
 Peranti teknologi
AI
Pilih GPT-3.5 atau perhalusi model sumber terbuka seperti Llama 2? Selepas perbandingan menyeluruh, jawapannya ialah
Peranti teknologi
AI
Pilih GPT-3.5 atau perhalusi model sumber terbuka seperti Llama 2? Selepas perbandingan menyeluruh, jawapannya ialah
Pilih GPT-3.5 atau perhalusi model sumber terbuka seperti Llama 2? Selepas perbandingan menyeluruh, jawapannya ialah

Seperti yang kita sedia maklum, penalaan halus GPT-3.5 adalah sangat mahal. Kertas ini menggunakan percubaan untuk mengesahkan sama ada model yang diperhalusi secara manual boleh mendekati prestasi GPT-3.5 pada sebahagian kecil daripada kos. Menariknya, artikel ini melakukan perkara itu.
Membandingkan keputusan pada tugas SQL dan tugas perwakilan berfungsi, artikel ini menemui:
- #🎜 #GPT-3.5 berprestasi lebih baik sedikit daripada Kod Llama 34B yang diperhalusi oleh Lora pada kedua-dua set data (subset set data Spider dan set data perwakilan fungsi Viggo).
- GPT-3.5 adalah 4-6 kali lebih mahal untuk dilatih dan lebih mahal untuk digunakan.
Salah satu kesimpulan eksperimen ini ialah penalaan halus GPT-3.5 sesuai untuk kerja pengesahan awal, tetapi selepas itu, model seperti Llama 2 mungkin Pilihan terbaik, untuk meringkaskan secara ringkas:
- Jika anda ingin mengesahkan bahawa penalaan halus ialah cara yang betul untuk menyelesaikan tugasan/set data tertentu, atau mahukan persekitaran Dihoskan yang lengkap, kemudian perhalusi GPT-3.5.
- Jika anda ingin menjimatkan wang, dapatkan prestasi maksimum daripada set data anda, mempunyai fleksibiliti yang lebih besar dalam melatih dan menggunakan infrastruktur, atau ingin mengekalkan Beberapa data peribadi, maka baiklah -tala model sumber terbuka seperti Llama 2.
Seterusnya mari kita lihat bagaimana artikel ini dilaksanakan.
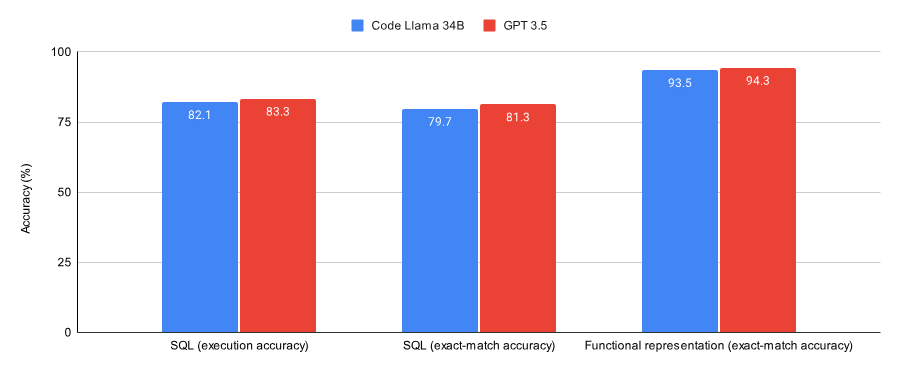
Rajah berikut menunjukkan prestasi Kod Llama 34B dan GPT-3.5 yang dilatih untuk menumpu pada tugas SQL dan tugas perwakilan berfungsi. Keputusan menunjukkan bahawa GPT-3.5 mencapai ketepatan yang lebih baik pada kedua-dua tugas.
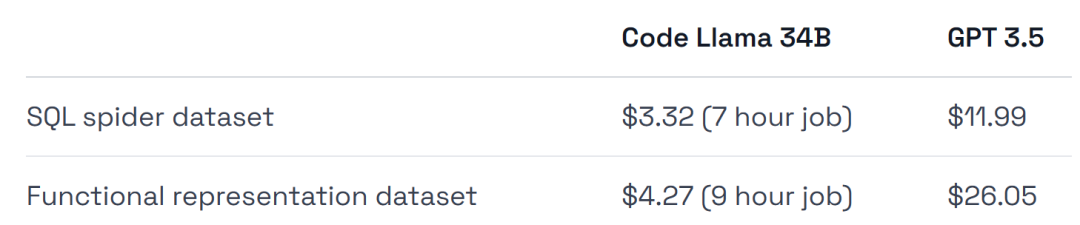
Dari segi penggunaan perkakasan, percubaan menggunakan GPU A40, yang berharga kira-kira $0.475 sejam.
Selain itu, eksperimen memilih dua set data yang sangat sesuai untuk penalaan halus , subset set data Spider dan set data perwakilan fungsi Viggo.
Untuk membuat perbandingan yang saksama dengan model GPT-3.5, percubaan melakukan penalaan halus hiperparameter minimum pada Llama.
Dua pilihan utama untuk percubaan artikel ini ialah menggunakan penalaan halus Kod Llama 34B dan Lora dan bukannya penalaan halus parameter penuh.
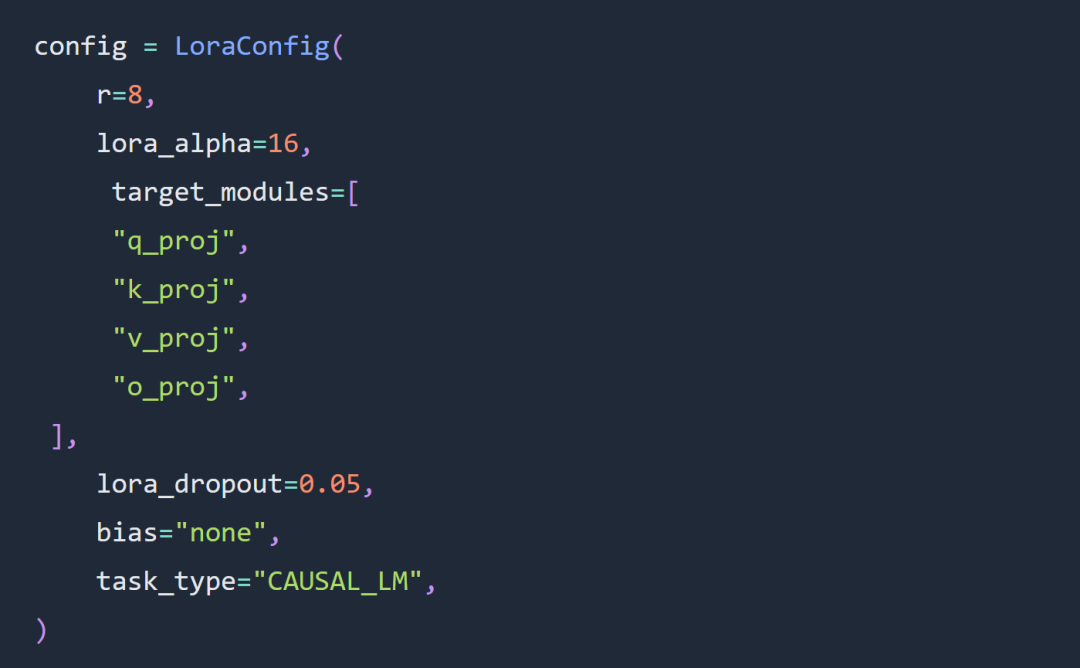
Percubaan mengikut peraturan tentang penalaan hiperparameter Lora pada tahap yang besar Penyesuai Lora telah dikonfigurasikan seperti berikut: #🎜. 🎜## 🎜🎜#
 SQL contoh segera adalah seperti berikut:
SQL contoh segera adalah seperti berikut:
#🎜🎜🎜##🎜🎜🎜##🎜🎜 🎜🎜##🎜 🎜#
Gesaan SQL dipaparkan sebahagiannya Untuk petua lengkap, sila semak blog asal#🎜#🎜##🎜. Percubaan tidak menggunakan set data Spider yang lengkap Bentuk khusus adalah seperti berikut 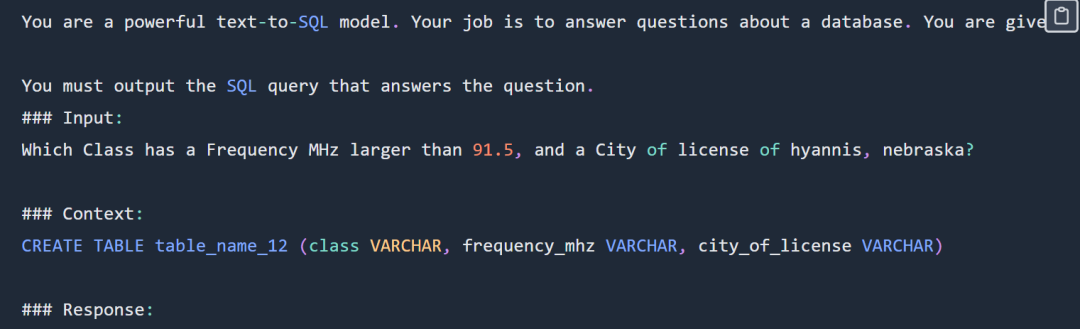
department : Department_ID [ INT ] primary_key Name [ TEXT ] Creation [ TEXT ] Ranking [ INT ] Budget_in_Billions [ INT ] Num_Employees [ INT ] head : head_ID [ INT ] primary_key name [ TEXT ] born_state [ TEXT ] age [ INT ] management : department_ID [ INT ] primary_key management.department_ID = department.Department_ID head_ID [ INT ] management.head_ID = head.head_ID temporary_acting [ TEXT ]
Percubaan memilih untuk menggunakan persilangan set data sql-create-context dan Set data labah-labah. Konteks yang disediakan untuk model ialah arahan penciptaan SQL seperti berikut:
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)
Kod dan alamat data tugas SQL: https://github.com/samlhuillier / spider-sql-finetune
Contoh gesaan perwakilan berfungsi kelihatan seperti ini:
# 🎜🎜#
pewakilan berfungsi Petua dipaparkan sebahagiannya Untuk petua lengkap, sila semak blog asal#🎜🎜🎜🎜🎜🎜 #Output adalah seperti berikut:# 🎜🎜#
verify_attribute(name[Little Big Adventure], rating[average], has_multiplayer[no], platforms[PlayStation])
Semasa fasa penilaian, kedua-dua eksperimen cepat bertumpu: 🎜#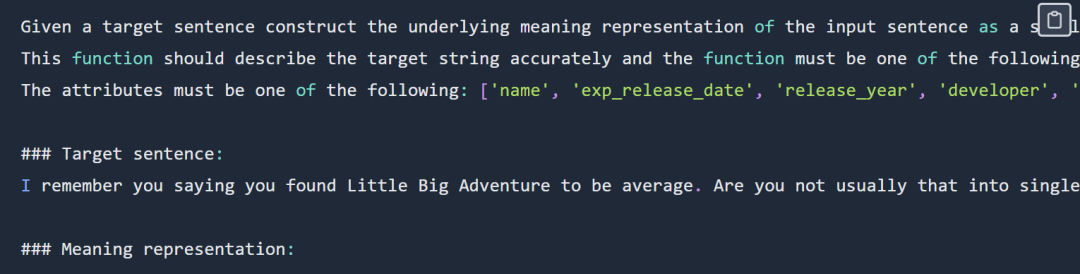 perwakilan berfungsi Kod tugas dan alamat data: https ://github.com/samlhuillier/viggo-finetune
perwakilan berfungsi Kod tugas dan alamat data: https ://github.com/samlhuillier/viggo-finetune
Untuk maklumat lanjut, sila semak Blog Asal.
Atas ialah kandungan terperinci Pilih GPT-3.5 atau perhalusi model sumber terbuka seperti Llama 2? Selepas perbandingan menyeluruh, jawapannya ialah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Cara Mencantikkan Format XML
Apr 02, 2025 pm 09:57 PM
Cara Mencantikkan Format XML
Apr 02, 2025 pm 09:57 PM
Pengindahan XML pada dasarnya meningkatkan kebolehbacaannya, termasuk lekukan yang munasabah, rehat garis dan organisasi tag. Prinsipnya adalah untuk melintasi pokok XML, tambah lekukan mengikut tahap, dan mengendalikan tag dan tag kosong yang mengandungi teks. Perpustakaan XML.Etree.ElementTree Python menyediakan fungsi Pretty_XML yang mudah yang dapat melaksanakan proses pengindahan di atas.
 Cara mengesahkan format XML
Apr 02, 2025 pm 10:00 PM
Cara mengesahkan format XML
Apr 02, 2025 pm 10:00 PM
Pengesahan format XML melibatkan memeriksa struktur dan pematuhannya dengan DTD atau skema. Parser XML diperlukan, seperti ElementTree (pemeriksaan sintaks asas) atau LXML (pengesahan yang lebih kuat, sokongan XSD). Proses pengesahan melibatkan parsing fail XML, memuatkan skema XSD, dan melaksanakan kaedah AssertValid untuk membuang pengecualian apabila ralat dikesan. Mengesahkan format XML juga memerlukan pengendalian pelbagai pengecualian dan mendapat gambaran mengenai bahasa skema XSD.
 Cara menggunakan array char dalam bahasa c
Apr 03, 2025 pm 03:24 PM
Cara menggunakan array char dalam bahasa c
Apr 03, 2025 pm 03:24 PM
Arus char menyimpan urutan watak dalam bahasa C dan diisytiharkan sebagai array_name char [saiz]. Unsur akses diluluskan melalui pengendali subskrip, dan elemen berakhir dengan terminator null '\ 0', yang mewakili titik akhir rentetan. Bahasa C menyediakan pelbagai fungsi manipulasi rentetan, seperti strlen (), strcpy (), strcat () dan strcmp ().
 Elakkan kesilapan yang disebabkan secara lalai dalam penyataan suis C
Apr 03, 2025 pm 03:45 PM
Elakkan kesilapan yang disebabkan secara lalai dalam penyataan suis C
Apr 03, 2025 pm 03:45 PM
Strategi untuk mengelakkan kesilapan yang disebabkan oleh lalai dalam pernyataan suis C: Gunakan enums dan bukannya pemalar, mengehadkan nilai pernyataan kes kepada ahli yang sah dari enum. Gunakan kejatuhan dalam pernyataan kes terakhir untuk membiarkan program terus melaksanakan kod berikut. Untuk pernyataan suis tanpa kejatuhan, selalu tambahkan pernyataan lalai untuk pengendalian ralat atau memberikan tingkah laku lalai.
 Apakah fungsi jumlah bahasa C?
Apr 03, 2025 pm 02:21 PM
Apakah fungsi jumlah bahasa C?
Apr 03, 2025 pm 02:21 PM
Tiada fungsi jumlah terbina dalam dalam bahasa C, jadi ia perlu ditulis sendiri. Jumlah boleh dicapai dengan melintasi unsur -unsur array dan terkumpul: Versi gelung: SUM dikira menggunakan panjang gelung dan panjang. Versi Pointer: Gunakan petunjuk untuk menunjuk kepada unsur-unsur array, dan penjumlahan yang cekap dicapai melalui penunjuk diri sendiri. Secara dinamik memperuntukkan versi Array: Perlawanan secara dinamik dan uruskan memori sendiri, memastikan memori yang diperuntukkan dibebaskan untuk mengelakkan kebocoran ingatan.
 Apakah perbezaan antara watak null dan null dalam bahasa c
Apr 03, 2025 am 11:12 AM
Apakah perbezaan antara watak null dan null dalam bahasa c
Apr 03, 2025 am 11:12 AM
NULL (penunjuk) dan \ 0 (watak null) sama sekali berbeza dalam bahasa C: NULL bermakna titik penunjuk tidak sah (alamat memori 0), manakala \ 0 adalah pemalar watak, menandakan hujung rentetan; Penggunaan campuran akan membuang ralat (amaran pengkompil).
 Apakah maksud bahasa C null
Apr 03, 2025 pm 12:00 PM
Apakah maksud bahasa C null
Apr 03, 2025 pm 12:00 PM
Null dalam bahasa C mewakili penunjuk null, menunjuk ke alamat memori yang tidak wujud. Ia digunakan untuk pengendalian ralat dan penandaan struktur akhir data, tetapi perhatian harus dibayar untuk memeriksa kesahihan penunjuk null untuk mengelakkan masalah seperti Segfaults dan kemalangan program.
 Apa yang tidak berguna dalam bahasa C
Apr 03, 2025 pm 12:03 PM
Apa yang tidak berguna dalam bahasa C
Apr 03, 2025 pm 12:03 PM
Null adalah nilai khas dalam bahasa C, yang mewakili penunjuk null, yang digunakan untuk mengenal pasti bahawa pembolehubah penunjuk tidak menunjuk kepada alamat memori yang sah. Memahami Null adalah penting kerana ia membantu mengelakkan kemalangan program dan memastikan kekukuhan kod. Penggunaan umum termasuk pemeriksaan parameter, peruntukan memori, dan parameter pilihan untuk reka bentuk fungsi. Apabila menggunakan NULL, anda harus berhati -hati untuk mengelakkan kesilapan seperti penunjuk menggantung dan lupa untuk memeriksa NULL, dan mengambil cek null yang cekap dan penamaan jelas untuk mengoptimumkan prestasi kod dan kebolehbacaan.
