
 Peranti teknologi
AI
Dengan GPT-4, robot itu telah mempelajari cara memutar pen dan plat walnut.
Peranti teknologi
AI
Dengan GPT-4, robot itu telah mempelajari cara memutar pen dan plat walnut.
Dengan GPT-4, robot itu telah mempelajari cara memutar pen dan plat walnut.

Dari segi pembelajaran, GPT-4 adalah pelajar yang hebat. Selepas mencerna sejumlah besar data manusia, ia telah menguasai pelbagai pengetahuan malah boleh memberi inspirasi kepada ahli matematik Terence Tao semasa berbual.
Dalam masa yang sama, ia juga menjadi seorang guru yang cemerlang, bukan sahaja mengajar ilmu buku, tetapi juga mengajar robot memusing pen.

Robot itu dipanggil Eureka dan merupakan hasil penyelidikan daripada NVIDIA, Universiti Pennsylvania, Institut Teknologi California dan Universiti Texas di Austin. Penyelidikan ini menggabungkan penyelidikan tentang model bahasa besar dan pembelajaran pengukuhan: GPT-4 digunakan untuk memperhalusi fungsi ganjaran, dan pembelajaran pengukuhan digunakan untuk melatih pengawal robot.
Dengan keupayaan untuk menulis kod dalam GPT-4, Eureka mempunyai keupayaan reka bentuk fungsi ganjaran yang sangat baik. Keupayaan ini membolehkan robot menyelesaikan banyak tugas yang tidak mudah diselesaikan sebelum ini, seperti memusing pen, membuka laci dan kabinet, membaling dan menangkap bola, menggelecek, dan gunting operasi. Walau bagaimanapun, ini semua dilakukan dalam persekitaran maya buat masa ini.



Di samping itu, Eureka juga melaksanakan jenis RLHF dalam konteks baharu yang mampu menggabungkan maklum balas bahasa semula jadi daripada pengendali manusia untuk membimbing dan menyelaraskan ganjaran. Ia boleh menyediakan fungsi tambahan yang berkuasa untuk jurutera robot dan membantu jurutera mereka bentuk tingkah laku gerakan yang kompleks. Jim Fan, saintis AI kanan di Nvidia dan salah seorang pengarang kertas kerja, menyamakan penyelidikan ini dengan "Voyager (probe ruang galaksi luar yang dibangunkan dan dibina oleh Amerika Syarikat) dalam ruang API simulator fizik." . .pdf

Pautan projek: https://eureka-research.github.io/

- Tinjauan Kertas
- Model bahasa besar (LLM) cemerlang dalam perancangan semantik peringkat tinggi untuk tugasan robotik (cth. Google SayCan, robot RT-2), tetapi bolehkah ia digunakan untuk mempelajari tugasan manipulasi peringkat rendah yang kompleks, seperti pen-pusing, Masih soalan terbuka. Percubaan sedia ada memerlukan kepakaran domain yang luas untuk membina gesaan tugas atau mempelajari kemahiran mudah sahaja, jauh daripada fleksibiliti peringkat manusia.
- Robot RT-2 Google.
Sebaliknya, pembelajaran pengukuhan (RL) telah mencapai hasil yang mengagumkan dalam fleksibiliti dan banyak aspek lain (seperti tangan robot yang bermain Kiub Rubik OpenAI), tetapi memerlukan pereka manusia untuk membina fungsi ganjaran dengan teliti Mengkod dan menyediakan isyarat pembelajaran untuk tingkah laku yang diingini. Memandangkan banyak tugas pembelajaran pengukuhan dunia sebenar hanya memberikan ganjaran yang jarang yang sukar digunakan untuk pembelajaran, pembentukan ganjaran diperlukan dalam amalan untuk memberikan isyarat pembelajaran progresif. Walaupun kepentingannya, fungsi ganjaran amat sukar untuk direka bentuk. Tinjauan baru-baru ini mendapati bahawa 92% penyelidik dan pengamal pembelajaran pengukuhan yang ditinjau berkata mereka menggunakan percubaan dan kesilapan manual semasa mereka bentuk ganjaran, dan 89% mengatakan mereka mereka bentuk ganjaran yang tidak optimum dan membawa kepada akibat yang tidak diingini.
Memandangkan reka bentuk ganjaran sangat penting, kami tidak boleh tidak bertanya, adakah mungkin untuk membangunkan algoritma pengaturcaraan ganjaran umum menggunakan pengekodan terkini LLM (seperti GPT-4)? LLM ini mempunyai prestasi cemerlang dalam penulisan kod, penjanaan sifar pukulan dan pembelajaran dalam konteks, dan telah meningkatkan prestasi ejen pengaturcaraan dengan banyak. Sebaik-baiknya, algoritma reka bentuk ganjaran tersebut harus mempunyai keupayaan penjanaan ganjaran peringkat manusia, boleh diskalakan kepada pelbagai tugas, mengautomasikan proses percubaan dan kesilapan yang membosankan tanpa pengawasan manusia, sambil serasi dengan penyeliaan manusia untuk memastikan seks dan konsistensi .
Kertas kerja ini mencadangkan algoritma reka bentuk ganjaran EUREKA (nama penuh ialah Kit REward Universal dipacu Evolusi untuk Ejen) didorong oleh LLM. Algoritma telah mencapai pencapaian berikut:
1 Prestasi reka bentuk ganjaran telah mencapai tahap manusia dalam 29 persekitaran RL sumber terbuka yang berbeza, termasuk 10 bentuk robot yang berbeza (robot quadruped, robot quadcopter, robot bipedal, manipulator dan beberapa. tangan yang tangkas, lihat Rajah 1. Tanpa sebarang gesaan atau templat ganjaran khusus tugasan, ganjaran yang dijana secara autonomi EUREKA mengatasi ganjaran pakar manusia dalam 83% tugasan dan mencapai 52% purata peningkatan normal. tugas-tugas operasi ketangkasan yang sebelum ini mustahil dicapai melalui kejuruteraan ganjaran manual Ambil masalah memusing pen sebagai contoh seberapa banyak kitaran yang mungkin. Dengan menggabungkan EUREKA dengan pembelajaran kursus, para penyelidik menunjukkan operasi putaran pen pantas pada simulasi "Tangan Bayang" (Lihat bahagian bawah Rajah 1
3. Menyediakan kaedah pembelajaran konteks bebas kecerunan baharu untuk pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF), yang boleh menjana imej yang lebih cekap dan sejajar dengan manusia berdasarkan pelbagai bentuk input manusia Tahap fungsi ganjaran yang lebih tinggi boleh mendapat manfaat daripada dan meningkatkan fungsi ganjaran manusia sedia ada, penyelidik juga menunjukkan keupayaan EUREKA untuk menggunakan maklum balas teks manusia untuk membantu dalam mereka bentuk fungsi ganjaran 
Tidak seperti kerja L2R sebelumnya yang menggunakan reka bentuk ganjaran berbantukan LLM. , EUREKA tidak mempunyai gesaan tugas khusus, templat ganjaran dan sebilangan kecil contoh Dalam percubaan, EUREKA menunjukkan prestasi yang lebih baik daripada L2R Mendapat manfaat daripada keupayaannya untuk menjana dan memperhalusi program ganjaran ekspresif,
EUREKA. manfaat serba boleh daripada tiga pilihan reka bentuk algoritma utama: persekitaran sebagai konteks, carian evolusi dan refleksi ganjaran
Pertama, EUREKA boleh menjana fungsi ganjaran boleh laku daripada sampel sifar dalam pengekodan tulang belakang LLM (GPT-4) dengan mengambil persekitaran. kod sumber sebagai konteks Kemudian, EUREKA mencadangkan sekumpulan calon ganjaran dengan melakukan carian evolusi, dan memperhalusi ganjaran yang paling menjanjikan dalam tetingkap konteks LLM, dengan itu meningkatkan kualiti ganjaran dalam konteks ini , yang merupakan ringkasan tekstual kualiti ganjaran berdasarkan statistik latihan dasar dan pengeditan ganjaran yang disasarkan boleh dicapai
Rajah 3 ialah contoh ganjaran sampel sifar EUREKA, serta pelbagai peningkatan yang terkumpul semasa pengoptimuman. Untuk memastikan EUREKA dapat mengembangkan carian ganjarannya kepada potensi maksimumnya, EUREKA dilaksanakan dalam pembelajaran tetulang teragih dipercepatkan GPU digunakan untuk menilai ganjaran perantaraan, yang menyediakan sehingga tiga urutan peningkatan dalam kelajuan pembelajaran dasar. EUREKA algoritma luas yang berskala secara semula jadi apabila jumlah pengiraan meningkat.
Seperti yang ditunjukkan dalam Rajah 2. Para penyelidik komited untuk mendapatkan sumber terbuka semua gesaan, persekitaran dan fungsi ganjaran yang dijana untuk memudahkan penyelidikan lanjut mengenai reka bentuk ganjaran berasaskan LLM.

Pengenalan kaedah
 EUREKA boleh menulis algoritma ganjaran secara bebas. Mari kita lihat cara melaksanakannya.
EUREKA boleh menulis algoritma ganjaran secara bebas. Mari kita lihat cara melaksanakannya.
EUREKA terdiri daripada tiga komponen algoritmik: 1) persekitaran sebagai konteks, dengan itu menyokong penjanaan sifar ganjaran boleh laku; 2) carian evolusi, mengusulkan secara berulang dan menambah baik calon ganjaran, menyokong penambahbaikan Ganjaran yang terperinci .
Persekitaran sebagai konteks
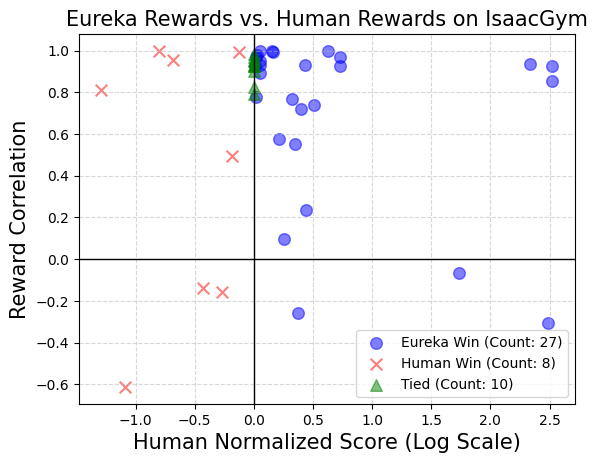
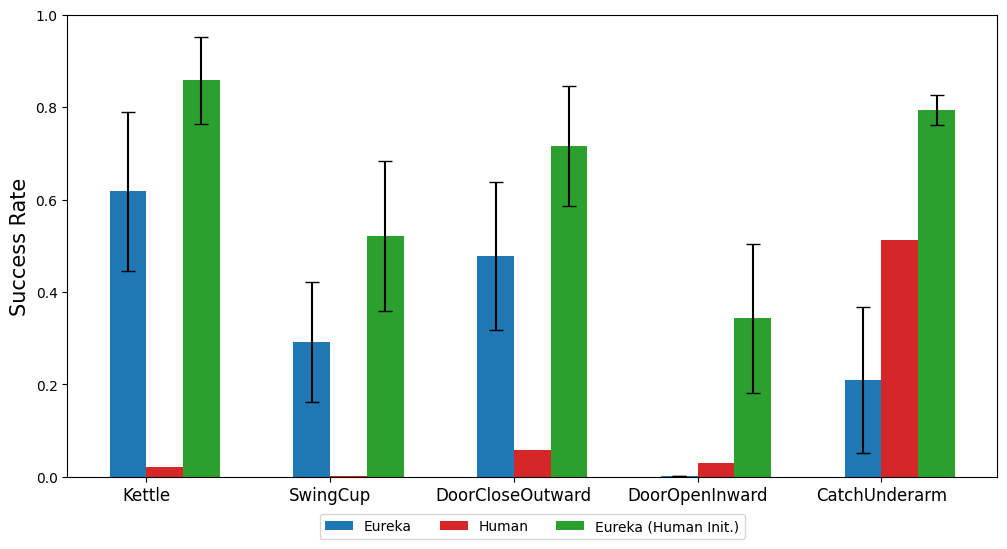
Artikel ini mengesyorkan menyediakan terus kod persekitaran asal sebagai konteks. Dengan hanya arahan yang minimum, EUREKA boleh menjana ganjaran dalam persekitaran yang berbeza dengan sampel sifar. Contoh output EUREKA ditunjukkan dalam Rajah 3. EUREKA pakar menggabungkan pembolehubah pemerhatian sedia ada (cth., kedudukan hujung jari) dalam kod persekitaran yang disediakan dan menghasilkan kod ganjaran yang sah - semuanya tanpa sebarang templat kejuruteraan petunjuk khusus persekitaran atau ganjaran. Walau bagaimanapun, ganjaran yang dijana mungkin tidak sentiasa boleh dilaksanakan pada percubaan pertama, dan walaupun ia boleh dilaksanakan, ia mungkin tidak optimum. Ini menimbulkan persoalan, iaitu, bagaimana untuk mengatasi suboptimum penjanaan ganjaran sampel tunggal secara berkesan? Pencarian Evolusi Kemudian, kertas kerja memperkenalkan cara carian evolusi boleh menyelesaikan masalah penyelesaian sub-optimum yang dinyatakan di atas. Ia diperhalusi sedemikian rupa sehingga dalam setiap lelaran, EUREKA mengambil sampel beberapa output bebas LLM (baris 5 dalam Algoritma 1). Oleh kerana setiap lelaran (generasi) diedarkan secara bebas dan sama, apabila bilangan sampel bertambah, kebarangkalian ralat dalam semua fungsi ganjaran dalam lelaran berkurangan secara eksponen. Refleksi Ganjaran Untuk menyediakan analisis ganjaran yang lebih kompleks dan disasarkan, artikel ini mencadangkan membina maklum balas automatik teks untuk meringkaskan latihan dasar. Khususnya, memandangkan fungsi ganjaran EUREKA memerlukan komponen individu dalam program ganjaran (seperti komponen ganjaran dalam Rajah 3), kami menjejaki nilai skalar semua komponen ganjaran di pusat pemeriksaan dasar perantaraan sepanjang proses latihan. Walaupun sangat mudah untuk membina proses refleksi ganjaran ini, disebabkan kebergantungan algoritma pengoptimuman ganjaran, kaedah pembinaan ini sangat penting. Iaitu, sama ada fungsi ganjaran adalah cekap dipengaruhi oleh pilihan khusus algoritma RL, dan ganjaran yang sama boleh berkelakuan sangat berbeza walaupun di bawah pengoptimum yang sama memandangkan perbezaan dalam hiperparameter. Dengan memperincikan cara algoritma RL mengoptimumkan komponen ganjaran individu, refleksi ganjaran membolehkan EUREKA menghasilkan lebih banyak pengeditan ganjaran disasarkan dan mensintesis fungsi ganjaran yang lebih bersinergi dengan algoritma RL tetap. Bahagian eksperimen menjalankan penilaian menyeluruh Eureka, termasuk keupayaannya untuk menjana fungsi ganjaran, keupayaannya untuk menyelesaikan tugasan baharu, dan keupayaannya untuk mengintegrasikan pelbagai input manusia. Persekitaran eksperimen termasuk 10 robot berbeza dan 29 tugasan, antaranya 29 tugasan ini dilaksanakan oleh simulator IsaacGym. Eksperimen telah dijalankan menggunakan 9 persekitaran asal dari IsaacGym (Isaac), meliputi pelbagai morfologi robot daripada berkaki empat, biped, quadcopter, manipulator, dan tangan robot yang cekap. Di samping itu, kertas itu memastikan kedalaman penilaian dengan memasukkan 20 tugasan daripada penanda aras Ketangkasan. Eureka boleh menjana fungsi ganjaran tahap supermanusia. Merentasi 29 tugasan, fungsi ganjaran yang diberikan oleh Eureka menunjukkan prestasi yang lebih baik daripada ganjaran yang ditulis oleh pakar pada 83% tugasan, dengan purata peningkatan sebanyak 52%. Khususnya, Eureka mencapai keuntungan yang lebih besar dalam persekitaran penanda aras Ketangkasan dimensi tinggi. Eureka dapat mengembangkan carian ganjaran supaya ganjaran terus bertambah baik dari semasa ke semasa. Dengan menggabungkan carian ganjaran berskala besar dan maklum balas refleksi ganjaran terperinci, Eureka secara beransur-ansur menghasilkan ganjaran yang lebih baik, akhirnya mengatasi prestasi manusia. Eureka juga menjana ganjaran baru. Kertas kerja ini menilai kebaharuan ganjaran Eureka dengan mengira korelasi antara ganjaran Eureka dan ganjaran manusia pada semua tugas Ishak. Seperti yang ditunjukkan dalam rajah, Eureka terutamanya menjana fungsi ganjaran yang berkorelasi lemah, yang mengatasi fungsi ganjaran manusia. Di samping itu, kami mendapati bahawa lebih sukar tugas itu, semakin kurang relevan ganjaran Eureka. Dalam sesetengah kes, ganjaran Eureka malah berkorelasi negatif dengan ganjaran manusia namun dengan ketara mengatasinya. Jika anda ingin menyedari bahawa tangan robot yang lincah boleh terus memusingkan pen, program pengendalian perlu mempunyai seberapa banyak kitaran yang mungkin. Kertas kerja ini menangani tugas ini dengan (1) mengarahkan Eureka menjana fungsi ganjaran yang digunakan untuk mengubah hala pen ke konfigurasi sasaran rawak, dan kemudian (2) menggunakan ganjaran Eureka untuk memperhalusi dasar pra-latihan ini untuk mencapai penggiliran jujukan pen yang diingini konfigurasi. Seperti yang ditunjukkan dalam rajah, pemutar Eureka cepat menyesuaikan diri dengan strategi dan berjaya diputar untuk banyak kitaran berturut-turut. Sebaliknya, dasar yang telah dilatih atau dipelajari dari awal tidak boleh melengkapkan satu kitaran putaran. Kertas ini juga menyiasat sama ada berfaedah untuk Eureka memulakan dengan permulaan fungsi ganjaran manusia. Seperti yang ditunjukkan, Eureka bertambah baik dan mendapat manfaat daripada ganjaran manusia tanpa mengira kualitinya. Eureka juga melaksanakan RLHF, yang boleh menggabungkan maklum balas manusia untuk mengubah suai ganjaran, dengan itu secara beransur-ansur membimbing ejen untuk melengkapkan tingkah laku yang lebih selamat dan lebih seperti manusia. Contoh menunjukkan bagaimana Eureka mengajar robot humanoid untuk berlari tegak dengan beberapa maklum balas manusia yang menggantikan pantulan ganjaran automatik sebelumnya. Robot humanoid belajar berjalan melalui Eureka. Untuk maklumat lanjut, sila rujuk kertas asal. 



Eksperimen





Atas ialah kandungan terperinci Dengan GPT-4, robot itu telah mempelajari cara memutar pen dan plat walnut.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
Perintah untuk memulakan semula perkhidmatan SSH ialah: Sistem Restart SSHD. Langkah -langkah terperinci: 1. Akses terminal dan sambungkan ke pelayan; 2. Masukkan arahan: SistemCtl Restart SSHD; 3. Sahkan Status Perkhidmatan: Status Sistem SSHD.
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
