
 Peranti teknologi
AI
MiniGPT-5, yang menyatukan penjanaan imej dan teks, ada di sini: Token menjadi Voken, dan model itu bukan sahaja boleh meneruskan penulisan, tetapi juga menambah gambar secara automatik.
Peranti teknologi
AI
MiniGPT-5, yang menyatukan penjanaan imej dan teks, ada di sini: Token menjadi Voken, dan model itu bukan sahaja boleh meneruskan penulisan, tetapi juga menambah gambar secara automatik.
MiniGPT-5, yang menyatukan penjanaan imej dan teks, ada di sini: Token menjadi Voken, dan model itu bukan sahaja boleh meneruskan penulisan, tetapi juga menambah gambar secara automatik.

Model berskala besar membuat lompatan antara bahasa dan penglihatan, menjanjikan untuk memahami dan menjana kandungan teks dan imej dengan lancar. Dalam satu siri kajian baru-baru ini, penyepaduan ciri berbilang mod bukan sahaja menjadi trend yang semakin berkembang tetapi telah membawa kepada kemajuan utama yang terdiri daripada perbualan pelbagai mod kepada alatan penciptaan kandungan. Model bahasa yang besar telah menunjukkan keupayaan yang tiada tandingan dalam pemahaman dan penjanaan teks. Walau bagaimanapun, penjanaan imej secara serentak dengan naratif teks yang koheren masih merupakan kawasan yang perlu dibangunkan
Baru-baru ini, pasukan penyelidik dari University of California, Santa Cruz mencadangkan MiniGPT-5, kaedah berdasarkan konsep "undi generatif" Inovatif teknologi penjanaan bahasa visual interleaved.

- Alamat kertas: https://browse.arxiv.org/pdf/2310.02239v1.pdf
- alamat projek ai-lab/MiniGPT-5
Menggabungkan mekanisme resapan yang stabil dengan LLM melalui "undi generatif" token visual khas, MiniGPT-5 menandakan cara baharu untuk model penjanaan pelbagai mod mahir. Pada masa yang sama, kaedah latihan dua peringkat yang dicadangkan dalam artikel ini menekankan kepentingan peringkat asas tanpa penerangan, membolehkan model berkembang maju walaupun data adalah terhad. Fasa umum kaedah tidak memerlukan anotasi khusus domain, yang menjadikan penyelesaian kami berbeza daripada kaedah sedia ada. Untuk memastikan teks dan imej yang dijana adalah harmoni, strategi kerugian berganda kertas ini dimainkan, yang dipertingkatkan lagi dengan kaedah undian generatif dan kaedah klasifikasi
Berdasarkan teknik ini, kerja ini menandakan Pendekatan transformatif. Dengan menggunakan ViT (Pengubah Penglihatan) dan Qformer serta model bahasa yang besar, pasukan penyelidik menukar input berbilang modal kepada undian generatif dan memasangkannya dengan lancar dengan Resapan Stable2.1 resolusi tinggi untuk mencapai penjanaan imej yang sedar konteks. Kertas kerja ini menggabungkan imej sebagai input tambahan dengan kaedah pelarasan arahan, dan mempelopori penggunaan kehilangan penjanaan teks dan imej, dengan itu mengembangkan sinergi antara teks dan penglihatan
MiniGPT-5 memadankan model seperti kekangan CLIP, dengan bijak Menyatukan model penyebaran dengan MiniGPT-4 mencapai hasil berbilang modal yang lebih baik tanpa bergantung pada anotasi khusus domain. Paling penting, strategi kami boleh memanfaatkan kemajuan dalam model asas bahasa visual multimodal untuk menyediakan pelan tindakan baharu untuk meningkatkan keupayaan generatif multimodal.
Seperti yang ditunjukkan dalam rajah di bawah, sebagai tambahan kepada pemahaman multi-modal asal dan keupayaan penjanaan teks, MiniGPT5 juga boleh memberikan output multi-modal yang munasabah dan koheren: 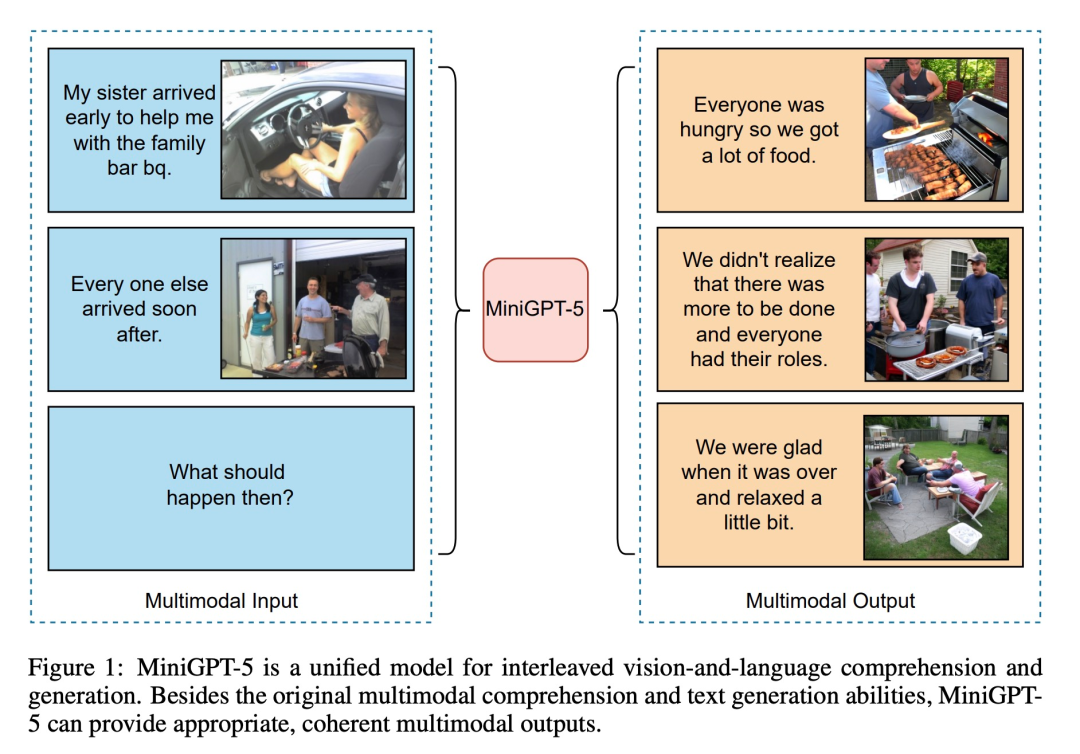
- Sumbangan artikel ini adalah dicerminkan dalam tiga aspek:
- Adalah dicadangkan untuk menggunakan pengekod berbilang modal, yang mewakili teknik umum baru dan telah terbukti lebih berkesan daripada LLM dan Voken generatif songsang, dan menggabungkannya dengan Stable Diffusion untuk menghasilkan interleaved output visual dan linguistik (model bahasa multimodal yang mampu menghasilkan multimodal).
- menyerlahkan strategi latihan dua peringkat baharu untuk penjanaan pelbagai mod tanpa penerangan. Peringkat penjajaran modal tunggal memperoleh ciri visual penjajaran teks berkualiti tinggi daripada sebilangan besar pasangan imej teks. Fasa pembelajaran multimodal termasuk tugas latihan baru, penjanaan konteks segera, memastikan gesaan visual dan tekstual diselaraskan dan dihasilkan dengan baik. Menambah panduan tanpa pengelas semasa fasa latihan meningkatkan lagi kualiti penjanaan.
Sekarang, marilah kita memahami kandungan penyelidikan ini secara terperinci
Tinjauan keseluruhan kaedah
🎜Untuk membolehkan model bahasa besar dengan keupayaan penjanaan pelbagai mod, penyelidik berstruktur memperkenalkan rangka kerja Model bahasa berskala besar berbilang modal terlatih dan model penjanaan teks ke imej disepadukan. Untuk menyelesaikan perbezaan antara medan model yang berbeza, mereka memperkenalkan simbol visual khas "undi generatif" (undi generatif), yang boleh dilatih terus pada imej asal. Selain itu, kaedah latihan dua peringkat dimajukan, digabungkan dengan strategi bootstrap tanpa pengelas, untuk meningkatkan lagi kualiti penjanaan. 🎜🎜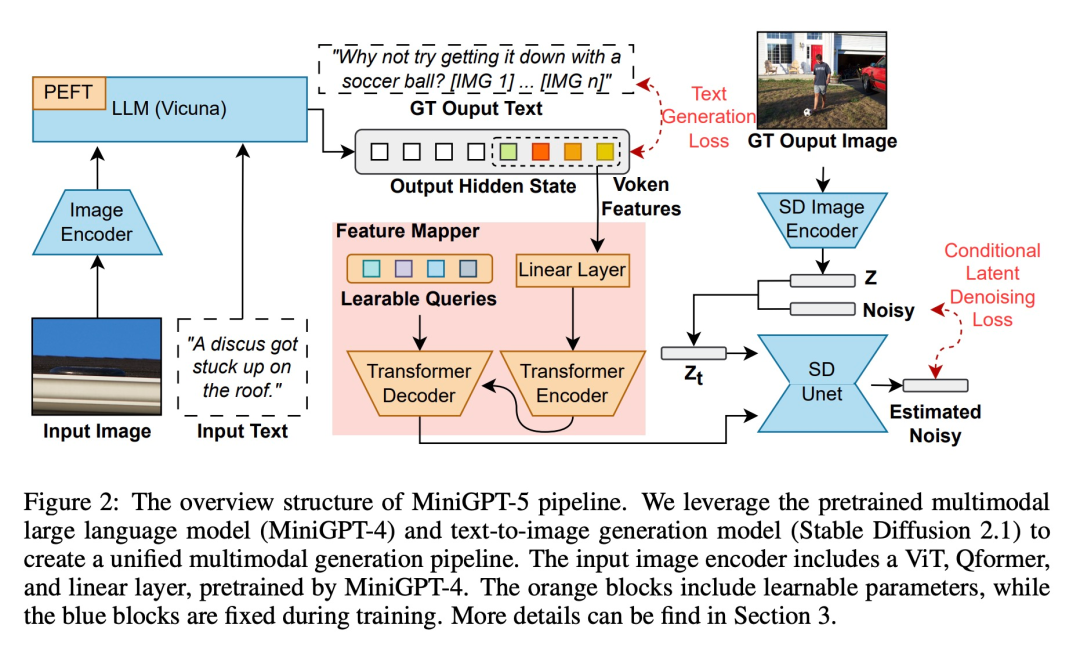
Peringkat input berbilang modal
Kemajuan terkini dalam model berbilang modal besar (seperti MiniGPT-4) terutamanya menumpukan pada pemahaman berbilang mod sebagai input berterusan, mampu mengendalikan input. Untuk melanjutkan fungsinya kepada penjanaan berbilang modal, penyelidik memperkenalkan Vokens generatif yang direka khusus untuk mengeluarkan ciri visual. Selain itu, mereka juga mengguna pakai teknologi penalaan halus yang cekap parameter dalam rangka kerja Model Bahasa Besar (LLM) untuk pembelajaran output berbilang modal
Penjanaan keluaran berbilang modal
Untuk memastikan penjanaan token adalah Untuk menjana penjajaran tepat model, para penyelidik membangunkan modul pemetaan padat untuk pemadanan dimensi dan memperkenalkan beberapa kehilangan yang diselia, termasuk kehilangan ruang teks dan kehilangan model penyebaran terpendam. Kehilangan ruang teks membantu model mempelajari lokasi token dengan tepat, manakala kehilangan resapan terpendam secara langsung menjajarkan token dengan ciri visual yang sesuai. Memandangkan ciri-ciri simbol generatif dipandu secara langsung oleh imej, kaedah ini tidak memerlukan penerangan imej yang lengkap dan mencapai pembelajaran tanpa penerangan
strategi latihan
Memandangkan terdapat kewujudan yang tidak boleh diabaikan. domain teks dan domain imej Pergeseran domain, penyelidik mendapati bahawa latihan secara langsung pada teks berselang yang terhad dan set data imej boleh membawa kepada salah jajaran dan kemerosotan kualiti imej.
Jadi mereka menggunakan dua strategi latihan berbeza untuk mengurangkan masalah ini. Strategi pertama melibatkan penggunaan teknik bootstrapping tanpa pengelas untuk meningkatkan keberkesanan token yang dijana sepanjang proses penyebaran strategi kedua dibentangkan dalam dua fasa: fasa pra-latihan awal memfokuskan pada penjajaran ciri kasar, diikuti dengan fasa penalaan halus Bekerja; mengenai pembelajaran ciri yang kompleks.
Eksperimen dan keputusan
Untuk menilai keberkesanan model, penyelidik memilih pelbagai penanda aras dan menjalankan satu siri penilaian. Tujuan percubaan adalah untuk menangani beberapa soalan utama: Bolehkah
- MiniGPT-5 menjana imej yang boleh dipercayai dan teks yang munasabah?
- Bagaimanakah prestasi MiniGPT-5 berbanding model SOTA lain dalam tugas penjanaan bahasa visual berjalin satu pusingan dan berbilang pusingan?
- Apakah kesan reka bentuk setiap modul terhadap prestasi keseluruhan?
Untuk menilai prestasi model MiniGPT-5 pada peringkat latihan yang berbeza, kami menjalankan analisis kuantitatif, dan hasilnya ditunjukkan dalam Rajah 3:

Untuk menunjukkan kebolehgunaan daripada model yang dicadangkan, kami menilainya, meliputi domain visual (metrik berkaitan imej) dan linguistik (metrik teks)
VIST Penilaian Langkah Akhir
set percubaan pertama penilaian langkah, iaitu, imej yang sepadan dijana mengikut model segera dalam langkah terakhir, dan hasilnya ditunjukkan dalam Jadual 1.
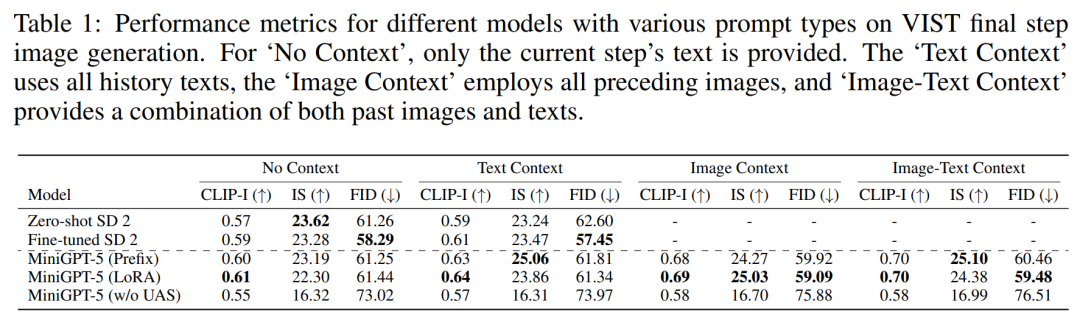 MiniGPT-5 mengatasi prestasi SD 2 yang diperhalusi dalam ketiga-tiga tetapan. Terutama sekali, skor CLIP model MiniGPT-5 (LoRA) secara konsisten mengatasi varian lain merentas pelbagai jenis gesaan, terutamanya apabila menggabungkan gesaan imej dan teks. Sebaliknya, skor FID menyerlahkan daya saing model MiniGPT-5 (Awalan), menunjukkan bahawa mungkin terdapat pertukaran antara kualiti pembenaman imej (dicerminkan oleh skor CLIP) dan kepelbagaian dan ketulenan imej (dicerminkan oleh skor FID). Berbanding dengan model yang dilatih secara langsung pada VIST tanpa memasukkan peringkat pendaftaran mod tunggal (MiniGPT-5 tanpa UAS), walaupun model mengekalkan keupayaan untuk menjana imej yang bermakna, kualiti imej dan konsistensi berkurangan dengan ketara . Pemerhatian ini menonjolkan kepentingan strategi latihan dua peringkat
MiniGPT-5 mengatasi prestasi SD 2 yang diperhalusi dalam ketiga-tiga tetapan. Terutama sekali, skor CLIP model MiniGPT-5 (LoRA) secara konsisten mengatasi varian lain merentas pelbagai jenis gesaan, terutamanya apabila menggabungkan gesaan imej dan teks. Sebaliknya, skor FID menyerlahkan daya saing model MiniGPT-5 (Awalan), menunjukkan bahawa mungkin terdapat pertukaran antara kualiti pembenaman imej (dicerminkan oleh skor CLIP) dan kepelbagaian dan ketulenan imej (dicerminkan oleh skor FID). Berbanding dengan model yang dilatih secara langsung pada VIST tanpa memasukkan peringkat pendaftaran mod tunggal (MiniGPT-5 tanpa UAS), walaupun model mengekalkan keupayaan untuk menjana imej yang bermakna, kualiti imej dan konsistensi berkurangan dengan ketara . Pemerhatian ini menonjolkan kepentingan strategi latihan dua peringkat
VIST Penilaian Pelbagai Langkah
🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 dalam model penilaian yang lebih terperinci dan menyeluruh tentang sistem sejarah penyelidik. konteks, dan imej dan naratif yang terhasil kemudiannya dinilai pada setiap langkah. 🎜🎜
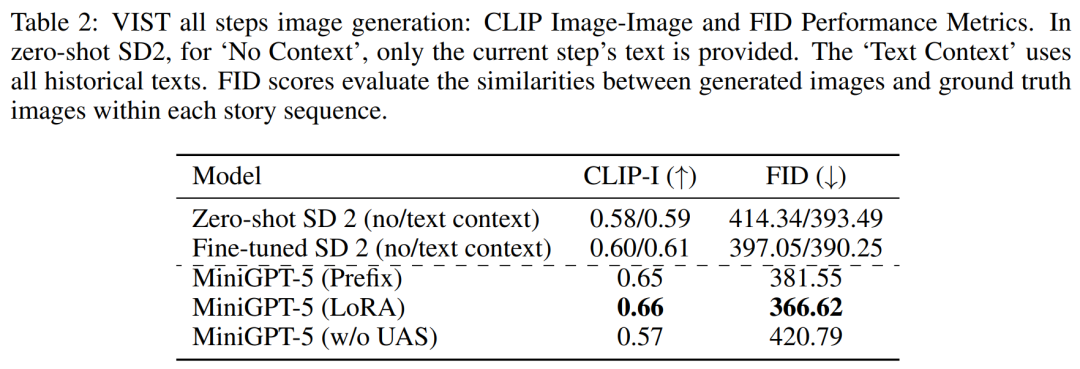
Jadual 2 dan Jadual 3 meringkaskan keputusan eksperimen ini, memberikan gambaran keseluruhan prestasi pada metrik imej dan bahasa masing-masing. Keputusan eksperimen menunjukkan bahawa MiniGPT-5 mampu mengeksploitasi isyarat input berbilang mod peringkat panjang untuk menjana imej berkualiti tinggi yang koheren merentas semua data tanpa menjejaskan keupayaan pemahaman pelbagai mod model asal. Ini menyerlahkan keberkesanan MiniGPT-5 dalam persekitaran yang berbeza

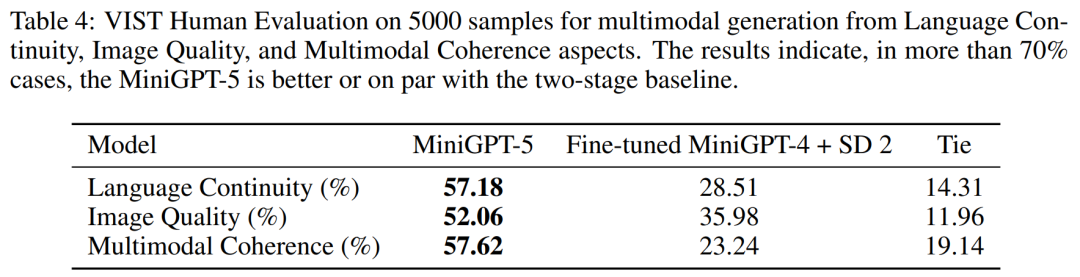
VIST Penilaian Manusia
ditunjukkan dalam Jadual 4. 5 7.18% menjana lebih relevan naratif teks dalam 52.06% kes, memberikan kualiti imej yang lebih baik dalam 52.06% kes, dan menghasilkan output berbilang modal yang lebih koheren dalam 57.62% adegan. Berbanding dengan garis dasar dua peringkat yang menggunakan penceritaan segera teks-ke-imej tanpa mood subjungtif, data ini jelas menunjukkan keupayaan penjanaan pelbagai mod yang lebih kukuh. . Walaupun imej yang dijana mempunyai kualiti yang sama, MiniGPT-5 mengatasi model garis dasar dari segi korelasi MM, menunjukkan bahawa ia lebih berupaya untuk mempelajari cara meletakkan penjanaan imej dengan sewajarnya dan menjana respons pelbagai mod yang sangat konsisten
Mari kita lihat keluaran MiniGPT-5 dan lihat sejauh mana keberkesanannya. Rajah 7 di bawah menunjukkan perbandingan antara MiniGPT-5 dan model garis dasar pada set pengesahan CC3M
 Rajah 8 di bawah menunjukkan perbandingan antara MiniGPT-5 dan model garis dasar pada set pengesahan VIST
Rajah 8 di bawah menunjukkan perbandingan antara MiniGPT-5 dan model garis dasar pada set pengesahan VIST
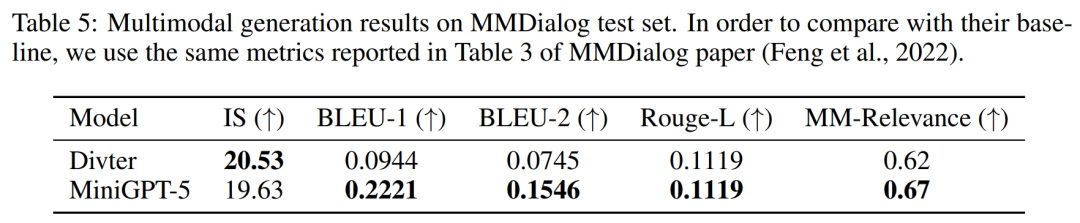
 Rajah 9 di bawah menunjukkan perbandingan antara MiniGPT-5 dan model garis dasar pada set ujian MMDialog.
Rajah 9 di bawah menunjukkan perbandingan antara MiniGPT-5 dan model garis dasar pada set ujian MMDialog.
 Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci MiniGPT-5, yang menyatukan penjanaan imej dan teks, ada di sini: Token menjadi Voken, dan model itu bukan sahaja boleh meneruskan penulisan, tetapi juga menambah gambar secara automatik.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1653
1653
 14
1413
52
1305
25
1251
29
1224
24
14
1413
52
1305
25
1251
29
1224
24

 Gunakan ddrescue untuk memulihkan data pada Linux
Mar 20, 2024 pm 01:37 PM
Gunakan ddrescue untuk memulihkan data pada Linux
Mar 20, 2024 pm 01:37 PM
DDREASE ialah alat untuk memulihkan data daripada fail atau peranti sekat seperti cakera keras, SSD, cakera RAM, CD, DVD dan peranti storan USB. Ia menyalin data dari satu peranti blok ke peranti lain, meninggalkan blok data yang rosak dan hanya memindahkan blok data yang baik. ddreasue ialah alat pemulihan yang berkuasa yang automatik sepenuhnya kerana ia tidak memerlukan sebarang gangguan semasa operasi pemulihan. Selain itu, terima kasih kepada fail peta ddasue, ia boleh dihentikan dan disambung semula pada bila-bila masa. Ciri-ciri utama lain DDREASE adalah seperti berikut: Ia tidak menimpa data yang dipulihkan tetapi mengisi jurang sekiranya pemulihan berulang. Walau bagaimanapun, ia boleh dipotong jika alat itu diarahkan untuk melakukannya secara eksplisit. Pulihkan data daripada berbilang fail atau blok kepada satu
 Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
0. Apakah fungsi artikel ini? Kami mencadangkan DepthFM: model anggaran kedalaman monokular generatif yang serba boleh dan pantas. Sebagai tambahan kepada tugas anggaran kedalaman tradisional, DepthFM juga menunjukkan keupayaan terkini dalam tugas hiliran seperti mengecat kedalaman. DepthFM cekap dan boleh mensintesis peta kedalaman dalam beberapa langkah inferens. Mari kita baca karya ini bersama-sama ~ 1. Tajuk maklumat kertas: DepthFM: FastMonocularDepthEstimationwithFlowMatching Pengarang: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Cara menggunakan fungsi penapis Excel dengan berbilang syarat
Feb 26, 2024 am 10:19 AM
Cara menggunakan fungsi penapis Excel dengan berbilang syarat
Feb 26, 2024 am 10:19 AM
Jika anda perlu tahu cara menggunakan penapisan dengan berbilang kriteria dalam Excel, tutorial berikut akan membimbing anda melalui langkah-langkah untuk memastikan anda boleh menapis dan mengisih data anda dengan berkesan. Fungsi penapisan Excel sangat berkuasa dan boleh membantu anda mengekstrak maklumat yang anda perlukan daripada sejumlah besar data. Fungsi ini boleh menapis data mengikut syarat yang anda tetapkan dan memaparkan hanya bahagian yang memenuhi syarat, menjadikan pengurusan data lebih cekap. Dengan menggunakan fungsi penapis, anda boleh mencari data sasaran dengan cepat, menjimatkan masa dalam mencari dan menyusun data. Fungsi ini bukan sahaja boleh digunakan pada senarai data ringkas, tetapi juga boleh ditapis berdasarkan berbilang syarat untuk membantu anda mencari maklumat yang anda perlukan dengan lebih tepat. Secara keseluruhan, fungsi penapisan Excel adalah sangat berguna
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Menghadapi ketinggalan, sambungan data mudah alih perlahan pada iPhone? Biasanya, kekuatan internet selular pada telefon anda bergantung pada beberapa faktor seperti rantau, jenis rangkaian selular, jenis perayauan, dsb. Terdapat beberapa perkara yang boleh anda lakukan untuk mendapatkan sambungan Internet selular yang lebih pantas dan boleh dipercayai. Betulkan 1 – Paksa Mulakan Semula iPhone Kadangkala, paksa memulakan semula peranti anda hanya menetapkan semula banyak perkara, termasuk sambungan selular. Langkah 1 – Hanya tekan kekunci naikkan kelantangan sekali dan lepaskan. Seterusnya, tekan kekunci Turun Kelantangan dan lepaskannya semula. Langkah 2 - Bahagian seterusnya proses adalah untuk menahan butang di sebelah kanan. Biarkan iPhone selesai dimulakan semula. Dayakan data selular dan semak kelajuan rangkaian. Semak semula Betulkan 2 – Tukar mod data Walaupun 5G menawarkan kelajuan rangkaian yang lebih baik, ia berfungsi lebih baik apabila isyarat lemah
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu
Apr 02, 2024 am 11:31 AM
Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu
Apr 02, 2024 am 11:31 AM
SOTA baharu untuk keupayaan memahami dokumen multimodal! Pasukan Alibaba mPLUG mengeluarkan kerja sumber terbuka terkini mPLUG-DocOwl1.5, yang mencadangkan satu siri penyelesaian untuk menangani empat cabaran utama pengecaman teks imej resolusi tinggi, pemahaman struktur dokumen am, arahan mengikut dan pengenalan pengetahuan luaran. Tanpa berlengah lagi, mari kita lihat kesannya dahulu. Pengecaman satu klik dan penukaran carta dengan struktur kompleks ke dalam format Markdown: Carta gaya berbeza tersedia: Pengecaman dan kedudukan teks yang lebih terperinci juga boleh dikendalikan dengan mudah: Penjelasan terperinci tentang pemahaman dokumen juga boleh diberikan: Anda tahu, "Pemahaman Dokumen " pada masa ini Senario penting untuk pelaksanaan model bahasa yang besar. Terdapat banyak produk di pasaran untuk membantu pembacaan dokumen. Sesetengah daripada mereka menggunakan sistem OCR untuk pengecaman teks dan bekerjasama dengan LLM untuk pemprosesan teks.
 Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Saya menangis hingga mati. Dunia sedang membina model besar. Data di Internet tidak mencukupi. Model latihan kelihatan seperti "The Hunger Games", dan penyelidik AI di seluruh dunia bimbang tentang cara memberi makan data ini kepada pemakan yang rakus. Masalah ini amat ketara dalam tugas berbilang modal. Pada masa mereka mengalami kerugian, pasukan pemula dari Jabatan Universiti Renmin China menggunakan model baharu mereka sendiri untuk menjadi yang pertama di China untuk menjadikan "suapan data yang dijana model itu sendiri" menjadi kenyataan. Selain itu, ia merupakan pendekatan serampang dua mata dari segi pemahaman dan sisi penjanaan Kedua-dua pihak boleh menjana data baharu berbilang modal yang berkualiti tinggi dan memberikan maklum balas data kepada model itu sendiri. Apakah model? Awaker 1.0, model berbilang modal besar yang baru sahaja muncul di Forum Zhongguancun. Siapa pasukan itu? Enjin Sophon. Diasaskan oleh Gao Yizhao, pelajar kedoktoran di Sekolah Kecerdasan Buatan Hillhouse Universiti Renmin.
