
 ditemui oleh Kod LLaMA dan LLaMA2 Long dan kajian lain -
ditemui oleh Kod LLaMA dan LLaMA2 Long dan kajian lain -  Peranti teknologi
AI
Panjang konteks LLaMA2 melonjak kepada 1 juta token, dengan hanya satu hiperparameter perlu dilaraskan.
Peranti teknologi
AI
Panjang konteks LLaMA2 melonjak kepada 1 juta token, dengan hanya satu hiperparameter perlu dilaraskan.
Panjang konteks LLaMA2 melonjak kepada 1 juta token, dengan hanya satu hiperparameter perlu dilaraskan.

Dengan hanya beberapa tweak, saiz konteks sokongan model besar boleh dilanjutkan daripada 16,000 token kepada 1 juta? !
Masih on LLaMA 2 yang hanya mempunyai 7 bilion parameter.
Anda mesti tahu bahawa Claude 2 dan GPT-4 yang popular pada masa ini menyokong panjang konteks hanya 100,000 dan 32,000 Di luar julat ini, model besar akan mula bercakap kosong dan tidak dapat mengingati sesuatu.
Kini, kajian baharu dari Universiti Fudan dan Makmal Kepintaran Buatan Shanghai bukan sahaja menemui cara untuk meningkatkan panjang tetingkap konteks untuk satu siri model besar, tetapi juga menemui peraturan.

Mengikut peraturan ini, hanya perlu melaraskan 1 hiperparameter, boleh memastikan kesan output sambil meningkatkan prestasi ekstrapolasi model besar secara stabil.
Ekstrapolasi merujuk kepada perubahan dalam prestasi output apabila panjang input model besar melebihi panjang teks pra-latihan. Jika keupayaan ekstrapolasi tidak baik, apabila panjang input melebihi panjang teks pra-latihan, model besar akan "bercakap bukan-bukan".
Jadi, apakah sebenarnya ia boleh meningkatkan keupayaan ekstrapolasi model besar, dan bagaimana ia melakukannya?
"Mekanisme" untuk meningkatkan keupayaan ekstrapolasi model besar
Kaedah meningkatkan keupayaan ekstrapolasi model besar ini berkaitan dengan modul yang dipanggil Pengekodan Kedudukan dalam seni bina Transformer.
Malah, modul mekanisme perhatian mudah (Perhatian) tidak dapat membezakan token dalam kedudukan yang berbeza Sebagai contoh, "Saya makan epal" dan "epal makan saya" tidak mempunyai perbezaan di matanya.
Oleh itu, pengekodan kedudukan perlu ditambah untuk membolehkannya memahami maklumat susunan perkataan dan benar-benar memahami maksud sesuatu ayat.
Kaedah pengekodan kedudukan Transformer semasa termasuk pengekodan kedudukan mutlak (mengintegrasikan maklumat kedudukan ke dalam input), pengekodan kedudukan relatif (menulis maklumat kedudukan ke dalam pengiraan skor perhatian) dan pengekodan kedudukan putaran. Antaranya, yang paling popular ialah pengekodan kedudukan putaran, iaitu RoPE.
RoPE mencapai kesan pengekodan kedudukan relatif melalui pengekodan kedudukan mutlak, tetapi berbanding dengan pengekodan kedudukan relatif, ia boleh meningkatkan potensi ekstrapolasi model besar dengan lebih baik.
Cara untuk merangsang lagi keupayaan ekstrapolasi model besar menggunakan pengekodan kedudukan RoPE juga telah menjadi hala tuju baharu dalam banyak kajian terkini.
Kajian ini terbahagi terutamanya kepada dua sekolah utama: menghadkan perhatian dan melaraskan sudut putaran.
Penyelidikan perwakilan tentang mengehadkan perhatian termasuk ALiBi, xPos, BCA, dsb. StreamingLLM baru-baru ini dicadangkan oleh MIT boleh membenarkan model besar mencapai panjang input tak terhingga (tetapi tidak meningkatkan panjang tetingkap konteks), yang tergolong dalam jenis penyelidikan ke arah ini.
△Pengarang sumber imej
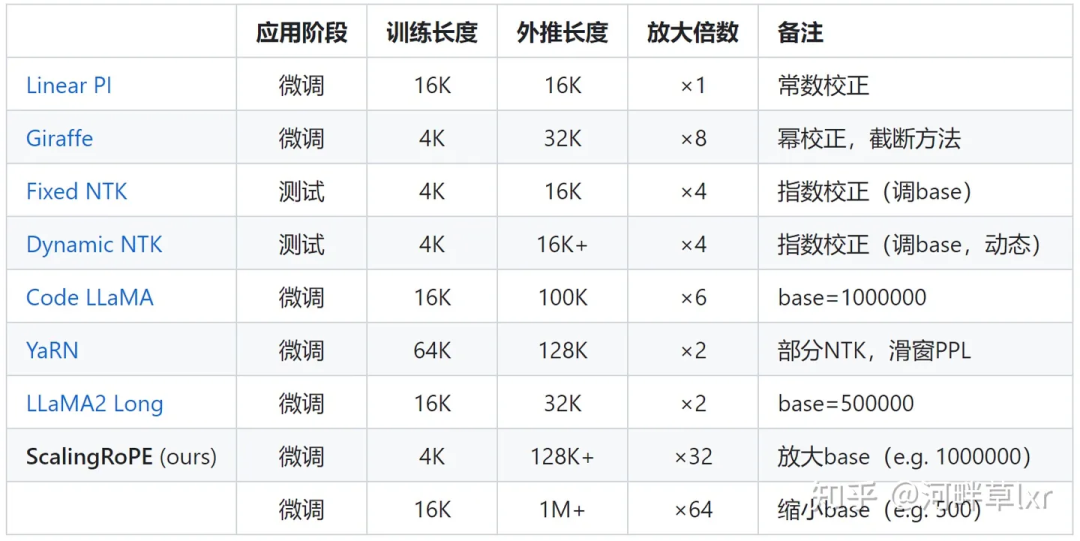
mempunyai lebih banyak kerja yang perlu dilakukan untuk melaraskan sudut putaran Perwakilan biasa seperti interpolasi linear, Zirafah, Kod LLaMA, LLaMA2 Panjang, dll. semuanya tergolong dalam jenis penyelidikan ini. .
Hiperparameter ini betul-betul "suis"  ditemui oleh Kod LLaMA dan LLaMA2 Long dan kajian lain -
ditemui oleh Kod LLaMA dan LLaMA2 Long dan kajian lain -
pangkal sudut putaran (tapak). Hanya memperhalusinya untuk memastikan prestasi ekstrapolasi yang lebih baik bagi model besar.
Tetapi sama ada Kod LLaMA atau LLaMA2 Long, mereka hanya diperhalusi pada asas tertentu dan tempoh latihan berterusan untuk meningkatkan keupayaan ekstrapolasi mereka. Bolehkah kami mencari peraturan untuk memastikan
semuamodel besar yang menggunakan pengekodan kedudukan RoPE dapat meningkatkan prestasi ekstrapolasi secara stabil? Kuasai peraturan ini, konteksnya mudah 100w+
Penyelidik dari Universiti Fudan dan Institut Penyelidikan AI Shanghai menjalankan eksperimen tentang masalah ini.
Mereka mula-mula menganalisis beberapa parameter yang mempengaruhi keupayaan ekstrapolasi RoPE, dan mencadangkan konsep yang dipanggil
Dimensi Kritikal(Dimensi Kritikal Kemudian berdasarkan konsep ini, mereka meringkaskan satu set Undang-undang Penskalaan Penskalaan RoPE bagi Ekstrapolasi berasaskan RoPE).
Hanya gunakanundang
ini untuk memastikan mana-mana model besar berdasarkan pengekodan kedudukan RoPE boleh meningkatkan keupayaan ekstrapolasi. Mari kita lihat dahulu apakah dimensi kritikal itu.Daripada definisi, ia berkaitan dengan Ttrain panjang teks pra-latihan, bilangan dimensi kepala perhatian diri d dan parameter lain Kaedah pengiraan khusus adalah seperti berikut:

Antaranya, 10000 ialah "nilai awal" hiperparameter dan tapak sudut putaran.
Penulis mendapati bahawa sama ada tapak dibesarkan atau dikurangkan, keupayaan ekstrapolasi model besar berdasarkan RoPE boleh dipertingkatkan pada akhirnya, sebaliknya, apabila asas sudut putaran ialah 10000, keupayaan ekstrapolasi model besar adalah yang paling teruk.
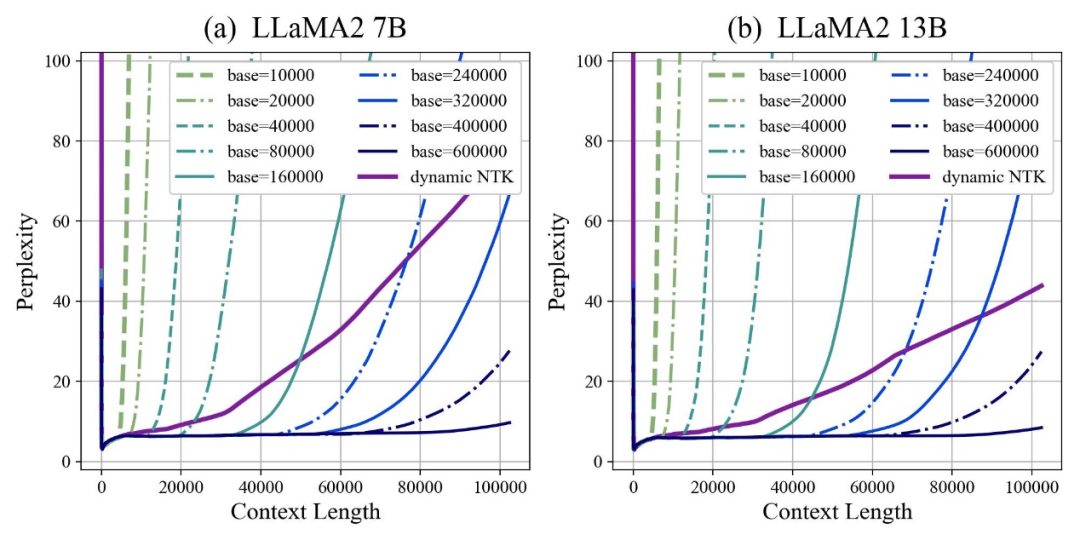
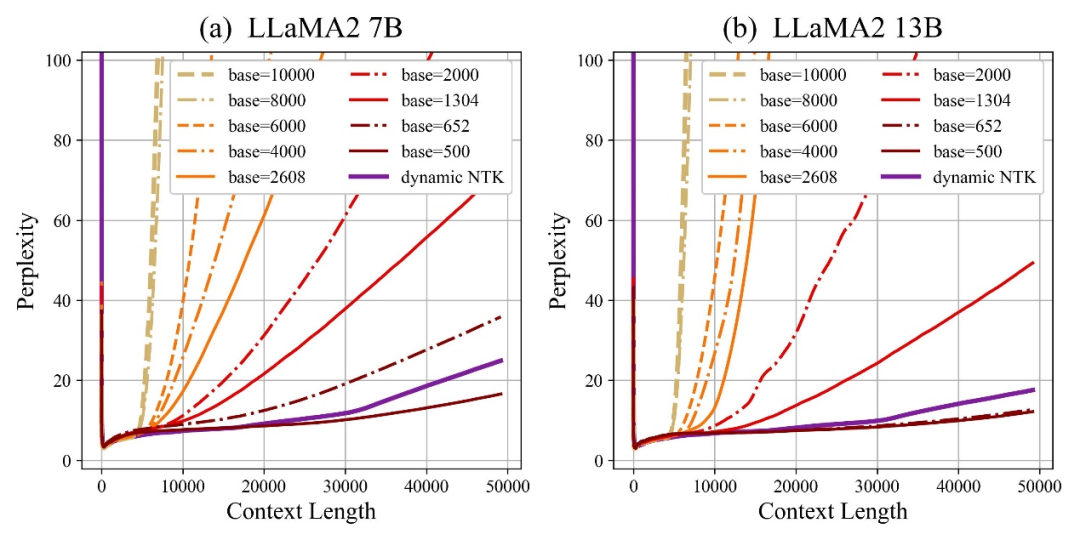
Makalah ini percaya bahawa asas sudut putaran yang lebih kecil boleh membolehkan maklumat kedudukan dilihat dalam lebih banyak dimensi asas sudut putaran, lebih lama maklumat kedudukan boleh dinyatakan.
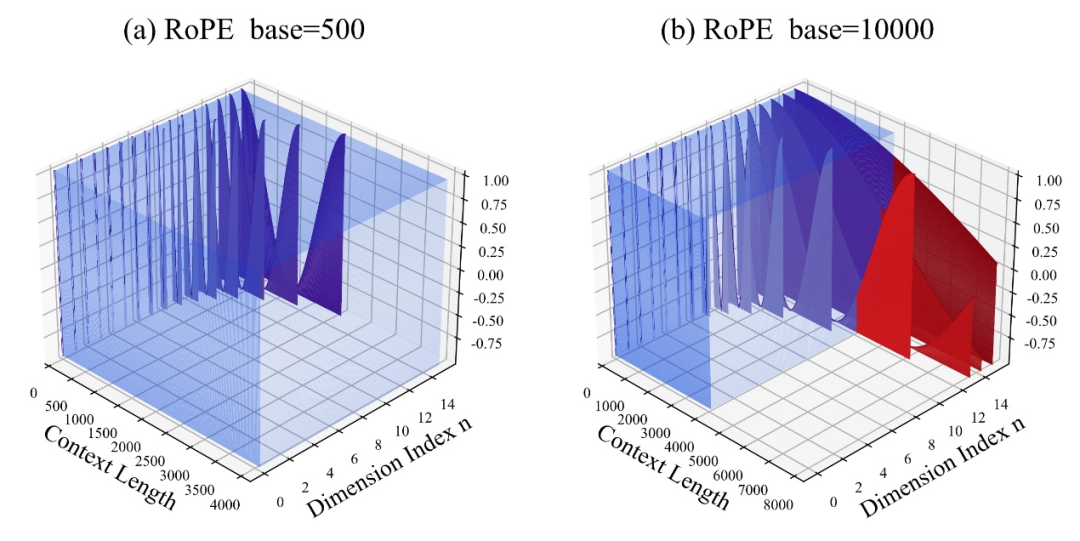
Dalam kes ini, apabila menghadapi korpus latihan berterusan dengan panjang yang berbeza, berapa banyak asas sudut putaran perlu dikurangkan dan dibesarkan untuk memastikan maksimum Adakah keupayaan ekstrapolasi model telah dimaksimumkan?
Kertas memberikan peraturan penskalaan untuk ekstrapolasi RoPE lanjutan, yang berkaitan dengan parameter seperti dimensi kritikal, panjang teks latihan berterusan dan panjang teks pra-latihan model besar:
#🎜🎜 ## 🎜🎜# Berdasarkan peraturan ini, prestasi ekstrapolasi model besar boleh dikira terus berdasarkan pra-latihan yang berbeza dan panjang teks latihan berterusan Dengan kata lain, panjang konteks yang disokong oleh model besar diramalkan.
Berdasarkan peraturan ini, prestasi ekstrapolasi model besar boleh dikira terus berdasarkan pra-latihan yang berbeza dan panjang teks latihan berterusan Dengan kata lain, panjang konteks yang disokong oleh model besar diramalkan.
Sebaliknya, menggunakan peraturan ini, anda boleh dengan cepat menyimpulkan cara terbaik melaraskan asas sudut putaran, dengan itu meningkatkan prestasi ekstrapolasi model besar.
Penulis menguji siri tugasan ini dan mendapati bahawa pada masa ini memasukkan 100,000, 500,000 atau 1 juta panjang token boleh menjamin bahawa ekstrapolasi boleh dicapai tanpa sekatan perhatian tambahan.
Pada masa yang sama, usaha untuk meningkatkan keupayaan ekstrapolasi model besar, termasuk Kod LLaMA dan LLaMA2 Long, telah membuktikan bahawa peraturan ini sememangnya munasabah dan berkesan.
Dengan cara ini, anda hanya perlu "melaraskan parameter" mengikut peraturan ini, dan anda boleh mengembangkan panjang tetingkap konteks model besar dengan mudah berdasarkan RoPE dan meningkatkan keupayaan ekstrapolasi.
Liu Xiaoran, pengarang pertama kertas itu, berkata bahawa penyelidikan ini masih menambah baik kesan tugasan hiliran dengan menambah baik korpus latihan yang berterusan Setelah selesai, kod dan model akan menjadi sumber terbuka nantikan~
# 🎜🎜#Alamat kertas:
https://arxiv.org/abs/2310.05209#🎜🎜 #
# 🎜🎜#Repositori Github:
https://github.com/OpenLMLab/scaling-rope#🎜🎜 🎜🎜##🎜🎜 #thesisanalyticsblog:
https://zhuanlan.zhihu.com/p/66007##3229🎜🎜🎜🎜
Atas ialah kandungan terperinci Panjang konteks LLaMA2 melonjak kepada 1 juta token, dengan hanya satu hiperparameter perlu dilaraskan.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Gunakan ddrescue untuk memulihkan data pada Linux
Mar 20, 2024 pm 01:37 PM
Gunakan ddrescue untuk memulihkan data pada Linux
Mar 20, 2024 pm 01:37 PM
DDREASE ialah alat untuk memulihkan data daripada fail atau peranti sekat seperti cakera keras, SSD, cakera RAM, CD, DVD dan peranti storan USB. Ia menyalin data dari satu peranti blok ke peranti lain, meninggalkan blok data yang rosak dan hanya memindahkan blok data yang baik. ddreasue ialah alat pemulihan yang berkuasa yang automatik sepenuhnya kerana ia tidak memerlukan sebarang gangguan semasa operasi pemulihan. Selain itu, terima kasih kepada fail peta ddasue, ia boleh dihentikan dan disambung semula pada bila-bila masa. Ciri-ciri utama lain DDREASE adalah seperti berikut: Ia tidak menimpa data yang dipulihkan tetapi mengisi jurang sekiranya pemulihan berulang. Walau bagaimanapun, ia boleh dipotong jika alat itu diarahkan untuk melakukannya secara eksplisit. Pulihkan data daripada berbilang fail atau blok kepada satu
 Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
0. Apakah fungsi artikel ini? Kami mencadangkan DepthFM: model anggaran kedalaman monokular generatif yang serba boleh dan pantas. Sebagai tambahan kepada tugas anggaran kedalaman tradisional, DepthFM juga menunjukkan keupayaan terkini dalam tugas hiliran seperti mengecat kedalaman. DepthFM cekap dan boleh mensintesis peta kedalaman dalam beberapa langkah inferens. Mari kita baca karya ini bersama-sama ~ 1. Tajuk maklumat kertas: DepthFM: FastMonocularDepthEstimationwithFlowMatching Pengarang: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Cara menggunakan fungsi penapis Excel dengan berbilang syarat
Feb 26, 2024 am 10:19 AM
Cara menggunakan fungsi penapis Excel dengan berbilang syarat
Feb 26, 2024 am 10:19 AM
Jika anda perlu tahu cara menggunakan penapisan dengan berbilang kriteria dalam Excel, tutorial berikut akan membimbing anda melalui langkah-langkah untuk memastikan anda boleh menapis dan mengisih data anda dengan berkesan. Fungsi penapisan Excel sangat berkuasa dan boleh membantu anda mengekstrak maklumat yang anda perlukan daripada sejumlah besar data. Fungsi ini boleh menapis data mengikut syarat yang anda tetapkan dan memaparkan hanya bahagian yang memenuhi syarat, menjadikan pengurusan data lebih cekap. Dengan menggunakan fungsi penapis, anda boleh mencari data sasaran dengan cepat, menjimatkan masa dalam mencari dan menyusun data. Fungsi ini bukan sahaja boleh digunakan pada senarai data ringkas, tetapi juga boleh ditapis berdasarkan berbilang syarat untuk membantu anda mencari maklumat yang anda perlukan dengan lebih tepat. Secara keseluruhan, fungsi penapisan Excel adalah sangat berguna
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Menghadapi ketinggalan, sambungan data mudah alih perlahan pada iPhone? Biasanya, kekuatan internet selular pada telefon anda bergantung pada beberapa faktor seperti rantau, jenis rangkaian selular, jenis perayauan, dsb. Terdapat beberapa perkara yang boleh anda lakukan untuk mendapatkan sambungan Internet selular yang lebih pantas dan boleh dipercayai. Betulkan 1 – Paksa Mulakan Semula iPhone Kadangkala, paksa memulakan semula peranti anda hanya menetapkan semula banyak perkara, termasuk sambungan selular. Langkah 1 – Hanya tekan kekunci naikkan kelantangan sekali dan lepaskan. Seterusnya, tekan kekunci Turun Kelantangan dan lepaskannya semula. Langkah 2 - Bahagian seterusnya proses adalah untuk menahan butang di sebelah kanan. Biarkan iPhone selesai dimulakan semula. Dayakan data selular dan semak kelajuan rangkaian. Semak semula Betulkan 2 – Tukar mod data Walaupun 5G menawarkan kelajuan rangkaian yang lebih baik, ia berfungsi lebih baik apabila isyarat lemah
 Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Saya menangis hingga mati. Dunia sedang membina model besar. Data di Internet tidak mencukupi. Model latihan kelihatan seperti "The Hunger Games", dan penyelidik AI di seluruh dunia bimbang tentang cara memberi makan data ini kepada pemakan yang rakus. Masalah ini amat ketara dalam tugas berbilang modal. Pada masa mereka mengalami kerugian, pasukan pemula dari Jabatan Universiti Renmin China menggunakan model baharu mereka sendiri untuk menjadi yang pertama di China untuk menjadikan "suapan data yang dijana model itu sendiri" menjadi kenyataan. Selain itu, ia merupakan pendekatan serampang dua mata dari segi pemahaman dan sisi penjanaan Kedua-dua pihak boleh menjana data baharu berbilang modal yang berkualiti tinggi dan memberikan maklum balas data kepada model itu sendiri. Apakah model? Awaker 1.0, model berbilang modal besar yang baru sahaja muncul di Forum Zhongguancun. Siapa pasukan itu? Enjin Sophon. Diasaskan oleh Gao Yizhao, pelajar kedoktoran di Sekolah Kecerdasan Buatan Hillhouse Universiti Renmin.
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 Robot pertama yang menyelesaikan tugas manusia secara autonomi muncul, dengan lima jari fleksibel dan kelajuan manusia luar biasa, dan model besar menyokong latihan angkasa maya
Mar 11, 2024 pm 12:10 PM
Robot pertama yang menyelesaikan tugas manusia secara autonomi muncul, dengan lima jari fleksibel dan kelajuan manusia luar biasa, dan model besar menyokong latihan angkasa maya
Mar 11, 2024 pm 12:10 PM
Minggu ini, FigureAI, sebuah syarikat robotik yang dilaburkan oleh OpenAI, Microsoft, Bezos, dan Nvidia, mengumumkan bahawa ia telah menerima hampir $700 juta dalam pembiayaan dan merancang untuk membangunkan robot humanoid yang boleh berjalan secara bebas dalam tahun hadapan. Dan Optimus Prime Tesla telah berulang kali menerima berita baik. Tiada siapa yang meragui bahawa tahun ini akan menjadi tahun apabila robot humanoid meletup. SanctuaryAI, sebuah syarikat robotik yang berpangkalan di Kanada, baru-baru ini mengeluarkan robot humanoid baharu, Phoenix. Pegawai mendakwa bahawa ia boleh menyelesaikan banyak tugas secara autonomi pada kelajuan yang sama seperti manusia. Pheonix, robot pertama di dunia yang boleh menyelesaikan tugas secara autonomi pada kelajuan manusia, boleh mencengkam, menggerakkan dan meletakkan setiap objek secara elegan di sisi kiri dan kanannya dengan perlahan. Ia boleh mengenal pasti objek secara autonomi
