

Kesan kehilangan data pada ketepatan model


Impak kehilangan data pada ketepatan model memerlukan contoh kod khusus
Dalam bidang pembelajaran mesin dan analisis data, data ialah sumber yang berharga. Walau bagaimanapun, dalam situasi sebenar, kita sering menghadapi masalah kehilangan data dalam set data. Data yang hilang merujuk kepada ketiadaan atribut atau pemerhatian tertentu dalam set data. Data yang hilang boleh memberi kesan buruk pada ketepatan model kerana data yang hilang boleh memperkenalkan ramalan bias atau salah. Dalam artikel ini, kami membincangkan kesan kehilangan data pada ketepatan model dan menyediakan beberapa contoh kod konkrit.
Pertama sekali, kehilangan data boleh menyebabkan latihan model yang tidak tepat. Contohnya, jika dalam masalah pengelasan, label kategori bagi beberapa pemerhatian tiada, model tidak akan dapat mempelajari ciri dan maklumat kategori sampel ini dengan betul semasa melatih model. Ini akan memberi kesan negatif terhadap ketepatan model, menjadikan ramalan model lebih berat sebelah terhadap kategori sedia ada yang lain. Untuk menyelesaikan masalah ini, pendekatan biasa adalah untuk mengendalikan data yang hilang dan menggunakan strategi yang munasabah untuk mengisi nilai yang hilang. Berikut ialah contoh kod khusus:
import pandas as pd
from sklearn.preprocessing import Imputer
# 读取数据
data = pd.read_csv("data.csv")
# 创建Imputer对象
imputer = Imputer(missing_values='NaN', strategy='mean', axis=0)
# 填充缺失值
data_filled = imputer.fit_transform(data)
# 训练模型
# ...Dalam kod di atas, kami menggunakan kelas Imputer dalam modul sklearn.preprocessing untuk mengendalikan nilai yang tiada. Kelas Imputer menyediakan pelbagai strategi untuk mengisi nilai yang hilang, seperti menggunakan min, median atau nilai yang paling kerap untuk mengisi nilai yang tiada. Dalam contoh di atas, kami menggunakan min untuk mengisi nilai yang hilang. sklearn.preprocessing模块中的Imputer类来处理缺失值。Imputer类提供了多种填充缺失值的策略,例如使用均值、中位数或者出现频率最高的值来填充缺失值。在上面的例子中,我们使用了均值来填充缺失值。
其次,数据缺失还可能会对模型的评估和验证产生不利的影响。在许多模型评估和验证的指标中,对缺失数据的处理是十分关键的。如果不正确处理缺失数据,那么评估指标可能会产生偏差,并无法准确反映模型在真实场景中的性能。以下是一个使用交叉验证评估模型的示例代码:
import pandas as pd
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
# 读取数据
data = pd.read_csv("data.csv")
# 创建模型
model = LogisticRegression()
# 填充缺失值
imputer = Imputer(missing_values='NaN', strategy='mean', axis=0)
data_filled = imputer.fit_transform(data)
# 交叉验证评估模型
scores = cross_val_score(model, data_filled, target, cv=10)
avg_score = scores.mean()在上面的代码中,我们使用了sklearn.model_selection模块中的cross_val_score函数来进行交叉验证评估。在使用交叉验证之前,我们先使用Imputer
rrreee
Dalam kod di atas, kami telah menggunakan fungsicross_val_score daripada modul sklearn.model_selection untuk melaksanakan silang pengesahan Menilai. Sebelum menggunakan pengesahan silang, kami mula-mula menggunakan kelas Imputer untuk mengisi nilai yang tiada. Ini memastikan bahawa metrik penilaian mencerminkan prestasi model dengan tepat dalam senario sebenar. 🎜🎜Ringkasnya, kesan kehilangan data terhadap ketepatan model adalah isu penting yang perlu diambil serius. Apabila berurusan dengan data yang hilang, kami boleh menggunakan kaedah yang sesuai untuk mengisi nilai yang hilang, dan kami juga perlu mengendalikan data yang hilang dengan betul semasa penilaian dan pengesahan model. Ini boleh memastikan bahawa model mempunyai ketepatan yang tinggi dan keupayaan generalisasi dalam aplikasi praktikal. Di atas ialah pengenalan kepada kesan kehilangan data pada ketepatan model, dan beberapa contoh kod khusus diberikan. Saya harap pembaca boleh mendapat inspirasi dan bantuan daripadanya. 🎜Atas ialah kandungan terperinci Kesan kehilangan data pada ketepatan model. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

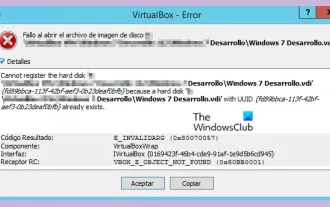 VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)Ralat VirtualBox
Mar 24, 2024 am 09:51 AM
VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)Ralat VirtualBox
Mar 24, 2024 am 09:51 AM
Apabila cuba membuka imej cakera dalam VirtualBox, anda mungkin menghadapi ralat yang menunjukkan bahawa cakera keras tidak boleh didaftarkan. Ini biasanya berlaku apabila fail imej cakera VM yang anda cuba buka mempunyai UUID yang sama seperti fail imej cakera maya yang lain. Dalam kes ini, VirtualBox memaparkan kod ralat VBOX_E_OBJECT_NOT_FOUND(0x80bb0001). Jika anda menghadapi ralat ini, jangan risau, terdapat beberapa penyelesaian yang boleh anda cuba. Mula-mula, anda boleh cuba menggunakan alat baris arahan VirtualBox untuk menukar UUID fail imej cakera, yang akan mengelakkan konflik. Anda boleh menjalankan arahan `VBoxManageinternal
 Sejauh manakah keberkesanan menerima panggilan telefon menggunakan mod kapal terbang?
Feb 20, 2024 am 10:07 AM
Sejauh manakah keberkesanan menerima panggilan telefon menggunakan mod kapal terbang?
Feb 20, 2024 am 10:07 AM
Apa yang berlaku apabila seseorang menelefon dalam mod pesawat? Telefon bimbit telah menjadi salah satu alat yang sangat diperlukan dalam kehidupan orang ramai, ia bukan sahaja alat komunikasi, tetapi juga koleksi hiburan, pembelajaran, kerja dan fungsi lain. Dengan peningkatan berterusan dan penambahbaikan fungsi telefon mudah alih, orang ramai menjadi semakin bergantung kepada telefon mudah alih. Dengan kemunculan mod kapal terbang, orang ramai boleh menggunakan telefon mereka dengan lebih mudah semasa penerbangan. Walau bagaimanapun, sesetengah orang bimbang tentang kesan panggilan orang lain dalam mod kapal terbang pada telefon mudah alih atau pengguna? Artikel ini akan menganalisis dan membincangkan dari beberapa aspek. pertama
 Kerentanan Kemasukan Fail di Jawa dan Kesannya
Aug 08, 2023 am 10:30 AM
Kerentanan Kemasukan Fail di Jawa dan Kesannya
Aug 08, 2023 am 10:30 AM
Java ialah bahasa pengaturcaraan yang biasa digunakan untuk membangunkan pelbagai aplikasi. Walau bagaimanapun, sama seperti bahasa pengaturcaraan lain, Java mempunyai kelemahan dan risiko keselamatan. Salah satu kelemahan yang biasa ialah kerentanan kemasukan fail (FileInclusionVulnerability) Artikel ini akan meneroka prinsip, kesan dan cara mencegah kerentanan ini. Kerentanan kemasukan fail merujuk kepada pengenalan dinamik atau kemasukan fail lain dalam program, tetapi fail yang diperkenalkan tidak disahkan dan dilindungi sepenuhnya, oleh itu
 Bagaimana untuk mematikan fungsi ulasan pada TikTok? Apakah yang berlaku selepas mematikan fungsi ulasan pada TikTok?
Mar 23, 2024 pm 06:20 PM
Bagaimana untuk mematikan fungsi ulasan pada TikTok? Apakah yang berlaku selepas mematikan fungsi ulasan pada TikTok?
Mar 23, 2024 pm 06:20 PM
Di platform Douyin, pengguna bukan sahaja boleh berkongsi detik hidup mereka, tetapi juga berinteraksi dengan pengguna lain. Kadangkala fungsi ulasan boleh menyebabkan beberapa pengalaman yang tidak menyenangkan, seperti keganasan dalam talian, komen berniat jahat, dsb. Jadi, bagaimana untuk mematikan fungsi ulasan TikTok? 1. Bagaimana untuk mematikan fungsi komen Douyin? 1. Log masuk ke APP Douyin dan masukkan halaman utama peribadi anda. 2. Klik "I" di penjuru kanan sebelah bawah untuk memasuki menu tetapan. 3. Dalam menu tetapan, cari "Tetapan Privasi". 4. Klik "Tetapan Privasi" untuk memasuki antara muka tetapan privasi. 5. Dalam antara muka tetapan privasi, cari "Tetapan Komen". 6. Klik "Tetapan Komen" untuk memasuki antara muka tetapan ulasan. 7. Dalam antara muka tetapan ulasan, cari pilihan "Tutup Komen". 8. Klik pilihan "Tutup Komen" untuk mengesahkan ulasan penutup
 Kesan kekurangan data terhadap latihan model
Oct 08, 2023 pm 06:17 PM
Kesan kekurangan data terhadap latihan model
Oct 08, 2023 pm 06:17 PM
Kesan kekurangan data pada latihan model memerlukan contoh kod khusus Dalam bidang pembelajaran mesin dan kecerdasan buatan, data ialah salah satu elemen teras untuk model latihan. Walau bagaimanapun, masalah yang sering kita hadapi dalam realiti adalah kekurangan data. Kekurangan data merujuk kepada jumlah data latihan yang tidak mencukupi atau kekurangan data beranotasi Dalam kes ini, ia akan memberi kesan tertentu pada latihan model. Masalah kekurangan data terutamanya dicerminkan dalam aspek-aspek berikut: Overfitting: Apabila jumlah data latihan tidak mencukupi, model terdedah kepada overfitting. Overfitting merujuk kepada model yang terlalu menyesuaikan diri dengan data latihan.
 Apakah masalah yang akan ditimbulkan oleh sektor buruk pada cakera keras?
Feb 18, 2024 am 10:07 AM
Apakah masalah yang akan ditimbulkan oleh sektor buruk pada cakera keras?
Feb 18, 2024 am 10:07 AM
Sektor buruk pada cakera keras merujuk kepada kegagalan fizikal cakera keras, iaitu, unit storan pada cakera keras tidak boleh membaca atau menulis data secara normal. Kesan sektor buruk pada cakera keras adalah sangat ketara, dan ia boleh menyebabkan kehilangan data, ranap sistem dan prestasi cakera keras yang berkurangan. Artikel ini akan memperkenalkan secara terperinci kesan sektor buruk cakera keras dan penyelesaian yang berkaitan. Pertama, sektor buruk pada cakera keras boleh menyebabkan kehilangan data. Apabila sektor dalam cakera keras mempunyai sektor buruk, data pada sektor itu tidak boleh dibaca, mengakibatkan kerosakan fail atau tidak boleh diakses. Keadaan ini amat serius jika fail penting disimpan dalam sektor di mana sektor buruk berada.
 Apakah kesan khusus kad lombong terhadap permainan?
Jan 03, 2024 am 09:05 AM
Apakah kesan khusus kad lombong terhadap permainan?
Jan 03, 2024 am 09:05 AM
Sesetengah pengguna mungkin mempertimbangkan untuk membeli kad perlombongan demi harga yang murah. Apakah kesan penggunaan kad mining untuk bermain permainan: 1. Kestabilan bermain permainan dengan kad mining tidak dapat dijamin, kerana hayat kad mining adalah sangat singkat dan berkemungkinan menjadi tidak berguna selepas bermain sahaja. 2. Kad perlombongan pada asasnya adalah versi yang dikebiri daripada versi asal Disebabkan haus dan lusuh jangka panjang, prestasi dalam semua aspek mungkin lemah. 3. Dengan cara ini, pengguna mungkin tidak dapat memaparkan semua kesan permainan semasa bermain permainan. 4. Lebih-lebih lagi, komponen elektronik kad grafik akan menua lebih awal, apatah lagi bermain permainan juga memakan kad grafik, jadi ia telah dikeringkan ke tahap yang lebih besar, jadi impak kepada permainan adalah hebat. 5. Secara umumnya, gunakan kad mining untuk bermain permainan
 Apakah kesan konfigurasi kad grafik rendah?
Feb 15, 2024 pm 03:27 PM
Apakah kesan konfigurasi kad grafik rendah?
Feb 15, 2024 pm 03:27 PM
Kualiti berjalan komputer pada asasnya mempunyai kesan yang besar pada kad grafiknya Sesetengah pengguna tidak tahu banyak tentang kad grafik, dan mereka tidak tahu dengan tepat aspek komputer yang akan dipengaruhi oleh kad grafik adalah Mari perkenalkan beberapa kesan konfigurasi kad grafik rendah. Apakah kesan konfigurasi kad grafik rendah Jawapan: 1. Beberapa permainan 3D berskala besar tidak boleh dijalankan. 2. Apabila memainkan beberapa video definisi tinggi, komputer akan berada di bawah tekanan yang hebat. 3. Untuk beberapa perisian yang lebih profesional, tiada cara untuk menjalankannya dengan baik apabila lukisan dan pemaparan model 3D diperlukan. 4. Jika konfigurasi kad grafik rendah, permainan tidak akan dapat dibuka, atau ia akan kerap ranap atau beku, dan komputer juga akan mempunyai skrin kabur atau skrin biru. 5. Perkara yang paling penting dalam permainan adalah kad grafik, kerana banyak gambar memerlukan
