

Isu kecekapan inferens model pembelajaran mesin


Masalah kecekapan inferens model pembelajaran mesin memerlukan contoh kod khusus
Pengenalan
Dengan pembangunan dan aplikasi pembelajaran mesin yang meluas, orang ramai semakin memberi perhatian kepada latihan model. Walau bagaimanapun, untuk kebanyakan aplikasi masa nyata, kecekapan inferens model juga penting. Artikel ini akan membincangkan kecekapan inferens model pembelajaran mesin dan memberikan beberapa contoh kod khusus.
1. Kepentingan kecekapan inferens
Kecekapan inferens model merujuk kepada keupayaan model untuk memberikan output dengan cepat dan tepat diberikan input. Dalam banyak aplikasi kehidupan sebenar, seperti pemprosesan imej masa nyata, pengecaman pertuturan, pemanduan autonomi, dll., keperluan untuk kecekapan inferens adalah sangat tinggi. Ini kerana aplikasi ini perlu memproses sejumlah besar data dalam masa nyata dan bertindak balas dengan segera.
2. Faktor yang mempengaruhi kecekapan inferens
- Seni bina model
Seni bina model merupakan salah satu faktor penting yang mempengaruhi kecekapan inferens. Sesetengah model kompleks, seperti Rangkaian Neural Dalam (DNN), dsb., mungkin mengambil masa yang lama semasa proses inferens. Oleh itu, apabila mereka bentuk model, kita harus cuba memilih model ringan atau mengoptimumkannya untuk tugas tertentu.
- Peranti perkakasan
Peranti perkakasan juga mempunyai kesan ke atas kecekapan inferens. Beberapa pemecut perkakasan yang muncul, seperti Unit Pemprosesan Grafik (GPU) dan Unit Pemprosesan Tensor (TPU), mempunyai kelebihan yang ketara dalam mempercepatkan proses inferens model. Memilih peranti perkakasan yang betul boleh meningkatkan kelajuan inferens.
- Teknologi pengoptimuman
Teknologi pengoptimuman ialah cara yang berkesan untuk meningkatkan kecekapan penaakulan. Sebagai contoh, teknologi pemampatan model boleh mengurangkan saiz model, dengan itu memendekkan masa inferens. Pada masa yang sama, teknologi pengkuantitian boleh menukar model titik terapung kepada model titik tetap, seterusnya meningkatkan kelajuan inferens.
3. Contoh Kod
Dua contoh kod diberikan di bawah, menunjukkan cara menggunakan teknik pengoptimuman untuk meningkatkan kecekapan inferens.
Contoh Kod 1: Model Compression
import tensorflow as tf
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.models import save_model
# 加载原始模型
model = MobileNetV2(weights='imagenet')
# 保存原始模型
save_model(model, 'original_model.h5')
# 模型压缩
compressed_model = tf.keras.models.load_model('original_model.h5')
compressed_model.save('compressed_model.h5', include_optimizer=False)Dalam kod di atas, kami menggunakan perpustakaan aliran tensor untuk memuatkan model MobileNetV2 yang telah terlatih dan menyimpannya sebagai model asal. Kemudian, gunakan model untuk pemampatan, simpan model sebagai fail compressed_model.h5. Melalui pemampatan model, saiz model boleh dikurangkan, dengan itu meningkatkan kelajuan inferens.
Contoh Kod 2: Menggunakan Pecutan GPU
import tensorflow as tf
from tensorflow.keras.applications import MobileNetV2
# 设置GPU加速
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
# 加载模型
model = MobileNetV2(weights='imagenet')
# 进行推理
output = model.predict(input)Dalam kod di atas, kami menggunakan perpustakaan aliran tensor untuk memuatkan model MobileNetV2 yang telah terlatih dan menetapkan proses inferens model kepada pecutan GPU. Dengan menggunakan pecutan GPU, kelajuan inferens boleh ditingkatkan dengan ketara.
Kesimpulan
Artikel ini membincangkan kecekapan inferens model pembelajaran mesin dan memberikan beberapa contoh kod khusus. Kecekapan inferens model pembelajaran mesin adalah sangat penting untuk banyak aplikasi masa nyata Kecekapan inferens harus dipertimbangkan semasa mereka bentuk model dan langkah pengoptimuman yang sepadan harus diambil. Kami berharap melalui pengenalan artikel ini, pembaca dapat lebih memahami dan menggunakan teknologi pengoptimuman kecekapan inferens.
Atas ialah kandungan terperinci Isu kecekapan inferens model pembelajaran mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1359
1359
 52
52

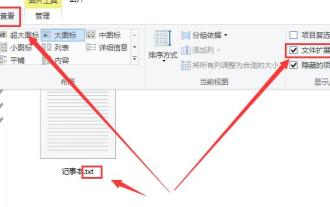 Bagaimana untuk menukar sambungan fail Win10 Notepad
Jan 04, 2024 pm 12:49 PM
Bagaimana untuk menukar sambungan fail Win10 Notepad
Jan 04, 2024 pm 12:49 PM
Apabila menggunakan Notepad, kita perlu menukar sambungan Notepad kerana perkara yang berbeza yang perlu kita tangani Jadi bagaimana kita menukar sambungan Sebenarnya, kita hanya perlu menggunakan fungsi nama semula untuk mengubah suai sambungan. Cara menukar sambungan Win10 Notepad: 1. Dalam folder, mula-mula klik pada bahagian atas dan semaknya. 2. Dengan cara ini, sambungan fail akan dipaparkan, kemudian klik kanan pad nota anda dan pilih 3. Pilih yang berikut. 4. Jika ditukar kepada format .jpeg. Kemudian gesaan akan muncul, klik padanya. 5. Perubahan telah selesai, dan itu sahaja.
 Panggil pencetus SQL untuk melaksanakan program luaran
Feb 18, 2024 am 10:25 AM
Panggil pencetus SQL untuk melaksanakan program luaran
Feb 18, 2024 am 10:25 AM
Tajuk: Contoh kod khusus untuk pencetus SQL untuk memanggil program luaran Teks: Apabila menggunakan pencetus SQL, kadangkala perlu memanggil program luaran untuk memproses beberapa operasi tertentu. Artikel ini akan memperkenalkan cara memanggil program luaran dalam pencetus SQL dan memberikan contoh kod khusus. 1. Buat pencetus Pertama, kita perlu mencipta pencetus untuk mendengar peristiwa dalam pangkalan data. Di sini kita mengambil "jadual pesanan (jadual_pesanan)" sebagai contoh Apabila pesanan baharu dimasukkan, pencetus akan diaktifkan, dan kemudian program luaran akan dipanggil untuk melaksanakan operasi.
 Bagaimana untuk menukar HTML kepada format MP4
Feb 19, 2024 pm 02:48 PM
Bagaimana untuk menukar HTML kepada format MP4
Feb 19, 2024 pm 02:48 PM
Tajuk: Cara menukar HTML kepada format MP4: Contoh kod terperinci Dalam proses pengeluaran halaman web harian, kami sering menghadapi keperluan untuk menukar halaman HTML atau elemen HTML tertentu kepada video MP4. Contohnya, simpan kesan animasi, tayangan slaid atau elemen dinamik lain sebagai fail video. Artikel ini akan memperkenalkan cara menggunakan HTML5 dan JavaScript untuk menukar HTML kepada format MP4 dan memberikan contoh kod khusus. Tag video HTML5 dan pengenalan HTML5 CanvasAPI
 Bagaimana untuk mengekstrak fail Dump
Feb 19, 2024 pm 12:15 PM
Bagaimana untuk mengekstrak fail Dump
Feb 19, 2024 pm 12:15 PM
Cara merebut fail Dump Dalam sistem komputer, fail Dump ialah fail yang merekodkan status pengendalian dan data sistem. Dalam pembangunan perisian dan penyelesaian masalah sistem, merebut fail Dump boleh membantu pembangun program dan pentadbir sistem menganalisis dan mendiagnosis pelbagai masalah, seperti ranap program, kebocoran memori dan keabnormalan sistem. Artikel ini akan memperkenalkan beberapa kaedah dan alatan biasa untuk merebut fail Dump. 1. Bagaimana untuk mengambil fail Dump di bawah sistem Windows menggunakan Pengurus Tugas: Dalam sistem pengendalian Windows,
 Tarikh keluaran Windows 12
Jan 05, 2024 pm 05:24 PM
Tarikh keluaran Windows 12
Jan 05, 2024 pm 05:24 PM
Sebelum ini, win11 telah dikeluarkan secara rasmi, dan ramai pengguna sudah mula menikmati win12 mereka ingin tahu bilakah win12 akan dikeluarkan. Bilakah win12 dikeluarkan: J: Win12 dijangka dikeluarkan sekitar musim luruh tahun 2024. 1. Menurut maklumat terkini Microsoft, win12 dijangka dikeluarkan pada musim luruh 2024. 2. Dan kali ini win12 akan mempunyai pelbagai konsep reka bentuk baharu, dan akan terdapat lebih banyak peningkatan dalam kekemasan dan penampilan visual. 3. Pada mesyuarat pembangun terkini, pembangun Microsoft mendedahkan bahawa mereka akan mencipta bar tugas terapung untuk memberikan bar tugas perasaan terapung.
 Apakah peranan Panel Kawalan NVIDIA?
Feb 19, 2024 pm 03:59 PM
Apakah peranan Panel Kawalan NVIDIA?
Feb 19, 2024 pm 03:59 PM
Apakah Panel Kawalan NVIDIA Dengan perkembangan pesat teknologi komputer, kepentingan kad grafik menjadi semakin penting. Sebagai salah satu pengeluar kad grafik terkemuka dunia, panel kawalan NVIDIA telah menarik lebih banyak perhatian. Jadi, apakah sebenarnya yang dilakukan oleh panel kawalan NVIDIA? Artikel ini akan memberi anda pengenalan terperinci kepada fungsi dan kegunaan panel kawalan NVIDIA. Mula-mula, mari kita fahami konsep dan definisi panel kawalan NVIDIA. Panel Kawalan NVIDIA ialah perisian yang digunakan untuk mengurus dan mengkonfigurasi tetapan berkaitan kad grafik.
 Bagaimana untuk membuka fail psd pada telefon bimbit
Feb 21, 2024 pm 05:48 PM
Bagaimana untuk membuka fail psd pada telefon bimbit
Feb 21, 2024 pm 05:48 PM
Fail PSD telefon mudah alih dibuka menggunakan perisian Photoshop PSD ialah format fail proprietari Photoshop dan boleh mengekalkan maklumat seperti lapisan, saluran, laluan, ketelusan, dll. Oleh itu, jika anda ingin membuka fail PSD telefon bimbit, pastikan dahulu anda telah memasang perisian Photoshop. Mula-mula, buka perisian Photoshop, kemudian klik pilihan "Fail" dalam bar menu, dan pilih "Buka" dalam menu lungsur timbul. Seterusnya, anda perlu menyemak imbas folder anda untuk mencari telefon yang anda simpan
 Peranan lebar penuh dan separuh lebar dalam kaedah input Cina
Mar 25, 2024 am 09:57 AM
Peranan lebar penuh dan separuh lebar dalam kaedah input Cina
Mar 25, 2024 am 09:57 AM
Lebar penuh dan separuh lebar ialah konsep biasa dalam kaedah input Cina, dan ia mewakili lebar aksara yang berbeza. Dalam bidang komputer, konsep lebar penuh dan separuh lebar digunakan terutamanya untuk menggambarkan saiz ruang yang diduduki oleh aksara Cina dan huruf Inggeris pada skrin atau dalam cetakan. Pertama sekali, lebar penuh dan separuh lebar asalnya berasal dari era mesin taip. Pada mesin taip, aksara Cina biasanya dipaparkan dalam bentuk lebar penuh, manakala aksara Inggeris dipaparkan dalam bentuk separuh lebar. Ini kerana aksara Cina agak luas, dan menggunakan lebar penuh boleh menjadikan keseluruhan artikel kelihatan lebih cantik dan reka letak lebih padat. Aksara Inggeris ialah
