


STRIDE ialah rangka kerja pemodelan ancaman popular yang kini digunakan secara meluas untuk membantu organisasi secara proaktif menemui ancaman, serangan, kelemahan dan Tindakan Balas. Jika anda memisahkan setiap huruf dalam "STRIDE", ia mewakili pemalsuan, pengubahan, penafian, pendedahan maklumat, penafian perkhidmatan dan peningkatan keistimewaan
Memandangkan aplikasi sistem kecerdasan buatan (AI) secara beransur-ansur menjadi sebagai kunci. komponen pembangunan digital, ramai pengamal keselamatan menyeru keperluan untuk mengenal pasti dan melindungi risiko keselamatan sistem ini secepat mungkin. Rangka kerja STRIDE boleh membantu organisasi lebih memahami kemungkinan laluan serangan dalam sistem AI dan meningkatkan keselamatan dan kebolehpercayaan aplikasi AI mereka. Dalam artikel ini, penyelidik keselamatan menggunakan rangka kerja model STRIDE untuk memetakan secara menyeluruh permukaan serangan dalam aplikasi sistem AI (lihat jadual di bawah), dan menjalankan penyelidikan tentang kategori serangan baharu dan senario serangan khusus untuk teknologi AI. Ketika teknologi AI terus berkembang, lebih banyak model, aplikasi, serangan dan mod pengendalian baharu akan muncul Penyelidik #AI Andrej Karpathy menegaskan bahawa kedatangan model rangkaian saraf dalam generasi baharu menandakan anjakan paradigma dalam cara tradisional mengkonseptualisasikan pengeluaran perisian. Pembangun semakin membenamkan model AI ke dalam sistem kompleks yang dinyatakan bukan dalam bahasa gelung dan bersyarat tetapi dalam ruang vektor berterusan dan pemberat berangka, mewujudkan kemungkinan baharu untuk laluan kerentanan dan menimbulkan kategori ancaman baharu.
Jika penyerang dapat mengganggu input dan output model, atau menukar parameter tetapan tertentu infrastruktur AI, ia mungkin membawa kepada hasil berniat jahat yang berbahaya dan tidak dapat diramalkan, seperti tingkah laku yang tidak dijangka , interaksi dengan ejen AI Interaksi dan kesan ke atas komponen yang dipautkan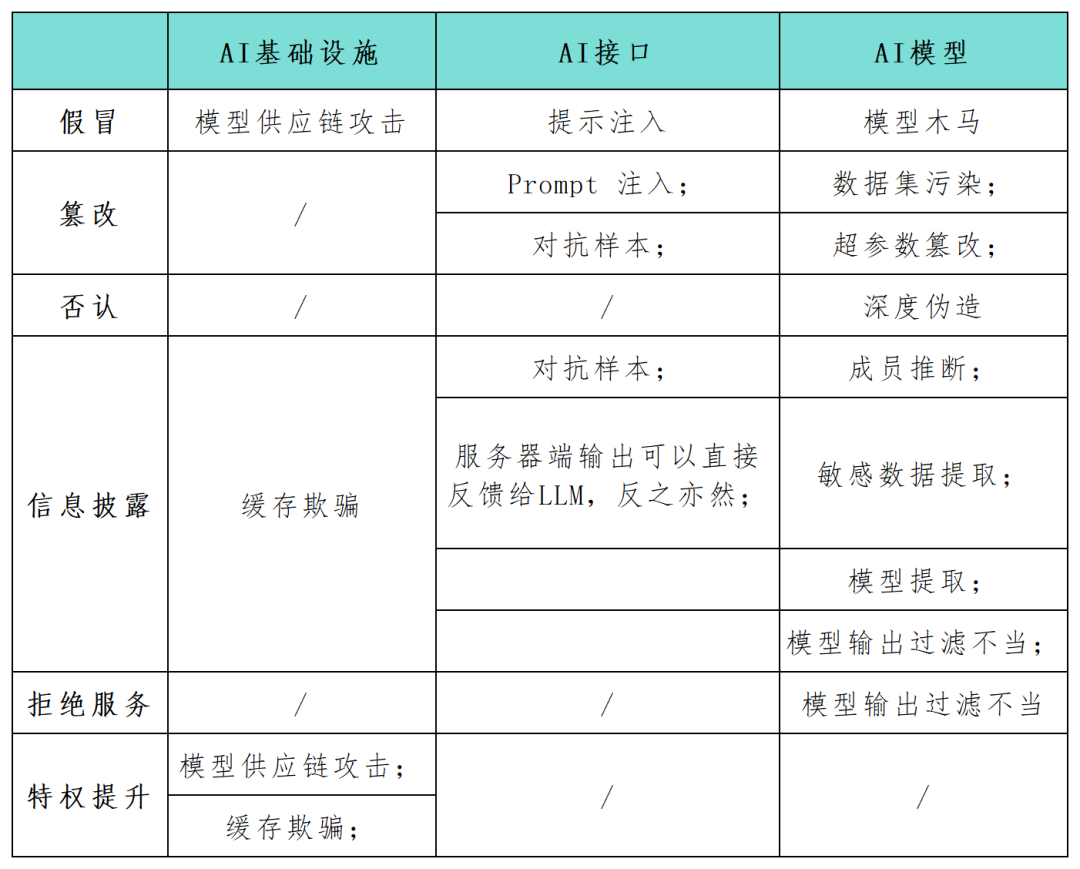
Kandungan yang ditulis semula: Serangan segera input merujuk kepada tingkah laku seperti pemecahan jail, kebocoran segera dan penyeludupan token. Dalam serangan ini, penyerang menggunakan gesaan input untuk mencetuskan gelagat LLM yang tidak dijangka. Manipulasi sedemikian boleh menyebabkan AI bertindak balas secara tidak wajar atau membocorkan maklumat sensitif, selaras dengan penipuan dan kategori kebocoran maklumat dalam model STRIDE. Serangan ini amat berbahaya apabila sistem AI digunakan bersama sistem lain atau dalam rangkaian aplikasi perisian
Output dan penapisan model yang tidak betul. Sebilangan besar aplikasi API boleh dieksploitasi dalam pelbagai cara yang tidak didedahkan kepada umum. Sebagai contoh, rangka kerja seperti Langchain membenarkan pembangun aplikasi menggunakan aplikasi kompleks dengan cepat pada model generatif awam dan sistem awam atau persendirian lain (seperti pangkalan data atau penyepaduan Slack). Penyerang boleh membina pembayang yang memperdaya model untuk membuat pertanyaan API yang tidak dibenarkan sebaliknya. Begitu juga, penyerang boleh menyuntik pernyataan SQL ke dalam borang web tidak bersih generik untuk melaksanakan kod berniat jahat.
Inferens ahli dan pengekstrakan data sensitif adalah perkara yang perlu ditulis semula. Penyerang boleh mengeksploitasi serangan inferens keahlian untuk membuat kesimpulan dari segi binari sama ada titik data tertentu berada dalam set latihan, menimbulkan kebimbangan privasi. Serangan pengekstrakan data membolehkan penyerang membina semula maklumat sensitif sepenuhnya tentang data latihan daripada respons model. Apabila LLM dilatih mengenai set data peribadi, senario biasa ialah model itu mungkin mempunyai data organisasi yang sensitif dan penyerang boleh mengekstrak maklumat sulit dengan membuat gesaan khusus
Kandungan ditulis semula: Model Trojan ialah sejenis model yang telah terbukti dapat Model yang terdedah kepada pencemaran set data latihan semasa fasa penalaan halus. Selain itu, pengubahan data latihan awam yang biasa telah terbukti boleh dilaksanakan dalam amalan. Kelemahan ini membuka pintu kepada model Trojan untuk model bahasa yang tersedia secara umum. Di permukaan, mereka berfungsi seperti yang diharapkan untuk kebanyakan petua, tetapi mereka menyembunyikan kata kunci tertentu yang diperkenalkan semasa penalaan halus. Sebaik sahaja penyerang mencetuskan kata kunci ini, model Trojan boleh melakukan pelbagai tingkah laku berniat jahat, termasuk meningkatkan keistimewaan, menjadikan sistem tidak boleh digunakan (DoS) atau membocorkan maklumat sensitif peribadi
Pautan rujukan:
Kandungan yang perlu ditulis semula ialah: https://www.secureworks.com/blog/unravelling-the-attack-surface-of-ai-systems
Atas ialah kandungan terperinci Melihat ancaman permukaan serangan dan pengurusan aplikasi AI daripada model ancaman STRIDE. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



