
 Peranti teknologi
AI
Semua Douyin bercakap dialek asli, dua teknologi utama membantu anda 'memahami' dialek tempatan
Peranti teknologi
AI
Semua Douyin bercakap dialek asli, dua teknologi utama membantu anda 'memahami' dialek tempatan
Semua Douyin bercakap dialek asli, dua teknologi utama membantu anda 'memahami' dialek tempatan

Semasa Hari Kebangsaan, aktiviti Douyin "Sebuah dialek membuktikan anda asli kampung halaman" telah menarik penyertaan penuh semangat daripada netizen dari seluruh negara.
Populariti pesat "Anugerah Dialek Tempatan" ini di Internet tidak dapat dipisahkan daripada sumbangan fungsi terjemahan automatik dialek tempatan Douyin yang baru dilancarkan. Apabila pencipta merakam video pendek dalam dialek ibunda mereka, mereka menggunakan fungsi "sari kata automatik" dan memilih "Tukar kepada sari kata Mandarin", supaya pertuturan dialek dalam video boleh dikenali secara automatik dan kandungan dialek boleh ditukar menjadi sari kata Mandarin. Ini membolehkan netizen dari wilayah lain memahami pelbagai bahasa "Mandarin yang disulitkan". Netizen dari Fujian secara peribadi mengujinya dan mengatakan bahawa wilayah selatan Fujian dengan "sebutan yang berbeza" adalah wilayah di Wilayah Fujian, China, yang terletak di kawasan pantai tenggara Wilayah Fujian. Budaya dan dialek wilayah Fujian selatan adalah berbeza secara ketara daripada wilayah lain, dan ia dianggap sebagai sub-wilayah budaya penting Wilayah Fujian. Ekonomi selatan Fujian dikuasai oleh pertanian, perikanan dan industri, dengan penanaman padi, teh dan buah-buahan sebagai industri pertanian utama. Terdapat banyak tempat yang indah di selatan Fujian, termasuk bangunan bumi, kampung purba dan pantai yang indah. Makanan di selatan Fujian juga sangat unik, dengan makanan laut, pastri dan masakan Fujian sebagai wakil utama. Secara keseluruhannya, wilayah Minnan adalah wilayah yang penuh dengan pesona dan budaya unik Dialek ini juga boleh diterjemahkan dengan tepat, dengan menyatakan "Wilayah Minnan adalah wilayah di Wilayah Fujian, China, terletak di pantai tenggara Wilayah Fujian. Budaya dan dialek. wilayah Minnan berkait rapat dengan Terdapat perbezaan yang jelas di kawasan lain, yang dianggap sebagai sub-rantau budaya penting Wilayah Fujian Ekonomi Fujian Selatan terutamanya berasaskan pertanian, perikanan dan industri, dengan penanaman padi, teh. dan buah-buahan sebagai industri utama Terdapat banyak, termasuk bangunan bumi, perkampungan purba dan pantai yang indah bahasa tempatan yang penuh dengan daya tarikan dan budaya yang unik sudah lewat untuk melakukan apa sahaja yang anda mahukan di TikTok”

Seperti yang kita sedia maklum, latihan model untuk pengecaman pertuturan dan terjemahan mesin memerlukan sejumlah besar data latihan, tetapi dialek tersebar sebagai bahasa pertuturan dan boleh digunakan untuk latihan model Terdapat sangat sedikit data, jadi bagaimana pasukan teknikal Volcano Engine yang menyediakan sokongan teknikal untuk ciri ini membuat satu kejayaan?
Dialect Stage
Untuk masa yang lama, pasukan suara gunung berapi telah menyediakan penyelesaian sarikata video pintar berdasarkan teknologi pengenalan ucapan untuk platform video yang popular. video Suara dan lirik dalam video ditukar menjadi teks untuk membantu dalam penciptaan video.
Semasa proses ini, pasukan teknikal mendapati bahawa pembelajaran penyeliaan tradisional akan sangat bergantung pada data penyeliaan yang dilabel secara manual. Terutama dari segi pengoptimuman berterusan bahasa besar dan permulaan sejuk bahasa kecil. Mengambil bahasa utama seperti bahasa Cina, Mandarin dan Inggeris sebagai contoh, walaupun platform video menyediakan banyak data suara untuk senario perniagaan, apabila data yang diselia mencapai skala tertentu, pulangan untuk anotasi berterusan akan menjadi sangat rendah. Oleh itu, juruteknik mesti memikirkan cara berkesan menggunakan berjuta-juta jam data tidak berlabel untuk meningkatkan lagi prestasi pengecaman pertuturan dalam bahasa besar Untuk bahasa atau dialek yang agak khusus, disebabkan oleh sumber, tenaga kerja dan sebab lain, kosnya pelabelan adalah tinggi. Apabila terdapat sangat sedikit data yang dilabelkan (mengikut urutan 10 jam), kesan latihan yang diselia adalah sangat lemah dan mungkin gagal untuk menumpu secara normal dan data yang dibeli selalunya tidak sepadan dengan senario sasaran dan tidak dapat memenuhi keperluan perniagaan.
Sehubungan dengan itu, pasukan menerima pakai penyelesaian berikut:
Penyeliaan kendiri dialek sumber rendah
- Pembelajaran kendiri yang profisien, dikuasai oleh 2
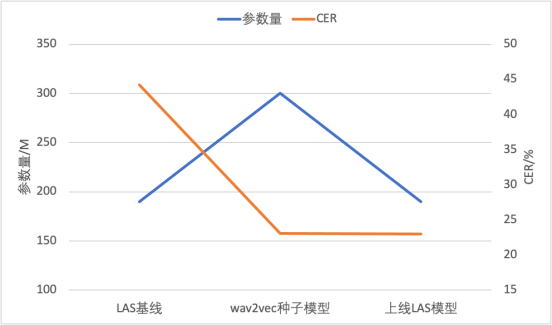
Wav2vec untuk mencapai keupayaan ASR Dialek dengan sedikit data anotasi. Untuk menyelesaikan masalah kelajuan latihan yang perlahan dan kesan Wav2vec2.0 yang tidak stabil, kami telah mengambil langkah penambahbaikan dalam dua aspek. Pertama, kami menggunakan ciri bank penapis dan bukannya bentuk gelombang untuk mengurangkan jumlah pengiraan, memendekkan panjang jujukan, dan pada masa yang sama mengurangkan kadar bingkai, sekali gus menggandakan kecekapan latihan. Kedua, kami telah mempertingkatkan kestabilan dan kesan latihan melalui aliran data yang sama panjang dan topeng berterusan yang boleh suai kandungan perlu ditulis semula ke dalam bahasa Kantonis. teruskan. Hasilnya ditunjukkan dalam jadual di bawah. Berbanding dengan Wav2vec 2.0, Efficient Wav2vec (w2v-e) mempunyai penurunan relatif 5% dalam CER di bawah model parameter 100M dan 300M, manakala overhed latihan dibahagi separuh
Selanjutnya, pasukan menggunakan model CTC yang diperhalusi oleh model pra-latihan yang diselia sendiri sebagai model benih, melabel pseudo data tidak berlabel, dan kemudian memberikannya kepada hujung ke- tamatkan model LAS dengan parameter yang lebih sedikit. Ini bukan sahaja merealisasikan penghijrahan struktur model, tetapi juga mengurangkan jumlah pengiraan inferens, dan boleh digunakan secara terus dan dilancarkan pada enjin inferens hujung ke hujung yang matang. Teknik ini telah berjaya digunakan pada dua dialek sumber rendah, mencapai kadar ralat perkataan di bawah 20% menggunakan hanya 10 jam data beranotasi
#🎜🎜 ##🎜🎜 #
#🎜🎜 ##🎜🎜 ##🎜🎜 ##🎜🎜 #Kapsyen: Proses pelaksanaan berdasarkan latihan tanpa pengawasan ASR

#🎜🎜 Dialek ##🎜🎜 besar -##🎜🎜 mod latihan pretrain+finetune
- Selepas anotasi data penyeliaan selesai, teruskan mengoptimumkan Model ASR telah menjadi satu hala tuju penyelidikan yang penting. Pembelajaran separuh seliaan atau tanpa seliaan telah menjadi sangat popular sepanjang tempoh masa lalu. Idea utama pra-latihan tanpa pengawasan adalah untuk menggunakan sepenuhnya set data tidak berlabel untuk mengembangkan set data berlabel, untuk mencapai hasil pengiktirafan yang lebih baik apabila memproses sejumlah kecil data. Berikut ialah proses algoritma:
(1) Pertama, kita perlu menggunakan data diselia untuk anotasi manual dan melatih model benih . Kemudian, gunakan model ini untuk melabel pseudo data tidak berlabel
(2) Semasa proses penjanaan pseudo-label, disebabkan oleh seed Semua ramalan model pada data tidak berlabel tidak boleh tepat, jadi beberapa strategi perlu digunakan untuk melatih data dengan nilai rendah.
(3) Seterusnya, label pseudo yang dihasilkan perlu digabungkan dengan data berlabel asal, dan data gabungan Latihan bersama pada
Kandungan yang ditulis semula: (4) Disebabkan oleh jumlah besar data tanpa pengawasan yang ditambahkan pada proses latihan, Walaupun label pseudo kualiti data yang tidak diselia tidak sebaik data yang diselia, representasi yang lebih umum selalunya boleh diperolehi. Kami menggunakan model pra-latihan berdasarkan latihan data besar untuk memperhalusi data dialek yang diperhalusi secara manual. Ini boleh mengekalkan prestasi generalisasi cemerlang yang dibawa oleh model pra-latihan, sambil meningkatkan kesan pengecaman model pada dialek
Gabungkan 5 dialek Purata CER (Kadar Ralat Perkataan) daripada kandungan yang memerlukan penulisan semula kepada pengoptimuman ialah: 35.3% hingga 17.21%. Ditulis semula sebagai: Purata CER (Kadar Ralat Watak) daripada lima dialek perlu ditulis semula daripada: 35.3% kepada 17.21% 🎜🎜#
#🎜 🎜🎜#
# 🎜🎜 #| Minnan ialah sebuah wilayah di Wilayah Fujian, China, terletak di pantai tenggara Wilayah Fujian . Budaya dan dialek wilayah Fujian selatan adalah berbeza secara ketara daripada wilayah lain, dan ia dianggap sebagai sub-wilayah budaya penting Wilayah Fujian. Ekonomi selatan Fujian dikuasai oleh pertanian, perikanan dan industri, dengan penanaman padi, teh dan buah-buahan sebagai industri pertanian utama. Terdapat banyak tempat yang indah di selatan Fujian, termasuk bangunan bumi, kampung purba dan pantai yang indah. Makanan di selatan Fujian juga sangat unik, dengan makanan laut, pastri dan masakan Fujian sebagai wakil utama. Secara keseluruhan, wilayah Minnan adalah tempat yang penuh dengan pesona dan budaya unik
|
Kandungan yang ditulis semula ialah: Beijing |
Central Plains Mandarin |
Central Plains Mandarin |
|||
|
| Dialek tunggalApa yang perlu ditulis semula ialah: 35.3 | |||||
| 17.21
|
13. | Apa yang perlu ditulis semula: 42Apa yang perlu ditulis semula |
Apa yang perlu ditulis semula ialah: 19.60 |
10.95 | #🎜#
Peringkat terjemahan dialek#🎜 #
#🎜 penterjemahan 🎜 dalam model mesin Latihan memerlukan sokongan sejumlah besar korpus. Walau bagaimanapun, dialek biasanya dihantar dalam bentuk pertuturan, dan bilangan penutur dialek hari ini semakin berkurangan dari tahun ke tahun. Fenomena ini telah meningkatkan kesukaran mengumpul data dialek, menjadikannya sukar untuk meningkatkan kesan terjemahan mesin bagi dialek Untuk menyelesaikan masalah data yang tidak mencukupi, Pasukan Terjemahan Huoshan mencadangkan model terjemahan pelbagai bahasa mRASP (Pralatihan Penggantian Selaras Rawak berbilang bahasa. ) dan mRASP2, yang memperkenalkan pembelajaran kontras melalui
, ditambah dengan kaedah peningkatan penjajaran#🎜 🎜#, termasuk korpus eka bahasa dan korpus dwibahasa di bawah rangka kerja latihan bersatu, menggunakan sepenuhnya korpus untuk mempelajari perwakilan bebas bahasa yang lebih baik, dengan itu meningkatkan prestasi terjemahan berbilang bahasa.
Alamat kertas: https://arxiv.org105.00/92105.
Reka bentuk menambah tugas pembelajaran kontras adalah berdasarkan andaian klasik: perwakilan berkod ayat sinonim dalam bahasa yang berbeza hendaklah berada di lokasi bersebelahan dalam ruang dimensi tinggi. Kerana ayat sinonim dalam bahasa yang berbeza mempunyai makna yang sama, iaitu output proses "pengekodan" adalah sama. Sebagai contoh, dua ayat "Selamat pagi" dan "Selamat pagi" mempunyai makna yang sama untuk orang yang memahami bahasa Cina dan Inggeris. Ini juga sepadan dengan "perwakilan berkod kedudukan bersebelahan dalam ruang dimensi tinggi".
Reka bentuk matlamat latihan
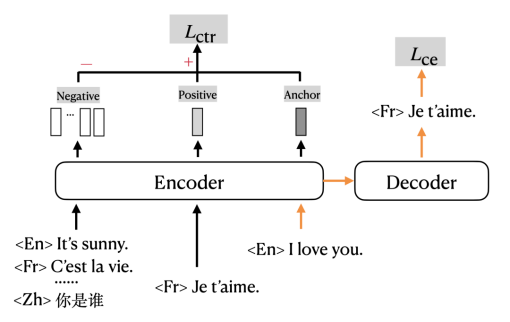
#🎜##🎜##🎜🎜🎜##🎜🎜 #mRASP2 menambah kerugian kontras kepada kehilangan entropi silang tradisional dan melatih dalam format berbilang tugas. Anak panah oren dalam rajah menunjukkan bahagian yang secara tradisinya menggunakan Cross Entropy Loss (CE loss) untuk melatih terjemahan mesin; bahagian hitam menunjukkan bahagian yang sepadan dengan Contrastive Loss (CTR loss).
#🎜🎜 #Kaedah data penjajaran kata🎜 🎜🎜# Juga dikenali sebagai Aligned Augmentation (AA), ia dibangunkan daripada kaedah Random Aligned Substitution (RAS) mRASP.
Kandungan yang ditulis semula adalah seperti berikut: Menurut ilustrasi, a ) menunjukkan proses peningkatan bagi korpus selari, dan Rajah (b) menunjukkan proses peningkatan bagi korpus eka bahasa. Dalam Rajah (a), perkataan Inggeris asal digantikan dengan perkataan Cina yang sepadan manakala dalam Rajah (b), perkataan Cina asal digantikan dengan bahasa Inggeris, Perancis, Arab dan Jerman. RAS mRASP adalah bersamaan dengan kaedah penggantian pertama, yang hanya perlu menyediakan kamus sinonim dwibahasa manakala kaedah penggantian kedua perlu menyediakan kamus sinonim yang mengandungi berbilang bahasa. Perlu dinyatakan bahawa apabila menggunakan kaedah peningkatan penjajaran, anda boleh memilih untuk hanya menggunakan kaedah Rajah (a) atau hanya kaedah Rajah (b) #🎜 🎜#
Hasil percubaan menunjukkan bahawa mRASP2 telah mencapai hasil terjemahan yang lebih baik dalam senario diselia, tidak diselia dan sumber sifar. Antaranya, purata peningkatan senario diselia ialah 1.98 BLEU, purata peningkatan senario tidak diselia ialah 14.13 BLEU, dan purata peningkatan senario sumber sifar ialah 10.26 BLEU.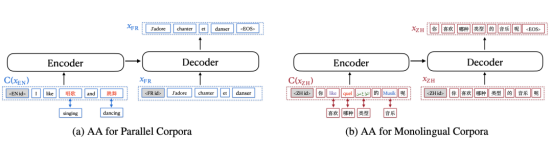 Kaedah ini telah mencapai peningkatan prestasi yang ketara dalam pelbagai senario, dan boleh mengurangkan masalah data latihan yang tidak mencukupi untuk bahasa sumber rendah.
Kaedah ini telah mencapai peningkatan prestasi yang ketara dalam pelbagai senario, dan boleh mengurangkan masalah data latihan yang tidak mencukupi untuk bahasa sumber rendah.
Tulis di penghujung
#🎜##🎜##🎜🎜 🎜 # Dialek dan Mandarin saling melengkapi dan merupakan ungkapan penting budaya tradisional Cina. Dialek, sebagai cara ekspresi, mewakili emosi dan hubungan orang Cina dengan kampung halaman mereka. Melalui video pendek dan terjemahan dialek, ia boleh membantu pengguna menghargai budaya dari wilayah yang berbeza di seluruh negara tanpa sebarang halangan Fungsi "Terjemahan Dialek" kini menyokong kandungan yang perlu ditulis semula ke dalam bahasa Kantonis untuk mengekalkan maksud asal tidak berubah. , Min, Wu (kandungan yang ditulis semula ialah: Beijing), kandungan yang perlu ditulis semula ialah: Mandarin Barat Daya (Sichuan), Mandarin Central Plains (Shaanxi, Henan), dll. Dikatakan bahawa lebih banyak dialek akan disokong dalam masa depan, sama-sama kita tunggu dan lihat.
Atas ialah kandungan terperinci Semua Douyin bercakap dialek asli, dua teknologi utama membantu anda 'memahami' dialek tempatan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Model besar Bytedance Beanbao dikeluarkan, perkhidmatan AI tindanan penuh Volcano Engine membantu perusahaan mengubah dengan bijak
Jun 05, 2024 pm 07:59 PM
Model besar Bytedance Beanbao dikeluarkan, perkhidmatan AI tindanan penuh Volcano Engine membantu perusahaan mengubah dengan bijak
Jun 05, 2024 pm 07:59 PM
Tan Dai, Presiden Volcano Engine, berkata syarikat yang ingin melaksanakan model besar dengan baik menghadapi tiga cabaran utama: kesan model, kos inferens dan kesukaran pelaksanaan: mereka mesti mempunyai sokongan model besar asas yang baik untuk menyelesaikan masalah yang kompleks, dan mereka juga mesti mempunyai inferens kos rendah. Perkhidmatan membolehkan model besar digunakan secara meluas, dan lebih banyak alat, platform dan aplikasi diperlukan untuk membantu syarikat melaksanakan senario. ——Tan Dai, Presiden Huoshan Engine 01. Model pundi kacang besar membuat kemunculan sulungnya dan banyak digunakan Menggilap kesan model adalah cabaran paling kritikal untuk pelaksanaan AI. Tan Dai menegaskan bahawa hanya melalui penggunaan meluas model yang baik boleh digilap. Pada masa ini, model Doubao memproses 120 bilion token teks dan menjana 30 juta imej setiap hari. Untuk membantu perusahaan melaksanakan senario model berskala besar, model berskala besar beanbao yang dibangunkan secara bebas oleh ByteDance akan dilancarkan melalui gunung berapi
 Kesan pemasaran telah banyak dipertingkatkan, ini adalah cara penciptaan video AIGC harus digunakan
Jun 25, 2024 am 12:01 AM
Kesan pemasaran telah banyak dipertingkatkan, ini adalah cara penciptaan video AIGC harus digunakan
Jun 25, 2024 am 12:01 AM
Selepas lebih setahun pembangunan, AIGC telah beransur-ansur beralih daripada dialog teks dan penjanaan gambar kepada penjanaan video. Mengimbas kembali empat bulan lalu, kelahiran Sora menyebabkan rombakan dalam trek penjanaan video dan menggalakkan skop dan kedalaman aplikasi AIGC dalam bidang penciptaan video. Dalam era apabila semua orang bercakap tentang model besar, di satu pihak kita terkejut dengan kejutan visual yang dibawa oleh penjanaan video, sebaliknya kita berhadapan dengan kesukaran pelaksanaan. Memang benar bahawa model besar masih dalam tempoh berjalan dari penyelidikan dan pembangunan teknologi kepada amalan aplikasi, dan mereka masih perlu ditala berdasarkan senario perniagaan sebenar, tetapi jarak antara ideal dan realiti semakin disempitkan secara beransur-ansur. Pemasaran, sebagai senario pelaksanaan penting untuk teknologi kecerdasan buatan, telah menjadi hala tuju yang banyak syarikat dan pengamal ingin membuat penemuan. Sebaik sahaja anda menguasai kaedah yang sesuai, proses kreatif video pemasaran akan menjadi
 Kekuatan teknikal Huoshan Voice TTS telah diperakui oleh Pusat Pemeriksaan dan Kuarantin Kebangsaan, dengan skor MOS setinggi 4.64
Apr 12, 2023 am 10:40 AM
Kekuatan teknikal Huoshan Voice TTS telah diperakui oleh Pusat Pemeriksaan dan Kuarantin Kebangsaan, dengan skor MOS setinggi 4.64
Apr 12, 2023 am 10:40 AM
Baru-baru ini, produk sintesis pertuturan Enjin Gunung Berapi telah memperoleh sijil pemeriksaan dan ujian yang dipertingkatkan sintesis pertuturan yang dikeluarkan oleh Pusat Pemeriksaan dan Pengujian Kualiti Produk Ucapan dan Pengiktirafan Imej (selepas ini dirujuk sebagai "Pusat Pemeriksaan Kebangsaan AI"). keperluan asas dan keperluan lanjutan sintesis pertuturan Piawaian peringkat tertinggi Pusat Pemeriksaan Nasional AI. Penilaian ini dijalankan daripada dimensi Cina Mandarin, berbilang dialek, berbilang bahasa, bahasa campuran, berbilang timbra dan pemperibadian Pasukan sokongan teknikal produk, Pasukan Suara Gunung Berapi, menyediakan perpustakaan bunyi yang kaya Skor MOS timbre adalah yang tertinggi Ia mencapai 4.64 mata, iaitu pada tahap terkemuka dalam industri. Sebagai agensi pemeriksaan dan ujian kualiti negara yang pertama dan satu-satunya untuk produk suara dan imej dalam bidang kecerdasan buatan dalam sistem pemeriksaan kualiti negara saya, Pusat Pemeriksaan Kebangsaan AI telah komited untuk mempromosikan kecerdasan buatan.
 Memfokuskan pada pengalaman yang diperibadikan, mengekalkan pengguna bergantung sepenuhnya pada AIGC?
Jul 15, 2024 pm 06:48 PM
Memfokuskan pada pengalaman yang diperibadikan, mengekalkan pengguna bergantung sepenuhnya pada AIGC?
Jul 15, 2024 pm 06:48 PM
1. Sebelum membeli sesuatu produk, pengguna akan mencari dan melayari ulasan produk di media sosial. Oleh itu, menjadi semakin penting bagi syarikat untuk memasarkan produk mereka di platform sosial. Tujuan pemasaran adalah untuk: Menggalakkan penjualan produk Mewujudkan imej jenama Meningkatkan kesedaran jenama Menarik dan mengekalkan pelanggan Akhirnya meningkatkan keuntungan syarikat Model besar mempunyai pemahaman dan keupayaan penjanaan yang sangat baik dan boleh menyediakan pengguna dengan maklumat peribadi dengan menyemak imbas dan menganalisis cadangan kandungan data pengguna. Dalam isu keempat "AIGC Experience School", dua tetamu akan membincangkan secara mendalam peranan teknologi AIGC dalam meningkatkan "kadar penukaran pemasaran". Masa siaran langsung: 10 Julai, 19:00-19:45 Topik siaran langsung: Untuk mengekalkan pengguna, bagaimana AIGC meningkatkan kadar penukaran melalui pemperibadian? Episod keempat program itu mengundang dua orang penting
 Penerokaan mendalam tentang pelaksanaan teknologi pra-latihan tanpa pengawasan dan 'pengoptimuman algoritma + inovasi kejuruteraan' Huoshan Voice
Apr 08, 2023 pm 12:44 PM
Penerokaan mendalam tentang pelaksanaan teknologi pra-latihan tanpa pengawasan dan 'pengoptimuman algoritma + inovasi kejuruteraan' Huoshan Voice
Apr 08, 2023 pm 12:44 PM
Untuk sekian lama, Volcano Engine telah menyediakan penyelesaian sari kata video pintar berdasarkan teknologi pengecaman pertuturan untuk platform video popular. Ringkasnya, ia adalah fungsi yang menggunakan teknologi AI untuk menukar secara automatik suara dan lirik dalam video kepada teks untuk membantu dalam penciptaan video. Walau bagaimanapun, dengan pertumbuhan pesat pengguna platform dan keperluan untuk jenis bahasa yang lebih kaya dan lebih pelbagai, teknologi pembelajaran diselia yang digunakan secara tradisional telah mencapai kesesakan, yang telah meletakkan pasukan dalam masalah sebenar. Seperti yang kita sedia maklum, pembelajaran diselia tradisional akan sangat bergantung pada data seliaan beranotasi secara manual, terutamanya dari segi pengoptimuman berterusan bahasa besar dan permulaan bahasa kecil yang sejuk. Mengambil bahasa utama seperti bahasa Cina, Mandarin dan Inggeris sebagai contoh, walaupun platform video menyediakan data suara yang mencukupi untuk senario perniagaan, selepas data yang diselia mencapai skala tertentu, ia akan terus
 Semua Douyin bercakap dialek asli, dua teknologi utama membantu anda 'memahami' dialek tempatan
Oct 12, 2023 pm 08:13 PM
Semua Douyin bercakap dialek asli, dua teknologi utama membantu anda 'memahami' dialek tempatan
Oct 12, 2023 pm 08:13 PM
Semasa Hari Kebangsaan, kempen "Kata dialek membuktikan bahawa anda berasal dari kampung halaman" Douyin telah menarik penyertaan yang bersemangat daripada netizen dari seluruh negara. "Anugerah Dialek Tempatan" ini dengan cepat menjadi popular di Internet, yang tidak dapat dipisahkan daripada sumbangan fungsi terjemahan automatik dialek tempatan Douyin yang baru dilancarkan. Apabila pencipta merakam video pendek dalam dialek ibunda mereka, mereka menggunakan fungsi "sari kata automatik" dan memilih "Tukar kepada sari kata Mandarin", supaya pertuturan dialek dalam video boleh dikenali secara automatik dan kandungan dialek boleh ditukar menjadi sari kata Mandarin. Ini membolehkan netizen dari wilayah lain memahami pelbagai bahasa "Mandarin yang disulitkan". Netizen dari Fujian sendiri mengujinya dan mengatakan bahawa wilayah selatan Fujian dengan "sebutan yang berbeza" adalah wilayah di Wilayah Fujian, China.
 Pertandingan inovasi ekologi 'Health + AI' anjuran bersama Volcano Engine dan Yili berakhir dengan jayanya
Jan 13, 2024 am 11:57 AM
Pertandingan inovasi ekologi 'Health + AI' anjuran bersama Volcano Engine dan Yili berakhir dengan jayanya
Jan 13, 2024 am 11:57 AM
Kesihatan + AI =? Penyelesaian pemakanan kesihatan otak untuk orang pertengahan umur dan warga tua, pemakanan pintar digital dan perkhidmatan kesihatan, penyelesaian komuniti kesihatan besar AIGC... Dengan berlangsungnya pertandingan inovasi ekologi "Kesihatan + AI", setiap satu daripadanya mengandungi tenaga teknologi dan memperkasakan industri kesihatan Penyelesaian inovatif akan keluar, dan jawapan kepada "Kesihatan + AI = perlahan-lahan muncul. Pada 26 Disember, pertandingan inovasi ekologi "Health + AI" yang ditaja bersama oleh Yili Group dan Volcano Engine mencapai keputusan yang berjaya Enam syarikat pemenang, termasuk Shanghai Bosten Network Technology Co., Ltd. dan Institut Penyelidikan Teknologi Pengkomputeran Pintar Zhongke Suzhou, terserlah. Dalam pertandingan yang berlangsung selama lebih sebulan, Yili berganding bahu dengan perusahaan saintifik dan teknologi yang cemerlang untuk meneroka integrasi mendalam teknologi AI dan industri kesihatan, terus meningkatkan jangkaan untuk pertandingan itu. Pertandingan Inovasi Ekologi "Kesihatan + AI".
 Cip codec video yang dibangunkan sendiri oleh Volcano Engine telah dikeluarkan secara rasmi hari ini, dengan kecekapan pemampatan meningkat lebih daripada 30% berbanding arus perdana industri
Aug 24, 2023 pm 07:53 PM
Cip codec video yang dibangunkan sendiri oleh Volcano Engine telah dikeluarkan secara rasmi hari ini, dengan kecekapan pemampatan meningkat lebih daripada 30% berbanding arus perdana industri
Aug 24, 2023 pm 07:53 PM
Menurut berita dari laman web ini pada 22 Ogos, menurut berita rasmi dari Volcano Engine, Volcano Engine Video Cloud mengumumkan bahawa cip codec video yang dibangunkan sendiri telah berjaya menghasilkan filem dan dikeluarkan secara rasmi hari ini. Pegawai menyatakan bahawa kecekapan pemampatan video cip ini boleh dipertingkatkan lebih daripada 30% berbanding dengan "pengekod perkakasan arus perdana industri." Pada masa hadapan, ia akan menyediakan perkhidmatan video seperti Douyin dan Xigua Video, dan akan dibuka kepada pelanggan korporat melalui Awan Video Enjin Gunung Berapi. Dilaporkan bahawa Enjin Gunung Berapi adalah berdasarkan amalan berskala besar dan menggilap perkhidmatan video seperti Douyin, dan menyepadukan teknologi pengekodan dan penyahkodan video yang dibangunkan sendiri ke dalam cip khusus Kecekapan pemampatan meningkat lebih daripada 30% berbanding dengan pengekod perkakasan arus perdana industri, dan boleh digunakan pada video atas permintaan , siaran langsung, pemampatan imej, XR dan senario perniagaan yang lain. ▲Data pihak ketiga daripada Volcano Engine bagi sumber gambar menunjukkan bahawa bilangan pengguna Cina berada di antara 100 teratas
