

Aplikasi praktikal model cadangan permulaan sejuk kandungan Kuaishou


1. Apakah masalah yang dapat diselesaikan oleh permulaan sejuk Kuaishou?
Dalam jangka pendek, platform mesti terlebih dahulu membolehkan lebih banyak video baharu memperoleh trafik, yang bermaksud ia boleh diedarkan. Pada masa yang sama, trafik yang dihantar mestilah lebih cekap. Dalam jangka panjang, kami juga akan meneroka dan melombong lebih banyak video baharu berpotensi tinggi untuk memberikan lebih banyak darah segar kepada keseluruhan kolam popular dan mengurangkan Kesan Matthew ekologi. Menyediakan lebih banyak kandungan berkualiti tinggi, meningkatkan pengalaman pengguna, dan juga meningkatkan tempoh dan DAU. 
Gunakan permulaan yang dingin untuk mempromosikan pengarang UGC untuk mendapatkan insentif maklum balas interaktif untuk mengekalkan pengekalan keseluruhan pengeluar. Dalam proses ini, terdapat dua kekangan. Pertama, kos penerokaan keseluruhan dan kos trafik sepatutnya stabil dalam gambaran besar. Kedua, kami hanya campur tangan dalam pengedaran video baharu dalam peringkat vv rendah. Jadi, di bawah kekangan ini, bagaimanakah kita memaksimumkan faedah keseluruhan?
Pengedaran video permulaan sejuk memberi impak penting kepada ruang pertumbuhan mereka, terutamanya apabila kerja itu diedarkan kepada orang yang tidak sepadan dengan minat mereka, ia akan memberi dua impak. Pertama sekali, pertumbuhan pengarang akan terjejas Dalam jangka masa panjang, dia tidak akan dapat menerima insentif trafik interaktif yang berkesan, yang akan membawa kepada perubahan dalam arah penyerahan dan kesanggupannya. Kedua, disebabkan kekurangan kadar penukaran yang berkesan dalam trafik awal, sistem akan menganggap kandungannya berkualiti rendah Oleh itu, dalam jangka panjang, ia tidak akan dapat memperoleh sokongan trafik yang mencukupi dan dengan itu tidak dapat mencapai pertumbuhan
Jika keadaan berterusan seperti ini, ekosistem akan jatuh ke dalam perbandingan Keadaan yang buruk. Contohnya, jika ada karya tentang makanan tempatan, ia mesti mempunyai kumpulan penonton A yang paling sesuai, dan kadar aksi keseluruhannya adalah yang tertinggi. Di samping itu, mungkin terdapat kumpulan orang yang tidak berkaitan sama sekali C. Apabila mengundi untuk kumpulan orang ini, akan terdapat tahap selektiviti tertentu, dan kadar tindakan mungkin sangat rendah. Sudah tentu, terdapat juga jenis ketiga kumpulan B, iaitu kumpulan yang mempunyai minat yang sangat luas Walaupun kumpulan orang ini mempunyai aliran yang besar, kadar tindakan keseluruhan kumpulan orang ini akan menjadi rendah.
Jika kita boleh mencapai kumpulan teras A seawal mungkin untuk meningkatkan kadar interaksi awal kandungan, kita boleh menghasilkan pengedaran trafik semula jadi yang memanfaatkan. Tetapi jika kita memberi terlalu banyak trafik kepada kumpulan C atau kumpulan B pada peringkat awal, ia akan membawa kepada kadar tindakan keseluruhan yang rendah dan mengehadkan pertumbuhannya. Secara keseluruhannya, meningkatkan kecekapan pengedaran permulaan sejuk ialah cara paling penting untuk mencapai pertumbuhan kandungan. Untuk melengkapkan lelaran kecekapan permulaan sejuk kandungan, kami akan mewujudkan beberapa penunjuk proses perantaraan dan penunjuk jangka panjang akhir.
Kandungan yang ditulis semula ialah: Penunjuk proses terutamanya dibahagikan kepada dua bahagian Satu bahagian ialah prestasi penggunaan video baharu, terutamanya termasuk kadar tindakan trafiknya, termasuk arah penerokaan, orientasi penggunaan dan orientasi ekologi. Arah penerokaan adalah untuk memastikan video baharu berkualiti tinggi tidak diabaikan, terutamanya memerhatikan pertumbuhan bilangan video dengan dedahan lebih daripada 0 dan dedahan lebih daripada 100. Gunakan Xiangxiang untuk melihat pertumbuhan dalam bilangan video VV tinggi yang popular dan video baharu berkualiti tinggi. Arah ekologi terutamanya memerhatikan kadar penembusan pengguna kolam popular. Dalam jangka panjang, memandangkan ini adalah perubahan jangka panjang yang disebabkan oleh kesan ekologi, akhirnya kami akan menggunakan eksperimen Combo untuk memerhatikan perubahan arah aliran beberapa petunjuk teras dalam jangka panjang, termasuk tempoh APP, DAU pengarang dan DAU keseluruhan
2. Cabaran dan Penyelesaian untuk Permodelan Permulaan Dingin
Secara amnya, terdapat tiga kesukaran utama dengan permulaan kandungan yang sejuk. Pertama, terdapat perbezaan yang besar antara ruang sampel permulaan sejuk kandungan dan ruang penyelesaian sebenar. Kedua, sampel permulaan sejuk kandungan adalah sangat jarang, yang akan membawa kepada hasil pembelajaran yang tidak tepat dan penyelewengan yang sangat besar, terutamanya dari segi bias pendedahan. Ketiga, memodelkan nilai pertumbuhan video juga merupakan satu kesukaran, yang juga merupakan masalah yang sedang kami berusaha keras untuk menyelesaikannya. Artikel ini akan memberi tumpuan kepada kesukaran dalam dua aspek pertama
1 Masalahnya ruang sampel jauh lebih kecil daripada ruang penyelesaian sebenar
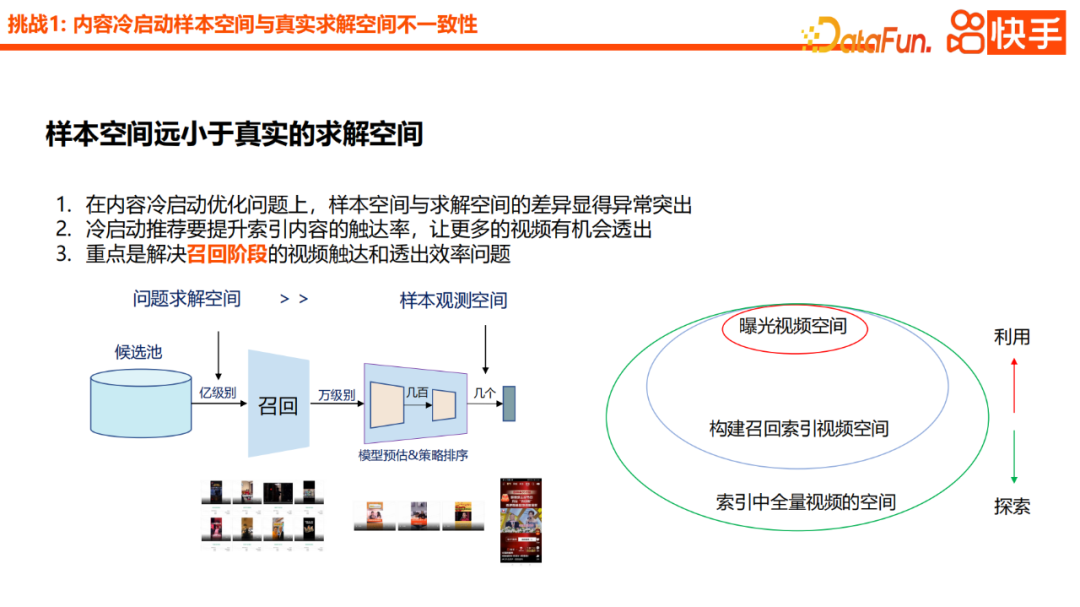
#🎜. 🎜# adalah mengoptimumkan kandungan Apabila ia datang kepada masalah permulaan sejuk, adalah masalah yang sangat ketara bahawa ruang sampel lebih kecil daripada ruang penyelesaian. Terutama dari segi permulaan sejuk kandungan yang disyorkan, adalah perlu untuk meningkatkan kadar capaian kandungan diindeks supaya lebih banyak video berpeluang untuk dipaparkan
Kami fikir kami perlu menyelesaikan masalah ini, perkara yang paling penting ialah meningkatkan kecekapan jangkauan dan pendedahan video semasa peringkat ingat semula. Untuk menyelesaikan kadar capaian ingat video mula sejuk. Pendekatan biasa dalam industri adalah berdasarkan Berasaskan Kandungan, termasuk penyongsangan atribut, beberapa kaedah ingat semula berdasarkan persamaan semantik, atau model ingat semula berdasarkan menara berkembar serta ciri generalisasi, atau pengenalan pemetaan antara ruang tingkah laku dan ruang kandungan, serupa kepada Berdasarkan pendekatan CB2CF.
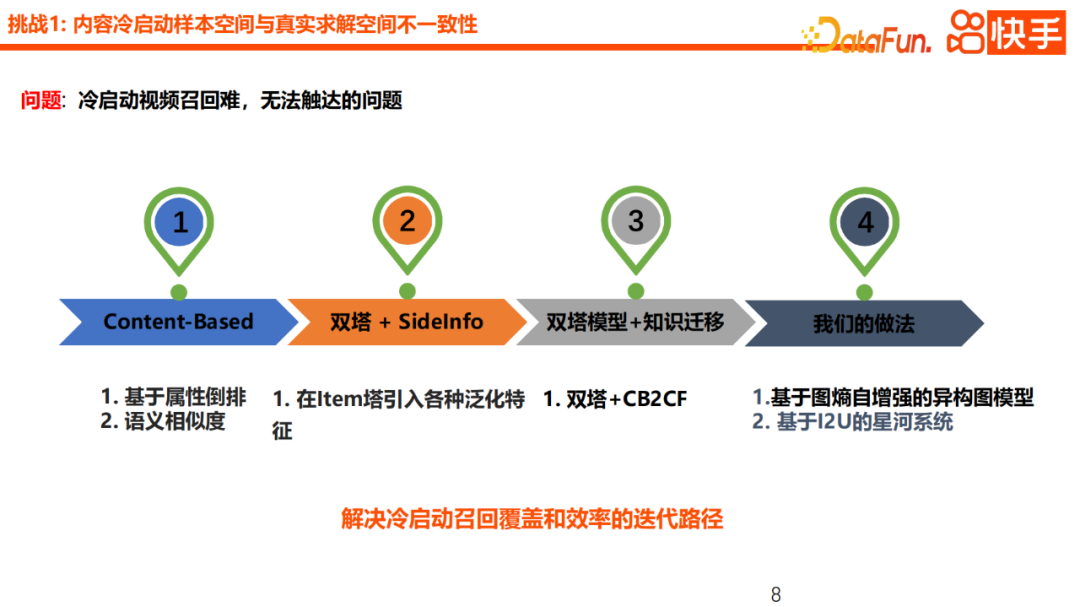
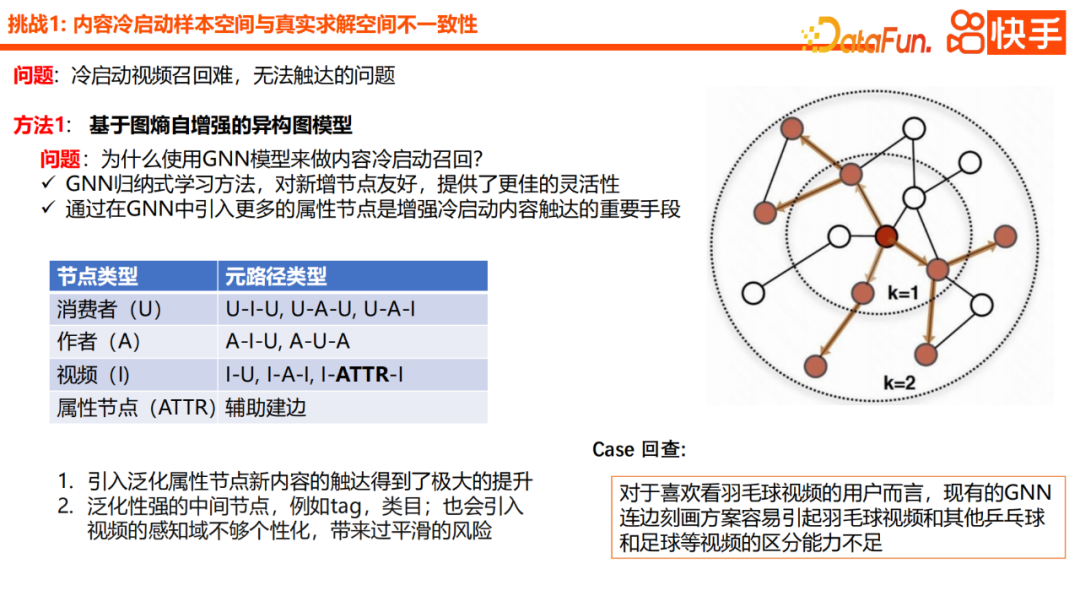
Kali ini kita akan fokus pada dua lagi menarik Kaedah baharu ialah rangkaian graf heterogen berdasarkan peningkatan diri entropi graf dan model galaksi berdasarkan I2U. Dari segi pemilihan teknologi, kami mula-mula menggunakan GNN sebagai model asas untuk kandungan mula sejuk U2I. Kerana kami menganggap bahawa GNN ialah kaedah pembelajaran induktif secara keseluruhan, ia sangat mesra kepada nod baharu dan memberikan lebih fleksibiliti. Di samping itu, GNN memperkenalkan lebih banyak nod atribut, yang merupakan cara penting untuk meningkatkan akses kandungan permulaan sejuk. Dari segi amalan khusus, kami juga akan memperkenalkan nod pengguna, nod pengarang dan nod item serta melengkapkan pengagregatan maklumat. Selepas pengenalan nod atribut umum ini, kadar capaian keseluruhan kandungan baharu telah dipertingkatkan dengan ketara. Walau bagaimanapun, nod perantaraan yang terlalu umum, seperti kategori teg, juga akan menyebabkan domain persepsi video tidak diperibadikan dengan secukupnya, membawa risiko pelicinan berlebihan. Daripada semakan kes, kami mendapati bahawa bagi sesetengah pengguna yang suka menonton video badminton, skema pencirian GNN sedia ada boleh menyebabkan perbezaan yang lemah antara video badminton dan video pingpong, bola sepak dan video lain.
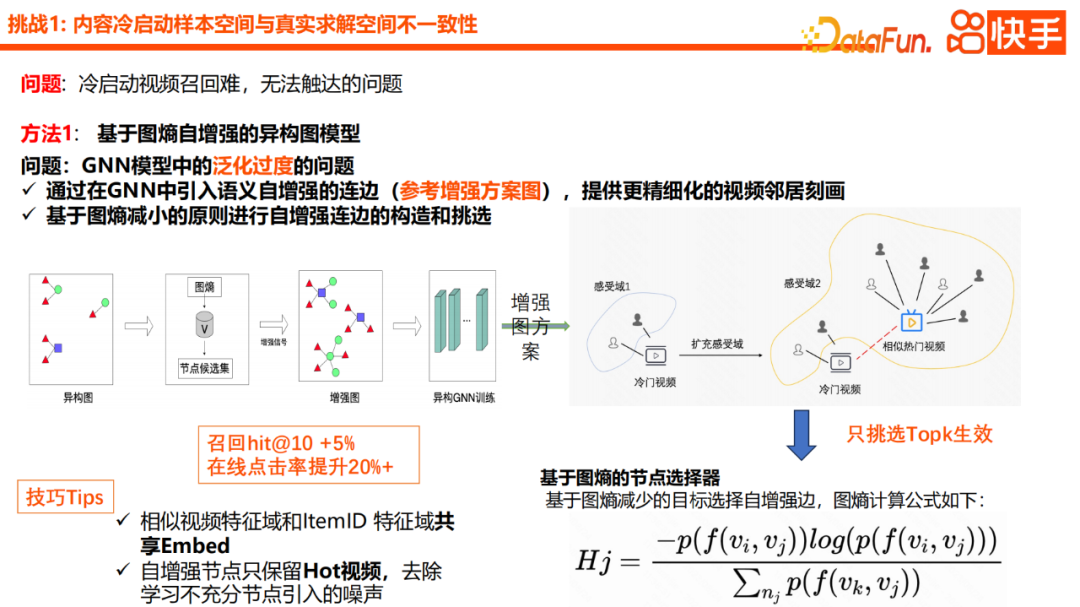
Untuk menyelesaikan masalah terlalu generalisasi yang disebabkan oleh memperkenalkan terlalu banyak maklumat generalisasi dalam proses pemodelan GNN, kami Idea utama adalah untuk memperkenalkan skema pencirian jiran yang lebih terperinci, khususnya memperkenalkan tepi peningkatan diri semantik ke dalam GNN. Seperti yang anda boleh lihat daripada gambar di penjuru kanan sebelah bawah, kami akan menggunakan video yang tidak popular untuk mencari video popularnya yang serupa dalam ruang popular, dan kemudian menggunakan video serupa yang popular sebagai nod awal sambungan mula sejuk. Dalam proses pengagregatan khusus, kami akan membina dan memilih tepi tetulang sendiri berdasarkan prinsip pengurangan entropi graf. Pelan pemilihan khusus boleh dilihat daripada formula, yang mengambil kira perihalan di atas tentang nod jiran yang disambungkan dan maklumat nod semasa. Jika persamaan antara dua nod lebih tinggi, entropi maklumat mereka akan menjadi lebih kecil. Penyebut nod di bawah mewakili domain persepsi keseluruhan nod jiran Ia juga boleh difahami bahawa dalam proses pemilihan, kami lebih suka mencari nod jiran dengan persepsi yang lebih kuat
#. 🎜 🎜#Dalam amalan, kami terutamanya mempunyai dua teknik Satu ialah domain ciri video yang serupa dan domain ciri id item harus berkongsi ruang pembenaman, dan kemudian nod peningkatan diri hanya mengekalkan video popular untuk mengeluarkan bunyi yang diperkenalkan. oleh nod pembelajaran yang tidak mencukupi. Dengan peningkatan ini, generalisasi keseluruhan dijamin sepenuhnya, yang meningkatkan tahap pemperibadian model dengan berkesan dan menghasilkan kesan luar talian dan dalam talian yang lebih baik.Kaedah di atas sebenarnya adalah penambahbaikan dalam pemodelan jangkauan kandungan dari perspektif U2I, tetapi mereka tidak dapat menyelesaikan masalah video yang tidak dapat dicapai#🎜🎜 ##🎜🎜 #
Jika anda mengubah pemikiran anda dan mencari orang yang betul dari perspektif item, iaitu beralih kepada perspektif I2U, secara teorinya Setiap video mempunyai ruang untuk mendapatkan trafik. 
Pendekatan khusus ialah kami perlu melatih perkhidmatan mendapatkan semula I2U dan menggunakan perkhidmatan mendapatkan semula ini untuk mendapatkan semula kumpulan yang berminat secara dinamik untuk setiap video. Melalui kaedah gubahan I2U ini, indeks terbalik U2I dibina secara terbalik, dan akhirnya senarai item dikembalikan sebagai senarai cadangan permulaan sejuk mengikut permintaan masa nyata pengguna
#🎜 🎜##🎜🎜 #
#🎜🎜 #
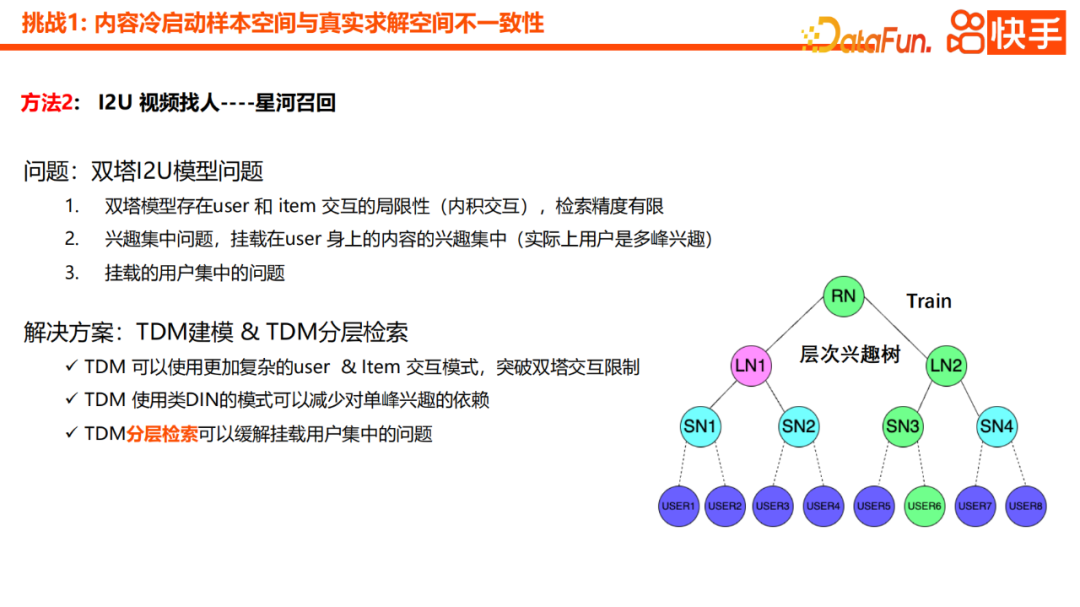 Versi pertama amalan kami ialah model I2U menara berkembar, dan beberapa masalah turut ditemui semasa latihan. Pertama sekali, model dua menara mempunyai had dalam interaksi antara pengguna dan item, dan ketepatan pengambilan keseluruhan adalah terhad. Di samping itu, terdapat juga masalah penumpuan minat Kandungan yang dipasang pada pengguna selalunya mempunyai minat yang sangat tertumpu, tetapi sebenarnya minat pengguna diedarkan secara pelbagai. Kami juga mendapati masalah pengguna yang terlalu tertumpu Kebanyakan video permulaan sejuk dipasang pada beberapa pengguna teratas Ini tidak munasabah kerana lagipun, kandungan yang boleh digunakan oleh pengguna teratas setiap hari juga terhad
Versi pertama amalan kami ialah model I2U menara berkembar, dan beberapa masalah turut ditemui semasa latihan. Pertama sekali, model dua menara mempunyai had dalam interaksi antara pengguna dan item, dan ketepatan pengambilan keseluruhan adalah terhad. Di samping itu, terdapat juga masalah penumpuan minat Kandungan yang dipasang pada pengguna selalunya mempunyai minat yang sangat tertumpu, tetapi sebenarnya minat pengguna diedarkan secara pelbagai. Kami juga mendapati masalah pengguna yang terlalu tertumpu Kebanyakan video permulaan sejuk dipasang pada beberapa pengguna teratas Ini tidak munasabah kerana lagipun, kandungan yang boleh digunakan oleh pengguna teratas setiap hari juga terhad
Untuk menyelesaikan tiga masalah di atas, penyelesaian baharu ialah pemodelan TDM dan kaedah pengambilan hierarki TDM. Satu faedah TDM ialah ia boleh memperkenalkan mod interaksi item pengguna yang lebih kompleks dan menembusi batasan interaksi Menara Berkembar. Yang kedua ialah menggunakan corak seperti DIN yang mengurangkan pergantungan pada minat unimodal. Akhir sekali, pengenalan pengambilan semula hierarki dalam TDM dapat mengurangkan masalah penumpuan pengguna yang dipasang dengan sangat berkesan.
Selain itu, kami mempunyai titik pengoptimuman yang lebih berkesan, iaitu menambah perwakilan agregat nod keturunan kepada nod induk. Ini boleh meningkatkan ketepatan generalisasi ciri dan diskriminasi nod induk. Dalam erti kata lain, kami akan mengagregatkan nod anak kepada nod induk melalui mekanisme perhatian, dan melalui pemindahan lapisan demi lapisan, nod perantaraan juga boleh mempunyai keupayaan generalisasi semantik tertentu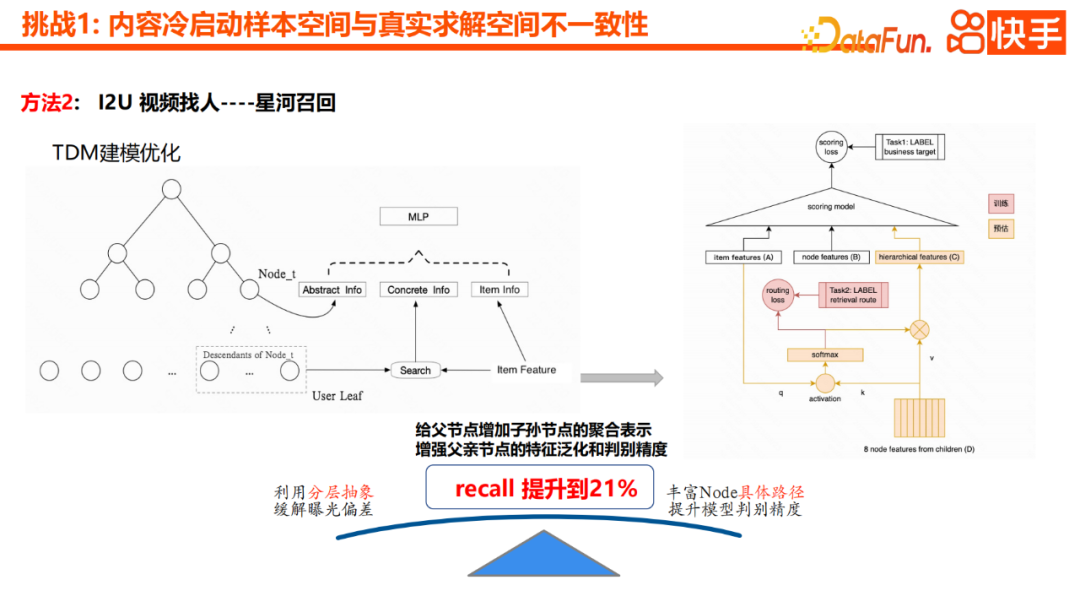
#🎜 🎜 #
Dalam amalan sistem akhir, sebagai tambahan kepada model I2U, kami juga memperkenalkan modul pengembangan minat U2U. Maksudnya, jika sesetengah pengguna menunjukkan prestasi yang baik dalam video permulaan sejuk, kami akan menyebarkan video dengan cepat
Kaedah khusus adalah serupa dengan beberapa kaedah dalam industri semasa , tetapi Modul pengembangan minat U2U di sini mempunyai tiga kelebihan utama. Pertama sekali, struktur pokok TDM agak kukuh, dan menambah modul U2U ini boleh menjadi lebih dekat dengan pilihan masa nyata pengguna. Kedua, melalui penyebaran minat masa nyata, kami boleh menembusi batasan model dan mempromosikan kandungan dengan cepat melalui kerjasama pengguna, membawa peningkatan kepelbagaian. Akhirnya, ini juga boleh meningkatkan liputan keseluruhan penarikan semula Galaxy Ini adalah beberapa perkara pengoptimuman yang telah kami buat semasa latihan 🎜#Melalui penyelesaian ini, kami boleh menyelesaikan masalah ketidakkonsistenan antara ruang sampel dan ruang penyelesaian sebenar dalam kandungan sejuk. mula, dengan itu meningkatkan dengan ketara jangkauan dan kesan liputan permulaan sejuk
#🎜 🎜#2 Sampel permulaan sejuk pembelajaran jarang adalah tidak tepat dan mempunyai sisihan yang besar.
Seterusnya, kami akan memperkenalkan masalah sampel permulaan sejuk yang jarang membawa kepada pembelajaran yang tidak tepat dan penyelewengan yang besar. Intipati masalah ini adalah keterlaluan tingkah laku interaksi Kami mengembangkan masalah kepada tiga arah.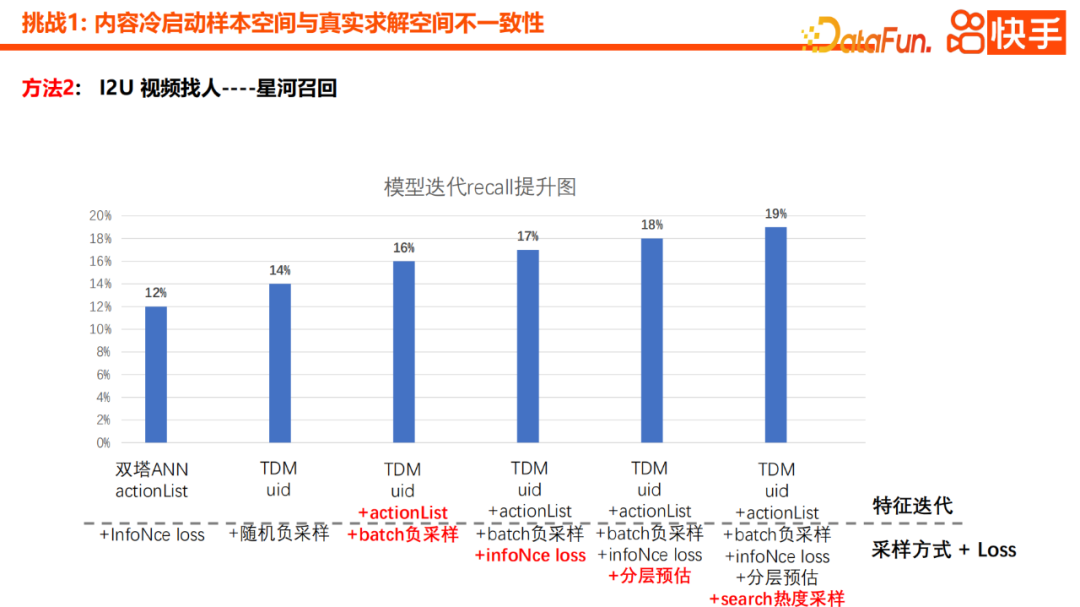
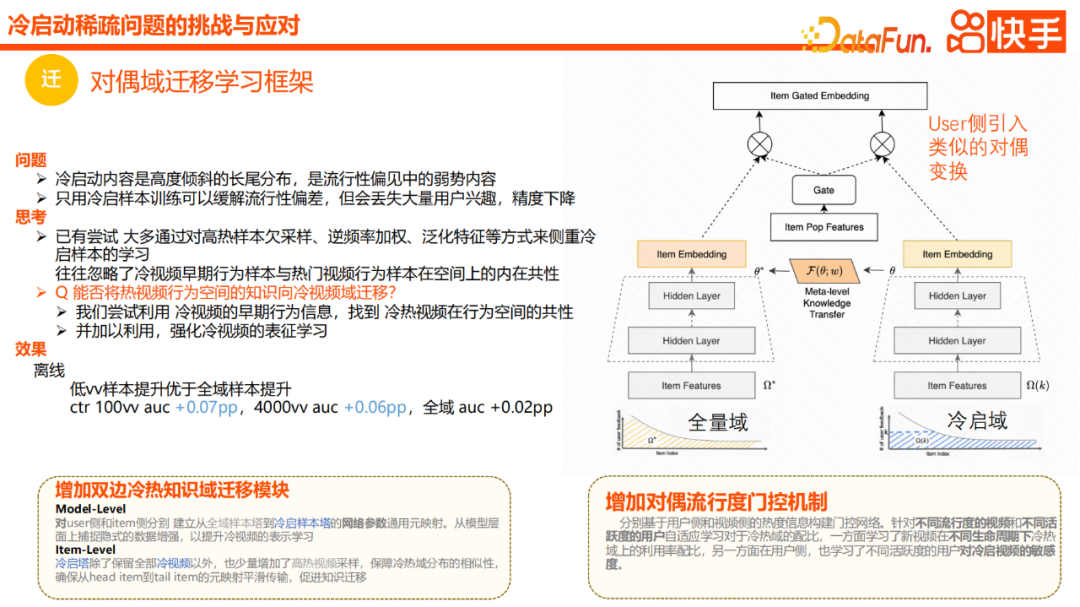
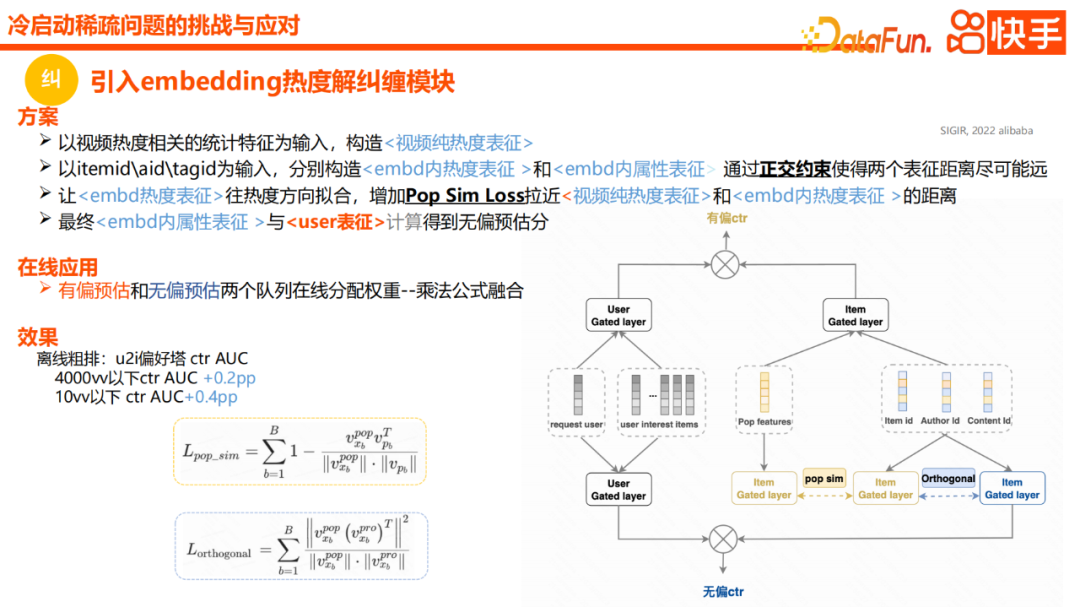
Pertama sekali, disebabkan oleh kurang pendedahan sampel permulaan sejuk, pembelajaran id item tidak mencukupi, yang seterusnya menjejaskan kesan pengesyoran dan kecekapan pengesyoran. Kedua, terdapat ketidakpastian yang tinggi dan keyakinan rendah dalam label yang dikumpul disebabkan oleh ketidaktepatan dalam pengedaran awal. Ketiga, paradigma latihan semasa akan memperkenalkan maklumat populariti ke dalam pembenaman item tanpa pembetulan, menyebabkan video permulaan sejuk dipandang rendah dan dengan itu tidak dapat diedarkan sepenuhnya Kami terutamanya pergi dari empat arah Selesaikan masalah ini. Yang pertama ialah generalisasi, yang kedua ialah pemindahan, yang ketiga ialah penerokaan, dan yang keempat ialah pembetulan. Generalisasi lebih kepada melengkapkan pemodelan dan menaik taraf daripada perspektif ciri umum. Tujuan utama penghijrahan adalah untuk menganggap video tidak popular dan popular sebagai dua domain, dan memindahkan maklumat secara berkesan daripada domain video popular atau domain maklumat penuh untuk membantu pembelajaran video tidak popular. Penerokaan terutamanya memperkenalkan idea penerokaan dan penggunaan, iaitu, apabila label awal tidak tepat, kami berharap dapat memperkenalkan idea penerokaan dalam proses pemodelan, dengan itu mengurangkan kesan negatif ketidakpercayaan pada label semasa sejuk peringkat permulaan. Pembetulan populariti pada masa ini menjadi trend hangat Kami mengehadkan penggunaan maklumat populariti melalui gating dan kehilangan biasa. Berikut adalah pengenalan terperinci kepada kerja kami. Pertama sekali, generalisasi adalah kaedah yang sangat biasa apabila menyelesaikan masalah permulaan sejuk. Walau bagaimanapun, dalam amalan kami mendapati bahawa ia juga sangat berguna untuk memperkenalkan beberapa pembenaman semantik berbanding dengan label dan kategori. Walau bagaimanapun, faedah menambah ciri semantik secara langsung pada model keseluruhan adalah terhad. Memandangkan terdapat perbezaan antara ruang semantik video dan ruang tingkah laku, bolehkah kita mewakili kedudukan video baharu dalam ruang tingkah laku melalui maklumat umum semantik video untuk membantu generalisasi. Kami menyebut beberapa kaedah sebelum ini, seperti CB2CF, yang belajar untuk memetakan maklumat generalisasi ke ruang tingkah laku sebenar. Walau bagaimanapun, daripada mengikuti pendekatan ini, kami mencari senarai item yang serupa dengan item sasaran berdasarkan vektor semantik video. Pertama, ia berkongsi ruang tingkah laku dengan gelagat minat jangka panjang dan jangka pendek pengguna, dan kami mengagregatkan senarai item yang serupa untuk mensimulasikan perwakilan video calon dalam ruang tingkah laku. Malah, kaedah ini adalah serupa dengan kaedah memperkenalkan tepi serupa dengan calon dalam ingatan graf yang kami nyatakan sebelum ini, dan kesannya sangat jelas, meningkatkan AUC luar talian sebanyak 0.35PP Kedua Pertama ialah penerokaan , iaitu, pengedaran awal video baharu yang tidak tepat akan membawa kepada min CTR posterior yang rendah, dan min yang rendah ini juga akan menyebabkan model percaya bahawa video itu sendiri mungkin berkualiti rendah, akhirnya mengehadkan kebolehjelajahan kandungan mula sejuk. Jadi bolehkah kita memodelkan ketidakpastian PCTR dan memperlahankan penggunaan mutlak dan kepercayaan label dalam peringkat permulaan yang sejuk. Kami cuba menukar anggaran CTR permintaan kepada anggaran teragih beta, menggunakan kedua-dua jangkaan dan varians dalam talian. Secara khusus, dalam amalan, kami akan menganggarkan α dan β taburan Beta Secara khusus, reka bentuk kerugian ialah nilai jangkaan bagi ralat kuasa dua bagi nilai anggaran dan label sebenar. Selepas kita mengembangkan nilai jangkaan, kita akan mendapati bahawa kita perlu mendapatkan jangkaan kuasa dua nilai anggaran dan jangkaan nilai anggaran. Kami boleh mengira kedua-dua nilai ini dengan berkesan melalui anggaran α dan β, dan kerugian dijana Kemudian kami boleh melatih pengagihan Beta, dan akhirnya menambah baris gilir pada anggaran nilai pengagihan Beta untuk mengimbangi penerokaan dan penggunaan. . Malah, apabila kita menggunakan kehilangan Beta pada peringkat vv rendah, terdapat peningkatan tertentu dalam AUC, tetapi ia tidak begitu ketara. Tetapi apabila kami menggunakan pengedaran beta dalam talian, kadar penembusan berkesan kandungan 0vv meningkat sebanyak 22% manakala kadar tindakan keseluruhan kekal sama. Pengenalan seterusnya ialah rangka kerja pembelajaran pemindahan domain dwi. Idea keseluruhannya ialah kandungan permulaan dingin selalunya merupakan pengedaran ekor panjang yang sangat condong dan juga merupakan kumpulan yang terdedah dalam kecenderungan populariti. Jika kita hanya menggunakan sampel permulaan sejuk, kecenderungan populariti boleh dikurangkan pada tahap tertentu, tetapi sejumlah besar minat pengguna akan hilang, mengakibatkan penurunan ketepatan keseluruhan. Kebanyakan percubaan semasa kami menumpukan pada pembelajaran sampel permulaan sejuk melalui beberapa sampel terkurang sampel panas, atau ciri pemberat frekuensi songsang atau generalisasi, tetapi mereka sering mengabaikan sampel tingkah laku permulaan sejuk awal Terdapat persamaan yang wujud dalam ruang tingkah laku dengan video popular. Jadi semasa proses reka bentuk, kami akan membahagikan sampel penuh dan sampel mula sejuk kepada dua domain, iaitu domain isipadu penuh dan domain mula sejuk dalam gambar di atas Domain isipadu penuh berkesan untuk semua sampel, dan domain permulaan sejuk hanya untuk permulaan sejuk Hanya sampel bersyarat akan berkuat kuasa, dan kemudian modul penghijrahan domain pengetahuan panas dan sejuk dua hala akan ditambahkan. Khususnya, pengguna dan item dimodelkan secara berasingan, dan pemetaan rangkaian dilakukan daripada menara sampel global ke menara sampel permulaan sejuk, dengan itu menangkap peningkatan data tersirat pada peringkat model dan meningkatkan perwakilan video permulaan sejuk. Di bahagian item, kami akan mengekalkan semua sampel permulaan sejuk Selain itu, kami juga akan mencuba beberapa video panas berdasarkan pendedahan untuk memastikan persamaan pengedaran domain panas dan sejuk, dan akhirnya memastikan pemindahan pengetahuan yang lancar bagi keseluruhan pemetaan. Selain itu, kami juga telah menambah mekanisme dwi populariti gating yang unik, memperkenalkan beberapa ciri populariti dan menggunakannya untuk membantu nisbah gabungan domain video panas dan sejuk. Di satu pihak, nisbah penggunaan ungkapan permulaan sejuk bagi video baharu di bawah kitaran hayat yang berbeza boleh dipelajari dan diedarkan dengan berkesan. Sebaliknya, pihak pengguna juga mempelajari sensitiviti pengguna aktif yang berbeza terhadap video mula sejuk. Dalam amalan, kesan luar talian telah dipertingkatkan pada tahap tertentu dalam kedua-dua peringkat vv rendah dan AUC 4000vv. Akhir sekali, saya akan memperkenalkan kerja pembetulan iaitu pembetulan haba. Sistem pengesyoran sering menghadapi kecenderungan populariti, dan secara amnya merupakan karnival produk letupan tinggi. Matlamat pemasangan paradigma model sedia ada ialah CTR global Mengesyorkan item popular mungkin menyebabkan kerugian keseluruhan yang lebih rendah, tetapi ia juga akan menyuntik beberapa maklumat popular ke dalam pembenaman item, menyebabkan video yang sangat popular menjadi terlalu tinggi. Sesetengah kaedah sedia ada terlalu mengejar anggaran yang tidak berat sebelah, tetapi sebenarnya ia akan membawa kepada beberapa kerugian penggunaan. Jadi bolehkah kita mengasingkan beberapa pembenaman item daripada maklumat populariti dan maklumat minat sebenar, dan menggunakan maklumat populariti dan maklumat minat untuk gabungan dalam talian Ini mungkin kaedah yang lebih munasabah? Dalam amalan khusus, kami merujuk kepada beberapa amalan rakan sebaya kami Tumpuan terutamanya pada dua modul Satu adalah untuk membuat kekangan ortogon pada populariti dan minat kandungan input, seperti input id item. , id pengarang, dsb. Ciri akan menjana dua perwakilan Satu daripada dua perwakilan ini ialah perwakilan populariti dan satu lagi ialah perwakilan minat sebenar Kekangan biasa akan dibuat semasa proses penyelesaian. Yang kedua ialah kami juga akan menjana pembenaman maklumat haba tulen beberapa item kerana perwakilan haba tulen video tersebut akan membuat kekangan persamaan berdasarkan perwakilan haba sebenar video, supaya kami boleh dapatkan perwakilan haba yang baru disebut dan perwakilan minat, satu daripadanya menyatakan maklumat populariti, dan satu lagi menyatakan maklumat minat. Akhir sekali, berdasarkan dua perwakilan ini, baris gilir anggaran berat sebelah dan anggaran tidak berat sebelah akan ditambah dalam talian untuk gabungan formula pendaraban. Akhir sekali, izinkan saya berkongsi pandangan saya tentang kerja masa depan. Pertama sekali, kita perlu memodelkan dan menggunakan model penyebaran khalayak dengan lebih tepat, terutamanya dalam masa nyata, termasuk penyebaran khalayak yang sama semasa. Kami telah pun melaksanakan beberapa skim resapan ramai yang serupa dalam fasa permulaan sejuk, seperti aplikasi resapan U2U, dan kami berharap dapat meningkatkan lagi penghalusannya Yang kedua ialah skema pembetulan Model penyebab semasa membetulkan penyelewengan dalam permulaan sejuk Terdapat juga banyak penyelidikan di China, dan kami akan terus melakukan penyelidikan dan penerokaan ke arah ini, terutamanya untuk pembetulan pendedahan, dan pembetulan haba Yang ketiga adalah dalam pemilihan sampel permulaan sampel haba tinggi masih Jika ia mempunyai nilai yang lebih besar, bolehkah kita memilih beberapa sampel yang lebih berharga dalam ruang sampel panas dan memberi mereka pemberat yang berbeza untuk meningkatkan kecekapan pengesyoran model permulaan sejuk. Yang ketiga ialah pencirian nilai pertumbuhan jangka panjang bagi setiap video perlu melalui proses permulaan-pertumbuhan-kestabilan-penurunan , iaitu pertumbuhan, apabila memodelkan video Ruang, terutamanya dari segi memanfaatkan nilai, bagaimana untuk memodelkan perbezaan nilai pengagihan tunggal yang berbeza untuk pertumbuhan masa depan juga merupakan kerja yang sangat menarik. Yang terakhir ialah penyelesaian melalui peningkatan data Sama ada ia adalah penyelesaian sampel atau pembelajaran perbandingan, kami berharap dapat memperkenalkan beberapa kerja dalam bidang ini untuk meningkatkan kecekapan pengesyoran permulaan dingin. A1: Model I2U akan terus mencari pengguna yang paling serupa dalam pustaka indeks semasa proses luar talian, dan kemudian mengelaskannya berdasarkan pengguna dan item yang paling serupa Ditemui. Tukar kepada pasangan item pengguna, dan akhirnya dapatkan hasil pengagregatan senarai item pengguna, dan simpan dalam Redis untuk kegunaan dalam talian Di satu pihak, cara untuk mengelakkan kandungan pengepala daripada terlalu panas dan perkadaran sampel terlalu tinggi , menyebabkan tolakan menjadi lebih pekat Adakah terdapat sebarang kaedah? S3: Bagaimanakah kadar populariti kumpulan popular dikira secara khusus? 


3. Tinjauan Masa Depan

4. Sesi Soal Jawab
S1: Permintaan dalam talian adalah berbutiran pengguna.
A2: Beberapa kaedah telah disebutkan dalam perkongsian, kami masih menyelesaikannya dari perspektif generalisasi, penerokaan dan pembetulan. Sebagai contoh, cara untuk memulakan id item supaya ia mempunyai titik permulaan yang lebih baik, dan pada masa yang sama memperkenalkan beberapa ciri umum untuk memetakan ciri umum kepada ruang semantik tingkah laku. Kemudian gunakan pengedaran Beta untuk meningkatkan kebolehjelajahan; dan memperkenalkan menara kandungan tulen untuk mengalih keluar ciri dengan ingatan yang kuat seperti pid, dengan itu memperkenalkan anggaran generalisasi tulen tanpa berat sebelah haba, dan kerja pembetulan, dengan harapan dapat meningkatkan pembelajaran Dalam proses itu, faktor populariti dipelajari dan dikekang secara berasingan, standard minat tulen dan standard populariti disediakan, dan intensiti penggunaan standard populariti diedarkan secara munasabah dalam talian. Sudah tentu, sebagai tambahan kepada kaedah ini, kami juga cuba mengurangkan kekurangan kandungan permulaan sejuk melalui peningkatan data, dan menggunakan kandungan popular untuk membantu dalam pembelajaran kandungan permulaan sejuk dari perspektif pembelajaran pemindahan.
A3: Kadar pengoptimuman sebenarnya adalah tugas dengan tahap penyertaan manual yang sangat tinggi. Adalah mustahil untuk kami menggunakan model sepenuhnya untuk menilai kadar pengoptimuman sebuah video. Jika kita boleh menggunakan model untuk menilai sekeping kandungan, seperti video dengan 50,000 pendedahan, penyertaan manual akan terlibat dalam keseluruhan kandungan berkualiti tinggi, dan ia pasti akan didesak kepada pengulas untuk menyemak mana yang tinggi- video berkualiti.
Atas ialah kandungan terperinci Aplikasi praktikal model cadangan permulaan sejuk kandungan Kuaishou. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Saya cuba pengekodan getaran dengan kursor AI dan ia menakjubkan!
Mar 20, 2025 pm 03:34 PM
Pengekodan Vibe membentuk semula dunia pembangunan perisian dengan membiarkan kami membuat aplikasi menggunakan bahasa semulajadi dan bukannya kod yang tidak berkesudahan. Diilhamkan oleh penglihatan seperti Andrej Karpathy, pendekatan inovatif ini membolehkan Dev
 Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 Genai dilancarkan pada Februari 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Februari 2025 telah menjadi satu lagi bulan yang berubah-ubah untuk AI generatif, membawa kita beberapa peningkatan model yang paling dinanti-nantikan dan ciri-ciri baru yang hebat. Dari Xai's Grok 3 dan Anthropic's Claude 3.7 Sonnet, ke Openai's G
 Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?
Mar 22, 2025 am 11:07 AM
Yolo (anda hanya melihat sekali) telah menjadi kerangka pengesanan objek masa nyata yang terkemuka, dengan setiap lelaran bertambah baik pada versi sebelumnya. Versi terbaru Yolo V12 memperkenalkan kemajuan yang meningkatkan ketepatan
 Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Artikel ini mengkaji semula penjana seni AI atas, membincangkan ciri -ciri mereka, kesesuaian untuk projek kreatif, dan nilai. Ia menyerlahkan Midjourney sebagai nilai terbaik untuk profesional dan mengesyorkan Dall-E 2 untuk seni berkualiti tinggi dan disesuaikan.
 Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4 kini tersedia dan digunakan secara meluas, menunjukkan penambahbaikan yang ketara dalam memahami konteks dan menjana tindak balas yang koheren berbanding dengan pendahulunya seperti ChATGPT 3.5. Perkembangan masa depan mungkin merangkumi lebih banyak Inter yang diperibadikan
 AI mana yang lebih baik daripada chatgpt?
Mar 18, 2025 pm 06:05 PM
AI mana yang lebih baik daripada chatgpt?
Mar 18, 2025 pm 06:05 PM
Artikel ini membincangkan model AI yang melampaui chatgpt, seperti Lamda, Llama, dan Grok, menonjolkan kelebihan mereka dalam ketepatan, pemahaman, dan kesan industri. (159 aksara)
 Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Artikel ini membincangkan pembantu penulisan AI terkemuka seperti Grammarly, Jasper, Copy.ai, WriteSonic, dan Rytr, yang memberi tumpuan kepada ciri -ciri unik mereka untuk penciptaan kandungan. Ia berpendapat bahawa Jasper cemerlang dalam pengoptimuman SEO, sementara alat AI membantu mengekalkan nada terdiri
 Cara Menggunakan Mistral OCR untuk Model RAG Seterusnya
Mar 21, 2025 am 11:11 AM
Cara Menggunakan Mistral OCR untuk Model RAG Seterusnya
Mar 21, 2025 am 11:11 AM
Mistral OCR: Merevolusi Generasi Pengambilan Pengambilan semula dengan Pemahaman Dokumen Multimodal Sistem Generasi Pengambilan Retrieval (RAG) mempunyai keupayaan AI yang ketara, membolehkan akses ke kedai data yang luas untuk mendapatkan respons yang lebih tepat
