluas, Python menyediakan banyak perpustakaan dan alatan, menjadikannya agak mudah untuk melatih model pada imej. Artikel ini akan memperkenalkan cara menggunakan Python dan perpustakaan berkaitannya untuk melatih model pada imej, dan menyediakan contoh kod yang sepadan. Penyediaan persekitaran: Sebelum memulakan, anda perlu memastikan bahawa anda telah memasang
